Es ist praktisch, Text in natürlicher Sprache mit Python zu verarbeiten, da es sich um ein Programmierwerkzeug auf ziemlich hohem Niveau handelt, über eine gut entwickelte Infrastruktur verfügt und sich auf dem Gebiet der Datenanalyse und des maschinellen Lernens bewährt hat. Die Community hat mehrere Bibliotheken und Frameworks entwickelt, um NLP-Probleme in Python zu lösen. In unserer Arbeit werden wir ein interaktives Web-Tool zum Entwickeln von Python-Skripten verwenden, Jupyter Notebook, die NLTK-Bibliothek für die Textanalyse und die Wordcloud-Bibliothek zum Erstellen einer Wortwolke.
Das Netzwerk enthält eine ziemlich große Menge an Material zum Thema Textanalyse, aber in vielen Artikeln (einschließlich russischsprachiger Artikel) wird vorgeschlagen, den Text auf Englisch zu analysieren. Die Analyse des russischen Textes enthält einige Besonderheiten der Verwendung des NLP-Toolkits. Betrachten Sie als Beispiel die Frequenzanalyse des Textes der Geschichte "Schneesturm" von A. Puschkin.
Die Frequenzanalyse kann grob in mehrere Stufen unterteilt werden:
- Laden und Durchsuchen von Daten
- Textbereinigung und Vorverarbeitung
- Stoppwörter entfernen
- Wörter in die Grundform übersetzen
- Berechnung der Statistik des Auftretens von Wörtern im Text
- Cloud-Visualisierung der Wortpopularität
Das Skript ist verfügbar unter github.com/Metafiz/nlp-course-20/blob/master/frequency-analisys-of-text.ipynb , Quelle - github.com/Metafiz/nlp-course-20/blob/master/pushkin -metel.txt
Daten werden geladen
Wir öffnen die Datei mit der integrierten Funktion zum Öffnen, geben den Lesemodus und die Codierung an. Wir lesen den gesamten Inhalt der Datei, als Ergebnis erhalten wir den Zeichenfolgentext:
f = open('pushkin-metel.txt', "r", encoding="utf-8")
text = f.read()
Die Länge des Textes - die Anzahl der Zeichen - kann mit der Standardfunktion len ermittelt werden:
len(text)
Eine Zeichenfolge in Python kann als Liste von Zeichen dargestellt werden, sodass für die Arbeit mit Zeichenfolgen auch Indexzugriffs- und Slicing-Vorgänge möglich sind. Um beispielsweise die ersten 300 Textzeichen anzuzeigen, führen Sie einfach den folgenden Befehl aus:
text[:300]
Vorverarbeitung (Vorverarbeitung) von Text
Um eine Frequenzanalyse durchzuführen und das Thema des Textes zu bestimmen, wird empfohlen, den Text von Satzzeichen, zusätzlichen Leerzeichen und Zahlen zu befreien. Sie können dies auf verschiedene Arten tun - mithilfe integrierter Zeichenfolgenfunktionen, regulärer Ausdrücke, Listenverarbeitung oder auf andere Weise.
Lassen Sie uns zunächst Zeichen in einen Einzelfall konvertieren, z. B. niedriger:
text = text.lower()
Wir verwenden den Standard-Interpunktionszeichensatz aus dem String-Modul:
import string
print(string.punctuation)
string.punctuation ist eine Zeichenfolge. Der Satz von Sonderzeichen, die aus dem Text entfernt werden sollen, kann erweitert werden. Es ist notwendig, den Quelltext zu analysieren und die Zeichen zu identifizieren, die entfernt werden sollen. Fügen wir Satzzeichen, Tabulatoren und andere Zeichen, die in unserem Quelltext enthalten sind, zu Satzzeichen hinzu (z. B. das Zeichen mit dem Code \ xa0):
spec_chars = string.punctuation + '\n\xa0«»\t—…'
Um Zeichen zu entfernen, verwenden wir die elementweise Verarbeitung der Zeichenfolge. Teilen Sie die ursprüngliche Textzeichenfolge in Zeichen, lassen Sie nur Zeichen übrig, die nicht im Satz spec_chars enthalten sind, und kombinieren Sie die Liste der Zeichen erneut zu einer Zeichenfolge:
text = "".join([ch for ch in text if ch not in spec_chars])
Sie können eine einfache Funktion deklarieren, die den angegebenen Zeichensatz aus dem Quelltext entfernt:
def remove_chars_from_text(text, chars):
return "".join([ch for ch in text if ch not in chars])
Es kann sowohl zum Entfernen von Sonderzeichen als auch zum Entfernen von Zahlen aus dem Originaltext verwendet werden:
text = remove_chars_from_text(text, spec_chars)
text = remove_chars_from_text(text, string.digits)
Tokenisieren von Text
Zur weiteren Verarbeitung muss der gelöschte Text in seine Bestandteile - Token - aufgeteilt werden. Bei der Textanalyse in natürlicher Sprache werden Symbol-, Wort- und Satzaufschlüsselungen verwendet. Der Partitionierungsprozess wird als Tokenisierung bezeichnet. Für unsere Aufgabe der Frequenzanalyse ist es notwendig, den Text in Wörter zu zerlegen. Dazu können Sie die vorgefertigte Methode der NLTK-Bibliothek verwenden:
from nltk import word_tokenize
text_tokens = word_tokenize(text)
Die Variable text_tokens ist eine Liste von Wörtern (Token). Um die Anzahl der Wörter im vorverarbeiteten Text zu berechnen, können Sie die Länge der Token-Liste ermitteln:
len(text_tokens)
Verwenden Sie die Slice-Operation, um die ersten 10 Wörter anzuzeigen:
text_tokens[:10]
Um die Frequenzanalysetools der NLTK-Bibliothek verwenden zu können, müssen Sie die Liste der Token in die Textklasse konvertieren, die in dieser Bibliothek enthalten ist:
import nltk
text = nltk.Text(text_tokens)
Lassen Sie uns den Typ des variablen Textes ableiten:
print(type(text))
Slice-Operationen sind auch auf eine Variable dieses Typs anwendbar. Diese Aktion gibt beispielsweise die ersten 10 Token aus dem Text aus:
text[:10]
Berechnung der Statistik des Auftretens von Wörtern im Text
Die FreqDist-Klasse (Häufigkeitsverteilungen) wird verwendet, um die Statistik der Worthäufigkeitsverteilung im Text zu berechnen:
from nltk.probability import FreqDist
fdist = FreqDist(text)
Wenn Sie versuchen, die Variable fdist anzuzeigen, wird ein Wörterbuch mit Token und deren Häufigkeit angezeigt. So oft erscheinen diese Wörter im Text:
FreqDist({'': 146, '': 101, '': 69, '': 54, '': 44, '': 42, '': 39, '': 39, '': 31, '': 27, ...})
Sie können auch die Methode most_common verwenden, um eine Liste der Tupel mit den häufigsten Token abzurufen:
fdist.most_common(5)
[('', 146), ('', 101), ('', 69), ('', 54), ('', 44)]
Die Häufigkeit der Verteilung von Wörtern in einem Text kann mithilfe eines Diagramms visualisiert werden. Die FreqDist-Klasse enthält eine integrierte Plotmethode zum Plotten eines solchen Plots. Es ist erforderlich, die Anzahl der Token anzugeben, deren Häufigkeit in der Tabelle angezeigt wird. Mit dem Parameter kumulativ = Falsch veranschaulicht der Graph das Zipf-Gesetz : Wenn alle Wörter eines ausreichend langen Textes in absteigender Reihenfolge der Häufigkeit ihrer Verwendung sortiert sind, ist die Häufigkeit des n-ten Wortes in einer solchen Liste ungefähr umgekehrt proportional zu seiner Ordnungszahl n.
fdist.plot(30,cumulative=False)
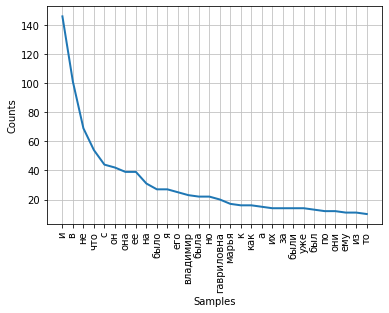
Es kann angemerkt werden, dass im Moment die höchsten Frequenzen Konjunktionen, Präpositionen und andere Dienstteile der Sprache haben, die keine semantische Last tragen, sondern nur semantisch-syntaktische Beziehungen zwischen Wörtern ausdrücken. Damit die Ergebnisse der Frequenzanalyse das Thema des Textes widerspiegeln, müssen diese Wörter aus dem Text entfernt werden.
Stoppwörter entfernen
Stoppwörter (oder Rauschwörter) umfassen in der Regel Präpositionen, Konjunktionen, Interjektionen, Partikel und andere Teile der Sprache, die häufig im Text enthalten sind, Dienstwörter sind und keine semantische Last tragen - sie sind redundant.
Die NLTK-Bibliothek enthält vorgefertigte Stoppwortlisten für verschiedene Sprachen. Lassen Sie uns eine Liste von hundert Wörtern für die russische Sprache erhalten:
from nltk.corpus import stopwords
russian_stopwords = stopwords.words("russian")
Es ist zu beachten, dass Stoppwörter kontextsensitiv sind - bei Texten verschiedener Themen können Stoppwörter unterschiedlich sein. Wie bei Sonderzeichen ist es erforderlich, den Quelltext zu analysieren und Stoppwörter zu identifizieren, die nicht im Standardsatz enthalten sind.
Die Stoppwortliste kann mit der Standard-Erweiterungsmethode erweitert werden:
russian_stopwords.extend(['', ''])
Nach dem Entfernen der Stoppwörter ist die Verteilungshäufigkeit der Token im Text wie folgt:
fdist_sw.most_common(10)
[('', 23),
('', 20),
('', 17),
('', 9),
('', 9),
('', 8),
('', 7),
('', 6),
('', 6),
('', 6)]
Wie Sie sehen können, sind die Ergebnisse der Frequenzanalyse informativer geworden und spiegeln das Hauptthema des Textes genauer wider. Wir sehen jedoch in den Ergebnissen solche Token wie "vladimir" und "vladimira", die zwar ein Wort sind, aber unterschiedliche Formen haben. Um diese Situation zu korrigieren, ist es notwendig, die Wörter des Quelltextes auf ihre Basis oder ihre ursprüngliche Form zu bringen - um Stemming oder Lemmatisierung durchzuführen.
Cloud-Visualisierung der Wortpopularität
Am Ende unserer Arbeit visualisieren wir die Ergebnisse der Frequenzanalyse des Textes in Form einer "Wortwolke".
Dafür benötigen wir die Bibliotheken wordcloud und matplotlib:
from wordcloud import WordCloud
import matplotlib.pyplot as plt
%matplotlib inline
Um eine Wortwolke zu erstellen, muss eine Zeichenfolge als Eingabe an die Methode übergeben werden. Um die Liste der Token nach der Vorverarbeitung und dem Entfernen von Stoppwörtern zu konvertieren, verwenden wir die Join-Methode und geben ein Leerzeichen als Trennzeichen an:
text_raw = " ".join(text)
Nennen wir die Methode zum Erstellen der Cloud:
wordcloud = WordCloud().generate(text_raw)
Als Ergebnis erhalten wir eine solche "Wortwolke" für unseren Text:

Wenn Sie ihn betrachten, können Sie sich einen allgemeinen Überblick über das Thema und die Hauptfiguren der Arbeit verschaffen.