Verstärkung Lernen ist schlecht oder funktioniert mit hohen Dimensionen überhaupt nicht. Und steht auch vor dem Problem, dass Physiksimulatoren ziemlich langsam sind. Daher ist in letzter Zeit ein Weg, diese Einschränkungen zu umgehen, populär geworden, indem ein separates neuronales Netzwerk trainiert wird, das eine Physik-Engine nachahmt. Es stellt sich so etwas wie ein Analogon der Vorstellungskraft heraus, in dem weiteres grundlegendes Lernen stattfindet.
Lassen Sie uns sehen, wie viel Fortschritt in diesem Bereich erzielt wurde, und die Hauptarchitekturen betrachten.
Die Idee, ein neuronales Netzwerk anstelle eines physischen Simulators zu verwenden, ist nicht neu, da einfache Simulatoren wie MuJoCo oder Bullet auf modernen CPUs mindestens 100-200 FPS (und häufiger bei 60) liefern können und der Betrieb eines neuronalen Netzwerksimulators in parallelen Stapeln problemlos 2000-10000 FPS bei erzeugt vergleichbare Qualität. Zwar auf kleinen Horizonten von 10-100 Schritten, aber für das verstärkte Lernen ist dies oft genug.
Noch wichtiger ist jedoch, dass der Prozess des Trainings eines neuronalen Netzwerks zur Nachahmung einer Physik-Engine normalerweise eine Verringerung der Dimensionalität beinhaltet. Da der einfachste Weg, ein solches neuronales Netzwerk zu trainieren, die Verwendung eines Autoencoders ist, geschieht dies automatisch.
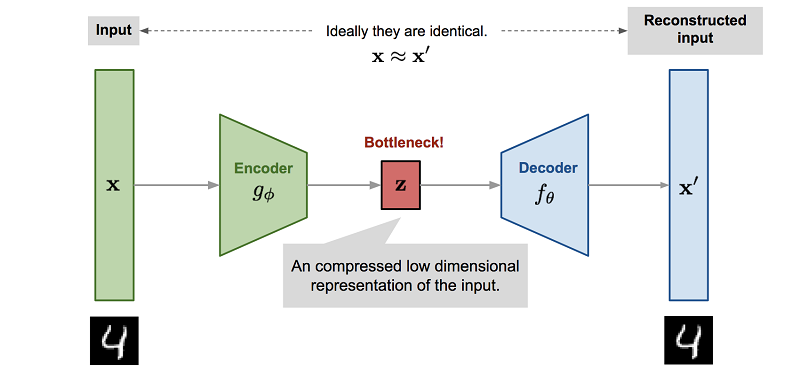
, , . , . - , , , , Z.
Z Reinforcement Learning. , , ( , , ). , .
, — , , . . , Z , model-based , , .
, Reinforcement Learning. "" : , , , .
World Models
( ), 2018 World Models.
: - "" , Z. ( ).
VAE:
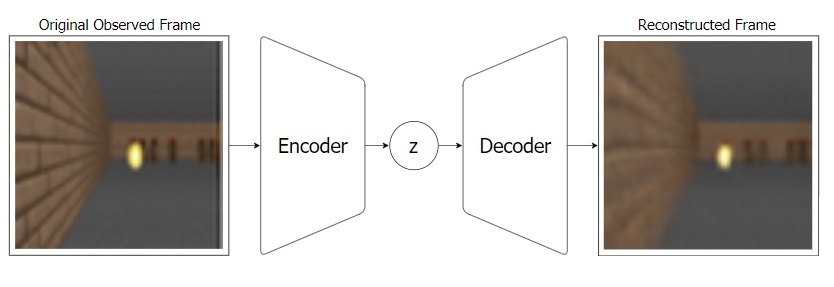
, VAE ( MDN-RNN), . VAE , . , RNN Z . .
:

, : VAE(V) Z MDN-RNN(M) . Z, . MDN-RNN , Z , .
, "" ( - MDN-RNN), . ( ), .
, "" (. ) MDN-RNN (Controller — "", ). , , environment. , C , . VAE(V).
Controller ©, ? ! , -"", Controller. , . , CMA-ES. , Z , . . , , , .
, , .
PlaNet
PlaNet. (, , Controller reinforcement learning), PlaNet Model-Based .
, Model-Based RL — . . , . , , RL , .
Model-Based , , , . (CEM PDDM).
- , ! , .
, . , . .
, . . . (.. state, Reinforcement Learning) , , . Model-Based .
PlaNet, World Models , , Z ( S — state).

Z (, S) , , . , - .
S (, Z) . , , . , .
S , . Model-Based ( ""). .
, , .. -"", A. Model-Based — . , state S . R , state S , ( ). , , ! ( ). Model-Based , .. , , , S R. , World Models, .
Model-Based , PlaNet . 50 . , , , , Model-Free .

Model-Based , (-), . , . . , Model-Based, PlaNet . ( ), .
Dreamer
PlaNet Dreamer. .
PlaNet, Dreamer S, , . Dreamer Value , . Reinforcement Learning. . , . Model-Based ( PlaNet) .

, , Dreamer Actor , . Model-Free , actor-critic.
actor-critic Model-Free , actor , critic ( value, advantage), Dreamer actor . Model-Free .
Dreamer' , . Actor , (. ). Value , , value reward .

, Dreamer Model-Based . Model-Free. model-based ( , ) Actor . Dreamer . , PlaNet Model-Based .
, Dreamer 20 , , Model-Free . , Dreamer 20 , ( ) .

Dreamer Reinforcement Learning . MuJoCo, , .
Plan2Explore
. Reinforcement Learning , .
, - , . , - , , . , , ! Plan2Explore .
Reinforcement Learning , , . , .
, . . , -, . -, , - , .
, . , , Plan2Explore , . , .
Plan2Explore : , . , - , . . . zero-shot . ( , . World Models ), few-shot .
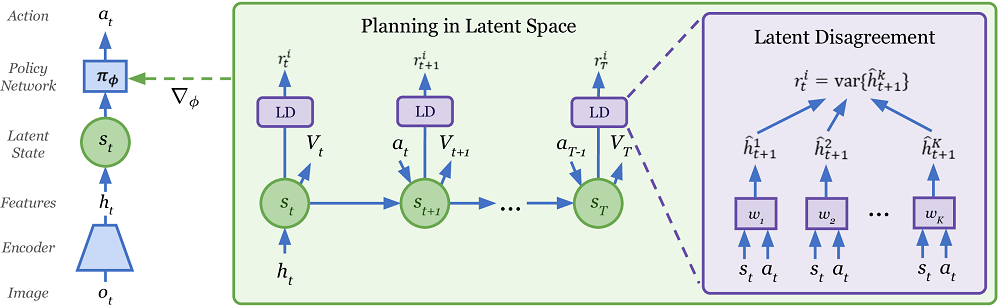
Plan2Explore , Dreamer Model-Free , , . , .
Interessanterweise verwendet Plan2Explore eine ungewöhnliche Methode, um die Neuheit neuer Orte zu bewerten und gleichzeitig die Welt zu erkunden. Zu diesem Zweck wird ein Ensemble von Modellen trainiert, die nur an einem Modell der Welt trainiert sind und nur einen Schritt vorwärts vorhersagen. Es wird argumentiert, dass sich ihre Vorhersagen für Zustände mit hoher Neuheit unterscheiden, aber als Datensätze (häufige Besuche auf der Website) stimmen ihre Vorhersagen auch in zufälligen stochastischen Umgebungen überein. Da einstufige Vorhersagen in dieser stochastischen Umgebung schließlich zu einigen Durchschnittswerten konvergieren. Wenn Sie nichts verstanden haben, sind Sie nicht allein. Dort im Artikel ist es nicht sehr klar, dass es beschrieben wird. Aber irgendwie scheint es zu funktionieren.