Tatsache ist, dass alle unsere Teams auf separaten Informationssystemen, Microservices und Fronten basieren, sodass die Teams nicht den Gesamtzustand des gesamten Systems als Ganzes sehen. Beispielsweise wissen sie möglicherweise nicht, wie sich ein kleiner Teil im tiefen Backend auf das Frontend auswirkt. Der Bereich ihrer Interessen beschränkt sich auf die Systeme, in die ihr System integriert ist. Wenn das Team und sein Dienst A fast nichts mit Dienst B zu tun haben, ist ein solcher Dienst für das Team fast unsichtbar.
Unser Team arbeitet wiederum mit Systemen, die sehr stark miteinander integriert sind: Es gibt viele Verbindungen zwischen ihnen, dies ist eine sehr große Infrastruktur. Und die Arbeit des Online-Shops hängt von all diesen Systemen ab (von denen wir übrigens eine große Anzahl haben).
Es stellt sich also heraus, dass unsere Abteilung keinem Team angehört, aber etwas distanziert ist. In dieser Geschichte ist es unsere Aufgabe, auf komplexe Weise zu verstehen, wie Informationssysteme funktionieren, welche Funktionen sie haben, welche Integrationen, welche Software, welches Netzwerk, welche Hardware und welche Hardware miteinander verbunden sind.
Die Plattform, auf der unsere Online-Shops betrieben werden, sieht folgendermaßen aus:
- Vorderseite
- mittleres Büro
- Backoffice
So viel wir möchten, aber es gibt keine Möglichkeit, dass alle Systeme reibungslos und fehlerfrei funktionieren. Der Punkt ist wiederum die Anzahl der Systeme und Integrationen - bei wie bei uns sind einige Vorfälle trotz der Qualität der Tests unvermeidlich. Darüber hinaus sowohl innerhalb eines separaten Systems als auch hinsichtlich ihrer Integration. Und Sie müssen den Status der gesamten Plattform umfassend überwachen und nicht einen separaten Teil davon.
Idealerweise sollte die Überwachung des Zustands der gesamten Plattform automatisiert werden. Und wir kamen zur Überwachung als unvermeidlichen Teil dieses Prozesses. Ursprünglich wurde es nur für den vorderen Teil gebaut, während Netzwerker, Software- und Hardwareadministratoren ihre eigenen Überwachungssysteme nach Schichten hatten. Alle diese Personen verfolgten die Überwachung nur auf ihrer eigenen Ebene, und auch niemand hatte ein umfassendes Verständnis.
Wenn beispielsweise eine virtuelle Maschine abstürzt, weiß in den meisten Fällen nur der für die Hardware und die virtuelle Maschine verantwortliche Administrator davon. In solchen Fällen erkannte das Frontteam die Tatsache des Absturzes der Anwendung, hatte jedoch keine Daten zum Absturz der virtuellen Maschine. Der Administrator kann wissen, wer der Kunde ist, und sich grob vorstellen, was gerade auf dieser virtuellen Maschine ausgeführt wird, vorausgesetzt, es handelt sich um ein großes Projekt. Er weiß wahrscheinlich nichts über die Kleinen. In jedem Fall muss der Administrator zum Eigentümer gehen und fragen, was sich auf diesem Computer befand, was wiederhergestellt werden muss und was geändert werden muss. Und wenn etwas sehr Ernstes zusammenbrach, rannten sie im Kreis herum - weil niemand das System als Ganzes sah.
Letztendlich betreffen diese unterschiedlichen Geschichten das gesamte Front-End, die Benutzer und unsere Kerngeschäftsfunktion, den Online-Verkauf. Da wir nicht Teil eines Teams sind, sondern alle E-Commerce-Anwendungen als Teil eines Online-Shops betreiben, haben wir es uns zur Aufgabe gemacht, ein umfassendes Überwachungssystem für die E-Commerce-Plattform zu erstellen.
Systemstruktur und Stack
Wir haben zunächst mehrere Überwachungsebenen für unsere Systeme hervorgehoben, in deren Kontext wir Metriken erfassen müssen. Und all dies musste kombiniert werden, was wir in der ersten Phase getan haben. In dieser Phase stellen wir die qualitativ hochwertigste Sammlung von Metriken für alle unsere Ebenen fertig, um eine Korrelation aufzubauen und zu verstehen, wie sich Systeme gegenseitig beeinflussen.
Das Fehlen einer umfassenden Überwachung in der Anfangsphase des Anwendungsstarts (seit wir mit der Erstellung begonnen haben, als die meisten Systeme in Betrieb waren) führte dazu, dass wir einen erheblichen technischen Aufwand hatten, um die Überwachung der gesamten Plattform einzurichten. Wir konnten es uns nicht leisten, uns darauf zu konzentrieren, die Überwachung eines einzelnen IS einzurichten und die Überwachung im Detail auszuarbeiten, da der Rest der Systeme für einige Zeit ohne Überwachung bleiben würde. Um dieses Problem zu lösen, haben wir eine Liste der wichtigsten Metriken zur Beurteilung des Zustands des Informationssystems nach Schichten ermittelt und mit der Implementierung begonnen.
Deshalb beschlossen sie, den Elefanten in Teilen zu essen.
Unser System besteht aus:
- Hardware;
- Betriebssystem;
- Software;
- UI-Teile in der Überwachungsanwendung;
- Geschäftsmetriken;
- Integrationsanwendungen;
- Informationssicherheit;
- Netzwerke;
- Verkehrsbalancer.
Im Zentrum dieses Systems steht die Überwachung selbst. Um den Status des gesamten Systems allgemein zu verstehen, müssen Sie wissen, was mit den Anwendungen auf all diesen Ebenen und im Kontext des gesamten Satzes von Anwendungen geschieht.
Also über den Stapel.

Wir verwenden Open Source Software. Im Zentrum steht Zabbix, das wir hauptsächlich als Warnsystem verwenden. Jeder weiß, dass es ideal für die Überwachung der Infrastruktur ist. Was ist hier gemeint? Dies sind die Low-Level-Metriken, über die jedes Unternehmen verfügt, das über ein eigenes Rechenzentrum verfügt (und Sportmaster über eigene Rechenzentren) - Servertemperatur, Speicherstatus, RAID, Metriken für Netzwerkgeräte.
Wir haben Zabbix in Telegram Messenger und Microsoft Teams integriert, die aktiv in Teams eingesetzt werden. Zabbix deckt die Schicht des eigentlichen Netzwerks, der Hardware und teilweise der Software ab, ist jedoch kein Allheilmittel. Wir bereichern diese Daten von einigen anderen Diensten. In Bezug auf die Hardwareebene stellen wir beispielsweise eine direkte Verbindung über die API zu unserem Virtualisierungssystem her und sammeln Daten.
Was sonst. Zusätzlich zu Zabbix verwenden wir Prometheus, mit dem Metriken in einer dynamischen Umgebungsanwendung überwacht werden können. Das heißt, wir können Anwendungsmetriken über den HTTP-Endpunkt empfangen und müssen uns keine Gedanken darüber machen, welche Metriken in ihn geladen werden sollen und welche nicht. Basierend auf diesen Daten können Sie analytische Abfragen bearbeiten.
Datenquellen für andere Ebenen, z. B. Geschäftsmetriken, sind in drei Komponenten unterteilt.
Erstens sind dies externe Geschäftssysteme, Google Analytics. Wir erfassen Metriken aus Protokollen. Von ihnen erhalten wir Daten über aktive Benutzer, Conversions und alles andere, was mit dem Geschäft zu tun hat. Zweitens handelt es sich um ein UI-Überwachungssystem. Es sollte detaillierter beschrieben werden.
Es war einmal, wir haben mit manuellen Tests begonnen und es hat sich zu Autotests für Funktion und Integration entwickelt. Wir haben die Überwachung daraus gemacht, nur die Hauptfunktionalität belassen und an Markierungen gebunden, die so stabil wie möglich sind und sich im Laufe der Zeit nicht oft ändern.
Die neue Teamstruktur impliziert, dass alle Anwendungsaktivitäten an Produktteams gebunden sind, sodass wir keine reinen Tests mehr durchführen. Stattdessen haben wir die Überwachung der Benutzeroberfläche anhand von Tests durchgeführt, die in Java, Selenium und Jenkins geschrieben wurden (als System zum Starten und Generieren von Berichten verwendet).
Wir hatten viele Tests, aber am Ende entschieden wir uns, zur Hauptstraße zu gehen, der Metrik der obersten Ebene. Und wenn wir viele spezifische Tests haben, wird es schwierig sein, die Daten auf dem neuesten Stand zu halten. Jede nachfolgende Version wird das gesamte System erheblich beschädigen, und wir werden uns nur mit der Behebung befassen. Deshalb haben wir uns an sehr grundlegende Dinge gebunden, die sich selten ändern, und sie nur überwacht.
Drittens ist die Datenquelle ein zentrales Protokollierungssystem. Für Protokolle verwenden wir Elastic Stack. Anschließend können wir diese Daten in unser Überwachungssystem für Geschäftsmetriken ziehen. Darüber hinaus funktioniert unser in Python geschriebener eigener Überwachungs-API-Dienst, der alle Dienste über die API abfragt und Daten von ihnen an Zabbix weiterleitet.
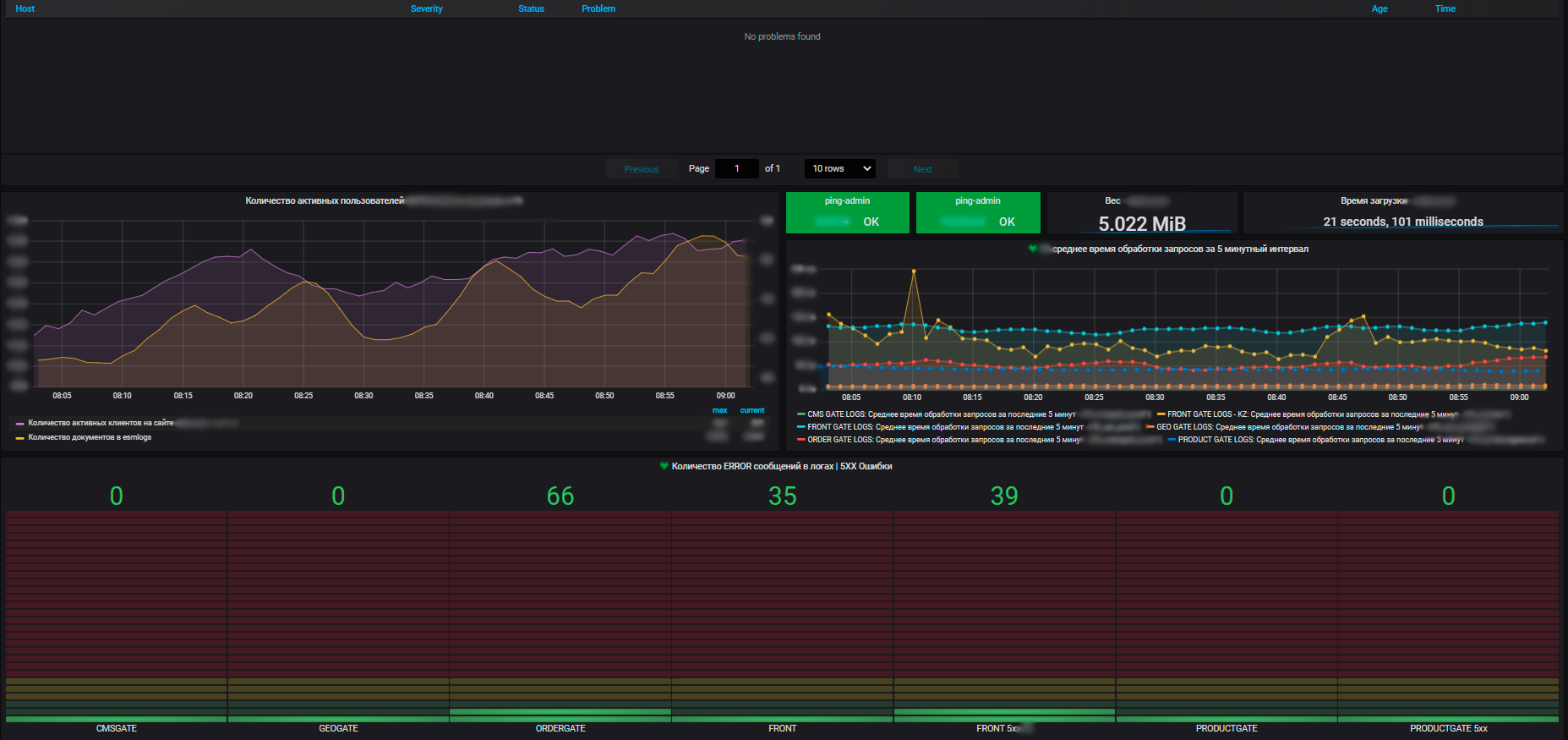
Ein weiteres unersetzliches Merkmal der Überwachung ist die Visualisierung. Wir bauen es auf Basis von Grafana. Neben anderen Visualisierungssystemen zeichnet es sich dadurch aus, dass Metriken aus verschiedenen Datenquellen im Dashboard visualisiert werden können. Wir können die Top-Level-Metriken des Online-Shops erfassen, z. B. die Anzahl der Bestellungen, die in der letzten Stunde im DBMS aufgegeben wurden, die Leistungsmetriken des Betriebssystems, auf dem dieser Online-Shop von Zabbix ausgeführt wird, und die Metriken der Instanzen dieser Anwendung von Prometheus. Und das alles auf einem Dashboard. Visuell und zugänglich.
Lassen Sie mich auf die Sicherheit eingehen - wir stellen jetzt das System fertig, das wir anschließend in das globale Überwachungssystem integrieren werden. Meiner Meinung nach sind die Hauptprobleme des E-Commerce im Bereich der Informationssicherheit mit Bots, Parsern und Brute-Force verbunden. Dies sollte überwacht werden, da sie alle sowohl die Leistung unserer Anwendungen als auch die Reputation aus geschäftlicher Sicht entscheidend beeinflussen können. Und mit dem gewählten Stack decken wir diese Aufgaben erfolgreich ab.
Ein weiterer wichtiger Punkt ist, dass die Anwendungsschicht von Prometheus gesammelt wird. Er selbst ist auch in Zabbix integriert. Außerdem haben wir Sitespeed, einen Dienst, mit dem wir Parameter wie die Geschwindigkeit des Ladens unserer Seite, Engpässe, das Rendern von Seiten, das Laden von Skripten usw. entsprechend betrachten können. Er ist auch über die API integriert. Damit die Metriken in Zabbix gesammelt werden, alarmieren wir auch von dort aus. Alle bisherigen Warnungen beziehen sich auf die wichtigsten Versandmethoden (im Moment sind dies E-Mail und Telegramm, sie haben kürzlich MS-Teams verbunden). Es ist geplant, den Alarm so zu aktivieren, dass Smart Bots als Service fungieren und allen interessierten Produktteams Überwachungsinformationen zur Verfügung stellen.
Für uns sind nicht nur Metriken einzelner Informationssysteme wichtig, sondern auch allgemeine Metriken für die gesamte Infrastruktur, die Anwendungen verwenden: Cluster von physischen Servern, auf denen virtuelle Maschinen ausgeführt werden, Traffic Balancer, Network Load Balancer, das Netzwerk selbst, Nutzung von Kommunikationskanälen. Plus Metriken für unsere eigenen Rechenzentren (wir haben mehrere davon und die Infrastruktur ist ziemlich bedeutend).
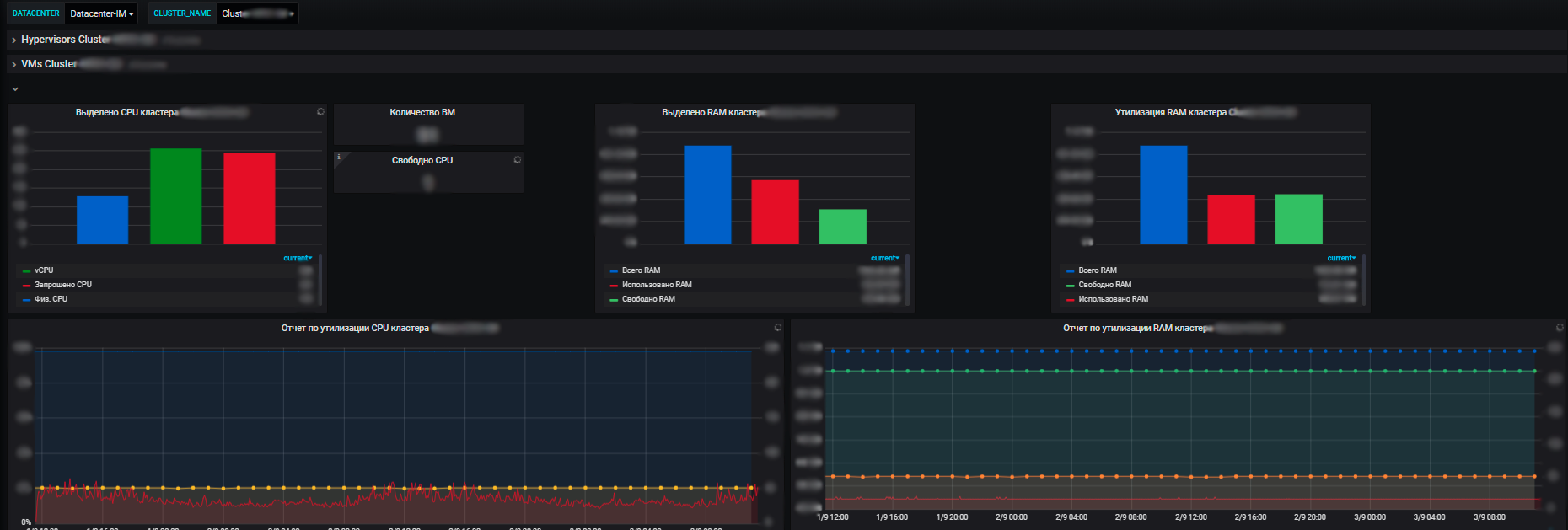
Die Vorteile unseres Überwachungssystems bestehen darin, dass wir mit seiner Hilfe den Gesundheitszustand aller Systeme erkennen und ihre Auswirkungen aufeinander und auf gemeinsame Ressourcen bewerten können. Und letztendlich ermöglicht es eine Ressourcenplanung, für die auch wir verantwortlich sind. Wir verwalten Serverressourcen - einen Pool im Rahmen des E-Commerce, führen neue Geräte ein und nehmen sie außer Betrieb, kaufen neue Geräte, führen ein Audit der Ressourcennutzung durch und so weiter. Jedes Jahr planen die Teams neue Projekte, entwickeln ihre Systeme und es ist wichtig, dass wir ihnen Ressourcen zur Verfügung stellen.
Mithilfe von Metriken sehen wir den Trend des Ressourcenverbrauchs unserer Informationssysteme. Und schon auf ihrer Basis können wir etwas planen. Auf der Virtualisierungsebene erfassen wir Daten und sehen Informationen zur verfügbaren Ressourcenmenge im Kontext von Rechenzentren. Und bereits im Rechenzentrum können Sie die Auslastung und die tatsächliche Verteilung sowie den Ressourcenverbrauch anzeigen. Darüber hinaus sowohl mit eigenständigen Servern als auch mit virtuellen Maschinen und Clustern physischer Server, auf denen sich alle diese virtuellen Maschinen kräftig drehen.
Perspektiven
Jetzt haben wir den Kern des gesamten Systems fertig, aber es gibt noch genügend Punkte, an denen wir arbeiten können. Zumindest ist dies eine Ebene der Informationssicherheit, aber es ist auch wichtig, zum Netzwerk zu gelangen, Warnungen zu entwickeln und das Problem mit der Korrelation zu lösen. Wir haben viele Ebenen und Systeme, es gibt viel mehr Metriken auf jeder Ebene. Es stellt sich heraus, dass eine Matroschka den Grad einer Matroschka hat.
Unsere Aufgabe ist es letztendlich, die richtigen Warnungen zu machen. Wenn beispielsweise erneut ein Problem mit der Hardware mit einer virtuellen Maschine aufgetreten ist und eine wichtige Anwendung vorhanden ist und der Dienst in keiner Weise gesichert wurde. Wir stellen fest, dass die virtuelle Maschine gestorben ist. Dann werden sie Geschäftsmetriken alarmieren: Benutzer sind irgendwo verschwunden, es gibt keine Konvertierung, die Benutzeroberfläche in der Benutzeroberfläche ist nicht verfügbar, Software und Dienste sind ebenfalls gestorben.
In dieser Situation erhalten wir Spam von Warnungen, und dies passt nicht mehr in das Format eines korrekten Überwachungssystems. Die Frage der Korrelation stellt sich. Daher sollte unser Überwachungssystem im Idealfall sagen: "Leute, Ihre physische Maschine ist gestorben, und zusammen mit dieser Anwendung und solchen Metriken", mit Hilfe einer Warnung, anstatt uns wütend mit Hunderten von Warnungen zu bombardieren. Sie muss die Hauptsache melden - den Grund, der aufgrund seiner Lokalisierung zur Schnelligkeit der Problembeseitigung beiträgt.
Unser Benachrichtigungs- und Alarmbehandlungssystem basiert auf einem 24/7-Hotline-Service. Dort werden alle Benachrichtigungen gesendet, die für uns ein Muss sind und in der Checkliste enthalten sind. Jede Warnung muss eine Beschreibung haben: Was ist passiert, was bedeutet es tatsächlich, was betrifft es? Und auch einen Link zum Dashboard und Anweisungen, was in diesem Fall zu tun ist.
Das ist alles für die Anforderungen für die Erstellung des Alarms. Darüber hinaus kann sich die Situation in zwei Richtungen entwickeln - entweder liegt ein Problem vor und es muss gelöst werden, oder es ist ein Fehler im Überwachungssystem aufgetreten. Aber auf jeden Fall müssen Sie es herausfinden.
Im Durchschnitt fallen derzeit pro Tag etwa hundert Warnungen an uns. Dies berücksichtigt die Tatsache, dass die Korrelation der Warnungen noch nicht richtig konfiguriert wurde. Und wenn wir technische Arbeiten ausführen müssen und etwas zwangsweise ausschalten, wächst ihre Anzahl erheblich.
Neben der Überwachung der von uns betriebenen Systeme und der Erfassung von Metriken, die auf unserer Seite als wichtig angesehen werden, ermöglicht das Überwachungssystem die Erfassung von Daten für Produktteams. Sie können die Zusammensetzung der Metriken innerhalb der hier überwachten Informationssysteme beeinflussen.
Unser Kollege kann kommen und nach einer Metrik fragen, die für uns und das Team nützlich ist. Oder das Team verfügt möglicherweise nicht über genügend grundlegende Messdaten, sondern muss eine bestimmte nachverfolgen. In Grafana erstellen wir einen Bereich für jedes Team und erteilen Administratorrechte. Wenn ein Team Dashboards benötigt, diese aber selbst nicht wissen, wie es geht, helfen wir ihnen.
Da wir uns außerhalb des Stroms der Teamwertschöpfung, ihrer Freigaben und Planung befinden, kommen wir nach und nach zu dem Schluss, dass die Freigaben aller Systeme nahtlos sind und täglich ohne Abstimmung mit uns eingeführt werden können. Für uns ist es wichtig, diese Releases zu verfolgen, da sie möglicherweise den Betrieb der Anwendung beeinträchtigen und etwas beschädigen können. Dies ist von entscheidender Bedeutung. Zum Verwalten von Releases verwenden wir Bamboo, von wo aus wir Daten über die API abrufen und sehen können, welche Releases in welchen Informationssystemen veröffentlicht wurden und welchen Status sie haben. Und das Wichtigste ist, zu welcher Zeit. Wir setzen Release-Marker auf die wichtigsten kritischen Metriken, was bei Problemen visuell sehr bezeichnend ist.
Auf diese Weise können wir den Zusammenhang zwischen Neuerscheinungen und aufkommenden Problemen erkennen. Die Hauptidee ist, zu verstehen, wie das System auf allen Ebenen funktioniert, um das Problem schnell zu lokalisieren und ebenso schnell zu beheben. In der Tat kommt es häufig vor, dass die meiste Zeit damit verbracht wird, das Problem nicht zu lösen, sondern die Ursache zu finden.
Und in diese Richtung wollen wir uns in Zukunft auf Proaktivität konzentrieren. Idealerweise möchte ich im Voraus über ein bevorstehendes Problem Bescheid wissen und nicht nachträglich, um seine Prävention zu behandeln, keine Lösung. Manchmal gibt es Fehlalarme des Überwachungssystems, sowohl aufgrund menschlicher Fehler als auch aufgrund von Änderungen in der Anwendung. Wir arbeiten daran, debuggen und versuchen, Benutzer davor zu warnen, bevor Manipulationen am Überwachungssystem vorgenommen werden, die es bei uns verwenden. oder führen Sie diese Ereignisse im technischen Fenster aus.
Das System wurde also eingeführt und funktioniert seit Beginn des Frühlings erfolgreich ... und zeigt einen sehr realen Gewinn. Dies ist natürlich nicht die endgültige Version, wir werden viele weitere nützliche Funktionen vorstellen. Bei so vielen Integrationen und Anwendungen ist die Automatisierung der Überwachung derzeit jedoch unverzichtbar.
Wenn Sie auch große Projekte mit einer Vielzahl von Integrationen überwachen, schreiben Sie in die Kommentare, welche Silberkugel Sie dafür gefunden haben.