
In IT-Kreisen gibt es einen solchen Witz, dass maschinelles Lernen (ML) wie Sex unter Teenagern ist: Jeder spricht darüber, jeder gibt vor, es zu tun, aber tatsächlich haben nur sehr wenige Menschen Erfolg. FunCorp ist es gelungen, ML in die Hauptmechanik seines Produkts einzuführen und eine radikale (fast 40%!) Verbesserung der wichtigsten Metriken zu erzielen. Interessant? Willkommen bei Katze.
Ein bisschen Hintergrund
Für diejenigen, die den FunCorp-Blog unregelmäßig lesen, möchte ich Sie daran erinnern, dass unser erfolgreichstes Produkt die iFunny UGC-Anwendung mit Elementen eines sozialen Netzwerks für Meme-Liebhaber ist. Benutzer (und dies ist jeder vierte Vertreter der jungen Generation in den USA) laden neue Bilder oder Videos direkt in die Anwendung hoch oder erstellen sie, und ein intelligenter Algorithmus wählt (oder, wie wir sagen, „Funktionen“ aus dem Wort „vorgestellt“) die besten von ihnen aus und formt sie jeweils Tag mit 7 Ausgaben von 30-60 Inhaltseinheiten in einem separaten Feed, mit dem 99% des Publikums interagieren. Infolgedessen sieht jeder Benutzer beim Aufrufen der Anwendung Top-Memes, Videos und lustige Bilder. Wenn Sie häufig besuchen, wird der Feed schnell gescrollt und der Benutzer wartet in wenigen Stunden auf die nächste Ausgabe. Wenn Sie jedoch weniger häufig besuchen, sammeln sich vorgestellte Inhalte an, und der Feed kann in wenigen Tagen auf 1000 Artikel anwachsen.
Dementsprechend stellte sich die Aufgabe: Jedem Benutzer den für ihn relevantesten Inhalt zu zeigen und Memes, die für ihn persönlich interessant sind, zu Beginn des Feeds zu gruppieren.
Seit über 9 Jahren des Bestehens von iFunny gibt es verschiedene Ansätze für diese Aufgabe.
Zuerst haben wir den offensichtlichen Weg versucht, den Feed nach der Anzahl der Lächeln zu sortieren (unser Analogon von "Likes") - Lächelnrate . Es war besser als das Sortieren in chronologischer Reihenfolge, führte aber gleichzeitig zum Effekt der "Durchschnittstemperatur im Krankenhaus": Es gibt wenig Humor, den jeder mag, und es wird immer diejenigen geben, die sich heute nicht für beliebte Themen interessieren (und diese sogar offen ärgern) ... Sie möchten aber auch alle neuen lustigen Witze aus Ihrem Lieblings-Cartoon sehen.
Im nächsten Experiment haben wir versucht, die Interessen einzelner Mikrogemeinschaften zu berücksichtigen: Fans von Anime, Sport, Memen mit Katzen und Hunden usw. Zu diesem Zweck begannen sie, mehrere thematische Feature-Feeds zu erstellen und den Benutzern die Auswahl von Themen anzubieten, die für sie von Interesse sind, wobei sie Tags und Text verwenden, die in Bildern erkannt werden. Etwas hat sich verbessert, aber die Wirkung des sozialen Netzwerks ist verloren gegangen: Es gibt weniger Kommentare zu vorgestellten Inhalten, die eine große Rolle bei der Benutzerinteraktion spielten. Außerdem haben wir auf dem Weg zu segmentierten Feeds viele wirklich beliebte Memes verloren. Sie sahen "Favorite Cartoon", sahen aber nicht die Witze über "The Last Avengers".
Da wir bereits begonnen haben, Algorithmen für maschinelles Lernen in unser Produkt zu implementieren, haben wir dies auf unserem eigenen Treffen vorgestelltwollten sie mit dieser Technologie einen anderen Ansatz verfolgen.
Es wurde beschlossen, ein Empfehlungssystem aufzubauen, das auf dem Prinzip der kollaborativen Filterung basiert. Dieses Prinzip ist in Fällen gut, in denen die Anwendung nur sehr wenige Daten über Benutzer enthält: Nur wenige geben bei der Registrierung ihr Alter oder Geschlecht an, und nur anhand der IP-Adresse kann man ihren geografischen Standort annehmen (obwohl ohne Wahrsager bekannt ist, dass die überwiegende Mehrheit der iFunny-Benutzer Einwohner sind USA) und per Telefonmodell - Einkommensniveau. Darauf im Allgemeinen alles. Die kollaborative Filterung funktioniert folgendermaßen: Der Verlauf positiver Bewertungen des Inhalts des Benutzers wird erfasst, andere Benutzer mit ähnlichen Bewertungen werden gefunden, und ihm wird empfohlen, was dieselben Benutzer zuvor mochten (mit ähnlichen Bewertungen).
Merkmale der Aufgabe
Memes sind ziemlich spezifische Inhalte. Erstens ist es sehr anfällig für sich schnell ändernde Trends. Der Inhalt und die Form, die vor einer Woche 80% des Publikums zum Lächeln gebracht haben, können heute aufgrund ihrer sekundären Natur und Irrelevanz zu Irritationen führen.
Zweitens eine sehr nichtlineare und situative Interpretation der Bedeutung des Mems. In der Nachrichtenauswahl können Sie bekannte Namen finden, Themen, die von einem bestimmten Benutzer ziemlich konsistent verwendet werden. In einer Auswahl von Filmen können Sie die Besetzung, das Genre und vieles mehr kennenlernen. Ja, all dies können Sie in einer Auswahl persönlicher Memes nachvollziehen. Aber wie enttäuschend wäre es, ein echtes Meisterwerk des Humors zu verpassen, das Bilder oder Vokabeln verwendet, die überhaupt nicht in den semantischen Inhalt passen!

Schließlich eine sehr große Menge an dynamisch generierten Inhalten. Bei iFunny erstellen Benutzer täglich Zehntausende von Posts. All diese Inhalte müssen so schnell wie möglich "geharkt" werden und im Falle eines personalisierten Empfehlungssystems nicht nur "Diamanten" finden, sondern auch in der Lage sein, die Bewertung von Inhalten durch verschiedene Vertreter der Gesellschaft vorherzusagen.
Was bedeuten diese Funktionen für die Entwicklung von Modellen für maschinelles Lernen? Zunächst muss das Modell ständig auf die neuesten Daten trainiert werden. Zu Beginn des Eintauchens in die Entwicklung eines Empfehlungssystems ist immer noch nicht ganz klar, ob es sich um zehn Minuten oder ein paar Stunden handelt. Beides bedeutet jedoch die Notwendigkeit einer ständigen Umschulung des Modells oder noch besser einer Online-Schulung in einem kontinuierlichen Datenstrom. All dies sind nicht die einfachsten Aufgaben unter dem Gesichtspunkt, eine geeignete Modellarchitektur zu finden und ihre Hyperparameter auszuwählen. Dies würde garantieren, dass sich die Metriken in ein paar Wochen nicht sicher verschlechtern.
Eine andere Schwierigkeit ist die Notwendigkeit, das von uns verabschiedete A / B-Testprotokoll zu befolgen. Wir implementieren niemals etwas, ohne vorher einige Benutzer zu überprüfen und die Ergebnisse mit einer Kontrollgruppe zu vergleichen.
Nach langen Berechnungen wurde beschlossen, ein MVP mit den folgenden Merkmalen zu starten: Wir verwenden nur Informationen über die Interaktion von Benutzern mit dem Inhalt, wir trainieren das Modell in Echtzeit direkt auf einem Server mit viel Speicher, der es ermöglicht, den gesamten Interaktionsverlauf einer Testgruppe von Benutzern über einen längeren Zeitraum zu speichern. Wir haben uns entschlossen, die Schulungszeit auf 15 bis 20 Minuten zu beschränken, um den Effekt der Neuheit aufrechtzuerhalten und Zeit zu haben, um die neuesten Daten von Benutzern zu verwenden, die während der Veröffentlichung massiv zur Anwendung kommen.
Modell
Zuerst haben wir begonnen, die klassischste kollaborative Filterung mit Matrixzerlegung und Training auf ALS (alternierendes kleinstes Quadrat) oder SGD (stochastischer Gradientenabstieg) zu verdrehen. Aber sie fanden schnell heraus: Warum nicht gleich mit dem einfachsten neuronalen Netzwerk beginnen? Aus einem einfachen einschichtigen Netz, in dem es nur eine lineare Einbettungsschicht gibt und keine versteckten Schichten umhüllt werden, um sich nicht in Wochen der Auswahl seiner Hyperparameter zu vergraben. Ein bisschen jenseits von MVP? Vielleicht. Ein solches Netz zu trainieren ist jedoch kaum schwieriger als eine klassischere Architektur, wenn Sie Hardware mit einer guten GPU haben (Sie mussten sich darauf einstellen).
Zunächst war klar, dass es nur zwei Optionen für die Entwicklung von Ereignissen gibt: Entweder liefert die Entwicklung ein signifikantes Ergebnis bei den Produktmetriken, dann müssen die Parameter von Benutzern und Inhalten weiter untersucht werden, zusätzliche Schulungen zu neuen Inhalten und neuen Benutzern, tiefe neuronale Netze oder ein personalisiertes Inhaltsranking wird nicht durchgeführt spürbare Zunahme und "Shop" können abgedeckt werden. Wenn die erste Option auftritt, müssen alle oben genannten Elemente mit der anfänglichen Einbettungsebene verschraubt werden.
Wir haben uns für die Neural Factorization Machine entschieden . Das Funktionsprinzip lautet wie folgt: Jeder Benutzer und jeder Inhalt werden durch Vektoren gleicher fester Länge codiert - Einbettungen, die dann auf einer Reihe bekannter Interaktionen zwischen dem Benutzer und dem Inhalt trainiert werden.
Das Trainingsset verwendet alle Fakten der Benutzer, die den Inhalt anzeigen. Zusätzlich zum Lächeln wurde beschlossen, Klicks auf die Schaltflächen "Teilen" oder "Speichern" in Betracht zu ziehen und einen Kommentar zu schreiben, um positives Feedback zum Inhalt zu erhalten. Falls vorhanden, wird die Interaktion mit 1 (eins) markiert. Wenn der Benutzer nach dem Anzeigen kein positives Feedback hinterlassen hat, wird die Interaktion mit 0 (Null) markiert. Selbst ohne eine explizite Bewertungsskala wird daher ein explizites Modell verwendet (ein Modell mit einer expliziten Bewertung des Benutzers) und kein implizites Modell, das nur positive Aktionen berücksichtigt.
Wir haben auch das implizite Modell ausprobiert, aber es hat nicht sofort funktioniert, also haben wir uns auf das explizite Modell konzentriert. Möglicherweise müssen Sie für das implizite Modell mehr List als einfache binäre Cross-Entropy-Ranking-Verlustfunktionen verwenden.
Der Unterschied zwischen der neuronalen Matrixfaktorisierung und der standardmäßigen neuronalen kollaborativen Filterung besteht in der Anwesenheit der sogenannten Bi-Interaction Pooling-Schicht anstelle der üblichen vollständig verbundenen Schicht, die einfach die Benutzer- und Inhaltseinbettungsvektoren verbindet. Die Bi-Interaction-Schicht konvertiert eine Reihe von Einbettungsvektoren (es gibt nur 2 Vektoren in iFunny: Benutzer und Inhalt) in einen Vektor, indem sie Element für Element multipliziert werden.
In Ermangelung zusätzlicher versteckter Schichten über Bi-Interaction erhalten wir das Punktprodukt dieser Vektoren und wickeln es, indem wir User Bias und Content Bias hinzufügen, in ein Sigmoid ein. Dies ist eine Schätzung der Wahrscheinlichkeit eines positiven Feedbacks eines Benutzers nach dem Anzeigen dieses Inhalts. Nach dieser Einschätzung ordnen wir den verfügbaren Inhalt, bevor wir ihn auf einem bestimmten Gerät demonstrieren.
Die Aufgabe des Trainings besteht daher darin, sicherzustellen, dass die Benutzer- und Inhaltseinbettungen, für die eine positive Interaktion besteht, nahe beieinander liegen (mit dem maximalen Punktprodukt), und dass die Benutzer- und Inhaltseinbettungen, für die eine negative Interaktion vorliegt, weit voneinander entfernt sind. (minimales Punktprodukt).
Durch diese Schulung werden Einbettungen von Benutzern, die dasselbe lächeln, von selbst nahe beieinander. Dies ist eine praktische mathematische Beschreibung der Benutzer, die für viele andere Aufgaben verwendet werden kann. Aber das ist eine andere Geschichte.
Der Benutzer gibt also den Feed ein und beginnt, den Inhalt anzusehen. Jedes Mal, wenn Sie anzeigen, lächeln, teilen usw. Der Client sendet Statistiken an unseren Analysespeicher (über den wir bei Interesse weiter oben im Artikel Wechsel von Redshift zu Clickhouse geschrieben haben ). Unterwegs wählen wir die für uns interessanten Ereignisse aus und senden sie an den ML-Server, wo sie gespeichert werden.
Alle 15 Minuten wird das Modell auf dem Server umgeschult, wonach neue Benutzerstatistiken in Empfehlungen berücksichtigt werden.
Der Client fordert die nächste Seite des Feeds an. Sie wird auf standardmäßige Weise erstellt. Auf dem Weg wird die Inhaltsliste jedoch an den ML-Dienst gesendet, der sie nach den vom trainierten Modell für diesen bestimmten Benutzer angegebenen Gewichten sortiert.

Infolgedessen sieht der Benutzer zuerst die Bilder und Videos, die ihm je nach Modell am meisten vorzuziehen sind.
Interne Servicearchitektur
Der Dienst funktioniert über HTTP. Flask wird in Verbindung mit Gunicorn als HTTP-Server verwendet. Es werden zwei Anforderungen verarbeitet: add_event und get_rates.
Die Anforderung add_event fügt eine neue Interaktion zwischen Benutzer und Inhalt hinzu. Es wird einer internen Warteschlange hinzugefügt und dann in einem separaten Prozess verarbeitet (bis zu 1600 U / min).
Die Anforderung get_rates berechnet die Gewichte für die Liste user_id und content_id gemäß dem Modell (bei einem Spitzenwert von etwa hundert U / s).
Der interne Hauptprozess ist der Dispatcher. Es ist in Asyncio geschrieben und implementiert die grundlegende Logik:
- verarbeitet die Warteschlange von add_event-Anforderungen und speichert sie in einer riesigen Hashmap (200 Millionen Ereignisse pro Woche);
- berechnet das Modell in einem Kreis neu;
- speichert alle halbe Stunde neue Ereignisse auf der Festplatte, während Ereignisse, die älter als eine Woche sind, aus der Hashmap gelöscht werden.

Das trainierte Modell wird im gemeinsamen Speicher abgelegt, von wo aus es von HTTP-Mitarbeitern gelesen wird.
Ergebnisse
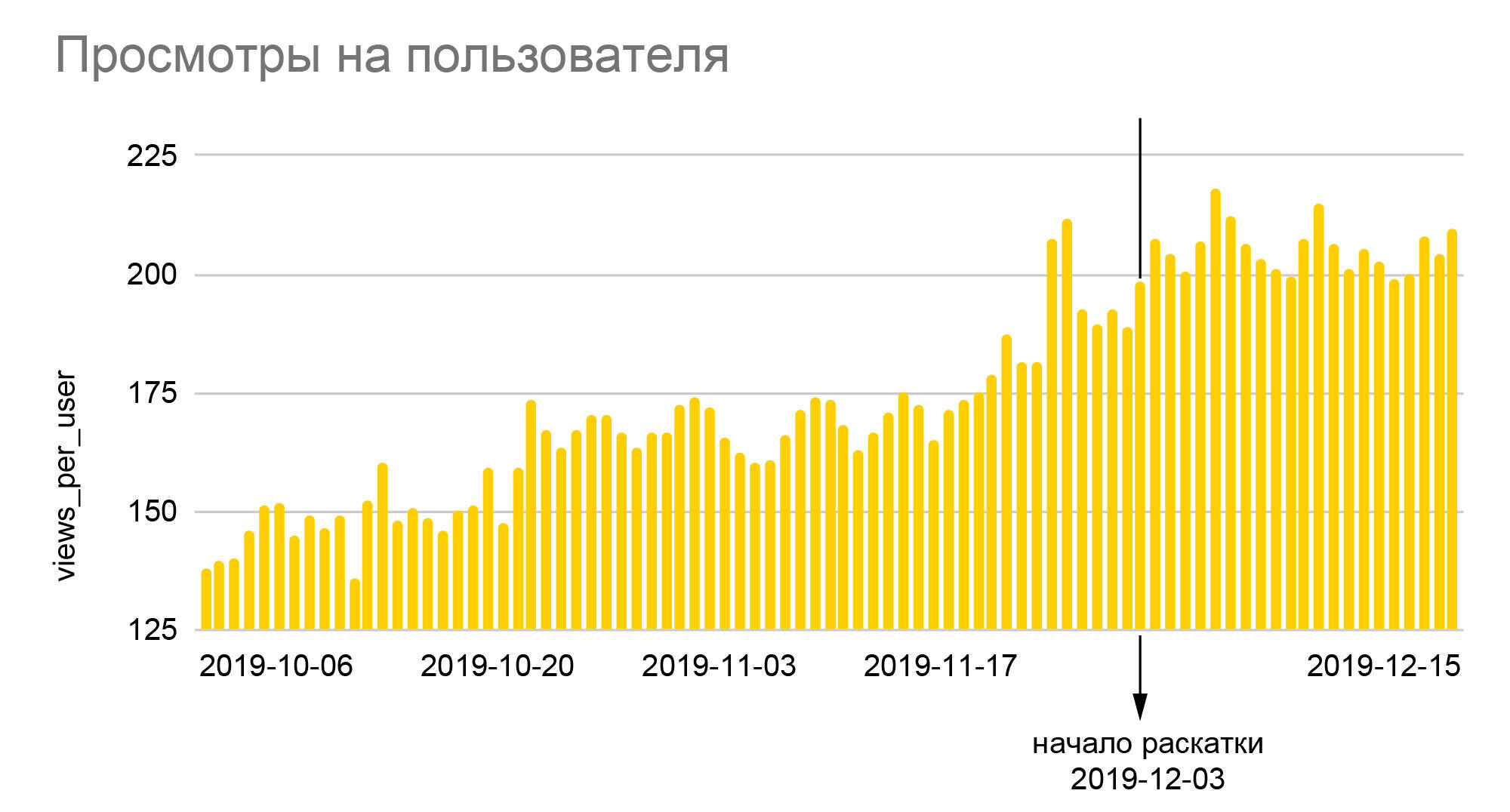

Die Charts sprechen für sich. Das 25% ige Wachstum der relativen Anzahl von Smilies und fast 40% der Tiefe der Ansichten, die wir auf ihnen sehen, ist das Ergebnis der Einführung des neuen Algorithmus für das gesamte Publikum am Ende des A / B-Tests 50/50, dh ein realer Anstieg im Vergleich zu den Basiswerten war fast doppelt so groß. Da iFunny mit Werbung Geld verdient, bedeutet die Erhöhung der Tiefe eine proportionale Steigerung der Einnahmen, die es uns wiederum ermöglichte, die Krisenmonate 2020 recht ruhig zu überstehen. Eine Erhöhung der Anzahl der Smilies führt zu einer höheren Loyalität, was eine geringere Wahrscheinlichkeit bedeutet, die Anwendung in Zukunft abzubrechen. Loyale Benutzer beginnen, andere Bereiche der Anwendung aufzurufen, Kommentare zu hinterlassen und miteinander zu kommunizieren. Und vor allem haben wir nicht nur eine verlässliche Grundlage für die Verbesserung der Qualität von Empfehlungen geschaffen.Es wurde jedoch auch der Grundstein für die Erstellung neuer Funktionen gelegt, die auf der enormen Menge an anonymen Verhaltensdaten basieren, die wir im Laufe der Jahre der Anwendung gesammelt haben.
Fazit
Der ML Content Rate Service ist das Ergebnis einer Vielzahl kleinerer Verbesserungen und Verbesserungen.
Erstens wurden auch nicht registrierte Benutzer in der Schulung berücksichtigt. Anfangs gab es Fragen zu ihnen, da sie a priori keine Emoticons hinterlassen konnten - das häufigste Feedback nach dem Betrachten von Inhalten. Es wurde jedoch bald klar, dass diese Befürchtungen vergeblich waren und einen sehr großen Wachstumspunkt schlossen. Mit der Konfiguration des Trainingsmusters werden viele Experimente durchgeführt: um einen größeren Teil des Publikums darin zu platzieren oder um das Zeitintervall der berücksichtigten Interaktionen zu erweitern. Im Verlauf dieser Experimente stellte sich heraus, dass nicht nur die Datenmenge eine wichtige Rolle für die Produktmetrik spielt, sondern auch die Zeit für die Aktualisierung des Modells. Oft ertrank die Verbesserung der Qualität des Rankings in den zusätzlichen 10 bis 20 Minuten, um das Modell neu zu berechnen, was es erforderlich machte, Innovationen aufzugeben.
Viele, selbst die kleinsten Verbesserungen haben zu Ergebnissen geführt: Sie haben entweder die Qualität des Lernens verbessert oder den Lernprozess beschleunigt oder Speicherplatz gespart. Zum Beispiel gab es ein Problem mit der Tatsache, dass Interaktionen nicht in den Speicher passten - sie mussten optimiert werden. Darüber hinaus wurde der Code geändert und es wurde möglich, beispielsweise mehr Interaktionen zur Neuberechnung hineinzuschieben. Dies führte auch zu einer verbesserten Servicestabilität.
Derzeit wird daran gearbeitet, die bekannten Benutzer- und Inhaltsparameter effektiv zu nutzen, ein inkrementelles, schnell umschulendes Modell zu erstellen, und es entstehen neue Hypothesen für zukünftige Verbesserungen.
Wenn Sie wissen möchten, wie wir diesen Service entwickelt haben und welche anderen Verbesserungen wir implementiert haben, schreiben Sie in die Kommentare. Nach einer Weile sind wir bereit, den zweiten Teil zu schreiben.
Über die Autoren
Leider erlaubt Habr nicht, mehrere Autoren für den Artikel anzugeben. Obwohl der Artikel von meinem Konto aus veröffentlicht wurde, wurde der größte Teil vom Hauptentwickler der FunCorp ML-Dienste - Grisha Kuzovnikov (PhoenixMSTU) sowie eine Analystin und Datenwissenschaftlerin - Dima Zemtsov. Ihr widerspenstiger Diener ist hauptsächlich für die Teenie-Sex-Witze, die Einführung und den Ergebnisbereich sowie die redaktionelle Arbeit verantwortlich. Und natürlich wären all diese Erfolge ohne die Hilfe der Backend-Entwicklungsteams, der Qualitätssicherung, der Analysten und des Produktteams nicht möglich gewesen, die all dies erfunden und mehrere Monate damit verbracht haben, A / B-Experimente durchzuführen und anzupassen.