
Einführung
Doom Eternal muss nicht separat vorgestellt werden: Es ist ein direkter Nachfolger von Doom 2016, das dank der siebten Iteration von id Tech, der internen Engine von id Software, entwickelt wurde. Zu einer Zeit war ich beeindruckt von der hohen Qualität der visuellen Komponente von Doom 2016 und der Einfachheit und Eleganz technischer Lösungen. In dieser Hinsicht übertrifft Doom Eternal seinen Vorgänger in vielen Bereichen, und einige von ihnen verdienen eine detaillierte Aufschlüsselung. In diesem analytischen Artikel werde ich versuchen, alle zu diskutieren.
Meine Analyse ist inspiriert von Adrian Courrèges über Doom 2016 ( Übersetzung)). Meiner Meinung nach bieten solche Arbeiten einen Einblick in Ansätze zur Lösung einiger Renderingprobleme von AAA-Projekten und werden so zu hervorragenden Lehrmaterialien. In dieser Analyse möchte ich allgemeine Funktionen diskutieren und nicht zu tief in die Feinheiten der einzelnen Rendermethoden und -durchläufe eintauchen. Darüber hinaus sind einige der Passagen in Doom Eternal fast identisch mit denen in Doom 2016 und wurden bereits in der Arbeit von Adrian Courrèges zerlegt, sodass ich sie überspringen kann.
Ich möchte in besonderer Weise die strikte Lehre markierendie Art des aktuellen Artikels. Ich unterstütze in keiner Weise das Reverse Engineering von Produkten zum Zwecke des Diebstahls von geistigem Eigentum oder anderer böswilliger Absichten. Wenn Sie Doom Eternal noch nicht gespielt haben, müssen Sie sich keine Sorgen machen: Ich habe nur den Anfang des Spiels behandelt, damit Sie nicht in Gefahr sind, Spoiler zu bekommen.
Also lasst uns anfangen.
Mit der Veröffentlichung von id Tech 7 ermöglichte der Übergang der Engine von OpenGL zur Vulkan-API Entwicklern eine effizientere Arbeit mit den Funktionen der aktuellen GPU-Generation, z. B. bindless Ressourcen.
Ein Frame in Doom Eternal

Oben sehen wir einen Abschnitt des Spiels in der Nähe des Anfangs: ein Innenraum mit mehreren Gegnern und volumetrischer Beleuchtung. In Analogie zu seinem Vorgänger ist der Renderprozess in Doom Eternal für das direkte Rendern zuständig . Wenn Doom 2016 jedoch gezwungen ist, zusammen mit der G-Pufferung reflektierender Oberflächen zu rendern, wird in unserem Fall der Puffer nicht verwendet und das Rendern übernimmt alle Aufgaben.
Weg von Megatexturen
Mit der Veröffentlichung des Spiels Rage, das auf der id Tech 5-Engine erstellt wurde, lernte die Welt das Konzept der Implementierung von Texturen kennen, die als "Mega-Texturen" bezeichnet werden. Diese Methode wird in Doom 2016 verwendet und rendert für jeden Frame eine sogenannte "virtuelle Textur" mit Informationen zu sichtbaren Texturen. Die virtuelle Textur wird im nächsten Frame analysiert, um zu bestimmen, welche Texturen von der Festplatte geladen werden sollen. Megatexturen haben jedoch ein offensichtliches Problem: Sobald die Textur in das Sichtfeld gelangt, ist es zu spät, sie zu laden, sodass die Textur in den ersten Frames nach dem Erscheinen verschwommen aussieht. Mit der Veröffentlichung von id Tech 7 haben die Entwickler diese Methode aufgegeben.
Skinning durch die GPU
Normalerweise wertet der Vertex-Shader das Skinnen aus, noch bevor Texturen und Schattierungen gerendert werden. Die Skinning-ID Tech 7 wird im Voraus von einem Computer-Shader ausgeführt, der die resultierenden Scheitelpunkte in den Puffer schreibt. Dank dieses Ansatzes benötigt der Vertex-Shader keine Skinning-Daten mehr. Da diese nicht mehr bei jedem Geometriedurchlauf ausgeführt werden, treten Shader-Swaps seltener auf.
Der Hauptunterschied zwischen dem Skinnen in einem Compute-Shader und einem Vertex-Shader besteht darin, das Ergebnis in einen Zwischenpuffer zu schreiben. Wie beim Vertex-Shader erhält der Compute-Shader-Thread für jeden Vertex eine Transformation von jedem Knochen, der den Vertex beeinflusst. Dann ändert es die Position des Scheitelpunkts bei jeder Knochentransformation und addiert alle neuen Positionen entsprechend dem Gewicht der im Scheitelpunkt gespeicherten Häute. Infolgedessen kann der Vertex-Shader das Ergebnis aus dem Puffer verwenden, um es als statisches Netz zu interpretieren.
Der Link bietet einen ausgezeichneten Artikel über Compute Shader Skinning von János Turánszki.
Es ist auch nützlich zu beachten, dass Doom Eternal eine interessante Art von Caching verwendet - Alembic Cachevergleichbar mit stark komprimiertem, wieder abspielbarem Video. Diese Caches speichern gebackene Animationen zum Ausgeben und Dekomprimieren während der Programmausführung. Alembic Cache zitiert die technische Analyse von Digital Foundry und wird auf eine Vielzahl von Animationen angewendet, von großformatigen Filmszenen bis hin zu winzigen Tentakeln auf dem Boden. Dieser Ansatz eignet sich besonders für Animationen mit komplexer Implementierung durch Hautanimationen, z. B. für die Simulation von organischen Stoffen und Gewebe. Wenn Sie an dieser Technologie interessiert sind, empfehle ich Ihnen , die Präsentation von Axel Gneiting auf der Siggraph 2014 zu lesen .
Schattenkarten
Der nächste Schritt ist das Rendern von Schatten, und auf den ersten Blick ist id Tech 7 und sein Vorgängeransatz zum Generieren ihrer Karten nicht anders.
Wie Sie unten sehen können, werden die Schatten zu einer großen Textur mit einer Tiefe von 24 Bit und einer Größe von 4096 x 8196 Pixel gerendert, deren Qualität sich stellenweise unterscheidet. Die Textur ändert sich nicht zwischen den Frames und laut der Präsentation "Devil is in the Details" auf der Siggraph 2016wird die statische Geometrie in der Schattenkarte zwischengespeichert, um ein erneutes Zeichnen für jeden Frame zu vermeiden. Die Idee selbst ist einfach: Wir müssen die Schatten erst aktualisieren, wenn sich vor der Lichtquelle etwas bewegt, und können daher eine "zwischengespeicherte" Schattenkarte deklarieren: eine reguläre Karte mit statischer Geometrie, da wir davon ausgehen, dass sich die Geometrie nicht ändert ... Wenn sich ein dynamisches Objekt im Ansichtskegel bewegt, wird die "zwischengespeicherte" Schattenkarte in die Hauptkarte kopiert und die dynamische Geometrie darüber neu gezeichnet. Dieser Ansatz ermöglicht es, nicht bei jeder Aktualisierung die gesamte Szene im Sichtkegel neu zu zeichnen. Wenn das Licht verschoben wird, muss natürlich die gesamte Szene von Grund auf neu gezeichnet werden.
Um die Schattenränder beim Abtasten der Karte auszugleichen, wird das 3x3-PCF-Abtasten verwendet. Da Sonnenlicht normalerweise einen erheblichen Teil der Umgebung bedeckt, werden kaskadierende Schattenkarten verwendet, um die Qualität besser zu verteilen.
Schauen Sie sich zum Beispiel den Atlas der Schattenkarten an. Je bedeutender das Licht ist, je größer der Bereich auf dem Bildschirm oder je näher das Objekt an der Kamera ist, desto größer ist das ausgewählte Segment des Atlas - dies ist für mehr Details erforderlich. Solche Heuristiken werden dynamisch ausgewertet.

Tiefengeschwindigkeit und Pre-Pass
Beginnend mit der Waffe des Spielers werden undurchsichtige, statische und dynamische Geometrien nacheinander auf die Zieltiefe gerendert. Um keine unnötigen Berechnungen von Pixel-Shadern an einem möglichen Schnittpunkt von Geometrien durchzuführen, wird normalerweise ein vorläufiger Durchlauf der Tiefenverarbeitung mit Hinzufügen des Ergebnisses zum Puffer durchgeführt. Da das Neuzeichnen von Pixeln beim Überschneiden unnötige Neuberechnungen verursacht und letztendlich die Leistung negativ beeinflusst, ist die Bedeutung dieses Ansatzes von unschätzbarem Wert. Mit dem Tiefenvorlauf kann ein Pixel-Shader mit direkter Beleuchtung zusätzliche Pixel eliminieren, indem er sie vor der eigentlichen Berechnung mit einem Tiefenpuffer vergleicht, wodurch wertvolle Ressourcen gespart werden.

Spielerwaffen

Statische Objekte

Dynamische Objekte
Im Pre-Pass wird nicht nur die Tiefe gerendert, sondern auch die Zielfarbe. In der dynamischen Geometrie wird die Geschwindigkeit durch Bewegungsvektoren gerendert, dh die Position der aktuellen Position, die von der Pixelposition im vorherigen Frame subtrahiert wurde. Da die Bewegung in den roten und grünen Kanälen eines 16-Bit-Gleitkomma-Rendering-Ziels gespeichert ist, müssen wir nur die X- und Y-Bewegung kennen. Diese Informationen werden dann in der Nachbearbeitung verwendet, um Unschärfe und Neuprojektion des zeitlichen Anti-Aliasing anzuwenden. Die statische Geometrie benötigt keine Bewegungsvektoren, da sie sich nur relativ zur Kamera "bewegt" und ihre Bewegung aus der Bewegung der Kamera selbst berechnet werden kann. Wie Sie im folgenden Screenshot sehen können, ist in unserer Szene nicht viel Bewegung.

Z-hierarchische Tiefe
Der nächste Schritt besteht darin, eine hierarchische Tiefenpuffer-Mip-Kette zu generieren: Diese Kette ähnelt einer Mip-Map, aber anstatt vier benachbarte Pixel zu mitteln, nimmt sie ihren Maximalwert an. Dieser Ansatz wird in Grafiken häufig für eine Vielzahl von Aufgaben verwendet, z. B. zum Beschleunigen von Reflexionen und zum Verwerfen von blockierter Geometrie. In unserem Fall verwirft die Mip-Kette Beleuchtung und Abziehbilder, über die wir später sprechen werden. In letzter Zeit wurde die Mip-Generierung in einem Durchgang durchgeführt, wobei mehrere Mip-s gleichzeitig aufgezeichnet wurden. In Doom Eternal wird die Aufzeichnung jedoch immer noch für jeden Mip separat durchgeführt.

Mesh-Abziehbilder
Bisher hatten wir keine Zeit, uns mit den wesentlichen Unterschieden zwischen den Prozessen in Doom Eternal und Doom 2016 vertraut zu machen, aber Gitteraufkleber passen in diese Kategorie. Dies sind kleine Abziehbilder (Bolzen, Gitter, Unebenheiten), die wie normale Abziehbilder alle Oberflächeneigenschaften (normal, Rauheit, Farbe) beeinflussen können. Ein typisches Raster-Abziehbild wird jedoch von Künstlern während der Entwicklung des Rasters zugewiesen und gehört im Gegensatz zur Standardplatzierung von Abziehbildern in der Umgebung zu einem eigenen Raster. Doom hat sich in der Vergangenheit stark auf Abziehbilder verlassen, und die derzeitige Umstellung auf Mesh-Abziehbilder hat nur die Details und die Flexibilität der Grafiken erhöht.
Um diesen Vorteil zu erzielen, werden beim nächsten Geometriedurchlauf die IDs jedes Abziehbilds in eine 8-Bit-Textur umgewandelt. Außerdem wenden wir beim Anwenden von Schatten die Textur ab und erhalten über die Bezeichner die Projektionsmatrix, die jedem zu zeichnenden Aufruf zugeordnet ist. Die Matrix projiziert Pixelkoordinaten aus dem Weltraum in den Texturraum. Diese Koordinaten werden dann verwendet, um das Abziehbild abzutasten und es mit dem Oberflächenmaterial zusammenzuführen. Diese Technik ist unglaublich schnell in der Ausführung und eröffnet Künstlern einen weiten Spielraum für die Arbeit mit einer Vielzahl von Abziehbildern. Da die IDs in einer 8-Bit-Textur gerendert werden, können möglicherweise bis zu 255 Abziehbilder auf einem einzelnen Netz vorhanden sein.
Die einzige Bedingung für all dies ist, dass alle Abziehbildtexturen beim Rendern von Netzen an Prozesse gebunden sind. Mit einem völlig unabhängigen Rendering-Prozess können Entwickler alle Decal-Texturen gleichzeitig verknüpfen und dynamisch im Shader indizieren. Da die Entwickler diese Methode verwenden, um ein paar weitere Tricks im Spiel zu implementieren, werden wir später mehr über den nicht verwandten Rendering-Prozess sprechen.
Unten sehen wir das Abziehbild-Texturnetz. Zur Vereinfachung der Visualisierung sind die Kennungen in verschiedenen Farben gefärbt.

Licht und Abziehbilder werfen
Das Licht in Doom Eternal ist voll dynamisch und bis zu mehrere hundert Quellen können gleichzeitig auf das Sichtfeld treffen. Darüber hinaus sind, wie bereits erwähnt, Abziehbilder im Spiel von großer Bedeutung. Beispielsweise hat im selben Doom 2016 die Anzahl der Abziehbilder Tausende überschritten. All dies erfordert einen speziellen Ansatz zum Verwerfen von Überschüssen, da sonst die Leistung der Schwere von Pixel-Shadern nicht standhält.
Doom 2016 verwendete eine prozessorbasierte Version der Cluster-Lichtunterdrückung: Das Licht und die Abziehbilder wurden in kegelförmigen "Froxeln" gesammelt, die dann während der Schattierung durch Bestimmen des Cluster-Index aus der Pixelposition gelesen wurden. Die Größe jedes Clusters betrug 256 Pixel und wurde logarithmisch in 24 Segmente unterteilt, um eine quadratische Form beizubehalten. Diese Technik wurde bald von vielen anderen Entwicklern übernommen, und ähnliche Methoden finden sich beispielsweise in Detroit: Mensch werden und gerechte Sache.
Angesichts der wachsenden Anzahl dynamischer Lichtquellen (Hunderte) und Abziehbilder (Tausende) reichte die CPU-Clusterbildung des Lichtgusses in Doom Eternal nicht aus, da die Voxel zu grob wurden. Infolgedessen entwickelten die Entwickler einen anderen Ansatz für id Tech 7 und erstellten mithilfe von Computer-Shadern, die in verschiedenen Phasen ausgeführt wurden, einen Software-Rasterizer. Zunächst werden die Abziehbilder und das Licht zu einem Hexaeder (Sechseck) verbunden und auf einen Rechenrasterer übertragen, von dem aus die Scheitelpunkte in den Bildschirmraum projiziert werden. Dann schneidet ein zweiter Compute-Shader die Dreiecke an die Ränder des Bildschirms und setzt sie zu Kacheln mit 256 x 256 Pixel zusammen. Gleichzeitig werden in Analogie zum Verwerfen von Clustern einzelne Elemente von Lichtquellen und Abziehbildern in Froxeln aufgezeichnet.Danach führt der nächste Computer-Shader eine ähnliche Prozedur für Kacheln mit 32 x 32 Pixel durch. In jeder Kachel werden Elemente, die den Tiefentest bestehen, in einem Bitfeld markiert. Der endgültige Berechnungs-Shader übersetzt die Bitfelder in eine Liste von Lichtern, die schließlich im Lichtdurchgang verwendet werden. Interessanterweise werden die Elementindizes immer noch in dreidimensionalen Froxeln von 256 x 256 Pixel aufgezeichnet, ähnlich wie beim Cluster-Ansatz. An Stellen mit einer signifikanten Tiefenunterbrechung wird der Mindestwert sowohl der neuen Liste der Lichter als auch der alten Liste der gruppierten Quellen verglichen, um die Anzahl der Lichter in jeder Kachel zu bestimmen.die letztendlich im Beleuchtungspass verwendet werden. Interessanterweise werden die Elementindizes immer noch in dreidimensionalen Froxeln von 256 x 256 Pixel aufgezeichnet, ähnlich wie beim Cluster-Ansatz. An Stellen mit einer signifikanten Tiefenunterbrechung wird der Mindestwert sowohl der neuen Liste der Lichter als auch der alten Liste der gruppierten Quellen verglichen, um die Anzahl der Lichter in jeder Kachel zu bestimmen.die letztendlich im Beleuchtungspass verwendet werden. Interessanterweise werden die Elementindizes immer noch in dreidimensionalen Froxeln von 256 x 256 Pixel aufgezeichnet, ähnlich wie beim Cluster-Ansatz. An Stellen mit einer signifikanten Unterbrechung der Tiefe wird der Mindestwert sowohl der neuen Liste der Lichter als auch der alten Liste der gruppierten Quellen verglichen, um die Anzahl der Lichter in jeder Kachel zu bestimmen.
Wenn Sie sich nicht mit traditioneller Rasterung befasst haben, ist Ihnen eine so ausführliche Beschreibung möglicherweise nicht klar. Wenn Sie sich eingehender mit der Frage befassen möchten, empfehle ich, die allgemeinen Prinzipien der Funktionsweise solcher Prozesse zu untersuchen. Beispielsweise verfügt Scratchapixel über eine sehr gute Analyse des Themas .
Die sogenannten "Bereiche", die zum Abfragen der Spielsichtbarkeit verwendet werden, werden von diesem System ebenfalls verworfen. Da die Software-Rasterung für Computer-Threads ein langer Prozess ist, ist die Belegung sehr wahrscheinlich gering, und das Hinzufügen einiger zusätzlicher Frames hat daher fast keinen Einfluss auf die Leistung. Vor diesem Hintergrund wird Licht wahrscheinlich asynchron geworfen, und daher ist die Nettoauswirkung auf die Leistung minimal.
Blockieren des Umgebungslichts im Bildschirmbereich
Die Umgebungsokklusion wird auf ziemlich übliche Weise mit halber Auflösung berechnet: Zuerst gehen 16 zufällige Strahlen von der Position jedes Pixels auf der Halbkugel aus, und dann werden die Strahlen, die sich mit der Geometrie schneiden, unter Verwendung des Tiefenpuffers bestimmt. Je mehr Strahlen die Geometrie kreuzen, desto größer wird das Hindernis. Diese Technik wird als Screen Space Directional Occlusion oder SSDO bezeichnet. Eine ausführliche Beschreibung von Yuriy O'Donnell finden Sie hier . Anstelle der herkömmlichen Speicherung von Okklusionswerten in einer Einkanaltextur wird die gerichtete Okklusion in einer Dreikomponententextur gespeichert, und die resultierende Okklusion wird über das Punktprodukt über der Pixelnormalen definiert.
Da die Berechnung mit halber Auflösung durchgeführt wird, ist das Ergebnis ziemlich verrauscht. Um die Qualität mit einem Tiefenpuffer zu verbessern, wird doppelseitige Unschärfe angewendet. Umgebungslichtblockierung tritt normalerweise bei niedrigen Frequenzen auf, so dass Unschärfe normalerweise nicht wahrnehmbar ist.

Undurchsichtiger gerader Durchgang
In dieser Passage fallen schließlich viele der Elemente zusammen. Im Gegensatz zu Doom 2016 wird hier alles direkt über mehrere massive Mega-Shader gerendert. Es gibt angeblich ungefähr 500 Prozessorzustände und ein Dutzend Deskriptor-Layouts während des Spiels. Die Waffen des Spielers werden zuerst gerendert, dann dynamische Objekte und dann statische. Bitte beachten Sie, dass die Reihenfolge nicht besonders wichtig ist, da wir dank der Tiefenvorverlegung bereits einen Tiefenpuffer erhalten haben und Pixel ausschließen können, die nicht der Tiefe im Voraus entsprechen.

Spielerwaffen

Dynamische Objekte

Erster Satz statischer Objekte

Zweiter Satz statischer Objekte
Bei den meisten AAA-Game-Engines können Entwickler mithilfe von Shader-Diagrammen und statischen Shader-Funktionen mit allen Arten von Materialien und Oberflächen kreativ werden. Jedes Material und jede Oberfläche führt zu einem eigenen Shader. Infolgedessen sind wir mit einer unglaublichen Vielfalt von Shader-Permutationen für alle möglichen Kombinationen von Motormerkmalen konfrontiert. Id Tech unterscheidet sich jedoch stark von anderen AAA-Projekten: Es kombiniert fast alle Materialien und Funktionen in nur wenigen massiven Mega-Shadern. Dieser Ansatz ermöglicht es GPUs, die Geometrie enger zu kombinieren, was sich wiederum positiv auf die Leistung auswirkt. Wir werden dies später diskutieren.
Ungebundene Ressourcen
Es ist erwähnenswert, dass der gesamte Prozess der Erstellung von Grafiken die Idee von "nicht verwandten Ressourcen" enthält. Dies bedeutet, dass anstatt die Unschärfe, Reflexionen und Rauheit der Textur vor jedem Zeichenaufruf zu binden, die gesamte Liste der Texturen in der Szene auf einmal gebunden wird. Auf die Texturen aus der Liste wird im Shader dynamisch über die Indizes zugegriffen, die von den Konstanten an den Shader übergeben werden. So können Sie durch jeden Aufruf zum Zeichnen eine beliebige Textur erhalten, die den Weg für viele Optimierungen ebnet, von denen wir jetzt über eine sprechen werden.

Draw Calls dynamisch zusammenführen
Zusätzlich zu einer vollständig entkoppelten Ressourcenarchitektur werden alle Geometriedaten aus einem großen Puffer zugeordnet . Dieser Puffer speichert einfach den Versatz der gesamten Geometrie.
Hier kommt die interessanteste Technologie von idTech 7 ins Spiel: das dynamische Zusammenführen von Draw Calls.... Es basiert auf einer entkoppelten Ressourcenarchitektur und einem verallgemeinerten Vertex-Speicher und reduziert dadurch die Anzahl der Draw-Aufrufe und die Prozessorzeit erheblich. Bevor mit dem Rendern begonnen wird, erstellt der Compute-Shader dynamisch einen „indirekten“ Indexpuffer, um Geometrien aus nicht verwandten Netzen effizient zu einem einzigen indirekten Zeichenaufruf zusammenzuführen. Ohne nicht verwandte Ressourcen würde das Zusammenführen von Aufrufen nicht funktionieren, da Geometrien mit nicht übereinstimmenden Materialeigenschaften verwendet werden. In Zukunft wird es möglich sein, den dynamischen Indexpuffer sowohl für die Tiefenvorverlegung als auch für die Beleuchtungsvorüberführung wieder zu verwenden.
Reflexionen
Der gebräuchlichste Computational Shader verwendet den Raymarching-Algorithmus, um Bildschirmraumreflexionen zu erzeugen. Der Algorithmus sendet einen Strahl vom Pixel in den Weltraum in Richtung der Reflexion aus, was von der Rauheit der reflektierenden Oberfläche abhängt. Gleiches galt für Doom 2016, wo ein kleiner G-Puffer als Teil des Vorwärtsdurchlaufs aufgezeichnet wurde. In Doom Eternal gibt es jedoch keinen G-Puffer mehr, und selbst Bildschirmraumreflexionen werden nicht im Computational Shader separat, sondern sofort im Direct Shader berechnet . Es ist interessant zu wissen, wie sich eine solche Abweichung im Pixel-Shader auf die Leistung auswirkt, da die Entwickler anscheinend auf Kosten der erhöhten Belastung des Registers versucht haben, die Anzahl der Renderziele und damit die Belastung der Speicherbandbreite zu verringern.
Wenn die Textur des Bildschirmbereichs nicht die erforderlichen Informationen enthält, werden Rendering-Artefakte häufig in den entsprechenden Effekten angezeigt. Dies tritt am häufigsten bei Reflexionen im Bildschirmbereich auf, wenn unsichtbare reflektierende Objekte nicht reflektiert werden können. Das Problem wird normalerweise mit dem herkömmlichen Ansatz gelöst, bei dem statische Reflexionswürfelkarten als Backup verwendet werden.

Da Mega-Texturen in Doom Eternal nicht mehr verwendet werden, sind auch keine Fallback-Texturen erforderlich.
Partikel
Simulation
In Doom Eternal fällt ein Teil der Partikelprozessorsimulation auf die Schultern von Computational Shadern, da einige Partikelsysteme von Bildschirmrauminformationen abhängig sind, beispielsweise von einem Tiefenpuffer zur Simulation von Kollisionen. Während andere Partikelsysteme gleichzeitig im Frame ausgeführt und asynchron berechnet werden können, benötigen solche Simulationen zunächst Tiefenvorabdaten. Was im Gegensatz zur herkömmlichen Shader-Simulation von Partikeln charakteristisch ist, ist hier die Simulation durch die Ausführung einer Folge von "Befehlen" aus dem im Computer-Shader gespeicherten Puffer. Jeder Shader-Thread führt alle Befehle aus, unter denen mehrere Änderungen an Kill-, Emit- oder Partikelparametern vorgenommen werden können. All dies sieht aus wie eine virtuelle Maschine, die in einem Shader geschrieben ist. Ich verstehe nicht viel über die Feinheiten einer solchen Simulation, aber der Ansatz basiertbei Brandon Whitneys Präsentation "The Destiny Particle Architecture" auf der Siggraph 2017 . Die Methode in der Präsentation ist der oben beschriebenen sehr ähnlich und wird in vielen anderen Spielen verwendet. Ich bin mir zum Beispiel ziemlich sicher, dass das Niagara-Partikelsimulationssystem in Unreal Engine 4 auf ähnliche Weise funktioniert.
Beleuchtung
Ähnlich wie bei Doom 2016 und der in Siggraph 2016 beschriebenen Methode wird die Auflösung der Beleuchtungspartikel von der tatsächlichen Bildschirmauflösung entkoppelt , sodass Entwickler die Auflösung jedes Partikelsystems basierend auf Qualität, Bildschirmgröße und direkter Steuerung steuern können. Für Niederfrequenzeffekte kann die Beleuchtung mit einer viel niedrigeren Auflösung ohne Qualitätsverlust bereitgestellt werden, verglichen mit beispielsweise Funken, die eine hohe Auflösung erfordern. Die Beleuchtung und die dominante Lichtrichtung werden in zwei Atlanten von 2048 x 2048 Pixel gespeichert, die beide wie jede andere Textur für jeden Durchgang durch ungebundene Ressourcen verfügbar sind. Zum Rendern von Partikeln wird durch Abtasten dieser Atlanten eine einfache Geometrie gezeichnet.

Ein vergrößertes Fragment eines Lichtatlas.
Himmel und Streuung
Jetzt sprechen wir über volumetrische Beleuchtung . Seine Erzeugung besteht aus vier Durchgängen und beginnt mit der Erstellung einer 3D-LUT-Textur für die Himmelsatmosphäre durch Raymarsch durch den Himmel selbst in Richtung der Lichtquelle.

Vom ersten Mal an verstehen Sie vielleicht nicht genau, was die Textur im Bild anzeigt, aber wenn wir sie um 90 Grad drehen und horizontal strecken, wird alles klar: Wir haben eine Streuung der Atmosphäre. Da es vertikal variabler als horizontal ist, ist die vertikale Auflösung größer. Die Atmosphäre wird durch eine Kugel dargestellt, daher wird die horizontale Drehung normalerweise als Längengrad und die vertikale Drehung normalerweise als Breitengrad bezeichnet. Die atmosphärische Streuung wird von der Hemisphäre berechnet und umfasst 360 Grad Längengrad und 180 Grad Breitengrad am oberen Rand der Kugel. Um unterschiedliche Entfernungen zum Beobachter zurückzulegen, enthält die LUT-Textur 32 Tiefensegmente. Anstatt die Himmelsdaten in jedem Frame neu zu berechnen, wird der Prozess auf 32 Frames verteilt.
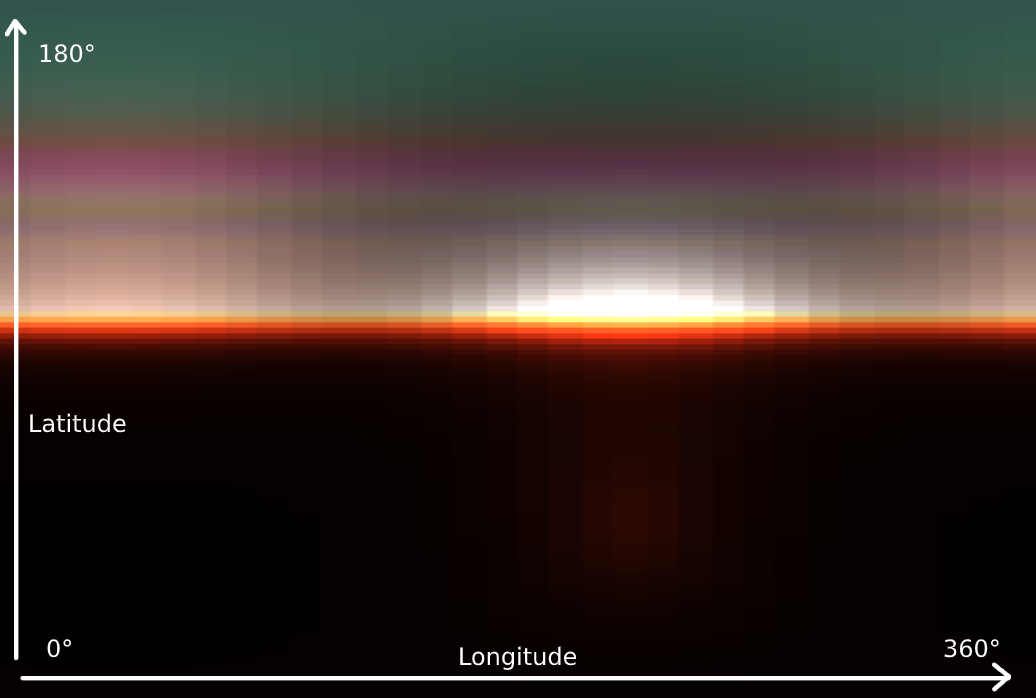
Dank der LUT-Textur berechnet der nächste Durchgang die Lichtstreuung durch das beobachtete "Froxel" in Analogie zur Clusterobstruktion von Licht in kleinerem Maßstab. Sie können unten mehrere Segmente von nah bis fern beobachten.

Im dritten Durchgang werden die Streudaten für jede Zelle in Richtung der Ansicht in jede nachfolgende Zelle multipliziert und in eine neue 3D-Textur geschrieben.
Infolgedessen wird die volumetrische Beleuchtung durch Abtasten der neu erzeugten 3D-Textur basierend auf der Pixeltiefe über dem gerenderten Bild platziert.

Vorher

Nachher
Der endgültige "sichtbare" Himmel wird in einer Halbkugel gerendert, wenn er in der Ansicht ist. In dieser Szene wurde der Himmel nicht in die Überprüfung einbezogen. Im Folgenden finden Sie ein Beispiel für das Rendern des Himmels in einer Außenszene.

Transparenz
Ähnlich wie bei Doom 2016 wird Transparenz durch einen Vorwärtsdurchlauf nach der undurchsichtigen Geometrie bei Lichtstreuungsdaten gerendert. Gleichzeitig verliert die Szenentextur an Auflösung (Downsamples), und es wird ein geeigneter Mip-Level ausgewählt, um die Transparenz basierend auf der Glätte der Oberfläche zu "simulieren". Lichtstreuungsdaten tragen dazu bei, eine visuell gute Streuung von der Innenseite der Oberfläche zu erzielen.
Unten sehen Sie ein Beispiel einer Textur-Mip-Kette aus der Szene, in der transparentere Oberflächen in das Ansichtsfenster fallen.

Aus Gründen der Transparenz gehen nur die damit verbundenen Pixel in der Auflösung verloren.
Benutzeroberfläche
Normalerweise ist der letzte Durchgang in einem Frame die Benutzeroberfläche. Wie normalerweise wird die Schnittstelle in ein sekundäres LDR-Rendering-Ziel (8-Bit) mit voller Auflösung gerendert, und die Farbe wird mit dem Alphakanal vormultipliziert. Während der Tonzuordnung wird die Schnittstelle der HDR-Textur überlagert. Es ist normalerweise schwierig, die Benutzeroberfläche mit dem Rest des HDR-Inhalts im Frame zu arbeiten, aber in Doom Eternal skaliert die Tonzuordnung die Benutzeroberfläche auf magische Weise und sieht im Vergleich zu anderen 3D-Inhalten natürlich aus.

Nachbearbeitung
Das erste, was bei der Nachbearbeitung auftritt, ist Unschärfe : Dieser Zwei-Durchlauf-Effekt liest Daten aus der Farbtextur und einem benutzerdefinierten Geschwindigkeitspuffer. Der erste Durchgang sammelt vier Proben auf der vertikalen Achse, der zweite - vier entlang der horizontalen. Dann werden die Farbfelder entsprechend der Pixelbewegung gemischt. Um Unschärfen zu vermeiden, muss der benutzerdefinierte Geschwindigkeitspuffer sicherstellen, dass keine Geisterbilder auftreten und die Waffe des Spielers vom Vorgang ausgeschlossen ist.
Als nächstes kommt die gezielte Wirkung: Diese RG (zweifarbige) 1 x 1-Textur enthält die durchschnittliche Beleuchtung der gesamten Szene und wird berechnet, indem die Farbtextur nacheinander heruntergesampelt und die durchschnittliche Beleuchtung einer Gruppe von Pixeln ermittelt wird. Am häufigsten wird diese Technik verwendet, um die Gewöhnung des menschlichen Auges an eine starke Änderung der Umgebungshelligkeit zu simulieren. Die durchschnittliche Beleuchtung wird auch verwendet, wenn die Auswirkung während der Tonabbildung berechnet wird.
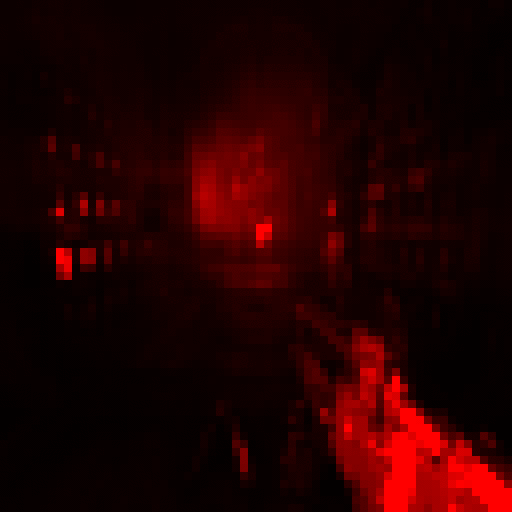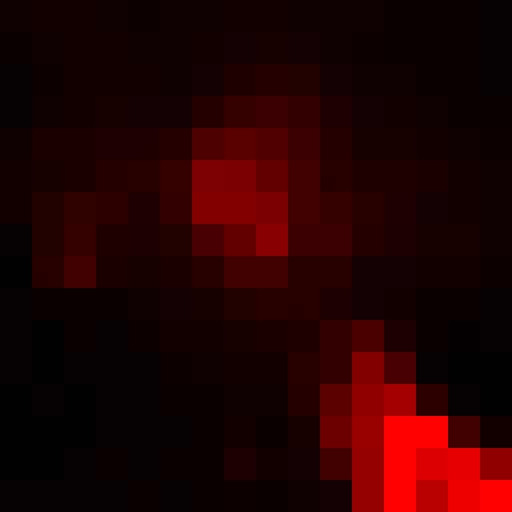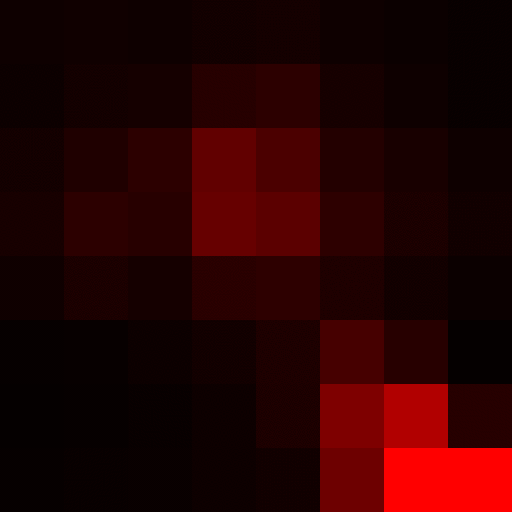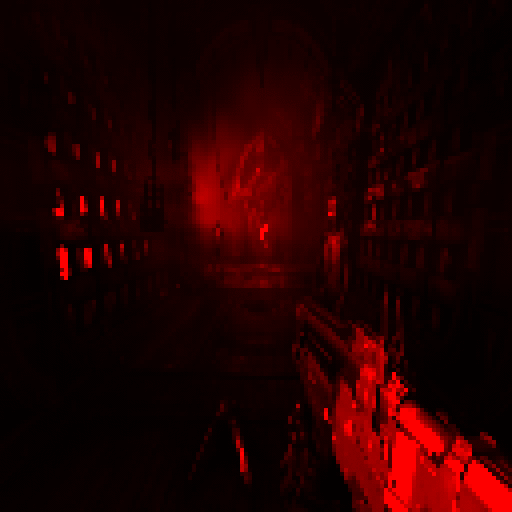
Nach all dem wird Bloom berechnet . Dieser Effekt reicht in unserem Beispiel nicht aus und es wird nicht möglich sein, ihn breit zu rendern, aber es reicht zu wissen, dass die Berechnung durchgeführt wird, indem Farbdaten über einem bestimmten Grenzwert erhalten und die Texturauflösung sukzessive verringert wird, um sie zu verwischen.
Dann Tonzuordnungkombiniert alle Effekte. Ein einzelner Compute-Shader führt Folgendes aus:
- Wendet Verzerrung an
- Rendert über Bloom-Textur
- Berechnet Vignettierung, Schmutz auf der Kamera, chromatische Aberration, Linseneffekt und viele andere Effekte
- Ruft den Belichtungswert basierend auf der durchschnittlichen Beleuchtung ab
- Ermöglicht der Tonzuordnung, HDR-Farben über einen benutzerdefinierten Tonzuordnungsoperator auf die richtigen Bereiche für LDR und HDR zu verteilen.
Schließlich wird die Schnittstelle überlagert.
Die Verzerrungstextur wird bereits vor dem Nachbearbeitungsdurchlauf gerendert: Die Geometrie wird wie ein Feuerdunst aus Partikeleffekten in einem Format mit einem Viertel der ursprünglichen Auflösung in ein neues Renderziel gerendert. In diesem Rendering werden die Verzerrungsdaten in den roten und grünen Kanälen und die Okklusion in den blauen Kanälen gespeichert. Die erhaltenen Daten werden angewendet, wenn das Bild beim Tonabbildungsschritt verzerrt wird.

Fazit
Unsere flüchtige Aufschlüsselung einer Einstellung von Doom Eternal ist beendet, obwohl ich sicher nicht ein paar Dinge angesprochen habe, die das Aussehen des Spiels beeinflussen. Meiner Meinung nach ist Doom Eternal ein unglaublicher technischer Erfolg, und id Software wird die Messlatte in Zukunft noch weiter höher legen können. Das Entwicklungsteam hat uns erfolgreich gezeigt, wie intelligentes Denken und effektive Planung dazu beigetragen haben, ein qualitativ hochwertiges Spiel zu erstellen, und ich glaube, dass dies ein großartiges Vorbild sowie Lehrmaterial ist. Ich freue mich auf zukünftige Entwicklungen von id Software.
Zerreißen und reißen, bis es fertig ist.