
PostgreSQL hat sich bereits bewährt - es funktioniert hervorragend, wird von trendigen digitalen Unternehmen wie Alibaba und TripAdvisor verwendet und ist aufgrund der fehlenden Lizenzgebühren eine verlockende Alternative zu Monstern wie MS SQL oder Oracle DB. Sobald wir jedoch über PostgreSQL in einer Unternehmenslandschaft nachdenken, stoßen wir sofort auf strenge Anforderungen: „Aber was ist mit der Toleranz gegenüber Konfigurationsfehlern? Notfallwiederherstellung? Wo ist die umfassende Überwachung? Was ist mit automatisierten Backups? Was ist mit der Verwendung von Bandbibliotheken, sowohl direktem als auch sekundärem Speicher? "
Einerseits verfügt PostgreSQL nicht über integrierte Sicherungsfunktionen wie das "erwachsene" DBMS wie RMAN, Oracle DB oder SAP Database Backup. Auf der anderen Seite arbeiten die Anbieter von Unternehmenssicherungssystemen (Veeam, Veritas, Commvault), obwohl sie PostgreSQL unterstützen, tatsächlich nur mit einer bestimmten (normalerweise eigenständigen) Konfiguration und mit einer Reihe verschiedener Einschränkungen.
Sicherungssysteme, die speziell für PostgreSQL entwickelt wurden, wie Barman, Wal-g, pg_probackup, sind in kleinen PostgreSQL-Installationen oder dort, wo umfangreiche Sicherungen anderer Elemente der IT-Landschaft nicht erforderlich sind, äußerst beliebt. Zusätzlich zu PostgreSQL kann die Infrastruktur beispielsweise physische und virtuelle Server, OpenShift, Oracle, MariaDB, Cassandra usw. enthalten. All dies sollte mit einem gemeinsamen Tool gesichert werden. Es ist eine schlechte Idee, eine separate Lösung exklusiv für PostgreSQL bereitzustellen: Die Daten werden irgendwo auf die Festplatte kopiert und müssen dann auf Band entfernt werden. Diese doppelte Sicherung erhöht die Sicherungszeit und vor allem die Wiederherstellung.
In einer Unternehmenslösung wird eine Installation mit einer bestimmten Anzahl von Knoten in einem dedizierten Cluster gesichert. Gleichzeitig kann Commvault beispielsweise nur mit einem Cluster mit zwei Knoten arbeiten, in dem Primär- und Sekundärknoten bestimmten Knoten starr zugewiesen sind. Und es ist sinnvoll, nur mit Primary zu sichern, da das Sichern mit Secondary seine Grenzen hat. Aufgrund der Besonderheiten des DBMS wird auf Secondary kein Speicherauszug erstellt, sodass nur die Möglichkeit einer Dateisicherung verbleibt.
Um das Risiko von Ausfallzeiten zu verringern, wird durch das Erstellen eines fehlertoleranten Systems eine Live-Clustering-Konfiguration erstellt, und Primary kann schrittweise zwischen verschiedenen Servern migrieren. Beispielsweise startet die Patroni-Software selbst Primary auf einem zufällig ausgewählten Clusterknoten. SRK kann dies nicht sofort nachverfolgen. Wenn sich die Konfiguration ändert, werden die Prozesse unterbrochen. Das heißt, die Einführung der externen Steuerung verhindert, dass das SRK effektiv funktioniert, da der Steuerungsserver einfach nicht versteht, wo und von welchen Daten kopiert werden muss.
Ein weiteres Problem ist die Backup-Implementierung in Postgres. Es ist über Dump möglich und funktioniert auf kleinen Basen. In großen Datenbanken dauert der Speicherauszug jedoch lange, erfordert viele Ressourcen und kann zu einem Ausfall der Datenbankinstanz führen.
Die Dateisicherung korrigiert die Situation, ist jedoch in großen Datenbanken langsam, da sie im Single-Thread-Modus funktioniert. Darüber hinaus gelten für Anbieter eine Reihe zusätzlicher Einschränkungen. Entweder können Sie nicht gleichzeitig Datei- und Dump-Sicherungen verwenden, oder die Deduplizierung wird nicht unterstützt. Es gibt viele Probleme, und meistens ist es einfacher, ein teures, aber bewährtes DBMS anstelle von Postgres zu wählen.
Nirgendwo zurückziehen! Hinter Moskauer Entwicklern!
Vor kurzem stand unser Team jedoch vor einer schwierigen Herausforderung: Bei dem Projekt zur Erstellung von AIS OSAGO 2.0, bei dem wir die IT-Infrastruktur herstellten, entschieden sich die Entwickler für das neue System für PostgreSQL.
Für große Softwareentwickler ist es viel einfacher, "modische" Open-Source-Lösungen zu verwenden. Facebook hat genug Spezialisten, um die Arbeit dieses DBMS zu unterstützen. Und im Fall von PCA fielen uns alle Aufgaben des "zweiten Tages" auf die Schultern. Wir mussten Fehlertoleranz gewährleisten, einen Cluster zusammenstellen und natürlich ein Backup erstellen. Die Logik der Handlungen war wie folgt:
- Bringen Sie dem SRK bei, eine Sicherung vom Primärknoten des Clusters zu erstellen. Dazu muss das SRK es finden - was bedeutet, dass die Integration mit der einen oder anderen Lösung zur Verwaltung des PostgreSQL-Clusters erforderlich ist. Bei PCA wurde hierfür die Patroni-Software verwendet.
- Entscheiden Sie sich für die Art der Sicherung basierend auf der Datenmenge und den Wiederherstellungsanforderungen. Wenn Sie beispielsweise Seiten granular wiederherstellen müssen, verwenden Sie einen Speicherauszug. Wenn die Datenbanken groß sind und keine granulare Wiederherstellung erforderlich ist, arbeiten Sie auf Dateiebene.
- Fügen Sie der Lösung die Block-Backup-Funktion hinzu, um ein Multithread-Backup zu erstellen.
Gleichzeitig haben wir uns zunächst zum Ziel gesetzt, ein effektives und einfaches System ohne monströse Umreifung durch zusätzliche Komponenten zu schaffen. Je weniger Krücken vorhanden sind, desto geringer ist die Arbeitsbelastung des Personals und desto geringer ist das Risiko eines IBS-Ausfalls. Wir haben die Ansätze von Veeam und RMAN sofort ausgeschlossen, da zwei Lösungen bereits auf die Unzuverlässigkeit des Systems hinweisen.
Ein bisschen Magie für ein Unternehmen
Daher mussten wir eine zuverlässige Sicherung für 10 Cluster mit jeweils 3 Knoten gewährleisten, während dieselbe Infrastruktur im Sicherungsdatenzentrum gespiegelt wird. Rechenzentren im PostgreSQL-Plan arbeiten nach dem Aktiv-Passiv-Prinzip. Die Gesamtmenge der Datenbanken betrug 50 TB. Jedes SRC auf Unternehmensebene kann dies problemlos handhaben. Die Nuance ist jedoch, dass Postgres anfangs keinen Haken für eine vollständige und umfassende Kompatibilität mit Backup-Systemen hat. Daher mussten wir nach einer Lösung suchen, die in Verbindung mit PostgreSQL zunächst die maximale Funktionalität aufwies, und das System verfeinern.
Wir haben 3 interne "Hackathons" durchgeführt - wir haben uns mehr als fünfzig Entwicklungen angesehen, sie getestet, Änderungen im Zusammenhang mit unseren Hypothesen vorgenommen und sie erneut getestet. Nachdem wir die verfügbaren Optionen analysiert hatten, entschieden wir uns für Commvault. Dieses Produkt war sofort einsatzbereit und konnte mit der einfachsten PostgreSQL-Clusterinstallation verwendet werden. Die offene Architektur ließ Hoffnung auf eine erfolgreiche Verfeinerung und Integration aufkommen. Commvault kann auch PostgreSQL-Protokolle sichern. Beispielsweise kann Veritas NetBackup im PostgreSQL-Teil nur vollständige Sicherungen erstellen.
Erfahren Sie mehr über Architektur. Commvault-Verwaltungsserver wurden in jedem der beiden Rechenzentren in einer CommServ HA-Konfiguration installiert. Das System wird gespiegelt, über eine einzige Konsole verwaltet und erfüllt aus HA-Sicht alle Unternehmensanforderungen.
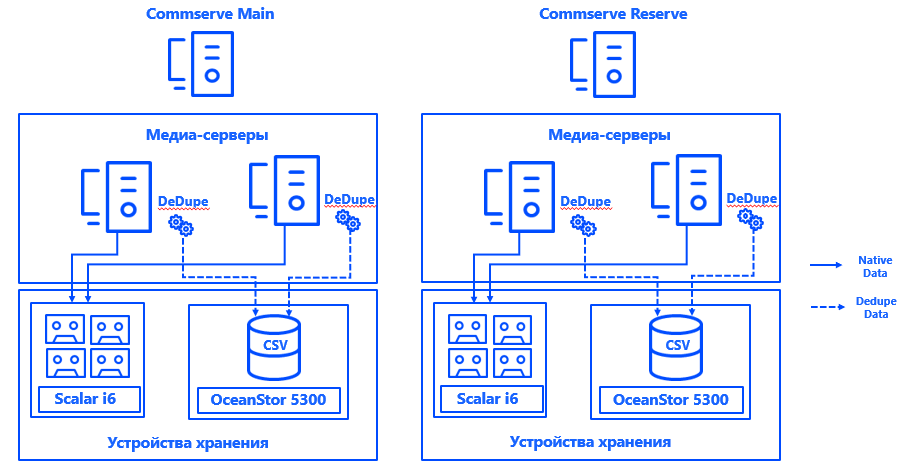
Außerdem haben wir in jedem Rechenzentrum zwei physische Medienserver gestartet, mit denen wir Festplatten-Arrays und Bandbibliotheken verbunden haben, die speziell für Backups über Fibre Channel über SAN vorgesehen sind. Ausgedehnte Deduplizierungsbasen stellten die Ausfallsicherheit der Medienserver sicher, und die Verbindung jedes Servers mit jeder CSV stellte den kontinuierlichen Betrieb bei Ausfall einer Komponente sicher. Die Architektur des Systems ermöglicht es, die Sicherung auch dann fortzusetzen, wenn eines der Rechenzentren ausfällt.
Patroni definiert für jeden Cluster einen Primärknoten. Es kann sich um einen beliebigen freien Knoten im Rechenzentrum handeln - jedoch nur im Hauptknoten. In der Sicherung sind alle Knoten sekundär.
Damit Commvault versteht, welcher Clusterknoten primär ist, haben wir das System (dank der offenen Architektur der Lösung) in Postgres integriert. Zu diesem Zweck wurde ein Skript erstellt, das den aktuellen Speicherort des Primärknotens an den Commvault-Verwaltungsserver meldet.
Im Allgemeinen sieht der Prozess folgendermaßen aus:
Patroni wählt Primär → Keepalived ruft den IP-Cluster auf und führt das Skript aus. → Der Commvault-Agent auf dem ausgewählten Knoten des Clusters erhält eine Benachrichtigung, dass es sich um Primär handelt. → Commvault konfiguriert die Sicherung innerhalb des Pseudo-Clients automatisch neu.
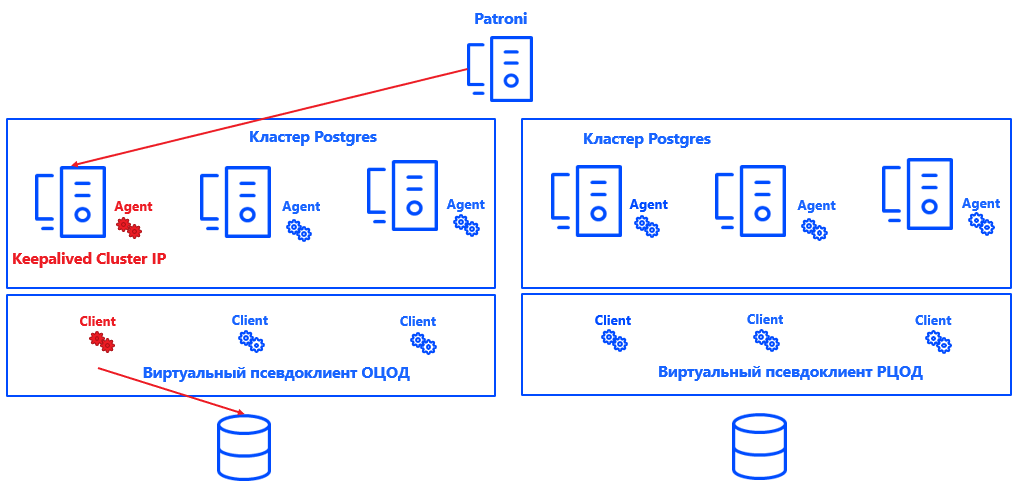
Der Vorteil dieses Ansatzes besteht darin, dass die Lösung weder die Konsistenz noch die Richtigkeit der Protokolle oder die Wiederherstellung der Postgres-Instanz beeinflusst. Es ist auch leicht skalierbar, da es jetzt nicht erforderlich ist, den primären und den sekundären Knoten für Commvault zu reparieren. Es reicht aus, dass das System versteht, wo sich Primary befindet, und die Anzahl der Knoten kann auf nahezu jeden Wert erhöht werden.
Die Lösung gibt nicht vor, ideal zu sein und hat ihre eigenen Nuancen. Commvault kann nur eine ganze Instanz sichern, nicht einzelne Datenbanken. Daher wurde für jede Datenbank eine separate Instanz erstellt. Reale Clients werden zu virtuellen Pseudo-Clients kombiniert. Jeder Commvault-Pseudo-Client ist ein UNIX-Cluster. Es werden die Clusterknoten hinzugefügt, auf denen der Commvault-Agent für Postgres installiert ist. Infolgedessen werden alle virtuellen Knoten des Pseudo-Clients als eine Instanz gesichert.
Innerhalb jedes Pseudo-Clients wird der aktive Knoten des Clusters angezeigt. Dies ist, was unsere Integrationslösung für Commvault definiert. Das Prinzip seiner Funktionsweise ist recht einfach: Wenn eine Cluster-IP auf einem Knoten ansteigt, setzt das Skript den Parameter "aktiver Knoten" in der Binärdatei des Commvault-Agenten - tatsächlich setzt das Skript "1" im erforderlichen Teil des Speichers. Der Agent sendet diese Daten an CommServe, und Commvault erstellt eine Sicherungskopie vom gewünschten Knoten. Darüber hinaus wird die Richtigkeit der Konfiguration auf Skriptebene überprüft, um Fehler beim Starten der Sicherung zu vermeiden.
Gleichzeitig werden große Datenbanken in mehreren Threads blockweise gesichert, um die Anforderungen von RPO- und Sicherungsfenstern zu erfüllen. Die Belastung des Systems ist unbedeutend: Vollkopien treten nicht so häufig auf, an anderen Tagen werden nur Protokolle in Zeiten geringer Auslastung erfasst.
Übrigens haben wir separate Richtlinien zum Sichern von archivierten PostgreSQL-Protokollen angewendet - sie werden nach unterschiedlichen Regeln gespeichert, nach einem anderen Zeitplan kopiert und die Deduplizierung ist für sie nicht aktiviert, da diese Protokolle eindeutige Daten enthalten.
Um die Konsistenz der gesamten IT-Infrastruktur sicherzustellen, werden auf jedem Clusterknoten separate Commvault-Dateiclients installiert. Sie schließen Postgres-Dateien von Sicherungen aus und sind nur für Betriebssystem- und Anwendungssicherungen vorgesehen. Dieser Teil der Daten hat auch eine eigene Richtlinie und eine eigene Speicherdauer.

Jetzt wirkt sich das SRK nicht auf die Produktivdienste aus. Wenn sich die Situation ändert, kann das Lastbegrenzungssystem in Commvault aktiviert werden.
Ist es gut? Gut!
Daher haben wir nicht nur eine funktionsfähige, sondern auch eine vollautomatische Sicherung für eine Cluster-PostgreSQL-Installation erhalten, die alle Anforderungen von Unternehmensaufrufen erfüllt.
Die RPO- und RTO-Parameter nach 1 Stunde und 2 Stunden überlappen sich mit einem Spielraum, was bedeutet, dass das System sie auch bei einer signifikanten Zunahme des Volumens gespeicherter Daten anpasst. Trotz vieler Zweifel sind PostgreSQL und die Unternehmensumgebung durchaus kompatibel. Und jetzt wissen wir aus eigener Erfahrung, dass ein Backup für ein solches DBMS in einer Vielzahl von Konfigurationen möglich ist.
Natürlich mussten wir auf dem Weg sieben Paar Eisenstiefel tragen, eine Reihe von Schwierigkeiten überwinden, auf ein paar Rechen treten und eine Reihe von Fehlern korrigieren. Aber jetzt wurde der Ansatz bereits getestet und kann verwendet werden, um Open Source anstelle von proprietärem DBMS in der rauen Unternehmensumgebung zu implementieren.
Haben Sie PostgreSQL in einer Unternehmensumgebung ausprobiert?
Autoren:
Oleg Lavrenov, Konstrukteur von Jet Infosystems-Datenspeichersystemen
Dmitry Erykin, Konstrukteur von Jet Infosystems-Computersystemen