Die Prinzipien unseres Systems
Wenn Sie Begriffe wie "automatisch" und "Betrug" hören, denken Sie wahrscheinlich an maschinelles Lernen, Apache Spark, Hadoop, Python, Airflow und andere Technologien aus dem Ökosystem und der Datenwissenschaft der Apache Foundation. Ich denke, es gibt einen Aspekt bei der Verwendung dieser Tools, der normalerweise nicht erwähnt wird: Sie erfordern bestimmte Voraussetzungen in Ihrem Unternehmenssystem, bevor Sie sie verwenden können. Kurz gesagt, Sie benötigen eine Unternehmensdatenplattform, die einen Datensee und einen Speicher enthält. Aber was ist, wenn Sie keine solche Plattform haben und diese Praxis noch entwickeln müssen? Die folgenden Prinzipien, die ich unten diskutiere, haben uns geholfen, den Punkt zu erreichen, an dem wir uns darauf konzentrieren können, unsere Ideen zu verbessern, anstatt eine zu finden, die funktioniert. Dies ist jedoch kein "Plateau" des Projekts.Aus technologischer und produktbezogener Sicht sind noch viele Dinge im Plan.
Prinzip 1: Geschäftswert steht an erster Stelle
Wir haben den geschäftlichen Wert in den Mittelpunkt all unserer Bemühungen gestellt. Im Allgemeinen gehört jedes automatische Analysesystem zur Gruppe der komplexen Systeme mit einem hohen Automatisierungsgrad und einer hohen technischen Komplexität. Die Erstellung einer vollständigen Lösung dauert lange, wenn Sie sie von Grund auf neu erstellen. Wir haben uns entschlossen, den geschäftlichen Wert und die technologische Vollständigkeit an zweiter Stelle zu setzen. Im wirklichen Leben bedeutet dies, dass wir fortschrittliche Technologie nicht als Dogma akzeptieren. Wir wählen die Technologie, die im Moment für uns am besten funktioniert. Im Laufe der Zeit scheint es, dass wir einige Module neu implementieren müssen. Diesen Kompromiss haben wir akzeptiert.
Prinzip 2: Erweiterte Intelligenz
Ich wette, die meisten Leute, die nicht tief in die Entwicklung von Lösungen für maschinelles Lernen involviert sind, denken vielleicht, dass das Ersetzen von Menschen das Ziel ist. Tatsächlich sind Lösungen für maschinelles Lernen alles andere als perfekt und können nur in bestimmten Bereichen ersetzt werden. Wir haben diese Idee von Anfang an aus mehreren Gründen verworfen: unausgewogene Daten zu betrügerischen Aktivitäten und die Unfähigkeit, eine vollständige Liste von Funktionen für Modelle des maschinellen Lernens bereitzustellen. Im Gegensatz dazu haben wir uns für die erweiterte Intelligenzoption entschieden. Es ist ein alternatives Konzept der künstlichen Intelligenz, das sich auf die unterstützende Rolle der KI konzentriert und die Tatsache hervorhebt, dass kognitive Technologien die menschliche Intelligenz verbessern und nicht ersetzen sollen. [1]
Vor diesem Hintergrund würde die Entwicklung einer vollständigen Lösung für maschinelles Lernen von Anfang an einen enormen Aufwand erfordern, der die Wertschöpfung für unser Unternehmen verzögern würde. Wir haben uns entschlossen, unter Anleitung unserer Domain-Experten ein System mit einem iterativ wachsenden Aspekt des maschinellen Lernens aufzubauen. Der schwierige Teil bei der Entwicklung eines solchen Systems besteht darin, dass es unseren Analysten Fälle liefern muss, nicht nur, ob es sich um eine betrügerische Aktivität handelt oder nicht. Im Allgemeinen ist jede Anomalie im Kundenverhalten ein verdächtiger Fall, den Spezialisten untersuchen und irgendwie reagieren müssen. Nur ein Bruchteil dieser gemeldeten Fälle kann tatsächlich als Betrug eingestuft werden.
Prinzip 3: Rich Intelligence-Plattform
Der schwierigste Teil unseres Systems ist die End-to-End-Überprüfung des Systemworkflows. Analysten und Entwickler sollten in der Lage sein, historische Datensätze mit allen für ihre Analyse verwendeten Metriken problemlos abzurufen. Darüber hinaus sollte die Datenplattform eine einfache Möglichkeit bieten, einem vorhandenen Satz von Metriken neue Metriken hinzuzufügen. Die von uns erstellten Prozesse, und dies sind nicht nur Softwareprozesse, sollten es einfach machen, frühere Perioden neu zu berechnen, neue Metriken hinzuzufügen und die Datenprognose zu ändern. Wir könnten dies erreichen, indem wir alle Daten sammeln, die unser Produktionssystem generiert. In diesem Fall würden die Daten allmählich zu einem Hindernis. Wir müssten die wachsende Datenmenge speichern und schützen, die wir nicht verwenden. In einem solchen Szenario werden die Daten im Laufe der Zeit immer irrelevanter.erfordern aber immer noch unsere Anstrengungen, um sie zu verwalten. Für uns war das Horten von Daten nicht sinnvoll, und wir entschieden uns für einen anderen Ansatz. Wir haben uns entschlossen, Echtzeit-Datenspeicher um die Zielentitäten herum zu organisieren, die wir klassifizieren möchten, und nur Daten zu speichern, mit denen wir die neuesten und aktuellsten Zeiträume überprüfen können. Die Herausforderung bei dieser Anstrengung besteht darin, dass unser System heterogen ist und mehrere Datenspeicher und Softwaremodule enthält, die eine sorgfältige Planung erfordern, um konsistent zu arbeiten.Hiermit können Sie die letzten und aktuellen Perioden überprüfen. Die Herausforderung bei dieser Anstrengung besteht darin, dass unser System heterogen ist und mehrere Datenspeicher und Softwaremodule enthält, die eine sorgfältige Planung erfordern, um konsistent zu arbeiten.Hiermit können Sie die letzten und aktuellen Perioden überprüfen. Die Herausforderung bei dieser Anstrengung besteht darin, dass unser System heterogen ist und mehrere Datenspeicher und Softwaremodule enthält, die eine sorgfältige Planung erfordern, um konsistent zu arbeiten.
Konstruktive Konzepte unseres Systems
Wir haben vier Hauptkomponenten in unserem System: Aufnahmesystem, Computer-, BI-Analyse- und Verfolgungssystem. Sie dienen bestimmten isolierten Zwecken, und wir halten sie isoliert, indem wir bestimmten Entwurfsansätzen folgen.
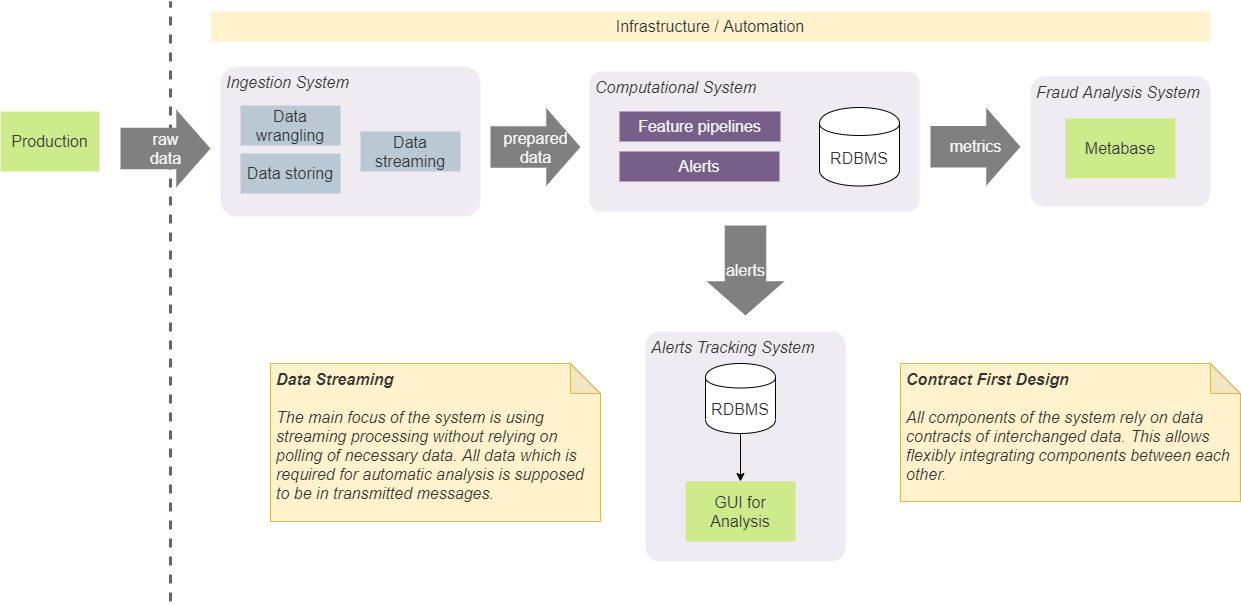
Vertragsbasiertes Design
Zunächst waren wir uns einig, dass Komponenten nur auf bestimmten Datenstrukturen (Verträgen) beruhen sollten, die zwischen ihnen ausgetauscht werden. Dies macht es einfach, sich zwischen ihnen zu integrieren und keine bestimmte Zusammensetzung (und Reihenfolge) von Komponenten festzulegen. In einigen Fällen können wir beispielsweise das empfangende System direkt in das Alarmverfolgungssystem integrieren. In diesem Fall erfolgt dies gemäß dem vereinbarten Benachrichtigungsvertrag. Dies bedeutet, dass beide Komponenten mithilfe eines Vertrags integriert werden, den jede andere Komponente verwenden kann. Wir werden keinen zusätzlichen Vertrag hinzufügen, um dem Verfolgungssystem Warnungen vom Eingabesystem hinzuzufügen. Dieser Ansatz erfordert die Verwendung einer vorgegebenen Mindestanzahl von Verträgen und vereinfacht das System und die Kommunikation. Eigentlich,Wir verwenden einen Ansatz namens "Contract First Design" und wenden ihn auf Streaming-Verträge an. [2]
Das Aufrechterhalten und Verwalten des Status im System führt unweigerlich zu Komplikationen bei der Implementierung. Im Allgemeinen sollte der Status von jeder Komponente aus zugänglich sein, konsistent sein und den relevantesten Wert für alle Komponenten liefern, und er sollte mit den richtigen Werten zuverlässig sein. Darüber hinaus erhöhen Aufrufe an persistenten Speicher, um den letzten Status zu erhalten, die E / A-Menge und die Komplexität der in unseren Echtzeit-Pipelines verwendeten Algorithmen. Aus diesem Grund haben wir uns entschlossen, den Statusspeicher so vollständig wie möglich aus unserem System zu entfernen. Dieser Ansatz erfordert die Aufnahme aller erforderlichen Daten in den übertragenen Datenblock (Nachricht). Wenn wir beispielsweise die Gesamtzahl einiger Beobachtungen berechnen müssen (die Anzahl der Operationen oder Fälle mit bestimmten Merkmalen),Wir berechnen es im Speicher und erzeugen einen Strom solcher Werte. Abhängige Module verwenden Partition und Batch, um den Stream in Entitäten aufzuteilen und die neuesten Werte zu verarbeiten. Durch diesen Ansatz wurde die Notwendigkeit eines dauerhaften Festplattenspeichers für solche Daten beseitigt. Unser System verwendet Kafka als Nachrichtenbroker und kann als Datenbank mit KSQL verwendet werden. [3] Aber die Verwendung würde unsere Lösung stark an Kafka binden, und wir haben beschlossen, sie nicht zu verwenden. Der von uns gewählte Ansatz ermöglicht es uns, Kafka ohne größere interne Systemänderungen durch einen anderen Nachrichtenbroker zu ersetzen.Durch diesen Ansatz wurde die Notwendigkeit eines dauerhaften Festplattenspeichers für solche Daten beseitigt. Unser System verwendet Kafka als Nachrichtenbroker und kann als Datenbank mit KSQL verwendet werden. [3] Aber die Verwendung würde unsere Lösung stark an Kafka binden, und wir haben beschlossen, sie nicht zu verwenden. Der von uns gewählte Ansatz ermöglicht es uns, Kafka ohne größere interne Systemänderungen durch einen anderen Nachrichtenbroker zu ersetzen.Durch diesen Ansatz wurde die Notwendigkeit eines dauerhaften Festplattenspeichers für solche Daten beseitigt. Unser System verwendet Kafka als Nachrichtenbroker und kann als Datenbank mit KSQL verwendet werden. [3] Aber die Verwendung würde unsere Lösung stark an Kafka binden, und wir haben beschlossen, sie nicht zu verwenden. Der von uns gewählte Ansatz ermöglicht es uns, Kafka ohne größere interne Systemänderungen durch einen anderen Nachrichtenbroker zu ersetzen.
Dieses Konzept bedeutet nicht, dass wir keinen Festplattenspeicher und keine Datenbanken verwenden. Um die Leistung des Systems zu überprüfen und zu analysieren, müssen wir einen wesentlichen Teil der Daten, die verschiedene Indikatoren und Zustände darstellen, auf der Festplatte speichern. Der wichtige Punkt hierbei ist, dass Echtzeitalgorithmen von solchen Daten unabhängig sind. In den meisten Fällen verwenden wir die gespeicherten Daten zur Offline-Analyse, zum Debuggen und zur Verfolgung bestimmter Fälle und Ergebnisse, die das System erzeugt.
Die Probleme unseres Systems
Es gibt bestimmte Probleme, die wir bis zu einem gewissen Grad gelöst haben, aber sie erfordern durchdachtere Lösungen. Im Moment möchte ich sie hier nur erwähnen, da jeder Punkt einen eigenen Artikel wert ist.
- , , .
- . , .
- IF-ELSE ML. - : «ML — ». , ML, , . , , .
- .
- (true positive) . — , . , , — . , , .
- , .
- : , () .
- Zu guter Letzt. Wir müssen eine umfassende Plattform zur Leistungsvalidierung erstellen, auf der wir unsere Modelle analysieren können. [4]