
Was sind kurze und lange Metriken?
Ranking-Modelle versuchen, die Wahrscheinlichkeit abzuschätzen, mit der der Benutzer mit den Nachrichten (Post) interagiert: Er wird darauf achten, die Markierung „Gefällt mir“ setzen und einen Kommentar schreiben. Das Modell verteilt dann die Datensätze in absteigender Reihenfolge dieser Wahrscheinlichkeit. Durch die Verbesserung des Rankings können wir daher die Klickrate (Klickrate) von Benutzeraktionen erhöhen: Likes, Kommentare und andere. Diese Metriken reagieren sehr empfindlich auf Änderungen im Ranking-Modell. Ich werde sie kurz nennen .
Es gibt jedoch eine andere Art von Metriken. Es wird beispielsweise angenommen, dass die in der Anwendung verbrachte Zeit oder die Anzahl der Benutzersitzungen seine Einstellung zum Dienst viel besser widerspiegeln. Wir werden solche Metriken lange nennen .
Die direkte Optimierung langer Metriken durch Ranking-Algorithmen ist keine triviale Aufgabe. Mit kurzen Metriken ist dies viel einfacher: Die Klickrate von Likes hängt beispielsweise direkt davon ab, wie gut wir ihre Wahrscheinlichkeit einschätzen. Wenn wir jedoch die kausalen (oder kausalen) Beziehungen zwischen kurzen und langen Metriken kennen, können wir uns darauf konzentrieren, nur die kurzen Metriken zu optimieren, die vorhersehbar lange beeinflussen sollten. Ich habe versucht, solche Kausalzusammenhänge zu extrahieren - und darüber in meiner Arbeit geschrieben, die ich als Diplom am Bachelor of Science (CT) der ITMO abgeschlossen habe. Wir haben die Forschung im Labor für maschinelles Lernen von ITMO zusammen mit VKontakte durchgeführt.
Links zu Code, Datensatz und Sandbox
Den gesamten Code finden Sie hier: AnverK .
Um die Beziehungen zwischen Metriken zu analysieren, haben wir einen Datensatz verwendet, der die Ergebnisse von mehr als 6.000 realen A / B-Tests enthält, die vom VK-Team zu verschiedenen Zeiten durchgeführt wurden. Der Datensatz ist auch im Repository verfügbar .
In der Sandbox können Sie sehen, wie der vorgeschlagene Wrapper verwendet wird: für synthetische Daten .
Und hier - wie man Algorithmen auf einen Datensatz anwendet: auf den vorgeschlagenen Datensatz .
Umgang mit falschen Korrelationen
Es scheint, dass es zur Lösung unseres Problems ausreicht, die Korrelationen zwischen den Metriken zu berechnen. Dies ist jedoch nicht ganz richtig: Korrelation ist nicht immer Kausalität. Nehmen wir an, wir messen nur vier Metriken und ihre Kausalzusammenhänge sehen folgendermaßen aus: Nehmen wir

ohne Verlust der Allgemeinheit an, dass es einen positiven Einfluss in Pfeilrichtung gibt: Je mehr Likes, desto mehr SPU. In diesem Fall kann festgestellt werden, dass sich Kommentare zum Foto positiv auf die SPU auswirken. Und entscheiden Sie, dass sich die SPU erhöht, wenn Sie diese Metrik "erhöhen". Dieses Phänomen wird als falsche Korrelation bezeichnet.: Der Korrelationskoeffizient ist ziemlich hoch, aber es gibt keinen Kausalzusammenhang. Eine falsche Korrelation ist nicht auf zwei Effekte derselben Ursache beschränkt. Aus dem gleichen Diagramm könnte man die falsche Schlussfolgerung ziehen, dass sich Likes positiv auf die Anzahl der Fotoöffnungen auswirken.
Selbst bei einem so einfachen Beispiel wird deutlich, dass eine einfache Analyse der Korrelationen zu vielen falschen Schlussfolgerungen führt. Kausale Inferenz (Methoden zur Inferenz von Beziehungen) ermöglicht die Wiederherstellung kausaler Beziehungen aus Daten. Um sie in der Aufgabe anzuwenden, haben wir die am besten geeigneten kausalen Inferenzalgorithmen ausgewählt, Python-Schnittstellen für sie implementiert und Modifikationen bekannter Algorithmen hinzugefügt, die unter unseren Bedingungen besser funktionieren.
Klassische Algorithmen für Inferenzverknüpfungen
Wir haben verschiedene Methoden der kausalen Inferenz betrachtet: PC (Peter und Clark), FCI (Fast Causal Inference) und FCI + (ähnlich wie FCI aus theoretischer Sicht, aber viel schneller). Sie können in diesen Quellen ausführlich darüber lesen:
- Kausalität (J. Pearl, 2009),
- Ursache, Vorhersage und Suche (P. Spirtes et al., 2000),
- Das Erlernen spärlicher Kausalmodelle ist nicht NP-schwer (T. Claassen et al., 2013).
Es ist jedoch wichtig zu verstehen, dass die erste Methode (PC) davon ausgeht, dass wir alle Größen beobachten, die zwei oder mehr Metriken beeinflussen - diese Hypothese wird als kausale Suffizienz bezeichnet. Die beiden anderen Algorithmen berücksichtigen, dass möglicherweise nicht beobachtbare Faktoren die überwachten Metriken beeinflussen. Das heißt, im zweiten Fall wird die kausale Darstellung als natürlicher angesehen und ermöglicht das Vorhandensein nicht beobachtbarer Faktoren:

Alle Implementierungen dieser Algorithmen werden in der pcalg- Bibliothek bereitgestellt . Es ist schön und flexibel, aber mit einem "Nachteil" - es ist in R geschrieben (bei der Entwicklung der rechenintensivsten Funktionen wird das RCPP-Paket verwendet). Daher habe ich für die oben aufgeführten Methoden Wrapper in die CausalGraphBuilder-Klasse geschrieben und Beispiele für deren Verwendung hinzugefügt.
Ich werde die Verträge der Funktion der Inferenz von Links beschreiben, dh die Schnittstelle und das Ergebnis, das am Ausgang erhalten werden kann. Sie können eine Testfunktion für die bedingte Unabhängigkeit bestehen. Dies ist ein Test wie dieser, der zurückkehrt unter der Nullhypothese, dass die Mengen und bedingt unabhängig für einen bekannten Satz von Mengen ... Der Standardwert ist ein Teilkorrelationstest . Ich habe die Funktion bei diesem Test ausgewählt, da dies die Standardeinstellung in pcalg ist und in RCPP implementiert ist - dies macht es in der Praxis schnell. Sie können auch übertragen, ab dem die Eckpunkte als abhängig betrachtet werden. Für PC- und FCI-Algorithmen können Sie auch die Anzahl der CPU-Kerne festlegen, wenn Sie kein Protokoll des Bibliotheksvorgangs schreiben müssen. Es gibt keine solche Option für FCI +, aber ich empfehle die Verwendung dieses speziellen Algorithmus - er gewinnt an Geschwindigkeit. Eine weitere Einschränkung: FCI + unterstützt derzeit den vorgeschlagenen Kantenorientierungsalgorithmus nicht - der Punkt liegt in den Einschränkungen der PCALG-Bibliothek.
Basierend auf den Ergebnissen der Arbeit aller Algorithmen wird ein PAG (Partial Ahnengraph) in Form einer Kantenliste erstellt. Mit dem PC-Algorithmus sollte es als Kausaldiagramm im klassischen Sinne (oder Bayes'sches Netzwerk) interpretiert werden: eine Kante, die sich an orientiert beim bedeutet Einfluss auf ... Wenn eine Kante ungerichtet oder bidirektional ist, können wir sie nicht eindeutig ausrichten. Dies bedeutet:
- oder die verfügbaren Daten reichen nicht aus, um eine Richtung festzulegen,
- oder es ist unmöglich, weil ein wahrer Kausaldiagramm, das nur beobachtbare Daten verwendet, nur bis zu einer Äquivalenzklasse erstellt werden kann.
Die FCI-Algorithmen führen ebenfalls zu PAG, es wird jedoch eine neue Art von Kanten angezeigt - mit einem "o" am Ende. Dies bedeutet, dass der Pfeil möglicherweise vorhanden ist oder nicht. In diesem Fall besteht der wichtigste Unterschied zwischen FCI-Algorithmen und PC darin, dass eine bidirektionale Kante (mit zwei Pfeilen) deutlich macht, dass die Scheitelpunkte, die sie verbindet, Konsequenzen eines nicht beobachtbaren Scheitelpunkts sind. Dementsprechend sieht eine Doppelkante im PC-Algorithmus jetzt wie eine Kante mit zwei "o" -Enden aus. Eine Illustration für einen solchen Fall befindet sich im Sandkasten mit synthetischen Beispielen.
Ändern des Kantenorientierungsalgorithmus
Die klassischen Methoden haben einen wesentlichen Nachteil. Sie geben zu, dass es unbekannte Faktoren geben kann, stützen sich aber gleichzeitig auf eine andere übermäßig ernste Annahme. Das Wesentliche ist, dass die Funktion des Testens auf bedingte Unabhängigkeit perfekt sein sollte. Andernfalls ist der Algorithmus nicht für sich selbst verantwortlich und garantiert weder die Richtigkeit noch die Vollständigkeit des Diagramms (die Tatsache, dass mehr Kanten nicht ausgerichtet werden können, ohne die Richtigkeit zu verletzen). Kennen Sie viele ideale bedingte Unabhängigkeitstests mit endlicher Stichprobe? Ich nicht.
Trotz dieses Nachteils sind Graphenskelette ziemlich überzeugend aufgebaut, aber sie sind zu aggressiv ausgerichtet. Daher schlug ich eine Änderung des Kantenorientierungsalgorithmus vor. Bonus: Hiermit können Sie die Anzahl der ausgerichteten Kanten implizit anpassen. Um sein Wesen klar zu erklären, müsste hier ausführlich auf die Algorithmen zur Ableitung von Kausalzusammenhängen eingegangen werden. Daher werde ich die Theorie dieses Algorithmus und die vorgeschlagene Modifikation separat anhängen - ein Link zum Material befindet sich am Ende des Beitrags.
Modelle vergleichen - 1: Graph Likelihood Estimation
Seltsamerweise ist eine der ernsthaften Schwierigkeiten bei der Ableitung von Kausalzusammenhängen der Vergleich und die Bewertung von Modellen. Wie ist es passiert? Der Punkt ist, dass normalerweise die wahre kausale Darstellung realer Daten unbekannt ist. Darüber hinaus können wir die Verteilung nicht so genau kennen, dass daraus echte Daten generiert werden. Das heißt, die Grundwahrheit ist für die meisten Datensätze unbekannt. Daher entsteht ein Dilemma: Verwenden Sie (halb-) synthetische Daten mit bekannter Grundwahrheit oder versuchen Sie, auf Grundwahrheit zu verzichten, testen Sie jedoch anhand realer Daten. In meiner Arbeit habe ich versucht, zwei Testansätze zu implementieren.
Die erste ist die Schätzung der Graphwahrscheinlichkeit:

Hier - viele Vertex-Eltern , - gemeinsame Mengenangabe und , und Ist die Entropie der Menge ... Tatsächlich hängt der zweite Term nicht von der Struktur des Graphen ab, daher wird in der Regel nur der erste berücksichtigt. Sie sehen jedoch, dass die Wahrscheinlichkeit mit dem Hinzufügen neuer Kanten nicht abnimmt - dies muss beim Vergleich berücksichtigt werden.
Es ist wichtig zu verstehen, dass eine solche Bewertung nur zum Vergleichen von Bayes'schen Netzwerken (Ausgabe des PC-Algorithmus) funktioniert, da in realen PAGs (Ausgabe von FCI-, FCI + -Algorithmen) Doppelkanten eine völlig andere Semantik haben.
Daher habe ich die Ausrichtung der Kanten mit meinem Algorithmus und dem klassischen PC verglichen: Die
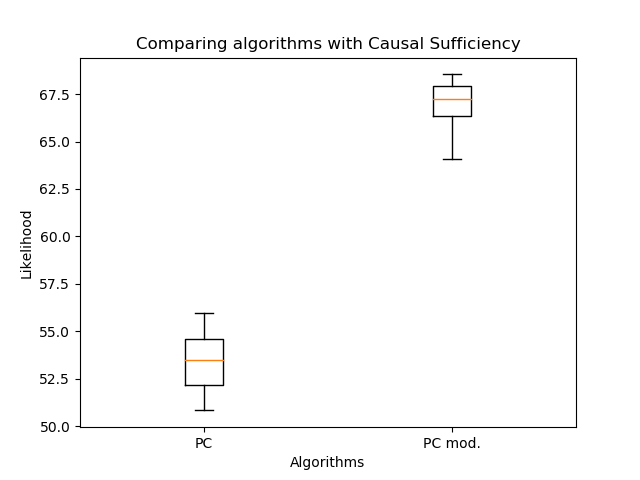
geänderte Ausrichtung der Kanten ermöglichte eine signifikante Erhöhung der Wahrscheinlichkeit im Vergleich zum klassischen Algorithmus. Aber jetzt ist es wichtig, die Anzahl der Kanten zu vergleichen:
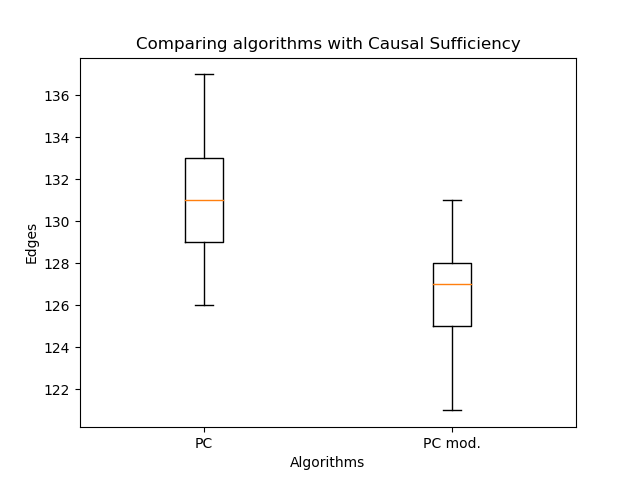
Es gibt noch weniger davon - das wird erwartet. So ist es auch mit weniger Kanten möglich, eine plausibelere Graphstruktur wiederherzustellen! Hier könnten Sie argumentieren, dass die Wahrscheinlichkeit nicht mit der Anzahl der Kanten abnimmt. Der Punkt ist, dass der resultierende Graph im allgemeinen Fall kein Teilgraph des Graphen ist, der durch den klassischen PC-Algorithmus erhalten wird. Anstelle von Einzelkanten können Doppelkanten angezeigt werden, und Einzelkanten können die Richtung ändern. Also kein Handwerk!
Modelle vergleichen - 2: Verwenden eines Klassifizierungsansatzes
Kommen wir zum zweiten Vergleich. Wir werden den PC-Algorithmus verwenden, um einen Kausalgraphen zu erstellen und einen zufälligen azyklischen Graphen daraus auszuwählen. Danach generieren wir die Daten an jedem Scheitelpunkt als lineare Kombination der Werte an den übergeordneten Scheitelpunkten mit den Koeffizientenmit der Hinzufügung von Gaußschem Rauschen. Die Idee für eine solche Generation habe ich aus dem Artikel "Auf dem Weg zu einer robusten und vielseitigen kausalen Entdeckung für Geschäftsanwendungen" (Borboudakis et al., 2016) übernommen. Die Scheitelpunkte ohne Eltern wurden aus einer Normalverteilung generiert - mit Parametern wie im Datensatz für den entsprechenden Scheitelpunkt.
Wenn die Daten empfangen werden, wenden wir die Algorithmen an, die wir auswerten möchten. Darüber hinaus haben wir bereits einen echten Kausalgraphen. Es bleibt nur zu verstehen, wie die resultierenden Graphen mit den wahren verglichen werden. In "Robuste Rekonstruktion kausaler grafischer Modelle basierend auf bedingten 2-Punkt- und 3-Punkt-Informationen" (Affeldt et al., 2015) wurde die Verwendung der Klassifikationsterminologie vorgeschlagen. Wir gehen davon aus, dass die gezeichnete Kante eine positive und die nicht gezeichnete Klasse negativ ist. Dann True Positive () Ist, wenn wir die gleiche Kante wie im wahren Kausaldiagramm gezeichnet haben, und False Positive () - wenn eine Kante gezeichnet wird, die nicht im wahren Kausaldiagramm enthalten ist. Wir werden diese Werte unter dem Gesichtspunkt des Skeletts bewerten.
Um Anweisungen zu berücksichtigen, stellen wir vorfür Kanten, die korrekt angezeigt werden, jedoch mit der falschen Richtung. Danach werden wir es so betrachten:
Dann können Sie lesen -Größe sowohl für das Skelett als auch unter Berücksichtigung der Ausrichtung (offensichtlich ist sie in diesem Fall nicht höher als die für das Skelett). Im Fall des PC-Algorithmus wird jedoch eine doppelte Kante hinzugefügt nur , und nicht , weil immer noch eine der realen Kanten abgeleitet wird (ohne kausale Suffizienz wäre dies falsch).
Lassen Sie uns abschließend die Algorithmen vergleichen:

Die ersten beiden Grafiken sind ein Vergleich der Skelette des PC-Algorithmus: der klassische und mit der neuen Kantenorientierung. Sie werden benötigt, um den oberen Rand anzuzeigen-Maße. Die zweiten beiden vergleichen diese Algorithmen hinsichtlich ihrer Orientierung. Wie Sie sehen, gibt es keinen Gewinn.
Modelle vergleichen - 3: Kausale Suffizienz ausschalten
Lassen Sie uns nun einige Variablen im wahren Diagramm und in den synthetischen Daten nach der Generierung "schließen". Dadurch wird die kausale Suffizienz ausgeschaltet. Es ist jedoch erforderlich, die Ergebnisse nicht mit dem tatsächlichen Diagramm zu vergleichen, sondern mit dem wie folgt erhaltenen:
- Die Kanten der Eltern des verborgenen Scheitelpunkts werden zu seinen Kindern gezogen.
- Verbinden Sie alle Kinder des verborgenen Scheitelpunkts mit einer doppelten Kante.
Wir werden bereits die FCI + -Algorithmen (mit modifizierter Kantenorientierung und mit der klassischen) vergleichen:

Und jetzt, wenn die kausale Suffizienz nicht erfüllt ist, wird das Ergebnis der neuen Orientierung viel besser.
Eine weitere wichtige Beobachtung ist aufgetaucht: Die PC- und FCI-Algorithmen bilden in der Praxis nahezu identische Skelette. Daher habe ich ihre Ausgabe mit der Ausrichtung der Kanten verglichen, die ich in meiner Arbeit vorgeschlagen habe.
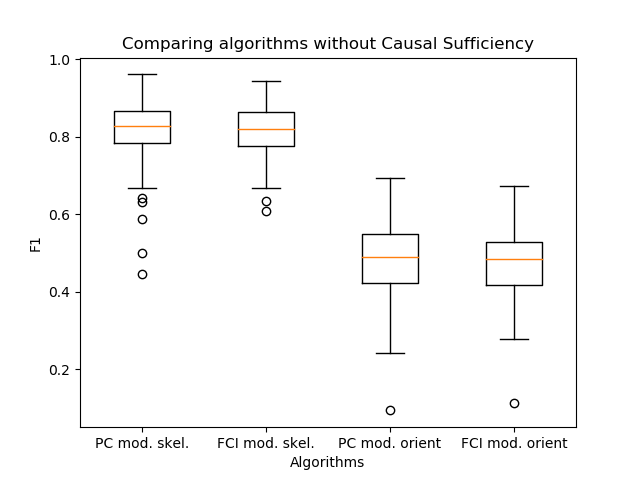
Es stellte sich heraus, dass sich die Algorithmen in der Qualität praktisch nicht unterscheiden. In diesem Fall ist PC ein Schritt des Skelettkonstruktionsalgorithmus innerhalb der FCI. Daher ist die Verwendung des Orientierungs-PC-Algorithmus wie beim FCI-Algorithmus eine gute Lösung, um die Geschwindigkeit der Verbindungsinferenz zu erhöhen.
Ausgabe
Ich werde kurz zusammenfassen, worüber wir in diesem Artikel gesprochen haben:
- Wie die Aufgabe, Kausalzusammenhänge abzuleiten, in einem großen IT-Unternehmen entstehen kann.
- Was sind falsche Korrelationen und wie können sie die Merkmalsauswahl beeinträchtigen?
- Welche Algorithmen für Inferenzverknüpfungen existieren und werden am häufigsten verwendet?
- Welche Schwierigkeiten können bei der Ableitung von Kausaldiagrammen auftreten?
- Was ist der Vergleich von Kausalgraphen und wie damit umzugehen?
Wenn Sie sich für das Thema der kausalen Folgerung interessieren, lesen Sie meinen anderen Artikel - er hat mehr Theorie. Dort schreibe ich ausführlich über die Grundbegriffe, die bei der Inferenz von Links verwendet werden, sowie über die Funktionsweise der klassischen Algorithmen und die Ausrichtung der von mir vorgeschlagenen Kanten.