
Die letzten Jahre des tiefen Lernens waren eine kontinuierliche Reihe von Erfolgen: von der Niederlage der Menschen im Go-Spiel bis zur weltweiten Führungsrolle bei Bilderkennung, Spracherkennung, Textübersetzung und anderen Aufgaben. Dieser Fortschritt ging jedoch mit einer unstillbaren Steigerung des Appetits auf Rechenleistung einher. Eine Gruppe von Wissenschaftlern des MIT, der Yongse University (Korea) und der Brasilia University veröffentlichte eine Metaanalyse von 1.058 wissenschaftlichen Arbeiten zum maschinellen Lernen . Es zeigt deutlich, dass der Fortschritt beim maschinellen Lernen (ML) eine Ableitung der Rechenleistung des Systems ist . Die Computerleistung hat die Funktionalität von ML immer eingeschränkt, aber jetzt wachsen die Anforderungen neuer ML-Modelle viel schneller als die Computerleistung.
Die Studie zeigt, dass Fortschritte beim maschinellen Lernen in der Tat kaum mehr als eine Folge des Mooreschen Gesetzes sind. Aus diesem Grund werden viele ML-Probleme aufgrund der physischen Einschränkungen des Computers niemals gelöst.
Die Forscher analysierten wissenschaftliche Arbeiten zu Bildklassifizierung (ImageNet), Objekterkennung (MS COCO), Beantwortung von Fragen (SQuAD 1.1), Erkennung benannter Entitäten (COLLN 2003) und maschineller Übersetzung (WMT 2014 En-to-Fr).

Rechenabfragen ML, Protokollskala Der
Fortschritt in allen fünf Bereichen hängt nachweislich stark von einer höheren Rechenleistung ab. Die Extrapolation dieser Beziehung macht deutlich, dass Fortschritte in diesen Bereichen rasch wirtschaftlich, technisch und ökologisch nicht mehr nachhaltig sind. Weitere Fortschritte bei diesen Anwendungen erfordern daher wesentlich recheneffizientere Methoden.
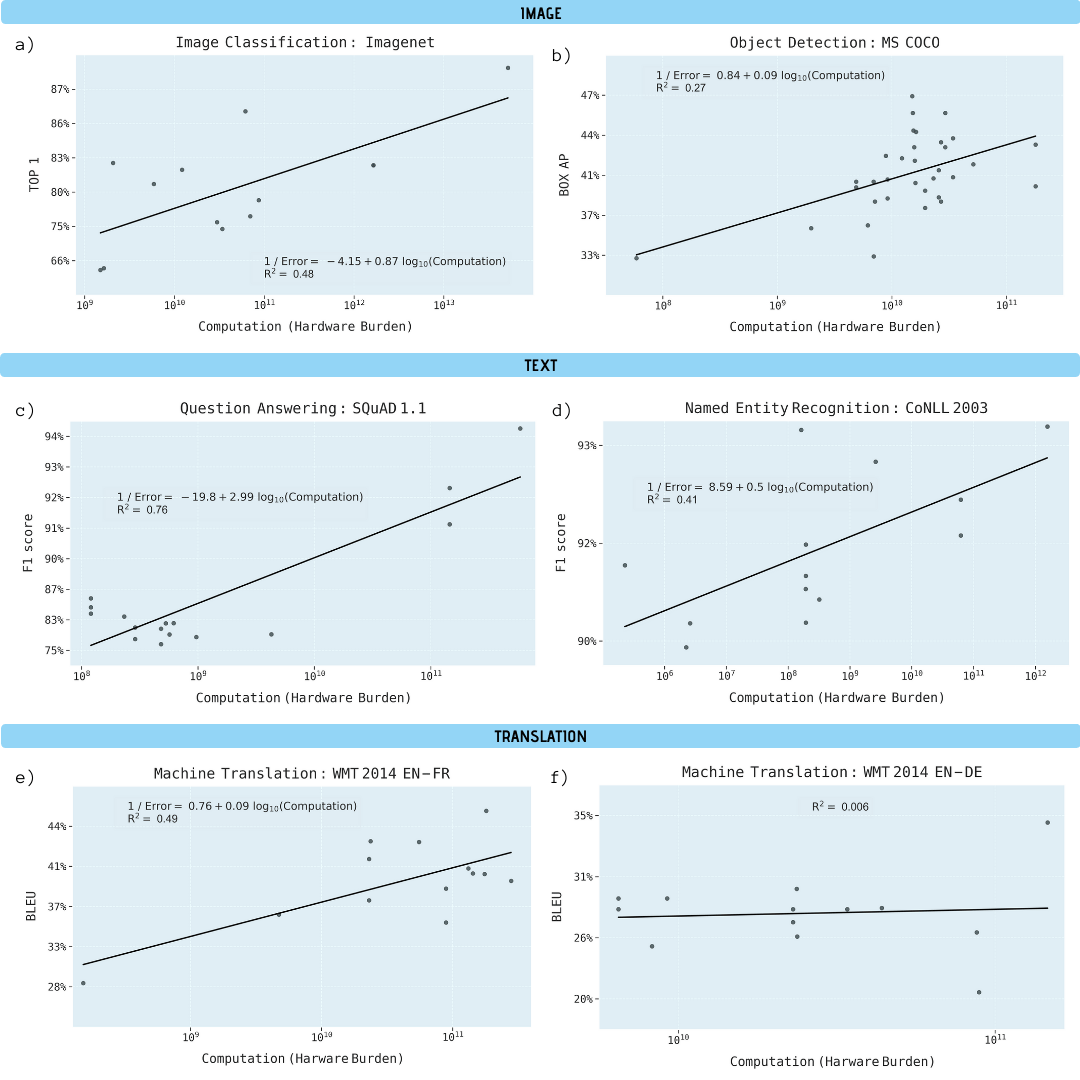
Leistungsverbesserung bei verschiedenen maschinellen Lernaufgaben in Abhängigkeit von der Rechenleistung des Lernmodells (in Gigaflops)
Warum ist maschinelles Lernen so abhängig von Rechenleistung?
Es gibt wichtige Gründe zu der Annahme, dass Deep Learning von Natur aus rechenabhängiger ist als andere Methoden. Insbesondere aufgrund der Rolle der Hyperparametrisierung und der Skalierung des Systems, wenn zusätzliche Trainingsdaten verwendet werden, um die Qualität des Ergebnisses zu verbessern (z. B. um die Rate von Klassifizierungsfehlern, den quadratischen mittleren Regressionsfehler usw. zu verringern).
Es wurde nachgewiesen, dass die Hyperparametrisierung erhebliche Vorteile bietet, dh die Implementierung neuronaler Netze mit mehr Parametern als der Anzahl der für das Training verfügbaren Datenpunkte. Klassischerweise würde dies zu einer Überanpassung führen. Stochastische Gradientenoptimierungstechniken bieten jedoch einen Regularisierungseffekt auf Kosten eines frühen Stopps, wodurch neuronale Netze in den Interpolationsmodus versetzt werden, in dem die Trainingsdaten fast genau passen, während an den Zwischenpunkten vernünftige Vorhersagen beibehalten werden. Ein Beispiel für große Netzwerke mit Hyperparametrisierung ist eines der besten Mustererkennungssysteme NoisyStudent mit 480 Millionen Parametern für 1,2 Millionen ImageNet-Datenpunkte.
Das Problem bei der Hyperparametrisierung besteht darin, dass die Anzahl der Deep-Learning-Parameter mit der Anzahl der Datenpunkte zunehmen muss. Da die Kosten für das Training eines Deep-Learning-Modells mit dem Produkt aus der Anzahl der Parameter und der Anzahl der Datenpunkte skalieren, bedeutet dies, dass der Rechenaufwand in einem hyperparametrisierten System um mindestens das Quadrat der Anzahl der Datenpunkte wächst. Die quadratische Skalierung schätzt noch nicht ausreichend ab, wie schnell Deep-Learning-Netzwerke wachsen müssen, da die Menge der Trainingsdaten viel schneller als linear skaliert werden muss, um lineare Leistungsverbesserungen zu erzielen.
Stellen Sie sich ein generatives Modell vor, das 10 von 1000 möglichen Werten ungleich Null hat, und betrachten Sie vier Modelle, um diese Parameter zu ermitteln:
- : 10
- : 9 1
- : 1000 ,
- : , 1000 , ()
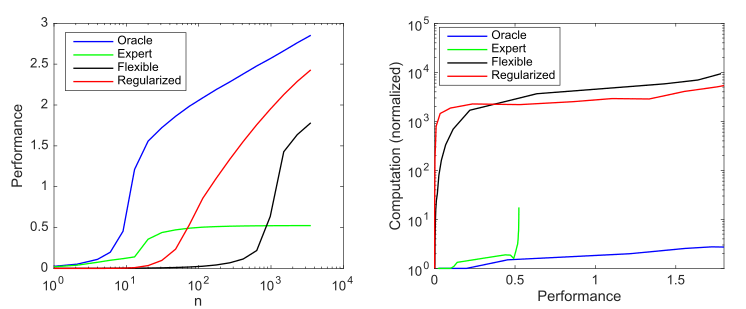
Einfluss der Modellkomplexität und Regularisierung auf die Modellleistung (gemessen als negativer log 10 normalisierter quadratischer Mittelwertfehler gegenüber dem optimalen Prädiktor) und auf die Rechenanforderungen, gemittelt über 1000 Simulationen pro Fall; a) durchschnittliche Produktivität mit zunehmender Stichprobengröße; b) Durchschnittliche Berechnung zur Verbesserung der Leistung
Diese Grafik fasst das von Andrew Ng skizzierte Prinzip zusammen: Traditionelle Methoden des maschinellen Lernens funktionieren besser mit kleinen Daten, aber flexible ML-Modelle funktionieren besser mit großen Datenmengen. Ein häufiges Phänomen bei agilen Modellen ist, dass sie ein höheres Potenzial haben, aber auch erheblich mehr Daten und Rechenanforderungen.
Wir können sehen, dass Deep Learning gut funktioniert, da es Hyperparametrisierung verwendet, um ein sehr flexibles Modell zu erstellen, und (implizite) Regularisierung, um die Komplexität der Stichproben auf ein akzeptables Maß zu reduzieren. Gleichzeitig ist Deep Learning jedoch wesentlich rechenintensiver als effizientere Modelle. Eine Erhöhung der Flexibilität von ML impliziert daher die Abhängigkeit von großen Datenmengen und Berechnungen.
Rechengrenzen
Die Computerleistung hat die Leistung von ML-Systemen immer begrenzt.
Zum Beispiel beschrieb Frank Rosenblatt 1960 das erste dreischichtige neuronale Netzwerk. Man hoffte, dass sie "die Möglichkeiten demonstrieren würde, das Perzeptron als Mustererkennungsgerät zu verwenden". Rosenblatt stellte jedoch fest, dass "mit zunehmender Anzahl von Verbindungen im Netzwerk die Belastung eines typischen digitalen Computers bald zu hoch wird". Später im Jahr 1969 erklärten Minsky und Papert die Einschränkungen von 3-Schicht-Netzwerken, einschließlich der Unfähigkeit, eine einfache XOR-Funktion zu erlernen. Sie stellten jedoch eine mögliche Lösung fest: „Die Experimentatoren haben einen interessanten Weg gefunden, um diese Schwierigkeit zu umgehen, indem sie längere Ketten von Zwischeneinheiten einführten“ (dh durch den Aufbau tieferer neuronaler Netze). Trotz dieser möglichen Problemumgehung wurde ein Großteil der akademischen Arbeit in diesem Bereich aufgegeben.denn zu dieser Zeit gab es einfach nicht genug Rechenleistung.
In den folgenden Jahrzehnten führten Verbesserungen der Hardware zu einer etwa 50.000-fachen Leistungssteigerung, und neuronale Netze erhöhten ihren Rechenbedarf proportional, wie in KDPV gezeigt. Da die Erhöhung der Rechenleistung um einen Dollar in etwa der Rechenleistung pro Chip entsprach, sind die wirtschaftlichen Kosten für den Betrieb solcher Modelle im Zeitverlauf weitgehend stabil geblieben.
Trotz dieser erheblichen CPU-Beschleunigung waren Deep-Learning-Modelle 2009 noch zu langsam für Großanwendungen. Dies zwang die Forscher, sich auf kleinere Modelle zu konzentrieren oder weniger Trainingsbeispiele zu verwenden.
Der Wendepunkt war die Übertragung von Deep Learning auf die GPU, was sofort zu einer Beschleunigung führte5-15 Mal , was bis 2012 auf 35 Mal angewachsen war und zu einem wichtigen Sieg für AlexNet im Imagenet-Wettbewerb 2012 führte . Die Bilderkennung war jedoch nur der erste Maßstab, an dem Deep-Learning-Systeme gewonnen haben. Sie siegten bald bei der Objekterkennung, der Erkennung von benannten Entitäten, der maschinellen Übersetzung, der Beantwortung von Fragen und der Spracherkennung.
Die Einführung von Deep Learning auf GPUs (und dann auf ASICs) führte zu einer breiten Akzeptanz dieser Systeme. Die Rechenleistung in modernen ML-Systemen wuchs jedoch noch schneller, von 2012 bis 2019 etwa zehnmal im Jahr. Diese Geschwindigkeit ist viel schneller als die allgemeine Verbesserung von der Umstellung auf GPUs, der bescheidene Gewinn aus dem letzten Atemzug von Moores Gesetz oder aus der gesteigerten Effizienz des Trainings neuronaler Netze.
Stattdessen wurde der Hauptgewinn bei der ML-Effizienz dadurch erzielt, dass Modelle über längere Zeiträume auf mehr Maschinen ausgeführt wurden. Zum Beispiel trainierte AlexNet 2012 5-6 Tage lang auf zwei GPUs, 2017 ResNeXt-101 über 10 Tage lang auf acht GPUs und 2019 NoisyStudent 6 Tage lang auf ungefähr tausend TPUs. Ein weiteres extremes Beispiel ist das maschinelle Übersetzungssystem Evolved Transformer , das mehr als 2 Millionen GPU-Stunden für Schulungen benötigte und Millionen von Dollar kostete.
Das Skalieren von Deep-Learning-Berechnungen durch Erhöhen der Hardwaretakte oder mehr Chips ist auf lange Sicht problematisch. Denn dies impliziert, dass die Kosten in etwa gleich hoch sind wie die Erhöhung der Rechenleistung, und dies macht ein weiteres Wachstum schnell unmöglich.
Zukunft
Traurige Schlussfolgerung aus dem oben Gesagten.
Die folgende Tabelle zeigt, wie viel Rechenleistung und Kosten des Systems bestimmte Ziele bei ML-Problemen erreichen, wenn wir aus den aktuellen Modellen extrapolieren. Maschinelles Lernen wird auf den leistungsstärksten Supercomputern ausgeführt. Die Autoren der wissenschaftlichen Arbeit glauben, dass die Anforderungen an die gesetzten Ziele nicht erfüllt werden . Obwohl sie theoretisch mögliche Optionen in Betracht ziehen, um sie zu erreichen: Verbesserung der Effizienz ohne Leistungssteigerung, Hardwarebeschleuniger wie TPU und FPGA, neuromorphes Computing, Quantencomputer und andere, können Sie (noch) keine dieser Technologien die Rechengrenzen von ML überwinden.

. .
