Wir werden Ihnen sagen, warum dieses Tool erschienen ist und was es kann.

Fehlende Algorithmen
Eine der wichtigsten Herausforderungen beim maschinellen Lernen ist die Reduzierung der Datendimensionalität. Data Scientists reduzieren die Anzahl der Variablen, indem sie unter ihnen die Werte isolieren, die den größten Einfluss auf das Ergebnis haben. Nach dieser Operation benötigt das Modell des maschinellen Lernens weniger Speicher, arbeitet schneller und besser. Das folgende Beispiel zeigt, dass das Eliminieren doppelter Features die Klassifizierungsgenauigkeit von 0,903 auf 0,943 erhöht.
>>> from sklearn.linear_model import SGDClassifier
>>> from ITMO_FS.embedded import MOS
>>> X, y = make_classification(n_samples=300, n_features=10, random_state=0, n_informative=2)
>>> sel = MOS()
>>> trX = sel.fit_transform(X, y, smote=False)
>>> cl1 = SGDClassifier()
>>> cl1.fit(X, y)
>>> cl1.score(X, y)
0.9033333333333333
>>> cl2 = SGDClassifier()
>>> cl2.fit(trX, y)
>>> cl2.score(trX, y)
0.9433333333333334Es gibt zwei Ansätze zur Dimensionsreduzierung: Feature-Design und Feature-Auswahl. In Bereichen wie Bioinformatik und Medizin wird letzteres häufig verwendet, da Sie damit wichtige Merkmale hervorheben und gleichzeitig die Semantik beibehalten können, dh die ursprüngliche Bedeutung von Merkmalen nicht ändern. Den gängigsten Python-Bibliotheken für maschinelles Lernen - Scikit-Learn, Pytorch, Keras, Tensorflow - fehlt jedoch ein vollständiger Satz von Methoden zur Funktionsauswahl.
Um dieses Problem zu lösen, haben Studenten und Doktoranden der ITMO-Universität eine offene Bibliothek entwickelt - ITMO_FS. Ein Team arbeitet unter der Leitung von Ivan Smetannikov, außerordentlicher Professor an der Fakultät für Informationstechnologien und Programmierung, daran, Stellvertretender Leiter des Labors für maschinelles Lernen. Hauptentwickler - Nikita Pilnenskiy, absolvierte den Master in Maschinellem Lernen und Datenanalyse . Jetzt geht er zur Graduiertenschule.
« , . , , , (-) .
, , , . , , , ».
—
ITMO_FS ist in Python implementiert und mit scikit-learn kompatibel, das als das de facto wichtigste Datenanalysetool gilt. Seine Funktion Wähler nehmen die gleichen Parameter:
data: array-like (2-D list, pandas.Dataframe, numpy.array);
targets: array-like (1-D list, pandas.Series, numpy.array).Die Bibliothek unterstützt alle klassischen Ansätze zur Funktionsauswahl - Filter, Wrapper und Inline-Methoden. Dazu gehören Algorithmen wie Filter, die auf Spearman- und Pearson-Korrelationen basieren, Fit Criterion, QPFS, Hill Climbing Filter und andere .

Die Bibliothek unterstützt auch Trainingsensembles, indem sie Algorithmen zur Merkmalsauswahl basierend auf den in ihnen verwendeten Signifikanzmaßen kombiniert. Mit diesem Ansatz können Sie mit geringem Zeitaufwand höhere Prognoseergebnisse erzielen.
Was sind die Analoga
Insbesondere in Python gibt es nicht viele Bibliotheken mit Algorithmen zur Funktionsauswahl. Eine der größten gilt als Entwicklung von Ingenieuren der Arizona State University (ASU). Es unterstützt eine große Anzahl von Algorithmen, wurde jedoch in letzter Zeit kaum aktualisiert.
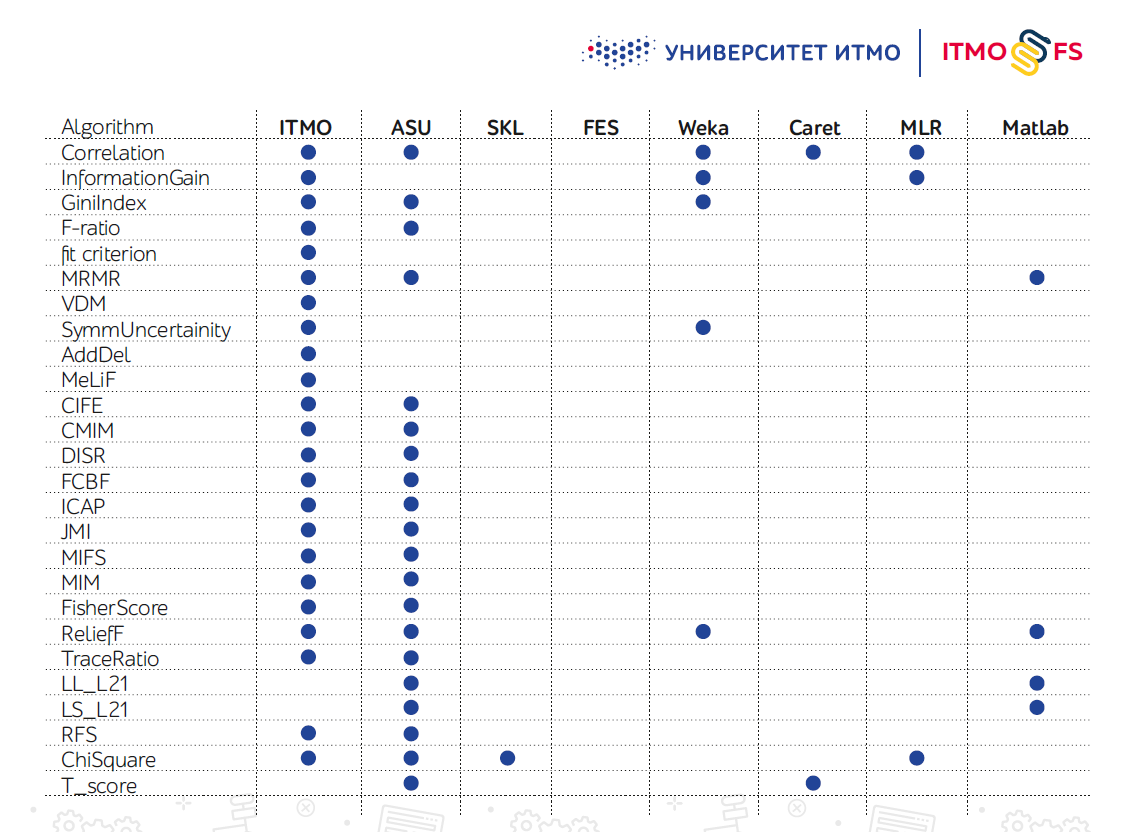
Scikit-learn selbst verfügt auch über mehrere Mechanismen zur Auswahl von Funktionen, die jedoch in der Praxis nicht ausreichen.
"Im Allgemeinen hat sich der Fokus in den letzten fünf bis sieben Jahren auf Ensemble-Algorithmen für die Merkmalsauswahl verlagert, aber sie sind in solchen Bibliotheken nicht besonders vertreten, die wir auch korrigieren möchten."
- Ivan Smetannikov
Projektaussichten
Die Autoren von ITMO_FS planen, ihr Produkt in scikit-learn zu integrieren, indem sie es der Liste der offiziell kompatiblen Bibliotheken hinzufügen . Im Moment enthält die Bibliothek bereits die größte Anzahl von Algorithmen zur Merkmalsauswahl unter allen Bibliotheken, aber ihre Hinzufügung wird fortgesetzt. Weiter auf der Roadmap stehen neue Algorithmen, einschließlich unserer eigenen Entwicklungen.
In weiter entfernten Plänen gibt es Aufgaben, die Bibliothek in das Meta-Learning-System einzuführen, Algorithmen für die direkte Arbeit mit Matrixdaten (Lücken füllen, Meta-Feature-Space-Daten generieren usw.) sowie eine grafische Oberfläche hinzuzufügen. Parallel dazu finden Hackathons in der Bibliothek statt, um mehr Entwickler für das Produkt zu interessieren und Feedback zu erhalten.
Es wird erwartet, dass ITMO_FS in den Bereichen Medizin und Bioinformatik Anwendung finden wird - beispielsweise bei der Diagnose verschiedener Krebsarten, der Erstellung von Vorhersagemodellen für phänotypische Merkmale (z. B. das Alter einer Person) und der Synthese von Arzneimitteln.
Wo kann ich herunterladen
Wenn Sie sich für das ITMO_FS-Projekt interessieren, können Sie die Bibliothek herunterladen und in der Praxis ausprobieren - hier ist das Repository auf GitHub . Eine erste Version der Dokumentation finden Sie unter readthedocs . Dort sehen Sie auch die Installationsanweisungen (unterstützt von pip). Wir freuen uns über jede Rückmeldung.
Zusätzliche Materialien aus unserem Blog über Habré:
- Podcast: Was erwartet angehende Wissenschaftler auf dem Gebiet der ML?
- Podcast: Quantum Hacking und Key Sharing