Fast jedes Unternehmen ist mit einer schwebenden Last konfrontiert: jetzt Stille, dann ein Gewitter. Für Beispiele muss man nicht weit gehen:
- Der Online-Shop-Verkehr kann je nach Tageszeit oder Jahreszeit erheblich schwanken.
- Interne Dienste von Unternehmen können wochenlang "leer" sein, und am Vorabend der Einreichung des Quartalsberichts wird ihre Teilnahme stark ansteigen.
Im Rahmen des Schnitts werden wir darüber sprechen, wie wir unseren Kunden bei der Lösung dieses Problems geholfen haben, indem wir eine neue Speicherebene mit benutzerdefinierten IOPS eingeführt haben.
Ein paar Worte zu Festplatten
Alle unsere Kunden wünschen sich Plus oder Minus - eine zuverlässige Infrastruktur, die die Anforderungen von Geschäftsprozessen zu einem guten Preis erfüllt. Dementsprechend stehen wir als Cloud-Anbieter vor der Aufgabe, Services und Services so aufzubauen, dass wir für jeden Kunden leicht die optimale Lösung finden können.
Zuvor hatten wir zwei Speicherebenen: st2 und gp2. Die Zahl "2" in unserer internen Terminologie bedeutet eine neuere, verbesserte Version.
st2: Standard (HDD) - Gemächliche und kostengünstige SAS-HDD-Medien. Hervorragend geeignet für Dienste, bei denen IOPS nicht kritisch ist, die Bandbreite jedoch wichtig ist.
Ihre Parameter sind wie folgt: Antwortzeit - nicht mehr als 10 ms, Leistung von Festplatten bis zu 2000 GB - 500 IOPS, von 2000 GB - 1000 IOPS, und die Bandbreite wächst mit jedem Gigabyte und erreicht 500 MB / s für dieselben 2000 GB.
gp2: Universal (SSD) - Teurere und schnellere SAS-SSD-Laufwerke. Geeignet für Kunden, deren Anwendungen in Bezug auf IOPS anspruchsvoller sind. Zum Beispiel - Datenbanken von Online-Shops.
Gp2-Parameter werden im SLA angegeben. Die Leistung in IOPS wird nach Volumen berechnet - es gibt 10 IOPS pro GB. Die obere Leiste ist 10.000 IOPS. Die Reaktionszeit solcher Festplatten beträgt nicht mehr als 2 ms. Dies ist eine ziemlich hohe Leistung, die 97% der Geschäftsaufgaben erledigen kann.
Im Laufe der jahrelangen Arbeit haben wir viele Statistiken und Fachkenntnisse in Bezug auf Kunden gesammelt und festgestellt, dass einige von ihnen nicht ganz bequem zwischen zwei Antriebsoptionen wählen können. Zum Beispiel könnte jemand eine bessere Leistung als 10 IOPS pro Gigabyte wünschen. Oder eine schwimmende Last macht es nicht möglich, bei einem der Typen anzuhalten und für die Hauptverkehrszeit zu bezahlen, aber periodische Leerlaufkapazitäten sind ebenfalls keine Option.
Sie können einen einfachen aktuellen Fall simulieren. Während der Pandemie musste ein Unternehmen Ausweise für Mitarbeiter ausstellen. Damit sie sicher in Moskau herumfahren können. Das Personal ist groß, zweitausend Menschen. Es wurde der Auftrag erteilt, personenbezogene Daten im CRM-System des Unternehmens dringend zu aktualisieren. Gesagt, getan. Mehr als tausend Menschen eilten gleichzeitig, um die Informationen zu aktualisieren. Aber sparsame Leute beschäftigten sich mit CRM. Es wurde wenig Kapazität zugewiesen. Niemand hatte erwartet, dass mehr als zehn Menschen gleichzeitig hineinklettern würden! Alles fiel und konnte sich für einen weiteren Tag nicht erheben. Geschäftsprozesse wurden gestört, Menschen sitzen zu Hause und haben Angst vor Geldstrafen. Und wenn es die Möglichkeit gäbe, die Leistung von Festplatten in der Cloud flexibel zu "optimieren", würden sie die IOPS für kurze Zeit erhöhen und sie dann so zurückgeben, wie sie waren, wodurch die CRM-Ausfallzeiten beseitigt oder erheblich reduziert würden.
Einerseits ist die Situation grotesk, der Prozentsatz der Kunden mit solchen Bedürfnissen ist nicht sehr groß. Ein kleiner Anbieter würde seine Existenz sogar als statistische Anomalie betrachten und keine Maßnahmen ergreifen. Auf der anderen Seite können wir durch die Organisation einer neuen Speicherebene die Flexibilität der Dienste für alle Kunden erhöhen. Das heißt, wir müssen es tun.
Wenn Sie unseren Blog schon lange verfolgen, erinnern Sie sich wahrscheinlich an den Artikel, in dem wir über eine Reihe von Experimenten mit Dell EMC ScaleIO (jetzt PowerFlex OS) und dessen Implementierung in der CROC Cloud gesprochen haben. Wie auch immer, wir empfehlen Ihnen, sich für ein allgemeines Verständnis damit vertraut zu machen.
Nehmen wir allgemein an: ScaleIO (DellEMC wurde zuerst in ScaleIO in VxFlex OS und ab dem 25. Juni 2020 in PowerFlex OS umbenannt) ist ein äußerst vielseitiger und zuverlässiger SDS für softwaredefinierten Speicher. Zuverlässigkeit ist unsere Anforderung Nr. 0. Daher wird jeder Knoten, der Teil des Speicherpools ist, in einem separaten Rack installiert, wodurch die Möglichkeit eines Datenverlusts bei einem teilweisen Stromausfall im Rechenzentrum oder lokal im Rack ausgeschlossen wird.
Wenn eine Festplatte, ein Server oder ein ganzes Rack ausfällt, haben wir genügend Zeit, um die Daten auf andere Hosts zu replizieren und anschließend das ausgefallene Element zu ersetzen. Wenn zwei Racks gleichzeitig sterben, geht sowieso nichts verloren. In dieser Situation wechselt der Cluster in den Notfallmodus, das Schreiben und Lesen von Daten von Datenträgern wird eingeschränkt. Nach der Wiederherstellung der Konnektivität mit dem "heruntergefallenen" Rack übernimmt PowerFlex OS selbst den Prozess der Datenwiederherstellung und Clusterwiederherstellung. Dieser Vorgang dauert übrigens meistens nicht länger als ein paar Minuten.
Dies ist natürlich eine Notsituation - Anwendungen, die nicht lesen und schreiben können, fallen sofort ab, aber der Verlust selbst eines so großen Teils der Infrastruktur zerstört die Daten nicht. Obwohl die Ausfallwahrscheinlichkeit von zwei Gestellen in verschiedenen Teilen der Turbinenhalle äußerst gering ist, bedeutet dies nicht, dass dies nicht berücksichtigt werden sollte.
In Bezug auf die Vielseitigkeit ist PowerFlex OS (ehemals ScaleIO) auch ideal für unsere Anforderungen. Tatsächlich ist dies ein Konstruktor, der bereit ist, jede Arbeitslast zu akzeptieren und langsame SATA / SAS-Festplatten, schnelle SSDs und ultraschnelle NVME-Laufwerke "akzeptieren" kann. Und das ist wirklich wahr - es wurde auf zahlreichen Bühnen- und Testständen von Entwicklungs- und Wartungsteams getestet. Sie können einen Cluster praktisch aus
Musik von fünf bis sechs
Schauen wir uns eines der Szenarien an, in denen ein Kunde möglicherweise eine flexible Leistung anhand eines Beispiels aus der Praxis benötigt. Zu unseren Kunden gehört ein Netzwerk von Musikinstrumentengeschäften. Die Techniker des Unternehmens verfolgen, wie viele Besucher ihre Website täglich und zu jeder Stunde besuchen. Dies spiegelt sich sogar in unserer SLA wider: Von 17:00 bis 18:00 Uhr empfängt das Geschäft die maximale Anzahl von Kunden, sodass keine technischen Arbeiten oder Ausfallzeiten auftreten sollten.
Die Standardberechnungspraxis besteht darin, dass 100% der Last in 24 Stunden aufgeteilt werden. Es stellt sich ungefähr 4% pro Stunde heraus. Für eine Kette von Musikgeschäften "wiegt" diese bestimmte Stunde nicht 4, sondern 10% - das sind Zehntausende von Besuchern und Kunden.
Dementsprechend wäre es für den Kunden sehr bequem, wenn in dieser "goldenen" Stunde ihre Festplatten schneller würden als durch Zauberei,
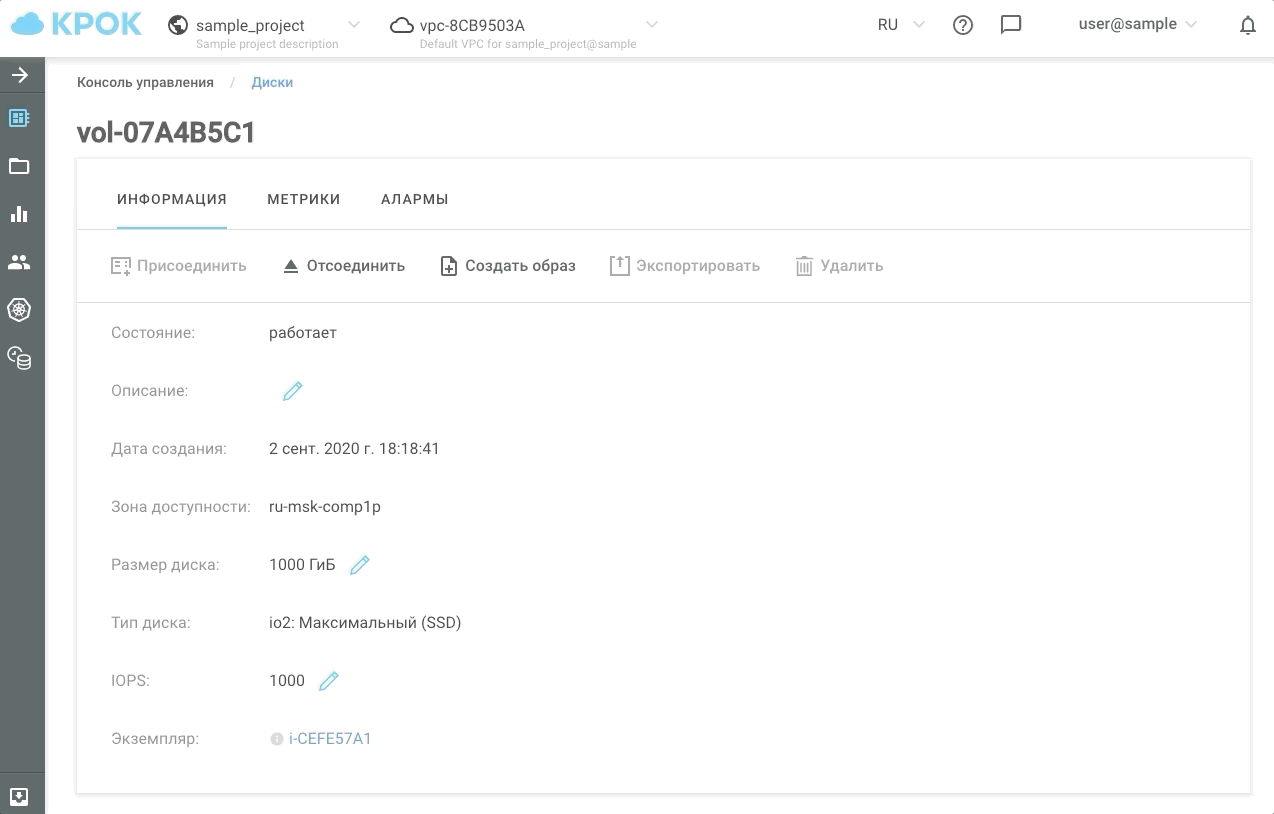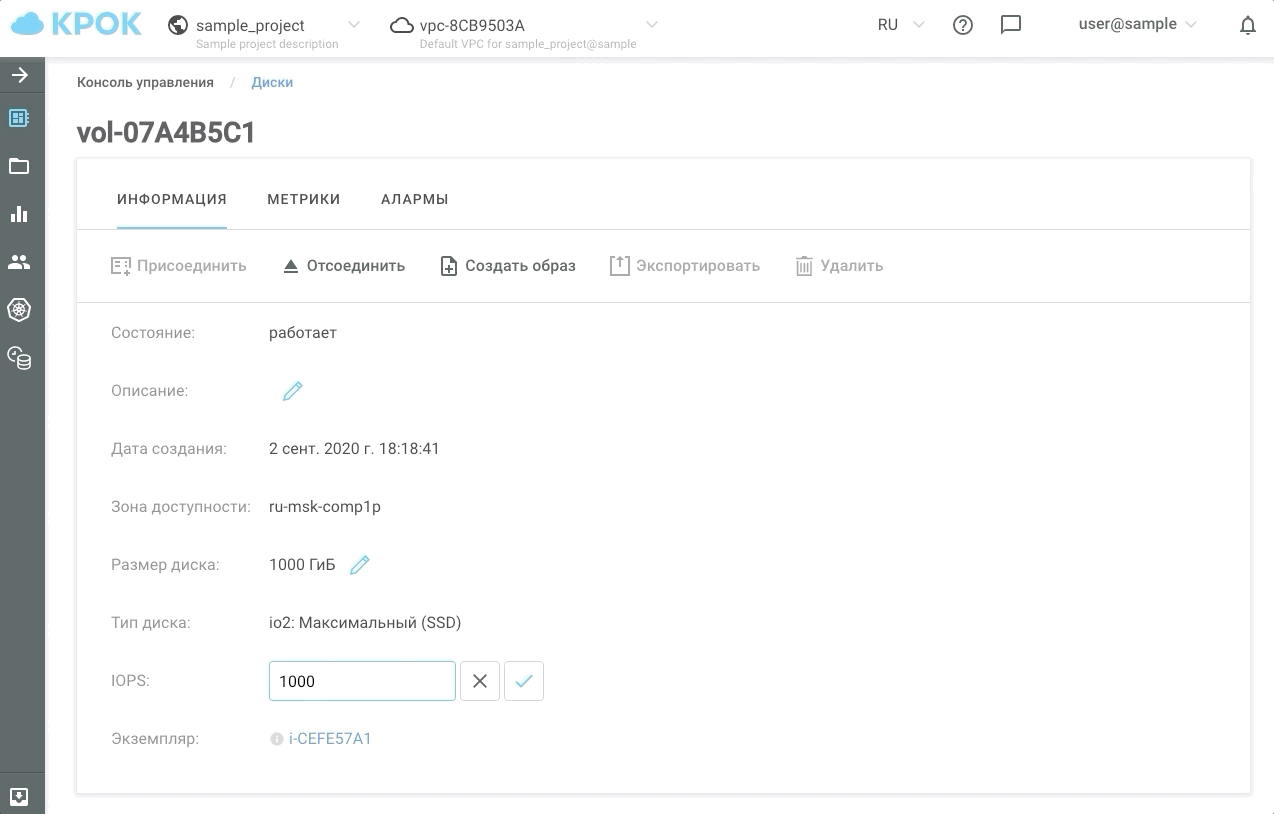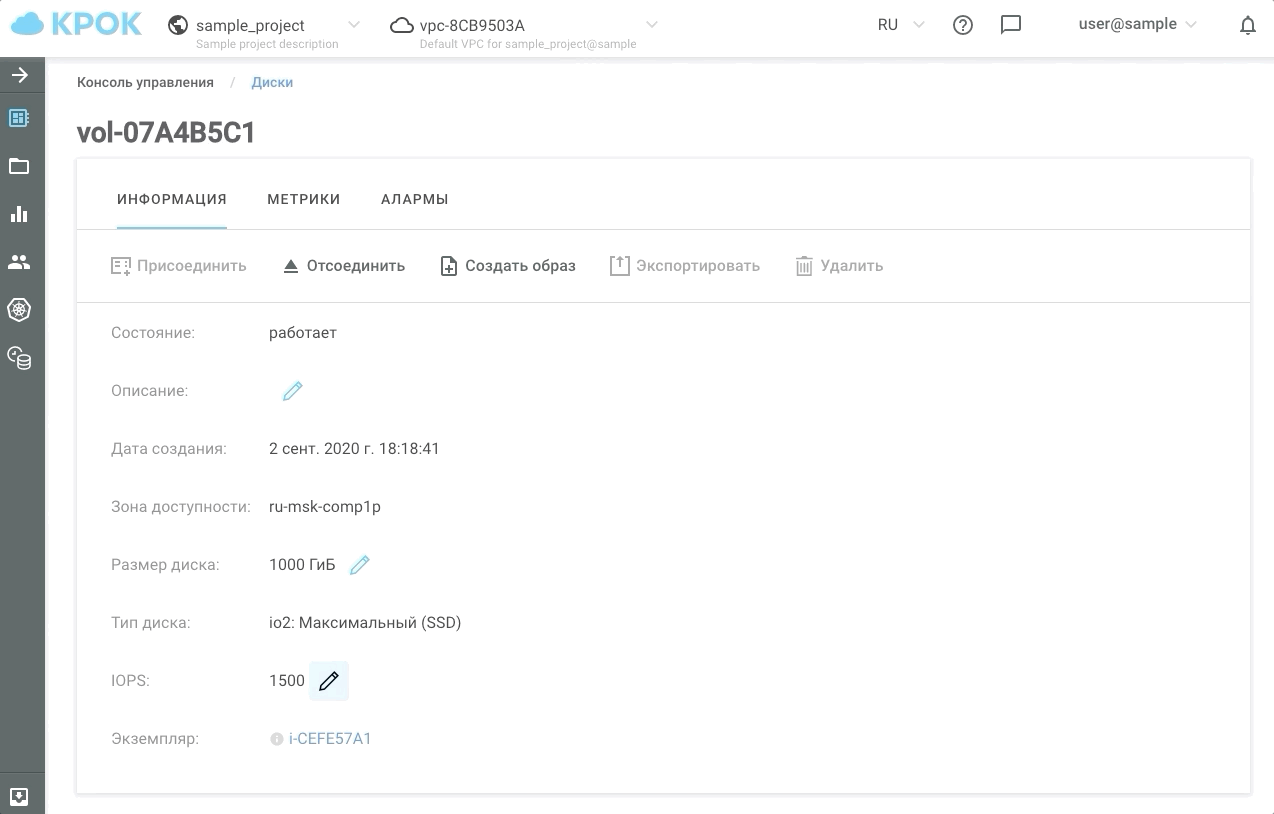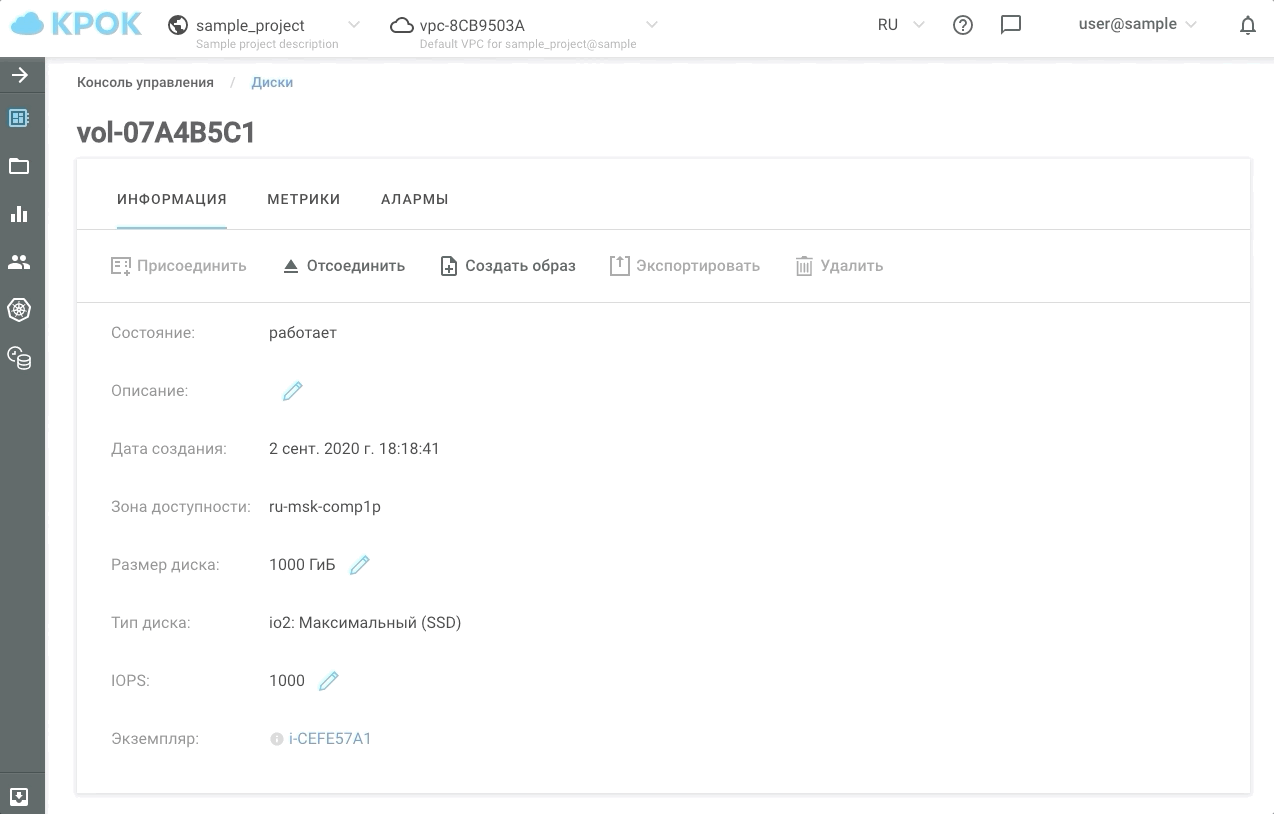
Jetzt haben wir die Möglichkeit, Kunden während der geschäftigsten Stunden mindestens 30, mindestens 50.000 IOPS und in der restlichen Zeit die Leistung auf dem üblichen Niveau zu halten. Wir haben diese Art von Speicher io2: Ultimate (SSD) genannt. Die Antwortzeit von Festplatten, die auf dieser Art von Speicher basieren, beträgt nicht mehr als 1 ms!
Und noch einmal zur Zuverlässigkeit: st2, gp2 und das neue io2 sind unabhängig voneinander, unabhängig voneinander Speicherpools in einem PowerFlex-Cluster.
Wenn der Client früher eine Festplatte ausgewählt und eine feste Leistung erhalten hat, kann er diese jetzt auswählen und konfigurieren. Unabhängig von der Lautstärke. Die Philosophie lautet wie folgt: Sie können eine große und schnelle Festplatte von einer großen Anzahl von Anbietern erhalten, sind aber bereit, 100% der Zeit dafür zu bezahlen?
Wie man verwaltet
Es gibt zwei Möglichkeiten, die Leistung zu verwalten: die altmodische Methode über die Weboberfläche und die Verwendung der API. Dies ermöglicht es, einfache Skripte zu schreiben, die Festplatten nach einem Zeitplan "beschleunigen" oder "verlangsamen" und dementsprechend Geld sparen.
Während wir früher die vom Kunden benötigte Ladung aufnehmen konnten, können wir dies jetzt zum besten Preis tun.
So sieht es in der Praxis aus.
Die Verbesserung der Anpassungsfähigkeit der Cloud-Infrastruktur ist ein relevanter und sehr korrekter Trend. Sie können dem Kunden nicht sagen: "Nehmen Sie, was er gibt, oder auch das wird nicht passieren!" Er muss entscheiden können, welche Ressourcen wann und wie viel er benötigt. Die Zukunft liegt in solchen flexiblen und zuverlässigen Lösungen.
Wir bürgen für unsere Dienstleistungen: Alle Parameter sind im SLA festgelegt, und Sie können sich darauf verlassen, dass die „Papier“ -Zahlen nicht von den tatsächlichen abweichen.
Und wie Sie Ihren Cloud-Anbieter überprüfen, haben wir bereits im vorherigen Artikel geschrieben .