
In diesem Artikel werde ich behandeln:
- Was für ein Biest ist dieser Luftstrom, aus welchen Komponenten er besteht und wie sie miteinander interagieren
- über die Hauptentitäten von Airflow: Pipelines namens DAG, Operator und ein paar weitere Dinge
- wie man bei Airflow erfolgreich entwickelt
- wie wir die Erzeugung von Pipelines und das sogenannte "deklarative Schreiben von Pipelines" implementiert haben
- über die Vor- und Nachteile der Verwendung von Airflow
Was ist Luftstrom?
Airflow ist eine Plattform zum Erstellen, Überwachen und Orchestrieren von Pipelines. Dieses in Python geschriebene Open Source-Projekt wurde 2014 bei Airbnb erstellt. Im Jahr 2016 wurde Airflow unter die Fittiche der Apache Software Foundation gestellt, durch einen Inkubator geführt und Anfang 2019 zu einem Apache-Projekt auf höchstem Niveau.
In der Welt der Datenverarbeitung wird es von einigen als ETL-Tool bezeichnet, aber dies ist nicht genau ETL im klassischen Sinne, wie Pentaho, Informatica PowerCenter, Talend und andere wie sie. Airflow ist ein Orchestrator, ein „batteriebetriebener Cron“: Er erledigt nicht die schwere Arbeit, Daten selbst zu übertragen und zu verarbeiten, sondern teilt anderen Systemen und Frameworks mit, was zu tun ist, und überwacht den Ausführungsstatus. Wir verwenden es hauptsächlich, um Abfragen in Hive- oder Spark-Jobs auszuführen.
Spoiler
Airflow, worker ( ), . , , .
Das Spektrum der mit Airflow gelösten Aufgaben beschränkt sich nicht nur auf die Ausführung in einem Hadoop-Cluster. Es kann Python-Code ausführen, Bash-Befehle ausführen, Docker-Container und Pods in Kubernetes hosten, Abfragen für Ihre Lieblingsdatenbank ausführen und vieles mehr.
Luftstromarchitektur
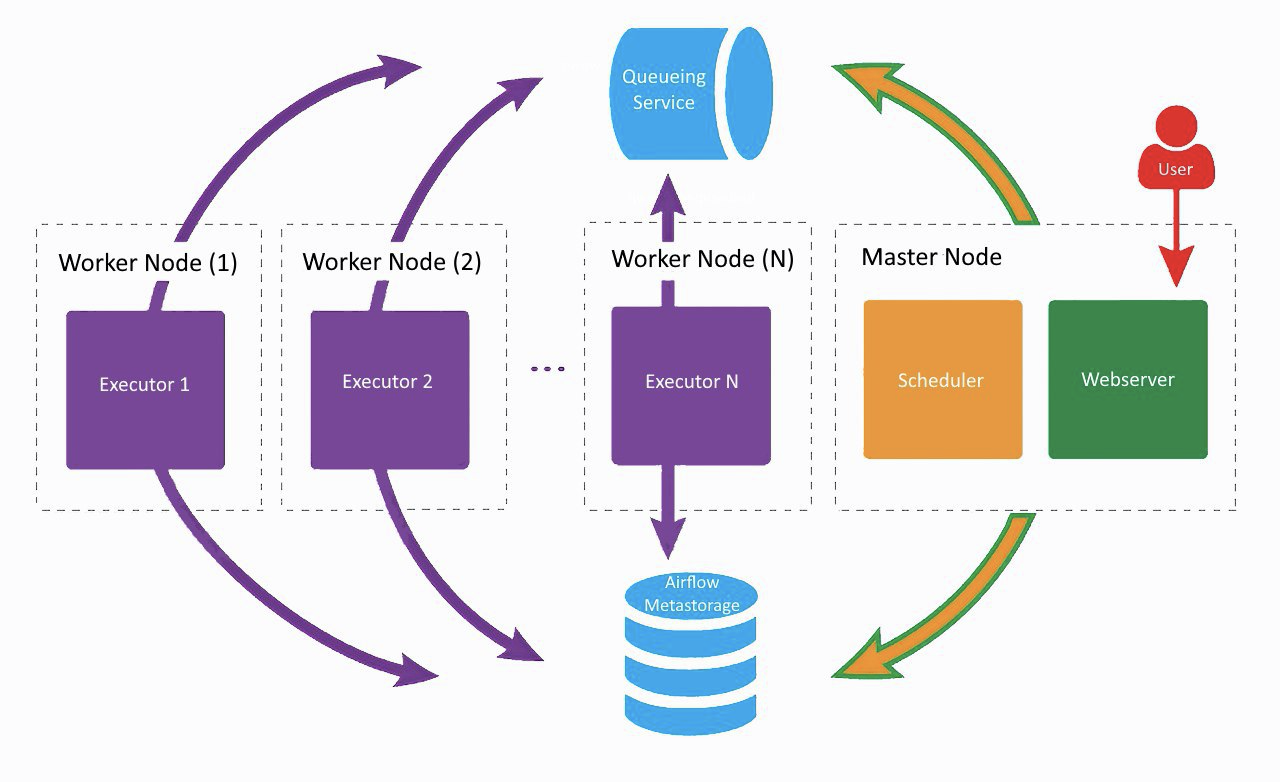
So sieht unser aktuelles Airflow-Setup ungefähr aus, nur Lamoda beschäftigt zwei Mitarbeiter. Auf einem separaten Computer drehen sich der Webserver und der Scheduler, die Mitarbeiter pusten auf die benachbarten. Eine wurde für reguläre Aufgaben entwickelt, die zweite für das Training von ML-Modellen mit Vowpal Wabbit. Alle Komponenten kommunizieren über eine Task-Warteschlange und eine Metadatenbasis miteinander.
Zu Beginn der Airflow-Entwicklung im Unternehmen arbeiteten alle Komponenten (mit Ausnahme der Datenbank) auf demselben Computer. Dies führte jedoch zu einem Mangel an Ressourcen auf dem Server und zu Verzögerungen bei der Arbeit des Schedulers. Aus diesem Grund haben wir uns entschlossen, die Dienste auf verschiedene Server zu verteilen, und sind zu der im obigen Bild gezeigten Architektur gekommen.
Luftstromkomponenten
Webserver
Webserver ist eine Webschnittstelle, die zeigt, was mit der Pipeline passiert. Diese Seite ist
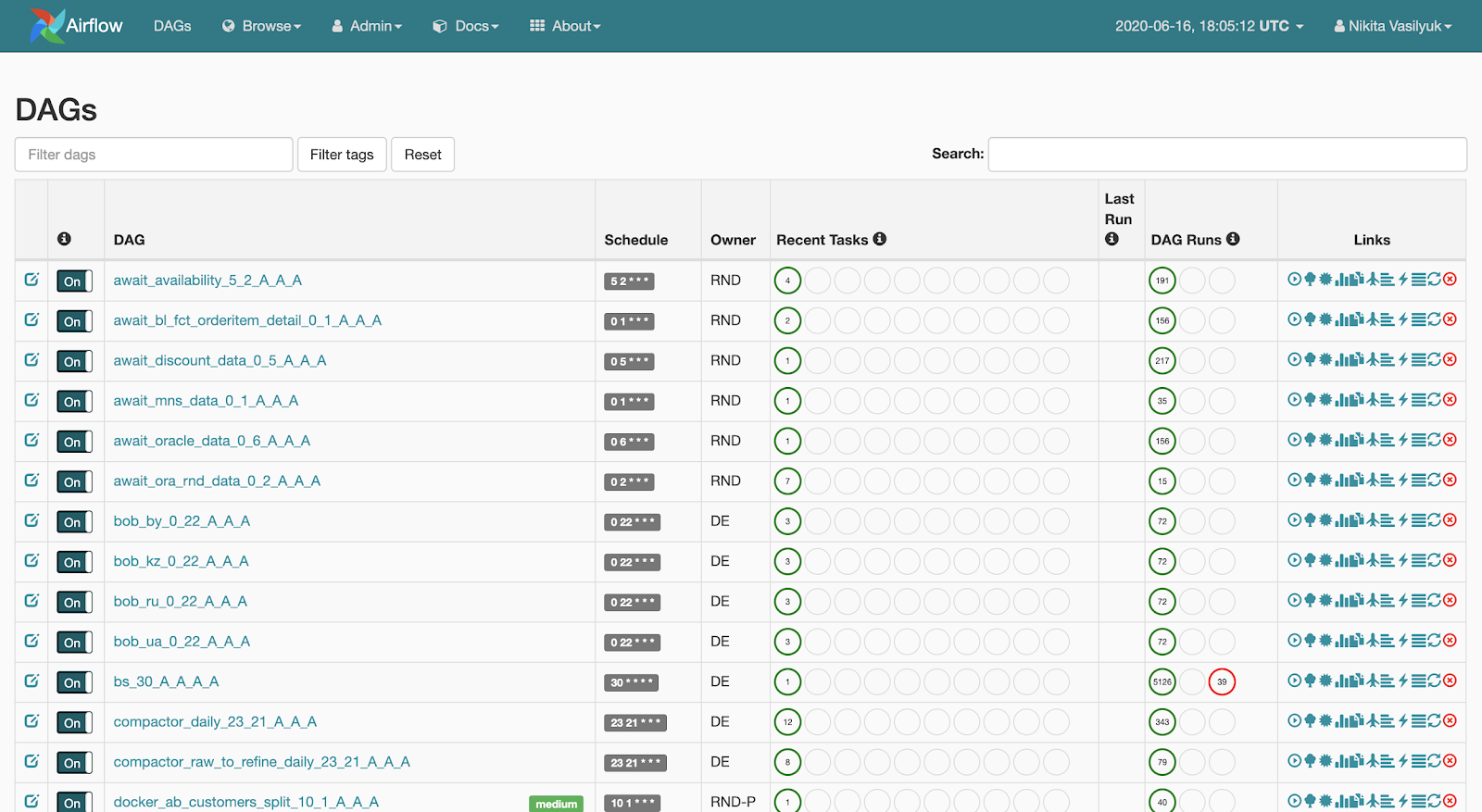
für den Benutzer sichtbar : Der Webserver ermöglicht das Anzeigen der Liste der verfügbaren Pipelines. Neben jeder Pipeline werden kurze Statistiken zu Starts angezeigt. Es gibt auch mehrere Schaltflächen, die die Pipeline zwingen, detaillierte Informationen zu starten oder anzuzeigen: Startstatistiken, Pipeline-Quellcode, deren Visualisierung in Form eines Diagramms oder einer Tabelle, eine Liste von Aufgaben und den Verlauf ihrer Starts.
Wenn wir auf die Pipeline klicken, werden wir durch das Menü Diagrammansicht fallen. Hier werden Aufgaben und Verknüpfungen zwischen ihnen angezeigt.
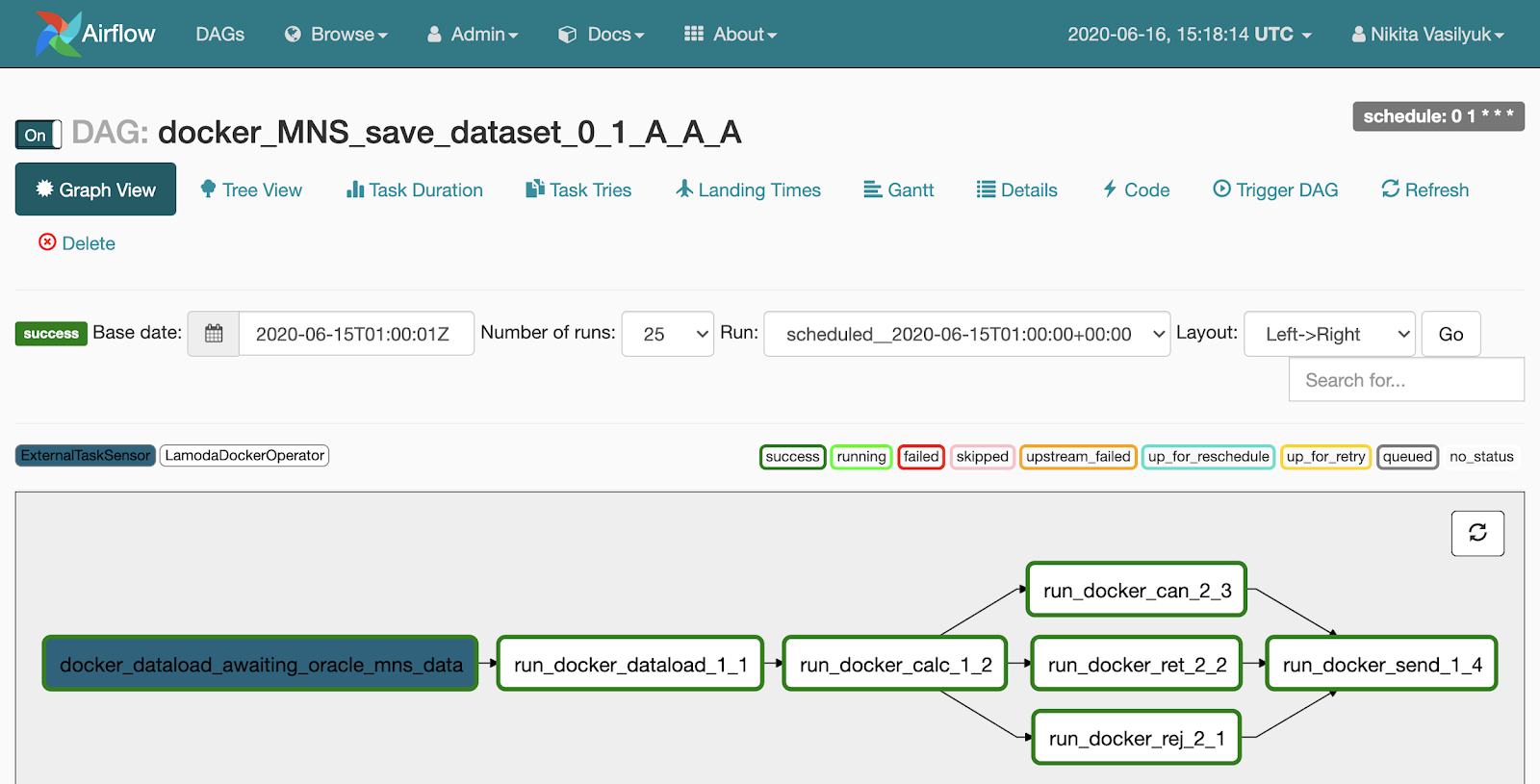
Neben der Diagrammansicht befindet sich ein Baumansicht-Menü. Es wurde erstellt, um Aufgaben neu zu starten, Statistiken und Protokolle anzuzeigen. Die baumartige Ansicht des Diagramms wird auf der linken Seite angezeigt. Gegenüber befindet sich eine Tabelle mit dem Verlauf des Taskstarts.
Jede Zeile dieser beängstigenden Tabelle ist eine Aufgabe, jede Spalte ist ein Anfang der Pipeline. An ihrer Kreuzung befindet sich ein Quadrat mit dem Start einer bestimmten Aufgabe für ein bestimmtes Datum. Wenn Sie darauf klicken, wird ein Menü angezeigt, in dem Sie detaillierte Informationen und Protokolle dieser Aufgabe anzeigen, starten oder neu starten und als erfolgreich oder nicht erfolgreich markieren können.

Scheduler - startet, wie der Name schon sagt, Pipelines, wenn es soweit ist. Es ist ein Python-Prozess, der regelmäßig mit Pipelines in das Verzeichnis wechselt, von dort aus den aktuellen Status abruft, den Status überprüft und ihn startet. Im Allgemeinen ist der Scheduler der interessanteste und gleichzeitig der Engpass in der Airflow-Architektur.
- Die erste Einschränkung ist, dass jeweils nur eine Scheduler-Instanz ausgeführt werden kann. Dies bedeutet, dass es derzeit unmöglich ist, mit Hochverfügbarkeit zu arbeiten (die Entwickler planen, Scheduler HA zu Airflow Version 2.0 hinzuzufügen).
- : , - . , - , .
Bis zu einer gewissen Zeit wird die Verzögerung durch die Parameter der Airflow-Konfigurationsdatei eingestellt, die Startverzögerung bleibt jedoch bestehen. Daraus folgt, dass es bei Airflow nicht um Echtzeit-Datenverarbeitung geht. Wenn Sie versehentlich handeln und ein zu häufiges Startintervall (alle paar Minuten) angeben, können Sie eine Verzögerung in Ihrer Pipeline erzielen. Die Erfahrung zeigt, dass alle 5 Minuten bereits häufig vorkommen und einige nicht empfehlen, die Pipeline alle 10 Minuten zu betreiben. Wir haben ein paar Pipelines, die alle 10 Minuten starten. Sie sind ziemlich einfach und es gab bisher keine Probleme mit ihnen.
Worker In
Worker wird unser Code ausgeführt und Aufgaben erledigt. Airflow unterstützt mehrere Ausführende:
- Der erste, der einfachste ist der SequentialExecutor. Es startet nacheinander eingehende Aufgaben und hält den Scheduler für die Dauer ihrer Ausführung an.
- LocalExecutor , , LocalExecutor . : - SQLite, LocalExecutor SequentialExecutor.
- CeleryExecutor , . Celery – , RabbitMQ Redis. , .
- DaskExecutor Dask – .
- KubernetesExecutor pod Kubernetes.
- DebugExecutor IDE.
Apache Airflow-Entitäten
Pipeline oder DAG
Die wichtigste Essenz von Airflow ist die DAG, auch bekannt als Pipeline, auch bekannt als gerichteter azyklischer Graph. Um klarer zu machen, wie man es kocht und warum Sie es brauchen, werde ich ein kleines Beispiel analysieren.
Nehmen wir an, ein Analyst kam zu uns und bat uns, einmal am Tag Daten in eine bestimmte Tabelle einzutragen. Er bereitete alle Informationen vor: Was soll man von wo bekommen, wann soll man mit welchem SLA anfangen? Hier ist ein Beispiel, wie wir unsere Pipeline beschreiben können.
dag = DAG(
dag_id="load_some_data",
schedule_interval="0 1 * * *",
default_args={
"start_date": datetime(2020, 4, 20),
"owner": "DE",
"depends_on_past": False,
"sla": timedelta(minutes=45),
"email": "<your_email_here>",
"email_on_failure": True,
"retries": 2,
"retry_delay": timedelta(minutes=5)
}
)
Die dag_id enthält den eindeutigen Namen der Pipeline. Als Nächstes verwenden wir Schedule_Interval, um anzugeben, wie oft es ausgeführt werden soll.
Sehr wichtiger Punkt: Da Airflow von einem internationalen Unternehmen entwickelt wurde, funktioniert es nur in UTC. Im Moment gibt es keine vernünftige Möglichkeit, Airflow in einer anderen Zeitzone zum Laufen zu bringen. Sie müssen sich daher ständig an den Unterschied zwischen unserer Zeitzone und UTC erinnern. In Version 1.10.10 wurde es möglich, die Zeitzone in der Benutzeroberfläche zu ändern. Dies gilt jedoch nur für die Weboberfläche. Pipelines werden weiterhin in UTC ausgeführt.
Der Parameter default_args ist ein Wörterbuch, das die Standardargumente für alle Aufgaben in dieser Pipeline beschreibt. Die Namen der meisten Parameter beschreiben sich gut, ich werde nicht darauf eingehen.
Operator
Ein Operator ist eine Python-Klasse, die beschreibt, welche Aktionen innerhalb unserer täglichen Aufgabe ausgeführt werden müssen, um den Analysten zu begeistern.
Wir können den HiveOperator verwenden, der seltsamerweise dafür ausgelegt ist, Ausführungsanforderungen an Hive zu senden. Um den Operator zu starten, müssen Sie den Aufgabennamen, die Pipeline, die Verbindungs-ID zu Hive und die auszuführende Anforderung angeben.
run_sql = HiveOperator(
dag=dag,
task_id="run_sql",
hive_cli_conn_id="hive",
hql="""
INSERT OVERWRITE TABLE some_table
SELECT * FROM other_table t1
JOIN another_table t2 on ...
WHERE other_table.dt = '{{ ds }}'
"""
)
notify = SlackAPIPostOperator(
dag=dag,
task_id="notify_slack",
slack_conn_id="slack",
token=token,
channel="airflow_alerts",
text="Guys, I'm done for {{ ds }}"
)
run_sql >> notify
Die Anfrage enthält ein Stück Jinja-Vorlage, die wir an den Konstruktor des Operators übergeben. Jinja ist eine Python-Vorlagenbibliothek.
Jeder Pipeline-Start speichert Informationen zum Startdatum. Es liegt in einer Variablen namens execute_date. {{ds}} ist ein Makro, das im Ausführungsdatum nur das Datum im Format% Y-% m-% d annimmt. Zu einem bestimmten Zeitpunkt vor dem Starten des Operators rendert Airflow eine Abfragezeichenfolge, ersetzt dort das erforderliche Datum und sendet eine Anforderung zur Ausführung.
ds ist nicht das einzige Makro, es gibt ungefähr 20 davon (eine Liste aller verfügbaren Makros) . Sie enthalten verschiedene Datumsformate und einige Funktionen zum Arbeiten mit Datumsangaben - Tage hinzufügen oder entfernen.
Als ich Airflow kennenlernte, verstand ich nicht, warum alle Arten von Makros benötigt werden, wenn Sie dort einfach einen datetime.now () -Aufruf einfügen und das Leben genießen können. In einigen Fällen kann dies jedoch das Leben von uns und dem Analytiker erheblich ruinieren. Wenn wir beispielsweise etwas für ein Datum in der Vergangenheit neu berechnen möchten, ersetzt Airflow dort nicht das Startdatum der Pipeline, sondern die tatsächliche Ausführungszeit. In einigen Fällen erhalten wir möglicherweise nicht das, was wir erwarten.
Wenn wir beispielsweise die Pipeline für den letzten Dienstag neu starten möchten, berechnen wir bei Verwendung von datetime.now () die Pipeline für heute und nicht für das erforderliche Datum neu. Außerdem sind die heutigen Daten zu diesem Zeitpunkt möglicherweise noch nicht einmal fertig.
Nach erfolgreichem Abschluss der Anfrage können wir eine Benachrichtigung über das Laden von Daten senden. Als nächstes befehlen wir Airflow, in welcher Reihenfolge Aufgaben gestartet werden sollen. Dank der Überlastung des Bedieners in Airflow kann ich mit dem Operator >> problemlos die Reihenfolge der Schritte in der Pipeline festlegen. In meinem Beispiel sagen wir, dass wir zuerst mit der Ausführung der Anforderung beginnen und dann eine Benachrichtigung an slack senden.
Idempotenz
Es ist unmöglich, über Luftstrom zu sprechen, ohne die Idempotenz zu erwähnen. Für alle Fälle möchte ich Sie daran erinnern: Idempotenz ist eine Eigenschaft eines Objekts. Wenn Sie eine Operation erneut auf ein Objekt anwenden, geben Sie immer das gleiche Ergebnis zurück.
Im Kontext von Airflow bedeutet dies, dass wenn heute Freitag ist und wir die Aufgabe letzten Dienstag neu starten, die Aufgabe so startet, als wäre es letzter Dienstag, und sonst nichts. Das heißt, der Start oder Neustart einer Aufgabe für ein Datum in der Vergangenheit sollte in keiner Weise davon abhängen, wann diese Aufgabe tatsächlich gestartet wird. Die Idempotenz wird mithilfe der oben genannten Variablen execute_date implementiert.
Airflow wurde als Werkzeug zur Lösung von Datenverarbeitungsaufgaben entwickelt. In dieser Welt verarbeiten wir normalerweise einen großen Datenblock nur dann, wenn er fertig ist, dh am nächsten Tag. Und die Entwickler von Airflow haben ursprünglich ein solches Konzept in ihren Produkten festgelegt.
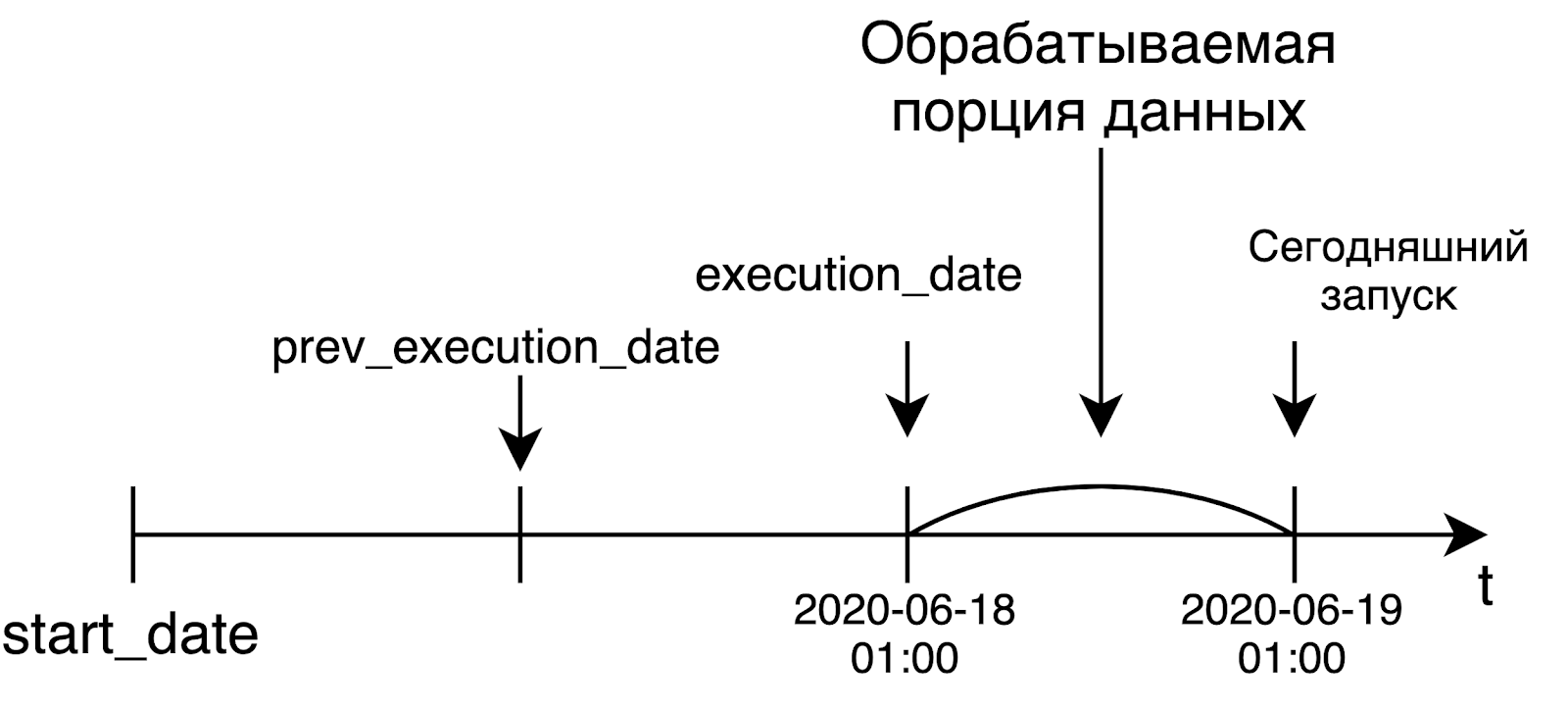
Wenn wir eine tägliche Pipeline starten, werden wir höchstwahrscheinlich Daten von gestern verarbeiten wollen. Aus diesem Grund entspricht execution_date dem linken Rand des Intervalls, für das wir die Daten verarbeiten. Beispielsweise erhält der heutige Start, der um 1 Uhr UTC begann, das gestrige Datum als Ausführungsdatum. Bei einer stündlichen Pipeline ist die Situation dieselbe: Um die Pipeline um 6 Uhr morgens zu starten, beträgt die Zeit in execute_date 5 Uhr morgens. Diese Idee ist zunächst nicht sehr offensichtlich, aber dennoch sehr bedeutungsvoll und wichtig.
Die gängigsten Luftstrombetreiber
In Airflow gibt es nicht nur Betreiber, die zu Hive gehen und etwas zum Nachlassen senden. Tatsächlich gibt es Unmengen von Betreibern. In dem Artikel habe ich die beliebtesten und nützlichsten herausgebracht.
- BashOpetator und PythonOperator. Mit ihnen ist alles klar: Sie senden einen Bash-Befehl bzw. eine Python-Funktion zur Ausführung.
- Es gibt eine Vielzahl von Operatoren zum Senden von Abfragen an verschiedene Datenbanken. Standard Postgres, MySQL, Oracle, Hive, Presto werden unterstützt. Wenn es aus irgendeinem Grund keinen Operator für Ihre Lieblingsdatenbank gibt, können Sie einen allgemeineren JdbcOperator verwenden oder Ihren eigenen schreiben, Airflow erlaubt dies.
- Sensor – , . , - . , , . , : 3 , . . , , .
- BranchPythonOperator – , , python , , .
- DockerOpetator Docker- . , Docker- , . , .
- KubernetesPodOperator pod Kubernetes.
- DummyOperator , .
Lamoda
- – LamodaDockerOperator. , : - Hadoop, . LamodaDockerOperator Spark- , python.
- LamodaHiveperator – , . Hive. , - , , . , , HiveCliHook HiveServer2Hook, .
- – ExternalTaskSensor. . , Hadoop . , , , - , , . , - HDFS, Airflow.
- BashOperator, PythonOperator – , bash- python .
- , . - , .
Airflow
- Variables – , , , . , . , Hive, HDFS, . dev- prod-, .
- Connections – , . Airflow : http ftp, .
- Hooks – , .
- SLA -. , . SLA , , - - . - : - , Airflow .
- – XCom, cross-communication. : , json-. – 48 .
- – , . , . , 5, , , , .

Außerdem können Sie sehen, wie sich die Dauer der Aufgaben im Laufe des Tages geändert hat. In unserem Fall ist dies der Prozess der Übertragung von Daten von Kafka nach Hive mit Überprüfung der Datenqualität. Außerdem können Sie nachverfolgen, wann die Aufgabe aus irgendeinem Grund länger als gewöhnlich gedauert hat.

Erfolg in der Luftstromentwicklung
Im Folgenden finden Sie einige Tipps, mit denen Sie vermeiden können, dass Sie bei Verwendung von Airflow in den Fuß geschossen werden:
- Es ist nützlich, jede Pipeline (oder jeden Pipeline-Generator, mehr dazu weiter unten) in einer separaten Datei zu speichern. Ich weiß sofort, zu welcher Datei ich gehen muss, um die erforderliche Pipeline oder den erforderlichen Generator anzuzeigen.
- , , . , -, . , - , . : , , .
- – schedule_interval start_date dag_id. , Airflow , - -. DAGS , Scheduler, . , , dag_id. , .
- catchup. True, Airflow , start_date . , . False Airflow . , Airflow True ( -).
- – . , python , airflow DAG, , DAG. . , , . REST API, requests.get() .
:
Seit Beginn der Verwendung von Airflow haben wir Pipeline-Konfigurationen vom Code getrennt. Ursprünglich war dies auf die Besonderheiten des Bereitstellungsschemas zurückzuführen, doch allmählich setzte sich dieser Ansatz durch. Und jetzt verwenden wir Konfigurationen überall dort, wo es einen Hauch von Boilerplate gibt. Dies betrifft insbesondere Spark-Jobs, die wir von Docker aus ausführen. Daraus entstand die Geschichte mit dem deklarativen Schreiben von Pipelines.
Der Ansatz ist, dass wir ein Verzeichnis mit Konfigurationen haben. Jede Konfigurationsdatei enthält eine oder mehrere Pipelines mit ihrer Beschreibung: Wie sollten sie funktionieren, wann sollen sie gestartet werden, welche Aufgaben sind darin enthalten und in welcher Reihenfolge sollten sie ausgeführt werden.
Ich werde zeigen, wie der Code zum Aufrufen unseres Pipeline-Generators aussieht. Am Eingang erhält er ein Verzeichnis mit Konfigurationen, einem Präfix und einer Klasse, die für das Füllen der Pipeline mit Aufgaben verantwortlich ist. Unter der Haube geht der Generator in das angegebene Verzeichnis, findet dort die Konfigurationsdateien und erstellt in diesen Dateien Aufgaben für jede Pipeline und verknüpft sie.
from libs.dag_from_config.dag_generator import DagGenerator
from libs.runners.docker_runner import DockerRunner
generator = DagGenerator(config_dir='dag_configs/docker_runner', prefix='docker')
dags = generator.generate(task_runner=DockerRunner)
for dag in dags:
globals()[dag.dag_id] = dag #
So sieht eine typische Konfigurationsdatei aus. Zur Beschreibung der Konfigurationen verwenden wir das HOCON- Format , eine Obermenge von JSON. Es unterstützt den Import anderer HOCON-Dateien und kann auf die Werte anderer Variablen verweisen.
In der Konfiguration auf Pipeline-Ebene (Attributionsblock) können Sie viele Parameter angeben, die wichtigsten sind jedoch Name, Startdatum und Zeitplanintervall.
docker_image = "docker_registry/attribution/calculation:1.1.0"
dags {
attribution {
owner = "RND"
name = "attribution"
start_date = "20190601"
emails = [...]
schedule_interval = "0 1 * * *"
depends_on_past = true
concurrency = 4
description = """
- z_log
-
- ,
-
"""
tags = ["critical"]
Hier können Sie die Parallelität angeben - wie viele Aufgaben gleichzeitig in einem Lauf ausgeführt werden. Kürzlich haben wir hier einen Block mit einer kurzen Markdown-Beschreibung der Pipeline hinzugefügt. Dann geht es zusammen mit den restlichen Informationen über die Pipeline zu Confluence (wir haben das Senden mit Foliant implementiert ). Es hat sich als sehr praktisch herausgestellt: Auf diese Weise sparen wir Zeit für ausgegrabene Entwickler, um Seiten in Confluence zu erstellen.
Als nächstes kommt der Teil, der für die Bildung von Aufgaben verantwortlich ist. Zunächst geben wir im Verbindungsblock an, von welcher Verbindung in Airflow wir Parameter für die Verbindung mit einer externen Quelle übernehmen müssen - im Beispiel ist dies unser DWH.
docker {
connections {
LMD_DWH = "dwh"
}
containers {
desktop {
image = ${docker_image}
connections = [LMD_DWH]
environment {
LMD_YARN_QUEUE = "{{ var.value.YARN_QUEUE }}"
LMD_INSTANCES = 60
LMD_MEMORY_PER_INSTANCE = "4g"
LMD_ZLOG_SOURCE = "z_log_db.z_log"
LMD_ATTRIBUTION_TABLE = "{{ var.value.HIVE_DB_DERIVATIVES }}.z_log_attribution"
LMD_ORDERS_TABLE = "rocket_dwh_bl.fct_orderitem_detail"
LMD_PLATFORMS = "desktop"
LMD_RUN_DATE = "{{ ds_nodash }}"
}
}
mobile {...}
iOS {...}
Android {...}
}
tasks = [[desktop, mobile, iOS, Android]]
}
Alle erforderlichen Informationen wie Benutzer, Kennwort, URL usw. werden als Umgebungsvariablen an den Docker-Container weitergeleitet. Im Container-Block geben wir an, welche Aufgaben wir starten werden. Im Inneren befinden sich der Name des Bildes, eine Liste der verwendeten Verbindungen und eine Liste der Umgebungsvariablen.
Möglicherweise stellen Sie fest, dass Jinja-Vorlagen in den Werten einiger Umgebungsvariablen angezeigt werden. Um eine Warteschlange in YARN anzugeben, verwenden wir die Standard-Airflow-Syntax, um Variablenwerte abzurufen. Um das Startdatum anzugeben, verwenden wir das Makro {{ds_nodash}}, das das Datum ihres Ausführungsdatums ohne Bindestriche darstellt. Die Konfiguration enthält 3 weitere ähnliche Aufgaben, die der Übersichtlichkeit halber ausgeblendet sind.
Als Nächstes geben wir anhand von Aufgaben an, wie diese Aufgaben gestartet werden. Sie werden feststellen, dass sie als Liste in einer Liste aufgeführt sind. Dies bedeutet, dass alle 4 dieser Aufgaben parallel zueinander ausgeführt werden.
Und noch eine letzte Sache: Wir geben an, von welchen Basis-Pipelines unsere aktuelle DAG abhängt. Seltsame Zahlen und Buchstaben am Ende der Namen der Basis-Dags sind der Zeitplan, den wir in den Namen der Pipeline einbetten. Daher wird unsere Pipeline erst gefüllt, nachdem die grundlegenden Dags und die darin angegebenen Aufgaben abgeschlossen sind.
awaits {
z_log_compaction {
dag = "compactor_daily_23_21_A_A_A"
task = "compact_z_log_db_z_log"
timedelta = 3hr37m
}
oracle_bl_fct_orderitem_detail {
dag = "await_bl_fct_orderitem_detail_0_1_A_A_A"
}
}
}
}
Volltext der Konfigurationsdatei
docker_image = "docker_registry/attribution/calculation:1.1.0"
dags {
attribution {
owner = "RND"
name = "attribution"
start_date = "20190601"
emails = [...]
schedule_interval = "0 1 * * *"
depends_on_past = true
concurrency = 4
description = """
- z_log
-
- ,
-
"""
tags = ["critical"]
docker {
connections {
LMD_DWH = "dwh"
}
containers {
desktop {
image = ${docker_image}
connections = [LMD_DWH]
environment {
LMD_YARN_QUEUE = "{{ var.value.YARN_QUEUE }}"
LMD_INSTANCES = 60
LMD_MEMORY_PER_INSTANCE = "4g"
LMD_ZLOG_SOURCE = "z_log_db.z_log"
LMD_ATTRIBUTION_TABLE = "{{ var.value.HIVE_DB_DERIVATIVES }}.z_log_attribution"
LMD_ORDERS_TABLE = "rocket_dwh_bl.fct_orderitem_detail"
LMD_PLATFORMS = "desktop"
LMD_RUN_DATE = "{{ ds_nodash }}"
}
}
mobile {...}
iOS {...}
Android {...}
}
tasks = [[desktop, mobile, iOS, Android]]
}
awaits {
z_log_compaction {
dag = "compactor_daily_23_21_A_A_A"
task = "compact_z_log_db_z_log"
timedelta = 3hr37m
}
oracle_bl_fct_orderitem_detail {
dag = "await_bl_fct_orderitem_detail_0_1_A_A_A"
}
}
}
}
Das bekommen wir nach der Generation:
- 2 Punkte im Warteblock wurden zu zwei Sensoren, die auf die Ausführung der Basis-Pipeline warten.
- Die 4 Aufgaben, die wir im Docker-Block angegeben haben, wurden zu 4 parallel laufenden Aufgaben.
- Wir haben einen DummyOperator zwischen den beiden Operatorblöcken hinzugefügt, damit kein Verbindungsnetz zwischen Aufgaben besteht.
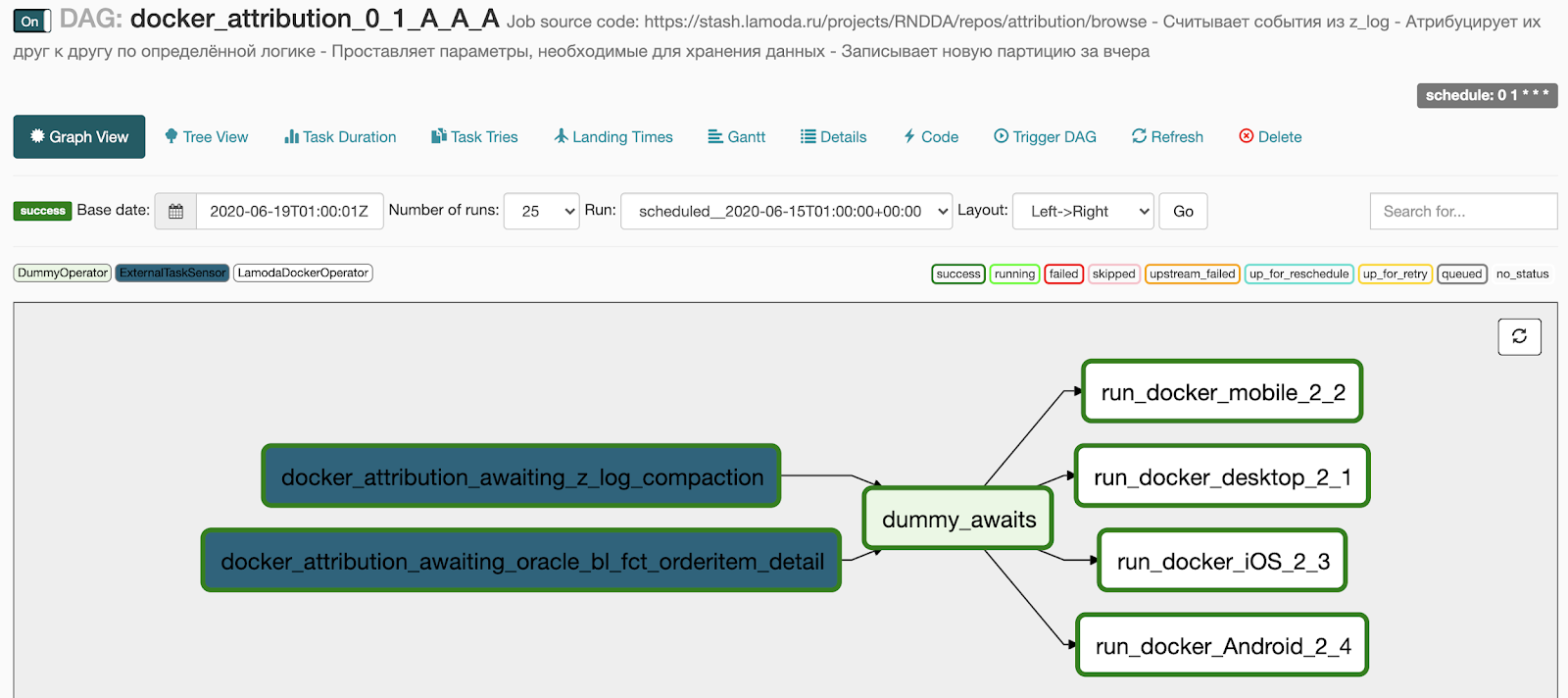
Was wollen wir als nächstes tun?
Erstellen Sie zunächst eine vollständige Feature-Umgebung. Wir haben jetzt einen Entwicklungsstand zum Testen aller unserer Pipelines. Und bevor Sie testen, müssen Sie sicherstellen, dass die Entwicklungslandschaft jetzt frei ist.
Vor kurzem hat sich unser Team erweitert und die Anzahl der Bewerber hat zugenommen. Wir haben eine vorübergehende Lösung für das Problem gefunden und lassen uns jetzt in Slack wissen, wann wir dev nehmen. Es funktioniert, aber es ist immer noch ein Engpass bei der Entwicklung und beim Testen.
Eine Möglichkeit besteht darin, zu Kubernetes zu wechseln. Wenn Sie beispielsweise eine Pull-Anforderung in Master erstellen, können Sie in Kubernetes einen separaten Namespace erstellen, in dem Airflow bereitgestellt, der Code bereitgestellt und dann Variablen und Verbindungen verteilt werden. Nach der Bereitstellung kommt der Entwickler zur neu erstellten Airflow-Instanz und testet seine Pipelines. Wir haben einige Grundlagen zu diesem Thema, aber unsere Hände kamen nicht zum Kampf-Kubernetes-Cluster, wo wir alles ausführen konnten.
Die zweite Option zum Implementieren der Feature-Umgebung besteht darin, ein Repository mit einem gemeinsamen Entwicklungszweig zu organisieren, in dem Entwicklercode zusammengeführt und automatisch in die Entwicklungslandschaft eingeführt wird. Jetzt schauen wir uns aktiv diesem Schema an.
Wir möchten auch versuchen, Plugins zu implementieren - Dinge, um die Funktionalität der Weboberfläche zu erweitern. Das Hauptziel der Implementierung von Plugins besteht darin, ein Gantt-Diagramm auf der Ebene des gesamten Luftstroms, dh auf der Ebene aller Pipelines, sowie ein Abhängigkeitsdiagramm zwischen verschiedenen Pipelines zu erstellen.
Warum wir uns für Airflow entschieden haben
- Erstens ist dies Python, wo Sie mit Hilfe von zwei Schleifen und einigen Bedingungen eine elegante, korrekt funktionierende Pipeline erstellen können. Und es muss nicht in einem großen Teil von XML beschrieben werden. Außerdem ist fast das gesamte Python-Ökosystem und sein gesamter Bibliothekszoo sofort verfügbar und können nach Belieben verwendet werden.
- Das Fehlen von XML vereinfacht die Codeüberprüfung erheblich. Wir haben den Pipeline-Code und die Konfigurationen dafür geschrieben, und alles ist in Ordnung, alles funktioniert. Sie können zwar XML oder ein anderes Konfigurationsformat ziehen, aber das ist Geschmackssache.
- unit-, , .
- , «», . Airflow . , , .
- Airflow ( ).
- Active Directory RBAC (role-based access control, )
- Worker Celery Kubernetes.
- open source-, , .
- Airflow , . .
- : statsd , Sentry – , Airflow , . Airflow-exporter Prometheus.
Airflow,
- – : , , execution_date – , .
- - -, , , Apache NiFi. – code-review diff- , .
- Scheduler - .
- – , . – .
- Airflow : . , , . RBAC ( ) , UI (, , ). RBAC – security Flask, .
- : , , -, , . , .
Airflow
- crontab’a cron .
- Python.
- - Docker, , .
- , , real time.
- Airflow , “, , , Z – ”.