Mal sehen, welche Lösungen dieses Problem hat.
Verteilung von Objekten "nach Kapazität"
Um in uninteressant Abstraktionen nicht zu vertiefen, werden wir es am Beispiel einer bestimmten Aufgabe betrachten - Überwachung . Ich bin sicher, dass Sie die vorgeschlagenen Methoden selbst auf Ihre spezifischen Aufgaben beziehen können.
"Äquivalente" Überwachungsobjekte
Ein Beispiel sind unsere Metrikkollektoren für Zabbix , die historisch gesehen eine gemeinsame Architektur mit PostgreSQL-Protokollkollektoren haben. In der Tat
, jedes Überwachungsobjekt (Host) erzeugt für zabbix fast stabil den gleichen Satz von Metriken mit der gleichen Frequenz die ganze Zeit:
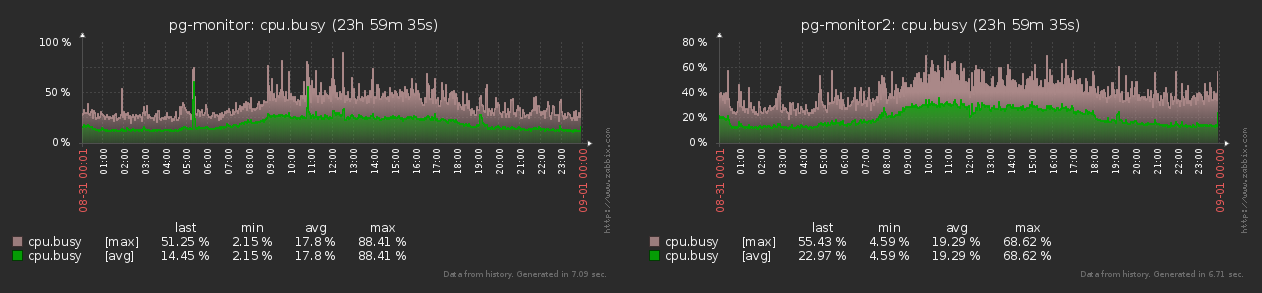
Wie Sie in der Grafik sehen können, überschreitet die Differenz zwischen den Min-Max-Werten der Anzahl der generierten Metriken 15% nicht . Daher können wir alle Objekte als gleich in denselben "Papageien" betrachten .
Starkes "Ungleichgewicht" zwischen Objekten
Im Gegensatz zum Vorgängermodell sind die überwachten Hosts für die Protokollkollektoren alles andere als homogen .
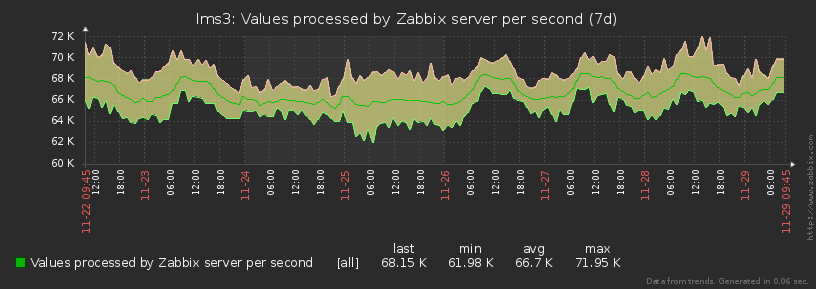
Beispielsweise kann ein Host eine Million Pläne pro Tag im Protokoll generieren, weitere Zehntausende und einige - sogar nur wenige. Und die Pläne selbst unterscheiden sich stark in Bezug auf Volumen und Komplexität sowie in Bezug auf die Verteilung über die Tageszeit. Es stellt sich also heraus, dass die Last manchmal stark "wackelt" :

Nun, da sich die Last so stark ändern kann, müssen Sie lernen, wie man damit umgeht ...
Koordinator
Wir verstehen sofort, dass wir offensichtlich das Kollektorsystem skalieren müssen , da ein separater Knoten mit der gesamten Last eines Tages nicht mehr fertig wird. Und dafür brauchen wir einen Koordinator - jemanden, der den gesamten Zoo verwaltet.
Es stellt sich ungefähr so heraus:

Jeder Arbeiter seine Last "in Papageien" und als Prozentsatz der CPU setzt regelmäßig den Master zurück, diese - auf den Sammler. Auf der Grundlage dieser Daten kann er einen Befehl wie "Einen neuen Host auf einen entladenen Worker Nr. 4 setzen" oder "HostA muss an Worker Nr. 3 übertragen werden" ausgeben .
Hier müssen Sie auch bedenken, dass die Kollektoren selbst im Gegensatz zu Überwachungsobjekten überhaupt nicht die gleiche "Leistung" haben - zum Beispiel haben Sie auf einem 8 CPU-Kerne und auf dem anderen nur 4 und sogar eine niedrigere Frequenz. Und wenn Sie sie mit Aufgaben "gleichermaßen" laden, wird die zweite "still" und die erste wird inaktiv sein. Daraus folgt ...
Aufgaben des Koordinators
Tatsächlich gibt es nur eine Aufgabe - die gleichmäßigste Verteilung der gesamten Last (in% CPU) unter allen verfügbaren Arbeitnehmern sicherzustellen . Wenn wir es perfekt lösen können, wird die Gleichmäßigkeit der prozentualen CPU-Lastverteilung über die Kollektoren „automatisch“ erhalten.
Es ist klar, dass selbst wenn jedes Objekt im Laufe der Zeit die gleiche Last erzeugt, einige von ihnen "absterben" können und einige neue erscheinen. Daher muss man in der Lage sein, die gesamte Situation dynamisch zu managen und ständig ein Gleichgewicht zu halten .
Dynamisches Auswuchten
Wir können ein einfaches Problem (zabbix) ganz trivial lösen:
- Wir berechnen die relative Kapazität jedes Sammlers "in Aufgaben".
- Teilen Sie alle Aufgaben proportional auf
- Wir verteilen uns gleichmäßig auf die Arbeiter

Aber was tun bei "stark ungleichen" Objekten, wie bei einem Protokollsammler?
Bewertung der Einheitlichkeit
Oben haben wir immer den Begriff " maximal gleichmäßige Verteilung " verwendet, aber wie können Sie zwei Verteilungen formal vergleichen, von denen eine "gleichmäßiger" ist?
Für die Bewertung der Einheitlichkeit in der Mathematik gibt es seit langem eine Standardabweichung . Wer ist faul zu lesen:
S[X] = sqrt( sum[ ( x - avg[X] ) ^ 2 of X ] / count[X] )Da die Anzahl der Arbeiter an jedem der Kollektoren auch für uns unterschiedlich sein kann, sollte die Lastverteilung nicht nur zwischen ihnen, sondern auch zwischen den Sammlern insgesamt normalisiert werden .
Das heißt, die Verteilung der Last auf die Arbeiter der beiden Sammler
[ (10%, 10%, 10%, 10%, 10%, 10%) ; (20%) ]ist ebenfalls nicht sehr gut, da sich herausstellt, dass der erste 10% und der zweite - 20% , was sozusagen relativ doppelt so hoch ist.
Daher führen wir einen einzelnen metrischen Abstand für eine allgemeine Schätzung der "Gleichmäßigkeit" ein:
d([%wrk], [%col]) = sqrt( S[%wrk] ^ 2 + S[%col] ^ 2 )Modellieren
Wenn wir ein paar Objekte hätten, könnten wir sie zwischen Arbeitern mit Brute-Force "zerlegen", so dass die Metrik minimal wäre . Wir haben jedoch Tausende von Objekten, sodass diese Methode nicht funktioniert. Wir wissen jedoch, dass der Kollektor ein Objekt von einem Arbeiter zu einem anderen "verschieben" kann. Modellieren Sie diese Option mithilfe der Gradientenabstiegsmethode .
Es ist klar, dass wir möglicherweise nicht das „ideale“ Minimum der Metrik finden, aber das lokale ist sicher. Und die Last selbst kann im Laufe der Zeit so stark variieren, dass es absolut nicht notwendig ist, für eine unendliche Zeit nach einem "Ideal" zu suchen .
Das heißt, wir müssen nur bestimmen, welches Objekt und zu welchem Arbeiter es am effizientesten ist, sich zu "bewegen". Und machen wir es zu einer trivial erschöpfenden Modellierung:
- ( host, worker)
- host worker' «»
«» . - « »
- d «»
Wir richten alle Paare in aufsteigender Reihenfolge der Metrik aus . Idealerweise sollten wir immer die Übertragung des ersten Paares implementieren , da dies die minimale Zielmetrik ergibt. Leider "kostet" der Übertragungsprozess selbst in der Realität Ressourcen, sodass Sie ihn nicht öfter für dasselbe Objekt als ein bestimmtes "Abkühlungsintervall" ausführen sollten .
In diesem Fall können wir das zweite, dritte, ... Paar nach Rang nehmen - wenn nur die Zielmetrik relativ zum aktuellen Wert abnehmen würde.
Wenn es keinen Rückgang gibt - hier ist es ein lokales Minimum!
Beispiel im Bild:

Es ist überhaupt nicht notwendig, Iterationen "vollständig" zu starten. Sie können beispielsweise eine gemittelte Lastanalyse über einen Zeitraum von 1 Minute durchführen und nach Abschluss eine einzelne Übertragung durchführen.
Mikrooptimierungen
Es ist klar, dass ein Algorithmus mit Komplexität
T() x W()nicht sehr gut ist. Aber darin sollten Sie nicht vergessen, einige mehr oder weniger offensichtliche Optimierungen anzuwenden, die es manchmal beschleunigen können.
Null "Papageien"
Wenn ein Objekt / eine Aufgabe / ein Host im gemessenen Intervall eine Last von "0 Teilen" erzeugt hat , kann es nicht irgendwohin verschoben werden - es muss nicht einmal berücksichtigt und analysiert werden.
Selbstübertragung
Beim Generieren von Paaren muss die Effizienz der Übertragung eines Objekts an denselben Mitarbeiter , an dem es sich bereits befindet, nicht bewertet werden . Immerhin wird es schon sein
T x (W - 1)- eine Kleinigkeit, aber schön!
Nicht erkennbare Last
Da wir die Übertragung der Last modellieren und das Objekt nur ein Werkzeug ist, macht es keinen Sinn, zu versuchen, die "gleiche"% CPU zu übertragen - die Werte der Metriken bleiben genau gleich, wenn auch für eine andere Verteilung der Objekte.
Das heißt, es reicht aus, ein einzelnes Modell für das Tupel (wrkSrc, wrkDst,% cpu) auszuwerten . Nun, und Sie können beispielsweise "gleich" als% cpu-Werte betrachten, die mit bis zu 1 Dezimalstelle übereinstimmen.
JavaScript-Beispielimplementierung
var col = {
'c1' : {
'wrk' : {
'w1' : {
'hst' : {
'h1' : 5
, 'h2' : 1
, 'h3' : 1
}
, 'cpu' : 80.0
}
, 'w2' : {
'hst' : {
'h4' : 1
, 'h5' : 1
, 'h6' : 1
}
, 'cpu' : 20.0
}
}
}
, 'c2' : {
'wrk' : {
'w1' : {
'hst' : {
'h7' : 1
, 'h8' : 2
}
, 'cpu' : 100.0
}
, 'w2' : {
'hst' : {
'h9' : 1
, 'hA' : 1
, 'hB' : 1
}
, 'cpu' : 50.0
}
}
}
};
// ""
let $iv = (obj, fn) => Object.values(obj).forEach(fn);
let $mv = (obj, fn) => Object.values(obj).map(fn);
// initial reparse
for (const [cid, c] of Object.entries(col)) {
$iv(c.wrk, w => {
w.hst = Object.keys(w.hst).reduce((rv, hid) => {
if (typeof w.hst[hid] == 'object') {
rv[hid] = w.hst[hid];
return rv;
}
// ,
if (w.hst[hid]) {
rv[hid] = {'qty' : w.hst[hid]};
}
return rv;
}, {});
});
c.wrk = Object.keys(c.wrk).reduce((rv, wid) => {
// ID -
rv[cid + ':' + wid] = c.wrk[wid];
return rv;
}, {});
}
//
let S = col => {
let wsum = 0
, wavg = 0
, wqty = 0
, csum = 0
, cavg = 0
, cqty = 0;
$iv(col, c => {
$iv(c.wrk, w => {
wsum += w.cpu;
wqty++;
});
csum += c.cpu;
cqty++;
});
wavg = wsum/wqty;
wsum = 0;
cavg = csum/cqty;
csum = 0;
$iv(col, c => {
$iv(c.wrk, w => {
wsum += (w.cpu - wavg) ** 2;
});
csum += (c.cpu - cavg) ** 2;
});
return [Math.sqrt(wsum/wqty), Math.sqrt(csum/cqty)];
};
// -
let distS = S => Math.sqrt(S[0] ** 2 + S[1] ** 2);
//
let iterReOrder = col => {
let qty = 0
, max = 0;
$iv(col, c => {
c.qty = 0;
c.cpu = 0;
$iv(c.wrk, w => {
w.qty = 0;
$iv(w.hst, h => {
w.qty += h.qty;
});
w.max = w.qty * (100/w.cpu);
c.qty += w.qty;
c.cpu += w.cpu;
});
c.cpu = c.cpu/Object.keys(c.wrk).length;
c.max = c.qty * (100/c.cpu);
qty += c.qty;
max += c.max;
});
$iv(col, c => {
c.nrm = c.max/max;
$iv(c.wrk, w => {
$iv(w.hst, h => {
h.cpu = h.qty/w.qty * w.cpu;
h.nrm = h.cpu * c.nrm;
});
});
});
// ""
console.log(S(col), distS(S(col)));
//
let wrk = {};
let hst = {};
for (const [cid, c] of Object.entries(col)) {
for (const [wid, w] of Object.entries(c.wrk)) {
wrk[wid] = {
wid
, cid
, 'wrk' : w
, 'col' : c
};
for (const [hid, h] of Object.entries(w.hst)) {
hst[hid] = {
hid
, wid
, cid
, 'hst' : h
, 'wrk' : w
, 'col' : c
};
}
}
}
// worker
let move = (col, hid, wid) => {
let w = wrk[wid]
, h = hst[hid];
let wsrc = col[h.cid].wrk[h.wid]
, wdst = col[w.cid].wrk[w.wid];
wsrc.cpu -= h.hst.cpu;
wsrc.qty -= h.hst.qty;
wdst.qty += h.hst.qty;
// "" CPU
if (h.cid != w.cid) {
let csrc = col[h.cid]
, cdst = col[w.cid];
csrc.qty -= h.hst.qty;
csrc.cpu -= h.hst.cpu/Object.keys(csrc.wrk).length;
wsrc.hst[hid].cpu = h.hst.cpu * csrc.nrm/cdst.nrm;
cdst.qty += h.hst.qty;
cdst.cpu += h.hst.cpu/Object.keys(cdst.wrk).length;
}
wdst.cpu += wsrc.hst[hid].cpu;
wdst.hst[hid] = wsrc.hst[hid];
delete wsrc.hst[hid];
};
// (host, worker)
let moveCheck = (orig, hid, wid) => {
let w = wrk[wid]
, h = hst[hid];
// -
if (h.wid == w.wid) {
return;
}
let col = JSON.parse(JSON.stringify(orig));
move(col, hid, wid);
return S(col);
};
// (hsrc,hdst,%cpu)
let checked = {};
// ( -> )
let moveRanker = col => {
let currS = S(col);
let order = [];
for (hid in hst) {
for (wid in wrk) {
// ( 0.1%) ""
let widsrc = hst[hid].wid;
let idx = widsrc + '|' + wid + '|' + hst[hid].hst.cpu.toFixed(1);
if (idx in checked) {
continue;
}
let _S = moveCheck(col, hid, wid);
if (_S === undefined) {
_S = currS;
}
checked[idx] = {
hid
, wid
, S : _S
};
order.push(checked[idx]);
}
}
order.sort((x, y) => distS(x.S) - distS(y.S));
return order;
};
let currS = S(col);
let order = moveRanker(col);
let opt = order[0];
console.log('best move', opt);
//
if (distS(opt.S) < distS(currS)) {
console.log('move!', opt.hid, opt.wid);
move(col, opt.hid, opt.wid);
console.log('after move', JSON.parse(JSON.stringify(col)));
return true;
}
else {
console.log('none!');
}
return false;
};
// -
while(iterReOrder(col));Infolgedessen wird die Last auf unseren Stauseen zu jedem Zeitpunkt nahezu gleich verteilt, wodurch die entstehenden Spitzen sofort ausgeglichen werden: