
Bereits im April 2020 berichtete Citizenlab über die eher schwache Verschlüsselung von Zoom und gab an, dass Zoom den SILK-Audio-Codec verwendet. Leider enthielt der Artikel nicht die ursprünglichen Daten, um dies zu bestätigen und mir die Möglichkeit zu geben, in Zukunft darauf zu verweisen. Vielen Dank jedoch an Natalie Silvanovich von Google Project ZeroMit dem Frida-Tracing-Tool konnte ich einige rohe SILK-Frames sichern. Ihre Analyse hat mich dazu inspiriert, einen Blick darauf zu werfen, wie WebRTC mit Audio umgeht. Wenn es um die wahrgenommene Anrufqualität im Allgemeinen geht, ist es die Audioqualität, die am meisten beeinflusst, da wir selbst kleine Störungen bemerken. Nur zehn Sekunden Analyse reichten aus, um ein echtes Abenteuer zu beginnen - auf der Suche nach Optionen zur Verbesserung der von WebRTC bereitgestellten Klangqualität.
Ich habe mich bereits 2017 (vor dem DataChannel-Beitrag ) mit dem nativen Zoom-Client befasst und festgestellt, dass seine Audiopakete im Vergleich zu den WebRTC-basierten Lösungspaketen manchmal sehr groß waren:

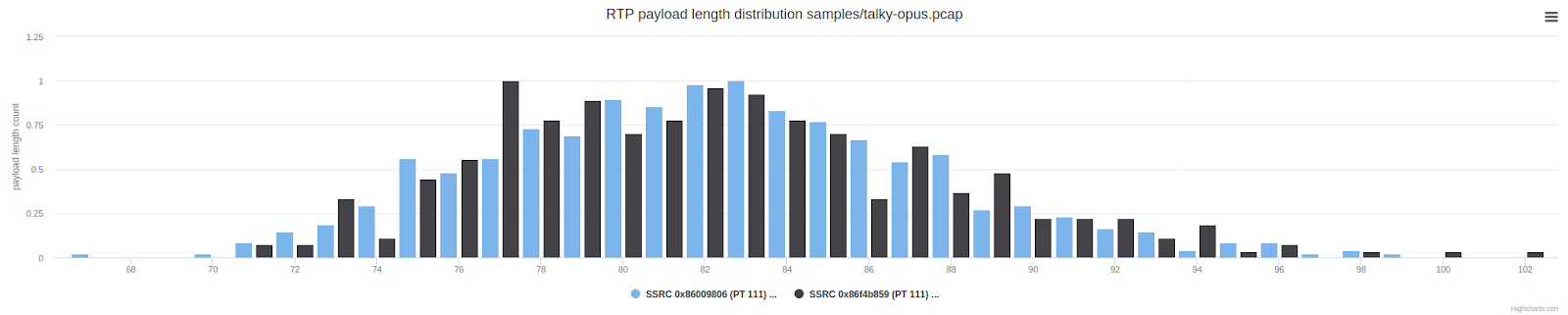
Die obige Grafik zeigt die Anzahl der Pakete mit einer bestimmten UDP-Nutzlastlänge. Pakete zwischen 150 und 300 Bytes sind im Vergleich zu einem typischen WebRTC-Aufruf ungewöhnlich. Sie sind viel länger als die Pakete, die wir normalerweise von Opus erhalten. Wir hatten den Verdacht, dass es eine Vorwärtsfehlerkontrolle (FEC) oder Redundanz gab, aber ohne Zugriff auf unverschlüsselte Frames war es schwierig, weitere Schlussfolgerungen zu ziehen oder etwas zu unternehmen.
Unverschlüsselte SILK-Frames im neuen Dump zeigten eine sehr ähnliche Verteilung. Nach dem Konvertieren der Frames in eine Datei und dem Abspielen einer kurzen Nachricht (danke an Giacomo Vacca für einen sehr hilfreichen Blog-BeitragIch ging zurück zu Wireshark und sah mir die Pakete an. Hier ist ein Beispiel für drei Pakete, die ich besonders interessant fand:
packet 7:
e9e4ab17ad8b9b5176b1659995972ac9b63737f8aa4d83ffc3073d3037b452fe6e1ee
5e6e68e6bcd73adbd59d3d31ea5fdda955cbb7f
packet 8:
e790ba4908639115e02b457676ea75bfe50727bb1c44144d37f74756f90e1ab926ef
930a3ffc36c6a8e773a780202af790acfbd6a4dff79698ea2d96365271c3dff86ce6396
203453951f00065ec7d26a03420496f
packet 9:
e93997d503c0601e918d1445e5e985d2f57736614e7f1201711760e4772b020212dc
854000ac6a80fb9a5538741ddd2b5159070ebbf79d5d83363be59f10ef
e790ba4908639115e02b457676ea75bfe50727bb1c44144d37f74756f90e1ab926ef
930a3ffc36c6a8e773a780202af790acfbd6a4dff79698ea2d96365271c3dff86ce6396
203453951f00065ec7d26a03420496f
e9e4ab17ad8b9b5176b1659995972ac9b63737f8aa4d83ffc3073d3037b452fe6e1ee
5e6e68e6bcd73adbd59d3d31ea5fdda955cbaefPaket 9 enthält zwei vorherige Pakete, Paket 8 - 1 vorheriges Paket. Diese Redundanz wird durch die Verwendung des LBRR-Formats (Low Bit Rate Redundancy) verursacht, das durch eine eingehende Untersuchung des SILK-Decoders gezeigt wurde (es befindet sich im Internetprojekt des Skype-Teams oder im Repository auf GitHub ):

Zoom verwendet SKP_SILK_LBRR_VER1, jedoch mit zwei Fallback-Paketen. Wenn jedes UDP-Paket nicht nur den aktuellen Audio-Frame enthält, sondern auch die beiden vorherigen, ist es robust, selbst wenn Sie zwei der drei Pakete verlieren. Vielleicht ist der Schlüssel zur Zoom-Klangqualität Omas Skype-Geheimrezept?
Opus FEC
Wie kann ich mit WebRTC dasselbe erreichen? Der nächste naheliegende Schritt war die Prüfung des Opus FEC.
SILKs LBRR (Low Rate Reservation) ist auch in Opus enthalten (denken Sie daran, dass Opus ein Hybrid-Codec ist, der SILK für das untere Ende des Bitratenbereichs verwendet). Opus SILK unterscheidet sich jedoch stark von der ursprünglichen SILK, deren Quellcode einst von Skype entdeckt wurde, ebenso wie der Teil von LBRR, der im Fehlerkontrollmodus verwendet wird.
Opus fügt nicht nur nach dem ursprünglichen Audio-Frame eine Fehlerkontrolle hinzu, sondern geht diesem voraus und wird im Bitstream codiert. Wir haben versucht, mithilfe der Insertable Streams-API mit dem Hinzufügen einer eigenen Fehlerkontrolle zu experimentieren. Dies erforderte jedoch eine vollständige Transcodierung, um die Informationen vor dem eigentlichen Paket in den Bitstream einzufügen.
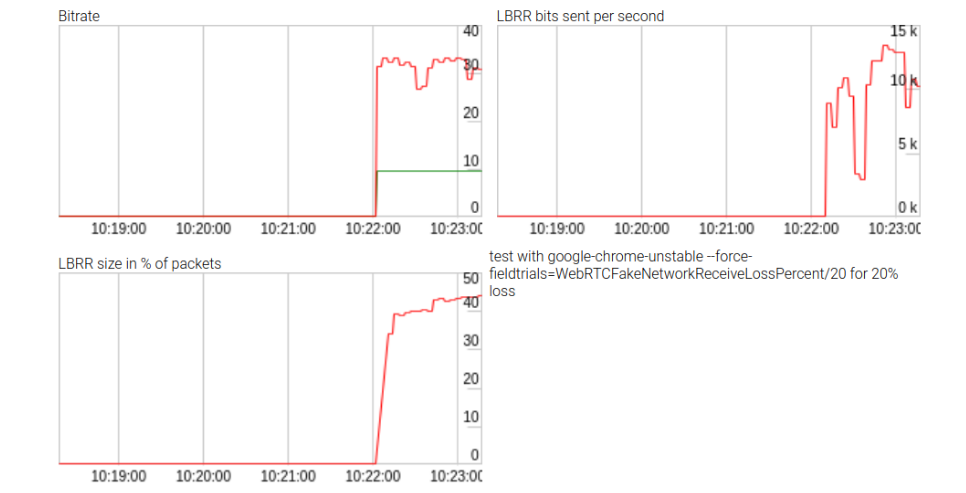
Obwohl die Bemühungen erfolglos blieben, erstellten sie einige Statistiken über die Auswirkungen von LBRR, die in der obigen Abbildung dargestellt sind. LBRR verwendet eine Bitrate von bis zu 10 kbps (oder zwei Dritteln der Datenrate) für einen hohen Paketverlust. Das Repository finden Sie hier . Diese Statistiken werden beim Aufrufen der WebRTC-
getStats() API nicht angezeigt , daher waren die Ergebnisse sehr interessant.
Die Notwendigkeit der Transcodierung ist nicht das einzige Problem bei Opus FEC. Wie sich herausstellte, sind seine Einstellungen in WebRTC etwas nutzlos:
- , , - . Slack 2016 . , .
- 25%. .
- FEC (. ).
Das Subtrahieren der FEC-Bitrate von der maximalen Zielbitrate ist überhaupt nicht sinnvoll - FEC reduziert aktiv die Bitrate des Hauptstroms. Ein Strom mit niedrigerer Bitrate führt normalerweise zu einer geringeren Qualität. Wenn es keinen Paketverlust gibt, der mit FEC korrigiert werden kann, wird die Qualität durch FEC nur beeinträchtigt, nicht verbessert. Warum passiert es? Die grundlegende Theorie ist, dass eine Überlastung einer der Gründe für den Paketverlust ist. Wenn Sie überlastet sind, möchten Sie möglicherweise nicht mehr Daten senden, da dies das Problem nur verschlimmert. Wie Emil Ivov jedoch in seinem hervorragenden KrankyGeek-Vortrag 2017 beschreibtÜberlastung ist nicht immer die Ursache für Paketverlust. Darüber hinaus ignoriert dieser Ansatz auch alle zugehörigen Videostreams. Die überlastungsbasierte FEC-Strategie für Opus-Audio macht wenig Sinn, wenn Sie Hunderte von Kilobit Video zusammen mit einem relativ kleinen 50-Kbit / s-Opus-Stream senden. Vielleicht werden wir in Zukunft einige Änderungen in libopus sehen, aber im Moment möchte ich versuchen, es zu deaktivieren, da es derzeit standardmäßig in WebRTC aktiviert ist .
Wir schließen daraus, dass dies nicht zu uns passt ...
ROT
Wenn wir echte Redundanz wünschen, hat RTP eine Lösung namens RTP Payload for Redundant Audio Data oder RED. Es ist ziemlich alt, RFC 2198 wurde 1997 geschrieben . Die Lösung ermöglicht es, mehrere RTP-Nutzdaten mit unterschiedlichen Zeitstempeln zu relativ geringen Kosten in dasselbe RTP-Paket zu packen.
Die Verwendung von RED zum Einfügen von ein oder zwei redundanten Audio-Frames in jedes Paket würde den Paketverlust wesentlich robuster machen als das Opus FEC. Dies ist jedoch nur möglich, indem die Audio-Bitrate von 30 kbit / s auf 60 oder 90 kbit / s verdoppelt oder verdreifacht wird (mit zusätzlichen 10 kbit / s für den Header). Im Vergleich zu mehr als 1 Megabit Videodaten pro Sekunde ist das jedoch nicht schlecht.
Die WebRTC-Bibliothek enthielt einen zweiten Codierer und Decodierer für ROT, der jetzt redundant ist! Trotz der Versuche , nicht verwendeten Audio-RED-Code zu entfernen , konnte ich diesen Encoder mit relativ geringem Aufwand anwenden. Der vollständige Verlauf der Lösung ist im WebRTC-Fehlerverfolgungssystem verfügbar.
Und es ist als Testversion verfügbar, die enthalten ist, wenn Sie Chrome mit den folgenden Flags starten:
--force-fieldtrials=WebRTC-Audio-Red-For-Opus/Enabled/Dann kann ROT über SDP-Aushandlung aktiviert werden. es wird wie folgt angezeigt:
a=rtpmap:someid red/48000/2Es ist standardmäßig nicht aktiviert, da es Umgebungen gibt, in denen die Verwendung zusätzlicher Bandbreite keine gute Idee ist. Um RED zu verwenden, ändern Sie die Reihenfolge der Codecs so, dass sie vor dem Opus-Codec stehen. Dies kann mithilfe der hier
RTCRtpTransceiver.setCodecPreferences gezeigten API erfolgen . Offensichtlich besteht eine andere Alternative darin, das SDP manuell zu ändern. Das SDP-Format könnte auch eine Möglichkeit bieten, das maximale Redundanzniveau zu konfigurieren, aber die Semantik der RFC 2198-Angebotsantwort war nicht vollständig klar, sodass ich mich entschied, dies für eine Weile zu verschieben.
Sie können zeigen, wie dies alles funktioniert, indem Sie es in einem Audiobeispiel ausführen . So sieht die frühe Version mit einem Backup-Paket aus:
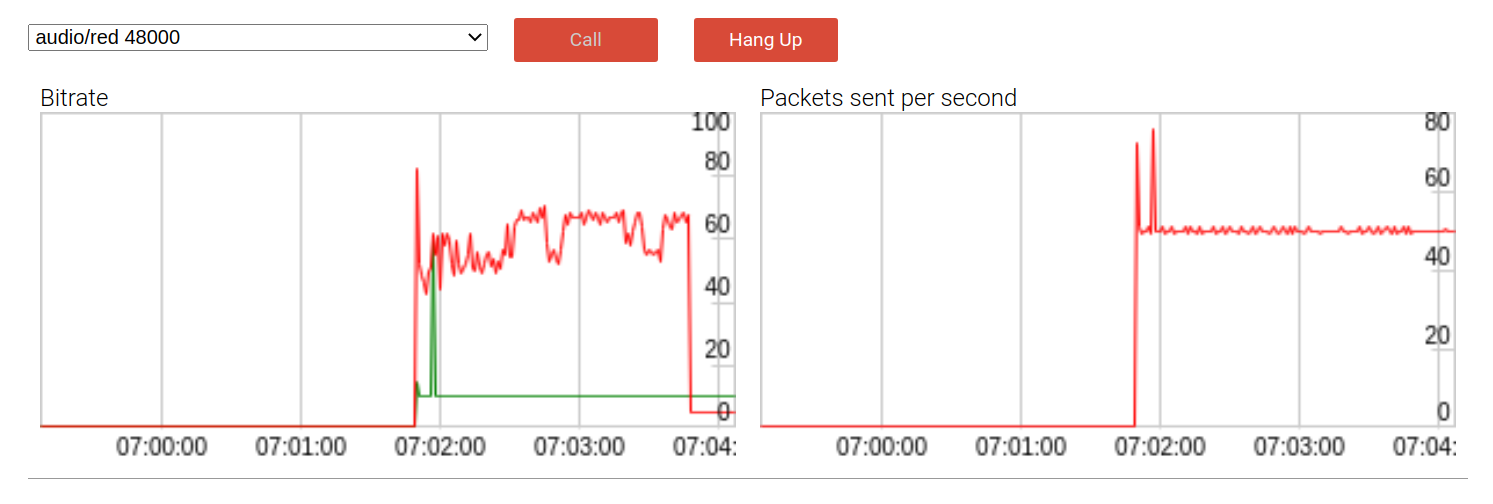
Standardmäßig ist die Nutzlast-Bitrate (rote Linie) mit fast 60 kbit / s fast doppelt so hoch wie ohne Redundanz. DTX (Discontinuous Transfer) ist ein bandbreitenschonender Mechanismus, der nur Pakete sendet, wenn Sprache erkannt wird. Wie erwartet lässt sich bei Verwendung von DTX der Effekt der Bitrate etwas abschwächen, wie wir am Ende des Aufrufs sehen können.
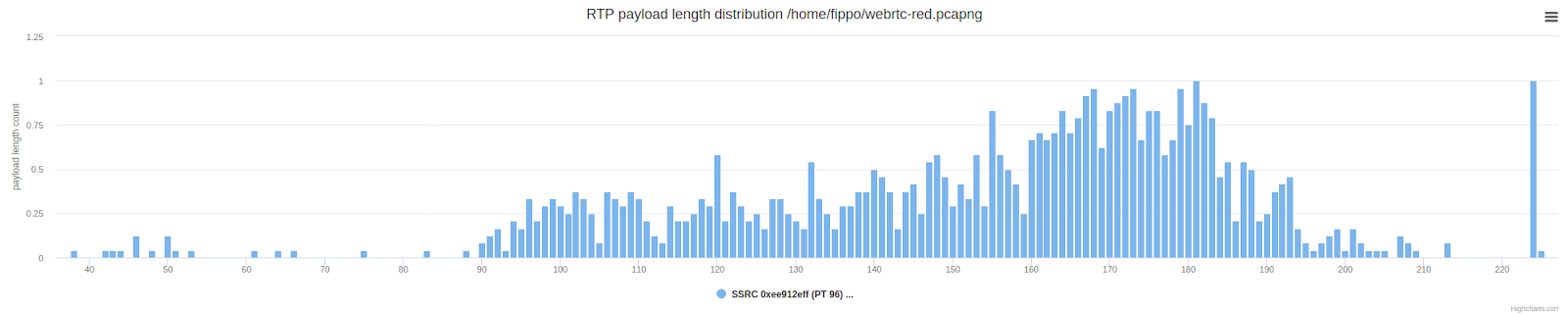
Das Überprüfen der Paketlänge zeigt das erwartete Ergebnis: Die Pakete sind im Durchschnitt doppelt so lang (größer) als die unten gezeigte Normalverteilung der Nutzlastlänge.
Dies unterscheidet sich immer noch geringfügig von dem, was Zoom tut, wo wir gebrochene Vorbehalte gesehen haben. Sehen wir uns das oben gezeigte Zoom-Paketlängen-Diagramm noch einmal an, um einen Vergleich zu sehen:
Hinzufügen von VAD-Unterstützung (Voice Activity Detection)
Opus FEC sendet Sicherungsdaten nur, wenn das Paket Sprachaktivität enthält. Gleiches sollte für die RED-Implementierung gelten. Dazu muss der Opus-Encoder geändert werden, um die korrekten VAD-Informationen anzuzeigen , die auf SILK-Ebene definiert sind. Mit dieser Einstellung erreicht die Bitrate 60 kbps nur bei Vorhandensein von Sprache (im Vergleich zu konstanten 60+ kbps):

und das "Spektrum" ähnelt eher dem, was wir mit Zoom gesehen haben:

Die Änderung, um dies zu erreichen, ist noch nicht erschienen.
Den richtigen Abstand finden
Entfernung ist die Anzahl der Sicherungspakete, dh die Anzahl der vorherigen Pakete im aktuellen. Während wir daran arbeiteten, den richtigen Abstand zu finden, stellten wir fest, dass ROT in Abstand 2 noch kühler ist, wenn ROT in Abstand 1 kühl ist. Unsere Laborschätzung simulierte einen zufälligen Paketverlust von 60%. In dieser Umgebung lieferte Opus + RED einen hervorragenden Klang, während Opus ohne RED eine viel schlechtere Leistung erbrachte. Die WebRTC getStats () API stellt eine sehr nützliche Fähigkeit , dies zu messen , indem man den Prozentsatz der versteckten Proben erhalten Vergleich durch Dividieren concealedSamples durch totalSamplesReceived .
Auf der Seite mit den Audiobeispielen können diese Daten einfach mit diesem in die Konsole eingefügten JavaScript-Snippet abgerufen werden:
(await pc2.getReceivers()[0].getStats()).forEach(report => {
if(report.type === "track") console.log(report.concealmentEvents, report.concealedSamples, report.totalSamplesReceived, report.concealedSamples / report.totalSamplesReceived)})Ich habe einige Paketverlusttests mit einem nicht sehr bekannten, aber sehr nützlichen Flag durchgeführt
WebRTCFakeNetworkReceiveLossPercent:
--force-fieldtrials=WebRTC-Audio-Red-For-Opus/Enabled/WebRTCFakeNetworkReceiveLossPercent/20/Bei 20% Paketverlust und standardmäßig aktiviertem FEC gab es keinen großen Unterschied in der Audioqualität, aber einen geringfügigen Unterschied in der Metrik:
| Szenario | Verlustprozentsatz |
|---|---|
| ohne rot | achtzehn% |
| kein rot, FEC deaktiviert | 20% |
| rot mit Abstand 1 | 4% |
| rot mit Abstand 2 | 0,7% |
Ohne RED oder FEC entspricht die Metrik fast dem angeforderten Paketverlust. Es gibt einen Effekt von FEC, aber er ist gering.
Ohne ROT wurde die Klangqualität bei einem Verlust von 60% eher schlecht, ein wenig metallisch und die Wörter schwer zu verstehen:
| Szenario | Verlustprozentsatz |
|---|---|
| ohne rot | 60% |
| rot mit Abstand 1 | 32% |
| rot mit Abstand 2 | achtzehn% |
Bei RED gab es einige hörbare Artefakte mit Abstand = 1, aber bei Abstand 2 nahezu perfekten Klang (dies ist die derzeit verwendete Redundanzmenge).
Es besteht das Gefühl, dass das menschliche Gehirn einem bestimmten Grad an Stille standhalten kann, der unregelmäßig auftritt. (Und Google Duo scheint einen Algorithmus für maschinelles Lernen zu verwenden , um die Stille zu füllen.)
Leistung in der realen Welt messen
Wir hoffen, dass die Aufnahme von RED in Opus die Klangqualität verbessern wird, obwohl dies in einigen Fällen die Situation verschlechtern kann. Emil Ivov bot sich an, einige Hörtests mit der POLQA-MOS-Methode durchzuführen. Dies wurde bereits für Opus durchgeführt, daher haben wir eine Vergleichsbasis.
Wenn die ersten Tests vielversprechende Ergebnisse zeigen, werden wir ein groß angelegtes Experiment mit dem Hauptscan von Jitsi Meet durchführen und dabei die oben verwendeten prozentualen Verlustmetriken anwenden.
Beachten Sie, dass für Medienserver und SFUs das Aktivieren von RED etwas schwieriger ist, da der Server möglicherweise die RED-Weiterleitung verwalten muss, um Clients auszuwählen, wie dies der Fall ist, wenn nicht alle Clients RED-Konferenzen unterstützen. Einige Clients befinden sich möglicherweise auch auf einem Kanal mit begrenzter Bandbreite, für den ROT nicht erforderlich ist. Wenn der Endpunkt RED nicht unterstützt, kann die SFU unnötige Codierungen entfernen und Opus ohne Wrapper senden. Ebenso kann es RED selbst implementieren und verwenden, wenn Pakete von einem Endpunkt, der Opus überträgt, erneut an einen Endpunkt gesendet werden, der RED unterstützt.
Vielen Dank an Jitsi / 8 × 8 Inc für das Sponsern dieses aufregenden Abenteuers und an die Mitarbeiter von Google, die die erforderlichen Änderungen analysiert und Feedback gegeben haben.
Und ohne Natalie Silvanovich hätte ich mir die verschlüsselten Bytes angesehen!