Maschinelles Lernen. Neuronale Netze (Teil 1): Der Lernprozess des Perzeptrons
In diesem Artikel werden wir ein neuronales Netz verwenden, um die Ausführung logischer ODER-Operationen zu modellieren. XOR, eine Art "Hello World" -Anwendung für neuronale Netze.
Der Artikel beschreibt Schritt für Schritt den Prozess einer solchen Modellierung mit TensorFlow.js.
Bauen wir also ein neuronales Netzwerk für die logische ODER-Verknüpfung auf. Am Eingang senden wir immer zwei Signale X 1 und X 2 und am Ausgang ein Ausgangssignal Y. Um das neuronale Netzwerk zu trainieren, benötigen wir auch einen Trainingsdatensatz (Abbildung 1).

Abbildung 1 - Ein Trainingsdatensatz und ein Modell zur Modellierung einer logischen ODER-Operation
Um zu verstehen, welche Struktur eines neuronalen Netzwerks festgelegt werden soll, stellen wir uns einen Trainingsdatensatz auf einer Koordinatenebene mit den Achsen X 1 und X 2 vor (Abbildung 2, links).
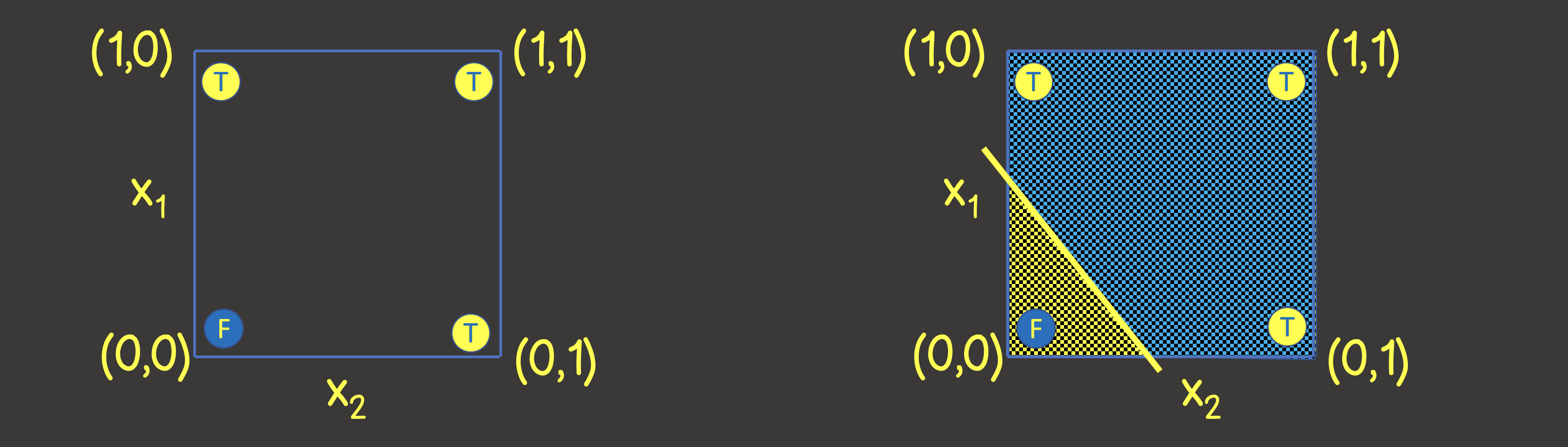
Abbildung 2 - Trainingssatz auf der Koordinatenebene für die logische ODER-Verknüpfung
Bitte beachten Sie, dass es zur Lösung dieses Problems ausreicht, eine Linie zu zeichnen, die die Ebene so teilt, dass auf einer Seite der Linie alle TRUE- Werte und auf der anderen Seite alle FALSE- Werte vorhanden sind (Abbildung 2, rechts). Wir wissen auch, dass ein Neuron in einem neuronalen Netzwerk (Perzeptron) diesen Zweck perfekt erfüllen kann, dessen Ausgangswert aus den Eingangssignalen berechnet wird als:
Das ist eine mathematische Darstellung der Gleichung der Linie
Angesichts der Tatsache, dass unsere Werte im Bereich von 0 bis 1 liegen, wenden wir auch die Sigmoid-Aktivierungsfunktion an. Daher sieht unser neuronales Netzwerk wie in Abbildung 3 aus.

Abbildung 3 - Neuronales Netzwerk zum Trainieren der logischen ODER-Verknüpfung
Lösen wir dieses Problem mit TensorFlow.js.
Zuerst müssen wir den Trainingsdatensatz in Tensoren konvertieren. Ein Tensor ist ein Datencontainer, der haben kannAchsen und eine beliebige Anzahl von Elementen entlang jeder der Achsen. Die meisten Tensoren kennen sich mit Mathematik aus - Vektoren (Tensor mit einer Achse), Matrizen (Tensor mit zwei Achsen - Zeilen, Spalten).
Um den Trainingsdatensatz zu definieren, ist die erste Achse (Achse 0) immer die Achse, entlang der sich alle verfügbaren Datenbeispielinstanzen befinden (Abbildung 4).
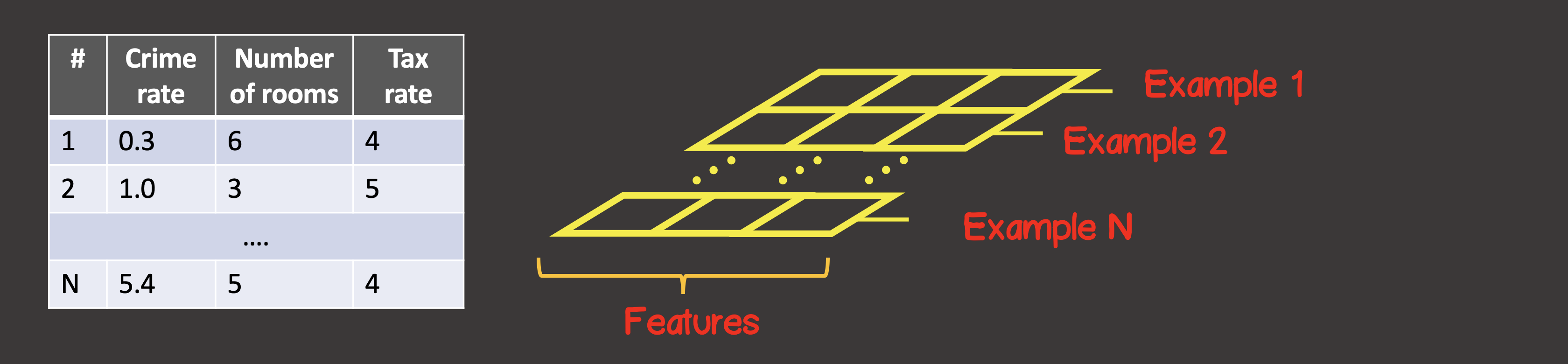
Abbildung 4 - Tensorstruktur
In unserem speziellen Fall haben wir 4 Instanzen von Datenproben (Abbildung 1), was bedeutet, dass der Eingangstensor entlang der ersten Achse 4 Elemente hat. Jedes Element der Trainingsprobe ist ein Vektor, der aus zwei Elementen X 1 , X 2 besteht . Somit hat der Eingangstensor 2 Achsen (Matrix), entlang der ersten Achse gibt es 4 Elemente, entlang der zweiten Achse - 2 Elemente.
const input = [[0, 0], [1, 0], [0, 1], [1, 1]];
const inputTensor = tf.tensor(input, [input.length, 2]);
Konvertieren Sie den Ausgang ebenfalls in einen Tensor. Was die Eingangssignale betrifft, so haben wir entlang der ersten Achse 4 Elemente, und jedes Element enthält einen Vektor, der einen Wert enthält:
const output = [[0], [1], [1], [1]]
const outputTensor = tf.tensor(output, [output.length, 1]);
Erstellen wir ein Modell mit der TensorFlow-API:
const model = tf.sequential();
model.add(
tf.layers.dense({ inputShape: [2], units: 1, activation: 'sigmoid' })
);
Die Modellerstellung beginnt immer mit einem Aufruf von tf.sequential () . Der Hauptbaustein eines Modells sind Ebenen. Wir können so viele Schichten im neuronalen Netzwerk mit dem Modell verbinden, wie wir benötigen. Hier verwenden wir eine dichte Schicht, was bedeutet, dass jedes Neuron in der nächsten Schicht eine Verbindung mit jedem Neuron in der vorherigen Schicht hat. Zum Beispiel, wenn wir zwei dichte Schichten in der ersten Schicht haben Neuronen, und in der zweiten - Dann beträgt die Gesamtzahl der Verbindungen zwischen den Schichten ...
In unserem Fall besteht das neuronale Netzwerk, wie wir sehen können, aus einer Schicht, in der sich ein Neuron befindet, daher werden Einheiten auf eins gesetzt.
Außerdem müssen wir für die erste Schicht des neuronalen Netzwerks die Eingabiform festlegen , da jede Eingabeinstanz durch einen Vektor mit zwei Werten X 1 und X 2 dargestellt wird. Daher ist inputShape = [2] . Beachten Sie, dass inputShape für Zwischenebenen nicht festgelegt werden muss. TensorFlow kann diesen Wert aus dem Einheitenwert der vorherigen Ebene ermitteln.
Falls erforderlich, kann jeder Schicht auch eine Aktivierungsfunktion zugewiesen werden. Wir haben oben festgestellt, dass dies eine Sigmoidfunktion ist. Die aktuell verfügbaren Aktivierungsfunktionen in TensorFlow finden Sie hier .
Als nächstes müssen wir das Modell kompilieren (siehe API hier ), während wir zwei erforderliche Parameter festlegen müssen - dies ist die Fehlerfunktion und die Art von Optimierer, die nach dem Minimum sucht:
model.compile({
optimizer: tf.train.sgd(0.1),
loss: 'meanSquaredError'
});
Wir haben den stochastischen Gradientenabstieg als Optimierer mit einem Trainingsschritt von 0,1 festgelegt.
Die Liste der in der Bibliothek implementierten Optimierer: tf.train.sgd , tf.train.momentum , tf.train.adagrad , tf.train.adadelta , tf.train.adam , tf.train.adamax , tf.train.rmsprop .
In der Praxis können Sie standardmäßig sofort den Adam- Optimierer auswählen , der im Gegensatz zu sgd die besten Modellkonvergenzraten aufweist. Die Lernrate in jeder Trainingsphase wird abhängig von der Historie der vorherigen Schritte festgelegt und ist während des gesamten Lernprozesses nicht konstant.
Als Fehlerfunktion wird sie durch die quadratische mittlere Fehlerfunktion angegeben:
Das Modell wird festgelegt, und der nächste Schritt ist das Trainieren des Modells. Dazu muss die Anpassungsmethode für das Modell aufgerufen werden :
async function initModel() {
// skip for brevity
await model.fit(trainingInputTensor, trainingOutputTensor, {
epochs: 1000,
shuffle: true,
callbacks: {
onEpochEnd: async (epoch, { loss }) => {
// any actions on during any epoch of training
await tf.nextFrame();
}
}
})
}
Wir haben festgelegt, dass der Lernprozess aus 100 Lernschritten bestehen soll (Anzahl der Lernepochen). Auch in jeder aufeinanderfolgenden Epoche - die Eingabedaten sollten in zufälliger Reihenfolge gemischt werden ( shuffle = true ) - wird der Prozess der Modellkonvergenz beschleunigt, da unser Trainingsdatensatz nur wenige Fälle enthält (4).
Nach Abschluss des Trainingsprozesses können wir die Vorhersagemethode verwenden, die den Ausgabewert basierend auf neuen Eingangssignalen berechnet.
const testInput = generateInputs(10);
const testInputTensor = tf.tensor(testInput, [testInput.length, 2]);
const output = model.predict(testInputTensor).arraySync();
Die Methode generateInputs generiert einfach einen 10x10-Beispieldatensatz, der die Koordinatenebene in 100 Quadrate unterteilt:
Den vollständigen Code finden Sie hier
import React, { useEffect, useState } from 'react';
import LossPlot from './components/LossPlot';
import Canvas from './components/Canvas';
import * as tf from "@tensorflow/tfjs";
let model;
export default () => {
const [data, changeData] = useState([]);
const [lossHistory, changeLossHistory] = useState([]);
useEffect(() => {
async function initModel() {
const input = [[0, 0], [1, 0], [0, 1], [1, 1]];
const inputTensor = tf.tensor(input, [input.length, 2]);
const output = [[0], [1], [1], [1]]
const outputTensor = tf.tensor(output, [output.length, 1]);
const testInput = generateInputs(10);
const testInputTensor = tf.tensor(testInput, [testInput.length, 2]);
model = tf.sequential();
model.add(
tf.layers.dense({ inputShape:[2], units:1, activation: 'sigmoid'})
);
model.compile({
optimizer: tf.train.adam(0.1),
loss: 'meanSquaredError'
});
await model.fit(inputTensor, outputTensor, {
epochs: 100,
shuffle: true,
callbacks: {
onEpochEnd: async (epoch, { loss }) => {
changeLossHistory((prevHistory) => [...prevHistory, {
epoch,
loss
}]);
const output = model.predict(testInputTensor)
.arraySync();
changeData(() => output.map(([out], i) => ({
out,
x1: testInput[i][0],
x2: testInput[i][1]
})));
await tf.nextFrame();
}
}
})
}
initModel();
}, []);
return (
<div>
<Canvas data={data} squareAmount={10}/>
<LossPlot loss={lossHistory}/>
</div>
);
}
function generateInputs(squareAmount) {
const step = 1 / squareAmount;
const input = [];
for (let i = 0; i < 1; i += step) {
for (let j = 0; j < 1; j += step) {
input.push([i, j]);
}
}
return input;
}
In der folgenden Abbildung sehen Sie einen Teil des Lernprozesses:

Planker-Implementierung:
Simulation der logischen Operation XOR Der
Trainingssatz für diese Funktion ist in Abbildung 6 dargestellt. Wir werden diese Punkte auch wie für die logische Operation ODER auf der Koordinatenebene anordnen.
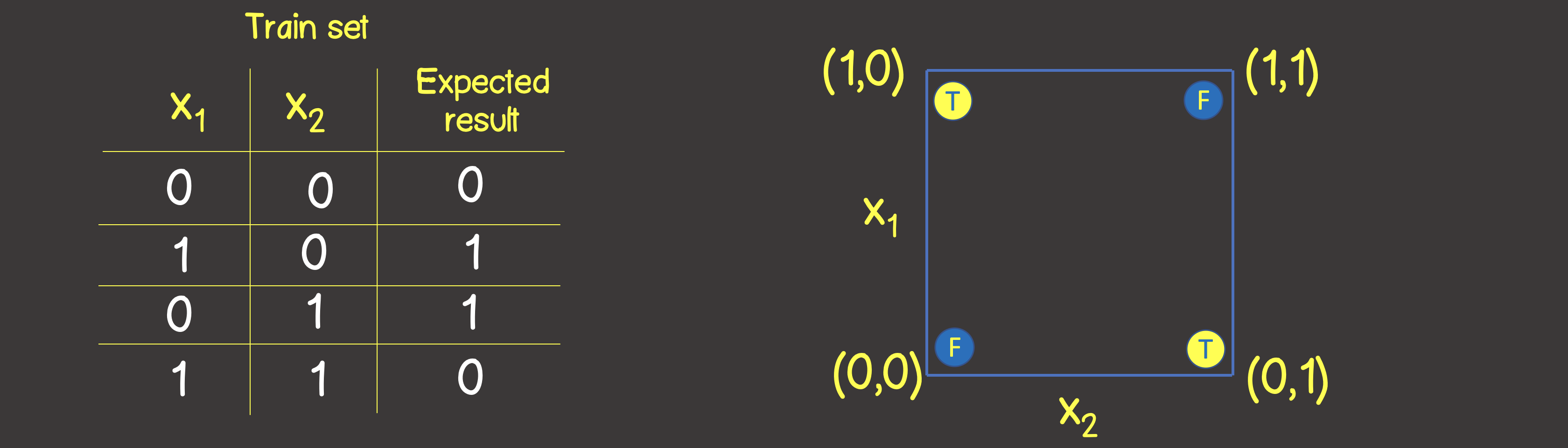
Abbildung 6 - Trainingsdatensatz und Modell zur Modellierung der logischen Operation EXKLUSIV ODER (XOR)
Bitte beachten Sie dies Im Gegensatz zur logischen ODER-Verknüpfung können Sie die Ebene nicht durch eine gerade Linie teilen, sodass auf der einen Seite alle TRUE- Werte und auf der anderen Seite alle FALSE vorhanden sind . Wir können dies jedoch mit zwei Kurven tun (Abbildung 7).
In diesem Fall reicht natürlich ein Neuron in einer Schicht nicht aus - es wird mindestens eine weitere Schicht mit zwei Neuronen benötigt, von denen jede eine der beiden Linien in der Ebene definieren würde.
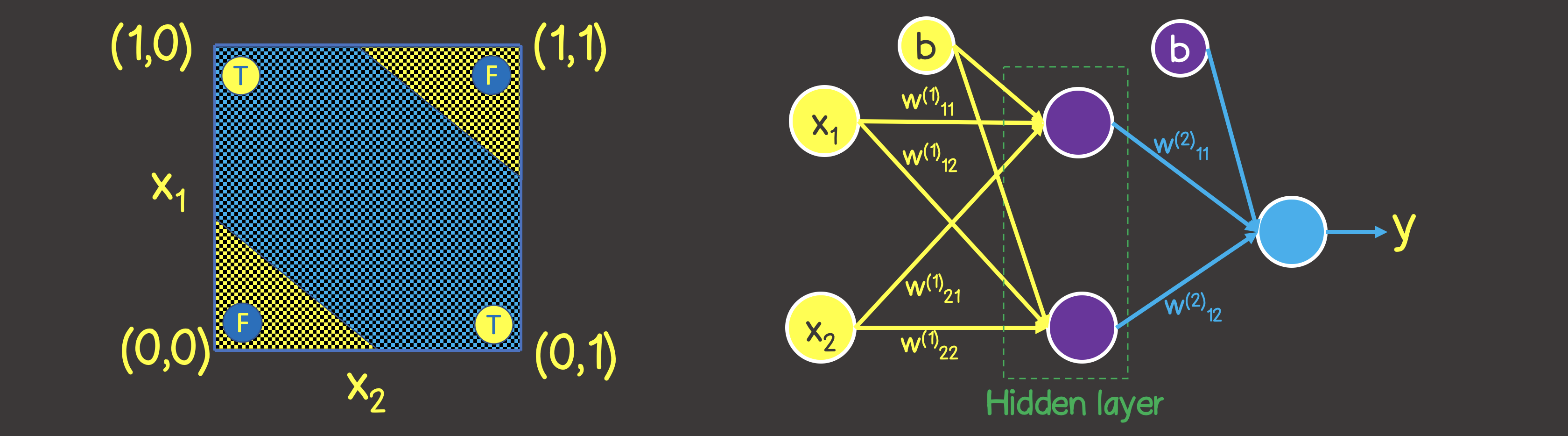
Abbildung 7 - Neuronales Netzwerkmodell für die logische Operation EXKLUSIV ODER (XOR)
Im vorherigen Code müssen wir an mehreren Stellen Änderungen vornehmen, von denen eine der Trainingsdatensatz selbst ist:
const input = [[0, 0], [1, 0], [0, 1], [1, 1]];
const inputTensor = tf.tensor(input, [input.length, 2]);
const output = [[0], [1], [1], [0]]
const outputTensor = tf.tensor(output, [output.length, 1]);
Der zweite Platz ist die geänderte Struktur des Modells gemäß Abbildung 7:
model = tf.sequential();
model.add(
tf.layers.dense({ inputShape: [2], units: 2, activation: 'sigmoid' })
);
model.add(
tf.layers.dense({ units: 1, activation: 'sigmoid' })
);
Der Lernprozess in diesem Fall sieht folgendermaßen aus:

Planker-Implementierung:
Thema des nächsten Artikels
Im nächsten Artikel beschreiben wir anhand einer Liste einiger Zeichen, wie Probleme im Zusammenhang mit der Klassifizierung von Objekten in Kategorien gelöst werden können.