1.1 Was ist ein Entscheidungsbaum?
1.1.1 Beispiel für einen Entscheidungsbaum
Zum Beispiel haben wir den folgenden Datensatz (Datumssatz): Wetter, Temperatur, Luftfeuchtigkeit, Wind, Golf. Je nach Wetter und allem anderen haben wir (〇) oder nicht (×) Golf gespielt. Nehmen wir an, wir haben 14 vorgefasste Optionen.

Aus diesen Daten können wir eine Datenstruktur erstellen, aus der hervorgeht, in welchen Fällen wir Golf gespielt haben. Diese Struktur wird aufgrund ihrer verzweigten Form als Entscheidungsbaum bezeichnet.
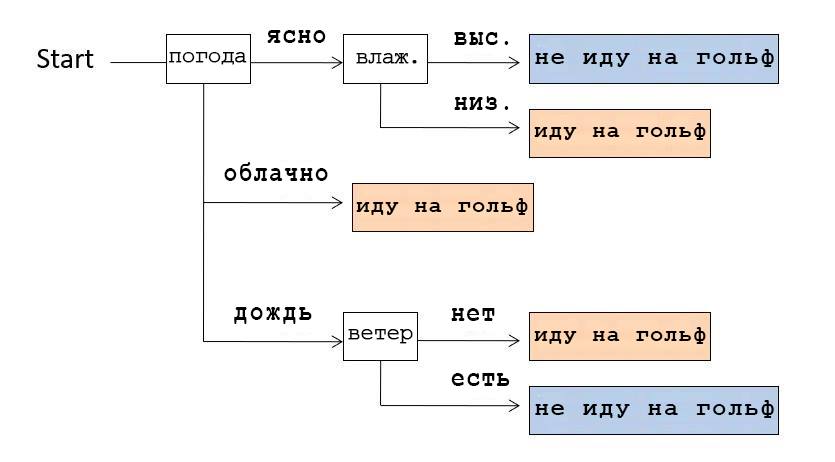
Wenn wir uns beispielsweise den im obigen Bild gezeigten Entscheidungsbaum ansehen, stellen wir fest, dass wir zuerst das Wetter überprüft haben. Wenn es klar war, haben wir die Luftfeuchtigkeit überprüft: Wenn es hoch ist, haben wir nicht Golf gespielt, wenn es niedrig ist, sind wir gegangen. Und wenn das Wetter bewölkt war, gingen sie ungeachtet anderer Bedingungen Golf spielen.
1.1.2 Über diesen Artikel
Es gibt Algorithmen, die solche Entscheidungsbäume automatisch basierend auf den verfügbaren Daten erstellen. In diesem Artikel verwenden wir den ID3-Algorithmus in Python.
Dieser Artikel ist der erste in einer Reihe. Die folgenden Artikel:
(Anmerkung des Übersetzers: "Wenn Sie an der Fortsetzung interessiert sind, teilen Sie uns dies bitte in den Kommentaren mit.")
- Grundlagen der Python-Programmierung
- Grundlegende Grundlagen der Bibliothek für die Pandas-Datenanalyse
- Grundlagen der Datenstruktur (im Fall des Entscheidungsbaums)
- Grundlagen der Informationsentropie
- Lernen eines Algorithmus zum Generieren eines Entscheidungsbaums
1.1.3 Ein wenig über den Entscheidungsbaum
Die Generierung des Entscheidungsbaums bezieht sich auf überwachtes maschinelles Lernen und Klassifizierung. Die Klassifizierung im maschinellen Lernen ist eine Möglichkeit, ein Modell zu erstellen, das zur richtigen Antwort führt, basierend auf dem Training am festgelegten Datum mit den richtigen Antworten und Daten, die zu ihnen führen. Deep Learning, das in den letzten Jahren insbesondere im Bereich der Bilderkennung sehr beliebt war, ist auch Teil des maschinellen Lernens auf der Grundlage der Klassifizierungsmethode. Der Unterschied zwischen Deep Learning und Decision Tree besteht darin, ob das Endergebnis auf eine Form reduziert wird, in der eine Person die Prinzipien der Erzeugung der endgültigen Datenstruktur versteht. Die Besonderheit von Deep Learning ist, dass wir das Endergebnis erhalten, aber das Prinzip seiner Erzeugung nicht verstehen. Im Gegensatz zu Deep Learning ist der Entscheidungsbaum für Menschen leicht verständlich, was ebenfalls ein wichtiges Merkmal ist.
Diese Funktion von Decision Tree eignet sich nicht nur für maschinelles Lernen, sondern auch für Date Mining, bei dem das Verständnis der Daten durch den Benutzer ebenfalls wichtig ist.
1.2 Informationen zum ID3-Algorithmus
ID3 ist ein Entscheidungsbaum-Generierungsalgorithmus, der 1986 von Ross Quinlan entwickelt wurde. Es hat zwei wichtige Merkmale:
- Kategoriale Daten. Dies sind Daten ähnlich unserem obigen Beispiel (Golf spielen oder nicht), Daten mit einer bestimmten kategorialen Bezeichnung. ID3 kann keine numerischen Daten verwenden.
- Die Informationsentropie ist ein Indikator, der eine Datenfolge mit der geringsten Varianz der Eigenschaften einer Werteklasse angibt.
1.2.1 Informationen zur Verwendung numerischer Daten
Der C4.5-Algorithmus, eine fortgeschrittenere Version von ID3, kann numerische Daten verwenden. Da die Grundidee in dieser Serie jedoch dieselbe ist, werden wir zuerst ID3 verwenden.
1.3 Entwicklungsumgebung
Das unten beschriebene Programm habe ich unter folgenden Bedingungen getestet und ausgeführt:
- Jupyter-Notizbücher (mit Azure-Notizbüchern)
- Python 3.6
- Bibliotheken: Mathematik, Pandas, Funktionswerkzeuge (ohne Scikit-Learn, Tensorflow usw.)
1.4 Beispielprogramm
1.4.1 Eigentlich das Programm
Kopieren wir zunächst das Programm in Jupyter Notebook und führen es aus.
import math
import pandas as pd
from functools import reduce
#
d = {
"":["","","","","","","","","","","","","",""],
"":["","","","","","","","","","","","","",""],
"":["","","","","","","","","","","","","",""],
"":["","","","","","","","","","","","","",""],
# - , ,
# .
"":["×","×","○","○","○","×","○","×","○","○","○","○","○","×"],
}
df0 = pd.DataFrame(d)
# - , - pandas.Series,
# -
# s value_counts() ,
# , , items().
# , sorted,
#
# , , : (k) (v).
cstr = lambda s:[k+":"+str(v) for k,v in sorted(s.value_counts().items())]
# Decision Tree
tree = {
# name: ()
"name":"decision tree "+df0.columns[-1]+" "+str(cstr(df0.iloc[:,-1])),
# df: , ()
"df":df0,
# edges: (), ,
# , .
"edges":[],
}
# , , open
open = [tree]
# - .
# - pandas.Series、 -
entropy = lambda s:-reduce(lambda x,y:x+y,map(lambda x:(x/len(s))*math.log2(x/len(s)),s.value_counts()))
# , open
while(len(open)!=0):
# open ,
# ,
n = open.pop(0)
df_n = n["df"]
# , 0,
#
if 0==entropy(df_n.iloc[:,-1]):
continue
# ,
attrs = {}
# ,
for attr in df_n.columns[:-1]:
# , ,
# , .
attrs[attr] = {"entropy":0,"dfs":[],"values":[]}
# .
# , sorted ,
# , .
for value in sorted(set(df_n[attr])):
#
df_m = df_n.query(attr+"=='"+value+"'")
# ,
attrs[attr]["entropy"] += entropy(df_m.iloc[:,-1])*df_m.shape[0]/df_n.shape[0]
attrs[attr]["dfs"] += [df_m]
attrs[attr]["values"] += [value]
pass
pass
# , ,
# .
if len(attrs)==0:
continue
#
attr = min(attrs,key=lambda x:attrs[x]["entropy"])
#
# , , open.
for d,v in zip(attrs[attr]["dfs"],attrs[attr]["values"]):
m = {"name":attr+"="+v,"edges":[],"df":d.drop(columns=attr)}
n["edges"].append(m)
open.append(m)
pass
#
print(df0,"\n-------------")
# , - tree: ,
# indent: indent,
# - .
# .
def tstr(tree,indent=""):
# .
# ( 0),
# df, , .
s = indent+tree["name"]+str(cstr(tree["df"].iloc[:,-1]) if len(tree["edges"])==0 else "")+"\n"
# .
for e in tree["edges"]:
# .
# indent .
s += tstr(e,indent+" ")
pass
return s
# .
print(tstr(tree))1.4.2 Ergebnis
Wenn Sie das obige Programm ausführen, wird unser Entscheidungsbaum wie unten gezeigt als Symboltabelle dargestellt.
decision tree ['×:5', '○:9']
=
=['○:2']
=['×:3']
=['○:4']
=
=['×:2']
=['○:3']
1.4.3 Ändern Sie die Attribute (Datenfelder), die wir untersuchen möchten
Das letzte Array in der Datumsmenge d ist ein Klassenattribut (das Datenarray, das wir klassifizieren möchten).
d = {
"":["","","","","","","","","","","","","",""],
"":["","","","","","","","","","","","","",""],
"":["","","","","","","","","","","","","",""],
"":["×","×","○","○","○","×","○","×","○","○","○","○","○","×"],}
# - , , .
"":["","","","","","","","","","","","","",""],
}Wenn Sie beispielsweise die Arrays "Golf" und "Wind" austauschen, wie im obigen Beispiel gezeigt, erhalten Sie das folgende Ergebnis:
decision tree [':6', ':8']
=×
=
=
=[':1', ':1']
=[':1']
=[':2']
=○
=
=[':1']
=[':1']
=
=[':2']
=[':1']
=[':1']
=[':3']Im Wesentlichen erstellen wir eine Regel, nach der wir dem Programm sagen, dass es sich zuerst durch das Vorhandensein und Nichtvorhandensein von Wind verzweigen soll und ob wir Golf spielen wollen oder nicht.
Danke fürs Lesen!
Wir würden uns sehr freuen, wenn Sie uns mitteilen, ob Ihnen dieser Artikel gefallen hat. War die Übersetzung klar, war sie für Sie nützlich?