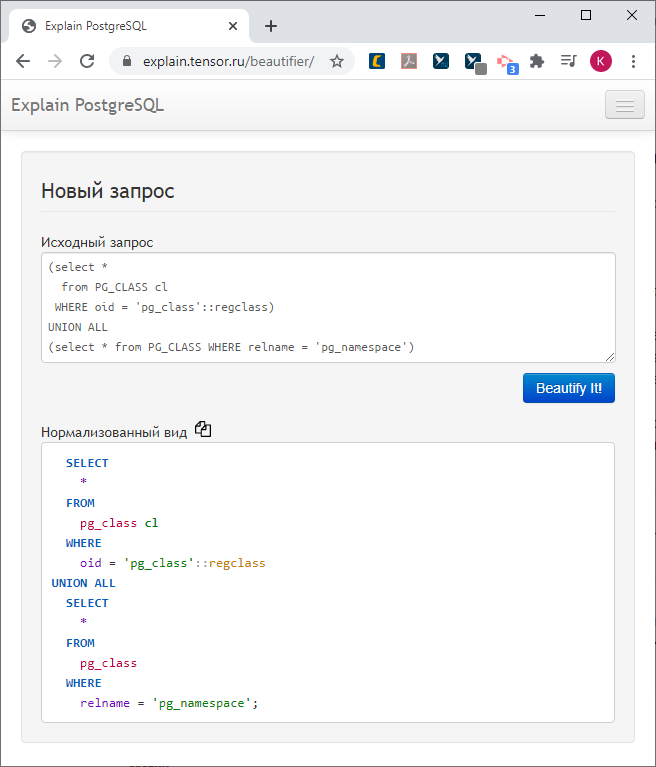
... in eine schön gestaltete Abfrage mit kontextbezogenen Hinweisen für die entsprechenden Plan-Knoten:

In dieser Abschrift des zweiten Teils meines Vortrags auf der PGConf.Russia 2020 werde ich Ihnen erzählen, wie wir das geschafft haben.
Das Transkript des ersten Teils, das sich mit typischen Problemen bei der Abfrageleistung und deren Lösungen befasst, finden Sie im Artikel "Rezepte für angeschlagene SQL-Abfragen" .
Zuerst werden wir malen - und wir werden den Plan nicht mehr malen, wir haben ihn bereits gemalt, wir haben ihn bereits schön und verständlich, aber eine Bitte.
Es schien uns, dass die Abfrage, die mit einem unformatierten "Blatt" aus dem Protokoll gezogen wurde, sehr hässlich und daher unangenehm aussieht.

Besonders wenn die Entwickler im Code den Anforderungshauptteil (dies ist natürlich ein Anti-Pattern, aber es passiert) in einer Zeile "kleben". Grusel!
Lass es uns irgendwie schöner zeichnen.
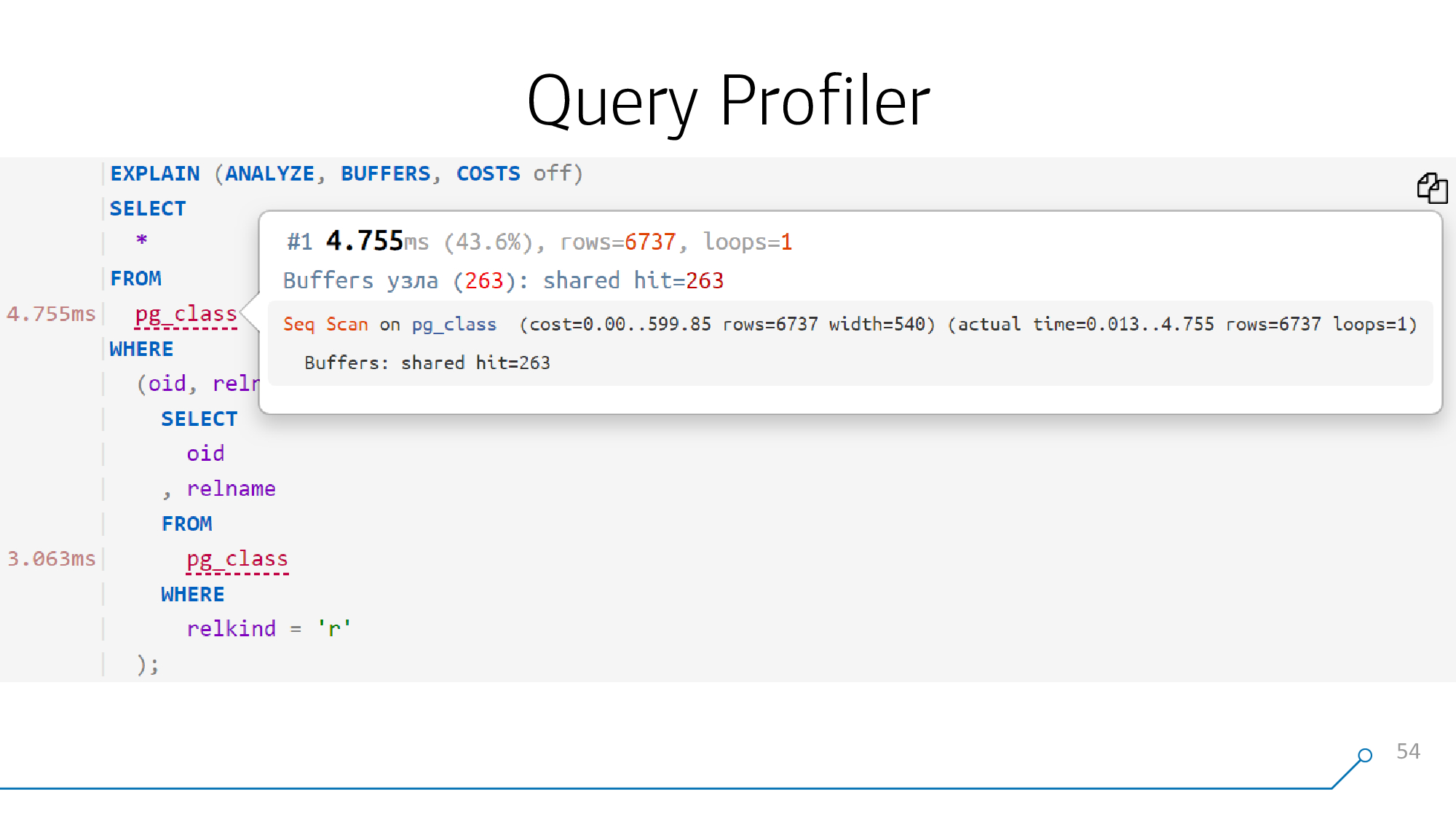
Und wenn wir es schön zeichnen können, dh den Anforderungskörper zerlegen und wieder zusammensetzen können, können wir jedem Objekt dieser Anforderung einen Hinweis hinzufügen - was an der entsprechenden Stelle im Plan passiert ist.
Syntax-Abfragebaum
Dazu muss die Anfrage zuerst analysiert werden.
Da unser Systemkern auf NodeJS läuft , haben wir Module dafür erstellt, die Sie auf GitHub finden . Tatsächlich handelt es sich hierbei um erweiterte "Bindungen" an die Interna des PostgreSQL-Parsers. Das heißt, die Grammatik wird einfach binär kompiliert und von der NodeJS-Seite an sie gebunden. Wir haben die Module anderer Leute als Grundlage genommen - hier gibt es kein großes Geheimnis.
Wir geben den Anforderungshauptteil an die Eingabe unserer Funktion weiter - an der Ausgabe erhalten wir den analysierten Syntaxbaum in Form eines JSON-Objekts.

Jetzt können Sie durch diesen Baum in die entgegengesetzte Richtung gehen und die Anfrage mit den gewünschten Einrückungen, Farben und Formatierungen sammeln. Nein, es ist nicht konfigurierbar, aber es schien uns praktisch zu sein.

Zuordnungs- und Plan-Knoten zuordnen
Nun wollen wir sehen, wie wir den Plan, den wir im ersten Schritt analysiert haben, und die Abfrage, die wir im zweiten Schritt analysiert haben, kombinieren können.
Nehmen wir ein einfaches Beispiel: Wir haben eine Anfrage, die einen CTE generiert und zweimal liest. Er generiert einen solchen Plan.

CTE
Wenn Sie es sich vor der 12. Version genau ansehen (oder mit dem Schlüsselwort beginnen
MATERIALIZED), ist die Bildung von CTE eine absolute Barriere für den Planer .
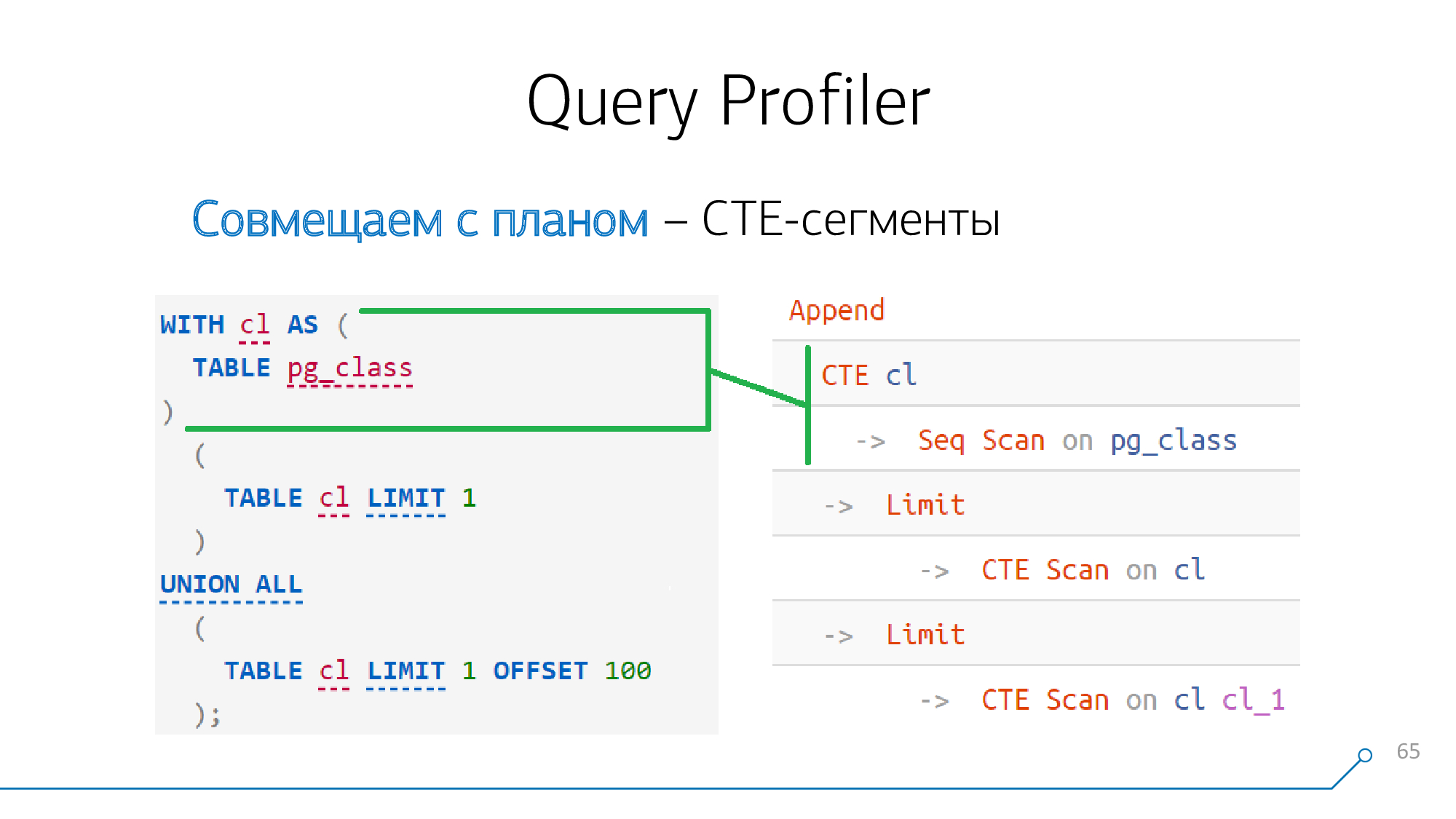
Dies bedeutet, dass wenn wir die Erzeugung von CTEs irgendwo in der Anfrage und irgendwo im Plan eines Knotens sehen
CTE, diese Knoten definitiv miteinander "kämpfen", wir sie sofort kombinieren können.
Sternchenproblem : CTEs können verschachtelt werden.

Es gibt sehr schlecht verschachtelte und sogar die gleichen Namen. Zum Beispiel können
CTE ASie es im Inneren tun CTE Xund CTE Bes auf derselben Ebene im Inneren erneut tun CTE X:
WITH A AS (
WITH X AS (...)
SELECT ...
)
, B AS (
WITH X AS (...)
SELECT ...
)
...Sie müssen dies beim Vergleich verstehen. Es ist sehr schwierig, dies mit „Augen“ zu verstehen - sogar den Plan zu sehen, sogar den Hauptteil der Anfrage zu sehen. Wenn Ihre CTE-Generation komplex und verschachtelt ist und die Anforderungen groß sind, ist sie völlig unbewusst.
UNION
Wenn unsere Abfrage ein Schlüsselwort enthält
UNION [ALL](der Operator zum Verbinden zweier Auswahlen), entspricht entweder ein Knoten Appendoder ein Knoten im Plan diesem Recursive Union.

Was "oben" oben
UNIONist, ist das erste Kind unseres Knotens, was "unten" ist, ist das zweite. Wenn UNIONmehrere Blöcke gleichzeitig durch uns "geklebt" werden, Appendgibt es immer noch nur einen Knoten, aber es werden nicht zwei Kinder, sondern viele - in der Reihenfolge, in der sie gehen:
(...) -- #1
UNION ALL
(...) -- #2
UNION ALL
(...) -- #3Append
-> ... #1
-> ... #2
-> ... #3
Problem "mit einem Stern" : Innerhalb der Generierung einer rekursiven Auswahl (
WITH RECURSIVE) kann es auch mehrere geben UNION. Aber nur der allerletzte Block nach dem letzten ist immer rekursiv UNION. Alles oben ist eins, aber anders UNION:
WITH RECURSIVE T AS(
(...) -- #1
UNION ALL
(...) -- #2,
UNION ALL
(...) -- #3, T
)
...Sie müssen auch in der Lage sein, solche Beispiele "einzufügen". In diesem Beispiel sehen wir, dass
UNIONunsere Anfrage 3 Segmente enthielt. Dementsprechend UNION entspricht einer einem Append-knoten und der andere entspricht einem Recursive Union.

Lese- / Schreibdaten
Das war's, wir haben es ausgebreitet, jetzt wissen wir, welcher Teil der Anfrage welchem Teil des Plans entspricht. Und in diesen Stücken können wir leicht und natürlich jene Objekte finden, die "lesbar" sind.
Aus Sicht der Abfrage wissen wir nicht, ob es sich um eine Tabelle oder einen CTE handelt, aber sie werden von demselben Knoten bezeichnet
RangeVar. Und in Bezug auf "lesbar" - dies ist auch eine ziemlich begrenzte Anzahl von Knoten:
Seq Scan on [tbl]Bitmap Heap Scan on [tbl]Index [Only] Scan [Backward] using [idx] on [tbl]CTE Scan on [cte]Insert/Update/Delete on [tbl]
Wir kennen die Struktur des Plans und der Abfrage, wir kennen die Entsprechung der Blöcke, wir kennen die Namen der Objekte - wir machen einen eindeutigen Vergleich.

Wieder ein Sternchenproblem . Wir nehmen die Anfrage an, führen sie aus, wir haben keine Aliase - wir lesen sie nur zweimal von einem CTE.

Wir schauen uns den Plan an - was ist das Problem? Warum ist unser Alias rausgekommen? Wir haben es nicht bestellt. Woher kommt er von so einem "Nummernschild"?
PostgreSQL fügt es selbst hinzu. Sie müssen nur verstehen, dass ein solcher Alias für uns zum Vergleich mit dem Plan keinen Sinn ergibt. Er wird einfach hier hinzugefügt. Lasst uns nicht auf ihn achten.
Die zweite Aufgabe ist "mit einem Sternchen" : Wenn wir aus einer partitionierten Tabelle lesen, erhalten wir einen Knoten
AppendoderMerge Append, Die aus einer großen Anzahl von „Kinder“, und von denen jeder irgendwie Scan‚th des Abschnitts der Tabelle: Seq Scan, Bitmap Heap Scanoder Index Scan. In jedem Fall handelt es sich bei diesen "untergeordneten Elementen" jedoch nicht um komplexe Abfragen. Auf diese Weise können diese Knoten von Appendwann unterschieden werden UNION.

Wir verstehen auch solche Knoten, wir sammeln sie "auf einem Stapel" und sagen: " Alles, was Sie von megatable lesen, ist genau hier und unten im Baum ."
"Einfache" Knoten zum Empfangen von Daten

Values Scanin Plan passt VALUESauf Anfrage.
Result- Dies ist eine Anfrage ohne FROMwie SELECT 1. Oder wenn Sie einen wissentlich falschen Ausdruck im WHERE-block haben (dann tritt das Attribut auf One-Time Filter):
EXPLAIN ANALYZE
SELECT * FROM pg_class WHERE FALSE; -- 0 = 1Result (cost=0.00..0.00 rows=0 width=230) (actual time=0.000..0.000 rows=0 loops=1)
One-Time Filter: false
Function Scan"Map" zum gleichnamigen SRF.
Bei verschachtelten Abfragen ist jedoch alles komplizierter - leider werden sie nicht immer zu
InitPlan/ SubPlan. Manchmal verwandeln sie sich in ... Joinoder ... Anti Join, besonders wenn Sie so etwas schreiben WHERE NOT EXISTS .... Und es ist nicht immer möglich, dort zu kombinieren - es gibt keine Operatoren, die den Plan-Knoten im Plan-Text entsprechen.
Wieder eine Aufgabe mit einem Sternchen : mehrere
VALUESin der Anfrage. In diesem Fall und im Plan erhalten Sie mehrere Knoten Values Scan.

"Nummerierte" Suffixe helfen dabei, sie voneinander zu unterscheiden. Sie werden genau in der Reihenfolge hinzugefügt, in der die entsprechenden
VALUESBlöcke entlang der Anforderung von oben nach unten gefunden werden.
Datenverarbeitung
Es scheint, dass alles in unserer Anfrage geklärt wurde - es war nur noch eine übrig
Limit.
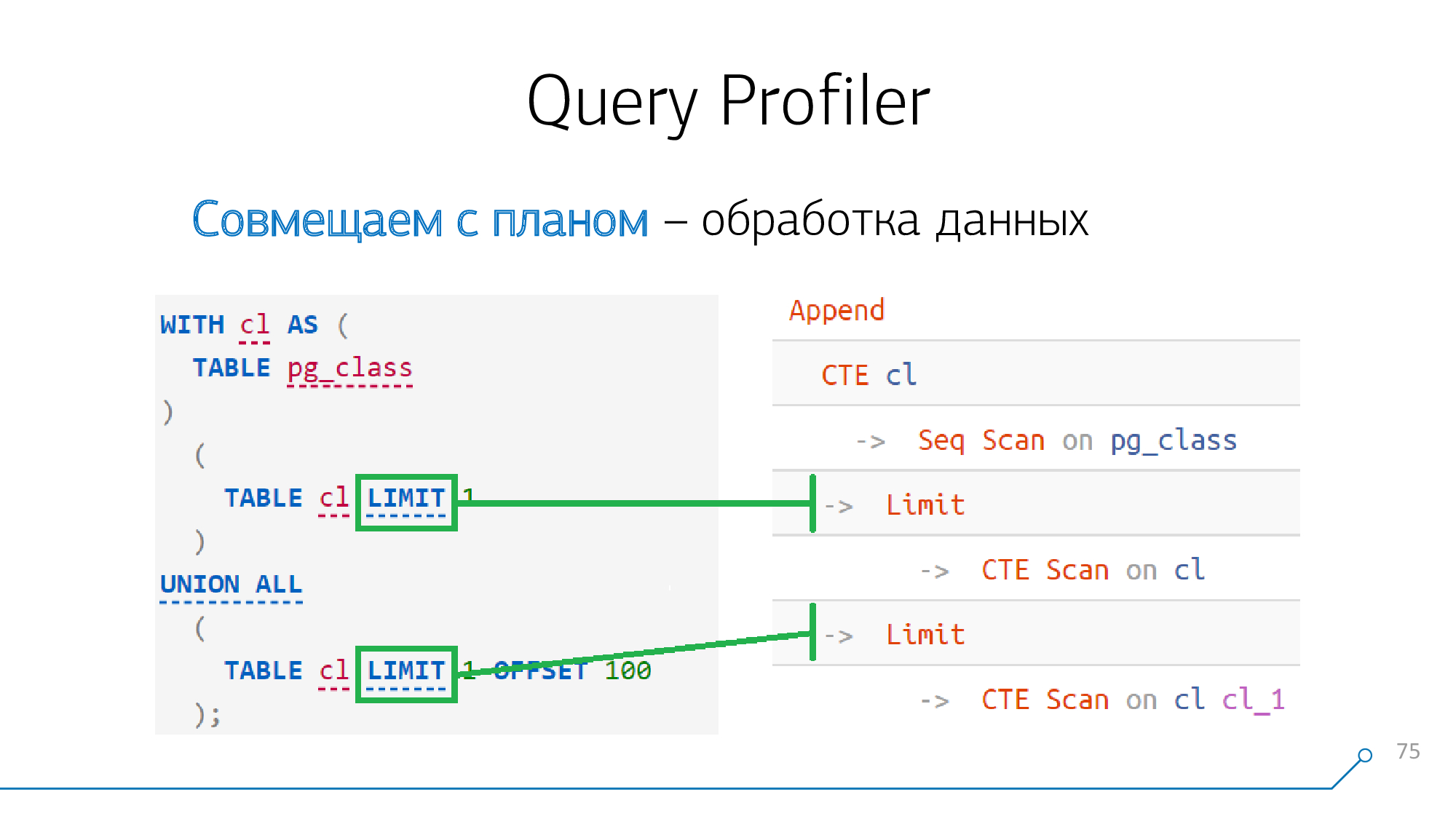
Aber alles ist einfach - wie die Knoten
Limit, Sort, Aggregate, WindowAgg, Unique„mapyatsya“ one-to-one zu den entsprechenden Aussagen in der Anforderung, wenn sie da sind. Es gibt keine "Sterne" und keine Schwierigkeiten.

BEITRETEN
Schwierigkeiten entstehen, wenn wir uns miteinander verbinden wollen
JOIN. Dies wird nicht immer gemacht, aber Sie können.

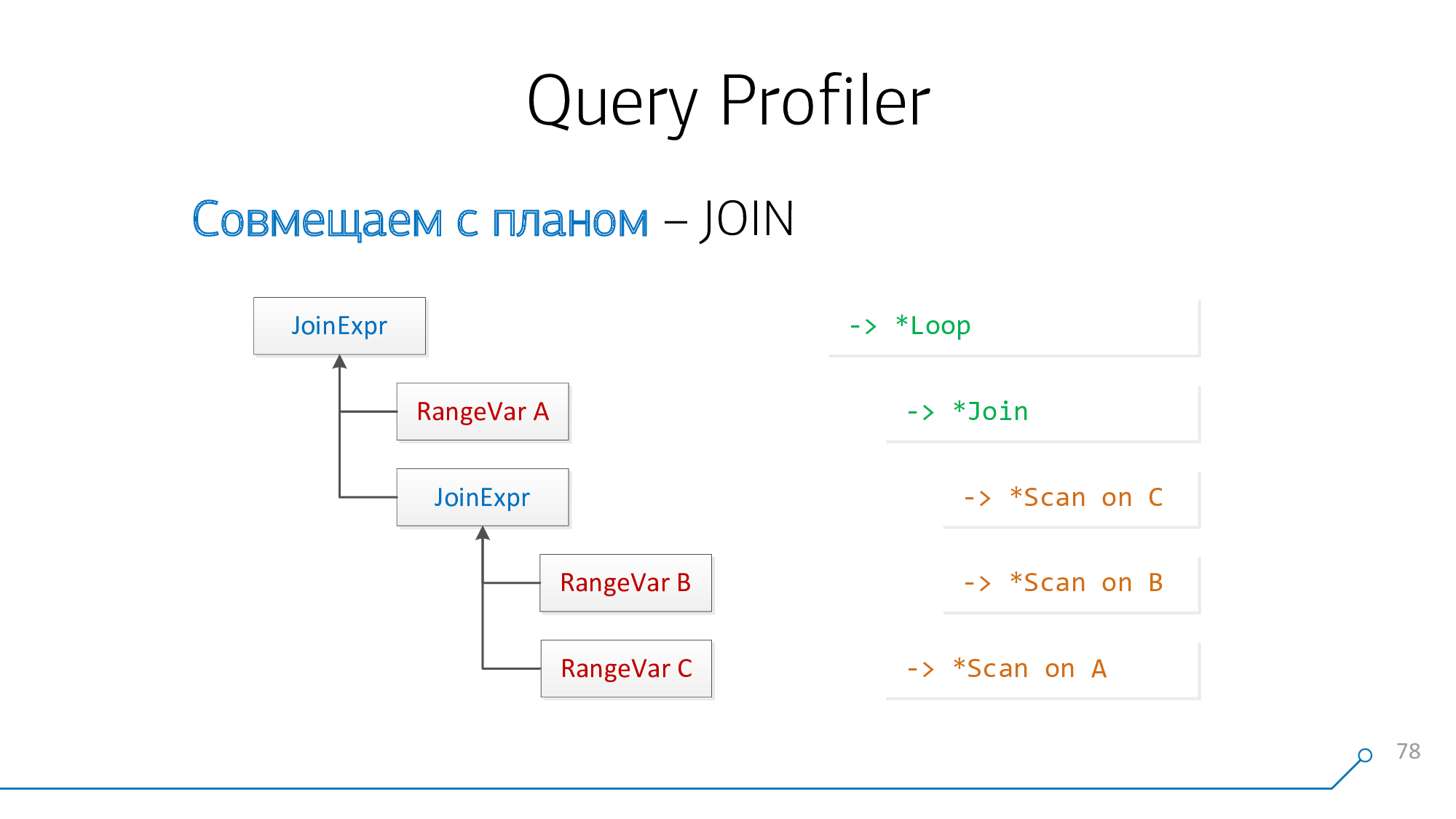
Aus Sicht des Anforderungsparsers haben wir einen Knoten
JoinExpr, der genau zwei untergeordnete Elemente hat - links und rechts. Dies ist jeweils das, was "über" Ihrem JOIN steht und was "darunter" in der Anfrage steht.
Und aus Sicht des Plans sind dies zwei Nachkommen einiger
* Loop/ * Join-Knoten. Nested Loop, Hash Anti Join... - das ist etwas.
Verwenden wir eine einfache Logik: Wenn wir die Platten A und B haben, die sich im Plan "verbinden", dann könnten sie in der Anfrage entweder
A-JOIN-Boder gefunden werden B-JOIN-A. Versuchen wir es auf diese Weise zu kombinieren, versuchen wir es umgekehrt zu kombinieren und so weiter, bis solche Paare ausgehen.
Nehmen Sie unseren Syntaxbaum, nehmen Sie unsere Gliederung, schauen Sie sie sich an ... es sieht nicht so aus!
Lassen Sie es uns in Form von Grafiken neu zeichnen - oh, es ist schon so etwas wie etwas geworden!
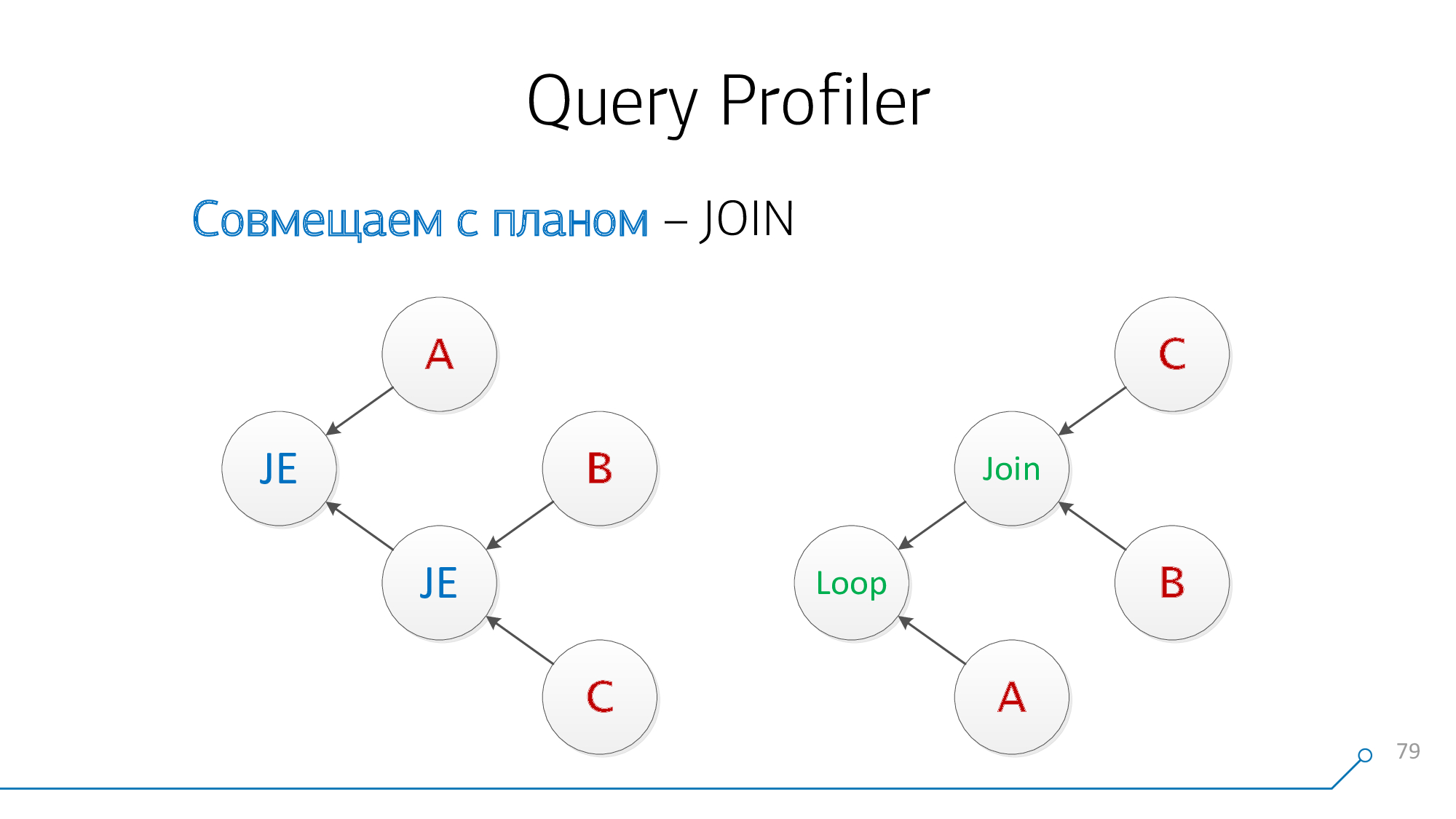
Beachten wir, dass wir Knoten haben, die gleichzeitig Kinder B und C haben - es ist uns egal, in welcher Reihenfolge. Kombinieren wir sie und drehen wir das Knotenbild.

Mal sehen. Jetzt haben wir Knoten mit Kindern A und Paaren (B + C) - auch mit ihnen kompatibel.
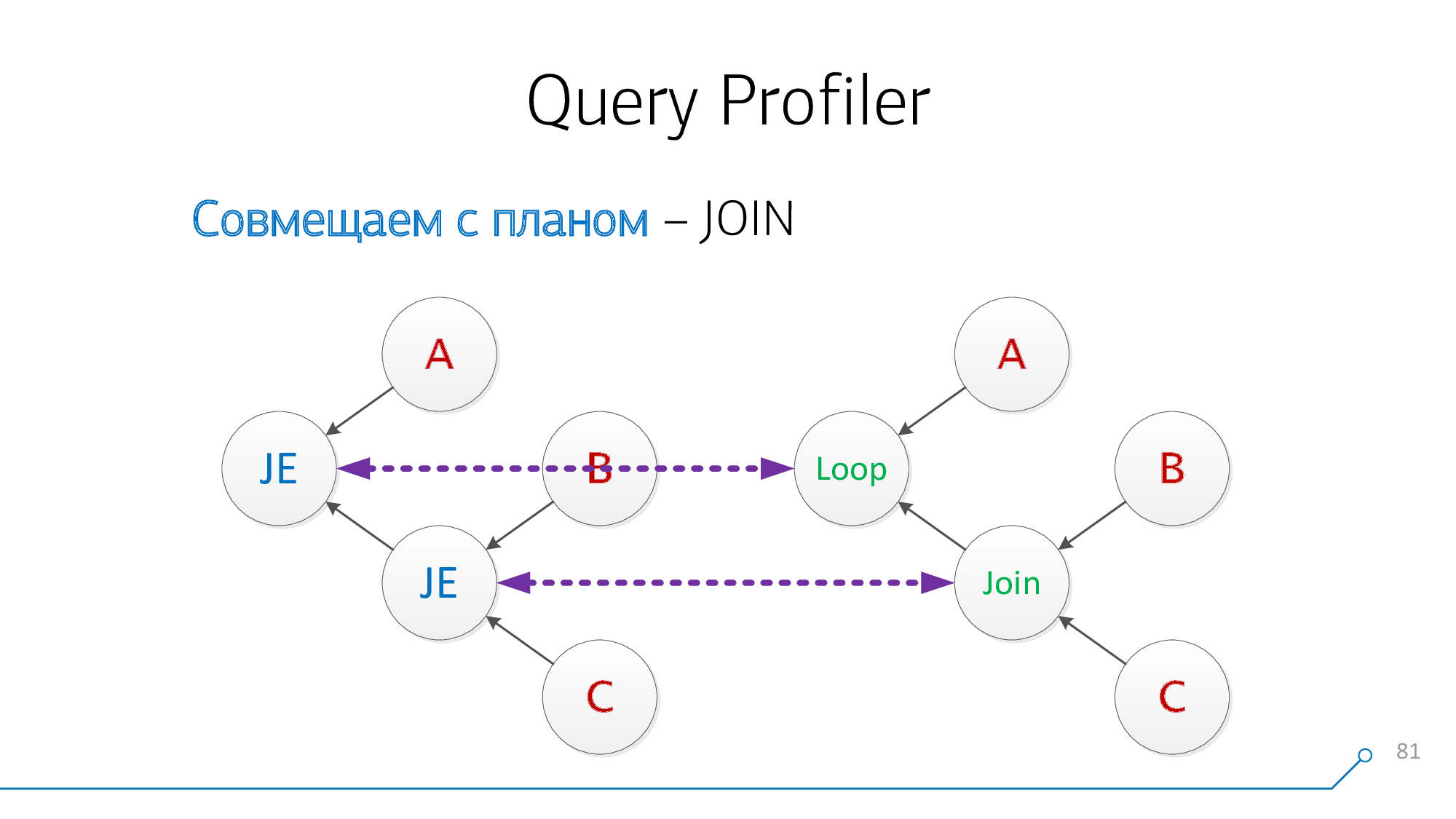
Ausgezeichnet! Es stellt sich heraus, dass wir diese beiden
JOINaus der Abfrage erfolgreich mit den Plan-Knoten kombiniert haben .
Leider ist diese Aufgabe nicht immer gelöst.
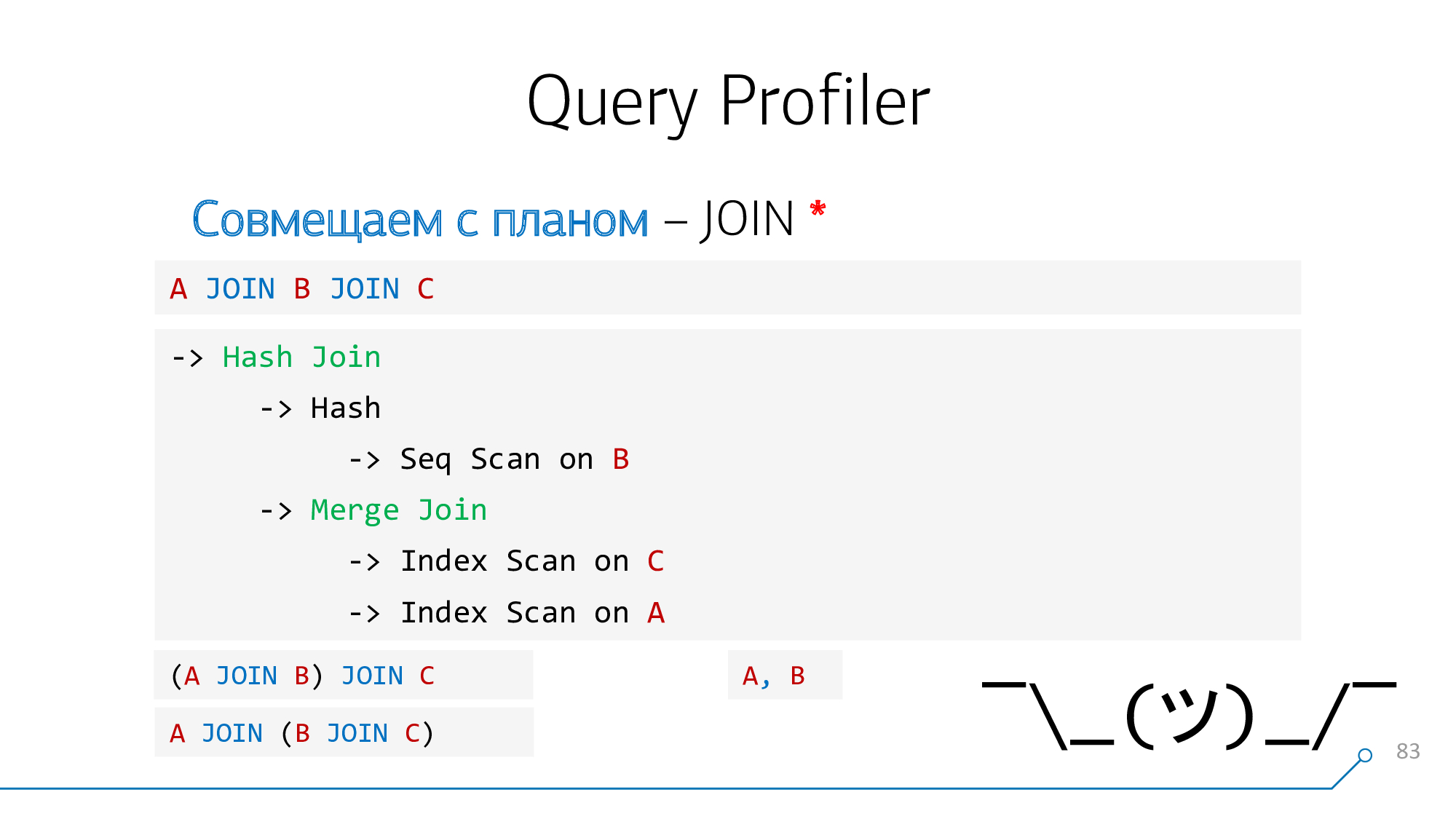
Wenn zum Beispiel in der Abfrage
A JOIN B JOIN C, aber im Plan, zuerst die "extremen" Knoten A und C verbunden wurden. Und in der Abfrage gibt es keinen solchen Operator, wir haben nichts hervorzuheben, es gibt nichts, an das der Hinweis gebunden werden kann. Das gleiche gilt für das "Komma" beim Schreiben A, B.
In den meisten Fällen können jedoch fast alle Knoten "gelöst" werden, und Sie erhalten diese Art der Profilerstellung rechtzeitig auf der linken Seite - buchstäblich wie in Google Chrome, wenn Sie JavaScript-Code analysieren. Sie können sehen, wie lange jede Zeile und jede Anweisung "ausgeführt" wurde.

Um Ihnen die Nutzung all dieser Funktionen zu erleichtern, haben wir einen Archivspeicher erstellt , in dem Sie Ihre Pläne zusammen mit den zugehörigen Anforderungen speichern und dann finden oder einen Link mit jemandem teilen können.
Wenn Sie nur eine unlesbare Abfrage in eine angemessene Form bringen müssen, verwenden Sie unseren "Normalisierer" .