
Eine wichtige Aufgabe der Codologie bei der Verarbeitung von Informationsströmen codierter Nachrichten in den Kanälen von Kommunikationssystemen und Computern ist die Trennung von Strömen und deren Auswahl gemäß den gegebenen Merkmalen. Der dedizierte Stream wird in separate Nachrichten aufgeteilt und für jede von ihnen wird eine eingehende Analyse durchgeführt, um den Code und seine Eigenschaften zu ermitteln, gefolgt von der Decodierung und dem Zugriff auf die Semantik der Nachricht.
So müssen Sie beispielsweise für einen bestimmten Reed-Solomon-Code (PC-Code) Folgendes festlegen:
- die Länge n des Codeworts (Block);
- die Anzahl von k Informationen und Nk Prüfsymbolen;
- ein irreduzibles Polynom p (x), das ein endliches Feld GF (2 r ) definiert;
- primitives Element α eines endlichen Feldes;
- Erzeugen des Polynoms g (x);
- Parameter j des Codes;
- verwendetes Interleaving;
- Reihenfolge der Übertragung von Codewörtern oder Symbolen an den Kanal und einige andere.
Hier wird ein etwas anderes spezielles Problem bei der Arbeit betrachtet - die Modellierung des PC-Codes selbst, der der zentrale Hauptteil des obigen Code-Analyse-Problems ist.
Beschreibung des PC-Codes und seiner Eigenschaften
Zur Vereinfachung und zum besseren Verständnis der Essenz des PC-Code-Geräts und des Codierungsprozesses werden zunächst die grundlegenden Konzepte und Begriffe (Elemente) des Codes vorgestellt.
Reed-Solomon-Codes (RS-Code) können als nicht-binäre BCH-Codes (Bose-Chowdhury-Hawkingham) interpretiert werden, deren Werte der Codesymbole aus dem GF (2 r ) -Feld stammen , d. H. R Informationssymbole werden als separates Element des Feldes angezeigt. Reed-Solomon-Codes sind lineare nicht-binäre systematische zyklische Codes, deren Symbole R-Bit-Sequenzen sind, wobei r eine positive ganze Zahl größer als 1 ist.
Reed-Solomon-Codes (n, k) sind für alle n und auf R-Bit-Symbolen definiert k, für die:
0 <k <n <2 r + 2, wobei
k ist die Anzahl der zu codierenden Informationssymbole,
n ist die Anzahl der Codesymbole in dem codierten Block.
Für die meisten (n, k) Reed-Solomon-Codes; (n, k) = (2 r –1, 2 r –1–2 ∙ t), wobei
t die Anzahl der fehlerhaften Symbole ist, die der Code korrigieren kann, und
n - k = 2t die Anzahl der Prüfsymbole ist.
Der Reed-Solomon-Code hat den größtmöglichen Mindestabstand (die Anzahl der Zeichen, die die Sequenzen unterscheiden), der für einen linearen Code möglich ist. Für Reed-Solomon-Codes ist der Mindestabstand wie folgt definiert: dmin = n - k +1.
Definition . PC-Code über dem Feld GF (q = m ) mit der Blocklänge n = q m-1, das t Fehler korrigiert, ist die Menge aller Codewörter u (n) über GF (q), für die 2t aufeinanderfolgende Spektralkomponenten mit Zahlen vorliegen sind gleich 0.
Die Tatsache, dass 2 t aufeinanderfolgende Potenzen von α Wurzeln des erzeugenden Polynoms g (x) sind oder dass das Spektrum 2 t aufeinanderfolgende Nullkomponenten enthält, ist eine wichtige Eigenschaft des Codes, mit der t Fehler korrigiert werden können.
InformationspolynomQ. Gibt den Text der Nachricht an, der in Blöcke (Wörter) konstanter Länge unterteilt und digitalisiert ist. Dies soll im Kommunikationssystem übertragen werden.
Polynom erzeugeng (x) eines PC-Codes ist ein Polynom, das Informationspolynome (Nachrichten) in Codewörter umwandelt, indem Q · g (x) = = u (n) über GF (q) multipliziert wird .
Mit dem Prüfpolynom h (x) können Sie das Vorhandensein verzerrter Zeichen in einem Wort feststellen.
Syndrompolynom S (z). Ein Polynom, das Komponenten enthält, die fehlerhaften Positionen entsprechen. Berechnet für jedes vom Decoder empfangene Wort.
Fehlerpolynom E. Ein Polynom mit einer Länge, die dem Codewort entspricht, mit Nullwerten an allen Positionen, außer denen, die Verzerrungen der Codewortsymbole enthalten.
FehlerlokalisierungspolynomΛ (z) liefert Wurzeln, die die Positionen von Fehlern in Wörtern angeben, die von der Empfangsseite des Kommunikationskanals (Decodierers) empfangen werden. Seine Wurzeln können durch Versuch und Irrtum gefunden werden, d.h. indem Sie nacheinander alle Elemente des Feldes einsetzen, bis Λ (z) gleich Null wird.
Das Polynom der Fehlerwerte Ω (z) ≡Λ (z) · S (z) (modz 2t ) ist mit dem Produkt des Polynoms der Fehlerlokalisierer durch das syndromale Polynom mit Modulo z 2t vergleichbar .
Irreduzibles Polynom des Feldes p (x). Endliche Felder existieren nicht für eine beliebige Anzahl von Elementen, sondern nur, wenn die Anzahl der Elemente eine Primzahl p oder eine Potenz von q = p m istPrimzahl. Im ersten Fall heißt das Feld einfach (seine Elemente sind der Rest der Zahlen modulo a prime p), im zweiten Fall ist es eine Erweiterung des entsprechenden einfachen Feldes (seine q Elemente von Polynomen vom Grad m-1 oder weniger sind die Reste von Polynomen modulo das Polynom p (x) vom Grad m)
Primitives Polynom . Wenn die Wurzel eines irreduziblen Polynoms des Feldes ein primitives Element α ist, wird p (x) als irreduzibles primitives Polynom bezeichnet.
Bei der Beschreibung von Aktionen mit dem PC-Code müssen wir wiederholt auf das Galois-Feld verweisen. Daher platzieren wir hier sofort ein Arbeitsblatt mit den Elementen dieses Felds mit unterschiedlichen Darstellungen der Elemente (Dezimalzahl, Binärvektor, Polynom, Grad eines primitiven Elements)).
Tabelle II - Eigenschaften von Elementen des endlichen Feldes der Erweiterung GF (2 4 ), irreduzibles Polynom p (x) = x 4 + x + 1, primitives Element α = 0010 = 2 10

Beispiel 1 . Über ein endliches Feld GF (2 4 ) wird ein irreduzibles Feldpolynom p (x) = x 4 + x + 1 gegeben, ein primitives Element α = 2 und ein (n, k) - Reed-Solomon-Code (PC-Code). Der Codeabstand dieses Codes beträgt d = n - k + 1 = 7. Dieser Code kann bis zu drei Fehler im Block (Codewort) der Nachricht korrigieren.
Das erzeugende Polynom g (z) des Codes hat den Grad m = nk = 15-9 = 6 (seine Wurzeln sind 6 Elemente des Feldes GF (2 4 ) in Dezimalschreibweise, nämlich die Elemente 2, 3, 4, 5, 6, 7) und wird durch das Verhältnis bestimmt, d.h. Polynom in z mit Koeffizienten (Elementen) aus GF (2 4 ) in Dezimaldarstellung für i = 1 (1) 6. Im betrachteten PC-Code 2 9 = 512 Codewörter.
PC-Nachrichtencodierung
In Tabelle II haben diese Wurzeln auch eine Potenzdarstellung ...

Hier ist z eine abstrakte Variable und α ist ein primitives Element des Feldes, durch seine Kräfte werden alle (16) Elemente des Feldes ausgedrückt. Die Polynomdarstellung von Feldelementen verwendet die Variable x.
Die Berechnung des generierenden Polynoms g (x) = A B des PC-Codes erfolgt in Teilen (jeweils drei Klammern):

Die Vektordarstellung (in Bezug auf die Koeffizienten g (z) durch die Elemente des Feldes in Dezimaldarstellung) des erzeugenden Polynoms ist
g (z) = G7 = (1, 11, 15, 5, 7, 10, 7).
Nach der Erzeugung des Erzeugungspolynoms des PC-Codes, das auf Fehlererkennung und -korrektur ausgerichtet ist, wird eine Nachricht gesetzt. Die Nachricht wird in digitaler Form (z. B. ASCII-Code) dargestellt, von der aus der Übergang zur Polynom- oder Vektordarstellung erfolgt.
Ein Informationsvektor (Nachrichtenwort) hat k - Komponenten von (n, k). In dem Beispiel k = 9 ist der Vektor eine 9-Komponente, alle Komponenten sind Elemente des GF-Feldes (2 4 ) in Dezimaldarstellung Q9 = (11, 13, 9, 6, 7, 15, 14, 12, 10) ...
Aus diesem Vektor wird das Codewort u gebildet<15> ist ein Vektor mit 15 Komponenten. Codewörter sind wie die Codes selbst systematisch und nicht systematisch. Ein nicht systematisches Codewort wird erhalten, indem der Informationsvektor Q mit dem Vektor multipliziert wird, der dem erzeugenden Polynom entspricht

Nach Transformationen erhalten wir ein nicht systematisches Codewort (Vektor) in der Form
Q · g = <11, 15, 3, 9, 6, 14, 7, 5, 12, 15, 14, 3, 3, 7, 1>.
Bei der systematischen Codierung wird eine Nachricht (Informationsvektor) durch ein Polynom Q (z) in der Form Q (z) = q (z) g (z) + R (z) dargestellt, wobei der Grad degR (z) <m = 6 ist Dem Vektor Q auf der rechten Seite wird der Rest R zugewiesen (alle in Dezimalform). Dies geschieht so.
Das Polynom Q wird um den Wert m = n - k zu den höheren Stellen verschoben, was durch Multiplizieren von Q (z) mit Z n - k (im Beispiel Z n - k = Z 6 ) und nach der Verschiebung durch die Division Q (z) Z erreicht wird n - k durch g (z). Finden Sie als Ergebnis den Rest der Division R (z). Alle Operationen werden auf dem GF-Feld ausgeführt (2 4 )
(11, 13, 9, 6, 7, 15, 14, 12, 10, 0, 0, 0, 0, 0, 0) =
= (1, 11, 15, 5, 7, 10, 7) ( 11, 15, 9, 10,12,10,10,10,10,3) + (1, 2, 3, 7, 13, 9) = G · S + R.
Der Rest der Polynomteilung wird auf übliche Weise berechnet ( siehe Ecke) hier Beispiel 6 ). Die Division erfolgt nach dem Muster: Sei Q = 26, g (z) = 7, dann 26 = 7 3 + R (z), R (z) = 26 -7 3 = 26-21 = 5. Berechnung des Restes R (z ) zur Teilung von Polynomen. Wir weisen Sie den Rest R auf den Vektor Q auf der rechten Seite .
Wir u bekommen <15> - ein Codewort in systematischer Form. In dieser Ansicht deutlich enthält eine Informationsnachricht in dem k Hoch um Bits des Codewortes
u <15> = (11,13,9,6,7,15,14,12,10; 1, 2, 3, 7, 13, 9)
Die Ziffern des Vektors sind von 0 (1) 14 von rechts nach links nummeriert. Die sechs niedrigstwertigen Bits rechts sind die Prüfbits.
Dekodierung von Reed-Solomon-Codes
Nach dem Empfang eines Blocks verarbeitet der Decoder jeden Block (Codewort) und korrigiert Fehler, die während der Übertragung oder Speicherung aufgetreten sind. Der Decoder teilt das resultierende Polynom durch das erzeugende Polynom des RS-Codes. Wenn der Rest Null ist, wurden keine Fehler gefunden, andernfalls treten Fehler auf.
Ein typischer PC-Decoder führt fünf Schritte in einer Decodierungsschleife aus, nämlich:
- Bei der Berechnung des syndromalen Polynoms (seiner Koeffizienten) werden Fehler gefunden.
- Die Pade-Schlüsselgleichung wird gelöst - Berechnung der Fehlerwerte und ihrer Positionen an den entsprechenden Stellen.
- Chens Prozedur wird implementiert - die Wurzeln des Fehlerlokalisierungspolynoms finden.
- Der Forney-Algorithmus wird verwendet, um den Fehlerwert zu berechnen.
- Verzerrte Codewörter werden korrigiert.
Der Zyklus endet mit dem Extrahieren der Nachricht aus den Codewörtern (Entfernen des Codes).
Berechnung des Syndroms.
Die Syndromgenerierung aus dem empfangenen Codewort ist der erste Schritt im
Decodierungsprozess. Hier werden Syndrome berechnet und es wird festgestellt, ob das empfangene Codewort Fehler enthält oder nicht. Die
Decodierung der PC-Codewörter kann auf verschiedene Arten organisiert werden. Die klassischen Verfahren umfassen das Decodieren unter Verwendung von Algorithmen, die im Zeit- oder Frequenzbereich arbeiten und entweder die Berechnung des Syndroms verwenden oder nicht. Ohne auf die Theorie dieses Problems einzugehen, werden wir uns für die Decodierung mit der Berechnung von Codewortsyndromen im Zeitbereich entscheiden.
Verzerrungserkennung
Syndrom wo Der Vektor wird nacheinander für jedes der Codewörter bestimmt, die der Decoder an seinem Eingang empfängt. Mit Nullwerten der Komponenten des SyndromvektorsDer Decoder ist der Ansicht, dass das empfangene Wort keinen Fehler enthält. Wenn für mindestens einenDann schließt der Decodierer, dass es Fehler im Codevektor gibt, und fährt fort, diese zu identifizieren, was der erste Schritt in der Operation des Decoders ist.
Die Berechnung der syndromalen Polynom-
Multiplikation auf der Empfangsseite des Codeworts C durch die Paritätsprüfmatrix H kann zu zwei Ergebnissen führen:
- Syndromvektor S = 0, was der Abwesenheit von Fehlern in Vektor C entspricht;
- der Syndromvektor S ≠ 0, was das Vorhandensein von Fehlern (einer oder mehrere) in den Komponenten des Vektors C bedeutet.
Der zweite Fall ist von Interesse.
Der Codevektor mit Fehlern wird dargestellt als C (E) = C + E, E ist der Fehlervektor. Dann
Die Komponenten Sj des Syndroms werden entweder durch die Summationsrelation
für n = q-1 und j = 1 (1) m = nk oder durch das Horner-Schema bestimmt:
Beispiel 2 . Der Fehlervektor habe die Form = <0 0 0 0 12 0 0 0 0 0 8 0 0 0>. Es zerfleischt die Zeichen an der 3. und 10. Position im Codevektor. Die Fehlerwerte sind 8 bzw. 12 - diese Werte sind ebenfalls Elemente des GF-Feldes (2 4 ) und werden in Dezimalschreibweise (Tabelle P) angegeben. In Vektor E sind die Positionen von rechts nach links beginnend mit 0 (1) 14 von den niedrigsten aus nummeriert.
Bilden wir nun einen Codevektor mit zwei Fehlern im 3. Bit und im 10. Bit mit den Werten 8 bzw. 12. Dies erfolgt durch Summieren in der GF (2 4) nach den Regeln der Arithmetik dieses Feldes. Das Summieren von Feldelementen mit Null ändert ihren Wert nicht. Werte ungleich Null (Feldelemente) werden summiert, nachdem sie in eine Polynomdarstellung umgewandelt wurden, da Polynome normalerweise summiert werden, aber die Koeffizienten für das Unbekannte werden mod 2 reduziert.
Nachdem das Summationsergebnis erhalten wurde, werden sie erneut in eine Dezimaldarstellung umgewandelt, nachdem sie zuvor die Potenzdarstellung durchlaufen haben

Das Folgende zeigt die Berechnung von fehlerverfälschten Werten an 10 und 3 Positionen des Codeworts:
Der Decodierer führt Berechnungen gemäß der allgemeinen Formel für die Komponenten Sj, j = 1 (1) m durch. Hier (im Modell) verwenden wir die BeziehungDa wir im Programm selbst angeben (simulieren), werden Terme ungleich Null nur für i = 3 und i = 10 erhalten.

Im Folgenden werden die Berechnungen nach dieser Formel speziell in erweiterter Form dargestellt.
Die Prüfmatrix des PC-Codes
Sobald das generierende Polynom des Codes formuliert ist, wird es möglich, eine Paritätsprüfungsmatrix für Codewörter zu erstellen sowie die Anzahl der zu korrigierenden Fehler zu bestimmen ( siehe hier den Decoder ). Konstruieren wir eine Hilfsmatrix [7 × 15], aus der zwei verschiedene Paritätsprüfmatrizen erhalten werden können: Die ersten sechs Zeilen sind eine und die letzten sechs Zeilen sind die andere.
Die Matrix selbst wird auf besondere Weise gebildet. Die ersten beiden Zeilen sind offensichtlich, die dritte Zeile und alle nachfolgenden werden erhalten, indem von der vorherigen (zweiten) Zeile ein Segment der natürlichen Zahlen 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, subtrahiert wird. 15 mod 15. Wenn ein Nullwert auftritt, wird er durch 15 ersetzt, negative Reste werden in positive umgewandelt.

Jede Matrix entspricht einem eigenen Generatorpolynom für die systematische und nicht systematische Codierung.
Bestimmung der Koeffizienten des syndromalen Polynoms
Ferner werden wir die Koeffizienten des syndromalen Polynoms für j = 1 (1) 6 bestimmen.
In Bezug auf ein Codewort mit LängeWenn wir am Eingang des Decoders ankommen, nehmen wir an, dass er durch Fehler verzerrt ist.
Um den Fehlervektor zu identifizieren, müssen Sie Folgendes wissen:
- die Anzahl der verzerrten Positionen im Codewort
- ;;
- Zahlen (Position) verzerrter Positionen in einem Codewort ;;
- Verzerrungswerte ...
Wie wird der Syndromvektor (Polynom) S berechnet und weiter verwendet? Seine Rolle bei der Dekodierung von Codewörtern ist sehr wichtig. Lassen Sie uns dies anhand eines numerischen Beispiels veranschaulichen.
Beispiel 3 . (Berechnung der Komponenten des Syndromvektors )

dann haben wir am Ende = <8,13,7,13,15,15>
Zur weiteren Betrachtung führen wir neue Konzepte ein. Der Wertwird als Fehlersuchgerät bezeichnet, hier das verzerrte Codewortsymbol an der Position , α ist ein primitives Element des Feldes GF (2 4 ).
Der Satz von Fehlerlokalisierern für ein bestimmtes Codewort wird nachstehend als die Koeffizienten des Fehlerlokalisierungspolynoms σ (z), Wurzeln, betrachtet Welches sind die Werte invers zu Locators.
Darüber hinaus die Ausdrückeverschwinden.
immer freie Laufzeit immer freie Laufzeit ...
Der Grad des Polynoms der Fehlerlokalisierer ist gleich v - die Anzahl der Fehler und überschreitet den Wert nicht...
Alle verzerrten Zeichen befinden sich daher an verschiedenen Positionen des Wortes unter den Locatorskann es keine wiederholten Feldelemente geben, und das Polynom σ (z) = 0 hat keine Mehrfachwurzeln.
Zur Vereinfachung des Schreibens werden die Fehlerwerte durch das Symbol neu gekennzeichnet... Für die Koeffizienten des syndromalen Polynoms wurden zuvor nichtlineare Gleichungen berücksichtigt. In unserem Fall ist v = 1 der Ursprung der Komponenten des Syndroms.
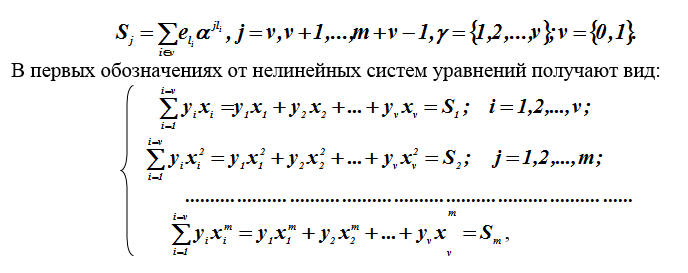
Wo Sind unbekannte Größen und - bekannte, in der ersten Phase der Dekodierung berechnete Parameter (Komponenten des Syndromvektors).
Methoden zum Lösen solcher Systeme nichtlinearer Gleichungen sind unbekannt, aber Lösungen werden mithilfe von Tricks (Problemumgehungen) gefunden. Für die Koeffizienten wird ein Übergang zum linearen Gleichungssystem Hankel (Toeplitz) vorgenommendas Locator-Polynom.
Umwandlung in ein lineares Gleichungssystem
In eine Gleichung des Fehlerlokalisierungspolynoms wird der Wert seiner Wurzeln ersetzt ... In diesem Fall verschwindet das Polynom. Es entsteht eine Identität, deren beide Seiten mit multipliziert werden, wir bekommen:
...
Wir erhalten solche Gleichheiten
Wir summieren diese Gleichheiten über alles für die diese Gleichheiten erfüllt sind. Da das Polynom σ (z) v Wurzeln hatÖffnen Sie die Klammern und übertragen Sie die Koeffizienten pro Vorzeichen des Betrags:

Bei dieser Gleichheit ist gemäß dem zuvor angegebenen System nichtlinearer Gleichungen
jede Summe gleich einer der Komponenten des Syndromvektors. Daher kommt er zu dem Schluss, dass in Bezug auf die Koeffizienten Sie können ein System linearer Gleichungen schreiben.

Vorzeichen "-" bei der Berechnung über ein Binärfeld werden weggelassen, da sie "+" entsprechen. Das resultierende lineare Gleichungssystem ist Hankel und entspricht einer Matrix mit Dimensionen Bit.

Diese Matrix ist nicht entartet, wenn die Anzahl der Fehler im Codewort C (E) genau gleich ist d.h. Die Störfestigkeit dieses Codes wird nicht verletzt.
Lösen eines linearen Gleichungssystems
Das resultierende lineare Gleichungssystem enthält die Koeffizienten als Unbekannte das Fehlerlokalisierungspolynom für das Codewort C (E). Die zuvor berechneten Komponenten des Syndromvektors gelten als bekannt... Hier ist t die Anzahl der Fehler im Wort, m ist die Anzahl der Prüfpositionen im Wort.
Es gibt verschiedene Methoden zum Lösen des gebildeten Systems.
Beachten Sie, dass die (Hankel-) Matrix für Dimensionen, die durch die Anzahl der in einem einzelnen Wort zulässigen Fehler (weniger als 0,5 m) begrenzt sind, nicht entartet ist. In diesem Fall ist das Gleichungssystem eindeutig gelöst, und das Problem kann einfach auf die Inversion der Hankel-Matrix reduziert werden. Es wäre wünschenswert, die Beschränkung der Dimension von Matrizen aufzuheben, d.h. über ein endloses Feld.
Methoden zur Lösung des Hankel-Systems linearer Gleichungen sind über unendliche Felder bekannt:
- iterative Trench-Berlekamp-Messi-Methode (TBM-Methode); (1)
- direkter deterministischer Peterson - Gorenstein - Zierler; (PHC - Methode); (2)
- Sugiyamas Methode unter Verwendung des Euklid-Algorithmus zum Finden der GCD (C-Methode). (3)
Ohne andere Methoden in Betracht zu ziehen, werden wir uns für die TBM-Methode entscheiden. Die Motivation für die Wahl ist wie folgt.
Die Methode (PHC) ist einfach und gut, aber für eine kleine Anzahl korrigierbarer Fehler ist die C-Methode auf einem Computer schwer zu implementieren und wurde nur begrenzt in Quellen veröffentlicht (abgedeckt), obwohl die C-Methode wie die TBM-Methode nach dem bekannten Polynom der Syndrome S (z) vorsieht Lösung der Pade-Gleichung über dem Galois-Feld. Diese Gleichung wird für das Polynom der Fehlerlokalisierer σ (z) und das Polynom ω (z) gebildet. In der Codierungstheorie wird sie als Schlüssel-Pade-Gleichung bezeichnet:
...
Die Lösung für die Schlüsselgleichung ist die Menge Wurzeln des Polynoms σ (z) und dementsprechend die Locatoren d.h. Fehlerpositionen. Fehlerwerte (Größen) werden aus der Forney-Formel in der Form bestimmt

Wo und Sind die Werte der Polynome σ (z) und ω (z) am Punkt invers zur Wurzel des Polynoms σ (z);
i ist die Position des Fehlers; - die formale Ableitung des Polynoms σ (z) in Bezug auf z;
Formale Ableitung eines Polynoms in einem endlichen Feld
Es gibt Unterschiede und Ähnlichkeiten für die Ableitung in Bezug auf eine Variable im Bereich der reellen Zahlen und die formale Ableitung in einem endlichen Feld. Betrachten Sie das Polynom

Sind die Feldelemente, i = 1 (1) n
Feldelemente. Ein Code über einem realen Feld GF (2 4 ) wird gegeben. Die Ableitung in Bezug auf z ist:

In einem unendlichen reellen Feld fallen die Operationen mit n multipliziert und summieren sich n-mal. Für endliche Felder ist die Ableitung unterschiedlich definiert.
Die Ableitung wird in ähnlicher Weise durch das Verhältnis bestimmt:

wobei ((i)) = 1 + 1 + ... + 1, (i) mal, summiert nach den Regeln eines endlichen Feldes: das + -Zeichen bezeichnet die Operation "so oft summieren", d.h. Element 2 mal wiederholen, Element 3 mal wiederholen, Element n mal wiederholen.
Es ist klar, dass diese Operation nicht mit der Multiplikationsoperation in einem endlichen Feld zusammenfällt. Insbesondere wird in den Feldern GF (2 r ) die Summe einer geraden Anzahl identischer Terme mod2 genommen und auf Null gesetzt, und eine ungerade Zahl ist gleich dem Term selbst ohne Änderungen. Daher nimmt im Feld GF (2 r ) die Ableitung die Form an

Die zweite und höchste gerade Ableitung in diesem Bereich ist gleich Null.
Aus der Algebra ist bekannt, dass, wenn ein Polynom mehrere Wurzeln (der Multiplizität p) hat, die Ableitung des Polynoms dieselbe Wurzel hat, jedoch mit der Multiplizität p-1. Wenn p = 1 ist, haben f (z) und f '(z) keine gemeinsame Wurzel. Wenn also ein Polynom und seine Ableitung einen gemeinsamen Teiler haben, gibt es eine Mehrfachwurzel. Alle Wurzeln der Ableitung f '(z) sind Vielfache in f (z).
Schlüsselgleichungslösungsmethode
TMB (Trench-Berlekampa-Messi) ist eine Methode zur Lösung der Schlüsselgleichung. Der iterative Algorithmus liefert die Definition der Polynome σ (z) und ω (z) sowie die Lösung der Pade-Gleichung (Schlüsselgleichung).
Anfangsdaten: PolynomkoeffizientenGrad n-1.
Tor. Definition der Polynome σ (z) und ω (z) in expliziter (analytischer) Form.
Der Algorithmus verwendet die folgende Notation: j - Schrittnummer, - der Grad des Polynoms, - Erweiterung des Polynoms in Potenzen und - Zwischenvariablen und Funktionen im j-ten Schritt des Algorithmus;
Die Anfangsbedingungen müssen angegeben werden, da hier die Rekursion verwendet wird.
Anfangsbedingungen:

Beispiel 4 . Ausführung des iterativen Algorithmus für den Vektor
S = (8,13,7,13,15,15). Polynome sind definiert und ...
Tabelle 2 - Berechnung von Fehlerlokalisierungspolynomen
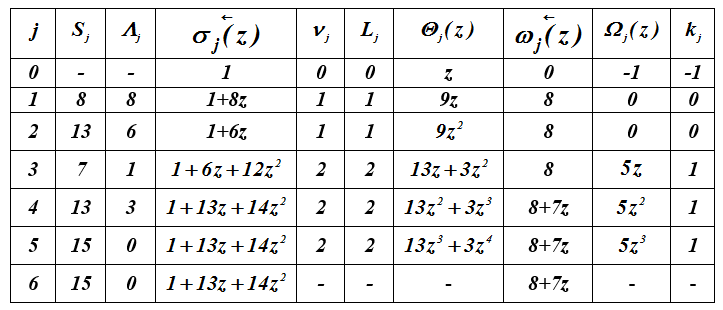

damit , = 7z + 8.
Das Fehlerlokalisierungspolynom σ (z) über dem Feld GF (2 4 ) mit dem irreduziblen Polynom p (x) = x 4 + x + 1 hat Wurzeln
und ist es leicht, dies durch direkte Verifikation zu verifizieren, d.h. und ... Wurzelsubstitution in
=
=;;
=
=...
Nehmen wir die formale Ableitung von σ (z), so erhalten wir σ_2 (z) = 2 14 + 13 = 13, da 14z zweimal in der Summe genommen wird und mod 2 verschwindet.
Unter Verwendung der Forney-Formel finden wir Ausdrücke zur Berechnung der Fehlerwerte...

Wenn
wir die Werte i = 3 und i = 10 im letzten Ausdruck einsetzen, finden wir
= =;;
= =...
Die Architektur zum Erstellen eines Softwarepakets
Zum Erstellen eines Softwarepakets wird die Verwendung der folgenden Architekturlösung vorgeschlagen. Das Softwarepaket ist als Anwendung mit einer grafischen Benutzeroberfläche implementiert.
Die Anfangsdaten für das Softwarepaket sind digitale Datenströme, die mithilfe eines Speicherauszugs aus einer Datei entladen werden. Zur Vereinfachung der Analyse und Klarheit des komplexen Vorgangs sollten TXT-Dateien verwendet werden.
Der geladene digitale Stream wird im Rahmen der komplexen Arbeit, auf die verschiedene Rechenaktionen angewendet werden, in Form von Datenarrays dargestellt.
In jeder Phase der komplexen Operation ist es möglich, die Zwischenergebnisse der Arbeit zu visualisieren.
Die Ergebnisse des Softwarepakets werden in Form von numerischen Daten dargestellt, die in Tabellen angezeigt werden.
Die Ergebnisse der Zwischen- und Endanalyse werden in Dateien gespeichert.
Funktionsschema des Softwarekomplexes Der
Betrieb mit dem Komplex beginnt mit dem Laden eines digitalen Streams mithilfe eines Speicherauszugs aus einer Datei. Nach dem Herunterladen wird dem Benutzer eine visuelle Darstellung des binären Inhalts der Datei und ihres Textinhalts angezeigt.
Im Rahmen dieser Schnittstelle sollten folgende funktionale Aufgaben implementiert werden:
- Laden Sie die Originalnachricht herunter.
- Konvertieren einer Nachricht in einen Speicherauszug;
- Nachrichtenkodierung;
- Simulation einer abgefangenen Nachricht
- Konstruktion von Spektren der empfangenen Codewörter zur Analyse ihrer visuellen Darstellung;
- Code-Parameter anzeigen.
Beschreibung des Softwarepaketvorgangs
Wenn die ausführbare Datei des Programms gestartet wird, wird das in Abbildung 2 gezeigte Fenster auf dem Bildschirm angezeigt, auf dem die Hauptoberfläche des Programms angezeigt wird.
Die Eingabe des Programms ist eine Datei, die über den Kommunikationskanal übertragen werden muss. Für die Übertragung über reale Kommunikationskanäle ist eine Codierung erforderlich - das Hinzufügen von Prüfsymbolen, die für die eindeutige Decodierung eines Wortes am Quellenempfänger erforderlich sind. Um den Komplex zu starten, müssen Sie die gewünschte Textdatei über die Schaltfläche „Datei laden“ auswählen. Der Inhalt wird im unteren Feld des Hauptprogrammfensters angezeigt.
Die binäre Darstellung der Nachricht wird im entsprechenden Feld angezeigt, die binäre Darstellung von Informationswörtern - im Feld "Binäre Darstellung von Informationswörtern".
Die Anzahl der Bits in der ursprünglichen Nachricht und die Gesamtzahl der darin enthaltenen Wörter werden in den Feldern "Anzahl der Bits in der übertragenen Nachricht" und "Anzahl der Wörter in der übertragenen Nachricht" angezeigt.
Gebildete Informationen und Codewörter werden in Tabellen auf der rechten Seite des Hauptprogrammfensters angezeigt.
Das Programmfenster mit Zwischenergebnissen ist in Abbildung 3 dargestellt.
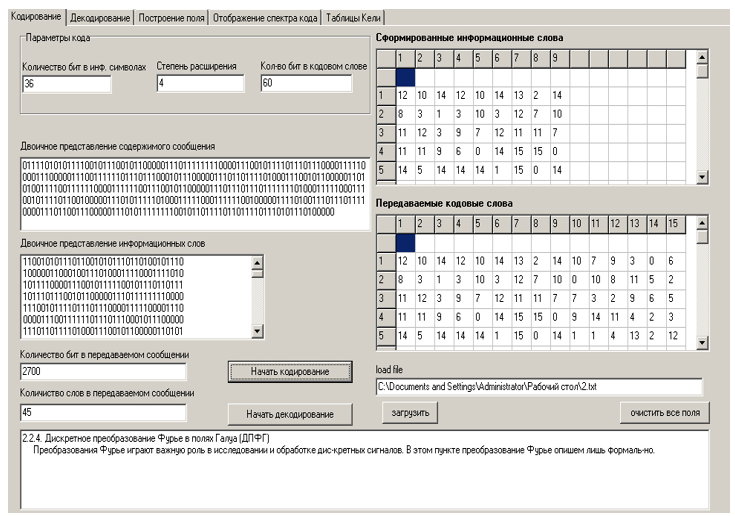
Abbildung 3 - Zwischenpräsentation der Ergebnisse des Softwarepakets

Abbildung 4. Ergebnisse des Herunterladens der Nachrichtendatei
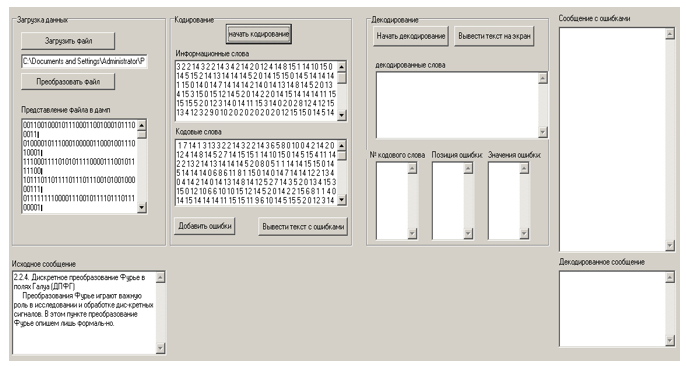
Abbildung 5. Ergebnisse der Dateikodierung

Abbildung 6. Ausgabe einer Nachricht mit eingegebenen Fehlern.

Abbildung 7. Ausgabe von Decodierungsergebnissen und Nachrichten mit eingeführten Fehlern
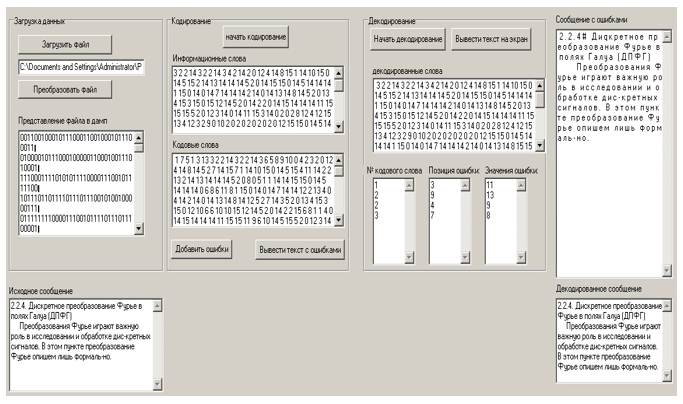
Abbildung 8. Ausgabe von decodierten Nachrichten.
Fazit
Die US-amerikanische NSA ist der Hauptbetreiber des globalen Abhörsystems von Echelon. Echelon verfügt über eine umfangreiche Infrastruktur mit Bodenverfolgungsstationen auf der ganzen Welt. Fast alle weltweiten Informationsflüsse werden überwacht.
Die Untersuchung der Möglichkeiten, in der gegenwärtigen Zeit des aktiven Informationskriegs sowohl auf dem Gebiet der Technologie als auch in der Politik Zugang zur Semantik verschlüsselter Informationsnachrichten zu erhalten, ist zur nächsten Herausforderung und zu einer der dringenden und geforderten Aufgaben unserer Zeit geworden.
In der überwiegenden Mehrheit der Codes wird das Codieren und Decodieren von Nachrichten (Informationen) auf einer strengen mathematischen Basis endlicher erweiterter Galois-Felder implementiert. Die Arbeit mit Elementen solcher Felder unterscheidet sich von den in der Arithmetik allgemein akzeptierten und erfordert das Schreiben spezieller Verfahren zum Bearbeiten von Feldelementen bei Verwendung von Rechenwerkzeugen.
Die Arbeit, die den Lesern angeboten wird, öffnet leicht den Schleier der Geheimhaltung über solche Aktivitäten auf der Ebene von Unternehmen, Unternehmen und Staaten im Allgemeinen.
Literaturverzeichnis
- . , . – .: , 1986. – 576 .
- - . , . . . , . – .: , 1979. – 744 .
- . . – .: , 1971. – 478 .
- .., .. . – .: , 1986. – 176 ., .
- . . . – .: , 2004. – 288 .
- .. . . – : - , 2005. – 147 .
- . ., .. . – : , 2001. – 60 .
- ., ., ., . . – .: , 1978. – 576 .
- . . . – .: . , 1990. – 288 .
- . ., .. « »/ . .26. . .. –. .: .. , 2007. – . 121-130.
- . ( 2. ). – . . . , 2002. – 97 .
- . . . – .: , 1987 – 120 .