CPU-Limits und Drosselung
Wie viele andere Kubernetes-Nutzer empfiehlt Google dringend, die CPU-Grenzwerte anzupassen . Ohne diese Konfiguration können die Container im Knoten die gesamte Prozessorleistung in Anspruch nehmen, was wiederum dazu führt, dass wichtige Kubernetes-Prozesse (zum Beispiel
kubelet) nicht mehr auf Anforderungen reagieren. Das Festlegen von CPU-Grenzwerten ist daher ein guter Weg, um Ihre Knoten zu schützen.
Prozessorlimits legen für den Container die maximale Prozessorzeit fest, die er für einen bestimmten Zeitraum verwenden kann (standardmäßig 100 ms), und der Container wird dieses Limit niemals überschreiten. Kubernetes verwendet ein spezielles Tool CFS Quota , um den Container zu drosseln und zu verhindern, dass er den Grenzwert überschreitet.Letztendlich schränkt ein solcher künstlicher Prozessor jedoch die geringere Leistung ein und verlängert die Reaktionszeit Ihrer Container.
Was kann passieren, wenn wir keine CPU-Grenzwerte festlegen?
Leider mussten wir uns selbst mit diesem Problem befassen. Jeder Knoten verfügt über einen Prozess, der für die Verwaltung von Containern verantwortlich ist
kubelet, und reagiert nicht mehr auf Anforderungen. In diesem NotReadyFall wird der Knoten in den Status versetzt , und die Container von ihm werden an eine andere Stelle umgeleitet und verursachen dieselben Probleme bereits auf neuen Knoten. Kein ideales Szenario, um es milde auszudrücken.
Manifestieren von Drosselungs- und Reaktionsproblemen
Die Schlüsselmetrik für die Verfolgung von Containern ist,
trottlingwie oft Ihr Container gedrosselt wurde. Wir haben mit Interesse festgestellt, dass in einigen Containern eine Drosselung vorhanden ist, unabhängig davon, ob die Belastung des Prozessors maximal war oder nicht. Schauen
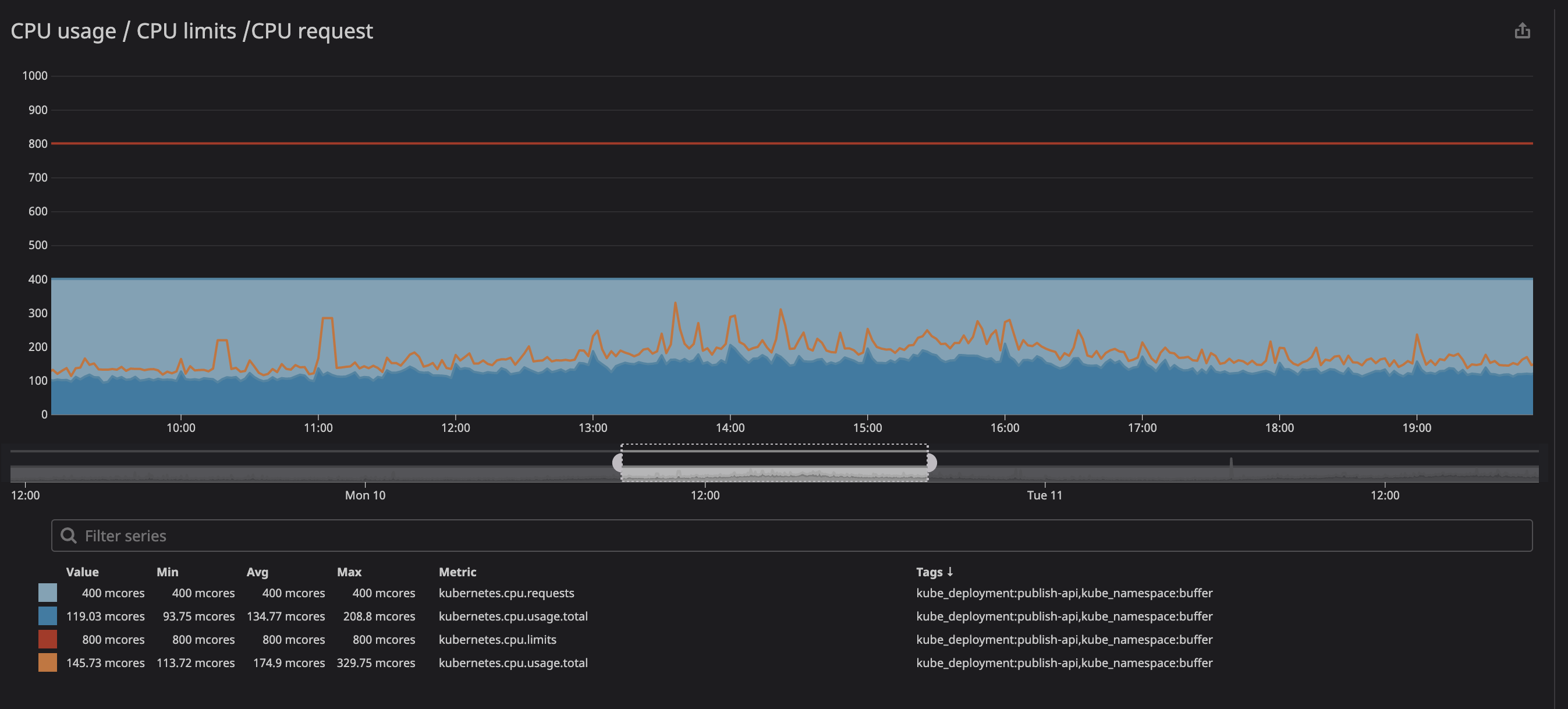
wir uns zum Beispiel eine unserer Haupt-APIs an: Wie Sie unten sehen können, setzen wir den Grenzwert auf
800m(0,8 oder 80% des Kerns) und die Spitzenwerte sind bestenfalls 200m(20% des Kerns). Es scheint, dass wir noch viel Prozessorleistung haben, bevor wir den Service drosseln ...
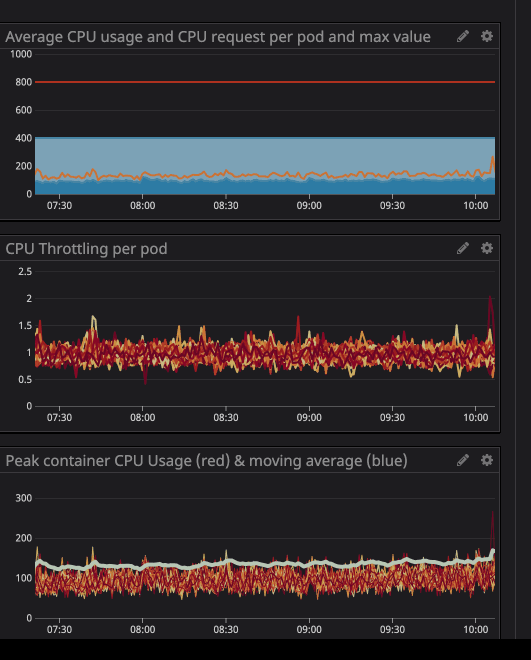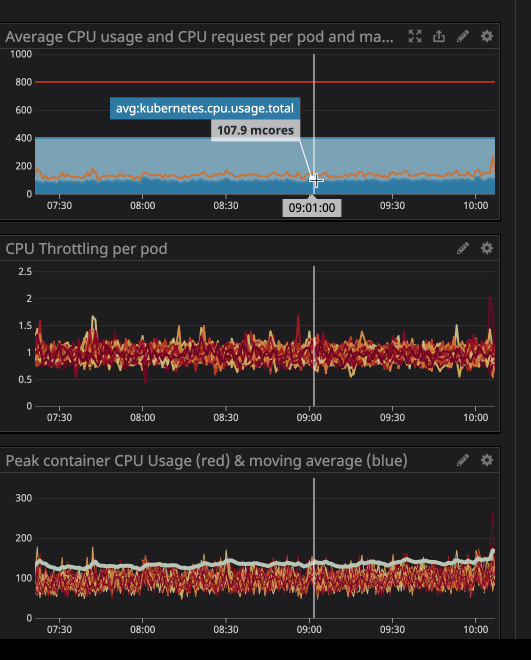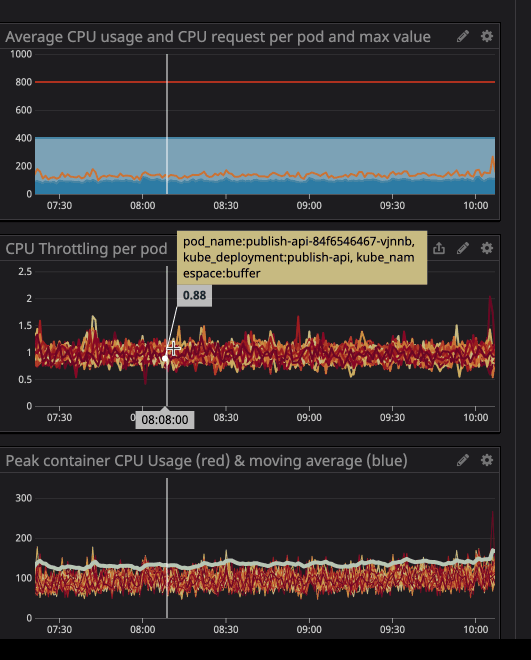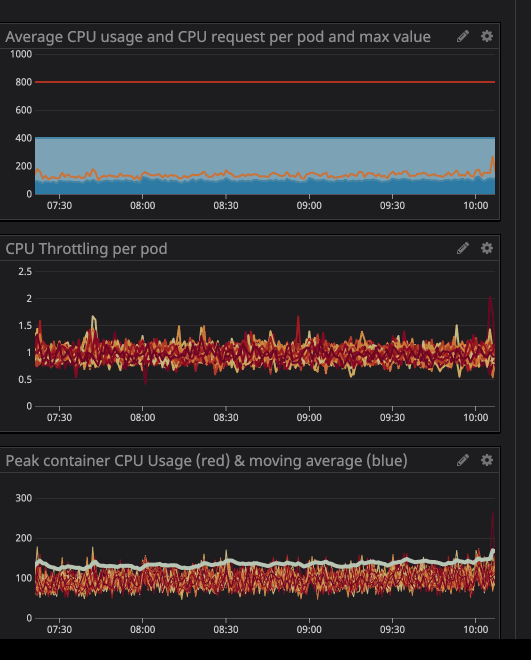
Möglicherweise haben Sie bemerkt, dass die Drosselung auch dann noch funktioniert, wenn die Belastung des Prozessors unter den angegebenen Grenzwerten liegt - viel niedriger.
Angesichts dessen entdeckten wir bald mehrere Ressourcen (ein Problem bei Github , eine Präsentation bei Zadano , ein Beitrag bei Omio ) über den Leistungsabfall und die Reaktionszeit von Diensten aufgrund von Drosselung.
Warum drosseln wir bei geringer CPU-Auslastung? Die Kurzversion lautet wie folgt: "Es gibt einen Fehler im Linux-Kernel, der eine unnötige Drosselung von Containern mit festgelegten Prozessorlimits auslöst." Wenn Sie an der Art des Problems interessiert sind, können Sie die Präsentation ( Video und Text) lesen Varianten) von Dave Chiluk.
Prozessorlimits entfernen (mit äußerster Vorsicht)
Nach langen Diskussionen haben wir beschlossen, Prozessoreinschränkungen aus allen Diensten zu entfernen, die sich direkt oder indirekt auf die kritische Funktionalität unserer Benutzer auswirken.
Die Entscheidung erwies sich als schwierig, da wir die Stabilität unseres Clusters sehr schätzen. In der Vergangenheit haben wir bereits mit der Instabilität unseres Clusters experimentiert, und dann haben die Dienste zu viele Ressourcen verbraucht und die Arbeit unseres gesamten Knotens verlangsamt. Jetzt war alles etwas anders: Wir hatten ein klares Verständnis dafür, was wir von unseren Clustern erwarten, sowie eine gute Strategie zur Umsetzung der geplanten Änderungen.

Geschäftskorrespondenz zu einem dringenden Thema.
Wie schützen Sie Ihre Knoten beim Entfernen von Einschränkungen?
Isolieren von "unbegrenzten" Diensten:
In der Vergangenheit haben einige Knoten einen Zustand erreicht
notReady, hauptsächlich aufgrund von Diensten, die zu viele Ressourcen verbraucht haben.
Wir haben beschlossen, solche Dienste in separaten ("markierten") Knoten zu platzieren, damit sie die "verknüpften" Dienste nicht beeinträchtigen. Infolgedessen haben wir durch Markieren einiger Knoten und Hinzufügen eines Toleranzparameters zu den "nicht verwandten" Diensten mehr Kontrolle über den Cluster erlangt, und es wurde für uns einfacher, Probleme mit den Knoten zu identifizieren. Um ähnliche Prozesse selbst durchzuführen, können Sie sich mit der Dokumentation vertraut machen .
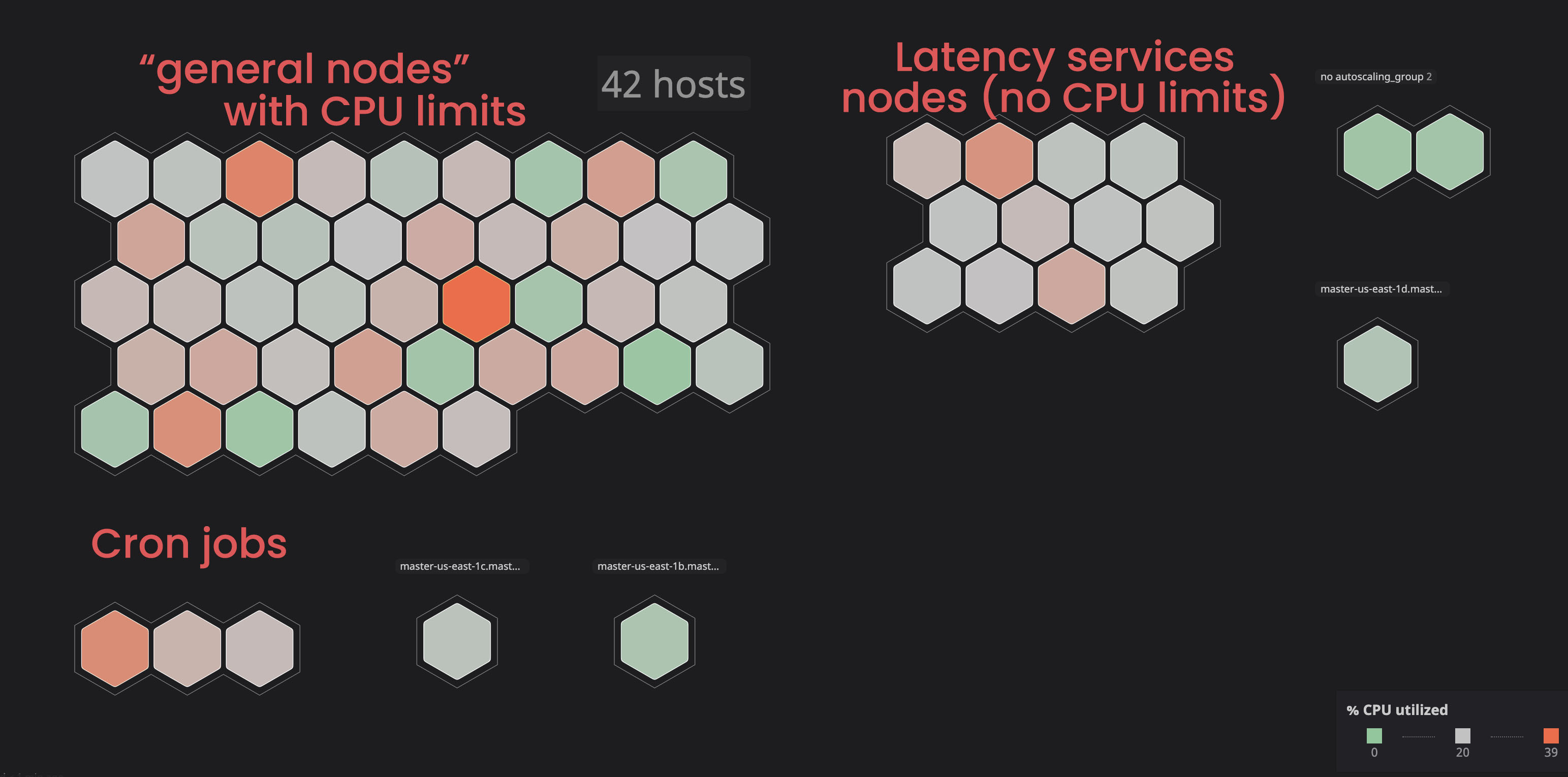
Zuweisen der richtigen Prozessor- und Speicheranforderung:
Vor allem befürchteten wir, dass der Prozess zu viele Ressourcen verbrauchen und der Knoten nicht mehr auf Anfragen reagiert. Da wir jetzt (dank Datadog) alle Dienste in unserem Cluster klar beobachten konnten, analysierte ich mehrere Betriebsmonate derjenigen, die wir als "nicht verwandt" bezeichnen wollten. Ich habe einfach die maximale CPU-Auslastung mit einer Marge von 20% festgelegt und damit Speicherplatz im Knoten zugewiesen, falls k8s versucht, dem Knoten andere Dienste zuzuweisen.
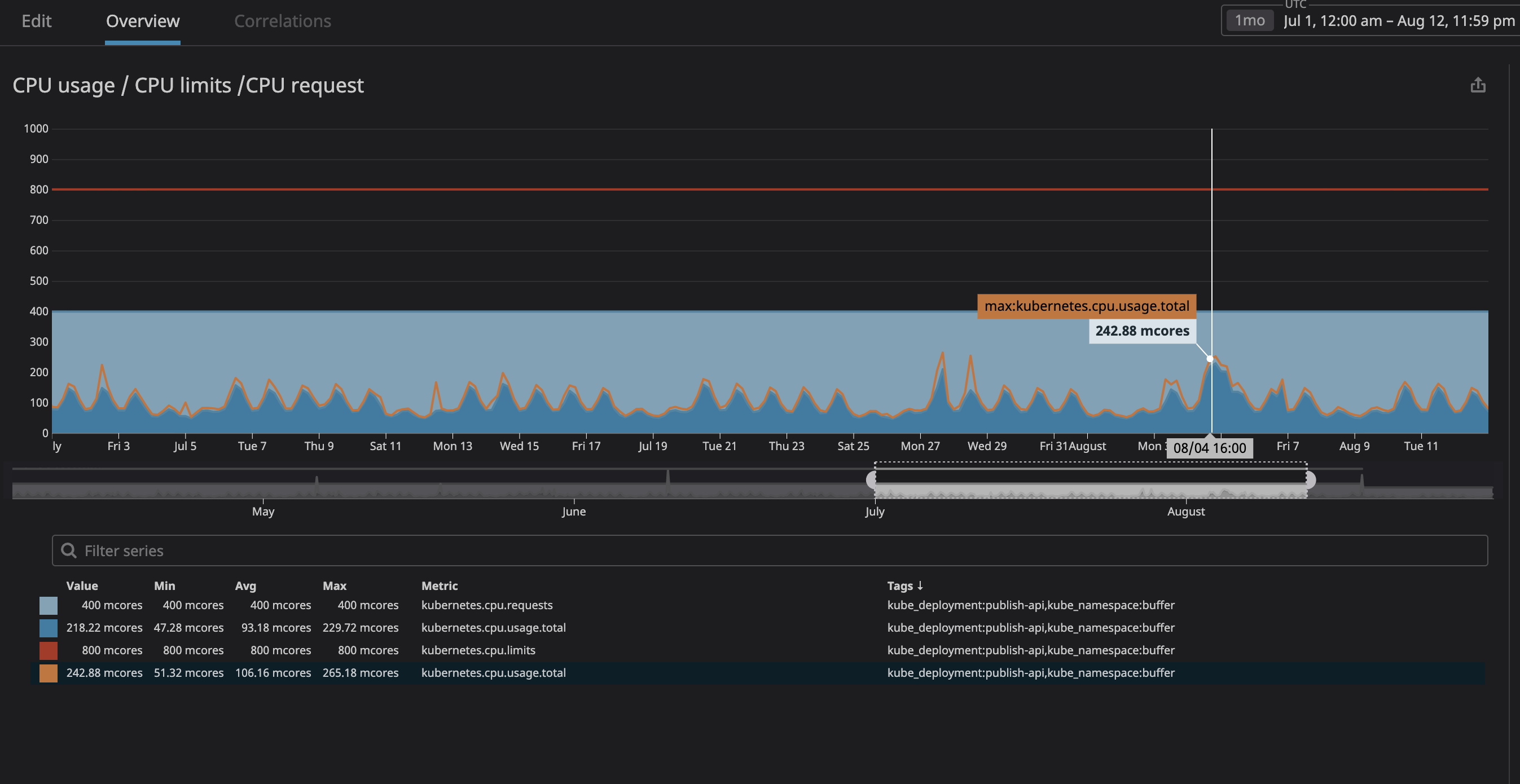
Wie Sie in der Grafik sehen können, hat die maximale Prozessorlast
242mCPU-Kerne erreicht (0,242 Prozessorkerne). Für eine Prozessoranforderung reicht es aus, eine Zahl anzunehmen, die etwas größer als dieser Wert ist. Da die Dienste benutzerzentriert sind, fallen die Lastspitzen mit dem Datenverkehr zusammen.
Machen Sie dasselbe mit der Speichernutzung und den Abfragen und voila - Sie sind fertig! Für mehr Sicherheit können Sie die horizontale automatische Skalierung von Pods hinzufügen. Jedes Mal, wenn die Ressourcen hoch belastet werden, werden durch die automatische Skalierung neue Pods erstellt und von Kubernetes an Knoten mit freiem Speicherplatz verteilt. Falls im Cluster selbst kein Speicherplatz mehr vorhanden ist, können Sie selbst eine Warnung festlegen oder das Hinzufügen neuer Knoten durch deren automatische Skalierung konfigurieren.
Von den Minuspunkten ist anzumerken, dass wir in der " Dichte der Behälter " verloren haben, d.h. Die Anzahl der Container, die in einem Knoten arbeiten. Wir haben möglicherweise auch viele "Ablässe" bei geringer Verkehrsdichte, und es besteht auch die Möglichkeit, dass Sie eine hohe Prozessorlast erreichen, aber die automatische Skalierung der Knoten sollte bei letzterer helfen.
Ergebnisse
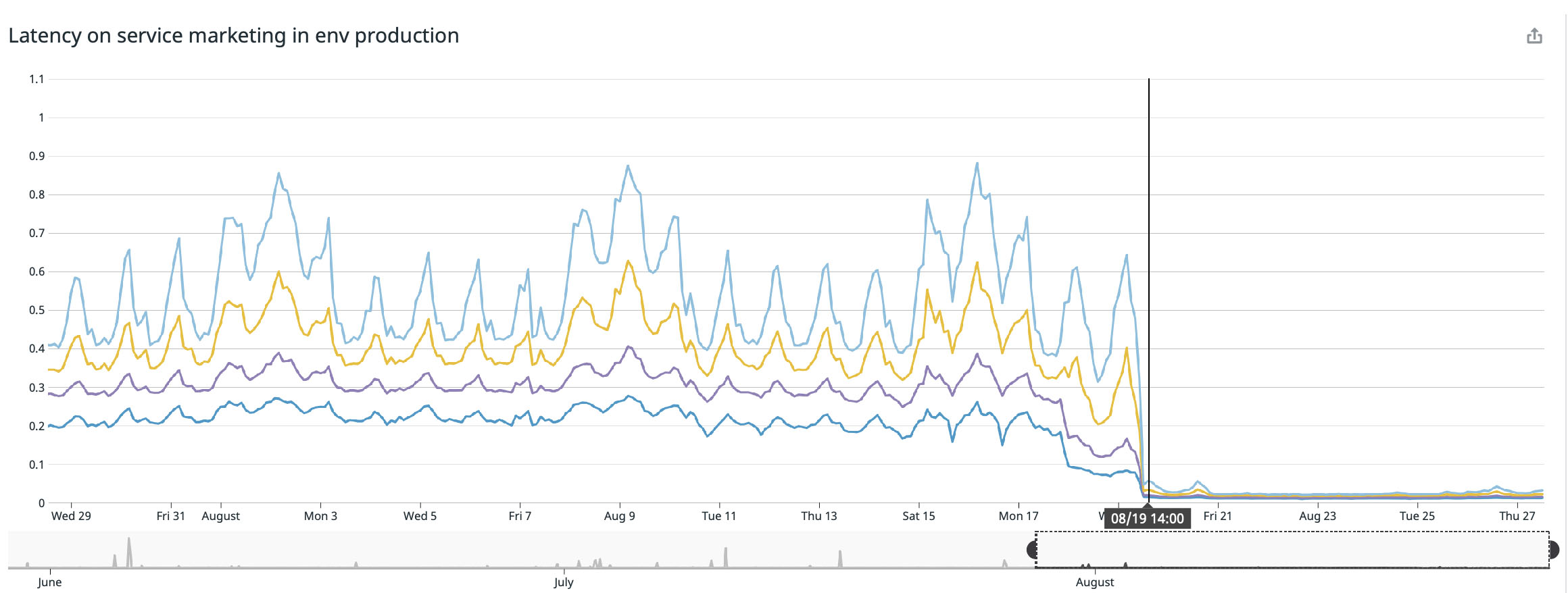
Ich freue mich sehr, diese hervorragenden Ergebnisse von Experimenten in den letzten Wochen veröffentlichen zu können. Wir haben bereits eine signifikante Verbesserung der Reaktion bei allen geänderten Diensten festgestellt:
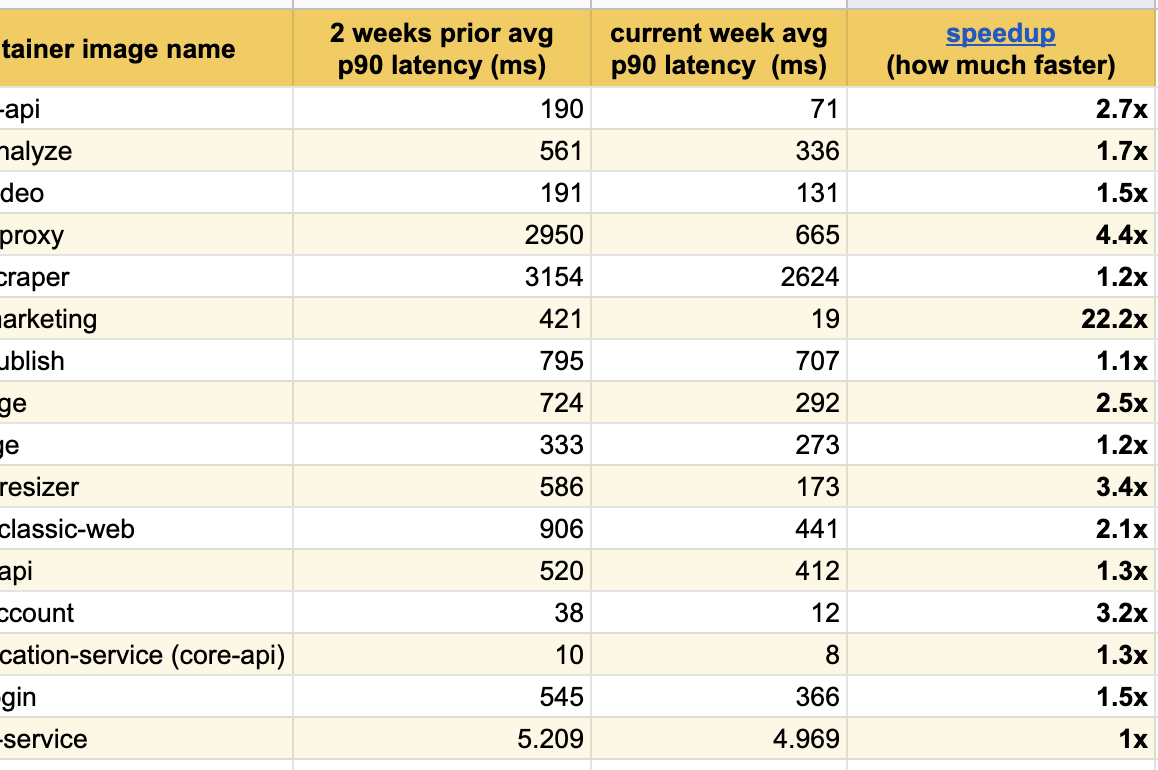
Wir haben das beste Ergebnis auf unserer Hauptseite ( buffer.com ) erzielt , auf der der Dienst zweiundzwanzig Mal beschleunigt wurde!
Ist der Linux-Kernel-Fehler behoben?
Ja, der Fehler wurde bereits behoben, und der Fix wurde dem Kernel von Distributionen ab Version 4.19 hinzugefügt .
Beim Lesen der Kubernetes-Ausgabe auf Github für den 2. September 2020 stoßen wir jedoch immer noch auf Verweise auf einige Linux-Projekte mit einem ähnlichen Fehler. Ich glaube, dass einige Linux-Distributionen diesen Fehler immer noch haben und derzeit an einem Fix arbeiten.
Wenn Ihre Version der Distribution niedriger als 4.19 ist, würde ich empfehlen, auf die neueste Version zu aktualisieren. Sie sollten jedoch trotzdem versuchen, die Prozessorlimits zu entfernen und festzustellen, ob die Drosselung weiterhin besteht. Unten finden Sie eine unvollständige Liste der Verwaltung von Kubernetes-Diensten und Linux-Distributionen:
- Debian: , buster, ( 2020 ). .
- Ubuntu: Ubuntu Focal Fossa 20.04
- EKS 2019 . , AMI.
- kops: 2020
kops 1.18+Ubuntu 20.04. kops , , , . . - GKE (Google Cloud): 2020 , .
Was ist, wenn das Problem mit der Drosselung behoben wurde?
Ich bin nicht sicher, ob das Problem vollständig behoben wurde. Wenn wir zur festen Version des Kernels kommen, werde ich den Cluster testen und den Beitrag aktualisieren. Wenn jemand bereits aktualisiert hat, möchte ich Ihre Ergebnisse mit Interesse überprüfen.
Fazit
- Wenn Sie mit Docker-Containern unter Linux arbeiten (egal ob Kubernetes, Mesos, Swarm oder was auch immer), können Ihre Container aufgrund von Drosselung an Leistung verlieren.
- Versuchen Sie, auf die neueste Version Ihrer Distribution zu aktualisieren, in der Hoffnung, dass der Fehler bereits behoben wurde.
- Das Entfernen von Prozessorlimits löst das Problem. Dies ist jedoch eine gefährliche Technik, die mit äußerster Vorsicht angewendet werden sollte (es ist besser, zuerst den Kernel zu aktualisieren und die Ergebnisse zu vergleichen).
- Wenn Sie die Prozessorbeschränkungen aufgehoben haben, überwachen Sie sorgfältig die Prozessor- und Speichernutzung und stellen Sie sicher, dass Ihre Prozessorressourcen den Verbrauch überschreiten.
- Eine sichere Option wäre die automatische Skalierung von Pods, um bei hoher Hardwarelast neue Pods zu erstellen, damit Kubernetes sie freien Knoten zuweisen können.
Ich hoffe, dieser Beitrag hilft Ihnen, die Leistung Ihrer Containersysteme zu verbessern.
PS Hier steht der Autor in Korrespondenz mit Lesern und Kommentatoren (auf Englisch).