- Ich beginne damit, woher die Online-Kinos kamen.

Im Zuge der Entwicklung des Internets erschienen OTT-Mediendienste, die im Gegensatz zu herkömmlichen Mediendiensten, bei denen Kabel-, Satelliten- und andere Kommunikationskanäle verwendet wurden, zur Übertragung von Medieninhalten über das Internet verwendet wurden.
Solche Mediendienste basieren auf OVP - einer Online-Videoplattform, die ein Content-Management-System, einen Web-Player und ein CDN umfasst. Eine separate Klasse solcher Systeme ist OTT-TV, ein Online-Kino, das neben OVP Kontroll- und Verwaltungssysteme für den Zugriff auf Inhalte, ein System zum Schutz der Rechte digitaler Inhalte, die Verwaltung von Abonnements, Käufen sowie verschiedene Produkt- und technische Metriken implementiert. Und es stellt an diese Systeme erhöhte Anforderungen an Verfügbarkeit und Latenz.
Ich werde über das Backend sprechen, das für das Content-Management-System, für die Benutzerfunktionalität des Online-Kinos und für den Teil des Content-Management- und Kontrollsystems verantwortlich ist.
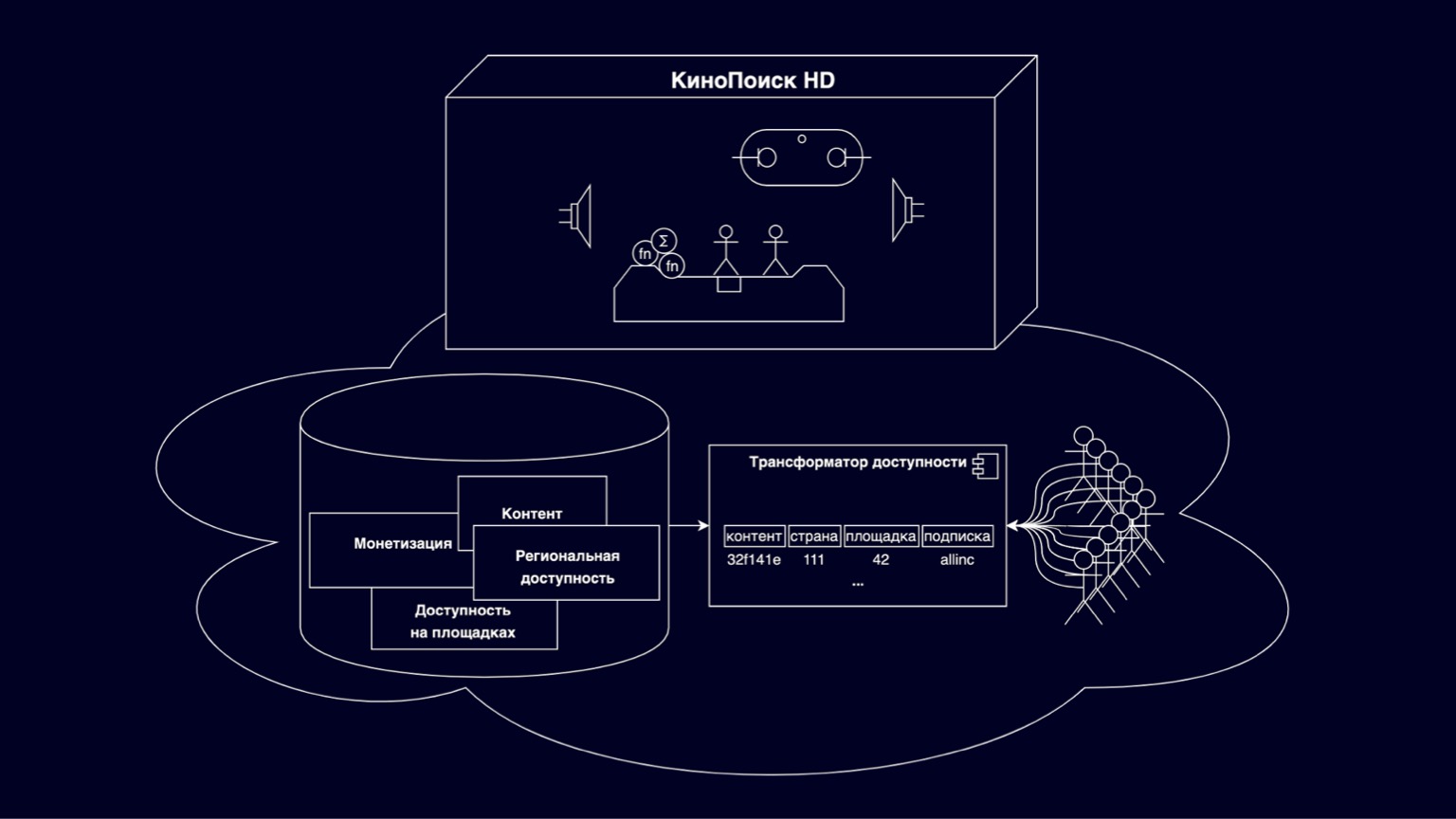
Mal sehen, woraus Online-Kinos bestehen. In der KinoPoisk HD-Box sind alle möglichen coolen Dinge und Anzeigemodi implementiert. Tausende von RPS-Benutzern wählen verfügbare Inhalte in Storefronts aus, abonnieren und kaufen. Speichern Sie den Browserfortschritt und die Benutzereinstellungen. Tausende von RPS generieren verschiedene Metriken. Dies ist ein ziemlich großer und interessanter Satz von Komponenten, auf deren Details wir heute nicht mehr eingehen werden. Erwähnenswert ist jedoch, dass es sich im Allgemeinen um gute und verständlicherweise skalierbare Dienste handelt - aufgrund der Tatsache, dass sie von Benutzern gehortet werden.
Heute konzentrieren wir uns auf die Cloud unter der Box. Dies ist eine Plattform, die für die Speicherung von Filmen, Serien und verschiedenen Einschränkungen von Copyright-Inhabern verantwortlich ist. Unterstützt durch die Bemühungen mehrerer Abteilungen. Teil dieser Plattform ist ein Barrierefreiheitstransformator, der Fragen beantwortet, die ich gerade an diesem Ort sehen kann. Ohne Barrierefreiheitstransformator wird auf KinoPoisk HD buchstäblich kein Inhalt angezeigt.
Die Herausforderung für den Transformator besteht darin, ein flexibles und geschichtetes Barrierefreiheitsmodell in ein effizientes Modell zu übersetzen, das sich gut an möglichst viele Inhaltskonsumenten anpassen lässt.
Warum ist es flexibel und skalierbar?? In erster Linie, weil es verschiedene Entitäten enthält, die Inhalt, Monetarisierung, relationale Verfügbarkeit und Verfügbarkeit auf Websites beschreiben. All dies ist in revolutionären Beziehungen, hat eine komplexe Hierarchie. Diese Flexibilität ist erforderlich, um den Anforderungen von Dutzenden von Copyright-Inhabern und verschiedenen flexiblen Preisoptionen gerecht zu werden.
Mit Plattformen meinen wir beispielsweise ein Online-Kino im Internet, ein Online-Kino auf Geräten und andere OTT-Partnerdienste, die ebenfalls unsere Inhalte abspielen.
Es ist klar, dass Sie zur effizienten Berechnung der Verfügbarkeit eines solchen mehrstufigen Modells komplexe Verknüpfungen erstellen müssen. Solche Abfragen lassen sich nicht für jede Last skalieren. Ihre Interpretation ist recht komplex, um schnell und klar einige Funktionen darauf aufzubauen. Um diese Probleme zu lösen, wurde ein Transformator für Barrierefreiheit entwickelt, der das auf der Folie dargestellte Modell als zusammengesetzten Schlüssel denormalisiert, der Inhalts-IDs, Länder, Websites, Abonnements und einige unsichtbare Nicht-Schlüssel-Reste enthält, die den größten Teil des Speichers ausmachen. Heute werden wir über die Schwierigkeiten bei der Skalierung des Zugänglichkeitstransformators sprechen.
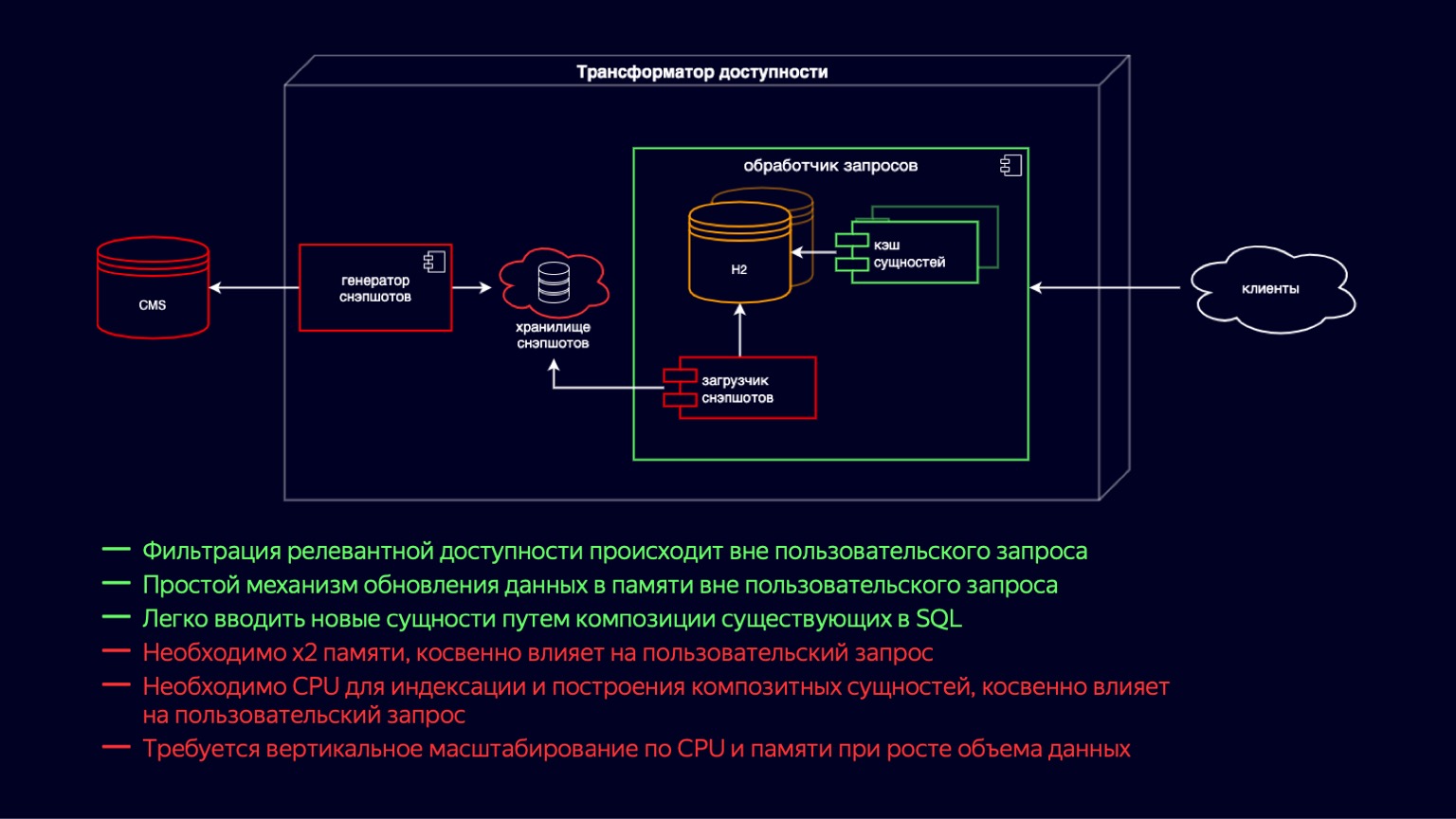
Lassen Sie uns tiefer in diese Komponente eintauchen und sehen, woraus sie besteht. Hier sehen wir den Zustand des Systems kurz vor dem Beginn des Problems. Während dieser ganzen Zeit hat sich der Barrierefreiheitstransformator auf dem Weg der blitzschnellen Entwicklung des Online-Kinos bewegt. Es war wichtig, zunächst schnell neue Funktionen einzuführen, um die Verfügbarkeit von Zehntausenden von Filmen und Fernsehserien sicherzustellen.
Wenn Sie von links nach rechts gehen, gibt es ein CMS, eine relationale Datenbank, in der in dritter Normalform und in EAVUnsere Hauptentitäten werden gespeichert. Als nächstes kommt der Snapshot Loader. Darüber hinaus filtert der Snapshot-Generator, der regelmäßig relevante Daten empfängt, diese und fügt sie dem Snapshot-Speicher hinzu. Dies ist eigentlich ein SQL-Dump. Weiter innerhalb der Anforderungsprozessorinstanz empfängt der Snapshot Loader regelmäßig neue Daten und importiert sie in H2. H2 ist eine in Java geschriebene In-Memory-Datenbank, die die grundlegenden Funktionen eines DBMS implementiert, dh es gibt einen Abfrageinterpreter, einen Abfrageoptimierer und Indizes.
Genau diese Komponente bietet die Flexibilität, neue Funktionen für ein Online-Kino zu erstellen, da Sie einfach und einfach SQL-Abfragen schreiben und denormalisierte Entitäten verbinden können.
H2 wird auf einem Copy-on-Write-Modell aktualisiert. Der Snapshot Loader nimmt eine neue Datenbankinstanz auf und füllt sie. Und dann, nach dem Befüllen, entsorgt es das alte mit dem Müllsammler.
Gleichzeitig mit H2 wird der Entitätscache ausgelöst, der zusammengesetzte Entitäten und einen Index darüber enthält. Zusammengesetzte Entitäten sind im Wesentlichen eine Fortsetzung der Denormalisierung von H2, um anspruchsvollere Latenzanforderungen von Clients zu erfüllen. Die Cache-Entitäten werden auf dieselbe Weise gemäß dem Copy-on-Write-Modell aktualisiert, gleichzeitig mit dem Auslösen neuer H2-Instanzen.
Die Hauptvorteile des Systems: Mit Joins können Sie einfach und flexibel neue Funktionen hinzufügen. Ein relativ einfaches Schema zum Aktualisieren von Daten durch Copy-on-Write. Der Nachteil ist natürlich, dass zum Speichern und Aktualisieren dieser Entitäten x2-Speicher erforderlich ist. Dies wirkt sich indirekt auf die Benutzeranforderung aus, da diese vom Garbage Collector entsorgt wird.
Außerdem wird beim Erstellen des Entitätscaches eine CPU-Ressource für die Indizierung benötigt. Dies wirkt sich auch indirekt auf die Benutzeranforderung aus, jedoch auf Kosten des Wettbewerbs um CPU-Ressourcen. Beide Punkte zusammen führen dazu, dass der Abfrageprozessor mit dem Wachstum des Datenvolumens unserer Hauptentitäten sowohl hinsichtlich der CPU als auch des Speichers vertikal skalieren muss.
Das System stützte sich jedoch auf Zehntausende von Filmen und Fernsehserien, die online verfügbar waren. Daher waren diese Nachteile lange Zeit akzeptabel und ermöglichten es, den Hauptvorteil in Bezug auf Flexibilität und einfache Einführung neuer Funktionen eines Online-Kinos zu nutzen.
Es ist klar, dass dies alles bis zu einem gewissen Punkt funktioniert hat. Stellen Sie sich vor, dieser gelbe Bus ist unser Barrierefreiheitstransformator.

Es enthält Filme und Serien, die durch Denormalisierung reproduziert wurden, dh es gibt Zehntausende von ihnen. Und an einer der Haltestellen müssen Hunderttausende von Musikvideos und Trailern an Bord gehoben und irgendwie platziert werden. Einmal an Bord, vermehren sie sich auch aufgrund der Denormalisierung. Diejenigen, die drinnen sind, müssen schrumpfen, und diejenigen, die draußen sind, müssen hineinspringen und sich durchdrücken. Sie können sich vorstellen, wie das passiert. Technisch gesehen stieg unsere Speicherkapazität auf der Instanz in diesem Moment auf mehrere zehn Gigabyte. Das Erstellen des Caches und das Entsorgen alter Instanzen mithilfe des Garbage Collector erforderte mehrere virtuelle Kerne. Und da die Datenmenge dramatisch gewachsen ist, hat dieses gesamte Verfahren dazu geführt, dass die Veröffentlichung neuer Inhalte mehrere zehn Minuten dauert.
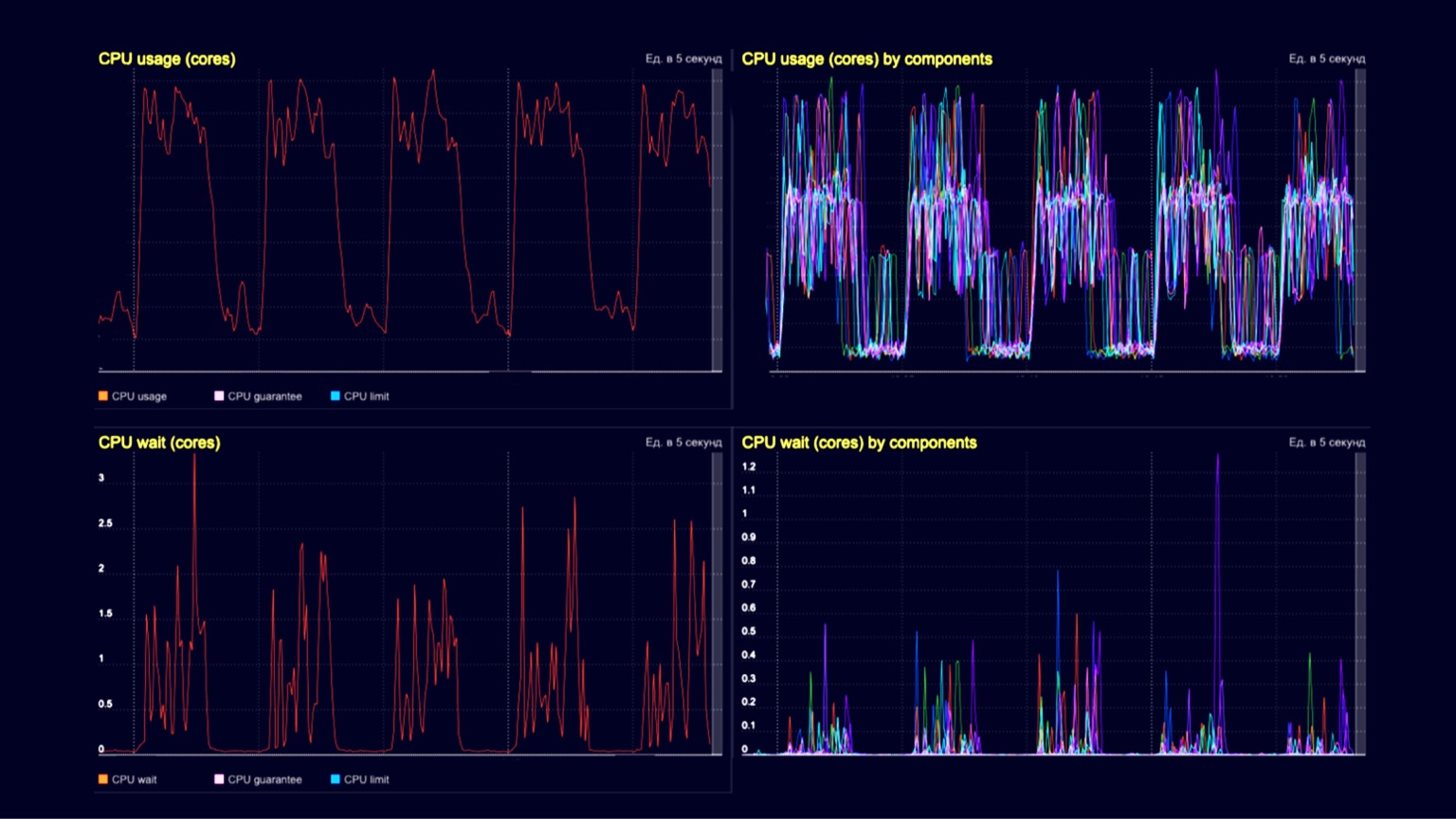
Technisch gesehen sehen wir hier die CPU-Auslastung in einem Abfrageprozessor-Cluster. In den Gräben - der Bearbeitung von Kundenanfragen in der Größenordnung von mehreren tausend RPS und in den Hügeln - die gleichen mehreren tausend RPS sowie das gleiche Laden von Schnappschüssen und deren Entsorgung mit einem Garbage Collector. Die beiden unteren Diagramme zeigen die CPU-Wartezeit auf dem Container. Wir sehen, dass sie sich auch im Moment des Herunterladens von Schnappschüssen und ihrer Entsorgung manifestieren.
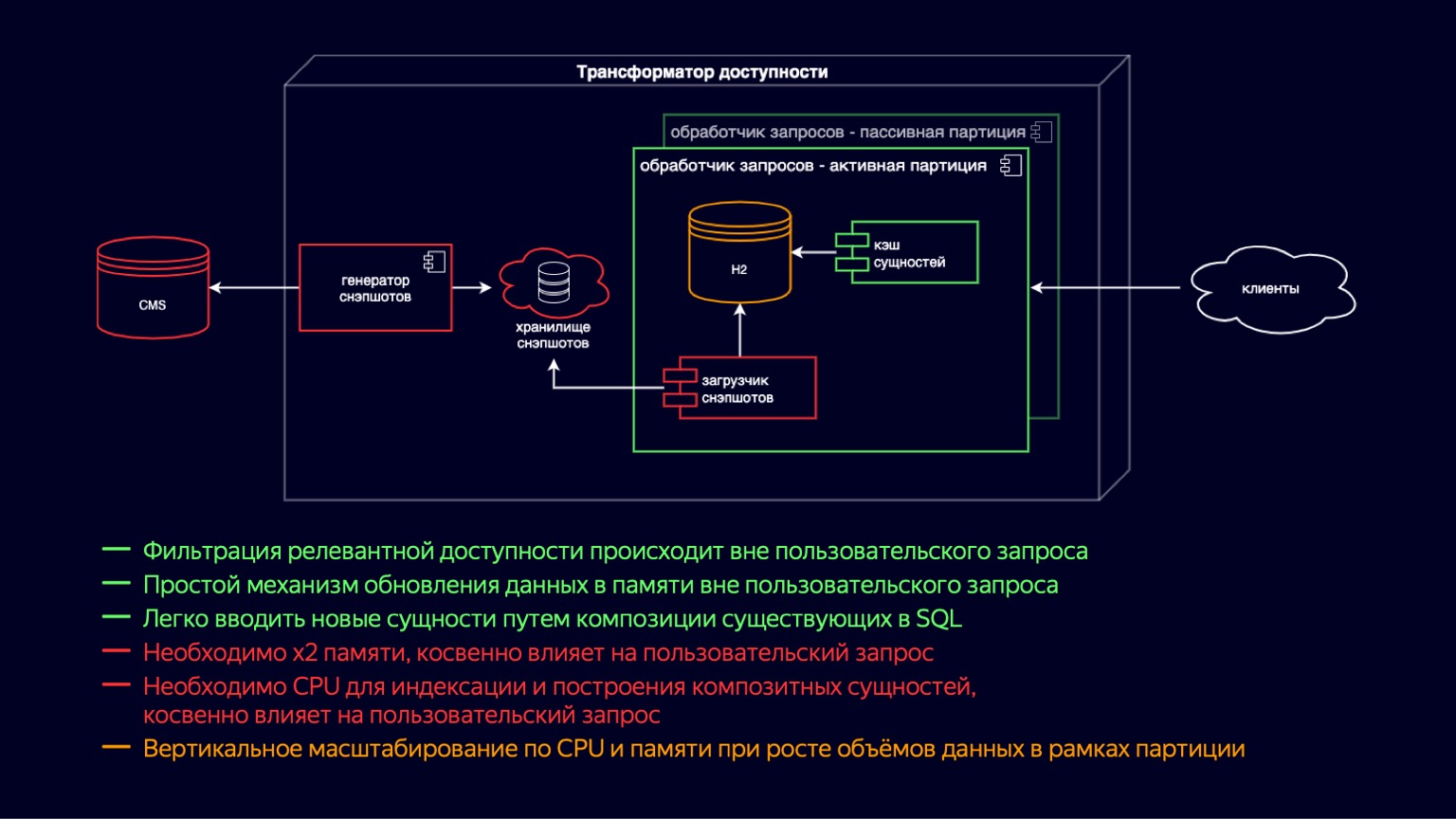
Um diese Musikvideos und Trailer aufzunehmen und weiter zu skalieren, haben wir aktive und passive Anforderungsprozessorinstanzen eingeführt. In der Tat ist dies eine Übertragung von Copy-on-Write auf einer Ebene. Jetzt haben wir sowohl aktive als auch passive Instanzen im Container. Der Passive bereitet den neuen H2- und den Entity-Cache vor, während der Aktive einfach Benutzeranforderungen verarbeitet. Daher haben wir die Auswirkungen der Speicherbereinigung und ihrer Pausen auf die Verarbeitung von Benutzeranforderungen verringert. Da sie sich jedoch immer noch im selben Container befinden, konkurrieren das Laden von Snapshots und das Erstellen des Caches immer noch um CPU-Ressourcen, und die Auswirkungen auf Benutzeranforderungen sind immer noch vorhanden.
Wir haben zusätzlich die Partitionierung nach Standort eingeführt. Dies führte zu einer Reduzierung des Speichers auf den Websites, auf denen all diese neuen Arten von Inhalten nicht benötigt werden. Dies ermöglichte es beispielsweise einem Online-Kino, keine Musikvideos und Trailer herunterzuladen und die Auswirkungen zu verringern. Gleichzeitig hat sich für Websites, die alle Inhalte zugänglich machen müssen, natürlich nichts geändert.
Daher blieben die Vor- und Nachteile des Systems in etwa unverändert. Aufgrund der Partitionierung wurde die vertikale Skalierung in Bezug auf CPU und Speicher auf Standorte verschoben, sodass einige Standorte weiterhin skaliert werden konnten. Im Vergleich zum vorherigen Inhaltsveröffentlichungsschema hat sich dies in keiner Weise geändert. Es dauerte im Allgemeinen die gleichen zehn Minuten, daher suchten wir nach Möglichkeiten, es zu optimieren.

Was haben wir damals verstanden? Diese Online-Kinoabfragen nutzen einen kleinen Teil der DBMS-Funktionen. Der Abfrageinterpreter und -optimierer ist im Laufe der Zeit in einen Entitätscache entartet. Wir haben erkannt, dass die Definition der Barrierefreiheit im Allgemeinen universell ist. Abfragen unterscheiden sich darin, dass Sie die Verfügbarkeit einer Inhaltseinheit oder Liste verstehen und dieser Verfügbarkeit zusätzliche Attribute hinzufügen müssen. Im Allgemeinen kann dies ohne ein vollwertiges DBMS erfolgen.
Und zweitens sind die niedrigen Kardinalparameter ein Teil des zusammengesetzten Schlüssels. Es gibt Dutzende von Ländern, im Grenzbereich von ein paar Hundert, Dutzende von Websites und nur wenige Abonnements. Eine vollständige Denormalisierung ist höchstwahrscheinlich nicht erforderlich. Beide Ergebnisse haben uns zu einer kompakteren und weniger denormalisierten In-Memory-Darstellung geführt, die jedoch immer noch schnell auf Benutzeranforderungen reagiert.

Auf der Folie sehen wir den Übergang vom Verfügbarkeitstransformator v1 zu v2. Hier ist ein Schema eines neuen Eingabehilfenschemas, bei dem der zusammengesetzte Schlüssel tatsächlich nur ein Inhalts-ID-Schlüssel ist. Die physische oder logische Zugänglichkeit hängt davon ab, ob die Verfügbarkeit anhand von Listen mit Ländern, Websites und Abonnements ermittelt wird.
Auf diese Weise reduzieren wir die Menge an unsichtbarem Rest ohne Schlüssel, der den größten Teil des Speichers ausmacht, und reduzieren gleichzeitig die Menge an Speicher.
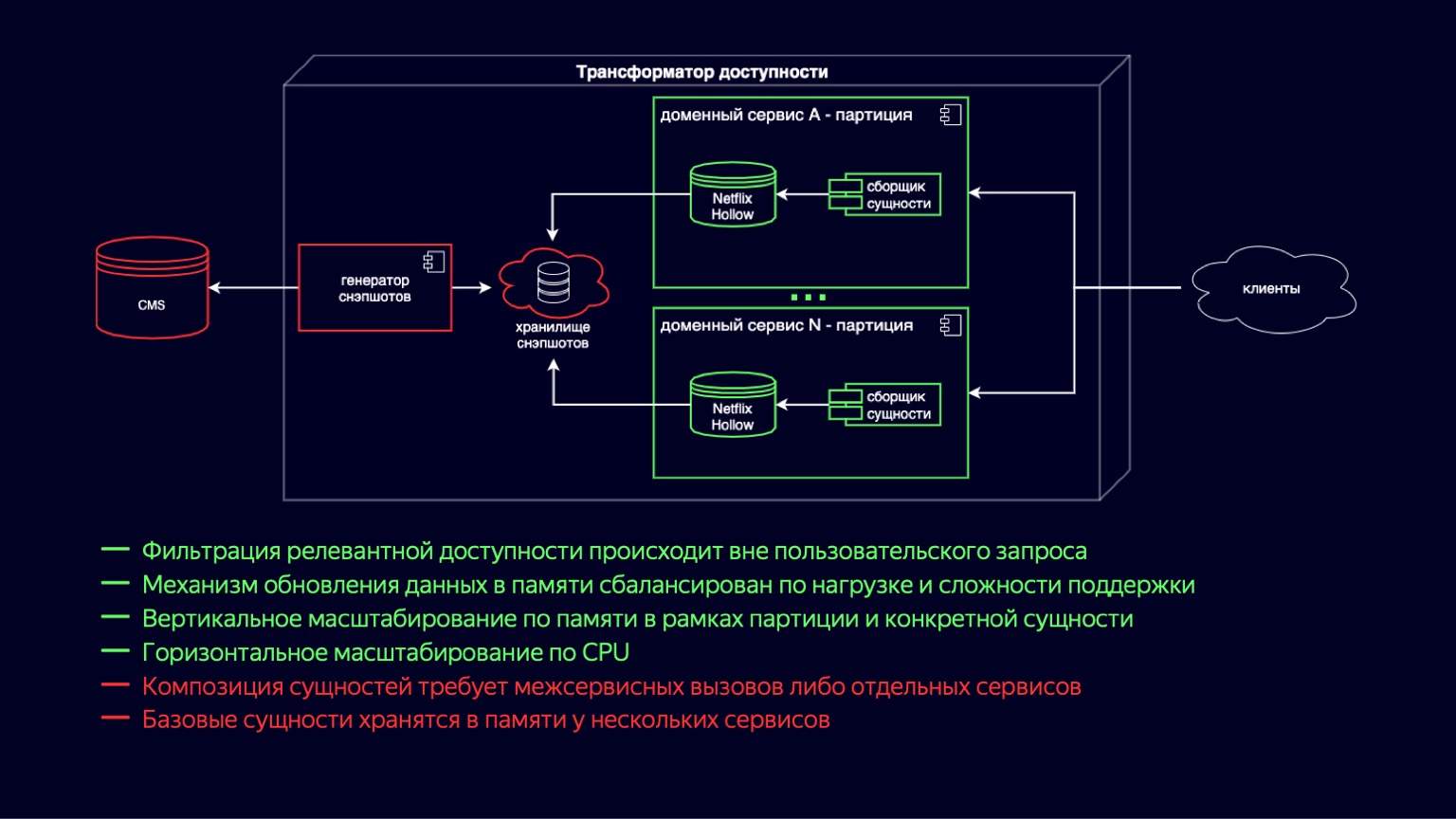
Hier sehen wir den Prozess des Übergangs zur neuen Zugänglichkeitstransformatorschaltung. Netflix Hollow spielt die Rolle eines Anbieters und Indexers von Basisentitäten, über die Domänendienste im laufenden Betrieb Baugruppen aus zusammengesetzten Entitäten unterschiedlicher Größenordnung sammeln. Dies funktioniert, weil die zugrunde liegenden Entitäten immer noch denormalisiert sind und die Anzahl der Verknüpfungen beim Erstellen minimal ist. Andererseits hängt die Bestimmung der Verfügbarkeit von einfachen und billigen Zyklen ab und sollte nicht schwierig sein.
Gleichzeitig speichert und behandelt Netflix Hollow die Belastung der CPU und der Speicherbereinigung sowohl während der Datenaktualisierung als auch während des Zugriffs auf diese sorgfältig. Auf diese Weise können wir die Hügel, die wir in den CPU-Auslastungsdiagrammen gesehen haben, reduzieren und auf ein akzeptables Minimum beschränken. Da ein hybrides Bereitstellungsschema in Form von Snapshots implementiert wird und sich von diesen unterscheidet, kann es außerdem die Geschwindigkeit der Veröffentlichung neuer Inhalte auf einige Minuten erhöhen.
Es ist klar, dass die meisten Vorteile des vorherigen Schemas erhalten geblieben sind. Der Mechanismus zum Aktualisieren von Daten im Speicher ist im Hinblick auf die Ressourcennutzung einfacher und billiger geworden. Die vertikale Skalierung nach Partitionen und Standorten wurde ebenfalls durch die Skalierung für eine bestimmte Entität ergänzt und ist jetzt günstiger. Und da wir den Aufwand für die Aktualisierung von Snapshot-Kopien reduziert haben, gab es eine wirklich horizontale Skalierung in der gesamten CPU.
Der Nachteil dieses Schemas besteht darin, dass für die Zusammensetzung von Entitäten dienstübergreifende Aufrufe oder separate Dienste erforderlich sind. Und es gibt immer noch doppelte Daten auf der Ebene der Basisentität, da diese jetzt in jedem Domänendienst gespeichert sind, in dem sie verwendet werden. Netflix Hollow speichert Daten jedoch kompakter als H2, und H2 speichert sie viel kompakter als HashMap mit Objekten. Dieses Minus wird also definitiv auch als akzeptabel angesehen und ermöglicht es Ihnen, optimistisch in die Zukunft zu blicken.

Diese Folie kann sogar Leitungswasser mit Optimismus aufladen. Weil die Skalierung in neue Länder kein Multiplikationsfaktor mehr im Speicher ist - und auch keine Skalierung auf neue Standorte. Aufgrund der Partitionierung wird es in horizontale Skalierung konvertiert.
Die Skalierung neuer Benutzer und die Erweiterung der Funktionalität eines Online-Kinos führt zu einer Erhöhung der Auslastung. Um dies bereitzustellen, sind wir bereit, so viele leichte CPU-gebundene Dienste wie nötig bereitzustellen. Auf der anderen Seite haben wir genug Wissen im Bereich Barrierefreiheit gesammelt, um uns mit Zuversicht auf neue Herausforderungen zu freuen. Ich hoffe, ich konnte etwas von diesem Wissen mit Ihnen teilen. Vielen Dank für Ihre Aufmerksamkeit.