Aber all diese Lösungen hatten nicht das, was ich brauchte:
- Zentralisierte Installation
- Suchergebnisse unter Berücksichtigung der Zugriffsrechte
- Suche nach Dokumentinhalten
- Morphologie
Und ich beschloss, meine eigenen zu machen.
Ich werde Punkt für Punkt offenlegen, was ich in der Form habe, um Unterschiede in der Interpretation und Missverständnisse zu vermeiden.
Zentralisierte Installation - Client-Server-Ausführung. Alle oben genannten Lösungen haben ein grundlegendes Problem: Jeder Benutzer erstellt seinen eigenen lokalen Suchindex, der bei großen Speichervolumina die Indizierung verzögert, das Benutzerprofil auf dem Computer vergrößert und im Allgemeinen unpraktisch ist, wenn ein neuer Mitarbeiter ankommt oder auf einen neuen Computer wechselt.
Suchergebnisse unter Berücksichtigung der Rechte - hier ist alles einfach - müssen die Ergebnisse den Rechten des Mitarbeiters an der Dateiressource entsprechen. Andernfalls stellt sich heraus, dass der Mitarbeiter auch dann, wenn er keine Rechte an der Ressource hat, alles aus dem Suchcache lesen kann. Es wird sich als unangenehm herausstellen, stimme zu? Suche nach dem Inhalt des Dokuments - Suche nach dem Text des Dokuments, alles ist offensichtlich, scheint mir, und es kann keine Unstimmigkeiten geben.
Die Morphologie ist noch einfacher. In der Abfrage "Messer" angegeben und erhielt sowohl "Messer" als auch "Messer", "Messer" und "Messer". Es ist wünschenswert, dass dies für Russisch und Englisch funktioniert.
Wir haben uns für die Formulierung des Problems entschieden, wir können mit der Implementierung fortfahren.
Als Suchmaschine habe ich mich für das Sphinx-System entschieden. Die Entwicklungssprache für die Benutzeroberfläche war C # und .net. Daher wurde das Projekt nach einem französischen Detektiv Vidocq (Vidocq) genannt. Nun, es findet alles und das war's.
Architektonisch sieht die Anwendung folgendermaßen aus: Der
Suchroboter durchsucht rekursiv eine Dateiressource und verarbeitet Dateien gemäß einer bestimmten Liste von Erweiterungen. Die Verarbeitung besteht darin, den Inhalt der Datei abzurufen, den Text zu komprimieren - Anführungszeichen, Kommas, zusätzliche Leerzeichen usw. werden aus dem Text entfernt, der Inhalt wird in die Datenbank (MS SQL) gestellt, das Datum der Platzierung wird markiert und der Roboter fährt fort.
Der Sphins-Indexer arbeitet direkt mit der empfangenen Basis, bildet einen eigenen Index und gibt als Antwort einen Zeiger auf die gefundene Datei und einen Ausschnitt des gefundenen Textfragments zurück.
In C # wurde ein Formular entwickelt, das über den MySQL-Connector mit der Sphinx kommuniziert. Sphinx gibt ein Array von Dateien gemäß der Anforderung an, dann wird das Array nach dem Zugriffsrecht des Benutzers gefiltert, der sucht, die Ausgabe wird formatiert und dem Benutzer angezeigt.
Wir müssen die folgenden Informationen über die Datei speichern:
- Datei-ID
- Dateiname
- Der Pfad zur Datei
- Dateiinhalt
- Erweiterung
- Datum der Datenbank hinzugefügt
Dies geschieht alles in einer Tabelle und der Suchroboter fügt alles hinzu. Das Datum des Hinzufügens ist erforderlich, damit der Roboter in der nächsten Runde das Datum der Dateiänderung mit dem Datum vergleicht, an dem er in die Datenbank aufgenommen wurde. Wenn sich die Daten unterscheiden, aktualisieren Sie die Informationen über die Datei.
Richten Sie dann die Suchmaschine selbst ein. Ich werde nicht die gesamte Konfiguration beschreiben, sie wird im Projektarchiv verfügbar sein, aber ich werde nur die Hauptpunkte behandeln.
Die Hauptanforderung, die die Basis der
Quelldokumente bildet : documents_base
{
sql_query = \
select \
DocumentId as 'Id', \
DocumentPath as 'Path', \
DocumentTitle as 'Title', \
DocumentExtention as 'Extension', \
DocumentContent as 'Content' \
from \
VidocqDocs
}Morphologie durch einen Lemmatizer einrichten.
index documents
{
source = documents
path = D:/work/VidocqSearcher/Sphinx/data/index
morphology = lemmatize_ru_all, lemmatize_en_all
}Danach können Sie den Indexer auf die Basis setzen und die Arbeit überprüfen.
d:\work\VidocqSearcher\Sphinx\bin\indexer.exe documents --config D:\work\VidocqSearcher\Sphinx\bin\main.conf –rotateHier ist der Pfad zum Indexer ferner der Name des Index, in den der verarbeitete Index eingefügt werden soll. Der Pfad zur Konfiguration und das Flag –rotate bedeuten, dass die Indizierung mit Gewinn durchgeführt wird, d. H. bei laufendem Suchdienst. Nach Abschluss der Indizierung wird der Index durch den aktualisierten ersetzt.
Wir überprüfen die Arbeit in der Konsole. Als Schnittstelle können Sie einen MySQL-Client verwenden, der beispielsweise aus dem Webserver-Kit stammt.
mysql -h 127.0.0.1 -P 9306Wählen Sie nach dieser Anforderung die ID aus den Dokumenten aus. sollte eine Liste indizierter Dokumente zurückgeben, wenn Sie natürlich den Sphinx-Dienst selbst gestartet und alles richtig gemacht haben.
Okay, die Konsole ist großartig, aber wir werden Benutzer nicht zwingen, Befehle einzugeben, oder?
Ich habe ein Formular wie dieses skizziert.
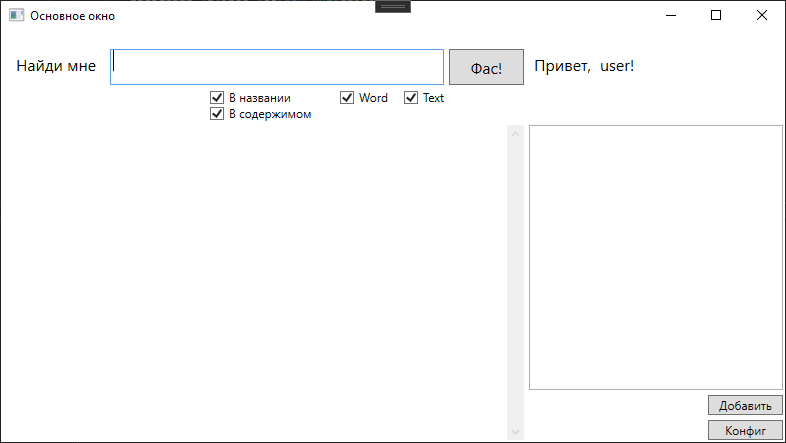
Und hier mit den Suchergebnissen.

Wenn Sie auf ein bestimmtes Ergebnis klicken, wird ein Dokument geöffnet.
Wie wird es umgesetzt?
using MySql.Data.MySqlClient;
string connectionString = "Server=127.0.0.1;Port=9306";
var query = "select id, title, extension, path, snippet(content, '" + textBoxSearch.Text.Trim() + "', 'query_mode=1') as snippet from documents " +
"where ";
if (checkBoxTitle.IsChecked == true && checkBoxContent.IsChecked == true)
{
query += "match ('@(title,content)" + textBoxSearch.Text.Trim() + "')";
}
if (checkBoxTitle.IsChecked == false && checkBoxContent.IsChecked == true)
{
query += "match ('@content" + textBoxSearch.Text.Trim() + "')";
}
if (checkBoxTitle.IsChecked == true && checkBoxContent.IsChecked == false)
{
query += "match ('@title" + textBoxSearch.Text.Trim() + "')";
}
if (checkBoxWord.IsChecked == true && checkBoxText.IsChecked == true)
{
query += "and extension in ('.docx', '.doc', '.txt');";
}
if (checkBoxWord.IsChecked == true && checkBoxText.IsChecked == false)
{
query += "and extension in ('.docx', '.doc');";
}
if (checkBoxWord.IsChecked == false && checkBoxText.IsChecked == true)
{
query += "and extension in ('.txt');";
}Ja, es gibt einen Bydloc-Code, aber dies ist ein MVP.
Tatsächlich wird hier abhängig von den festgelegten Kontrollkästchen eine Anfrage an die Sphinx gestellt. Kontrollkästchen geben den Dateityp an, in dem gesucht werden soll, und den Suchbereich.
Dann geht die Anfrage an die Sphinx und das Ergebnis wird analysiert.
using (var command = new MySqlCommand(query, connection))
{
connection.Open();
using (var reader = command.ExecuteReader())
{
while (reader.Read())
{
var id = reader.GetUInt16("id");
var title = reader.GetString("title");
var path = reader.GetString("path");
var extension = reader.GetString("extension");
var snippet = reader.GetString("snippet");
bool isFileExist = File.Exists(path);
if (isFileExist == true)
{
System.Windows.Controls.RichTextBox textBlock = new RichTextBox();
textBlock.IsReadOnly = true;
string xName = "id" + id.ToString();
textBlock.Name = xName;
textBlock.Tag = path;
textBlock.GotFocus += new System.Windows.RoutedEventHandler(ShowClickHello);
snippet = System.Text.RegularExpressions.Regex.Replace(snippet, "<.*?>", String.Empty);
Paragraph paragraph = new Paragraph();
paragraph.Inlines.Add(new Bold(new Run(path + "\r\n")));
paragraph.Inlines.Add(new Run(snippet));
textBlock.Document = new FlowDocument(paragraph);
StackPanelResult.Children.Add(textBlock);
}
else
{
counteraccess--;
}
}
}
}Gleichzeitig wird das Problem generiert. Jedes Element der Ausgabe ist eine Richtextbox mit einem Ereignis zum Öffnen eines Dokuments beim Klicken. Elemente werden auf dem StackPanel abgelegt und zuvor wird die Datei für den Benutzer überprüft. Daher wird eine Datei, auf die der Benutzer nicht zugreifen kann, nicht in die Ausgabe aufgenommen.
Die Vorteile dieser Lösung:
- Die Indizierung erfolgt zentral
- Genaue Anzeige basierend auf Zugriffsrechten
- Anpassbare Suche nach Dokumenttyp
Natürlich muss ein Dateiarchiv im Unternehmen ordnungsgemäß organisiert sein, damit eine solche Lösung voll funktionsfähig ist. Im Idealfall sollten Roaming-Benutzerprofile usw. konfiguriert werden. Und ja, ich kenne SharePoint, Windows Search und höchstwahrscheinlich einige weitere Lösungen. Dann können Sie endlos über die Wahl einer Entwicklungsplattform, der Sphinx-Suchmaschine, Manticore oder Elastic usw. diskutieren. Aber ich war daran interessiert, das Problem mit den Werkzeugen zu lösen, in denen ich ein wenig verstehe. Es läuft derzeit im MVP-Modus, aber ich entwickle es.
Aber auf jeden Fall bin ich bereit, Ihren Vorschlägen zuzuhören, welche Punkte im Keim entweder verbessert oder erneuert werden können.