 Hallo Bewohner! Das Buch Site Reliability Engineering löste eine hitzige Diskussion aus. Was ist Ausbeutung heute und warum sind Zuverlässigkeitsprobleme so grundlegend? Jetzt schlagen die Google-Ingenieure hinter diesem Bestseller vor, von der Theorie zur Praxis zu wechseln. Das Site Reliability Workbook zeigt, wie SRE-Prinzipien und -Praktiken in Ihrer Produktion verankert sind. Das Know-how von Google wird durch Benutzerfälle der Google Cloud Platform ergänzt. Vertreter von Evernote, The Home Depot, der New York Times und anderen Unternehmen beschreiben ihre Kampferfahrung und berichten, welche Praktiken sie übernommen haben und welche nicht. Dieses Buch hilft Ihnen dabei, SRE an die Realität Ihrer eigenen Praxis anzupassen, unabhängig von der Größe Ihres Unternehmens. Du wirst lernen zu:
Hallo Bewohner! Das Buch Site Reliability Engineering löste eine hitzige Diskussion aus. Was ist Ausbeutung heute und warum sind Zuverlässigkeitsprobleme so grundlegend? Jetzt schlagen die Google-Ingenieure hinter diesem Bestseller vor, von der Theorie zur Praxis zu wechseln. Das Site Reliability Workbook zeigt, wie SRE-Prinzipien und -Praktiken in Ihrer Produktion verankert sind. Das Know-how von Google wird durch Benutzerfälle der Google Cloud Platform ergänzt. Vertreter von Evernote, The Home Depot, der New York Times und anderen Unternehmen beschreiben ihre Kampferfahrung und berichten, welche Praktiken sie übernommen haben und welche nicht. Dieses Buch hilft Ihnen dabei, SRE an die Realität Ihrer eigenen Praxis anzupassen, unabhängig von der Größe Ihres Unternehmens. Du wirst lernen zu:
- Stellen Sie die Zuverlässigkeit von Diensten in Clouds und Umgebungen sicher, die Sie nicht vollständig steuern.
- verschiedene Methoden zum Erstellen, Starten und Überwachen von Diensten anwenden, wobei der Schwerpunkt auf SLO liegt;
- Admin-Teams in SRE-Ingenieure verwandeln;
- Implementieren Sie Methoden zum Starten von SRE von Grund auf neu und basierend auf vorhandenen Systemen. Betsy Beyer, Neil Richard Murphy, David Renzin, Kent Kawahara und Stephen Thorne sind alle an der Gewährleistung der Zuverlässigkeit von Google-Systemen beteiligt.
Systemverwaltung überwachen
Ihr Überwachungssystem ist genauso wichtig wie jeder andere Dienst, den Sie verwenden. Daher sollte die Überwachung mit der gebotenen Sorgfalt behandelt werden.
Behandeln Sie Ihre Konfiguration als Code Das Behandeln Ihrer
Systemkonfiguration als Code und das Speichern in einem Versionskontrollsystem ist eine gängige Praxis. Dazu gehören das Speichern des Änderungsverlaufs, das Verknüpfen bestimmter Änderungen mit dem Task-Management-System, vereinfachte Rollbacks, die statische Code-Analyse auf Fehler und Verfahren zur erzwungenen Codeprüfung.
Wir empfehlen außerdem dringend, die Überwachungskonfiguration als Code zu behandeln (weitere Informationen zur Konfiguration finden Sie in Kapitel 14). Ein Überwachungssystem, das die Anpassung mithilfe wohlgeformter Beschreibungen von Zielen und Funktionen unterstützt, anstatt Systeme, die nur Webschnittstellen oder APIs im CRUD-Stil bereitstellen (http://bit.ly/1G4WdV1). Dieser Konfigurationsansatz ist Standard für viele Open Source-Binärdateien, die nur eine Konfigurationsdatei lesen. Einige Lösungen von Drittanbietern wie Grafanalib (http://bit.ly/2so5Wrx) unterstützen diesen Ansatz für Komponenten, die traditionell über die Benutzeroberfläche angepasst werden können.
Konsistenz fördern
Große Unternehmen mit mehreren Projektteams, die die Überwachung verwenden, müssen ein empfindliches Gleichgewicht finden: Einerseits sorgt ein zentraler Ansatz für Konsistenz, andererseits möchten einzelne Teams möglicherweise die vollständige Kontrolle über die Funktionsweise ihrer Konfiguration haben.
Die richtige Entscheidung hängt von der Art Ihrer Organisation ab. Im Laufe der Zeit hat sich der Ansatz von Google dahingehend weiterentwickelt, alle Best Practices auf einer einzigen Plattform zusammenzuführen, die als zentraler Dienst fungiert. Dies ist eine gute Entscheidung für uns, und dafür gibt es mehrere Gründe. Eine einheitliche Infrastruktur ermöglicht es Ingenieuren, schneller und einfacher von einem Team in ein anderes zu wechseln, und erleichtert die Zusammenarbeit beim Debuggen. Darüber hinaus gibt es einen zentralen Dashboard-Service, bei dem die Dashboards jedes Teams geöffnet und zugänglich sind. Wenn Sie die Informationen des anderen Teams gut verstehen, können Sie schnell sowohl Ihre eigenen Probleme als auch die anderer Teams beheben.
Halten Sie die grundlegende Überwachungsabdeckung nach Möglichkeit so einfach wie möglich. Wenn alle Ihre Services einen konsistenten Satz von Baselines exportieren, können Sie diese Metriken automatisch in Ihrem Unternehmen erfassen und einen konsistenten Satz von Dashboards bereitstellen. Dieser Ansatz bedeutet, dass für jede neue Komponente, die Sie automatisch starten, eine grundlegende Überwachung vorhanden ist. Auf diese Weise können viele Teams in Ihrem Unternehmen - nicht einmal technische - die Überwachungsdaten verwenden.
Bevorzugen Sie schwache Bindungen Die
geschäftlichen Anforderungen ändern sich und Ihr Produktionssystem wird in einem Jahr anders aussehen. Genau wie die Dienste, die Sie steuern, muss sich Ihr Überwachungssystem im Laufe der Zeit entwickeln und weiterentwickeln, wobei verschiedene typische Probleme auftreten.
Wir empfehlen, dass die Kopplung zwischen den Komponenten Ihres Steuerungssystems nicht sehr stark ist. Sie müssen über zuverlässige Schnittstellen verfügen, um jede Komponente zu konfigurieren und Überwachungsdaten zu übertragen. Verschiedene Komponenten sollten für das Sammeln, Speichern, Warnen und Visualisieren Ihrer Überwachungsdaten verantwortlich sein. Stabile Schnittstellen machen es einfach, eine bestimmte Komponente durch die am besten geeignete Alternative zu ersetzen.
In der Open Source-Welt wird die Aufteilung der Funktionalität in separate Komponenten immer beliebter. Vor zehn Jahren haben Überwachungssysteme wie Zabbix (https://www.zabbix.com/) alle Funktionen in einer Komponente zusammengefasst. Modernes Design umfasst normalerweise das Trennen der Erfassung und Ausführung von Regeln (unter Verwendung von Lösungen wie dem Prometheus-Server (https://prometheus.io/)), das Speichern von Langzeitzeitreihen (InfluxDB, www.influxdata.com ) und das Aggregieren von Warnungen ( Alertmanager, bit.ly/2soB22b ) und Erstellen von Dashboards (Grafana, grafana.com ).
Zum Zeitpunkt dieses Schreibens gibt es mindestens zwei beliebte offene Standards, mit denen Sie Software mit den erforderlichen Tools ausstatten und Metriken bereitstellen können:
- statsd — , Etsy, ;
- Prometheus — , . Prometheus OpenMetrics (https://openmetrics.io/).
Ein separates Dashboard-System, das mehrere Datenquellen verwendet, bietet eine zentralisierte und einheitliche Ansicht Ihres Dienstes. Google hat diesen Vorteil kürzlich in der Praxis erlebt: Unser Legacy-Überwachungssystem (Borgmon1) kombinierte Dashboards in derselben Konfiguration wie Warnregeln. Beim Wechsel zu einem neuen System (Monarch, youtu.be/LlvJdK1xsl4 ) haben wir beschlossen, die Dashboards auf einen separaten Dienst (Viceroy, bit.ly/2sqRwad ) zu verschieben. Vizekönig war keine Borgmon- oder Monarch-Komponente, daher hatte Monarch weniger funktionale Anforderungen. Da Benutzer mit Viceroy Diagramme anzeigen können, die auf Daten beider Überwachungssysteme basieren, konnten sie schrittweise von Borgmon nach Monarch migrieren.
Sinnvolle Kennzahlen In
Kapitel 5 erfahren Sie, wie Sie SLI-Kennzahlen (Quality of Service) verwenden, um Bedrohungen zu verfolgen und an Ihr Budget zu melden. SLI-Metriken sind die ersten Metriken, die prüfen, wann Warnungen basierend auf SLO-Zielen (Quality of Service) ausgelöst werden. Diese Metriken sollten im Dashboard Ihres Dienstes angezeigt werden, idealerweise auf der Startseite.
Wenn Sie die Grundursache einer SLO-Verletzung untersuchen, erhalten Sie wahrscheinlich nicht genügend Informationen von den SLO-Panels. Diese Panels zeigen, dass es Verstöße gibt, aber es ist unwahrscheinlich, dass Sie die Gründe kennen, die zu ihnen geführt haben. Welche anderen Daten sollten im Dashboard angezeigt werden?
Wir glauben, dass die folgenden Richtlinien bei der Implementierung von Metriken hilfreich sind: Diese Metriken sollten eine aussagekräftige Überwachung bieten, mit der Sie betriebliche Probleme untersuchen und eine breite Palette von Informationen zu Ihren Diensten bereitstellen können.
Absichtliche Änderungen
Bei der Diagnose von SLO-bezogenen Warnungen müssen Sie in der Lage sein, von Warnungsmetriken, die Sie über Probleme informieren, die Benutzer betreffen, zu Metriken zu wechseln, die Sie auf die Hauptursache dieser Probleme aufmerksam machen. Solche Gründe können kürzlich absichtliche Änderungen an Ihrem Dienst sein. Fügen Sie eine Überwachung hinzu, die Sie über Änderungen in der Produktion informiert. Um festzustellen, ob Änderungen vorgenommen wurden, empfehlen wir Folgendes:
- Überwachen der Version einer Binärdatei;
- , ;
- , .
Wenn eine dieser Komponenten nicht versioniert ist, müssen Sie nachverfolgen, wann die Komponente zuletzt zusammengebaut oder verpackt wurde.
Wenn Sie versuchen, neu auftretende Serviceprobleme mit einer Bereitstellung zu korrelieren, ist es viel einfacher, ein Diagramm oder einen Bereich anzuzeigen, auf den in einer Warnung verwiesen wird, als die CI / CD-Protokolle nachträglich durchzublättern.
Abhängigkeiten
Auch wenn sich Ihr Dienst nicht geändert hat, können sich alle Abhängigkeiten ändern. Daher müssen Sie auch die Antworten verfolgen, die aus direkten Abhängigkeiten stammen.
Es ist ratsam, die Anforderungs- und Antwortgröße in Bytes, Antwortzeiten und Antwortcodes für jede Abhängigkeit zu exportieren. Beachten Sie bei der Auswahl einer Metrik für ein Diagramm diese vier goldenen Signale (siehe Abschnitt)"Die vier goldenen Signale", Kapitel 6 von Site Reliability Engineering ).
Sie können zusätzliche Bezeichnungen in den Metriken verwenden, um sie nach Antwortcode, Name der RPC-Methode (Remote Procedure Call) und Name des aufgerufenen Dienstes zu trennen.
Anstatt jede RPC-Clientbibliothek zu bitten, solche Beschriftungen zu exportieren, können Sie im Idealfall die RPC-Clientbibliothek der unteren Ebene zu diesem Zweck einmal bearbeiten. Dies bietet eine größere Konsistenz und ermöglicht die einfache Überwachung neuer Abhängigkeiten.
Es gibt Abhängigkeiten, die eine sehr eingeschränkte API bieten, bei der alle Funktionen über eine einzige RPC-Methode namens Get, Query oder genauso wenig aussagekräftig verfügbar sind und der tatsächliche Befehl als Argumente für diese Methode angegeben wird. Der Einzelpunktansatz für Tools in der Clientbibliothek funktioniert für diese Art von Abhängigkeit nicht: Sie werden eine große Variabilität der Latenz und einen bestimmten Prozentsatz von Fehlern feststellen, die möglicherweise darauf hinweisen, dass ein Teil dieses "Schlamms" vorhanden ist oder nicht. Die API ist vollständig heruntergefallen. Wenn diese Abhängigkeit kritisch ist, kann eine gute Überwachung auf folgende Weise implementiert werden.
- Exportieren Sie einzelne Metriken, die speziell für diese Abhängigkeit entwickelt wurden. Dabei werden Anforderungen entpackt, um ein gültiges Signal zu erhalten.
- Bitten Sie die Eigentümer der Abhängigkeit, sie neu zu schreiben, um eine erweiterte API zu exportieren, die die Trennung von Funktionen zwischen einzelnen RPC-Diensten und -Methoden unterstützt.
Die Arbeitsbelastung
Es ist wünschenswert, die Verwendung aller Ressourcen, mit denen der Dienst arbeitet, zu steuern und zu verfolgen. Einige Ressourcen haben feste Grenzen, die Sie nicht überschreiten können. Zum Beispiel die Größe des Arbeitsspeichers, die Ihrer Anwendung zugewiesene Festplatte oder das CPU-Kontingent. Andere Ressourcen, wie z. B. offene Dateideskriptoren, aktive Threads in Thread-Pools, Warteschlangen-Timeouts oder die Anzahl der geschriebenen Protokolle, haben möglicherweise keine eindeutige feste Obergrenze, müssen jedoch noch verwaltet werden.
Abhängig von der verwendeten Programmiersprache müssen Sie einige zusätzliche Ressourcen im Auge behalten:
- in Java Heap- und Metaspace-Größe (http://bit.ly/2J9g3Ha) sowie spezifischere Metriken je nach Art der verwendeten Garbage Collection;
- in Go die Anzahl der Goroutinen.
Die Programmiersprachen selbst bieten verschiedene Unterstützung, um diese Ressourcen im Auge zu behalten.
Zusätzlich zur Benachrichtigung über wichtige Ereignisse, wie in Kapitel 5 beschrieben, möchten Sie möglicherweise auch Warnungen einrichten, die ausgelöst werden, wenn bestimmte Ressourcen kurz vor der kritischen Erschöpfung stehen. Dies ist beispielsweise in folgenden Situationen nützlich:
- wenn die Ressource ein hartes Limit hat;
- wenn eine Leistungsverschlechterung auftritt, wenn der Nutzungsschwellenwert überschritten wird.
Die Überwachung ist für alle Ressourcen unerlässlich, auch für diejenigen, die der Dienst gut verwaltet. Diese Metriken sind für die Planung von Ressourcen und Funktionen von entscheidender Bedeutung.
Status des ausgegebenen Datenverkehrs
Es wird empfohlen, dem Dashboard Metriken oder Metrikbezeichnungen hinzuzufügen, mit denen Sie den ausgegebenen Datenverkehr nach Statuscode aufteilen können (wenn die von Ihrem Dienst für SLI-Zwecke verwendeten Metriken diese Informationen nicht enthalten). Hier sind einige Richtlinien.
- Behalten Sie alle Antwortcodes für den HTTP-Verkehr im Auge, auch diejenigen, die aufgrund eines möglichen falschen Client-Verhaltens keinen Grund für die Ausgabe von Warnungen darstellen.
- Wenn Sie Ihren Benutzern ein Zeitlimit oder ein Kontingentlimit zuweisen, behalten Sie die Anzahl der Anfragen im Auge, die aufgrund fehlender Kontingente abgelehnt wurden.
Mithilfe von Plots dieser Daten können Sie feststellen, wann sich die Fehlerrate während einer Produktionsänderung merklich ändert.
Implementierung von Zielmetriken
Jede Metrik sollte ihren Zweck erfüllen. Versuchen Sie nicht, mehrere Metriken zu exportieren, nur weil sie einfach zu generieren sind. Überlegen Sie stattdessen, wie sie verwendet werden. Die Metrikarchitektur (oder deren Fehlen) hat Auswirkungen. Im Idealfall ändern sich die zur Alarmierung verwendeten Metrikwerte nur dann abrupt, wenn ein Problem im System auftritt, und bleiben während des normalen Betriebs unverändert. Andererseits werden diese Anforderungen nicht an Debug-Metriken gestellt - sie sollten eine Vorstellung davon geben, was passiert, wenn eine Warnung ausgelöst wird. Gute Debug-Metriken weisen auf potenziell problematische Teile des Systems hin. Überlegen Sie beim Schreiben eines Postmortems, mit welchen zusätzlichen Metriken Sie das Problem schneller diagnostizieren können.
Testen der Alarmlogik
In einer idealen Welt sollten Überwachungs- und Warncode denselben Teststandards wie Entwicklungscode folgen. Derzeit gibt es kein allgemein anerkanntes System, mit dem Sie ein solches Konzept umsetzen können. Eines der ersten Anzeichen ist die neu hinzugefügte Funktion zum Testen von Regeleinheiten für Prometheus.
Bei Google testen wir unsere Überwachungs- und Warnsysteme in einer domänenspezifischen Sprache, mit der wir synthetische Zeitreihen erstellen können. Wir überprüfen dann entweder die Werte in den abgeleiteten Zeitreihen oder klären, ob eine bestimmte Warnung ausgelöst wurde und die erforderliche Bezeichnung hat.
Das Überwachen und Ausgeben von Warnungen ist häufig ein mehrstufiger Prozess, sodass mehrere Familien von Komponententests erforderlich sind.
Obwohl dieser Bereich noch weitgehend unterentwickelt ist, empfehlen wir einen dreistufigen Ansatz, wie in Abbildung 1 dargestellt, wenn Sie zu einem bestimmten Zeitpunkt Überwachungstests implementieren möchten. 4.1.
- Binärdateien. Stellen Sie sicher, dass die exportierten Metrikvariablen unter bestimmten Bedingungen die erwarteten Werte ändern.
- Überwachung der Infrastruktur. Stellen Sie sicher, dass die Regeln eingehalten werden und die spezifischen Bedingungen die erwarteten Warnungen sind.
- Alarmmanager. Stellen Sie sicher, dass generierte Warnungen basierend auf den Etikettenwerten an ein vordefiniertes Ziel weitergeleitet werden.
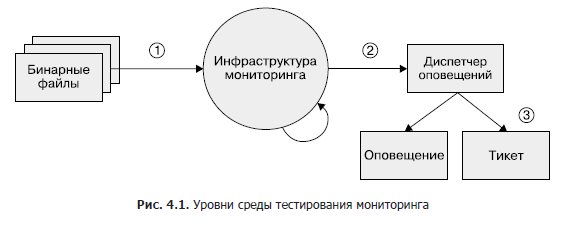
Wenn Sie Ihr Überwachungssystem nicht mit synthetischen Tools testen können oder wenn ein Schritt überhaupt nicht testbar ist, sollten Sie ein Produktionssystem erstellen, das bekannte Metriken wie Anforderungen und Fehler exportiert. Mit diesem System können Sie Zeitreihen und Warnungen überprüfen. Es ist wahrscheinlich, dass Ihre Warnungsregeln erst Monate oder Jahre nach dem Einrichten ausgelöst werden. Sie müssen sicherstellen, dass die Warnungen aussagekräftig bleiben und an die vorgesehenen Ingenieure gesendet werden, wenn die Metrik einen bestimmten Schwellenwert überschreitet.
Kapitelzusammenfassung
Da SR-Ingenieure für die Zuverlässigkeit von Produktionssystemen verantwortlich sein müssen, müssen diese Spezialisten häufig das Überwachungssystem und seine Funktionen genau verstehen und eng mit ihm zusammenarbeiten. Ohne diese Daten wissen SREs möglicherweise nicht, wo sie suchen und wie sie abnormales Systemverhalten identifizieren oder wie sie Informationen finden können, die sie im Notfall benötigen.
Wir hoffen, dass wir Ihnen helfen können, zu beurteilen, wie Ihr Überwachungssystem Ihren Anforderungen entspricht, indem wir auf die aus unserer Sicht nützlichen Funktionen des Überwachungssystems hinweisen und unsere Wahl begründen. Darüber hinaus helfen wir Ihnen dabei, einige der zusätzlichen Funktionen zu erkunden, die Sie verwenden können, und die Änderungen zu überprüfen, die Sie wahrscheinlich vornehmen möchten. Sie werden es höchstwahrscheinlich nützlich finden, Metrik- und Protokollquellen in Ihrer Überwachungsstrategie zu kombinieren. Die richtige Mischung aus Metriken und Protokollen ist stark kontextabhängig.
Stellen Sie sicher, dass Sie Metriken sammeln, die einem bestimmten Zweck dienen. Dies sind Ziele wie die Verbesserung der Bandbreitenplanung, das Debuggen oder das Melden auftretender Probleme.
Wenn Sie eine Überwachung haben, sollte diese visuell und nützlich sein. Zu diesem Zweck empfehlen wir, die Einstellungen zu testen. Ein gutes Überwachungssystem zahlt sich aus. Eine gründliche Vorplanung, welche Lösungen zur optimalen Abdeckung Ihrer spezifischen Anforderungen verwendet werden sollen, sowie kontinuierliche iterative Verbesserungen des Überwachungssystems sind eine Investition, die sich auszahlt.
»Weitere Details zum Buch finden Sie auf der Website des Verlags.
» Inhaltsverzeichnis
» Auszug
für Einwohner 25% Rabatt auf den Gutschein - Google
Nach Zahlung der Papierversion des Buches wird ein E-Book per E-Mail verschickt.