
Der Zweck dieses Artikels ist es, unsere ersten Erfahrungen mit MLflow zu teilen .
Wir werden unsere Überprüfung von MLflow von seinem Tracking-Server aus starten und alle Iterationen der Studie fortsetzen. Dann werden wir unsere Erfahrungen mit der Verbindung von Spark mit MLflow über UDF teilen.
Kontext
Bei Alpha Health setzen wir maschinelles Lernen und künstliche Intelligenz ein, um Menschen zu befähigen, sich um ihre Gesundheit und ihr Wohlbefinden zu kümmern. Aus diesem Grund stehen Modelle für maschinelles Lernen im Mittelpunkt der von uns entwickelten Datenprodukte. Deshalb wurde unsere Aufmerksamkeit auf MLflow gelenkt, eine Open-Source-Plattform, die alle Aspekte des Lebenszyklus von maschinellem Lernen abdeckt.
MLflow
Das Hauptziel von MLflow ist es, zusätzlich zum maschinellen Lernen eine zusätzliche Ebene bereitzustellen, die es Datenwissenschaftlern ermöglicht, mit nahezu jeder maschinellen Lernbibliothek ( Wasser , Keras , mleap , pytorch , sklearn und tensorflow ) zu arbeiten und ihre Arbeit auf die nächste Ebene zu heben.
MLflow bietet drei Komponenten:
- Tracking - Aufzeichnung und Abfrage von Experimenten: Code, Daten, Konfiguration und Ergebnisse. Es ist sehr wichtig, den Prozess der Erstellung des Modells zu verfolgen.
- Projekte - Paketformat zur Ausführung auf jeder Plattform (z. B. SageMaker )
- Modelle ist ein gängiges Format zum Senden von Modellen an verschiedene Bereitstellungstools.
MLflow (Alpha zum Zeitpunkt dieses Schreibens) ist eine Open-Source-Plattform, mit der Sie den Lebenszyklus des maschinellen Lernens verwalten können, einschließlich Experimentieren, Wiederverwenden und Bereitstellen.
MLflow konfigurieren
Um MLflow verwenden zu können, müssen Sie zuerst die gesamte Python-Umgebung einrichten. Dazu verwenden wir PyEnv (um Python auf einem Mac zu installieren, schauen Sie hier ). So können wir eine virtuelle Umgebung erstellen, in der wir alle für die Ausführung erforderlichen Bibliotheken installieren.
```
pyenv install 3.7.0
pyenv global 3.7.0 # Use Python 3.7
mkvirtualenv mlflow # Create a Virtual Env with Python 3.7
workon mlflow
```Installieren Sie die erforderlichen Bibliotheken.
```
pip install mlflow==0.7.0 \
Cython==0.29 \
numpy==1.14.5 \
pandas==0.23.4 \
pyarrow==0.11.0
```Hinweis: Wir verwenden PyArrow, um Modelle wie UDFs auszuführen. Die Versionen PyArrow und Numpy mussten behoben werden, da die neuesten Versionen in Konflikt standen.
Starten Sie die Tracking-Benutzeroberfläche
Mit MLflow Tracking können wir Experimente mit Python und der REST- API protokollieren und Anfragen zu Experimenten stellen . Darüber hinaus können Sie festlegen, wo Modellartefakte gespeichert werden sollen (localhost, Amazon S3 , Azure Blob-Speicher , Google Cloud Storage oder SFTP-Server ). Da wir AWS bei Alpha Health verwenden, wird S3 als Speicher für die Artefakte verwendet.
# Running a Tracking Server
mlflow server \
--file-store /tmp/mlflow/fileStore \
--default-artifact-root s3://<bucket>/mlflow/artifacts/ \
--host localhost
--port 5000MLflow empfiehlt die Verwendung eines dauerhaften Dateispeichers. In der Dateispeicherung speichert der Server Lauf- und Experimentiermetadaten. Stellen Sie beim Starten des Servers sicher, dass er auf dauerhaften Dateispeicher verweist. Hier verwenden wir es nur zum Experimentieren
/tmp.
Denken Sie daran, dass, wenn wir den mlflow-Server zum Ausführen alter Experimente verwenden möchten, diese im Dateispeicher vorhanden sein müssen. Aber auch ohne dies könnten wir sie in der UDF verwenden, da wir nur den Pfad zum Modell benötigen.
Hinweis: Beachten Sie, dass die Tracking-Benutzeroberfläche und der Modellclient Zugriff auf den Speicherort des Artefakts haben müssen. Das heißt, unabhängig von der Tatsache, dass sich die Tracking-Benutzeroberfläche in der EC2-Instanz befindet, muss der Computer beim lokalen Start von MLflow direkten Zugriff auf S3 haben, um Artefaktmodelle zu schreiben.
Die Tracking-Benutzeroberfläche speichert Artefakte in einem S3-Bucket
Laufende Modelle
Sobald der Tracking Server ausgeführt wird, können Sie mit dem Training der Modelle beginnen.
Als Beispiel verwenden wir die Weinmodifikation aus dem MLflow-Beispiel in Sklearn .
MLFLOW_TRACKING_URI=http://localhost:5000 python wine_quality.py \
--alpha 0.9
--l1_ration 0.5
--wine_file ./data/winequality-red.csvWie bereits erwähnt, können Sie mit MLflow Parameter, Metriken und Artefakte von Modellen protokollieren, um zu verfolgen, wie sie sich während der Iteration entwickeln. Diese Funktion ist äußerst nützlich, da wir auf diese Weise das beste Modell reproduzieren können, indem wir den Tracking-Server kontaktieren oder anhand der Git-Hash-Commit-Protokolle verstehen, welcher Code die erforderliche Iteration durchgeführt hat.
with mlflow.start_run():
... model ...
mlflow.log_param("source", wine_path)
mlflow.log_param("alpha", alpha)
mlflow.log_param("l1_ratio", l1_ratio)
mlflow.log_metric("rmse", rmse)
mlflow.log_metric("r2", r2)
mlflow.log_metric("mae", mae)
mlflow.set_tag('domain', 'wine')
mlflow.set_tag('predict', 'quality')
mlflow.sklearn.log_model(lr, "model")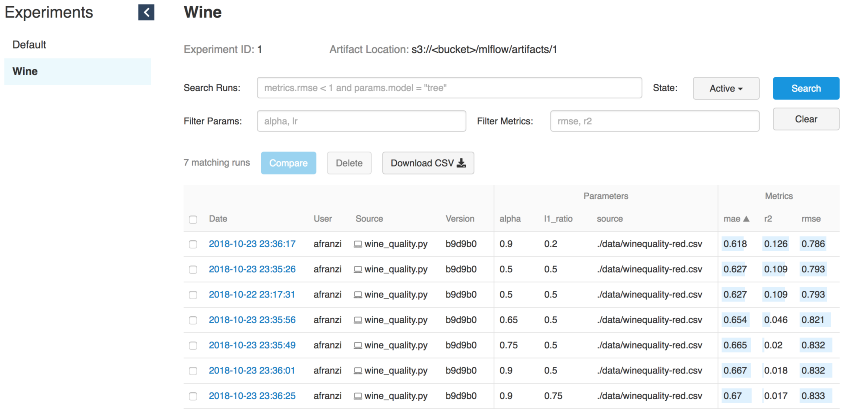
Weiniterationen
Serverteil für das Modell
Der mit dem Befehl „mlflow server“ gestartete MLflow-Tracking-Server verfügt über eine REST-API zum Verfolgen von Starts und zum Schreiben von Daten in das lokale Dateisystem. Sie können die Adresse des Tracking-Servers mithilfe der Umgebungsvariablen "MLFLOW_TRACKING_URI" angeben. Die MLflow-Tracking-API kontaktiert den Tracking-Server unter dieser Adresse automatisch, um Startinformationen, Protokollmetriken usw. zu erstellen / abzurufen.Um das Modell mit einem Server auszustatten, benötigen wir einen laufenden Tracking-Server (siehe Startschnittstelle) und eine Run-ID des Modells.
Quelle: Docs // Ausführen eines Tracking-Servers

ID ausführen
# Serve a sklearn model through 127.0.0.0:5005
MLFLOW_TRACKING_URI=http://0.0.0.0:5000 mlflow sklearn serve \
--port 5005 \
--run_id 0f8691808e914d1087cf097a08730f17 \
--model-path modelUm Modelle mit der MLflow-Serve-Funktion zu bedienen, benötigen wir Zugriff auf die Tracking-Benutzeroberfläche, um Informationen über das Modell durch einfaches Angeben zu erhalten
--run_id.
Sobald das Modell mit dem Tracking-Server kommuniziert, können wir den neuen Modellendpunkt abrufen.
# Query Tracking Server Endpoint
curl -X POST \
http://127.0.0.1:5005/invocations \
-H 'Content-Type: application/json' \
-d '[
{
"fixed acidity": 3.42,
"volatile acidity": 1.66,
"citric acid": 0.48,
"residual sugar": 4.2,
"chloridessssss": 0.229,
"free sulfur dsioxide": 19,
"total sulfur dioxide": 25,
"density": 1.98,
"pH": 5.33,
"sulphates": 4.39,
"alcohol": 10.8
}
]'
> {"predictions": [5.825055635303461]}Laufende Modelle von Spark
Trotz der Tatsache, dass der Tracking-Server leistungsfähig genug ist, um Modelle in Echtzeit zu bedienen, sie zu trainieren und die Serving- Funktionalität (Quelle: mlflow // docs // models # local ) zu verwenden, ist die Verwendung von Spark (Batch oder Streaming) eine noch leistungsfähigere Lösung für Verteilungskonto.
Stellen Sie sich vor, Sie haben gerade ein Offline-Training durchgeführt und dann das Ausgabemodell auf alle Ihre Daten angewendet. Hier zeigen Spark und MLflow ihr Bestes.
Installieren Sie PySpark + Jupyter + Spark
Quelle: Erste Schritte PySpark - Jupyter
Um zu zeigen, wie wir MLflow-Modelle auf Spark-Datenrahmen anwenden, müssen wir Jupyter-Notebooks für die Zusammenarbeit mit PySpark einrichten.
Beginnen Sie mit der Installation der neuesten stabilen Version von Apache Spark :
cd ~/Downloads/
tar -xzf spark-2.4.3-bin-hadoop2.7.tgz
mv ~/Downloads/spark-2.4.3-bin-hadoop2.7 ~/
ln -s ~/spark-2.4.3-bin-hadoop2.7 ~/spark̀Installieren Sie PySpark und Jupyter in einer virtuellen Umgebung:
pip install pyspark jupyterUmgebungsvariablen einrichten:
export SPARK_HOME=~/spark
export PATH=$SPARK_HOME/bin:$PATH
export PYSPARK_DRIVER_PYTHON=jupyter
export PYSPARK_DRIVER_PYTHON_OPTS="notebook --notebook-dir=${HOME}/Projects/notebooks"Sobald dies festgelegt ist
notebook-dir, können wir unsere Notizbücher im gewünschten Ordner speichern.
Start von Jupyter aus PySpark
Da wir Jupiter als PySpark-Treiber einrichten konnten, können wir jetzt Jupyter-Notebooks im PySpark-Kontext ausführen.
(mlflow) afranzi:~$ pyspark
[I 19:05:01.572 NotebookApp] sparkmagic extension enabled!
[I 19:05:01.573 NotebookApp] Serving notebooks from local directory: /Users/afranzi/Projects/notebooks
[I 19:05:01.573 NotebookApp] The Jupyter Notebook is running at:
[I 19:05:01.573 NotebookApp] http://localhost:8888/?token=c06252daa6a12cfdd33c1d2e96c8d3b19d90e9f6fc171745
[I 19:05:01.573 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 19:05:01.574 NotebookApp]
Copy/paste this URL into your browser when you connect for the first time,
to login with a token:
http://localhost:8888/?token=c06252daa6a12cfdd33c1d2e96c8d3b19d90e9f6fc171745
Wie oben erwähnt, bietet MLflow eine Funktion zum Protokollieren von Modellartefakten in S3. Sobald wir das ausgewählte Modell in unseren Händen haben, haben wir die Möglichkeit, es mit dem Modul als UDF zu importieren
mlflow.pyfunc.
import mlflow.pyfunc
model_path = 's3://<bucket>/mlflow/artifacts/1/0f8691808e914d1087cf097a08730f17/artifacts/model'
wine_path = '/Users/afranzi/Projects/data/winequality-red.csv'
wine_udf = mlflow.pyfunc.spark_udf(spark, model_path)
df = spark.read.format("csv").option("header", "true").option('delimiter', ';').load(wine_path)
columns = [ "fixed acidity", "volatile acidity", "citric acid",
"residual sugar", "chlorides", "free sulfur dioxide",
"total sulfur dioxide", "density", "pH",
"sulphates", "alcohol"
]
df.withColumn('prediction', wine_udf(*columns)).show(100, False)
PySpark - Ausgabe von Weinqualitätsvorhersagen
Bis zu diesem Punkt haben wir darüber gesprochen, wie PySpark mit MLflow verwendet wird, indem Weinqualitätsvorhersagen für den gesamten Weindatensatz ausgeführt werden. Was aber, wenn Sie Python MLflow-Module von Scala Spark verwenden müssen?
Wir haben dies auch getestet, indem wir den Spark-Kontext zwischen Scala und Python aufgeteilt haben. Das heißt, wir haben MLflow UDF in Python registriert und von Scala verwendet (ja, vielleicht nicht die beste Lösung, aber was wir haben).
Scala Spark + MLflow
In diesem Beispiel fügen wir den Toree-Kernel zum vorhandenen Jupiter hinzu.
Installieren Sie Spark + Toree + Jupyter
pip install toree
jupyter toree install --spark_home=${SPARK_HOME} --sys-prefix
jupyter kernelspec list
```
```
Available kernels:
apache_toree_scala /Users/afranzi/.virtualenvs/mlflow/share/jupyter/kernels/apache_toree_scala
python3 /Users/afranzi/.virtualenvs/mlflow/share/jupyter/kernels/python3
```Wie Sie dem beigefügten Notizbuch entnehmen können, wird UDF von Spark und PySpark gemeinsam genutzt. Wir hoffen, dass dieser Teil für diejenigen hilfreich ist, die Scala lieben und Modelle für maschinelles Lernen in der Produktion einsetzen möchten.
import org.apache.spark.sql.functions.col
import org.apache.spark.sql.types.StructType
import org.apache.spark.sql.{Column, DataFrame}
import scala.util.matching.Regex
val FirstAtRe: Regex = "^_".r
val AliasRe: Regex = "[\\s_.:@]+".r
def getFieldAlias(field_name: String): String = {
FirstAtRe.replaceAllIn(AliasRe.replaceAllIn(field_name, "_"), "")
}
def selectFieldsNormalized(columns: List[String])(df: DataFrame): DataFrame = {
val fieldsToSelect: List[Column] = columns.map(field =>
col(field).as(getFieldAlias(field))
)
df.select(fieldsToSelect: _*)
}
def normalizeSchema(df: DataFrame): DataFrame = {
val schema = df.columns.toList
df.transform(selectFieldsNormalized(schema))
}
FirstAtRe = ^_
AliasRe = [\s_.:@]+
getFieldAlias: (field_name: String)String
selectFieldsNormalized: (columns: List[String])(df: org.apache.spark.sql.DataFrame)org.apache.spark.sql.DataFrame
normalizeSchema: (df: org.apache.spark.sql.DataFrame)org.apache.spark.sql.DataFrame
Out[1]:
[\s_.:@]+
In [2]:
val winePath = "~/Research/mlflow-workshop/examples/wine_quality/data/winequality-red.csv"
val modelPath = "/tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model"
winePath = ~/Research/mlflow-workshop/examples/wine_quality/data/winequality-red.csv
modelPath = /tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model
Out[2]:
/tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model
In [3]:
val df = spark.read
.format("csv")
.option("header", "true")
.option("delimiter", ";")
.load(winePath)
.transform(normalizeSchema)
df = [fixed_acidity: string, volatile_acidity: string ... 10 more fields]
Out[3]:
[fixed_acidity: string, volatile_acidity: string ... 10 more fields]
In [4]:
%%PySpark
import mlflow
from mlflow import pyfunc
model_path = "/tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model"
wine_quality_udf = mlflow.pyfunc.spark_udf(spark, model_path)
spark.udf.register("wineQuality", wine_quality_udf)
Out[4]:
<function spark_udf.<locals>.predict at 0x1116a98c8>
In [6]:
df.createOrReplaceTempView("wines")
In [10]:
%%SQL
SELECT
quality,
wineQuality(
fixed_acidity,
volatile_acidity,
citric_acid,
residual_sugar,
chlorides,
free_sulfur_dioxide,
total_sulfur_dioxide,
density,
pH,
sulphates,
alcohol
) AS prediction
FROM wines
LIMIT 10
Out[10]:
+-------+------------------+
|quality| prediction|
+-------+------------------+
| 5| 5.576883967129615|
| 5| 5.50664776916154|
| 5| 5.525504822954496|
| 6| 5.504311247097457|
| 5| 5.576883967129615|
| 5|5.5556903912725755|
| 5| 5.467882654744997|
| 7| 5.710602976324739|
| 7| 5.657319539336507|
| 5| 5.345098606538708|
+-------+------------------+
In [17]:
spark.catalog.listFunctions.filter('name like "%wineQuality%").show(20, false)
+-----------+--------+-----------+---------+-----------+
|name |database|description|className|isTemporary|
+-----------+--------+-----------+---------+-----------+
|wineQuality|null |null |null |true |
+-----------+--------+-----------+---------+-----------+
Nächste Schritte
Obwohl MLflow zum Zeitpunkt des Schreibens in Alpha war, sieht es ziemlich vielversprechend aus. Die bloße Fähigkeit, mehrere Frameworks für maschinelles Lernen auszuführen und von einem einzigen Endpunkt aus zu verwenden, bringt Empfehlungssysteme auf die nächste Ebene.
Darüber hinaus bringt MLflow Data Engineers und Data Scientists näher zusammen, indem eine gemeinsame Ebene zwischen ihnen erstellt wird.
Nach diesen Untersuchungen zu MLflow sind wir zuversichtlich, dass wir sie für unsere Spark-Pipelines und Empfehlungssysteme verwenden werden.
Es wäre schön, den Dateispeicher mit der Datenbank anstelle des Dateisystems zu synchronisieren. Auf diese Weise müssen mehrere Endpunkte abgerufen werden, die denselben Dateispeicher verwenden können. Verwenden Sie beispielsweise mehrere Instanzen von Prestound Athena mit dem gleichen Leim-Metastore.
Zusammenfassend möchte ich der MLFlow-Community dafür danken, dass sie unsere Arbeit mit Daten interessanter gemacht hat.
Wenn Sie mit MLflow spielen, können Sie uns gerne schreiben und uns mitteilen, wie Sie es verwenden, und noch mehr, wenn Sie es in der Produktion verwenden.
Erfahren Sie mehr über Kurse:
Maschinelles Lernen. Grundkurs für
maschinelles Lernen. Fortgeschrittener Kurs
Weiterlesen: