Mein Team und ich vertreten mit Partnern von Rosbank die Richtung der Geschäftsentwicklung. Heute möchten wir über die erfolgreichen Erfahrungen bei der Automatisierung eines Bankgeschäftsprozesses mit direkten Integrationen zwischen Systemen, künstlicher Intelligenz in Bezug auf Bild- und Texterkennung auf der Grundlage von GreenOCR, RF-Gesetzgebung und der Vorbereitung von Mustern für Schulungen sprechen.

Also fangen wir an. Rosbank verfügt über einen Geschäftsprozess zur Eröffnung eines Kontos für einen Kreditnehmer, der von einer Partnerbank vertreten wird. Der bestehende Prozess, der alle behördlichen und Societe Generale-Anforderungen erfüllt, bevor die Automatisierung bis zu 20 Minuten Betriebszeit pro Kunde in Anspruch nahm. Der Prozess umfasst das Empfangen von Scans von Dokumenten durch das Backoffice, das Überprüfen der Richtigkeit des Ausfüllens jedes Dokuments und das Buchen der Dokumentfelder in den Informationssystemen der Bank, eine Reihe anderer Schecks und erst ganz am Ende - die Eröffnung eines Kontos. Dies ist genau der Vorgang hinter der Schaltfläche "Konto eröffnen".
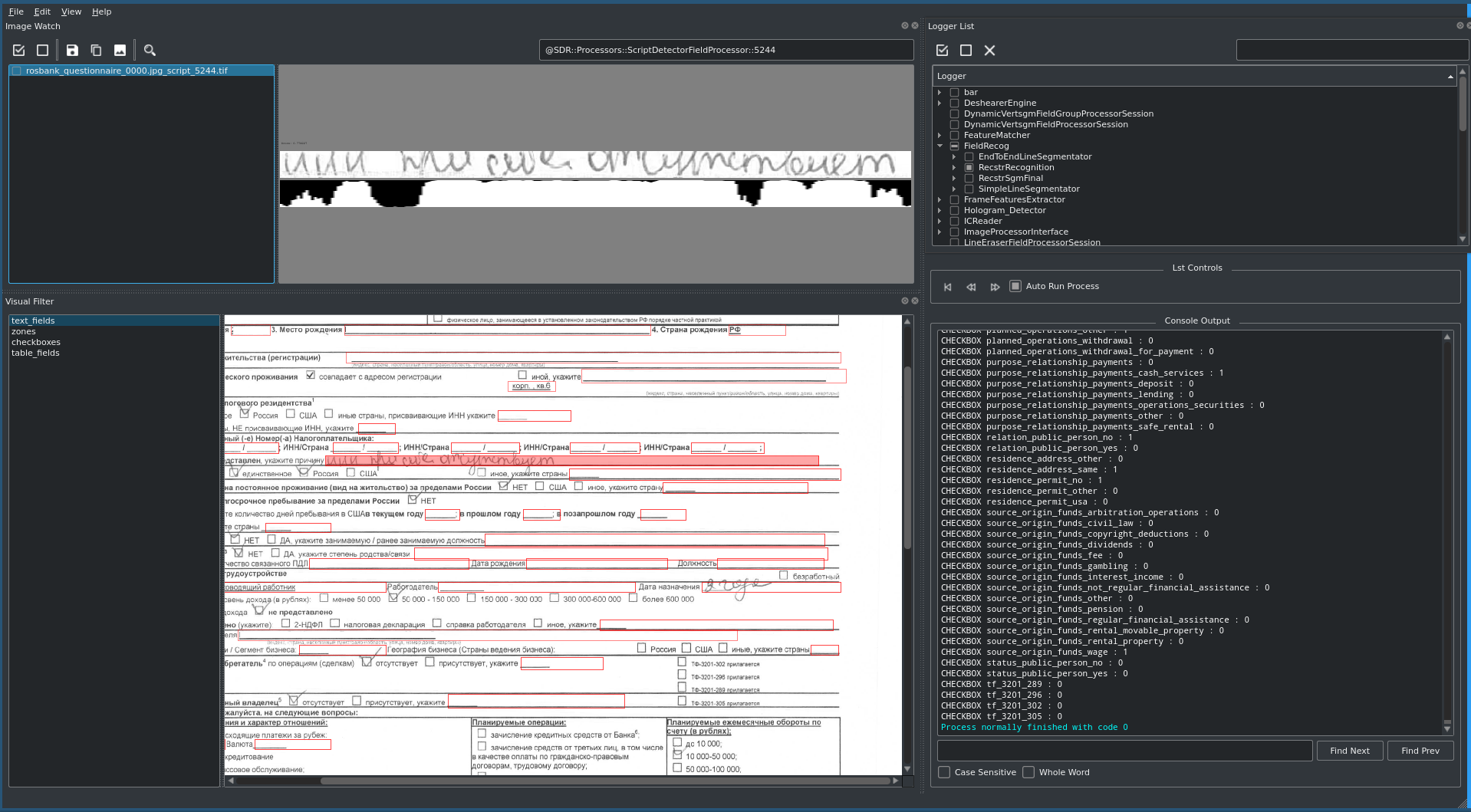
Die Hauptfelder des Dokuments - Nachname, Vorname, Patronym, Geburtsdatum des Kunden usw. - sind in fast allen Arten von eingegangenen Dokumenten enthalten und werden bei Eingabe in verschiedene Systeme der Bank dupliziert. Das komplexeste Dokument - der KYC-Fragebogen (von Know Your Customer - Know Your Customer) - ist ein druckbares A4-Format mit 8-Punkt-Schrift, das etwa 170 Textfelder und Kontrollkästchen sowie Tabellenansichten enthält.
Was sollten wir tun?
Unser Hauptziel war es, die Zeit für die Kontoeröffnung auf ein Minimum zu reduzieren.
Die Analyse des Prozesses hat gezeigt, dass es notwendig ist:
- Reduzieren Sie die Anzahl der manuellen Überprüfungen jedes Dokuments.
- Automatisieren Sie das Ausfüllen derselben Felder in verschiedenen Bankensystemen.
- Reduzieren Sie die Bewegung von Scans von Dokumenten zwischen Systemen.
Um die Probleme (1) und (2) zu lösen, wurde beschlossen, die bereits in der Bank implementierte GreenOCR-basierte Bild- und Texterkennungslösung zu verwenden (der Arbeitsname lautet "Erkenner"). Die im Geschäftsprozess verwendeten Dokumentformate sind nicht Standard, daher stand das Team vor der Aufgabe, Anforderungen für den "Erkenner" zu entwickeln und Beispiele für das Training des neuronalen Netzwerks (Beispiele) vorzubereiten.
Um die Probleme (2) und (3) zu lösen, war es notwendig, die System- und Systemintegration zu verfeinern.
Unser Team unter der Leitung von Julia Aleksashina
- Alexander Bashkov - interne Systementwicklung (.Net)
- Valentina Sayfullina - Geschäftsanalyse, Testen
- Grigory Proskurin - Integration zwischen Systemen (.Net)
- Ekaterina Panteleeva - Geschäftsanalyse, Prüfung
- Sergey Frolov - Projektmanagement, Modellqualitätsanalyse
- Teilnehmer eines externen Anbieters ( Smart Engines in Verbindung mit Philosophy.it )
Erkennertraining
Zu den im Geschäftsprozess verwendeten Kundendokumenten gehörten:
- Reisepass;
- Zustimmung - gedrucktes Formular A4, 1 Liter;
- Vollmacht - gedruckte Form A4, 2 l;
- KYC-Fragebogen - gedrucktes Formular A4, 1 Liter;
Zunächst wurden die Dokumente gründlich untersucht und Anforderungen entwickelt, die nicht nur die Arbeit des Erkenners mit dynamischen Feldern, sondern auch die Arbeit mit statischem Text, Felder mit handschriftlichen Daten, im Allgemeinen die Dokumentenerkennung entlang des Umfangs und andere Verbesserungen umfassten.
Die Passerkennung war in der Box-Funktionalität des GreenOCR-Systems enthalten und erforderte keine Änderungen.
Für den Rest der Dokumenttypen wurden als Ergebnis der Analyse die erforderlichen Attribute und Zeichen festgelegt, die der "Erkenner" zurückgeben sollte. Gleichzeitig mussten folgende Punkte berücksichtigt werden, die den Erkennungsprozess erschwerten und eine spürbare Komplikation der verwendeten Algorithmen erforderten:
- , . , «» ;
- 8- . , ;
- ( ) ;
- ;
- , , ;
- ;
Anfangs erschien uns die Aufgabe nicht allzu schwierig und sah ziemlich normal aus:
Anforderungen -> Anbieter -> Modell -> Testen des Modells -> Starten des Prozesses
Bei erfolglosen Tests wird das Modell zur wiederholten Schulung an den Anbieter zurückgesendet.
Jeden Tag erhalten wir eine große Anzahl von Scans von Dokumenten, und die Vorbereitung eines Musters für das Training des Modells sollte kein Problem gewesen sein. Die Verarbeitung personenbezogener Daten muss den Anforderungen des Bundesgesetzes "Über personenbezogene Daten" N152-FZ entsprechen. Die Zustimmung des Kunden zur Verarbeitung personenbezogener Daten des Kunden ist nur innerhalb von Rosbank verfügbar. Wir können keine Kundendokumente an den Lieferanten übertragen, um das Modell zu trainieren.
Es wurden drei Möglichkeiten zur Lösung des Problems in Betracht gezogen:
- , , , , ;
- . , – () , ;
- () . , , , , , ;
Nachdem wir die vorgeschlagenen Optionen mit dem Team hinsichtlich der Geschwindigkeit ihrer Implementierung und möglicher Risiken analysiert hatten, entschieden wir uns für die dritte Option - den Weg der Nachahmung von Dokumenten für die Schulung des Modells. Der Hauptvorteil dieses Verfahrens besteht in der Möglichkeit, einen möglichst großen Bereich von Scanvorrichtungen abzudecken, um die Anzahl der Iterationen für die Kalibrierung und Modellverfeinerung zu verringern.
Dokumentvorlagen wurden im HTML-Format implementiert. Eine Reihe von Testdaten und ein Makro wurden schnell und effizient erstellt, um Vorlagen mit synthetisierten Daten zu füllen und das Drucken zu automatisieren. Als Nächstes haben wir druckbare Formulare im PDF-Format erstellt und jeder Datei eine eindeutige Kennung zugewiesen, um die vom "Decoder" empfangenen Antworten zu überprüfen.
Das Training des neuronalen Netzes, die Markierung der Regionen und die Konfiguration der Formulare erfolgte auf Anbieterseite.
Aufgrund des begrenzten Zeitrahmens wurde das Training des Modells in zwei Phasen unterteilt.
In der ersten Phase wurde das Modell geschult, um Dokumenttypen zu erkennen und den Inhalt der Dokumente selbst "grob" zu erkennen:
Anforderungen -> Anbieter -> Testdaten vorbereiten -> Datenerfassung -> Schulung des Modells in Formularerkennung -> Formulare testen -> Modell einrichten
In der zweiten Phase Es gab eine detaillierte Schulung des Modells, um den Inhalt jeder Art von Dokumenten zu erkennen. Die Schulung und Implementierung des Modells in der zweiten Phase kann durch das folgende Schema beschrieben werden, das für alle Arten von Dokumenten gleich ist:
Vorbereiten von Testdaten in verschiedenen Auflösungen -> Sammeln und Übertragen von Daten an den Anbieter -> Trainieren des Modells -> Testen des Modells -> Kalibrieren des Modells -> Implementieren des Modells -> Überprüfen der Ergebnisse im Kampf -> Identifizieren von Problemfällen -> Simulieren von Problemfällen und Übertragen an den Anbieter -> Wiederholung der Testschritte
Es ist zu beachten, dass trotz der sehr breiten Abdeckung des Bereichs der verwendeten Scangeräte eine Reihe von Geräten in den Beispielen für das Training des Modells immer noch nicht vorgestellt wurden. Daher erfolgte die Einführung des Modells in den Kampf im Pilotmodus, und die Ergebnisse wurden nicht für die Automatisierung verwendet. Die während der Arbeit im Pilotmodus erhaltenen Daten wurden nur zur weiteren Analyse und Analyse in der Datenbank aufgezeichnet.
Testen
Da sich die Modellschulungsschleife auf der Seite des Anbieters befand und nicht mit den Systemen der Bank verbunden war, wurde das Modell nach jedem Schulungszyklus vom Anbieter an die Bank übertragen, wo es in einer Testumgebung getestet wurde. Im Falle einer erfolgreichen Verifizierung wurde das Modell in die Zertifizierungsumgebung übertragen, wo es auf Regression getestet wurde, und dann in die industrielle Umgebung, um Sonderfälle zu identifizieren, die bei der Schulung des Modells nicht berücksichtigt wurden.
Am Rand der Bank wurden Daten an das Modell übermittelt, die Ergebnisse wurden in der Datenbank aufgezeichnet. Die Datenqualitätsanalyse wurde mit dem allmächtigen Excel durchgeführt - unter Verwendung von Pivot-Tabellen, Logik mit Formeln und deren Kombinationen vlookup, hlookup, index, len, match und zeichenweiser Zeichenfolgenvergleich über die if-Funktion.
Durch Tests mit simulierten Dokumenten konnten wir die maximale Anzahl von Testszenarien ausführen und den Prozess so weit wie möglich automatisieren.
Zunächst haben wir im manuellen Modus die Rückgabe aller Felder auf Übereinstimmung mit den ursprünglichen Anforderungen für jeden Dokumenttyp überprüft. Als nächstes überprüften wir die Antworten des Modells, wenn wir Textblöcke unterschiedlicher Länge dynamisch füllten. Ziel war es, die Qualität der Antworten zu testen, wenn sich der Text von Zeile zu Zeile und von Seite zu Seite bewegt. Am Ende haben wir die Qualität der Antworten in den Feldern in Abhängigkeit von der Qualität des gescannten Dokuments überprüft. Für die Kalibrierung des Modells von höchster Qualität wurden Scans von Dokumenten mit niedriger Auflösung verwendet.
Besonderes Augenmerk sollte auf das komplexeste Dokument gelegt werden, das die meisten Felder und Kontrollkästchen enthält - den KYC-Fragebogen. Für ihn wurden im Voraus spezielle Skripte zum Ausfüllen des Dokuments erstellt und automatisierte Makros geschrieben, die es ermöglichten, den Testprozess zu beschleunigen, alle möglichen Datenkombinationen zu überprüfen und dem Anbieter umgehend eine Rückmeldung zur Kalibrierung des Modells zu geben.
Integration und interne Entwicklung
Die notwendige Überarbeitung der Systeme und der systemübergreifenden Integration der Bank wurde im Voraus durchgeführt und in den Testumgebungen der Bank angezeigt.
Das realisierte Szenario besteht aus folgenden Phasen:
- Annahme eingehender Scans von Dokumenten;
- Senden empfangener Scans an den "Erkenner". Das Senden ist im synchronen und asynchronen Modus mit bis zu 10 Threads möglich.
- Empfangen einer Antwort vom "Erkenner", Überprüfen und Validieren der empfangenen Daten;
- Speichern des Originalscans des Dokuments in der elektronischen Bibliothek der Bank;
- Einleitung in die Bankensysteme zur Verarbeitung der vom "Erkenner" erhaltenen Daten und anschließende Überprüfung durch den Mitarbeiter;
Ergebnis
Im Moment ist die Schulung des Modells abgeschlossen, es wurden erfolgreiche Tests und Implementierungen des Geschäftsprozesses in der Produktionsumgebung der Bank durchgeführt. Durch die durchgeführte Automatisierung konnte die durchschnittliche Zeit für die Kontoeröffnung von 20 Minuten auf 5 Minuten reduziert werden. Die mühsame Phase des Geschäftsprozesses für die Erkennung und Eingabe von Dokumentdaten, die zuvor manuell durchgeführt wurde, wurde automatisiert. Gleichzeitig wird die Wahrscheinlichkeit von Fehlern, die durch den menschlichen Faktor verursacht werden, stark verringert. Darüber hinaus ist die Identität der Daten aus demselben Dokument in verschiedenen Systemen der Bank gewährleistet.