
Wir sind wieder in der Luft und setzen die Notizenreihe von Data Scientist fort. Heute präsentiere ich meine absolut subjektive Checkliste für die Auswahl eines Modells für maschinelles Lernen.
Dies sind die Top 10 Eigenschaften des Problems und nur Punkte (ohne Reihenfolge in ihnen), aus deren Sicht ich anfange, ein Modell auszuwählen und im Allgemeinen eine Datenanalyseaufgabe zu modellieren.
Es ist überhaupt nicht notwendig, dass Sie es gleich haben - hier ist alles subjektiv, aber ich teile meine Erfahrungen aus dem Leben.
Was ist unser Ziel im Allgemeinen? Interpretierbarkeit und Genauigkeit - Spektrum

Quelle Die
vielleicht wichtigste Frage, mit der ein Data Scientist vor Beginn der Modellierung konfrontiert ist, lautet:
Was genau ist eine Geschäftsaufgabe?
Oder Forschung, wenn wir über die Akademie sprechen, etc.
Zum Beispiel benötigen wir Analysen basierend auf einem Datenmodell oder umgekehrt. Wir sind nur an qualitativen Vorhersagen der Wahrscheinlichkeit interessiert, dass eine E-Mail Spam ist.
Das klassische Gleichgewicht, das ich gesehen habe, ist das Spektrum zwischen der Interpretierbarkeit der Methode und ihrer Genauigkeit (wie in der obigen Grafik).
Tatsächlich müssen Sie jedoch nicht nur Catboost / Xgboost / Random Forest fahren und ein Modell auswählen, sondern auch verstehen, was das Unternehmen will, welche Daten wir haben und wie sie angewendet werden.
In meiner Praxis wird dies sofort einen Punkt im Spektrum der Interpretierbarkeit und Genauigkeit setzen (was auch immer das hier bedeutet). Und auf dieser Grundlage kann man bereits über Methoden zur Modellierung des Problems nachdenken.
Der Typ der Aufgabe selbst
Nachdem wir verstanden haben, was das Unternehmen will, müssen wir außerdem verstehen, zu welchen mathematischen Problemen des maschinellen Lernens wir beispielsweise gehören
- Explorative Analyse - reine Analyse der verfügbaren Daten und Aufkleben
- Clustering - Sammeln Sie Daten in Gruppen basierend auf einigen gemeinsamen Attributen.
- Regression - Sie müssen ein ganzzahliges Ergebnis zurückgeben, da sonst die Wahrscheinlichkeit eines Ereignisses besteht
- Klassifizierung - Sie müssen eine Klassenbezeichnung zurückgeben
- Multi-Label - Sie müssen für jeden Eintrag ein oder mehrere Klassen-Labels zurückgeben
Beispiele
Daten: Es gibt zwei Klassen und ein unbeschriftetes Recordset:

Und Sie müssen ein Modell erstellen, das genau diese Daten kennzeichnet:

Optional gibt es keine Beschriftungen und Sie müssen die Gruppen auswählen:

Wie hier:
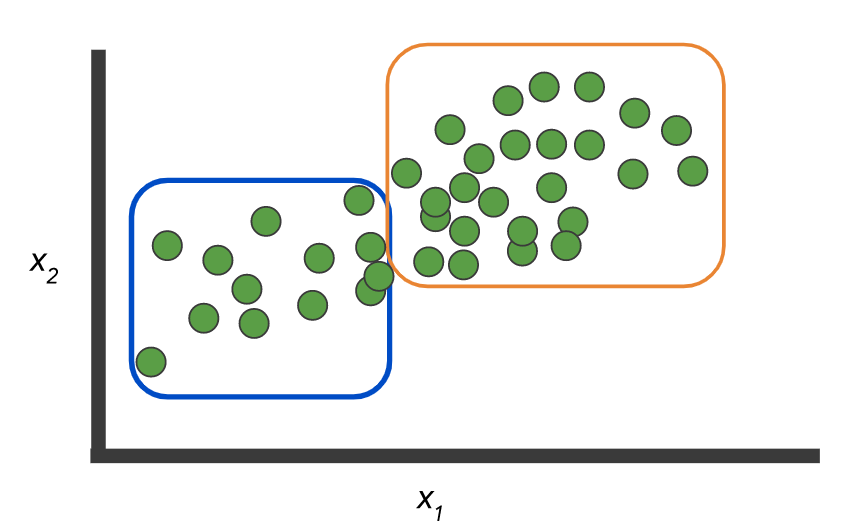
Bilder von hier .
Das Beispiel selbst zeigt jedoch den Unterschied zwischen den beiden Konzepten: Klassifizierung, wenn N> 2 Klassen - Mehrfachklasse vs. Multi-Label
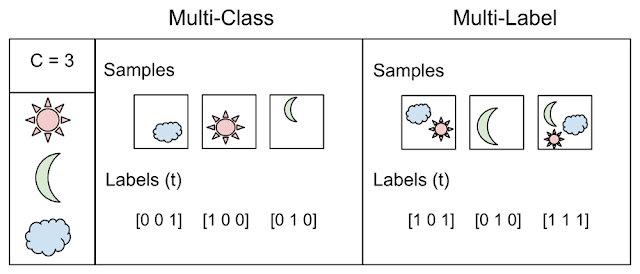
Von hier aus
Sie werden überrascht sein, aber sehr oft lohnt es sich auch, direkt mit dem Unternehmen zu sprechen - dies kann Ihnen wirklich viel Zeit und Mühe sparen. Fühlen Sie sich frei, Bilder zu zeichnen und einfache Beispiele zu nennen (aber nicht zu simpel).
Genauigkeit und wie sie bestimmt wird
Ich beginne mit einem einfachen Beispiel: Wenn Sie eine Bank sind und einen Kredit vergeben, verlieren wir bei einem erfolglosen Kredit fünfmal mehr als bei einem erfolgreichen.
Daher ist die Frage der Messung der Arbeitsqualität vorrangig! Oder stellen Sie sich vor, Sie haben ein signifikantes Ungleichgewicht in den Daten, Klasse A = 10% und Klasse B = 90%. Dann ist ein Klassifikator, der einfach B zurückgibt, immer zu 90% genau! Dies ist höchstwahrscheinlich nicht das, was Sie beim Training des Modells sehen wollten.
Daher ist es wichtig, eine Modellbewertungsmetrik zu definieren, die Folgendes umfasst:
- Gewichtsklasse - wie im obigen Beispiel beträgt der schlechte Kredit 5 und der gute Kredit 1
- Kostenmatrix - es ist möglich, niedriges und mittleres Risiko zu verwechseln - das spielt keine Rolle, aber geringes Risiko und hohes Risiko sind bereits ein Problem
- Sollte die Metrik das Gleichgewicht widerspiegeln? wie ROC AUC
- Zählen wir im Allgemeinen Wahrscheinlichkeiten oder sind Klassenbezeichnungen gerade?
- Oder vielleicht ist die Klasse im Allgemeinen "eins" und wir haben Präzision / Rückruf und andere Spielregeln?
Im Allgemeinen wird die Auswahl einer Metrik von der Aufgabe und ihrer Formulierung bestimmt - und für diejenigen, die diese Aufgabe festlegen (normalerweise Geschäftsleute), müssen all diese Details geklärt und geklärt werden, da sonst Nähte an der Ausgabe entstehen.
Modell nach der Analyse
Es ist häufig erforderlich, Analysen basierend auf dem Modell selbst durchzuführen. Was ist beispielsweise der Beitrag verschiedener Merkmale zum ursprünglichen Ergebnis: In der Regel können die meisten Methoden etwas Ähnliches erzeugen:
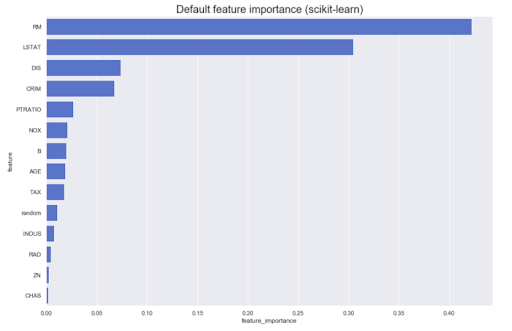
Was aber, wenn wir die Richtung kennen müssen - große Werte des Attributs A erhöhen die Zugehörigkeit zur Klasse Z oder umgekehrt? Nennen wir sie gerichtete Merkmalsbedeutung - sie können aus einigen Modellen erhalten werden, beispielsweise linear (durch Koeffizienten für normalisierte Daten).
Für eine Reihe von Modellen, die auf Bäumen und Boosting basieren, ist beispielsweise die SHapley Additive exPlanations-Methode geeignet.
SHAP
Dies ist eine der Modellanalysemethoden, mit der Sie unter die Haube des Modells schauen können.
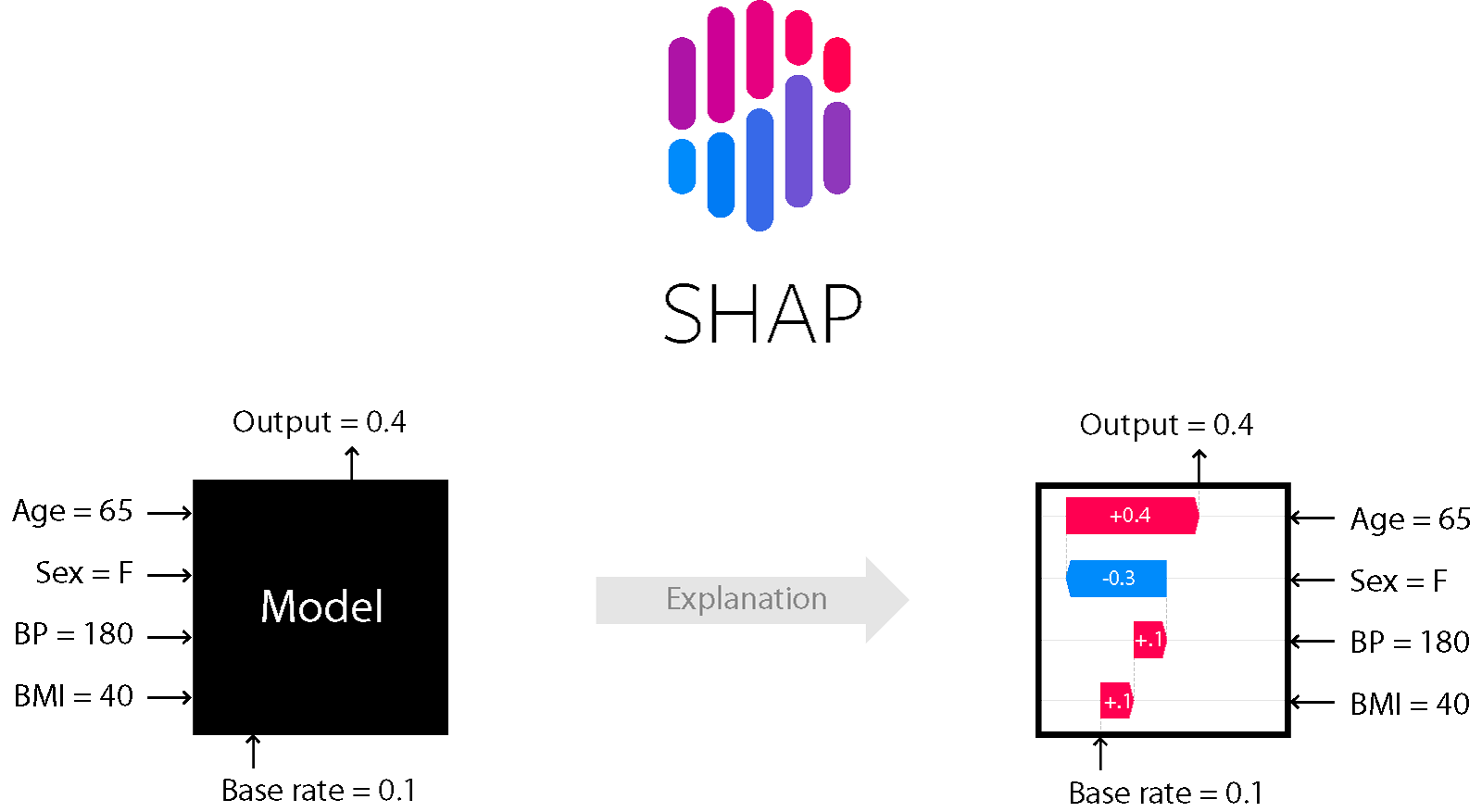
Hier können Sie die Richtung des Effekts beurteilen:

Darüber hinaus ist es für Bäume (und darauf basierende Methoden) genau. Lesen Sie mehr dazu hier .
Geräuschpegel - Stabilität, lineare Abhängigkeit, Ausreißererkennung usw.
Der Widerstand gegen Lärm und all diese Freuden des Lebens ist ein separates Thema, und Sie müssen den Geräuschpegel sorgfältig analysieren und die geeigneten Methoden auswählen. Wenn Sie sicher sind, dass die Daten Ausreißer enthalten, müssen Sie sie mit hoher Qualität bereinigen und rauschresistente Methoden anwenden (hohe Vorspannung, Regularisierung usw.).
Auch Zeichen können kollinear sein und bedeutungslose Zeichen können vorhanden sein - verschiedene Modelle reagieren unterschiedlich darauf. Lassen Sie uns ein Beispiel für den klassischen UCI-Datensatz (German Credit Data) und drei einfache (relativ) Lernmodelle geben:
- Ridge-Regressionsklassifikator: Klassische Regression mit Tikhonovs Regularisierer
- Entscheidungsbäume
- CatBoost von Yandex
Ridge Regression
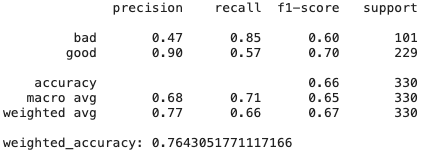
# Create Ridge regression classifier
ridge_clf = RidgeClassifier(class_weight=class_weight, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(pd.get_dummies(X), y, test_size=0.33, random_state=42)
# Train model
ridge_model = ridge_clf.fit(X_train, y_train)
y_pred = ridge_model.predict(X_test)
print(classification_report(y_test,y_pred))
print("weighted_accuracy:",weighted_accuracy(y_test,y_pred))
Entscheidungsbäume
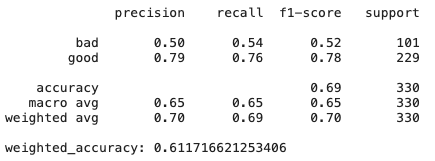
# Create Ridge regression classifier
dt_clf = DecisionTreeClassifier(class_weight=class_weight, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(pd.get_dummies(X), y, test_size=0.33, random_state=42)
# Train model
dt_model = dt_clf.fit(X_train, y_train)
y_pred = dt_model.predict(X_test)
print(classification_report(y_test,y_pred))
print("weighted_accuracy:", weighted_accuracy(y_test,y_pred))
CatBoost

# Create boosting classifier
catboost_clf = CatBoostClassifier(class_weights=class_weight, random_state=42, cat_features = X.select_dtypes(include=['category', object]).columns)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
# Train model
catboost_model = catboost_clf.fit(X_train, y_train, verbose=False)
y_pred = catboost_model.predict(X_test)
print(classification_report(y_test,y_pred))
print("weighted_accuracy:",weighted_accuracy(y_test,y_pred))
Wie wir sehen können, zeigt einfach das Ridge-Regressionsmodell, das eine hohe Verzerrung und Regularisierung aufweist, Ergebnisse noch besser als CatBoost - es gibt viele Funktionen, die nicht sehr nützlich und kollinear sind, daher zeigen Methoden, die gegen sie resistent sind, gute Ergebnisse.
Mehr über DT - was ist, wenn Sie den Datensatz ein wenig ändern? Die Wichtigkeit von Merkmalen kann variieren, da Entscheidungsbäume im Allgemeinen sensible Methoden sind, selbst für das Mischen von Daten.
Fazit: Manchmal ist einfacher besser und effektiver.
Skalierbarkeit
Benötigen Sie wirklich Spark oder neuronale Netze mit Milliarden von Parametern?
Erstens müssen Sie die Datenmenge vernünftig auswerten. Wir haben bereits den massiven Einsatz von Funken bei Aufgaben gesehen, die leicht in den Speicher einer Maschine passen.
Spark erschwert das Debuggen, erhöht den Overhead und erschwert die Entwicklung - Sie sollten es nicht dort verwenden, wo Sie es nicht benötigen. Klassiker .
Zweitens müssen Sie natürlich die Komplexität des Modells bewerten und es mit der Aufgabe in Beziehung setzen. Wenn Ihre Konkurrenten hervorragende Ergebnisse erzielen und RandomForest ausgeführt wird, kann es sich lohnen, zweimal darüber nachzudenken, wenn Sie ein neuronales Netzwerk mit Milliarden von Parametern benötigen.
Und natürlich müssen Sie berücksichtigen, dass das Modell, wenn Sie wirklich über große Datenmengen verfügen, in der Lage sein muss, diese zu bearbeiten - wie man aus Stapeln lernt oder über verteilte Lernmechanismen verfügt (und so weiter). Und verlieren Sie an der gleichen Stelle nicht zu viel an Geschwindigkeit, wenn die Datenmenge zunimmt. Wir wissen beispielsweise, dass Kernel-Methoden ein Quadrat Speicher für Berechnungen im dualen Raum benötigen. Wenn Sie eine 10-fache Zunahme der Datengröße erwarten, sollten Sie zweimal überlegen, ob Sie in die verfügbaren Ressourcen passen.
Verfügbarkeit von vorgefertigten Modellen
Ein weiteres wichtiges Detail ist die Suche nach bereits trainierten Modellen, die vorab trainiert werden können. Ideal, wenn:
- Es gibt nicht viele Daten, aber sie sind sehr spezifisch für unsere Aufgabe - zum Beispiel medizinische Texte.
- Thema im Allgemeinen ist relativ beliebt - zum Beispiel das Hervorheben von Textthemen - viele Arbeiten in NLP.
- Ihr Ansatz ermöglicht im Prinzip das Vorlernen - wie zum Beispiel bei einer Art neuronaler Netze.
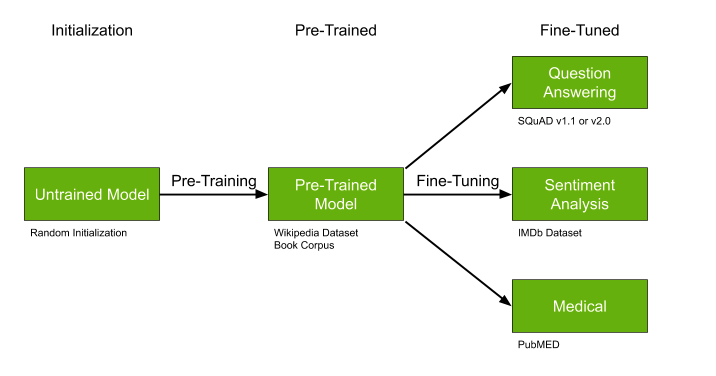
Vorab trainierte Modelle wie GPT-2 und BERT können die Lösung Ihres Problems erheblich vereinfachen. Wenn bereits trainierte Modelle vorhanden sind, empfehle ich dringend, diese Chance nicht zu nutzen.
Feature-Interaktionen und lineare Modelle
Einige Modelle funktionieren besser, wenn keine komplexen Wechselwirkungen zwischen Merkmalen bestehen - beispielsweise die gesamte Klasse linearer Modelle - Generalisierte additive Modelle. Es gibt eine Erweiterung dieser Modelle für den Fall der Interaktion zweier Merkmale, die als GA2M bezeichnet werden - Generalized Additive Models with Pairwise Interactions.
In der Regel zeigen solche Modelle gute Ergebnisse mit solchen Daten, sind hervorragend reguliert, interpretierbar und robust gegenüber Rauschen. Daher lohnt es sich auf jeden Fall, auf sie zu achten.
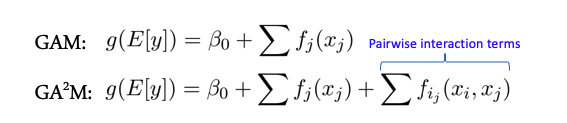
Wenn die Zeichen jedoch in Gruppen von mehr als 2 aktiv interagieren, zeigen diese Methoden keine so guten Ergebnisse mehr.
Paket- und Modellunterstützung
Viele coole Algorithmen und Modelle aus Artikeln kommen in Form eines Moduls oder eines Pakets für Python, R usw. Es lohnt sich, zweimal darüber nachzudenken, bevor Sie eine solche Lösung verwenden und sich langfristig darauf verlassen (ich sage dies als Person, die viele Artikel über ML mit einem solchen Code geschrieben hat). Die Wahrscheinlichkeit, dass es in einem Jahr keine Unterstützung mehr gibt, ist sehr hoch, da der Autor jetzt höchstwahrscheinlich andere Projekte durchführen muss, keine Zeit und keine Anreize für Investitionen in die Entwicklung des Moduls oder des Repositorys vorhanden sind.
In dieser Hinsicht sind Bibliotheken a la Scikit Learn genau deshalb gut, weil sie tatsächlich eine garantierte Gruppe von Enthusiasten haben und wenn etwas ernsthaft kaputt geht, werden sie früher oder später repariert.
Vorurteile und Fairness
Neben der automatischen Entscheidungsfindung werden Menschen, die mit solchen Entscheidungen unzufrieden sind, zum Leben erweckt. Stellen Sie sich vor, wir haben ein Ranking-System für Bewerbungen um ein Stipendium oder ein Forschungsstipendium an einer Universität. Unsere Universität wird ungewöhnlich sein - es gibt nur zwei Gruppen von Studenten: Historiker und Mathematiker. Wenn das System auf der Grundlage seiner Daten und seiner Logik plötzlich alle Zuschüsse an Historiker verteilte und sie keinem Mathematiker gewährte, kann dies die Mathematiker nicht schwach beleidigen. Sie werden ein solches System als voreingenommen bezeichnen. Jetzt reden nur die Faulen nicht darüber und Firmen und Leute verklagen sich gegenseitig.
Stellen Sie sich herkömmlicherweise ein vereinfachtes Modell vor, das einfach die Zitate von Artikeln zählt und Historiker sich aktiv zitieren lässt - der Durchschnitt liegt bei 100 Zitaten, aber es gibt keine Mathematik, sie haben einen Durchschnitt von 20 - und sie schreiben überhaupt sehr wenig. Dann erkennt das System alle Historiker als "gut", weil die Zitierrate hoch ist 100> 60 (Durchschnitt) und Mathematiker als "schlecht", weil sie alle eine Zitierrate haben, die viel niedriger ist als der Durchschnitt 20 <60. Ein solches System kann für jemanden kaum angemessen erscheinen.
Die Klassiker präsentieren nun die Logik von Entscheidungs- und Trainingsmodellen, die einen derart voreingenommenen Ansatz bekämpfen. Somit haben Sie für jede Entscheidung eine Erklärung (bedingt), warum sie getroffen wurde und wie Sie sich tatsächlich bemüht haben, sicherzustellen, dass das Modell keinen Bullshit gemacht hat (ELI5 GDPR).

Lesen Sie mehr von Google hieroder im Artikel hier .
Im Allgemeinen haben viele Unternehmen solche Aktivitäten aufgenommen, insbesondere im Hinblick auf die Veröffentlichung der DSGVO. Solche Maßnahmen und Kontrollen können dazu beitragen, künftige Probleme zu vermeiden.
Wenn ein Thema mehr interessiert ist als andere - schreiben Sie in die Kommentare, wir werden tiefer gehen. (DFS)!
