Angenommen, wir haben ein Register von Dokumenten, mit denen Bediener oder Buchhalter in VLSI arbeiten , wie folgt: Traditionell verwendet eine solche Anzeige entweder eine direkte (neue Unterseite) oder eine umgekehrte (neue Oberseite) Sortierung nach Datum und Ordnungskennung, die beim Erstellen eines Dokuments zugewiesen wird - oder ... Die typischen Probleme, die in diesem Fall auftreten, habe ich bereits im Artikel PostgreSQL Antipatterns: Navigieren in der Registrierung erörtert . Was aber, wenn der Benutzer aus irgendeinem Grund "atypisch" sein wollte - zum Beispiel ein Feld "so" und ein anderes "so" sortieren -

ORDER BY dt, idORDER BY dt DESC, id DESC
ORDER BY dt, id DESC? Wir möchten den zweiten Index jedoch nicht erstellen, da er das Einfügen und das zusätzliche Volumen in der Datenbank verlangsamt.
Ist es möglich, dieses Problem nur mit dem Index effektiv zu lösen
(dt, id)?
Lassen Sie uns zunächst skizzieren, wie unser Index geordnet ist:
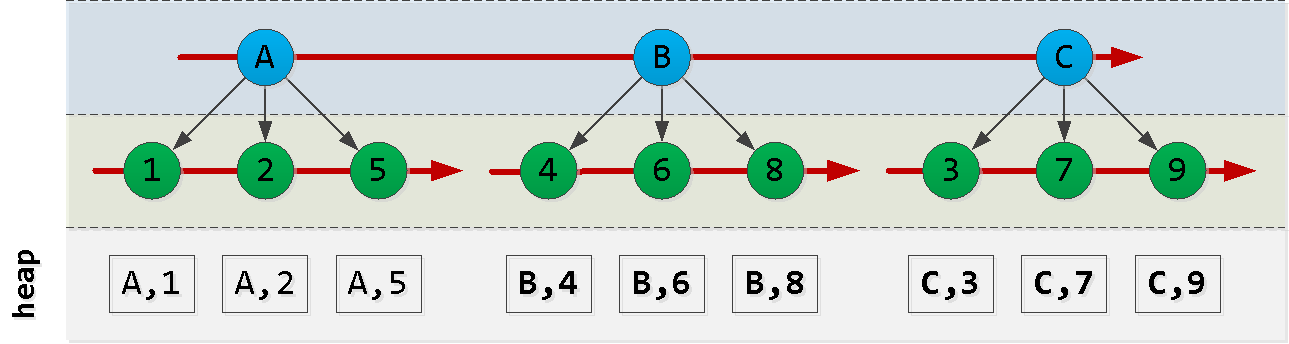
Beachten Sie, dass die Reihenfolge, in der die ID-Einträge erstellt werden, nicht unbedingt mit der Reihenfolge von dt übereinstimmt, sodass wir uns nicht darauf verlassen können und etwas erfinden müssen.
Nehmen wir nun an, wir sind an Punkt (A, 2) und möchten die "nächsten" 6 Einträge in der Sortierung lesen : Aha! Wir haben ein "Stück" vom ersten Knoten , ein anderes "Stück" vom letzten Knoten und alle Datensätze von den Knoten zwischen ihnen ausgewählt ( ). Jeder dieser Blöcke wird trotz der nicht ganz geeigneten Reihenfolge recht erfolgreich vom Index gelesen . Versuchen wir, eine Abfrage wie folgt zu erstellen:
ORDER BY dt, id DESC
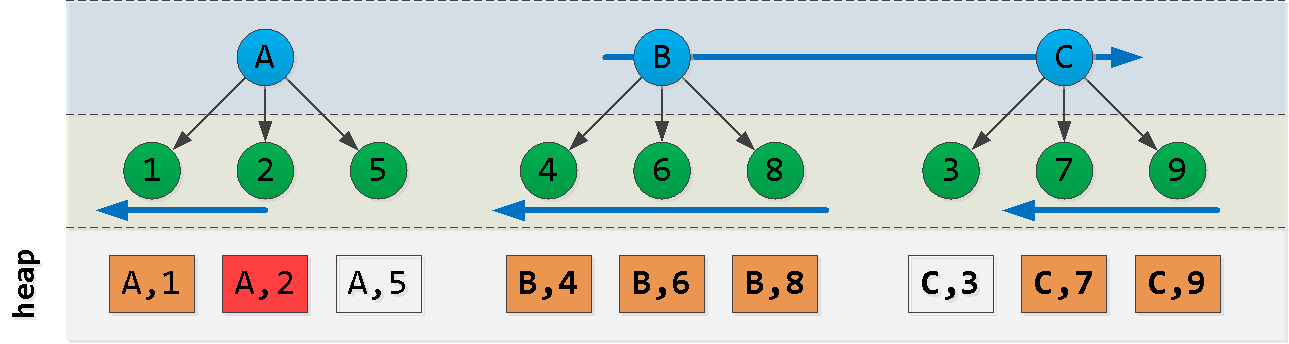
ACB(dt, id)
- Zuerst lesen wir aus Block A "links" des Startdatensatzes - wir erhalten
NDatensätze - weiter lesen wir
L - N"rechts" vom Wert A. - Finden Sie im letzten Block den Maximalschlüssel C.
- Filtern Sie mit dieser Taste alle Datensätze aus der vorherigen Auswahl heraus und subtrahieren Sie sie "rechts".
Versuchen wir nun, den Code darzustellen und das Modell zu überprüfen:
CREATE TABLE doc(
id
serial
, dt
date
);
CREATE INDEX ON doc(dt, id); --
-- ""
INSERT INTO doc(dt)
SELECT
now()::date - (random() * 365)::integer
FROM
generate_series(1, 10000);Um die Anzahl der bereits gelesenen Datensätze und die Differenz zwischen dieser und der Zielnummer nicht zu berechnen, werden wir PostgreSQL dazu zwingen, dies mit einem "Hack" zu tun
UNION ALLund LIMIT:
(
... LIMIT 100
)
UNION ALL
(
... LIMIT 100
)
LIMIT 100Sammeln wir nun die folgenden 100 Datensätze mit Zielsortierung aus dem letzten bekannten Wert:
(dt, id DESC)
WITH src AS (
SELECT
'{"dt" : "2019-09-07", "id" : 2331}'::json -- ""
)
, pre AS (
(
( -- 100 "" "" A
SELECT
*
FROM
doc
WHERE
dt = ((TABLE src) ->> 'dt')::date AND
id < ((TABLE src) ->> 'id')::integer
ORDER BY
dt DESC, id DESC
LIMIT 100
)
UNION ALL
( -- 100 "" "" A -> B, C
SELECT
*
FROM
doc
WHERE
dt > ((TABLE src) ->> 'dt')::date
ORDER BY
dt, id
LIMIT 100
)
)
LIMIT 100
)
-- C ,
, maxdt AS (
SELECT
max(dt)
FROM
pre
WHERE
dt > ((TABLE src) ->> 'dt')::date
)
( -- "" C
SELECT
*
FROM
pre
WHERE
dt <> (TABLE maxdt)
ORDER BY
dt, id DESC -- , B
LIMIT 100
)
UNION ALL
( -- "" C 100
SELECT
*
FROM
doc
WHERE
dt = (TABLE maxdt)
ORDER BY
dt, id DESC
LIMIT 100
)
LIMIT 100;Mal sehen, was passiert ist in Bezug auf:

[siehe EXPLAIN.tensor.ru]
- Also
A = '2019-09-07'lesen wir 3 Datensätze mit dem ersten Schlüssel . - Sie beendeten das Lesen weiterer 97 von
BundCaufgrund des genauen TreffersIndex Scan. - Unter allen Datensätzen wurden 18 nach dem Maximalschlüssel gefiltert
C. - Wir lesen 23 Datensätze (anstelle von 18 gesuchten
Bitmap Scan) mit dem Maximalschlüssel. - Alle haben die Ziel-100-Datensätze neu sortiert und zugeschnitten.
- ... und alles dauerte weniger als eine Millisekunde!
Die Methode ist natürlich nicht universell und mit Indizes für eine größere Anzahl von Feldern wird sie zu etwas wirklich Schrecklichem. Wenn Sie dem Benutzer jedoch eine "nicht standardmäßige" Sortierung geben möchten, ohne die Basis in
Seq Scaneine große Tabelle "zu reduzieren" , können Sie sie vorsichtig verwenden.