Wir bei Lyft haben beschlossen, unsere Serverinfrastruktur auf Kubernetes, ein verteiltes Container-Orchestrierungssystem, zu verlagern, um die Vorteile der Automatisierung zu nutzen. Sie wollten eine solide und zuverlässige Plattform, die die Grundlage für die weitere Entwicklung bilden, die Gesamtkosten senken und gleichzeitig die Effizienz steigern kann.
Verteilte Systeme können schwierig zu verstehen und zu analysieren sein, und Kubernetes ist in dieser Hinsicht keine Ausnahme. Trotz der vielen Vorteile haben wir bei der Umstellung auf CronJob , ein in Kubernetes integriertes System zur Ausführung sich wiederholender Aufgaben nach Zeitplan , mehrere Engpässe festgestellt . In dieser zweiteiligen Serie werden wir die technischen und betrieblichen Nachteile von Kubernetes CronJob bei der Verwendung in einem großen Projekt erörtern und unsere Erfahrungen mit deren Überwindung mit Ihnen teilen.
Zunächst werden wir die Mängel von Kubernetes CronJobs beschreiben, auf die wir bei der Verwendung in Lyft gestoßen sind. Dann (im zweiten Teil) werden wir Ihnen erklären, wie wir diese Mängel im Kubernetes-Stack beseitigt, die Benutzerfreundlichkeit erhöht und die Zuverlässigkeit verbessert haben.
Teil 1. Einführung
Wer wird von diesen Artikeln profitieren?
- Kubernetes CronJob Benutzer.
- , Kubernetes.
- , Kubernetes .
- , Kubernetes , .
- Contributor' Kubernetes.
?
- , Kubernetes ( , CronJob) .
- , Kubernetes Lyft , .
:
- cron'.
- , CronJob, — , CronJob, Job' Pod', . CronJob Unix cron' .
- sidecar- , . Lyft sidecar- , runtime- Envoy, statsd .., sidecar-, , .
- ronjobcontroller — Kubernetes, CronJob'.
- , cron , ( ).
- Lyft Engineering , ( «», « », « ») — Lyft ( «», « », «» «»). , , «-» .
CronJob' Lyft
In unserer mandantenfähigen Produktionsumgebung werden heute fast 500 Cron-Jobs mehr als 1500 Mal pro Stunde ausgeführt.
Wiederkehrende geplante Aufgaben werden in Lyft häufig für verschiedene Zwecke verwendet. Bevor sie zu Kubernetes wechselten, liefen sie mit regulären Unix-Cron direkt auf Linux-Computern. Die Entwicklungsteams waren für das Schreiben von
crontabDefinitionen und das Bereitstellen der Instanzen verantwortlich, die sie mithilfe der IaC-Pipelines ( Infrastructure As Code) ausführten, und das Infrastrukturteam war für deren Wartung verantwortlich.
Im Rahmen größerer Anstrengungen zur Containerisierung und Migration von Workloads auf unsere eigene Kubernetes-Plattform haben wir uns für CronJob * entschieden und das klassische Unix-Cron durch das Kubernetes-Gegenstück ersetzt. Wie viele andere wurde Kubernetes aufgrund seiner enormen Vorteile (zumindest theoretisch) ausgewählt, einschließlich seines effizienten Ressourceneinsatzes.
Stellen Sie sich eine Cron-Aufgabe vor, die 15 Minuten lang einmal pro Woche ausgeführt wird. In unserer alten Umgebung war die für diese Aufgabe vorgesehene Maschine in 99,85% der Fälle im Leerlauf. Bei Kubernetes werden Rechenressourcen (CPU, Speicher) nur während eines Aufrufs verwendet. In der restlichen Zeit können die nicht genutzten Kapazitäten verwendet werden, um andere CronJobs zu starten oder einfach zu verkleinernCluster. Angesichts der bisherigen Art, Cron-Jobs auszuführen, würden wir viel davon profitieren, zu einem Modell überzugehen, bei dem Jobs kurzlebig sind.

Verantwortungsgrenzen für Entwickler und Plattformingenieure im Lyft-Stack
Nach dem Wechsel zur Kubernetes-Plattform haben die Entwicklungsteams die Zuweisung und den Betrieb ihrer eigenen Recheninstanzen eingestellt. Das Plattformteam ist jetzt für die Verwaltung und den Betrieb von Rechenressourcen und Laufzeitabhängigkeiten im Kubernetes-Stack verantwortlich. Darüber hinaus ist sie für die Erstellung der CronJob-Objekte selbst verantwortlich. Entwickler müssen nur den Aufgabenplan und den Anwendungscode konfigurieren.
Auf dem Papier sieht es jedoch alles gut aus. In der Praxis haben wir mehrere Engpässe bei der Migration von einer gut untersuchten traditionellen Unix-Cron-Umgebung zu einer verteilten, kurzlebigen CronJob-Umgebung in Kubernetes festgestellt.
* Obwohl sich CronJob (ab Kubernetes v1.18) im Beta-Status befand und befindet, haben wir festgestellt, dass es unseren damaligen Anforderungen sehr gerecht wurde und auch perfekt zu dem Rest des Kubernetes-Infrastruktur-Toolkits passte, das wir hatten. ...
Was ist der Unterschied zwischen Kubernetes CronJob und Unix Cron?
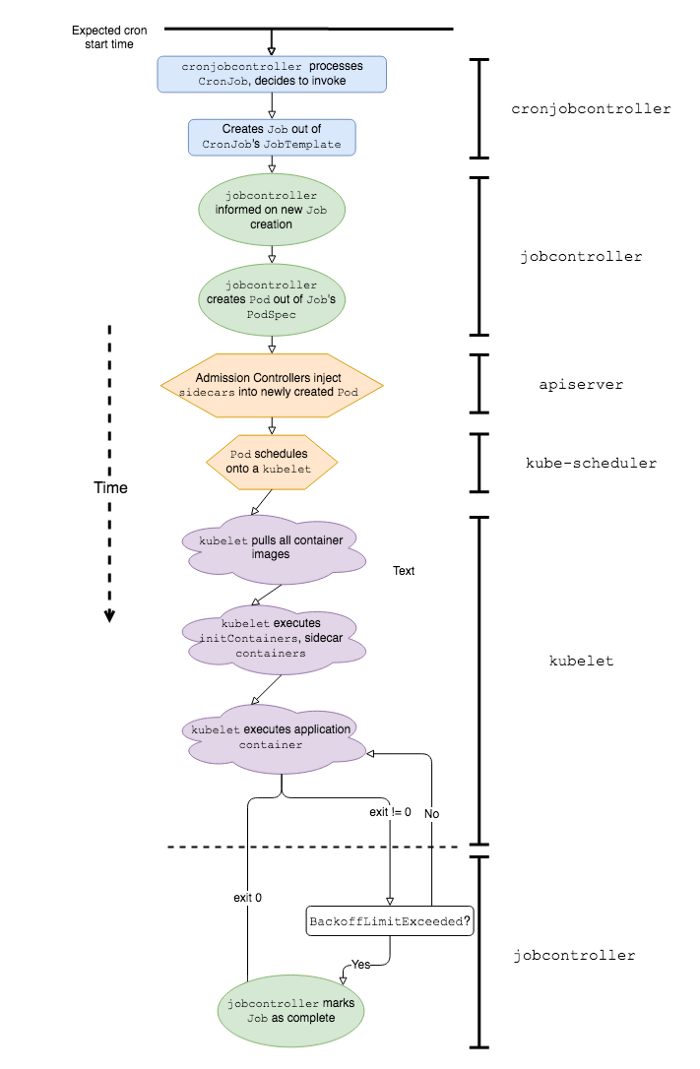
Vereinfachte Abfolge von Ereignissen und K8s-Softwarekomponenten, die an der Arbeit von Kubernetes CronJob beteiligt sind
Um besser zu erklären, warum die Arbeit mit Kubernetes CronJob in einer Produktionsumgebung mit bestimmten Schwierigkeiten verbunden ist, definieren wir zunächst, wie sie sich vom Klassiker unterscheiden. Es wird erwartet, dass CronJob genauso funktioniert wie Cron-Jobs unter Linux oder Unix. Tatsächlich gibt es jedoch zumindest einige wesentliche Unterschiede in ihrem Verhalten: Startgeschwindigkeit und Crash-Behandlung .
Startgeschwindigkeit
Verzögerungsstart (Startverzögerung) ist definiert als die Zeit, die vom geplanten Start bis zum tatsächlichen Beginn des Anwendungscodes vergangen ist. Mit anderen Worten, wenn der Start des Cron um 00:00:00 Uhr geplant ist und die Anwendung um 00:00:22 Uhr gestartet wird, beträgt die Verzögerung beim Starten dieses bestimmten Cron 22 Sekunden.
Bei klassischen Unix-Crones ist die Startverzögerung minimal. Wenn die Zeit reif ist, werden diese Befehle einfach ausgeführt. Bestätigen wir dies mit folgendem Beispiel:
# date
0 0 * * * date >> date-cron.log
Bei einer solchen Cron-Konfiguration erhalten wir höchstwahrscheinlich die folgende Ausgabe in
date-cron.log:
Mon Jun 22 00:00:00 PDT 2020
Tue Jun 23 00:00:00 PDT 2020
…
Auf der anderen Seite kann es bei Kubernetes CronJob zu erheblichen Startverzögerungen kommen, da der Anwendung eine Reihe von Ereignissen vorausgeht. Hier sind einige davon:
-
cronjobcontrollerverarbeitet und beschließt, den CronJob aufzurufen; -
cronjobcontrollererstellt einen Job basierend auf der CronJob-Jobspezifikation; -
jobcontrollerbemerkt einen neuen Job und erstellt einen Pod; - Admission Controller fügt Seitenwagencontainerdaten in die Pod-Spezifikation * ein;
-
kube-schedulerPlanung eines Pods auf Kubelet; -
kubeletstartet Pod (Abrufen aller Container-Bilder); -
kubeletstartet alle Beiwagencontainer *; -
kubeletStartet den Anwendungscontainer *.
* Diese Stufen gelten nur für den Lyft Kubernetes-Stack.
Wir haben festgestellt, dass die Punkte 1, 5 und 7 den größten Beitrag zur Latenz leisten, sobald wir eine bestimmte CronJob-Skala in der Kubernetes-Umgebung erreichen.
Arbeitsbedingte Verzögerung cronjobcontroller'
Um besser zu verstehen, woher die Latenz kommt, untersuchen wir den Inline-Quellcode
cronjobcontroller'. In Kubernetes 1.18 werden cronjobcontrollernur alle 10 Sekunden alle CronJobs überprüft und auf jedem eine Logik ausgeführt .
Die Implementierung
cronjobcontroller'führt dies synchron durch, indem für jeden CronJob mindestens ein zusätzlicher API-Aufruf ausgeführt wird. Wenn die Anzahl von CronJob eine bestimmte Anzahl überschreitet, leiden diese API-Aufrufe unter clientseitigen Einschränkungen .
Der 10-Sekunden-Abfragezyklus und clientseitige API-Aufrufe erhöhen die Verzögerung beim Start von CronJob erheblich.
Planen von Pods mit Cron
Aufgrund der Art des Cron-Zeitplans werden die meisten von ihnen zu Beginn der Minute ausgeführt (XX: YY: 00). Zum Beispiel
@hourlyläuft der (stündliche) Cron um 01:00:00, 02:00:00 usw. Bei einer mandantenfähigen Cron-Plattform mit vielen Crones, die jede Stunde, jede Viertelstunde, alle 5 Minuten usw. ausgeführt werden, führt dies zu Engpässen (Hotspots), wenn mehrere Cron gestartet werden gleichzeitig. Wir bei Lyft haben festgestellt, dass ein solcher Ort der Beginn der Stunde ist (XX: 00: 00). Diese Hotspots erzeugen eine Last und führen zu einer zusätzlichen Begrenzung der Häufigkeit von Anforderungen in den Steuerschichtkomponenten, die an der Ausführung des CronJob beteiligt sind, wie z. B. kube-schedulerund kube-apiserver, was zu einer spürbaren Erhöhung der Startverzögerung führt.
Wenn Sie keine Verarbeitungsleistung für Spitzenlasten bereitstellen (und / oder Recheninstanzen des Cloud-Dienstes verwenden) und stattdessen den Cluster-Autoscaling-Mechanismus zum dynamischen Skalieren von Knoten verwenden, trägt die zum Starten von Knoten benötigte Zeit zusätzlich zur Startlatenz bei. Hülsen CronJob.
Pod-Start: Helfer-Container
Sobald der CronJob-Pod erfolgreich geplant wurde
kubelet, sollte dieser Container-Images aller Sidecars und der Anwendung selbst abrufen und ausführen. Aufgrund der Besonderheiten beim Starten von Containern in Lyft (Startwagencontainer starten vor Anwendungscontainern) wirkt sich die Verzögerung beim Starten eines Beiwagens zwangsläufig auf das Ergebnis aus, was zu einer zusätzlichen Verzögerung beim Starten der Aufgabe führt.
Verzögerungen beim Start vor der Ausführung des erforderlichen Anwendungscodes führen in Verbindung mit einer großen Anzahl von CronJobs in einer Umgebung mit mehreren Mandanten zu spürbaren und unvorhersehbaren Startverzögerungen. Wie wir etwas später sehen werden, kann eine solche Verzögerung im wirklichen Leben das Verhalten des CronJob negativ beeinflussen und drohen, Starts zu verpassen.
Behandlung von Containerunfällen
Im Allgemeinen wird empfohlen, die Arbeit von Cron im Auge zu behalten. Für Unix-Systeme ist dies ziemlich einfach. Unix-Crones interpretieren den angegebenen Befehl mithilfe der angegebenen Shell
$SHELL. Nach dem Beenden des Befehls (erfolgreich oder nicht) wird dieser bestimmte Aufruf als abgeschlossen betrachtet. Sie können die Ausführung eines Cron unter Unix mit einem einfachen Skript wie dem folgenden verfolgen:
#!/bin/sh
my-cron-command
exitcode=$?
if [[ $exitcode -ne 0 ]]; then
# stat-and-log is pseudocode for emitting metrics and logs
stat-and-log "failure"
else
stat-and-log "success"
fi
exit $exitcode
Unter Unix wird cron
stat-and-logbei jedem cron-Aufruf genau einmal ausgeführt - unabhängig davon $exitcode. Daher können diese Metriken verwendet werden, um die einfachsten Benachrichtigungen über nicht erfolgreiche Anrufe zu organisieren.
Im Fall von CronJob Kubernetes, bei dem standardmäßig Wiederholungsversuche bei Fehlern definiert sind und der Fehler selbst aus verschiedenen Gründen (Jobfehler oder Containerfehler) verursacht werden kann, ist die Überwachung nicht so einfach und unkompliziert.
Mithilfe eines ähnlichen Skripts im Anwendungscontainer und mit Jobs, die so konfiguriert sind, dass sie bei einem Fehler neu gestartet werden, versucht CronJob, die Aufgabe bei einem Fehler auszuführen und dabei Metriken und Protokolle zu generieren, bis BackoffLimit erreicht ist(max. Anzahl der Wiederholungen). Daher muss ein Entwickler, der versucht, die Ursache eines Problems zu ermitteln, eine Menge unnötigen "Mülls" aussortieren. Darüber hinaus kann sich die Warnung aus dem Shell-Skript als Reaktion auf den ersten Fehler als normales Rauschen herausstellen, auf das sich keine weiteren Aktionen stützen können, da der Anwendungscontainer die Aufgabe selbst wiederherstellen und erfolgreich abschließen kann.
Sie können Warnungen auf Jobebene und nicht auf Anwendungscontainerebene implementieren. Hierzu stehen Metriken auf API-Ebene für Jobfehler zur Verfügung, z. B.
kube_job_status_failedvon kube-state-metrics. Der Nachteil dieses Ansatzes besteht darin, dass der diensthabende Ingenieur erst dann auf das Problem aufmerksam wird, wenn der Job die „endgültige Fehlerphase“ erreicht und die Grenze erreicht BackoffLimit, die viel später als der erste Fehler des Anwendungscontainers auftreten kann.
CronJob'
Eine erhebliche Startverzögerung und Neustartzyklen führen zu einer zusätzlichen Latenz, die verhindern kann, dass Kubernetes CronJob erneut ausgeführt wird. Bei CronJobs, die häufig aufgerufen werden oder deren Laufzeit erheblich länger als die Leerlaufzeit ist, kann diese zusätzliche Verzögerung Probleme beim nächsten geplanten Anruf verursachen. Wenn der CronJob über eine Richtlinie verfügt
ConcurrencyPolicy: Forbid, die die Parallelität verbietet , führt die Verzögerung dazu, dass zukünftige Anrufe nicht rechtzeitig und verzögert abgeschlossen werden.

Ein Beispiel für eine Zeitleiste (aus Sicht eines Cronjob-Controllers), in der startDeadlineSeconds für einen bestimmten stündlichen CronJob überschritten wird: Sie überspringt ihren geplanten Start und wird erst zum nächsten geplanten Zeitpunkt aufgerufen
Es gibt auch ein unangenehmeres Szenario (wir sind in Lyft darauf gestoßen), aufgrund dessen CronJobs Anrufe vollständig überspringen können. Dies ist der Zeitpunkt, an dem CronJob installiert ist
startingDeadlineSeconds. Wenn in diesem Szenario die Startverzögerung überschritten startingDeadlineSecondswird, überspringt der CronJob den Start vollständig.
Wenn
ConcurrencyPolicyCronJob auf eingestellt ist, Forbidkann der Neustart-bei-Fehler-Zyklus des vorherigen Aufrufs auch den nächsten CronJob-Aufruf stören.
Probleme beim Betrieb von Kubernetes CronJob unter realen Bedingungen
Seit wir begonnen haben, sich wiederholende Kalenderaufgaben nach Kubernetes zu migrieren, hat sich herausgestellt, dass die unveränderte Verwendung des CronJob-Mechanismus sowohl aus Sicht des Entwicklers als auch aus Sicht des Plattformteams zu unangenehmen Momenten führt. Leider haben sie begonnen, die Vorteile und Vorteile, für die wir uns ursprünglich für Kubernetes CronJob entschieden haben, zu negieren. Wir stellten schnell fest, dass weder die Entwickler noch das Plattformteam über die erforderlichen Tools verfügten, um CronJobs zu nutzen und ihre komplizierten Lebenszyklen zu verstehen.
Die Entwickler haben versucht, ihren CronJob auszunutzen und zu konfigurieren, aber als Ergebnis kamen sie mit vielen Beschwerden und Fragen wie diesen zu uns :
- Warum funktioniert mein Cron nicht?
- Es sieht so aus, als hätte mein Cron aufgehört zu arbeiten. Wie können Sie bestätigen, dass es tatsächlich ausgeführt wird?
- Ich wusste nicht, dass Cron nicht funktioniert und ich fand alles in Ordnung.
- Wie "repariere" ich einen fehlenden Cron? Ich kann mich nicht einfach per SSH anmelden und den Befehl selbst ausführen.
- Können Sie sagen, warum dieser Cron mehrere Läufe zwischen X und Y verpasst zu haben scheint?
- Wir haben X (große Anzahl) Crones, jedes mit seinen eigenen Benachrichtigungen, und es wird ziemlich mühsam / schwierig, alle zu warten.
- Pod, Job, Beiwagen - was für ein Unsinn ist das?
Als Plattformteam konnten wir folgende Fragen nicht beantworten:
- Wie kann die Leistung der Kubernetes-Cron-Plattform quantifiziert werden?
- Wie wirkt sich das Aktivieren zusätzlicher CronJobs auf unsere Kubernetes-Umgebung aus?
- Kubernetes CronJob' ( multi-tenant) single-tenant cron' Unix?
- Service-Level-Objectives (SLOs — ) ?
- , , , ?
Das Debuggen von CronJob-Abstürzen ist keine leichte Aufgabe. Es braucht oft Intuition, um zu verstehen, wo Fehler auftreten und wo nach Beweisen gesucht werden muss. Manchmal ist es ziemlich schwierig, diese Hinweise zu erhalten - wie zum Beispiel Protokolle
cronjobcontroller', die nur aufgezeichnet werden, wenn der hohe Detaillierungsgrad aktiviert ist. Zusätzlich können Spuren einfach nach einer gewissen Zeit verschwinden, die „Kick einen Maulwurf“ , um das Spiel Debuggen ähnlich macht (etwa das -.. Ca. Transl) - zum Beispiel, Kubernetes Events für CronJob'ov, Job'ov und Pod'ov die standardmäßig nur eine Stunde lang aufbewahrt werden. Keine dieser Methoden ist einfach zu verwenden, und keine von ihnen lässt sich hinsichtlich der Unterstützung gut skalieren, wenn die Anzahl der CronJobs auf der Plattform zunimmt.
Auch manchmal nur Kubernetesbeendet den Versuch, den CronJob auszuführen, wenn zu viele Läufe verpasst wurden. In diesem Fall muss es manuell neu gestartet werden. Im wirklichen Leben passiert dies viel häufiger, als Sie sich vorstellen können, und die Notwendigkeit, das Problem jedes Mal manuell zu beheben, wird ziemlich schmerzhaft.
Dies schließt meinen Einblick in die technischen und betrieblichen Probleme, die bei der Verwendung von Kubernetes CronJob in einem geschäftigen Projekt aufgetreten sind. Im zweiten Teil werden wir darüber sprechen, wie wir Kubernetes in unserem Stack eliminiert, die Benutzerfreundlichkeit verbessert und die Zuverlässigkeit von CronJob verbessert haben.
Teil 2. Einführung
Es wurde klar, dass Kubernetes CronJob unverändert kein einfacher und bequemer Ersatz für ihre Unix-Gegenstücke sein kann. Um alle unsere Crones sicher auf Kubernetes zu übertragen, mussten wir nicht nur die technischen Mängel von CronJob beseitigen, sondern auch deren Benutzerfreundlichkeit verbessern . Nämlich:
1. Hören Sie den Entwicklern zu, um die Antworten auf die Fragen zu Alten zu verstehen, über die sie sich am meisten Sorgen machen. Zum Beispiel: Hat mein Cron angefangen? Wurde der Anwendungscode ausgeführt? War der Start erfolgreich? Wie lange lief der Cron? (Wie lange hat der Anwendungscode gedauert ?)
2. Vereinfachen Sie die Plattformwartung, indem Sie CronJobs verständlicher, ihren Lebenszyklus transparenter und die Grenzen zwischen Plattform und Anwendung klarer gestalten.
3. Ergänzen Sie unsere Plattform mit Standardmetriken und Warnungen, um die Anzahl der benutzerdefinierten Warnungskonfigurationen zu verringern und die Anzahl der doppelten Cron-Bindungen zu verringern, die Entwickler schreiben und verwalten müssen.
4. Entwickeln Sie Tools für die einfache Wiederherstellung nach einem Absturz und testen Sie neue CronJob-Konfigurationen.
5. Beheben Sie langjährige technische Probleme in Kubernetes , z. B. einen TooManyMissedStarts-Fehler , für dessen Behebung manuelle Eingriffe erforderlich sind und der in einem kritischen Fehlerszenario ( wenn das Starten von DeadlineSeconds nicht festgelegt ist ) einen Absturz verursacht , der unbemerkt bleibt.
Entscheidung
Wir haben alle diese Probleme wie folgt gelöst:
- (observability). CronJob', (Service Level Objectives, SLOs) .
- CronJob' « » Kubernetes.
- Kubernetes.
CronJob'

Ein Beispiel für ein Dashboard, das von der Plattform zur Überwachung eines bestimmten CronJob generiert wurde
Wir haben dem Kubernetes-Stack die folgenden Metriken hinzugefügt (sie sind für alle CronJob in Lyft definiert):
1.
started.count- Dieser Zähler wird erhöht, wenn der Anwendungscontainer beim ersten Aufruf des CronJob zum ersten Mal gestartet wird. Es hilft bei der Beantwortung der Frage: „ Wurde der Anwendungscode ausgeführt? ".
2.
{success, failure}.count- Diese Zähler werden erhöht, wenn ein bestimmter CronJob-Aufruf den Terminalstatus erreicht ( dh der Job hat seinen Job beendet und jobcontrollerversucht nicht mehr, ihn auszuführen). Sie beantworten die Frage: „ War der Start erfolgreich? ".
3.
scheduling-decision.{invoke, skip}.count- diese ZählerHier können Sie sich über die Entscheidungen cronjobcontrollerinformieren , die beim Aufruf des CronJob getroffen werden. Insbesondere skip.counthilft es, die Frage zu beantworten: „ Warum funktioniert mein Cron nicht? ". Die folgenden Bezeichnungen dienen als Parameter reason:
-
reason = concurrencyPolicy-cronjobcontrollerden Anruf bei CronJob verpasst hat, weil er sonst unterbrochen würdeConcurrencyPolicy; -
reason = missedDeadline- sichcronjobcontrollergeweigert hat, CronJob anzurufen, weil das angegebene Anruffenster verfehlt wurde.spec.startingDeadlineSeconds; -
reason = errorIst ein allgemeiner Parameter für alle anderen Fehler, die beim Aufrufen eines CronJob auftreten.
4.
app-container-duration.seconds- Dieser Timer misst die Lebensdauer des Anwendungscontainers. Es hilft bei der Beantwortung der Frage: „ Wie lange lief der Anwendungscode? ". In diesem Timer haben wir bewusst nicht die Zeit berücksichtigt, die für die Pod-Planung, das Starten von Beiwagencontainern usw. erforderlich ist, da diese in der Verantwortung des Plattformteams liegen und in der Startverzögerung enthalten sind.
5.
start-delay.seconds- Dieser Timer misst die Startverzögerung. Wenn diese Metrik plattformübergreifend aggregiert wird, können Ingenieure, die sie verwalten, nicht nur die Plattformleistung bewerten, überwachen und optimieren, sondern auch als Grundlage für die Bestimmung von SLOs für Parameter wie Startverzögerung und maximale Cron-Zeitplanhäufigkeit dienen.
Basierend auf diesen Metriken haben wir Standardwarnungen erstellt. Sie benachrichtigen Entwickler, wenn:
- Ihr CronJob startete nicht planmäßig (
rate(scheduling-decision.skip.count) > 0); - Ihr CronJob ist fehlgeschlagen (
rate(failure.count) > 0).
Entwickler müssen in Kubernetes keine eigenen Warnungen und Metriken mehr für Crones definieren - die Plattform bietet ihre vorgefertigten Gegenstücke.
Cons laufen lassen, wenn nötig
Wir haben es
kubectl create job test-job --from=cronjob/<your-cronjob>an unser internes CLI-Tool angepasst . Die Ingenieure von Lyft verwenden es, um mit ihren Diensten auf Kubernetes zu interagieren und CronJob bei Bedarf anzurufen, um:
- Wiederherstellung nach zeitweiligen CronJob-Abstürzen;
- runtime- , 3:00 ( , CronJob', Job' Pod' ), — , ;
- runtime- CronJob' Unix cron', , .
TooManyMissedStarts
Wir haben einen Fehler mit TooManyMissedStarts behoben, sodass CronJobs jetzt nach 100 aufeinanderfolgenden Fehlstarts nicht "hängen bleiben". Dieser Patch macht nicht nur manuelle Eingriffe überflüssig, sondern ermöglicht es Ihnen auch, tatsächlich zu verfolgen, wann die Zeit
startingDeadlineSeconds überschritten wird . Dank an Vallery Lancey für das Entwerfen und Erstellen dieses Patches, Tom Wanielista für die Unterstützung beim Entwerfen des Algorithmus. Wir haben eine PR geöffnet , um diesen Patch in die Hauptniederlassung von Kubernetes zu bringen (er wurde jedoch nie übernommen und wegen Inaktivität geschlossen - ca. übersetzt) .
Implementierung der Cron-Überwachung

In welchen Phasen des Lebenszyklus von Kubernetes CronJob haben wir Exportmechanismen für Metriken hinzugefügt
Warnungen, die nicht von Cron-Zeitplänen abhängen
Der schwierigste Teil bei der Implementierung von Benachrichtigungen über verpasste Cron- Anrufe ist die Verwaltung ihrer Zeitpläne ( crontab.guru hat sich als nützlich erwiesen , um sie zu entschlüsseln ). Betrachten Sie beispielsweise den folgenden Zeitplan:
# 5
*/5 * * * *
Sie können den Zähler für dieses Cron-Inkrement bei jedem Beenden festlegen (oder eine Cron-Bindung verwenden ). Anschließend können Sie im Benachrichtigungssystem einen bedingten Ausdruck des Formulars schreiben: "Sehen Sie sich die letzten 60 Minuten an und lassen Sie mich wissen, ob sich der Zähler um weniger als 12 erhöht." Problem gelöst, oder?
Aber was ist, wenn Ihr Zeitplan so aussieht:
# 9 17
# .
# , (9-17, -)
0 9–17 * * 1–5
In diesem Fall müssen Sie an der Bedingung basteln (obwohl Ihr System möglicherweise nur für Geschäftszeiten eine Benachrichtigungsfunktion hat?). Wie dem auch sei, diese Beispiele veranschaulichen, dass das Binden von Benachrichtigungen an Cron-Zeitpläne mehrere Nachteile hat:
- Wenn Sie den Zeitplan ändern, müssen Sie Änderungen an der Benachrichtigungslogik vornehmen.
- Einige Cron-Zeitpläne erfordern recht komplexe Abfragen, um mithilfe von Zeitreihen zu replizieren.
- Es muss eine Art "Wartezeit" für alte Menschen geben, die ihre Arbeit nicht rechtzeitig beginnen, um Fehlalarme zu minimieren.
Schritt 2 allein macht das Generieren von Benachrichtigungen standardmäßig für alle Crones auf der Plattform zu einer sehr schwierigen Aufgabe, und Schritt 3 ist besonders relevant für verteilte Plattformen wie Kubernetes CronJob, bei denen die Startverzögerung ein wesentlicher Faktor ist. Darüber hinaus gibt es Lösungen, die " Dead Man 's Switches " verwenden, was uns wieder auf die Notwendigkeit zurückführt, die Warnung an den Cron-Zeitplan zu binden, und / oder Algorithmen zur Erkennung von Anomalien, die eine gewisse Schulung erfordern und bei neuen CronJob oder Änderungen an ihren nicht sofort funktionieren Zeitplan.
Eine andere Möglichkeit, das Problem zu betrachten, besteht darin, sich zu fragen: Was bedeutet es, dass Cron hätte beginnen sollen, aber nicht?
In Kubernetes, wenn Sie Fehler vergessen
cronjobcontroller'oder die Möglichkeit eines Sturzes in der Steuerebene selbst (obwohl Sie dies sofort sehen sollten, wenn Sie den Status des Clusters korrekt verfolgen) - dies bedeutet, dass cronjobcontrollerder CronJob (gemäß dem Zeitplan des Cron) bewertet und entschieden hat, dass er aufgerufen werden soll, aber aus irgendeinem Grund der Grund, warum ich mich bewusst dagegen entschieden habe .
Klingt vertraut? Genau das macht unsere Metrik
scheduling-decision.skip.count! Jetzt müssen wir nur noch die Änderung verfolgen rate(scheduling-decision.skip.count), um den Benutzer zu benachrichtigen, dass sein CronJob hätte ausgelöst werden sollen, aber dies war nicht der Fall.
Diese Lösung entkoppelt den Cron-Zeitplan von der Benachrichtigung selbst und bietet mehrere Vorteile:
- Jetzt müssen Sie Warnungen nicht mehr neu konfigurieren, wenn Sie Zeitpläne ändern.
- Es sind keine komplexen Zeitanforderungen und Bedingungen erforderlich.
- Sie können problemlos Standardbenachrichtigungen für alle CronJobs auf der Plattform generieren.
Dies trägt zusammen mit den anderen zuvor erwähnten Zeitreihen und Warnungen dazu bei, ein vollständigeres und verständlicheres Bild des Zustands des CronJob zu erstellen.
Implementieren eines Startverzögerungs-Timers
Aufgrund der Komplexität des CronJob-Lebenszyklus mussten wir sorgfältig über die spezifischen Punkte des Toolkits auf dem Stapel nachdenken, um diese Metrik zuverlässig und genau zu messen. Infolgedessen kam es darauf an, zwei Zeitpunkte festzulegen:
- T1: Wann soll Cron gestartet werden (gemäß Zeitplan)?
- T2: Wenn der Anwendungscode tatsächlich ausgeführt wird.
In diesem Fall
start delay(Startverzögerung) = 2 — 1. Um den Moment T1 zu korrigieren, haben wir den Code in die Cron-Aufruflogik in der aufgenommen cronjobcontroller'. Es erfasst die erwartete Startzeit wie .metadata.Annotationdie Job - Objekte es cronjobcontrollerschafft , wenn die CronJob genannt wird. Es kann jetzt mit jedem API-Client unter Verwendung einer normalen Anforderung abgerufen werden GET Job.
Mit T2 stellte sich heraus, dass alles komplizierter war. Da der Wert so nahe wie möglich an der Realität liegen muss, muss T2 mit dem Moment übereinstimmen, in dem der Container mit der Anwendung zum ersten Mal gestartet wird . Wenn Sie T2 auf eine schießenWenn der Container gestartet wird (einschließlich Neustarts), enthält die Verzögerung des Starts in diesem Fall die Laufzeit der Anwendung selbst. Aus diesem Grund haben wir beschlossen, ein anderes
.metadata.AnnotationJobobjekt zuzuweisen, wenn wir festgestellt haben, dass der Anwendungscontainer für einen bestimmten Job zuerst einen Status erhalten hat Running. Daher wurde im Wesentlichen eine verteilte Sperre erstellt und zukünftige Starts des Anwendungscontainers für diesen Job wurden ignoriert (nur der Moment des ersten Starts wurde gespeichert ).
Ergebnisse
Nachdem wir neue Funktionen eingeführt und Fehler behoben hatten, erhielten wir viele positive Rückmeldungen von den Entwicklern. Jetzt nutzen Entwickler unsere Kubernetes CronJob-Plattform:
- Sie müssen nicht mehr über ihre eigenen Überwachungstools und Warnungen rätseln.
- , CronJob' , .. alert' , ;
- CronJob' , CronJob' « »;
- (
app-container-duration.seconds).
Darüber hinaus verfügen die Plattformwartungsingenieure jetzt über einen neuen Parameter ( Startverzögerung ), um die Benutzererfahrung und die Plattformleistung zu messen.
Schließlich (und vielleicht unser größter Gewinn) haben wir den Debugging-Prozess für Entwickler und Plattformingenieure erheblich vereinfacht, indem wir CronJobs (und ihre Zustände) transparenter und nachvollziehbarer gemacht haben. Sie können jetzt gemeinsam mit denselben Daten debuggen. Daher kommt es häufig vor, dass die Entwickler das Problem selbst finden und mithilfe der von der Plattform bereitgestellten Tools lösen.
Fazit
Das Orchestrieren verteilter, geplanter Aufgaben ist nicht einfach. CronJob Kubernetes ist nur eine Möglichkeit, dies zu organisieren. Obwohl sie alles andere als ideal sind, sind CronJobs durchaus in der Lage, in globalen Projekten zu arbeiten, wenn Sie natürlich bereit sind, Zeit und Mühe in deren Verbesserung zu investieren: Verbesserung der Beobachtbarkeit, Verständnis der Ursachen und Besonderheiten von Fehlern und Ergänzung mit Tools, die die Verwendung vereinfachen.
Hinweis: Es gibt einen offenen Kubernetes Enhancement Proposal (KEP) , um die Mängel von CronJob zu beheben und die aktualisierte Version in GA zu übersetzen.
Vielen Dank an Rithu John , Scott Lau, Scarlett Perry , Julien Silland und Tom Wanielista für ihre Hilfe bei der Überprüfung dieser Artikelserie.
PS vom Übersetzer
Lesen Sie auch in unserem Blog: