Parsing
Was ist Parsen? Dies ist die Erfassung und Systematisierung von Informationen, die auf Websites mit speziellen Programmen veröffentlicht werden, die den Prozess automatisieren.
Das Parsen wird häufig für die Preisanalyse und das Abrufen von Inhalten verwendet.
Start
Um Geld von Buchmachern zu sammeln, musste ich umgehend Informationen über die Gewinnchancen für bestimmte Veranstaltungen von mehreren Websites erhalten. Wir werden nicht auf den mathematischen Teil eingehen.
Da ich in meiner Sharaga C # studiert habe, habe ich beschlossen, alles darin zu schreiben. Die Mitarbeiter von Stack Overflow haben empfohlen, Selenium WebDriver zu verwenden. Es ist ein Browsertreiber (Softwarebibliothek), mit dem Sie Programme entwickeln können, die das Verhalten des Browsers steuern. Das brauchen wir, dachte ich.
Ich habe die Bibliothek installiert und bin gelaufen, um die Anleitungen im Internet anzusehen. Nach einer Weile schrieb ich ein Programm, das einen Browser öffnen und einigen Links folgen konnte.
Hurra! Obwohl aufhören, wie man die Tasten drückt, wie man die notwendigen Informationen bekommt? XPath wird uns hier helfen.
XPath
In einfachen Worten ist es eine Sprache zum Abfragen von XML- und XHTML-Dokumentelementen.
Für diesen Artikel verwende ich Google Chrome. Andere moderne Browser sollten jedoch, wenn nicht gleich, eine sehr ähnliche Oberfläche haben.
Drücken Sie F12, um den Code der Seite anzuzeigen, auf der Sie sich befinden.

Um zu sehen, wo sich im Code ein Element auf der Seite befindet (Text, Bild, Schaltfläche), klicken Sie auf den Pfeil in der oberen linken Ecke und wählen Sie dieses Element auf der Seite aus. Kommen wir nun zur Syntax.
Standard-Syntax zum Schreiben von XPath:
// Tagname [@ attribute = 'value']
// : Wählt alle Knoten im HTML-Dokument ab dem aktuellen Knoten aus.
Tagname : Tag des aktuellen Knotens.
@ : Wählt Attribute aus
Attribut : Der Name des Attributs des Knotens.
Wert : Der Wert des Attributs.
Es mag zunächst nicht klar sein, aber nach den Beispielen sollte alles zusammenpassen.
Schauen wir uns einige einfache Beispiele an:
// Eingabe [@ type = 'text']
// Bezeichnung [@ id = 'l25']
// Eingabe [@ value = '4']
// a [@ href = 'www.walmart. com ']
Betrachten Sie komplexere Beispiele für das angegebene HTML:
<div class ='contentBlock'>
<div class = 'listItem'>
<a class = 'link' href = 'habr.com'>
<span class='name'>habr</span>
</a>
<div class = 'textConainer'>
<span class='description'>cool site</span>
"text2"
</div>
</div>
<div class = 'listItem'>
<a class = 'link' href = 'habr.com'>
<span class='name'>habrhabr</span>
</a>
<div class = 'textConainer'>
<span class='description'>the same site</span>
"text1"
</div>
</div>
</div>XPath = // div [@ class = 'contentBlock'] // div
Die folgenden Elemente werden für diesen XPath ausgewählt:
<div class = 'listItem'>
<div class = 'textConainer'>
<div class = 'listItem'>
<div class = 'textConainer'>XPath = // div [@ class = 'contentBlock'] / div
<div class = 'listItem'>
<div class = 'listItem'>Beachten Sie den Unterschied zwischen / (Abrufen vom Wurzelknoten) und // (Abrufen von Knoten vom aktuellen Knoten, unabhängig von ihrer Position). Wenn es nicht klar ist, schauen Sie sich die obigen Beispiele noch einmal an.
// div [@ class = 'contentBlock'] / div [@ class = 'listItem'] / a [@ class = 'link'] / span [@ class = 'name']
Diese Anfrage ist mit diesem HTML identisch :
// div / div / a / span
// span [@ class = 'name']
// a [@ class = 'link'] / span [@ class = 'name']
// a [@ class = ' Link 'undhref= 'habr.com'] / span
// span [text () = 'habr' oder text () = 'habrhabr']
// div [@ class = 'listItem'] // span [@ class = 'name' ]
// a [enthält (href, 'habr')] / span
// span [enthält (text (), 'habr')]
Ergebnis:
<span class='name'>habr</span>
<span class='name'>habrhabr</span>// Spanne [text () = 'habr'] / parent :: a / parent :: div
Gleich
// div / div [@ class = 'listItem'] [1]
Ergebnis:
<div class = 'listItem'>parent :: - Gibt das übergeordnete Element eine Ebene höher zurück.
Es gibt auch eine super coole Funktion wie " folgendes Geschwister :: - gibt viele Elemente auf derselben Ebene nach dem aktuellen zurück, ähnlich wie beim vorherigen Geschwister :: - gibt viele Elemente auf derselben Ebene vor dem aktuellen zurück."
// span [@ class = 'name'] / folgendes-sibiling :: text () [1]
Ergebnis:
"text1"
"text2"Ich denke es ist jetzt klarer. Um das Material zu konsolidieren, empfehle ich Ihnen, auf diese Website zu gehen und einige Anfragen zu schreiben, um einige Elemente dieses HTML zu finden.
<div class="item">
<a class="link" data-uid="A8" href="https://www.walmart.com/grocery/?veh=wmt" title="Pickup & delivery">
<span class="g_b">Pickup and delivery</span>
</a>
<a class="link" data-uid="A9" href="https://www.walmart.com/" title="Walmart.com">
<span class="g_b">Walmart.com</span>
</a>
</div>
<div class="item">
<a class="link" data-uid="B8" href="https://www.walmart.com/grocery/?veh=wmt" title="Savings spotlight">
<span class="g_b">Savings spotlight</span>
</a>
<a class="link" data-uid="B9" href="https://www.walmartethics.com/content/walmartethics/it_it.html" title="Walmart.com">
<span class="g_b">Walmart.com(Italian)</span>
"italian virsion"
</a>
</div>Nachdem wir nun wissen, was XPath ist, können wir wieder den Code schreiben. Da die Habr-Moderatoren keine Buchmacher mögen, werden sie die Preise für Kaffee in Walmart analysieren
string pathToFile = AppDomain.CurrentDomain.BaseDirectory + '\\';
IWebDriver driver = new ChromeDriver(pathToFile);
driver.Navigate().GoToUrl("https://walmart.com");
Thread.Sleep(5000);
IWebElement element = driver.FindElement(By.XPath("//button[@id='header-Header sparkButton']"));
element.Click();
Thread.Sleep(2000);
element = driver.FindElement(By.XPath("//button[@data-tl-id='GlobalHeaderDepartmentsMenu-deptButtonFlyout-10']"));
element.Click();
Thread.Sleep(2000);
element = driver.FindElement(By.XPath("//div[text()='Coffee']/parent::a"));
driver.Navigate().GoToUrl(element.GetAttribute("href"));
Thread.Sleep(10000);
List<string> names = new List<string>(), prices = new List<string>();
List<IWebElement> listOfElements =driver.FindElements(By.XPath("//div[@class='tile-content']/div[@class='tile-title']/div")).ToList();
foreach (IWebElement a in listOfElements)
names.Add(a.Text);
listOfElements = driver.FindElements(By.XPath("//div[@class='tile-content']/div[@class='tile-price']/span/span[contains(text(),'$')]")).ToList();
foreach (IWebElement a in listOfElements)
prices.Add(a.Text);
for (int i = 0; i < prices.Count; i++)
Console.WriteLine(names[i] + " " + prices[i]);Thread.Sleeps wurden so geschrieben, dass die Webseite Zeit zum Laden hatte.
Das Programm öffnet die Walmart Store-Website, drückt ein paar Knöpfe, öffnet den Kaffeebereich und erhält den Namen und die Preise der Waren.
Wenn die Webseite ziemlich groß ist und XPaths daher lange dauern oder schwer zu schreiben sind, müssen Sie eine andere Methode verwenden.
HTTP-Anfragen
Schauen wir uns zunächst an, wie der Inhalt auf der Website angezeigt wird.

Mit einfachen Worten, der Browser sendet eine Anfrage an den Server mit der Bitte, die erforderlichen Informationen bereitzustellen, und der Server stellt diese Informationen wiederum bereit. All dies erfolgt über HTTP-Anfragen.
Um die Anforderungen anzuzeigen, die Ihr Browser an eine bestimmte Site sendet, öffnen Sie einfach diese Site, drücken Sie F12, wechseln Sie zur Registerkarte Netzwerk und laden Sie die Seite neu.

Jetzt bleibt es, die Anfrage zu finden, die wir brauchen.
Wie es geht? - Berücksichtigen Sie alle Anforderungen mit dem Abruftyp (dritte Spalte im Bild oben) und sehen Sie sich die Registerkarte Vorschau an.

Wenn es nicht leer ist, muss es im XML- oder JSON-Format vorliegen. Wenn nicht, suchen Sie weiter. Wenn ja, prüfen Sie, ob die benötigten Informationen hier sind. Um dies zu überprüfen, empfehle ich Ihnen, eine Art JSON-Viewer oder XML-Viewer zu verwenden (googeln Sie und öffnen Sie den ersten Link, kopieren Sie den Text von der Registerkarte Antwort und fügen Sie ihn in den Viewer ein). Wenn Sie die gewünschte Anfrage gefunden haben, speichern Sie den Namen (linke Spalte) oder den URL-Host (Registerkarte "Überschriften") irgendwo, damit Sie später nicht mehr suchen. Wenn beispielsweise eine Kaffeeabteilung auf der Walmart-Website geöffnet wird, wird eine Anfrage gesendet, deren Recht mit walmart.com/cp/api/wpa beginnt. Es werden alle Informationen über Kaffee zum Verkauf angeboten.
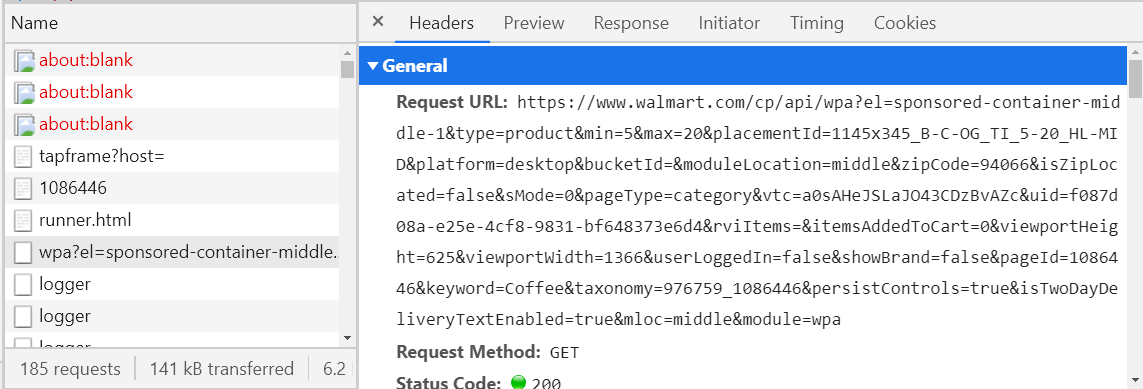
Auf halbem Weg kann diese Anfrage nun "gefälscht" und sofort über das Programm gesendet werden, wobei die erforderlichen Informationen innerhalb von Sekunden empfangen werden. Es bleibt zu analysieren JSON oder XML, und dies ist viel einfacher als das Schreiben von XPaths. Aber oft ist die Bildung solcher Anfragen ziemlich unangenehm (siehe die URL im Bild oben), und wenn Sie überhaupt Erfolg haben, erhalten Sie in einigen Fällen eine solche Antwort.
{
"detail": "No authorization token provided",
"status": 401,
"title": "Unauthorized",
"type": "about:blank"
}Jetzt erfahren Sie, wie Sie Probleme beim Nachahmen einer Anforderung mithilfe einer Alternative - eines Proxyservers - vermeiden können.
Proxy Server
Ein Proxyserver ist ein Gerät, das zwischen einem Computer und dem Internet vermittelt.
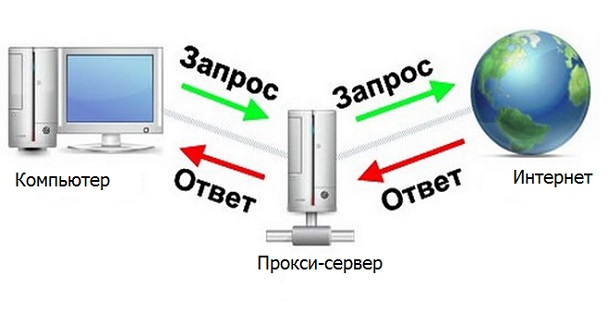
Es wäre großartig, wenn unser Programm ein Proxyserver wäre, dann können Sie die erforderlichen Antworten vom Server schnell und bequem verarbeiten. Dann gäbe es eine solche Kette Browser - Programm - Internet (Site-Server, der analysiert wird).
Zum Glück gibt es eine wunderbare Bibliothek für solche Anforderungen - Titanium Web Proxy.
Lassen Sie uns die PServer-Klasse erstellen
class PServer
{
private static ProxyServer proxyServer;
public PServer()
{
proxyServer = new ProxyServer();
proxyServer.BeforeResponse += OnResponse;
var explicitEndPoint = new ExplicitProxyEndPoint(IPAddress.Loopback, 8000, true);
explicitEndPoint.BeforeTunnelConnectRequest += OnBeforeTunnelConnectRequest;
proxyServer.AddEndPoint(explicitEndPoint);
proxyServer.Start();
}
private async Task OnBeforeTunnelConnectRequest(object sender, TunnelConnectSessionEventArgs e)
{
if (!e.HttpClient.Request.Url.Contains("www.walmart.com")){
e.DecryptSsl = false;
}
}
public async Task OnResponse(object sender, SessionEventArgs e)
{
if (e.HttpClient.Response.StatusCode == 200 && (e.HttpClient.Request.Method == "GET" || e.HttpClient.Request.Method == "POST"))
{
string url = e.HttpClient.Request.Url;
if (url.Contains("walmart.com/cp/api/wpa")){
Console.WriteLine(await e.GetResponseBodyAsString());
}
}
}
}Lassen Sie uns nun jede Methode einzeln durchgehen.
public PServer()
{
proxyServer = new ProxyServer();
proxyServer.BeforeResponse += OnResponse;
var explicitEndPoint = new ExplicitProxyEndPoint(IPAddress.Loopback, 8000, true);
explicitEndPoint.BeforeTunnelConnectRequest += OnBeforeTunnelConnectRequest;
proxyServer.AddEndPoint(explicitEndPoint);
proxyServer.Start();
}proxyServer.BeforeRepsone + = OnRespone - Fügt eine Methode zum Verarbeiten einer Antwort vom Server hinzu. Es wird automatisch aufgerufen, wenn die Antwort eintrifft.
expliziteEndPoint -
Proxyserverkonfiguration , ExplicitProxyEndPoint (IPAddress ipAddress, int port, bool decryptSsl = true)
IPAddress und Port, auf dem der Proxyserver ausgeführt wird.
decryptSsl - Gibt an, ob SSL entschlüsselt werden soll. Mit anderen Worten, wenn decrtyptSsl = true ist, verarbeitet der Proxyserver alle Anforderungen und Antworten.
explizitEndPoint.BeforeTunnelConnectRequest + = OnBeforeTunnelConnectRequest - Fügen Sie eine Methode zur Verarbeitung der Anforderung hinzu, bevor Sie sie an den Server senden. Es wird auch automatisch aufgerufen, bevor die Anfrage gesendet wird.
proxyServer.Start () - "Starten" des Proxyservers, ab diesem Moment beginnt er mit der Verarbeitung von Anforderungen und Antworten.
private async Task OnBeforeTunnelConnectRequest(object sender, TunnelConnectSessionEventArgs e)
{
if (!e.HttpClient.Request.Url.Contains("www.walmart.com")){
e.DecryptSsl = false;
}
}e.DecryptSsl = false - Die aktuelle Anforderung und Antwort wird nicht verarbeitet.
Wenn wir nicht an der Anfrage oder der Antwort darauf interessiert sind (zum Beispiel ein Bild oder eine Art Skript), warum dann entschlüsseln? Dafür werden sehr viele Ressourcen aufgewendet, und wenn alle Anforderungen und Antworten dekodiert werden, funktioniert das Programm lange. Wenn die aktuelle Anforderung nicht den Host der Anforderung enthält, an der wir interessiert sind, ist es daher sinnlos, sie zu entschlüsseln.
public async Task OnResponse(object sender, SessionEventArgs e)
{
if (e.HttpClient.Response.StatusCode == 200 && (e.HttpClient.Request.Method == "GET" || e.HttpClient.Request.Method == "POST"))
{
string url = e.HttpClient.Request.Url;
if (url.Contains("walmart.com/cp/api/wpa")) Console.WriteLine(await e.GetResponseBodyAsString());
}
}
}wait e.GetResponseBodyAsString () - gibt eine Antwort als Zeichenfolge zurück.
Damit WebDriver eine Verbindung zum Proxyserver herstellen kann, müssen Sie Folgendes schreiben:
string pathToFile = AppDomain.CurrentDomain.BaseDirectory + '\\';
ChromeOptions options = new ChromeOptions();
options.AddArguments("--proxy-server=" + IPAddress.Loopback + ":8000");
IWebDriver driver = new ChromeDriver(pathToFile, options);Jetzt können Sie die gewünschten Anfragen bearbeiten.
Fazit
Mit WebDriver können Sie durch Seiten navigieren, auf Schaltflächen klicken und das Verhalten eines normalen Benutzers imitieren. Mit XPaths können Sie die benötigten Informationen von Webseiten extrahieren. Wenn XPaths nicht funktionieren, kann immer ein Proxyserver helfen, der Anforderungen zwischen dem Browser und der Site abfangen kann.