Teil 1. Anfang
1.1 Einführung und Problemstellung
Bei MTS steuern wir zentral die Qualität der Datenübertragungsnetze oder einfacher des Transportnetzes (nicht zu verwechseln mit dem Logistik-Transportnetz), im Folgenden als TS bezeichnet. Und im Rahmen unserer Tätigkeit müssen wir ständig zwei Hauptaufgaben lösen:
- Es wurde eine Verschlechterung der Client-Dienste (in Bezug auf die TS) festgestellt. Es ist erforderlich, den Pfad ihrer Verbindung durch die TS zu bestimmen und herauszufinden, ob der Grund für die Verschlechterung der Dienste ein Teil der TS ist. Weiter werden wir dies das direkte Problem nennen.
- Eine Verschlechterung der Qualität des Transportkanals oder der Kanalsequenz wird festgestellt. Um die Auswirkungen zu bestimmen, muss ermittelt werden, welche Dienste von diesem Kanal / diesen Kanälen abhängen. Weiter werden wir dies das inverse Problem nennen.
Unter TS-Diensten wird jede Verbindung von Client-Geräten verstanden. Dies können Basisstationen (BS), B2B-Clients (die MTS TS zum Organisieren des Zugriffs auf das Internet und / oder Overlay-VPN-Netzwerke verwenden), Clients mit festem Zugriff (sogenannter Breitbandzugang) usw. sein. usw.
Wir verfügen über zwei zentralisierte Informationssysteme:
| Leistungsüberwachungssystem | Netzwerkparameter- und Topologiedaten |
|---|---|
 |
 |
| Metriken, KPI TS | Konfigurationsparameter, L2 / L3-Kanäle |
Jedes Transportnetz ist von Natur aus ein gerichteter Graph , in dem jede Kante hat eine nicht negative Kapazität. Daher wurde von Anfang an im Rahmen der Graphentheorie nach Lösungen für diese Probleme gesucht.
Zunächst wurde das Problem des Vergleichs der Qualitätsindikatoren des TS und der Dienste mit der TS-Topologie gelöst, indem die Topologie und die Qualitätsdaten buchstäblich in Form eines Netzwerkgraphen kombiniert und dargestellt wurden.
Die Ansicht des gemäß den Topologie- und Leistungsdaten erstellten Diagramms wurde unter Verwendung der Open-Source- Gephi- Software implementiert . Dies ermöglichte es, das Problem der automatischen Darstellung der Topologie zu lösen, ohne manuell an ihrer Aktualisierung arbeiten zu müssen. Es sieht aus wie das:
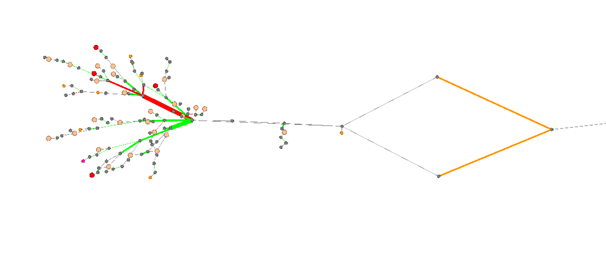
Hier sind die Knoten tatsächlich die Knoten des TS (Router, Switches) und die grundlegenden, die Kanten sind die Kanäle des TS. Die Farbcodierung bezeichnet das Vorhandensein von Qualitätsminderungen und den Behandlungsstatus dieser Verschlechterungen.
Es scheint, dass es ziemlich klar ist und Sie arbeiten können, aber:
- Das direkte Problem (von Dienst zu Dienstpfad) kann nur dann ziemlich genau gelöst werden, wenn die TS-Topologie selbst recht einfach ist - ein Baum oder nur eine serielle Verbindung ohne Ringe und alternative Routen.
- Das inverse Problem kann unter ähnlichen Bedingungen gelöst werden, aber gleichzeitig ist es auf der Ebene der Aggregation und des Netzwerkkerns unmöglich, dieses Problem im Prinzip zu lösen, da Diese Segmente werden von dynamischen Routing-Protokollen gesteuert und verfügen über viele potenzielle alternative Routen.
Beachten Sie auch, dass die Netzwerktopologie im Allgemeinen viel komplizierter ist (das obige Fragment ist rot eingekreist):

Und dies ist nicht das kleinste Segment - die Topologie wird immer komplexer:

Diese Option war also für die meditative Analyse von Einzelfällen geeignet, jedoch in keiner Weise für eine rationalisierte Arbeit und darüber hinaus nicht für die Automatisierung der Lösung von Direkt und Umgekehrt.
Teil 2. Automatisierung v1.0
Ich möchte Sie daran erinnern, welche Aufgaben wir gelöst haben:
- Bestimmen des Pfades des Dienstes durch das Fahrzeug - Direkte Aufgabe.
- Ermittlung abhängiger Dienste aus dem TC-Kanal - Inverses Problem.
2.1. Transportdienste für Basisstationen (BS)
Im Allgemeinen sieht die Organisation des Transports vom zentralen Knoten (Controller / Gateway) zur BS folgendermaßen aus:

Auf den Aggregationssegmenten und dem Kern des TS werden Verbindungen über Transportdienste des MPLS-Netzwerks hergestellt: L2 / L3 VPN, VLL. In Zugriffssegmenten werden Verbindungen in der Regel über dedizierte VLANs ausgeführt.
Ich möchte Sie daran erinnern, dass wir eine Datenbank haben, in der alle tatsächlichen (innerhalb eines bestimmten Zeitraums) Parameter und die Topologie des Fahrzeugs liegen.
2.2. DFÜ-Segmentlösung (Zugriff)
Wir nehmen Daten über das VLAN der logischen BS-Schnittstelle und „gehen“ Schritt für Schritt durch die Links, deren Ports diese Vlan-ID enthalten, bis wir den Border Router (MBN) erreichen.

Um eine so einfache Problemstellung zu lösen, musste ich:
- Schreiben Sie einen Algorithmus zur schrittweisen Verfolgung der "Ausbreitung" von VlanID von BS über die Kanäle des Aggregationsnetzwerks
- Berücksichtigen Sie vorhandene Datenlücken. Dies gilt insbesondere für die Verbindungen zwischen den Knoten an den Standorten.
- Schreiben Sie einen SPF-Algorithmus, um am Ende Sackgassenzweige zu löschen, die nicht zum MVN-Router führen.
Der Algorithmus entstand aus einem Hauptprozess und sieben Unterprozessen. Die Implementierung und das Debuggen dauerten 3-4 Wochen reine Arbeitszeit.
Darüber hinaus wurde uns besondere Freude bereitet ...
2.2.1. SQL JOIN
Aufgrund seiner Struktur erfordert das relationale Modell zum Durchlaufen des Diagramms einen expliziten rekursiven Ansatz mit Verknüpfungsoperationen auf jeder Ebene, während wiederholt ein Satz von Datensätzen durchlaufen wird. Dies führt wiederum zu einer Verschlechterung der Systemleistung, insbesondere bei großen Datenmengen.
Aus offensichtlichen Gründen kann ich den Inhalt von Abfragen hier nicht auf die Datenbank verweisen, sondern auswerten - jede "Kante" im Abfragetext ist die Verbindung der nächsten Tabelle, die in diesem Fall benötigt wird, um eine einheitliche Korrespondenz zwischen Port-VlanID zu erhalten:

Mit dieser Anforderung sollen VlanID-Querverbindungen innerhalb des Switches in einheitlicher Form erhalten werden:

In Anbetracht der Tatsache, dass die Anzahl der Ports mehrere Zehntausend betrug und das VLAN zehnmal höher war, war dies alles nur sehr ungern zu werfen und zu drehen. Und solche Anfragen mussten für jeden Knoten und jede VlanID gestellt werden. Und „alles auf einmal entladen und berechnen“ ist seitdem unmöglich Es handelt sich um eine sequentielle Berechnung des Pfads c mit schrittweisen Operationen, die von den Ergebnissen des vorherigen Schritts abhängen.
2.3. Bestimmen des Servicepfads in gerouteten Segmenten
Hier haben wir mit einem MVN-Anbieter begonnen, dessen Managementsystem Daten zu den aktuellen und Standby-LSPs über das MPLS-Segment bereitstellte. Bei Kenntnis der mit dem Zugriff verbundenen Access-Schnittstelle (L2 Vlan) war es möglich, den LSP zu finden und dann über eine Reihe von Anforderungen an das NBI-System den LSP-Pfad abzurufen, der aus Routern und Verbindungen zwischen ihnen besteht.

- Ähnlich wie beim geschalteten Segment führte die Beschreibung des Entladens des LSP-Pfads des MPLS-Dienstes zu einem Algorithmus mit bereits 17 Unterroutinen.
- Die Lösung funktionierte nur in Segmenten, die von diesem Anbieter bedient wurden
- Es war notwendig, die Definition der Verbindungen zwischen MPLS-Diensten zu bestimmen (zum Beispiel gab es in der Mitte des Segments einen allgemeinen VPLS-Dienst, von dem entweder EPIPE oder L3VPN abweichen).
Wir haben an dem Problem für andere MVN-Anbieter gearbeitet, bei denen es keine Steuerungssysteme gab oder die im Prinzip keine Daten zur aktuellen LSP-Passage lieferten. Wir haben eine Lösung für mehrere gefunden, aber - die Anzahl der LSPs, die den Router passieren, entspricht nicht mehr der Anzahl der VanIDs, die auf dem Switch registriert sind. Wenn Sie ein solches Datenvolumen „on demand“ verzögern (schließlich benötigen wir Betriebsinformationen), besteht die Gefahr, dass die Hardware heruntergefahren wird.
Darüber hinaus stellten sich weitere Fragen:
- – , , . .. – MPLS .
- , LSP, . . .
2.4. .
Die empfangenen Daten über die Pfade der Dienstverbindung müssen irgendwo notiert werden, damit wir später bei der Lösung unserer direkten und inversen Probleme darauf zurückgreifen können.
Die Option zum Speichern in einer relationalen Datenbank wurde sofort ausgeschlossen: Ist es so schwierig, Daten aus vielen Quellen zu aggregieren, damit sie später in die nächsten Tabellensätze sortiert werden? Dies ist nicht unsere Methode. Denken Sie außerdem an mehrstöckige Verbindungen und deren Leistung.
Die Daten sollten Informationen über die Struktur des Dienstes und die Abhängigkeiten seiner Komponenten enthalten: Links, Knoten, Ports usw.
Als Testlösung wurden das XML-Format und Native-XML DB - Exist ausgewählt.
Infolgedessen wurde jeder Dienst im Format in die Datenbank geschrieben (Details werden aus Gründen der Kompaktheit weggelassen):
<services>
<service>
<id>,<description> (, )
<source>
<target> Z
<<segment>> L2/L3
<topology> (, /, )
<<joints>> (, /, )
</service>
</services>Die Datenabfrage für direkte und inverse Probleme wurde unter Verwendung des XPath-Protokolls durchgeführt:

Alle. Jetzt arbeitet das System - für eine Anforderung mit dem Namen der BS wird die Topologie ihrer Verbindung über das Transportnetz zurückgegeben, für eine Anforderung mit dem Namen des Knotens und des Ports des TS wird eine Liste von BSs zurückgegeben, deren Verbindung von ihr abhängt. Daher haben wir folgende Schlussfolgerungen gezogen ...
2.5.

Anstatt auf die Ergebnisse von Teil 2 einzugehen
2.5.1. Für das Switched-Segment (Netzwerke auf L2-Ethernet-Switches)
- Vollständige Daten zur Topologie und Port-VlanID-Korrespondenz sind erforderlich. Wenn auf einer Verbindung keine VlanID-Daten vorhanden sind, stoppt der Algorithmus und der Pfad wurde nicht gefunden
- Unproduktive Abfragen auf mehreren Ebenen für eine relationale Datenbank. Wenn ein neuer Anbieter mit eigenen Details und Parametern angezeigt wird, werden Anforderungen in allen Arbeitsphasen hinzugefügt
2.5.2. Für ein geroutetes Segment
- Eingeschränkt durch die Möglichkeiten der MVN SU, Daten zur Topologie von LSP MPLS-Diensten bereitzustellen.
- – , .. LSP .
- LSP – ( , “” ).
2.5.3.
- , , , , ( – , ), , – .
- . 3-4 .
- , .. , MPLS .
- – , .
2.6. -
- , , .. – .
- , -
- (, VlanID)
Nachdem wir die möglichen Optionen für die Umsetzung unserer Wünsche geprüft hatten, entschieden wir uns für die Klasse von Systemen, die all dies "out of the box" bieten würden - dies ist die sogenannte. Diagrammdatenbanken.
Obwohl der letzte Satz etwas Lineares und Einfaches lautet, da zuvor keiner von uns (und, wie sich herausstellte, auch unsere IT-Spezialisten) jemals auf eine solche Datenbankklasse gestoßen war, kamen sie etwas zufällig zu der Entscheidung: Ähnliche Datenbanken wurden erwähnt (aber nicht verstanden) im Übersichtskurs zu Big Data. Insbesondere wurde das Produkt Neo4j erwähnt... Gemessen an der Beschreibung hat es nicht nur alle unsere Anforderungen erfüllt, sondern auch eine völlig kostenlose funktionale Community-Version. Jene. - Keine 30-Tage-Testversion, keine Einschränkung der Hauptfunktionalität, sondern ein voll funktionsfähiges Produkt, das Sie langsam studieren können. Nicht die letzte (wenn nicht die Haupt-) Rolle bei der Auswahl spielte die breite Unterstützung von Graph-Algorithmen .
Teil 3. Ein Beispiel für die Implementierung des direkten Problems in Neo4j
Um die lineare Darstellung der Implementierung des TS-Modells in der Neo4j-Diagrammdatenbank nicht herauszuziehen, zeigen wir das Endergebnis sofort anhand eines Beispiels.
3.1. Verfolgung des Pfades der Iub-Schnittstelle für 3G BS

Der Pfad der Dienstverbindung verläuft über zwei Segmente - eine geroutete MVN und eine geschaltete Funkrelaisverbindung (Funkrelaisstationen fungieren als Ethernet-Switches). Der Pfad durch das RRL-Segment wird auf die gleiche Weise wie in Teil 2 beschrieben bestimmt - durch den Durchgang der BS-Schnittstelle VlanID entlang des RRL-Segments zum MVN-Grenzrouter. Das MVN-Segment verbindet den Grenzrouter (mit dem RRL-Segment) - mit dem Router, mit dem der BS-Controller (RNC) verbunden ist.
Aus dem Iub-Parameter wissen wir zunächst genau, welches MVN das Gateway für die BS (Boundary MVN) ist und welcher Controller von der BS bedient wird.
Basierend auf diesen Anfangsbedingungen werden wir für jedes Segment 2 Abfragen an die Datenbank erstellen. Alle Abfragen an die Datenbank werden in der Cypher- Sprache erstellt... Um sich jetzt nicht von seiner Beschreibung ablenken zu lassen, stellen Sie es sich einfach als „SQL für Diagramme“ vor.
3.1.1. RRL-Segment. VlanID-Pfad
Verschlüsselungsanforderung zum Verfolgen des Dienstpfads basierend auf den verfügbaren VlanID- und L2-Topologiedaten:
| Fragment einer Cypher-Abfrage
(WITH-Konstruktion - Übertragen der Ergebnisse einer Stufe der Abfrage in die nächste (Pipelining der Verarbeitung)) |
Zwischenabfrageergebnisse (visuelle Darstellung in der Neo4j-Konsole - „ Neo4j-Browser “) |
|---|---|
Abrufen der BS- und MVN-Knoten, zwischen denen der Iub-Dienstpfad durchsucht wird
|
 |
Empfangen von Vlan-Knoten der BS-Schnittstelle Iub
|
 |
Wir wählen die Knoten des Fahrzeugs an derselben Stelle mit der BS aus, an deren Ports die VlanID Iub BS registriert ist
|
 |
Unter Verwendung des Dijkstra-Algorithmus finden wir den kürzesten Weg von der VlanID des TS des Standorts der BS zur Grenz-MVN
|
 |
Von der Vlan-Kette erhalten wir eine Liste von Knoten, Ports und Verbindungen zwischen Ports, mit denen der Iub-Dienst letztendlich von der BS zum Grenzrouter verbunden werden kann
Ergebnis: |
|
 |
|
Wie Sie sehen können, wurde der Pfad trotz eines teilweisen Datenmangels erhalten. In diesem Fall gibt es keine Informationen über die Verbindung des BS-Ports mit dem Port der Funkrelaisstation.
3.1.2. RRL-Segment. L2-Topologiepfad
Angenommen, in Abschnitt 3.1.1 wird ein Versuch unternommen. Fehler aufgrund vollständiger oder teilweiser Abwesenheit von Daten zum VlanID-Parameter. Mit anderen Worten, eine solche kontinuierliche Kette, die den MVN-Knoten erreicht, wird nicht aufgebaut:
Anschließend können Sie versuchen, die Dienstverbindung als den kürzesten Pfad zum MVN gemäß der L2-Topologie zu definieren:
Ergebnis: |
 |
Wie Sie sehen können, wird das gleiche Ergebnis erzielt. Hier wird der Mangel an Informationen über die Verbindung der BS mit dem RRS ausgeglichen, indem die Verbindung durch das Objekt (Knoten) der Stelle geleitet wird, an der sie sich befinden. Natürlich wird die Genauigkeit dieser Methode geringer sein, weil Im Allgemeinen wird Vlan möglicherweise nicht auf dem kürzesten Weg registriert, der vom Dijkstra-Algorithmus vorgeschlagen wird. Die Anfrage besteht jedoch nur aus zwei Operationen.
3.1.3 MVN-Segment. Verfolgung des Pfades von der Grenz-MVN zur Steuerung
Hier verwenden wir auch den Dijkstra-Algorithmus.
Ein Weg mit minimalen Kosten
|
 |
Top 2 Pfade mit minimalen Kosten (Haupt + Alternative)
|
 |
Top 3 Pfade mit minimalen Kosten (Haupt + zwei Alternativen)
|
 |
Ebenso gibt es in diesem Fall keine Informationen über die direkten Verbindungen des MVN mit dem RNC. Dies hindert Sie jedoch nicht daran, einen Servicepfad zu erstellen, selbst wenn dieser vom Algorithmus angenommen wird (dazu später mehr).
3.2. Arbeitskosten
Die jetzt gezeigte Implementierung des direkten Problems unterscheidet sich deutlich von dem Ansatz "Entwickeln eines Algorithmus, eines Programms, einer Methode zum Speichern und Abrufen von Ergebnissen" - alles läuft darauf hinaus, "eine Abfrage in die Datenbank zu schreiben". Mit Blick auf die Zukunft stellen wir fest, dass der gesamte Zyklus von der Entwicklung eines einfachen Diagrammmodells über das Laden von Daten aus einer relationalen Datenbank in Neo4j bis hin zum Schreiben von Abfragen und bis zum Erreichen des Ergebnisses insgesamt einen Tag dauerte.
3-4 Monate vs 1 Tag !!! Dies war der letzte Grund für die endgültige Abkehr von der Grafikdatenbank.
Teil 4. Graph Datenbank Neo4j und Laden von Daten in sie
4.1. Vergleich von relationalen und graphischen Datenbanken



4.2. Datenmodell
Das Grundmodell der TS-Präsentation bis zur L3-Topologie einschließlich:

Natürlich ist das Modell umfangreicher als das vorgestellte und enthält auch MPLS-Dienste und virtuelle Schnittstellen, aber der Einfachheit halber betrachten wir ein begrenztes Fragment davon.
In einem solchen Modell kann die Beziehung zwischen zwei Netzwerkelementen derselben Region wie folgt dargestellt werden:

4.3. Daten werden geladen
Wir laden Daten aus der Datenbank der Parameter und der Topologie des Fahrzeugs. Zum Laden in Neo4j aus der SQL-Datenbank wird die APOC-Bibliothek verwendet - apoc.load.jdbc , die eine Verbindungszeichenfolge zum RDBMS und den Text einer SQL-Abfrage als Eingabe akzeptiert und eine Reihe von Zeichenfolgen zurückgibt, die Knoten, Links oder Parametern über CYHPER-Ausdrücke zugeordnet sind. Solche Operationen werden Schicht für Schicht für jeden Typ von Modellobjekt ausgeführt.
Beispiel: Ein Durchgang zum Laden / Aktualisieren von Knoten, die Netzwerkelemente (Knoten) darstellen:
|
Rufen Sie die Prozedur apoc.load.jdbc auf und rufen Sie
einen Datensatz ab |
|
Für jede Zeile aus dem Datensatz
nach Region und Standortcode werden Knoten durchsucht, die die entsprechenden Standorte darstellen |
|
Für jedes Standortobjekt werden die
zugehörigen Netzwerkelemente (Knoten) aktualisiert . Der Befehl MERGE + SET wird verwendet, der die Parameter des Objekts aktualisiert, wenn es bereits in der Datenbank vorhanden ist. Wenn nicht , wird das Objekt erstellt. Die Parameter des Knotenknotens und seine Verbindungen mit dem PL-Knoten werden ebenfalls aufgezeichnet. |
Und so weiter - über alle Ebenen des TS-Modells hinweg.
Das Feld Aktualisiert wird verwendet, um die Relevanz der Daten in der Spalte zu steuern. Objekte, die nicht länger als einen bestimmten Zeitraum aktualisiert wurden, werden gelöscht.
Teil 5. Lösen des inversen Problems in Neo4j
Als wir anfingen, brachte der Ausdruck "Service Trace" zuerst die folgenden Assoziationen hervor:

Das heißt, dass der aktuelle Pfad des Dienstes zu einem bestimmten Zeitpunkt direkt verfolgt wird.
Dies ist nicht genau das, was wir in einer Graphendatenbank haben. In der GDB wird ein Dienst gemäß den Beziehungen von Objekten verfolgt, die seine Konfiguration in jedem beteiligten Netzwerkelement bestimmen . Das heißt, eine Konfiguration wird in Form eines Diagrammmodells dargestellt , und die resultierende Ablaufverfolgung ist ein Durchlauf durch das Modell, das diese Konfiguration darstellt.
Da im Gegensatz zum Switched-Segment die tatsächlichen Servicerouten im MPLS-Segment durch dynamische Protokolle bestimmt werden, mussten wir einige ...
5.1. Annahmen für geroutete Segmente
weil Aus den Konfigurationsdaten von mpls-Diensten kann der genaue Pfad durch die Segmente, die von dynamischen Routing-Protokollen gesteuert werden, nicht bestimmt werden (insbesondere wenn Verkehrstechnik verwendet wird). Für die Lösung wird der Dijkstra-Algorithmus verwendet.
Ja, es gibt Managementsysteme, die den tatsächlichen Pfad von Service-LSPs über die NBI-Schnittstelle bereitstellen können. Bisher haben wir jedoch nur einen solchen Anbieter, und es gibt mehr als einen Anbieter im MVN-Segment.
Ja, es gibt Systeme zur Analyse von Routing-Protokollen innerhalb des AS, die durch Abhören des Austauschs von IGP-Protokollen die aktuelle Route des interessierenden Präfixes bestimmen können. Aber es gibt solche Systeme - wie eine ausgefallene Boeing - und da ein solches System auf allen ASs desselben mobilen Backhole eingesetzt werden muss, werden die Kosten der Lösung zusammen mit allen Lizenzen die Kosten einer Boeing sein, die von einer gusseisernen Brücke abgeschossen wird, die an die Angara-Rakete gebunden ist, wenn sie vollständig betankt ist. Und dies trotz der Tatsache, dass solche Systeme das Problem der Berücksichtigung von Routen durch mehrere AS mit BGP nicht vollständig lösen.
Deshalb - soweit. Natürlich haben wir den Bedingungen des Standard-Dijkstra-Algorithmus einige Requisiten hinzugefügt:
- Berücksichtigung des Status von Schnittstellen / Ports. Die getrennte Verbindung erhöht die Kosten und geht bis zum Ende der möglichen Pfadoptionen.
- Berücksichtigung des Backup-Link-Status. Gemäß dem Leistungsüberwachungssystem wird das Vorhandensein von nur Keepalive-Verkehr im MPLS-Kanal berechnet, und die Kosten eines solchen Kanals steigen ebenfalls an.
5.2. So lösen Sie das inverse Problem in Neo4j
Erinnerung. Die umgekehrte Aufgabe besteht darin, eine Liste von Diensten zu erhalten, die von einem bestimmten Kanal oder Knoten des Transportnetzwerks (TS) abhängen.
5.2.1. Geschaltetes L2-Segment
Für das geschaltete Segment, in dem der Dienstpfad und die Dienstkonfiguration praktisch identisch sind, kann das Problem weiterhin durch CYPHER-Anforderungen gelöst werden. Zum Beispiel werden wir für einen Funkrelaisflug aufgrund der Ergebnisse der Lösung des direkten Problems in Abschnitt 3.1.1 eine Anfrage vom Funkrelaisverbindungsmodem stellen - "erweitern" Sie alle Vlan-Ketten, die es passieren:
match (tn:node {name:'RRN_29_XXXX_1'})-->(tn_port:port {name:'Modem-1'})-->(tn_vlan:vlan)
with tn, tn_vlan, tn_port
call apoc.path.spanningTree(tn_vlan,{relationshipFilter:"ptp_vlan>|v_ptp_vlan>", maxLevel:20}) yield path as pp
with tn_vlan,pp,nodes(pp)[-1] as last_node, tn_port
match (last_node)-[:vlan]->(:port)-->(n:node)
return pp, n, tn_portDer rote Knoten zeigt das Modem an, dessen Vlan wir bereitstellen. Es wurden 3 BSs eingekreist, woraufhin der Einsatz von Transit-Vlan mit Modem1 führte.

Dieser Ansatz hat mehrere Probleme:
- Der konfigurierte Vlan muss für die Ports bekannt und in das Modell geladen sein.
- Aufgrund einer möglichen Fragmentierung wird die Vlan-Kette nicht immer an den Endknoten ausgegeben
- Es ist unmöglich festzustellen, ob der letzte Knoten in der Vlan-Kette zu einem Endknoten gehört oder ob der Dienst tatsächlich fortgesetzt wird.
Das heißt, es ist immer bequemer, einen Dienst zwischen Endknoten / Punkten seines Segments zu verfolgen, als von einer beliebigen „Mitte“ und von einer OSI-Schicht.
5.2.2. Geroutetes Segment
Bei einem gerouteten Segment, wie bereits in Abschnitt 5.1 beschrieben, muss keine Auswahl getroffen werden - es gibt keine Möglichkeit, das inverse Problem basierend auf den Daten der aktuellen Konfiguration einer MPLS-Zwischenverbindung zu lösen -, die Konfiguration definiert den Service-Trace nicht explizit.
5.3. Entscheidung
Die Entscheidung wurde wie folgt getroffen.
- Die vollständige Beladung des Fahrzeugmodells einschließlich BS und Steuerungen wird durchgeführt
- Für alle BS ist das direkte Problem gelöst - Verfolgung von Iub, S1-Diensten von der BS zur Grenz-MVN und dann von der Grenz-MVN zu den entsprechenden Controllern oder Gateways.
- Trace-Ergebnisse werden im Format BS-Name - Array von Dienstpfadelementen in eine reguläre SQL-Datenbank geschrieben
Dementsprechend wird beim Zugriff auf die Datenbank mit der Bedingung Node TS oder Node TS + Port eine Liste von Diensten (BS) zurückgegeben, deren Pfadarray den erforderlichen Node oder Node + Port enthält.

Teil 6. Ergebnisse und Schlussfolgerungen
6.1. Ergebnisse
Infolgedessen funktioniert das System wie folgt:

Im Moment, um das direkte Problem zu lösen, d.h. Bei der Analyse der Ursachen für die Verschlechterung einzelner Dienste wurde eine Webanwendung entwickelt, die das Trace-Ergebnis (Pfad) von Neo4j mit überlagerten Daten zur Qualität und Leistung einzelner Abschnitte des Pfads anzeigt.

Um eine Liste von Diensten zu erhalten, die von Knoten oder Kanälen des TS abhängen (Lösung des inversen Problems), wurde eine API für externe Systeme (insbesondere Remedy) entwickelt.
6.2. Schlussfolgerungen
- Beide Lösungen haben die Automatisierung der Analyse der Dienstleistungsqualität und des Verkehrsnetzes auf ein qualitativ neues Niveau gebracht.
- Darüber hinaus wurde es bei Vorhandensein vorgefertigter Daten zu den Routen von BS-Diensten möglich, schnell Daten für Geschäftsbereiche über die technische Möglichkeit der Einbeziehung von B2B-Kunden an bestimmten Standorten bereitzustellen - in Bezug auf Kapazität und Qualität der Route.
- Neo4j hat sich als sehr leistungsfähiges Tool zur Lösung von Netzwerkgraphenproblemen erwiesen. Die Lösung ist gut dokumentiert , hat breite Unterstützung in verschiedenen Entwicklergemeinschaften und ständig weiterentwickelt und verbessert wird.
6.3. Pläne
Wir haben Pläne:
- Erweiterung der in der Neo4j-Datenbank modellierten Technologiesegmente
- Entwicklung und Implementierung von Tracing-Algorithmen für Breitbanddienste
- erhöhte Leistung der Serverplattform
Vielen Dank für Ihre Aufmerksamkeit!