
Viele Leute denken, dass es ausreicht, die Anwendung auf Kubernetes zu portieren (entweder mit Helm oder manuell), und es wird Glück geben. Aber so einfach ist das nicht.
Das Mail.ru Cloud Solutions- Team hateinen Artikel des DevOps-Ingenieurs Julian Guindi übersetzt. Er spricht über die Fallstricke, mit denen sein Unternehmen während des Migrationsprozesses konfrontiert war, damit Sie nicht auf denselben Rechen treten.
Schritt eins: Pod-Anforderungen und -Limits einrichten
Beginnen wir mit der Einrichtung einer sauberen Umgebung, in der unsere Pods ausgeführt werden. Kubernetes eignet sich hervorragend zum Planen von Pods und zum Behandeln von Fehlerzuständen. Es stellte sich jedoch heraus, dass der Planer manchmal keinen Pod platzieren kann, wenn es schwierig ist, abzuschätzen, wie viele Ressourcen er benötigt, um erfolgreich zu arbeiten. Hier kommen Ressourcenanforderungen und -limits ins Spiel. Es gab viele Debatten über den besten Ansatz zur Festlegung von Anforderungen und Grenzen. Manchmal scheint es wirklich mehr Kunst als Wissenschaft zu sein. Hier ist unser Ansatz.
Pod-Anforderungen sind der Hauptwert, den der Scheduler für eine optimale Pod-Platzierung verwendet.
Kubernetes: , . , PodFitsResources , .
Wir verwenden Anwendungsanforderungen, damit wir daraus abschätzen können, wie viele Ressourcen die Anwendung tatsächlich für den normalen Betrieb benötigt. Dadurch kann der Planer die Knoten realistisch platzieren. Ursprünglich wollten wir Anforderungen mit einem Spielraum einrichten, um sicherzustellen, dass für jeden Pod genügend Ressourcen vorhanden sind. Wir haben jedoch festgestellt, dass sich die Planungszeit erheblich erhöht hat und einige Pods nie vollständig geplant wurden, als ob keine Ressourcenanforderungen für sie vorhanden wären.
In diesem Fall "quetschte" der Scheduler häufig Pods und konnte sie nicht neu planen, da die Steuerebene keine Ahnung hatte, wie viel Ressourcen die Anwendung benötigen würde, was eine Schlüsselkomponente des Scheduling-Algorithmus ist.
Pod-GrenzenIst eine klarere Einschränkung für den Pod. Es stellt die maximale Menge an Ressourcen dar, die der Cluster dem Container zuweist.
Nochmals aus der offiziellen Dokumentation : Wenn für einen Container ein Speicherlimit von 4 GiB festgelegt ist, wird dies durch Kubelet (und die Container-Laufzeit) erzwungen. Die Laufzeit verhindert, dass der Container mehr als das angegebene Ressourcenlimit verwendet. Wenn beispielsweise ein Prozess in einem Container versucht, mehr als die zulässige Speichermenge zu verwenden, beendet der Kernel den Prozess mit einem OOM-Fehler (Out of Memory).
Ein Container kann immer mehr Ressourcen als in einer Ressourcenanforderung angegeben verwenden, jedoch niemals mehr als in einem Limit angegeben. Dieser Wert ist schwer richtig einzustellen, aber sehr wichtig.
Idealerweise möchten wir, dass sich die Ressourcenanforderungen des Pods während des gesamten Prozesslebenszyklus ändern, ohne andere Prozesse im System zu beeinträchtigen. Dies ist das Ziel, Grenzen zu setzen.
Leider kann ich keine spezifischen Anweisungen geben, welche Werte eingestellt werden sollen, aber wir halten uns selbst an die folgenden Regeln:
- Mit einem Lasttest-Tool simulieren wir den Basisdatenverkehr und überwachen die Pod-Ressourcennutzung (Speicher und Prozessor).
- ( 5 ) . , , Go.
Beachten Sie, dass höhere Ressourcenbeschränkungen die Planung erschweren, da der Pod einen Zielknoten mit genügend verfügbaren Ressourcen benötigt.
Stellen Sie sich eine Situation vor, in der Sie einen leichtgewichtigen Webserver mit einer sehr hohen Ressourcenbeschränkung wie 4 GB Speicher haben. Dieser Prozess muss wahrscheinlich horizontal skaliert werden und jedes neue Modul muss auf einem Knoten mit mindestens 4 GB verfügbarem Speicher geplant werden. Wenn kein solcher Knoten vorhanden ist, muss der Cluster einen neuen Knoten einführen, um diesen Pod zu verarbeiten. Dies kann einige Zeit dauern. Es ist wichtig, den Abstand zwischen Ressourcenanforderungen und -grenzen so gering wie möglich zu halten, um eine schnelle und reibungslose Skalierung zu gewährleisten.
Schritt zwei: Richten Sie die Lebendigkeits- und Bereitschaftstests ein
Dies ist ein weiteres subtiles Thema, das in der Kubernetes-Community häufig diskutiert wird. Es ist wichtig, ein gutes Verständnis der Liveness- und Readiness-Tests zu haben, da diese einen Mechanismus für den reibungslosen Betrieb der Software und die Minimierung von Ausfallzeiten bieten. Sie können jedoch die Leistung Ihrer Anwendung erheblich beeinträchtigen, wenn sie nicht richtig konfiguriert werden. Nachfolgend finden Sie eine Zusammenfassung der beiden Beispiele.
Die Lebensdauer zeigt an, ob der Container ausgeführt wird. Wenn dies fehlschlägt, beendet das Kubelet den Container und eine Neustartrichtlinie ist dafür aktiviert. Wenn der Container nicht mit einer Liveness-Sonde ausgestattet ist, ist der Standardstatus erfolgreich - wie in der Kubernetes-Dokumentation angegeben .
Liveness-Tests sollten billig sein, d. H. Nicht viele Ressourcen verbrauchen, da sie häufig ausgeführt werden und Kubernetes darüber informieren sollten, dass die Anwendung ausgeführt wird.
Wenn Sie festlegen, dass es jede Sekunde ausgeführt wird, wird 1 Anforderung pro Sekunde hinzugefügt. Beachten Sie daher, dass zusätzliche Ressourcen erforderlich sind, um diesen Datenverkehr zu verarbeiten.
In unserem Unternehmen validieren Liveness-Tests die Hauptkomponenten einer Anwendung, auch wenn die Daten (z. B. aus einer entfernten Datenbank oder einem Cache) nicht vollständig verfügbar sind.
Wir haben in Anwendungen einen "Integritäts" -Endpunkt konfiguriert, der einfach einen Antwortcode von 200 zurückgibt. Dies ist ein Hinweis darauf, dass ein Prozess aktiv ist und Anforderungen verarbeiten kann (aber noch keinen Datenverkehr). Bereitschaft
TestGibt an, ob der Container bereit ist, Anforderungen zu bedienen. Wenn die Bereitschaftsprüfung fehlschlägt, entfernt der Endpoint Controller die Pod-IP-Adresse von den Endpunkten aller Dienste, die mit dem Pod übereinstimmen. Dies ist auch in der Kubernetes-Dokumentation angegeben.
Bereitschaftsprüfungen verbrauchen mehr Ressourcen, da sie so an das Backend gesendet werden müssen, dass angezeigt wird, dass die Anwendung bereit ist, Anforderungen anzunehmen.
In der Community wird viel darüber diskutiert, ob direkt in die Datenbank gewechselt werden soll. Angesichts des Overheads (Überprüfungen werden häufig durchgeführt, können jedoch angepasst werden) haben wir entschieden, dass für einige Anwendungen die Verfügbarkeit für die Bereitstellung des Datenverkehrs erst gezählt wird, nachdem überprüft wurde, ob Datensätze aus der Datenbank zurückgegeben werden. Gut konzipierte Verfügbarkeitssonden stellten eine höhere Verfügbarkeit sicher und eliminierten Ausfallzeiten während der Bereitstellung.
Wenn Sie die Datenbank abfragen möchten, um zu überprüfen, ob Ihre Anwendung bereit ist, stellen Sie sicher, dass sie so billig wie möglich ist. Nehmen wir eine Abfrage wie folgt:
SELECT small_item FROM table LIMIT 1Hier ist ein Beispiel, wie wir diese beiden Werte in Kubernetes konfigurieren:
livenessProbe:
httpGet:
path: /api/liveness
port: http
readinessProbe:
httpGet:
path: /api/readiness
port: http periodSeconds: 2
Einige zusätzliche Konfigurationsoptionen können hinzugefügt werden:
initialDelaySeconds- Wie viele Sekunden vergehen zwischen dem Start des Behälters und dem Beginn des Starts der Proben?periodSeconds— .timeoutSeconds— , . -.failureThreshold— , .successThreshold— , ( , ).
:
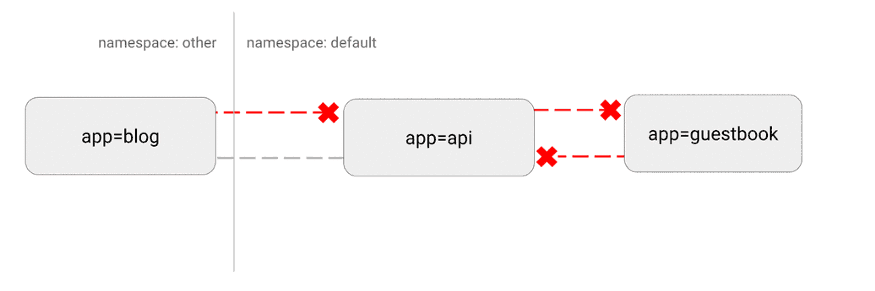
Kubernetes hat eine "flache" Netzwerktopographie. Standardmäßig interagieren alle Pods direkt miteinander. In einigen Fällen ist dies unerwünscht.
Ein potenzielles Sicherheitsproblem besteht darin, dass ein Angreifer eine einzige anfällige Anwendung verwenden kann, um Datenverkehr an alle Pods im Netzwerk zu senden. Wie in vielen Sicherheitsbereichen gilt das Prinzip der geringsten Privilegien. Im Idealfall sollten Netzwerkrichtlinien explizit angeben, welche Verbindungen zwischen Pods zulässig sind und welche nicht.
Das Folgende ist beispielsweise eine einfache Richtlinie, die den gesamten eingehenden Datenverkehr für einen bestimmten Namespace ablehnt:
---
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-ingress
spec:
podSelector: {}
policyTypes:
- Ingress
Visualisierung dieser Konfiguration:
(https://miro.medium.com/max/875/1*-eiVw43azgzYzyN1th7cZg.gif)
Weitere Details hier .
Schritt vier: Benutzerdefiniertes Verhalten mit Hooks und Init-Containern
Eines unserer Hauptziele war es, Kubernetes Bereitstellungen ohne Ausfallzeiten für Entwickler bereitzustellen. Dies ist schwierig, da es viele Möglichkeiten gibt, Anwendungen herunterzufahren und verbrauchte Ressourcen freizugeben.
Besondere Schwierigkeiten traten bei Nginx auf . Wir haben festgestellt, dass bei der sequentiellen Bereitstellung dieser Pods aktive Verbindungen vor dem erfolgreichen Abschluss getrennt wurden.
Nach umfangreichen Recherchen im Internet stellte sich heraus, dass Kubernetes nicht darauf wartet, dass sich die Nginx-Verbindungen erschöpfen, bevor der Pod heruntergefahren wird. Mit Hilfe eines Pre-Stop-Hooks haben wir die folgenden Funktionen implementiert und Ausfallzeiten vollständig beseitigt:
lifecycle:
preStop:
exec:
command: ["/usr/local/bin/nginx-killer.sh"]
Und hier
nginx-killer.sh:
#!/bin/bash
sleep 3
PID=$(cat /run/nginx.pid)
nginx -s quit
while [ -d /proc/$PID ]; do
echo "Waiting while shutting down nginx..."
sleep 10
done
Ein weiteres äußerst nützliches Paradigma ist die Verwendung von Init-Containern zum Starten bestimmter Anwendungen. Dies ist besonders nützlich, wenn Sie einen ressourcenintensiven Datenbankmigrationsprozess haben, der vor dem Ausführen der Anwendung gestartet werden muss. Sie können auch ein höheres Ressourcenlimit für diesen Prozess angeben, ohne ein solches Limit für die Hauptanwendung festzulegen.
Ein weiteres gängiges Schema ist der Zugriff auf Geheimnisse im Init-Container, der diese Anmeldeinformationen für das Hauptmodul bereitstellt, wodurch der unbefugte Zugriff auf Geheimnisse vom Hauptanwendungsmodul selbst verhindert wird.
, : init- , . , .
:
Lassen Sie uns abschließend über eine fortgeschrittenere Technik sprechen.
Kubernetes ist eine äußerst flexible Plattform, mit der Sie Workloads nach Ihren Wünschen ausführen können. Wir haben eine Reihe hocheffizienter, ressourcenintensiver Anwendungen. Durch umfangreiche Lasttests haben wir festgestellt, dass eine der Anwendungen Schwierigkeiten hat, die erwartete Verkehrslast zu bewältigen, wenn die Standardeinstellungen von Kubernetes wirksam sind.
Mit Kubernetes können Sie jedoch einen privilegierten Container ausführen, der die Kernelparameter nur für einen bestimmten Pod ändert. Folgendes haben wir verwendet, um die maximale Anzahl offener Verbindungen zu ändern:
initContainers:
- name: sysctl
image: alpine:3.10
securityContext:
privileged: true
command: ['sh', '-c', "sysctl -w net.core.somaxconn=32768"]
Dies ist eine fortgeschrittenere Technik und oft unnötig. Wenn Ihre Anwendung jedoch Schwierigkeiten hat, mit einer hohen Last fertig zu werden, können Sie versuchen, einige dieser Parameter anzupassen. Weitere Details zu diesem Prozess und zum Festlegen verschiedener Werte - wie immer in der offiziellen Dokumentation .
Abschließend
Während Kubernetes wie eine sofort einsatzbereite Lösung erscheint, müssen einige wichtige Schritte unternommen werden, damit Ihre Anwendungen reibungslos funktionieren.
Während Ihrer Migration zu Kubernetes ist es wichtig, einen "Lasttestzyklus" einzuhalten: Führen Sie die Anwendung aus, testen Sie sie unter Last, beobachten Sie Metriken und Skalierungsverhalten, optimieren Sie die Konfiguration anhand dieser Daten und wiederholen Sie den Zyklus erneut.
Schätzen Sie den erwarteten Datenverkehr realistisch ab und versuchen Sie, darüber hinauszugehen, um festzustellen, welche Komponenten zuerst beschädigt werden. Mit diesem iterativen Ansatz können nur einige dieser Empfehlungen ausreichen, um Erfolg zu haben. Möglicherweise ist auch eine eingehendere Anpassung erforderlich.
Stellen Sie sich immer folgende Fragen:
- ?
- ? ? ?
- ? , ?
- ? ? ?
- ? - , ?
Kubernetes bietet eine unglaubliche Plattform, mit der Best Practices Tausende von Diensten in einem Cluster bereitstellen können. Alle Anwendungen sind jedoch unterschiedlich. Manchmal erfordert die Implementierung etwas mehr Arbeit.
Glücklicherweise bietet Kubernetes die erforderliche Anpassung, um alle technischen Ziele zu erreichen. Mit einer Kombination aus Ressourcenanforderungen und -beschränkungen, Liveness- und Readiness-Tests, Init-Containern, Netzwerkrichtlinien und benutzerdefinierten Kernel-Optimierungen können Sie eine hohe Leistung bei Fehlertoleranz und schneller Skalierbarkeit erzielen.
Was noch zu lesen: