
Heute werden wir Ihnen erzählen, wie wir ein Suchsystem für Kandidatenbohrungen für das hydraulische Brechen (HF) unter Verwendung von maschinellem Lernen (im Folgenden - ML) entwickelt haben und was daraus entstanden ist. Lassen Sie uns herausfinden, warum hydraulisches Brechen erforderlich ist, was ML damit zu tun hat und warum unsere Erfahrung nicht nur für Ölmänner nützlich sein kann.
Unter dem Schnitt eine detaillierte Erklärung des Problems, eine Beschreibung unserer IT-Lösungen, die Auswahl der Metriken, die Erstellung einer ML-Pipeline, die Entwicklung einer Architektur für die Veröffentlichung eines Modells in prod.
Wir haben in unseren vorherigen Artikeln hier und hier darüber geschrieben, warum Frakturen durchgeführt werden .
Warum wird hier maschinell gelernt? Einerseits ist das hydraulische Brechen billiger als das Bohren, aber es ist immer noch kostspielig, und andererseits wird es nicht an jedem Bohrloch möglich sein - es wird keine Wirkung haben. Ein erfahrener Geologe sucht nach geeigneten Orten. Da die Anzahl der operativen Unternehmen groß ist (Zehntausende), werden Optionen häufig übersehen und das Unternehmen erhält keine möglichen Gewinne. Der Einsatz von maschinellem Lernen kann die Analyse von Informationen erheblich beschleunigen. Das Erstellen eines ML-Modells ist jedoch nur die halbe Miete. Es ist notwendig, es in einem konstanten Modus arbeiten zu lassen, es mit dem Datendienst zu verbinden, eine schöne Oberfläche zu zeichnen und es so zu gestalten, dass es für den Benutzer bequem ist, die Anwendung aufzurufen und sein Problem mit zwei Klicks zu lösen.
Aus der Ölindustrie geht hervor, dass in allen Unternehmen ähnliche Aufgaben gelöst werden. Jeder möchte:
A. Die Verarbeitung und Analyse großer Datenströme automatisieren.
B. Reduzieren Sie die Kosten und verpassen Sie nicht die Vorteile.
C. Machen Sie ein solches System schnell und effizient.
In dem Artikel erfahren Sie, wie wir ein solches System implementiert haben, welche Tools wir verwendet haben und welche Probleme wir auf dem schwierigen Weg hatten, ML in die Produktion einzuführen. Wir sind sicher, dass unsere Erfahrung für alle von Interesse sein kann, die eine Routine automatisieren möchten - unabhängig vom Tätigkeitsbereich.
Wie Brunnen auf "traditionelle" Weise für das hydraulische Brechen ausgewählt werden
Bei der Auswahl der Kandidatenbohrungen für das hydraulische Brechen stützt sich der Ölmann auf seine umfangreiche Erfahrung und betrachtet verschiedene Grafiken und Tabellen. Anschließend sagt er voraus, wo das hydraulische Brechen durchgeführt werden soll. Zuverlässig weiß jedoch niemand, was in einer Tiefe von mehreren tausend Metern passiert, da es nicht so einfach ist, unter die Erde zu schauen (mehr dazu im vorherigen Artikel ). Die Datenanalyse mit "traditionellen" Methoden erfordert erhebliche Arbeitskosten, garantiert jedoch leider keine genaue Vorhersage der Ergebnisse des hydraulischen Bruchs (Spoiler - auch mit ML).
Wenn wir den aktuellen Prozess zur Identifizierung von Kandidatenbohrungen für das hydraulische Brechen beschreiben, besteht er aus den folgenden Schritten: Entladen von Daten zu Bohrlöchern aus Unternehmensinformationssystemen, Verarbeiten der erhaltenen Daten, Durchführen von Expertenanalysen, Vereinbaren einer Lösung, Durchführen eines hydraulischen Brechens und Analysieren der Ergebnisse. Sieht einfach aus, aber nicht ganz.
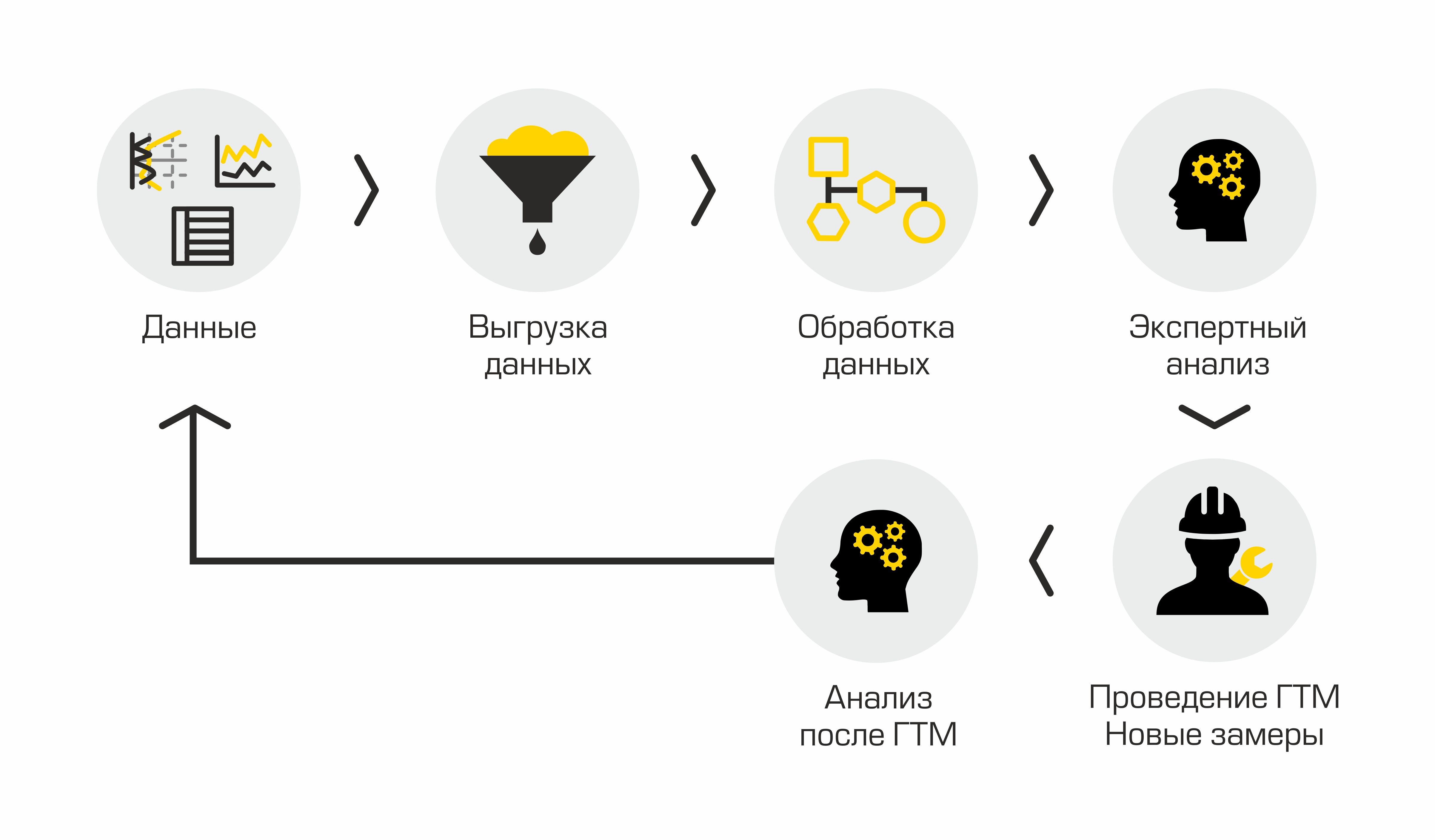
Aktueller Auswahlprozess für Kandidatenbrunnen
Der Hauptnachteil dieses „manuellen“ Ansatzes ist viel Routine, das Volumen wächst, die Menschen beginnen bei der Arbeit zu ertrinken, es gibt keine Transparenz im Prozess und in den Methoden.
Formulierung des Problems
Im Jahr 2019 stand unser Datenanalyseteam vor der Aufgabe, ein automatisiertes System für die Auswahl der Kandidatenbohrungen für das hydraulische Brechen zu erstellen. Für uns klang es so: Um den Zustand aller Bohrlöcher zu simulieren, unter der Annahme, dass derzeit hydraulische Fracking-Vorgänge an ihnen durchgeführt werden müssen, ordnen Sie die Bohrlöcher nach dem größten Anstieg der Ölförderung und wählen Sie die Top-N-Bohrlöcher aus, zu denen die Flotte gehen wird, und ergreifen Sie Maßnahmen zur Steigerung der Ölrückgewinnung.
Mithilfe von ML-Modellen werden Indikatoren gebildet, die die Machbarkeit des hydraulischen Aufbrechens an einem bestimmten Bohrloch anzeigen: die Ölförderung nach dem geplanten hydraulischen Aufbrechen und den Erfolg dieser Veranstaltung.
In unserem Fall ist die Ölförderrate die in Kubikmetern pro Monat produzierte Ölmenge. Dieser Indikator wird auf der Grundlage von zwei Werten berechnet: Flüssigkeitsdurchfluss und Wasserschnitt. Ölmänner nennen eine Flüssigkeit eine Mischung aus Öl und Wasser - diese Mischung ist das Produkt von Brunnen. Und der Wasserschnitt ist der Anteil des Wassergehalts in einer bestimmten Mischung. Um die erwartete Ölproduktionsrate nach dem Brechen zu berechnen, werden zwei Regressionsmodelle verwendet: eines sagt die Flüssigkeitsströmungsrate nach dem Brechen voraus, das andere sagt den Wasserschnitt voraus. Unter Verwendung der von den Modelldaten zurückgegebenen Werte werden Ölproduktionsprognosen unter Verwendung der folgenden Formel berechnet:

Der Brucherfolg ist eine binäre Zielvariable. Sie wird anhand des tatsächlichen Wertes der Zunahme der Ölproduktion bestimmt, der nach dem hydraulischen Brechen erhalten wurde. Wenn das Wachstum größer als ein bestimmter Schwellenwert ist, der von einem Experten auf dem Gebiet der Domäne festgelegt wurde, ist der Wert des Erfolgsattributs gleich Eins, andernfalls ist er gleich Null. Somit bilden wir das Markup zur Lösung des Klassifizierungsproblems.
Was die Metrik betrifft ... Die Metrik sollte aus dem Geschäft stammen und die Interessen des Kunden widerspiegeln, sagen uns alle Kurse zum maschinellen Lernen. Hier liegt unserer Meinung nach der Haupterfolg oder Misserfolg eines maschinellen Lernprojekts. Eine Gruppe von Datenwissenschaftlern kann die Qualität des Modells so lange verbessern, wie sie möchten. Wenn dies jedoch den Geschäftswert für den Kunden in keiner Weise erhöht, ist ein solches Modell zum Scheitern verurteilt. Schließlich war es für den Kunden wichtig, einen genauen Kandidaten mit „physikalischen“ Vorhersagen der Bohrlochleistungsparameter nach dem hydraulischen Brechen zu erhalten.
Für das Regressionsproblem wurden die folgenden Metriken ausgewählt:

Warum gibt es nicht eine Metrik, fragen Sie - jede spiegelt ihre eigene Wahrheit wider. In Bereichen mit hohen durchschnittlichen Produktionsraten ist MAE groß und MAPE klein. Wenn wir ein Feld mit niedrigen durchschnittlichen Produktionsraten nehmen, ist das Bild umgekehrt.
Die folgenden Metriken wurden für das Klassifizierungsproblem ausgewählt:

( Wiki ),
Bereich unter der ROC-AUC-Kurve ( Wiki ).
Fehler Wir sind auf
Fehler Nr. 1 gestoßen - um ein universelles Modell für alle Felder zu erstellen.
Nach der Analyse der Datensätze wurde deutlich, dass sich die Daten von einem Feld in ein anderes ändern. Dies ist nicht überraschend, da Lagerstätten in der Regel eine andere geologische Struktur haben.
Unsere Annahme, dass, wenn wir alle verfügbaren Daten für das Training in ein Modell aufnehmen und einfließen lassen, die Regelmäßigkeiten der geologischen Struktur selbst sichtbar werden, ist gescheitert. Das auf den Daten eines bestimmten Feldes trainierte Modell zeigte eine höhere Qualität der Vorhersagen als das Modell, das unter Verwendung von Informationen über alle verfügbaren Felder erstellt wurde.
Für jedes Feld wurden verschiedene Algorithmen für maschinelles Lernen getestet und basierend auf den Ergebnissen der Kreuzvalidierung einer mit der niedrigsten MAPE ausgewählt.
Fehler Nr. 2 - Mangelndes tiefes Verständnis der Daten.
Wenn Sie ein gutes Modell für maschinelles Lernen für einen realen physischen Prozess erstellen möchten, verstehen Sie, wie dieser Prozess abläuft.
Anfangs hatte unser Team keinen Domain-Experten, und wir bewegten uns chaotisch. Leider haben wir die Fehler des Modells bei der Analyse der Prognosen nicht bemerkt, sie haben aufgrund der Ergebnisse falsche Schlussfolgerungen gezogen.
Fehler Nr. 3 - mangelnde Infrastruktur.
Zuerst haben wir viele verschiedene CSV-Dateien für verschiedene Felder und verschiedene Parameter heruntergeladen. Irgendwann hat sich eine unerträglich große Anzahl von Dateien und Modellen angesammelt. Es wurde unmöglich, die bereits durchgeführten Experimente zu reproduzieren, Akten gingen verloren und es kam zu Verwirrung.
1. TECHNISCHER TEIL
Unser System zur automatischen Auswahl von Kandidaten sieht heute folgendermaßen aus:
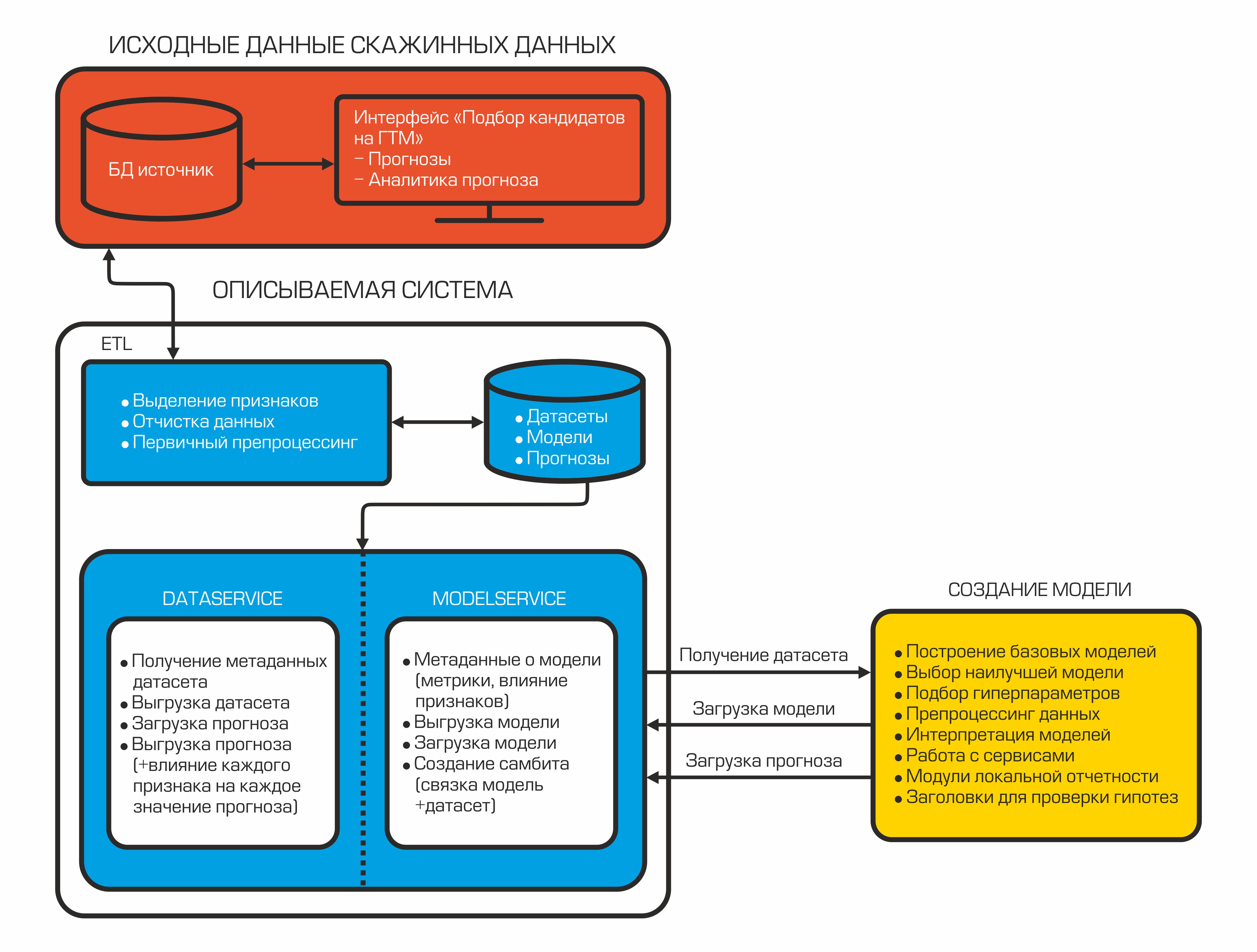
Jede Komponente ist ein isolierter Container, der eine bestimmte Funktion ausführt.
2.1 ETL = Datenladen
Alles beginnt mit Daten. Vor allem, wenn wir ein Modell für maschinelles Lernen erstellen möchten. Wir haben Pentaho Data Integration als Integrationssystem gewählt.

Screenshot einer der Transformationen
Hauptvorteile:
- freies System;
- eine große Auswahl an Komponenten zum Verbinden mit verschiedenen Datenquellen und zum Transformieren des Datenstroms;
- Verfügbarkeit einer Webschnittstelle;
- die Fähigkeit zur Verwaltung über die REST-API;
- Protokollierung.
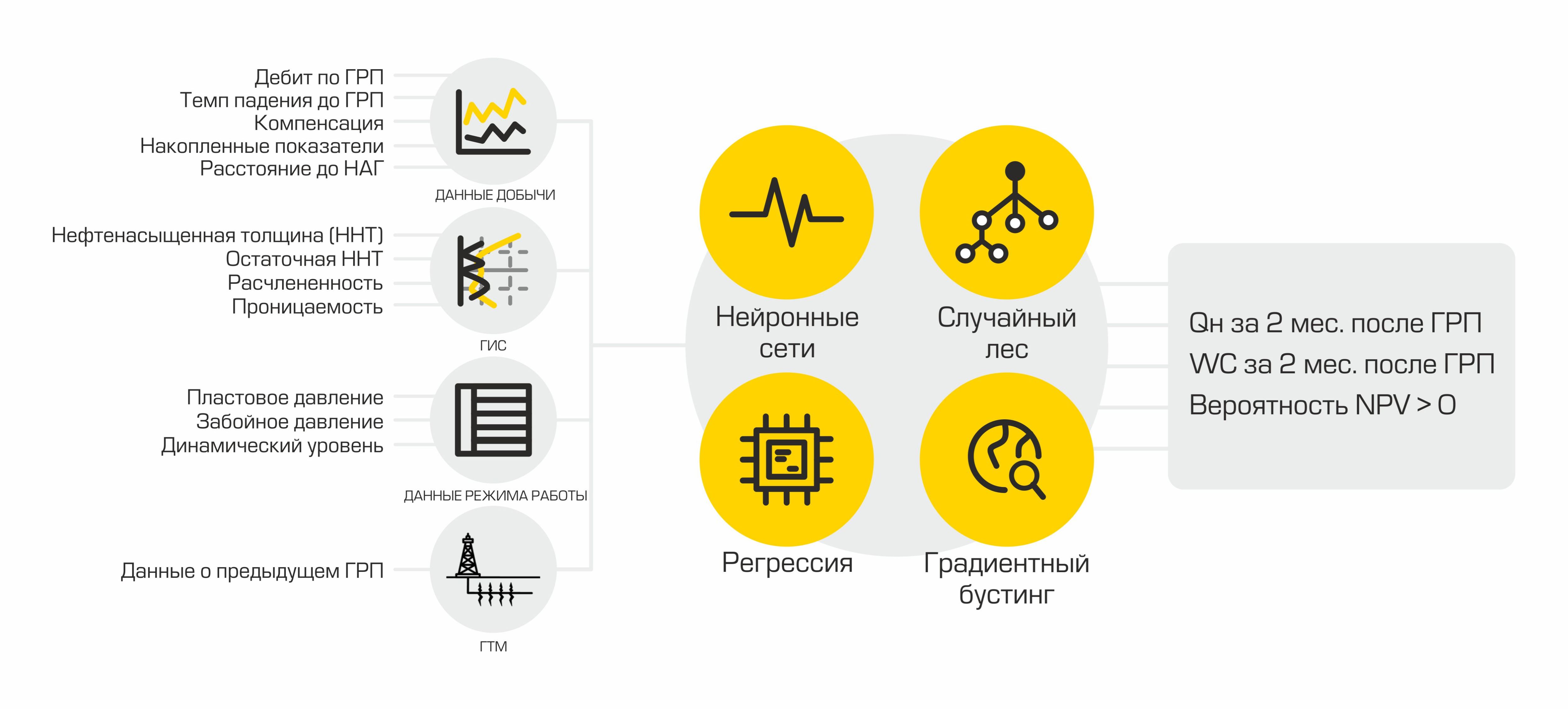
Darüber hinaus hatten wir umfangreiche Erfahrung in der Entwicklung von Integrationen für dieses Produkt. Warum ist in ML-Projekten eine Datenintegration erforderlich? Ständig benötigt , um komplexe Berechnungen durchführen , um Daten auf einen gemeinsamen Geist „auf dem Weg“ zur Verfügung stellen , um neue Zeichen zu berechnen In Datensätze vorbereitet werden - .. Durchschnitt, Parameteränderungen im Laufe der Zeit, usw.
Für jede Tatsache Fracturing entladen mehr als 400 Parameter beschreiben die gut Arbeit zum Zeitpunkt der Aktivitäten, Betrieb benachbarter Bohrlöcher sowie Informationen zu zuvor durchgeführten hydraulischen Frakturen. Ferner findet eine Datentransformation und Vorverarbeitung statt.
Wir haben PostgreSQL als Repository für die verarbeiteten Daten ausgewählt. Es gibt eine Vielzahl von Methoden für die Arbeit mit json. Da wir die endgültigen Datensätze in diesem Format speichern, wurde dies zu einem entscheidenden Faktor.
Ein maschinelles Lernprojekt ist aufgrund der Hinzufügung neuer Funktionen mit einer ständigen Änderung der Eingabedaten verbunden. Daher wird Data Vault als Datenbankschema verwendet (Link zum Wiki). Mit diesem Speicherentwurfsschema können Sie schnell neue Daten zu einem Objekt hinzufügen und die Integrität von Tabellen und Abfragen nicht verletzen.
2.2 Daten- und Modelldienste
Nach dem Kämmen und Berechnen der erforderlichen Indikatoren werden die Daten in die Datenbank hochgeladen. Sie werden hier gespeichert und warten darauf, dass der Dateinter sie zur Erstellung des ML-Modells verwendet. Dafür gibt es DataService - einen in Python geschriebenen Dienst, der das gRPC-Protokoll verwendet. Sie können damit Datensätze und ihre Metadaten (Arten von Features, ihre Beschreibung, Datensatzgröße usw.) abrufen, Prognosen laden und entladen sowie Filter- und Divisionsparameter per Zug / Test verwalten. Prognosen in der Datenbank werden im JSON-Format gespeichert, sodass Sie schnell Daten empfangen und nicht nur den Prognosewert, sondern auch den Einfluss der einzelnen Funktionen auf diese bestimmte Prognose speichern können.
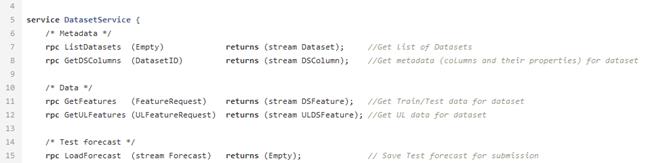
Beispielprotodatei für den Datendienst.
Wenn das Modell erstellt wird, sollte es gespeichert werden. Zu diesem Zweck wird ein ModelService verwendet, der ebenfalls in Python mit gRPC geschrieben wurde. Die Funktionen dieses Dienstes beschränken sich nicht nur auf das Speichern und Laden eines Modells. Darüber hinaus können Sie Metriken und die Bedeutung von Features überwachen und eine Modell + Dataset-Verbindung für die anschließende automatische Erstellung einer Prognose implementieren, wenn neue Daten angezeigt werden.

So sieht die Struktur unseres Modellservices aus.
2.3 ML-Modell
Zu einem bestimmten Zeitpunkt erkannte unser Team, dass die Automatisierung auch die Erstellung von ML-Modellen beeinflussen sollte. Dieser Bedarf wurde durch die Notwendigkeit getrieben, den Prozess der Erstellung von Prognosen und des Testens von Hypothesen zu beschleunigen. Und wir haben uns entschieden, eine eigene AutoML-Bibliothek zu entwickeln und in unsere Pipeline zu implementieren.
Ursprünglich wurde die Möglichkeit in Betracht gezogen, vorgefertigte AutoML-Bibliotheken zu verwenden, aber die vorhandenen Lösungen erwiesen sich als nicht flexibel genug für unsere Aufgabe und verfügten nicht über alle erforderlichen Funktionen auf einmal (auf Anfrage der Mitarbeiter können wir einen separaten Artikel über unsere AutoML schreiben). Wir stellen nur fest, dass das von uns entwickelte Framework Klassen enthält, die zum Vorverarbeiten eines Datasets, Generieren und Auswählen von Features verwendet werden. Als Modelle für maschinelles Lernen verwenden wir eine Reihe vertrauter Algorithmen, die wir bisher am erfolgreichsten eingesetzt haben: Implementierungen von Gradienten-Boosting aus den xgboost-Bibliotheken, Catboost, einer zufälligen Gesamtstruktur von Sklearn, einem vollständig verbundenen neuronalen Netzwerk auf Pytorch usw. Nach dem Training gibt AutoML eine Sklearn-Pipeline zurück, die Folgendes enthält die genannten Klassen sowie das ML-Modell,Dies zeigte das beste Ergebnis bei der Kreuzvalidierung für die ausgewählte Metrik.
Zusätzlich zum Modell wird ein Bericht über den Einfluss von Anzeichen auf eine bestimmte Prognose erstellt. Ein solcher Bericht ermöglicht es Geologen, unter die Haube einer mysteriösen Black Box zu schauen. Somit empfängt AutoML das markierte Dataset mithilfe des DataService und bildet nach dem Training das endgültige Modell. Als Nächstes können wir die endgültige Schätzung der Qualität des Modells erhalten, indem wir den Testdatensatz laden, Prognosen erstellen und Qualitätsmetriken berechnen. In der letzten Phase wird eine Binärdatei des generierten Modells, seiner Beschreibung und Metriken in den ModelService hochgeladen, während die Prognosen und Informationen zum Einfluss von Features an den DataService zurückgegeben werden.
Unser Modell befindet sich also in einem Reagenzglas und kann sofort in das Produkt eingeführt werden. Wir können es jederzeit verwenden, um Prognosen basierend auf neuen, relevanten Daten zu erstellen.
2.4 Schnittstelle
Der Endbenutzer unseres Produkts ist ein Geologe, und er muss irgendwie mit dem ML-Modell interagieren. Der bequemste Weg für ihn ist ein Modul in spezialisierter Software. Wir haben es umgesetzt.
Das Frontend, das unserem Benutzer zur Verfügung steht, sieht aus wie ein Online-Shop: Sie können das gewünschte Feld auswählen und eine Liste der wahrscheinlich erfolgreichsten Wells erhalten. In der Bohrlochkarte sieht der Benutzer das vorhergesagte Wachstum nach dem hydraulischen Brechen und entscheidet selbst, ob er es dem "Korb" hinzufügen und genauer betrachten möchte.

Modulschnittstelle in der Anwendung.

So sieht die Brunnenkarte im Anhang aus.
Zusätzlich zu den vorhergesagten Öl- und Flüssigkeitsgewinnen kann der Benutzer auch herausfinden, welche Merkmale das vorgeschlagene Ergebnis beeinflusst haben. Die Wichtigkeit von Features wird in der Phase der Erstellung eines Modells mithilfe der Shap- Methode berechnet und dann mit DataService in die Softwareschnittstelle geladen.

Die Anwendung zeigt deutlich, welche Funktionen für Modellvorhersagen am wichtigsten waren.
Der Benutzer kann auch Analoga des interessierenden Brunnens betrachten. Die Suche nach Analoga wird clientseitig mit dem Kd-Baum- Algorithmus implementiert .
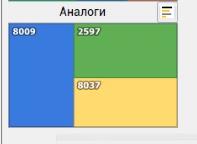
Das Modul zeigt Brunnen mit ähnlichen geologischen Parametern an.
2. WIE WIR DAS ML-MODELL VERBESSERT HABEN

Es scheint, dass es sich lohnt, AutoML für die verfügbaren Daten auszuführen, und wir werden uns freuen. Es kommt jedoch vor, dass die Qualität der automatisch erhaltenen Prognosen nicht mit den Ergebnissen von Datasintern verglichen werden kann. Tatsache ist, dass Analysten häufig verschiedene Hypothesen aufstellen und testen, um Modelle zu verbessern. Wenn die Idee die Genauigkeit der Prognose für reale Daten verbessert, wird sie in AutoML implementiert. Durch Hinzufügen neuer Funktionen haben wir die automatische Prognose so weit verbessert, dass Modelle und Prognosen mit minimaler Beteiligung von Analysten erstellt werden können. Hier sind einige Hypothesen, die in unserer AutoML getestet und implementiert wurden: 1. Ändern der Füllmethode
In den ersten Modellen haben wir fast alle Lücken in den Merkmalen mit dem Mittelwert gefüllt, mit Ausnahme der kategorialen - für sie wurde die häufigste Bedeutung verwendet. Später war es durch die gemeinsame Arbeit von Analysten und Experten im Domänenbereich möglich, die am besten geeigneten Werte auszuwählen, um die Lücken in 80% der Merkmale zu schließen. Wir haben auch einige weitere Füllmethoden unter Verwendung der Bibliotheken sklearn und missingpy ausprobiert. Die besten Ergebnisse wurden mit konstanter Füllung und KNNImputer erzielt - bis zu 5% MAPE.

Ergebnisse eines Experiments zum Füllen der Lücken mit verschiedenen Methoden.
2. Generierung von Funktionen
Das Hinzufügen neuer Funktionen ist für uns ein iterativer Prozess. Um die Modelle zu verbessern, versuchen wir, neue Funktionen hinzuzufügen, die auf den Empfehlungen eines Domain-Experten basieren, basierend auf den Erfahrungen aus wissenschaftlichen Artikeln und unseren eigenen Schlussfolgerungen aus den Daten.

Das Testen der vom Team vorgebrachten Hypothesen hilft bei der Einführung neuer Funktionen.
Eines der ersten waren die Merkmale, die anhand von Clustering identifiziert wurden. Tatsächlich haben wir einfach Cluster im Datensatz basierend auf geologischen Parametern ausgewählt und grundlegende Statistiken für andere Merkmale basierend auf Clustern erstellt - dies führte zu einer geringfügigen Qualitätssteigerung.
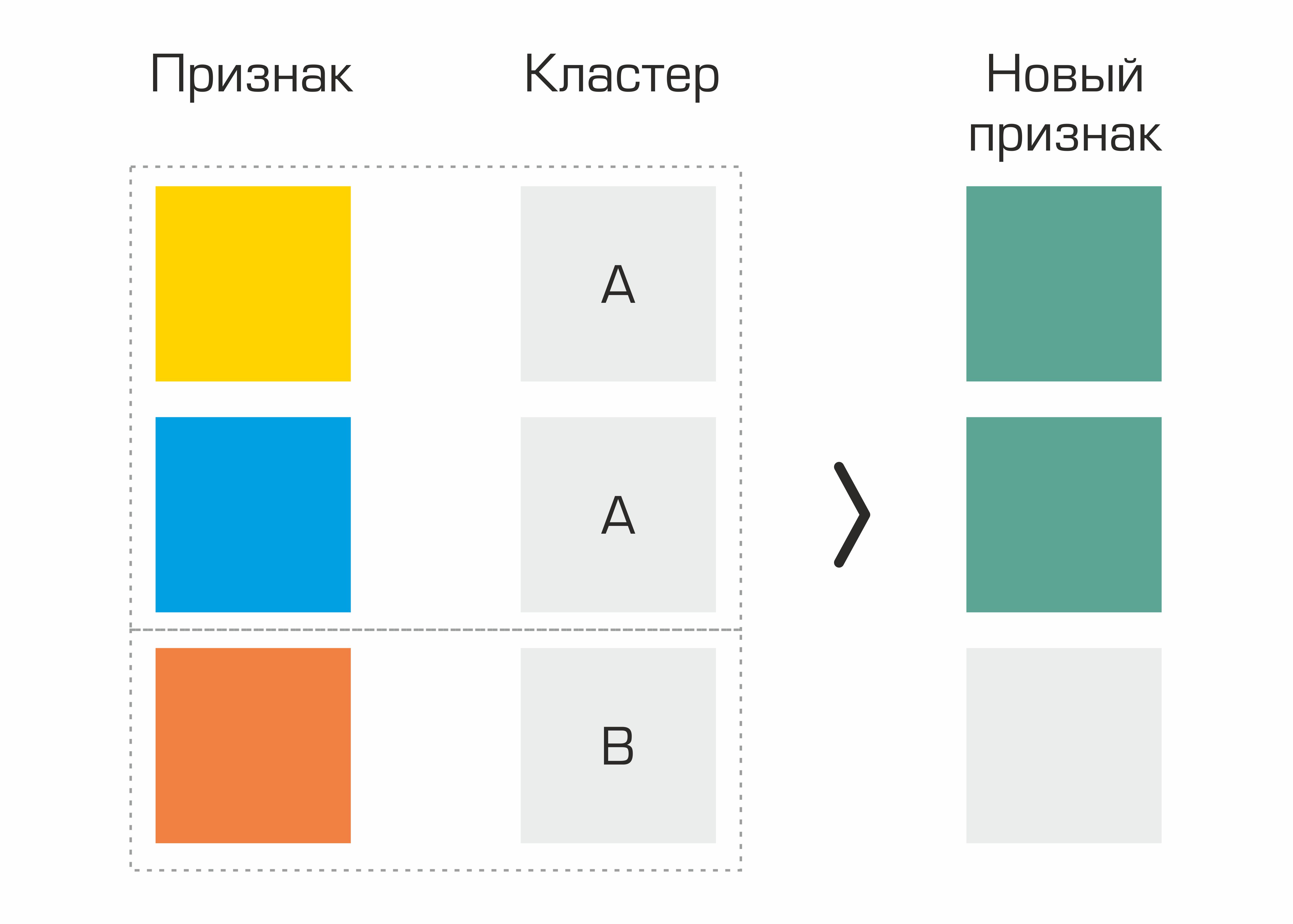
Der Prozess zum Erstellen eines Features basierend auf der Auswahl von Clustern.
Wir haben auch die Zeichen hinzugefügt, die wir erfunden haben, als wir in die Domänenregion eingetaucht waren: kumulative Ölproduktion normalisiert auf das Alter des Bohrlochs in Monaten, kumulative Injektion normalisiert auf das Alter des Bohrlochs in Monaten, Parameter in der Dupuis-Formel enthalten. Die Generierung des Standardsets aus PolynomialFeatures von sklearn hat uns jedoch nicht zu einer Qualitätssteigerung geführt.
3.
Funktionsauswahl Wir haben die Funktionsauswahl mehrmals durchgeführt: sowohl manuell zusammen mit einem Domain-Experten als auch unter Verwendung von Standardmethoden zur Funktionsauswahl. Nach mehreren Iterationen haben wir beschlossen, einige Funktionen aus den Daten zu entfernen, die das Ziel nicht beeinflussen. Auf diese Weise konnten wir die Größe des Datensatzes bei gleichbleibender Qualität reduzieren, wodurch die Erstellung von Modellen erheblich beschleunigt werden konnte.
Und nun zu den empfangenen Metriken ...
In einem der Felder haben wir die folgenden Modellqualitätsindikatoren erhalten:

Es ist zu beachten, dass das Ergebnis des hydraulischen Bruchs auch von einer Reihe externer Faktoren abhängt, die nicht vorhergesagt werden. Daher können wir nicht über die Reduzierung von MAPE auf 0 sprechen.
Fazit Die
Auswahl der Kandidatenbohrungen für das hydraulische Brechen mit ML ist ein ehrgeiziges Projekt, an dem 7 Personen teilnahmen: Dateningenieure, Datenwissenschaftler, Domänenexperten und Manager. Heute ist das Projekt tatsächlich startbereit und wird bereits bei mehreren Tochterunternehmen des Unternehmens getestet.
Das Unternehmen ist offen für Experimente, daher wurden etwa 20 Bohrlöcher aus der Liste ausgewählt und gebrochen. Die Abweichung der Prognose vom tatsächlichen Wert der Ausgangsölproduktionsrate (MAPE) betrug ca. 10%. Und das ist ein sehr gutes Ergebnis!
Seien wir nicht schlau: Insbesondere in der Anfangsphase erwiesen sich einige unserer vorgeschlagenen Bohrungen als ungeeignete Optionen.
Schreiben Sie Fragen und Kommentare - wir werden versuchen, sie zu beantworten.
Abonnieren Sie unseren Blog, wir haben viele weitere interessante Ideen und Projekte, über die wir definitiv schreiben werden!