
Mit dem Übergang zur Selbstisolation im März dieses Jahres haben wir, wie viele Unternehmen, alle unsere Lebensmittelveranstaltungen online gestellt. Nun, Sie erinnern sich an dieses wundervolle Bild über Webinare mit Affen. In den letzten sechs Monaten haben wir nur zum Thema Rechenzentren, für die mein Team verantwortlich ist, etwa 25 aufgezeichnete Webinare mit einer Dauer von 2 Stunden und insgesamt 50 Stunden Video gesammelt. Das Problem, das in vollem Umfang zugenommen hat, besteht darin, zu verstehen, in welchem Video nach Antworten auf bestimmte Fragen gesucht werden muss. Der Katalog, die Tags und eine kurze Beschreibung sind gut. Nun, wir haben endlich festgestellt, dass es 4 zweistündige Videos zum Thema gibt, und was dann? Beim Zurückspulen zuschauen? Ist es irgendwie anders möglich? Und wenn Sie modisch handeln und versuchen, die KI zu verarschen?
Spoiler für Ungeduldige : Ich konnte kein komplettes Wundersystem finden oder auf meinem Knie montieren, und dann hätte dieser Artikel keinen Sinn. Aber am Ende einiger Tage (oder eher Abende), Nachforschungen, bekam ich ein funktionierendes MVP, von dem ich Ihnen erzählen möchte. Der Zweck des Artikels besteht darin, das Interesse an dem Thema zu untersuchen, sich von sachkundigen Personen beraten zu lassen und möglicherweise jemanden zu finden, der das gleiche Problem hat.
Was ich machen will; was ich vorhabe zu tun
Auf den ersten Blick sah alles einfach aus - Sie nehmen ein Video auf, führen es durch das neuronale Netzwerk, erhalten einen Text und suchen dann nach einem Fragment im Text, das das Thema von Interesse beschreibt. Noch bequemer wäre es, alle Videos im Katalog gleichzeitig zu durchsuchen. Tatsächlich wurde es erfunden, Transkripte des Textes zusammen mit den Videos für eine lange Zeit hochzuladen. Youtube und die meisten Bildungsplattformen können dies tun, obwohl es klar ist, dass die Leute dort diese Texte bearbeiten. Sie können den Text schnell mit Ihren Augen scannen und verstehen, ob es eine Antwort auf die gewünschte Frage gibt. Aufgrund einer praktischen Funktionalität würde es wahrscheinlich nicht schaden, an der Stelle des Interesses im Text zu stöbern und zu hören, was der Dozent dort sagt und zeigt. Dies ist auch nicht schwierig, wenn Wörter rechtzeitig markiert werden, wo sie sich im Text befinden. Nun, ich habe von möglichen Entwicklungsrichtungen geträumt, lassen Sie uns am Ende sprechen,und jetzt versuchen wir einfach, die Kette so effizient wie möglich zu implementieren
Videodatei -> Textfragment -> Fuzzy-Textsuche .
Zuerst dachte ich, da alles so einfach ist und dieser Fall bereits seit 4 Jahren auf allen KI-Konferenzen diskutiert wird, sollten solche Systeme fertig existieren. Ein paar Stunden Suchen und Lesen von Artikeln zeigten, dass dies nicht der Fall war. Video wird hauptsächlich verwendet, um nach Gesichtern, Autos und anderen visuellen Objekten (Masken / Helme) und Audio-Songs, Tracks sowie dem Ton / der Intonation des Lautsprechers als Teil von Lösungen für Call Center zu suchen. Nur diese Erwähnung des Deepgram- Systems konnte gefunden werden . Leider hat sie keine Unterstützung für die russische Sprache. Microsoft hat auch sehr ähnliche Funktionen in Streams , aber nirgends wurde die Unterstützung für die russische Sprache erwähnt, anscheinend ist sie auch nicht vorhanden.
Okay, lass uns neu erfinden. Ich bin kein professioneller Programmierer (und akzeptiere übrigens gerne konstruktive Kritik am Code), aber von Zeit zu Zeit schreibe ich etwas „für mich“. Neuronale Netze, die Sprache in Text umwandeln können, werden (Überraschung, Überraschung) als Sprache in Text bezeichnet . Wenn Sie einen öffentlichen Speech-to-Text-Dienst finden, können Sie damit in allen Webinaren die Sprache „digitalisieren“ und anschließend eine unscharfe Suche im Text durchführen - eine einfachere Aufgabe. Ich gestehe, zuerst dachte ich nicht daran, "in die Wolke zu klettern", ich wollte alles lokal sammeln, aber nachdem ich diesen Artikel über Habré gelesen hatte , entschied ich, dass Spracherkennung in der Wolke wirklich besser ist.
Auf der Suche nach Cloud-Diensten für die Sprachausgabe
Die Suche nach Diensten, die Sprachausgabe ermöglichen, hat gezeigt, dass es viele solcher Systeme gibt, einschließlich der in Russland entwickelten, darunter auch globale Cloud-Anbieter wie Google , Amazon und MS Azure . Beschreibungen mehrerer Dienste, russisch-sprachigen diejenigen darunter , sind hier . Im Allgemeinen sind die ersten 20 Zeilen in den Suchmaschinenergebnissen eindeutig. Aber es gibt noch einen weiteren Haken: Ich möchte dieses System in Zukunft in die Produktion einführen. Dies ist mit Kosten verbunden. Ich arbeite für Cisco, das weltweit Verträge mit führenden Clouds hat. Aus der ganzen Liste habe ich beschlossen, vorerst nur sie zu berücksichtigen.
Daher wurde meine Liste auf Google , Amazon , Azure , reduziert.IBM Watson (Links zu Titeln sind dieselben wie in der folgenden Tabelle). Alle Dienste verfügen über APIs, über die sie verwendet werden können. Nachdem ich den Rest der Möglichkeiten analysiert hatte, stellte ich eine kleine Tabelle zusammen:

IBM Watson hat das Rennen zu diesem Zeitpunkt verlassen, da alle Aufnahmen, die ich auf Russisch habe, beschlossen wurden, den Rest der Anbieter in einem kurzen Auszug aus dem Webinar zu testen. Ich habe Konten in AWS und Azure eingerichtet. Mit Blick auf die Zukunft werde ich sagen, dass sich Microsoft bei der Einrichtung eines Kontos als eine harte Nuss herausgestellt hat. Ich habe in einem Unternehmensnetzwerk gearbeitet, das irgendwo in Amsterdam im Internet "landet". Während des Registrierungsprozesses wurde ich zweimal gefragt, ob ich sicher bin, dass meine Adresse Russland ist. Danach zeigte das System die Meldung an, dass sich das Konto "bis zur Klärung" in der Verwaltungssperre befindet. ... Nach 5 Tagen, als ich diesen Artikel schrieb, hat sich die Situation nicht geändert, sodass ich Azure noch nicht testen konnte, was schade ist! Ich verstehe - Sicherheit, aber dies hat mir noch nicht erlaubt, den Dienst auszuprobieren. Ich werde dies später versuchen, wenn die Situation gelöst ist.
Unabhängig davon möchte ich eine solche Funktion in Yandex.Cloud testen. Ihre Erkennung der russischen Sprache sollte theoretisch die beste sein. Leider gibt es auf der Testzugriffsseite des Dienstes nur die Möglichkeit, den Text zu "sagen", ein Dateidownload wird nicht bereitgestellt. Daher werden wir zusammen mit Azure den zweiten Platz verschieben.
Also, Google und Amazon bleiben übrig, testen wir es bald! Bevor Sie Code schreiben, können Sie alles von Hand überprüfen und vergleichen. Beide Anbieter verfügen neben der API über eine Verwaltungsschnittstelle. Für den Test habe ich zunächst ein 10-minütiges Fragment allgemeiner Art, wenn möglich, mit einem Minimum an Fachterminologie vorbereitet. Aber dann stellte sich heraus, dass Google im Testmodus ein Fragment von bis zu 1 Minute unterstützt. Deshalb habe ich dieses Fragment von 57 Sekunden Länge verwendet , um Dienste zu vergleichen .
Basierend auf den Ergebnissen der Arbeit geben beide Dienste den erkannten Text aus. Sie können die Ergebnisse ihrer Arbeit in einem Intervall von einer Minute vergleichen.
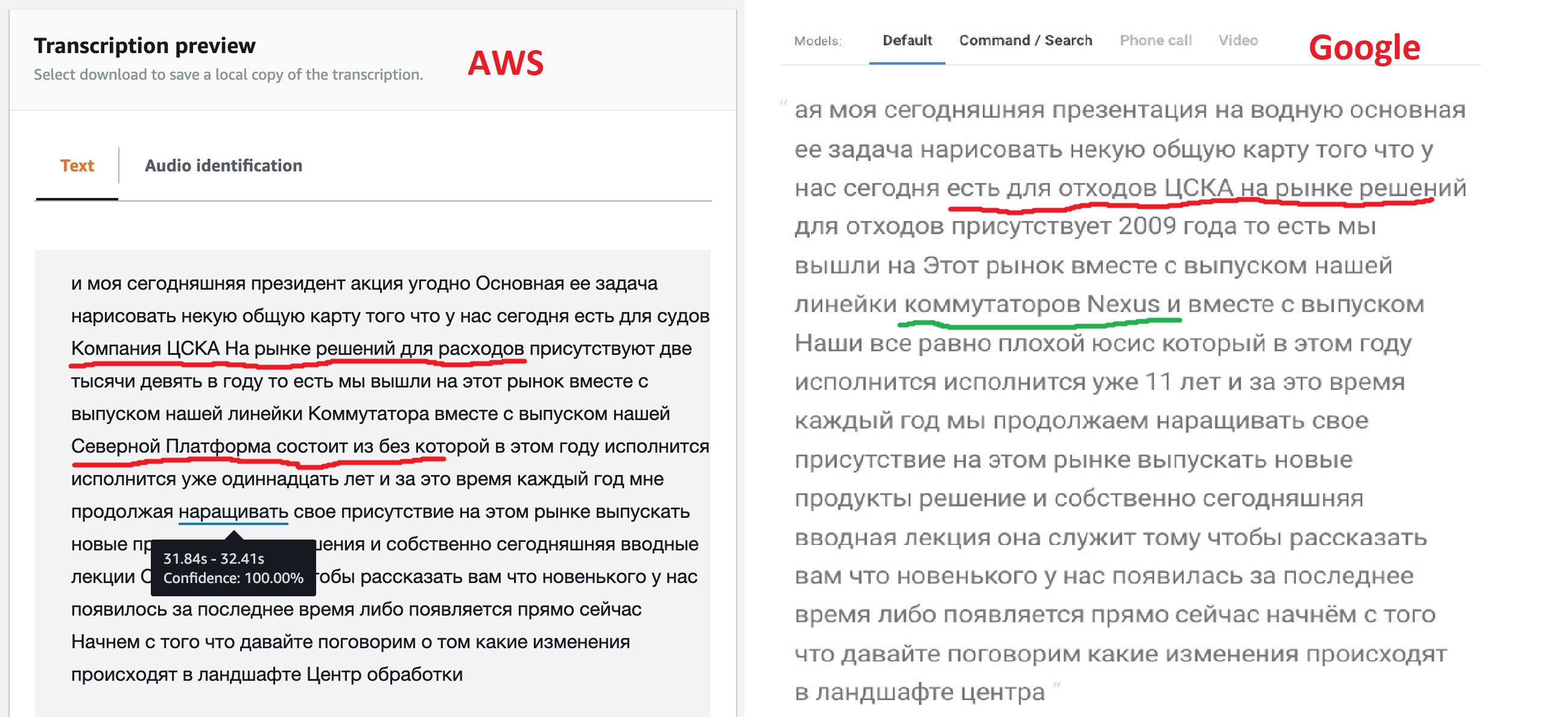
Das Ergebnis ist ehrlich gesagt nicht wie erwartet, aber nicht umsonst bieten die Modelle unterschiedliche Optionen für ihre Anpassung. Wie wir sehen können, hat die Google-Engine "out of the box" den größten Teil des Textes deutlicher erkannt und es auch geschafft, die Namen einiger Produkte zu sehen, wenn auch nicht aller. Dies deutet darauf hin, dass ihr Modell mehrsprachigen Text zulässt. Amazon (später wurde dies bestätigt) hat keine solche Gelegenheit - sie sagten Russisch, was bedeutet, dass wir singen werden: "Kin babe lom" und Punkt!
Aber die Möglichkeit, JSON zu markieren, die Amazon bietet, schien mir sehr interessant zu sein. Dies ermöglicht schließlich in Zukunft einen direkten Übergang zu dem Teil der Datei, in dem das gewünschte Fragment gefunden wurde. Vielleicht hat Google auch eine solche Funktion, weil alle neuronalen Spracherkennungsnetzwerke auf diese Weise funktionieren, aber eine flüchtige Suche in der Dokumentation hat es nicht geschafft, diese Funktion zu finden.

Wenn Sie sich diesen JSON ansehen, sehen Sie, dass er aus drei Abschnitten besteht: dem übersetzten Text (Transkript), einem Array von Wörtern (Elementen) und einer Reihe von Segmenten (Segmenten). Für eine Reihe von Wörtern und Segmenten für jedes Element werden seine Start- und Endzeiten sowie das Vertrauen (die Zuversicht) des neuronalen Netzwerks angegeben, dass es es korrekt erkannt hat.
Ein neuronales Netzwerk lehren, Rechenzentren zu verstehen
Am Ende dieser Phase entschied ich mich für Amazon Transcribe für weitere Experimente und versuchte, ein Lernmodell einzurichten. Und wenn Sie keine stabile Erkennung erzielen können, wenden Sie sich an Google. Weitere Tests wurden an einem 10-minütigen Fragment durchgeführt.
AWS Transcribe bietet zwei Optionen zum Optimieren der Erkennung durch das neuronale Netzwerk sowie einige weitere Funktionen zum Nachbearbeiten von Text:
- Custom Vocabularies – «» , , «» , . : «, , » Word 97- . , , .. .
- Custom Language Models – «» 10 . , . , , , .
- , , -. , – , .. -, .
Also habe ich beschlossen, mein eigenes Wort für den Text zu machen. Offensichtlich enthält es Wörter wie "Netzwerk, Server, Profile, Rechenzentrum, Gerät, Controller, Infrastruktur". Nach 2-3 Tests wuchs mein Wortschatz auf 60 Wörter. Dieses Wörterbuch muss in einer regulären Textdatei erstellt werden, ein Wort pro Zeile, alle in Großbuchstaben. Es gibt auch eine komplexere Option ( hier beschrieben ) mit der Möglichkeit anzugeben, wie das Wort ausgesprochen wird, aber im Anfangsstadium habe ich mich für eine einfache Liste entschieden.
Bevor Sie ein Wörterbuch verwenden können, müssen Sie es erstellen. Klicken Sie in Amazon Transcribe auf der Registerkarte Benutzerdefinierter Wortschatz auf Wortschatz erstellen , laden Sie den Text unserer Datei, geben Sie die russische Sprache an, beantworten Sie die restlichen Fragen, und der Vorgang zum Erstellen eines Wörterbuchs beginnt. Sobald er raus istDie Verarbeitung wird fertig - das Wörterbuch kann verwendet werden.
Die Frage bleibt - wie erkennt man "englische" Begriffe? Ich möchte Sie daran erinnern, dass das Wörterbuch nur eine Sprache unterstützt. Zuerst dachte ich daran, ein separates Wörterbuch mit englischen Begriffen zu erstellen und denselben Text durchzuarbeiten. Wenn Begriffe wie Cisco , VLAN , UCS erkannt werdenusw. c Wahrscheinlichkeitsrate 100% - nehmen Sie sie für das gegebene Zeitfragment. Aber ich sage gleich - es hat nicht funktioniert, der englische Sprachanalysator hat nicht mehr als die Hälfte der Begriffe im Text erkannt. Nachdem ich nachgedacht hatte, entschied ich, dass dies logisch ist, da wir alle diese Begriffe mit einem "russischen Akzent" aussprechen, verstehen uns selbst Anglo-Amerikaner nicht beim ersten Mal. Dies veranlasste die Idee, diese Begriffe einfach nach dem Prinzip "wie es gehört wird, so wird es geschrieben" in das russische Wörterbuch aufzunehmen. Cisco , usies , eisiai , vilan , viikslan - schließlich sagen wir das ehrlich, wenn wir miteinander kommunizieren. Dies erhöhte das Wörterbuch um ein paar Dutzend Wörter, aber mit Blick auf die Zukunft verbesserte es die Erkennungsqualität um eine Größenordnung!
Wie das Sprichwort sagt: "Ein guter Gedanke kommt danach" , wurde bereits das erste Wörterbuch erstellt. Deshalb habe ich beschlossen, ein weiteres zu erstellen, alle Abkürzungen hinzuzufügen und zu vergleichen, was passiert.
Starterkennung mit einem Wörterbuch ist genauso einfach, im Transkribieren Dienst auf dem Transcription Job Registerkarte wählt Job erstellen , geben Sie die russische Sprache, und vergessen Sie nicht das Wörterbuch , müssen wir angeben. Eine weitere nützliche Aktion - Sie können das neuronale Netzwerk bitten, uns mehrere alternative Suchergebnisse zu geben, das Element Alternative Ergebnisse - Ja , ich habe 3 alternative Optionen festgelegt. Wenn ich später Fuzzy-Textsuchen durchführe, ist dies hilfreich.
Die Ausstrahlung eines 10-minütigen Textes dauert 4 bis 5 Minuten. Um keine Zeit zu verschwenden, habe ich beschlossen, ein kleines Tool zu schreiben, das den Vergleich der Ergebnisse erleichtert. Ich werde den endgültigen Text aus der JSON-Datei im Browser anzeigen und gleichzeitig die „Zuverlässigkeit“ der Erkennung einzelner Wörter durch das neuronale Netzwerk hervorheben (der gleiche Konfidenzparameter ). Ich habe drei Optionen für den resultierenden Text - die Standardübersetzung, ein Wörterbuch ohne Begriffe und ein Wörterbuch mit Begriffen. Lassen Sie alle drei Texte gleichzeitig in drei Spalten angezeigt werden. Ich hebe Wörter mit einer Zuverlässigkeit von über 95% in Grün, von 95% bis 70% in Gelb und unter 70% in Rot hervor. Der hastig kompilierte Code der resultierenden HTML-Seite befindet sich unten. Die JSON-Dateien sollten sich im selben Verzeichnis wie die Datei befinden. Dateinamen werden in den Variablen FILENAME1 usw. angegeben.
HTML-Seitencode zum Anzeigen der Ergebnisse
<!DOCTYPE html>
<html lang="en">
<head> <meta charset="UTF-8"> <title>Title</title> </head>
<body onload="initText()">
<hr> <table> <tr valign="top">
<td width="400"> <h2 >- </h2><div id="text-area-1"></div></td>
<td width="400"> <h2 > 1: / </h2><div id="text-area-2"></div></td>
<td width="400"> <h2 > 2: / </h2><div id="text-area-3"></div></td>
</tr> </table> <hr>
<style>
.known { background-image: linear-gradient(90deg, #f1fff4, #c4ffdb, #f1fff4); }
.unknown { background-image: linear-gradient(90deg, #ffffff, #ffe5f1, #ffffff); }
.badknown { background-image: linear-gradient(90deg, #feffeb, #ffffc2, #feffeb); }
</style>
<script>
// File names
const FILENAME1 = "1-My_CiscoClub_transcription_10min-1-default.json";
const FILENAME2 = '2-My_CiscoClub_transcription_10min-2-Russian_only.json';
const FILENAME3 = '3-My_CiscoClub_transcription_10min-v3_Russian_terminilogy.json';
// Read file from disk and call callback if success
function readTextFile(file, textBlockName, callback) {
let rawFile = new XMLHttpRequest();
rawFile.overrideMimeType("application/json");
rawFile.open("GET", file, true);
rawFile.onreadystatechange = function() {
if (rawFile.readyState === 4 && rawFile.status == "200") {
callback(textBlockName, rawFile.responseText);
}
};
rawFile.send(null);
}
// Insert text to text block and color words confidence level
function updateTextBlock(textBlockName, text) {
var data = JSON.parse(text);
let translatedTextList = data['results']['items'];
const listLen = translatedTextList.length;
const textBlock = document.getElementById(textBlockName);
for (let i=0; i<listLen; i++) {
let addWord = translatedTextList[i]['alternatives'][0];
// load word probability and setup color depends on it
let wordProbability = parseFloat(addWord['confidence']);
let wordClass = 'unknown';
// setup the color
if (wordProbability > 0.95) {
wordClass = 'known';
} else if (wordProbability > 0.7) {
wordClass = 'badknown';
}
// insert colored word to the end of block
let insText = '<span class="' + wordClass+ '">' + addWord['content'] + ' </span>';
textBlock.insertAdjacentHTML('beforeEnd', insText)
}
}
function initText() {
// read three files each to it's area
readTextFile(FILENAME1, "text-area-1", function(textBlockName, text){
updateTextBlock(textBlockName, text);
});
readTextFile(FILENAME2, "text-area-2", function(textBlockName, text) {
updateTextBlock(textBlockName, text);
});
readTextFile(FILENAME3, "text-area-3", function(textBlockName, text) {
updateTextBlock(textBlockName, text);
});
}
</script>
</body></html>
Ich lade die Dateien asrOutput.json für alle drei Aufgaben herunter, benenne sie so um, wie sie im HTML-Skript geschrieben sind, und genau das passiert.

Es ist deutlich zu sehen, dass das neuronale Netz durch das Hinzufügen russischsprachiger Begriffe bestimmte Begriffe - " Dienstprofil " usw. - genauer erkennen konnte. Und die Hinzufügung der russischen Transkription im zweiten Schritt machte CSKA zu Cisco . Der Text ist immer noch ziemlich "schmutzig", aber für meine Kontextsuchaufgabe sollte er bereits geeignet sein. Wenn neue Webinare hinzugefügt und gelesen werden, wird das Vokabular schrittweise erweitert. Dies ist ein Prozess zur Aufrechterhaltung eines solchen Systems, das nicht vergessen werden sollte.
Fuzzy-Suche im erkannten Text
Es gibt wahrscheinlich ein Dutzend Ansätze zur Lösung des Problems der Fuzzy-Suche, die größtenteils auf einem kleinen Satz mathematischer Algorithmen basieren, wie zum Beispiel der Levenshtein-Entfernung. guter Artikel darüber , noch einer und noch einer . Aber ich wollte etwas bereit finden, wie gestartet und funktioniert.
Aus vorgefertigten Lösungen für die lokale Dokumentensuche habe ich nach ein wenig Recherche ein relativ altes Projekt SPHINX gefunden, und die Möglichkeit der Volltextsuche scheint in PostgreSQL zu sein, es wird HIER darüber geschrieben . Die meisten Materialien, auch in russischer Sprache, wurden jedoch über Elasticsearch gefunden . Nach dem Lesen gute Start- und Setup-Anleitungen wieDiesen Beitrag oder diese Lektion , hier ist eine andere , sowie die Dokumentation und das API-Handbuch für Python , habe ich beschlossen, es zu verwenden.
Für alle lokalen Experimente verwende ich Docker seit langer Zeit und empfehle jedem, der es aus irgendeinem Grund noch nicht herausgefunden hat, dies zu tun. Tatsächlich versuche ich, nichts anderes als Entwicklungsumgebungen, Browser und "Viewer" im lokalen Betriebssystem auszuführen. Abgesehen vom Fehlen von Kompatibilitätsproblemen usw. Auf diese Weise können Sie schnell ein neues Produkt ausprobieren und prüfen, ob es gut funktioniert.
Wir laden den Container mit Elasticsearch herunter und führen ihn mit zwei Befehlen aus:
$ docker pull elasticsearch:7.9.1
$ docker run -d --name elasticsearch -p 9200:9200 -e "discovery.type=single-node" elasticsearch:7.9.1
Nach dem Starten des Containers wird
http://localhost:9200die elastische Oberfläche unter der Adresse angezeigt, auf die über einen Browser oder die REST-API eines POSTMAN-Tools zugegriffen werden kann. Aber ich habe ein handliches Chrome-Plugin gefunden .
So sieht das Plugin-Fenster mit dem Beispiel über lustige Kätzchen aus, das in einer der obigen Anleitungen beschrieben ist .
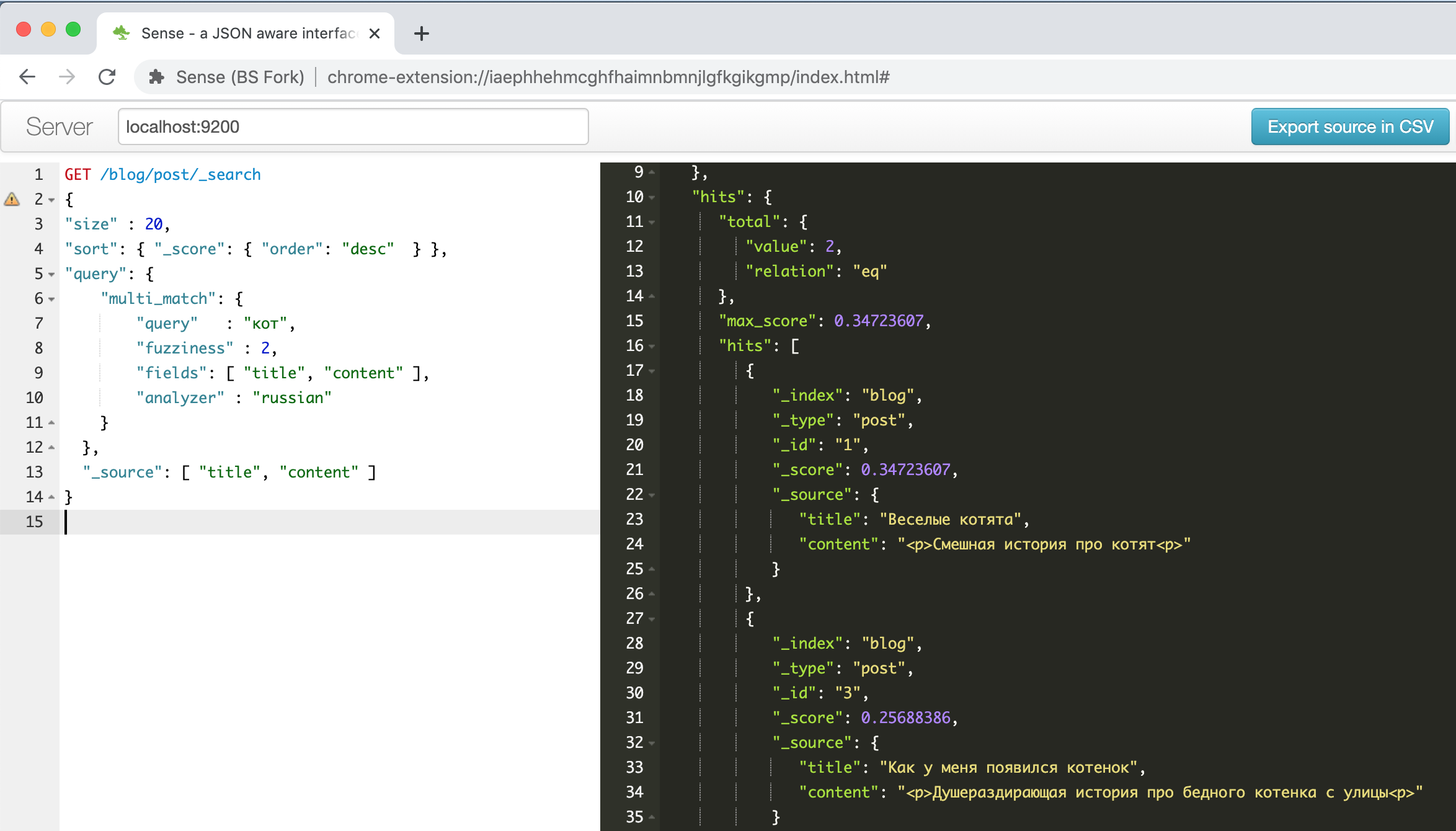
Links ist eine Anfrage - rechts ist eine Antwort, Autocomplete, Syntaxhervorhebung, Autoformating - was sonst noch benötigt wird, um produktiv zu sein! Darüber hinaus kann dieses Plugin das CURL-Befehlszeilenformat in dem aus der Zwischenablage eingefügten Text erkennen und korrekt formatieren. Versuchen Sie beispielsweise, die Zeile
" curl -X GET $ ES_URL " einzufügen, und sehen Sie, was passiert. Im Allgemeinen eine praktische Sache.
Was und wie werde ich speichern und suchen?Elasticsearch nimmt alle JSON-Dokumente und speichert sie in Strukturen, die als Indizes bezeichnet werden. Es kann beliebig viele verschiedene Indizes geben, aber ein Index kann homogene Daten und Dokumente mit einer ähnlichen Feldstruktur und demselben Suchansatz enthalten.
Um die Möglichkeiten der Fuzzy-Suche zu untersuchen, habe ich mich entschlossen, den im vorherigen Schritt erhaltenen Abschnitt mit den Phrasen (Segmenten) der Transkriptionsdatei herunterzuladen und zu durchsuchen. Im Segmentabschnitt der JSON-Datei werden Daten im folgenden Format gespeichert:
- 1 (segment)
-> /
->
--> 1
---->
----> , (confidence)
--> 2
---->
----> , (confidence)
Ich möchte die Wahrscheinlichkeit einer erfolgreichen Suche erhöhen, daher lade ich alle alternativen Optionen zur Suche in die Datenbank hoch und wähle dann aus den gefundenen Fragmenten die Option mit dem höheren Gesamtvertrauen aus.
Um ein JSON-Dokument neu zu formatieren und in Elasticsearch zu laden, verwende ich ein kleines Python-Skript. Die Logik des Skripts lautet wie folgt:
- Zunächst gehen wir alle Elemente des Segmentabschnitts und alle alternativen Transkriptionsoptionen durch
- Für jede Transkriptionsoption betrachten wir das Vertrauen in die vollständige Erkennung. Ich nehme nur das arithmetische Mittel für einzelne Wörter, obwohl dies wahrscheinlich in Zukunft sorgfältiger angegangen werden muss
- Laden Sie für jede alternative Transkriptionsoption einen Datensatz des Formulars in Elasticsearch
{ "recording_id" : < >, "seg_id" : <id >, "alt_id" : <id >, "start_time" : < >, "end_time" : < >, "transcribe_score" : < (confidence) >, "transcript" : < > }
Python-Skript, das Datensätze aus einer JSON-Datei in Elasticsearch lädt
from elasticsearch import Elasticsearch
import json
from statistics import mean
#
TRANCRIBE_FILE_NAME = "3-My_CiscoClub_transcription_10min-v3_Russian_terminilogy.json"
LOCAL_IP = "192.168.2.35"
INDEX_NAME = 'ciscorecords'
# Setup Elasticsearch connection
es = Elasticsearch([{'host': LOCAL_IP, 'port': 9200}])
if not es.ping():
print ("ES connection error, check IP and port")
es.indices.create(index=INDEX_NAME) # Create index for our recordings
# Open and load file
res = None
with open(TRANCRIBE_FILE_NAME) as json_file:
data = json.load(json_file)
res = data['results']
#
index = 1
for idx, seq in enumerate(res['segments']):
# enumerate fragments
for jdx, alt in enumerate(seq['alternatives']):
# enumerate alternatives for each segments
score_list = []
for item in alt['items']:
score_list.append( float(item['confidence']))
score = mean(score_list)
obj = {
"recording_id" : "rec_1",
"seg_id" : idx,
"alt_id" : jdx,
"start_time" : seq["start_time"],
"end_time" : seq ["end_time"],
"transcribe_score" : score,
"transcript" : alt["transcript"]
}
es.index( index=INDEX_NAME, id = index, body = obj )
index += 1
Wenn Sie nicht über Python verfügen, lassen Sie sich nicht entmutigen. Docker hilft uns erneut. Normalerweise verwende ich einen Container mit einem Jupyter-Notizbuch. Sie können mit einem normalen Browser eine Verbindung herstellen und alles tun, was Sie tun müssen. Das einzige, was Sie über das Speichern der Ergebnisse nachdenken müssen, da alle Informationen verloren gehen, wenn der Container zerstört wird. Wenn Sie noch nie mit diesem Tool gearbeitet haben, finden Sie hier einen guten Artikel für Anfänger. Übrigens können Sie den Abschnitt über die Installation sicher überspringen. Wir
starten einen Container mit einem Python-Notizbuch mit dem folgenden Befehl:
$ docker run -p 8888:8888 jupyter/base-notebook sh -c 'jupyter notebook --allow-root --no-browser --ip=0.0.0.0 --port=8888'
Und wir stellen mit jedem Browser eine Verbindung zu der Adresse her, die wir nach dem erfolgreichen Start des Skripts auf dem Bildschirm sehen. Dies geschieht
http://127.0.0.1:8888mit dem angegebenen Sicherheitsschlüssel.
Wir erstellen ein neues Notizbuch in der ersten Zelle, die wir schreiben:
!pip install elasticsearch
Ausführen, warten Sie, bis das Paket für die Arbeit mit ES über die API installiert ist, kopieren Sie unser Skript in die zweite Zelle und führen Sie es aus. Wenn nach der Arbeit alles erfolgreich ist, können wir in der Elasticsearch-Konsole überprüfen, ob unsere Daten erfolgreich geladen wurden. Wir geben den Befehl ein
GET /ciscorecords/_searchund sehen unsere geladenen Datensätze im Antwortfenster, insgesamt 173 Teile, wie das Feld Hits.Total.Wert zeigt .
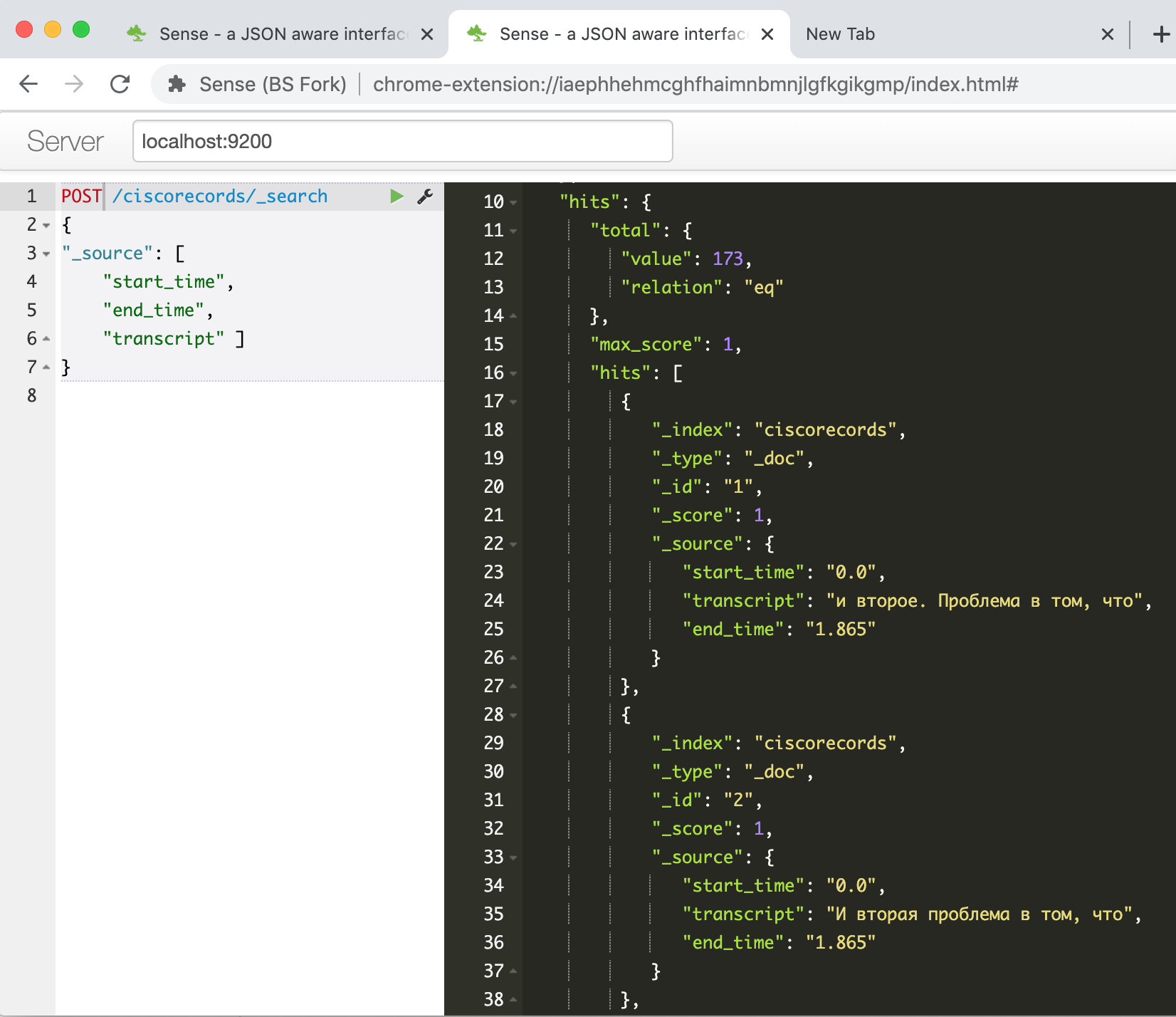
Jetzt ist es an der Zeit, die Fuzzy-Suche auszuprobieren - darum ging es. Um beispielsweise nach dem Ausdruck "Kern des Rechenzentrumsnetzwerks" zu suchen, müssen Sie den folgenden Befehl eingeben:
POST /ciscorecords/_search
{
"size" : 20,
"min_score" : 1,
"sort": { "_score": { "order": "desc" } },
"query": {
"multi_match": {
"query" : " ",
"fuzziness" : 2,
"fields": [ "transcript" ],
"analyzer" : "russian"
}
},
"_source": [ "transcript", "transcribe_score" ]
}
Wir erhalten bis zu 47 Ergebnisse!

Kein Wunder, denn die meisten von ihnen sind verschiedene Variationen desselben Fragments. Schreiben wir ein weiteres Skript, um aus jedem Segment einen Datensatz mit dem höchsten Konfidenzwert auszuwählen.
Python-Skript zum Abfragen der Elasticsearch-Datenbank
#####
#
# PHRASE = " "
# PHRASE = " "
PHRASE = " "
LOCAL_IP = "192.168.2.35"
INDEX_NAME = 'ciscorecords'
#
elastic_queary = {
"size" : 40,
"min_score" : 1,
"sort": { "_score": { "order": "desc" } },
"query": {
"multi_match": {
"query" : PHRASE,
"fuzziness" : 2,
"fields": [ "transcript" ],
"analyzer" : "russian"
}
},
}
# Setup Elasticsearch connection
es = Elasticsearch([{'host': LOCAL_IP, 'port': 9200}])
if not es.ping():
print ("ES connection error, check IP and port")
#
res = es.search(index=INDEX_NAME, body = elastic_queary)
print ("Got %d Hits:" % res['hits']['total']['value'])
#
search_results = {}
for hit in res['hits']['hits']:
seg_id = hit["_source"]['seg_id']
if seg_id not in search_results or search_results[seg_id]['score'] < hit["_score"]:
_res = hit["_source"]
_res["score"] = hit["_score"]
search_results[seg_id] = _res
print ("%s unique results \n-----" % len(search_results))
for rec in search_results:
print ("seg %(seg_id)s: %(score).4f : start(%(start_time)s)-end(%(end_time)s) -- %(transcript)s" % \
(search_results[rec]))
Ausgabebeispiel:
Got 47 Hits:
16 unique results
-----
seg 39: 7.2885 : start(374.24)-end(377.165) -- , ..
seg 49: 7.0923 : start(464.44)-end(468.065) -- , ...
seg 41: 4.5401 : start(385.14)-end(405.065) -- . , , , , , ...
seg 30: 4.3556 : start(292.74)-end(298.265) -- , , ,
seg 44: 2.1968 : start(415.34)-end(426.765) -- , , , . -
seg 48: 2.0587 : start(449.64)-end(464.065) -- , , , , , .
seg 26: 1.8621 : start(243.24)-end(259.065) -- . . , . ...
Wir sehen, dass die Ergebnisse viel kleiner geworden sind, und jetzt können wir sie anzeigen und die auswählen, die uns am meisten interessiert.
Da wir die Start- und Endzeit des Videofragments haben, können wir eine Seite mit einem Videoplayer erstellen und programmgesteuert auf das gewünschte Fragment zurückspulen.
Ich werde diese Aufgabe jedoch in einem separaten Artikel veröffentlichen, wenn Interesse an weiteren Veröffentlichungen zu diesem Thema besteht.
Anstelle einer Schlussfolgerung
Im Rahmen dieses Artikels habe ich gezeigt, wie ich das Problem des Aufbaus eines Textsuchsystems mithilfe eines Video-Tools mit Aufzeichnungen von Webinaren zu technischen Themen gelöst habe. Das Ergebnis ist das, was üblicherweise als MVP bezeichnet wird, d.h. Der minimale Arbeitsalgorithmus, mit dem Sie ein Ergebnis erhalten und nachweisen können, dass das Ergebnis im Prinzip mit vorhandenen Technologien erreichbar ist.
Von Ideen, die in naher Zukunft umgesetzt werden können, ist es noch ein langer Weg bis zum Endprodukt:
- Schrauben Sie den Videoplayer an, damit Sie das gefundene Fragment anhören und anzeigen können
- Denken Sie über die Möglichkeit der Textbearbeitung nach. Während Sie die Bindung an den Text von Wörtern, die zu 100% erkannt werden, belassen können, bearbeiten Sie nur Fragmente, bei denen die Erkennungsqualität "nachlässt".
- elasticsearch, -
- speech-to-text, Google, Yandex, Azure. –
- , «»
- BERT (Bi-directional Encoder Representation from Transformer), . – « xx yy».
- , - - . Youtube , 15-20 , ,
- – , , ,
Wenn Sie Fragen / Kommentare haben, beantworte ich diese gerne und freue mich über Vorschläge zur Verbesserung oder Vereinfachung des gesamten Prozesses. Dies ist mein erster technischer Artikel für Habr. Ich hoffe wirklich, dass er sich als nützlich und interessant herausgestellt hat.
Viel Glück für alle auf Ihrer kreativen Suche, und möge die Macht mit Ihnen sein!