Das Projekt ist gewachsen, die Bibliothek löst nun alle grundlegenden Aufgaben der Verarbeitung der natürlichen russischen Sprache: Segmentierung in Token und Sätze, morphologische und syntaktische Analyse, Lemmatisierung, Extraktion benannter Entitäten.

Bei Nachrichtenartikeln ist die Qualität aller Aufgaben mit vorhandenen Lösungen vergleichbar oder überlegen... Zum Beispiel bewältigt Natasha die NER-Aufgabe um 1 Prozentpunkt schlechter als Deeppavlov BERT NER (F1 PER 0,97, LOC 0,91, ORG 0,85), das Modell wiegt 75-mal weniger (27 MB) und läuft 2-mal schneller auf der CPU (25 Artikel / Sek.) ) als BERT NER auf GPU.
Das Projekt enthält 9 Repositorys , die von der Natasha-Bibliothek unter einer Oberfläche zusammengefasst werden. In dem Artikel werden wir über neue Tools sprechen und sie mit vorhandenen Lösungen vergleichen: Deeppavlov , SpaCy , UDPipe .

Diesem Longridu ging eine Reihe von Veröffentlichungen auf der Website natasha.github.io voraus :Wenn Sie von der Größe des folgenden Textes eingeschüchtert sind, sehen Sie sich die ersten 20 Minuten des U-Bahn-Streams über die Geschichte des Natasha-Projekts an. Es gibt eine kurze Nacherzählung:
- Natasha - hochwertige kompakte NER für die russische Sprache
- Navec - kompakte Einbettungen für die russische Sprache
- Corus - Sammlung russischsprachiger NLP-Datensätze
- Razdel - Segmentierung von russischsprachigem Text in Token und Angebote
- Naeval - quantitativer Vergleich von Systemen für russischsprachiges NLP
- Nerus ist ein großer synthetischer Datensatz in russischer Sprache mit Markup von Morphologie, Syntax und benannten Entitäten
Der Text verwendet Notizen und Diskussionen aus dem Chat t.me/natural_language_processing . Links zu neuen Materialien werden an derselben Stelle angezeigt :
- Warum Natasha keine Transformatoren benutzt. BERT in 100 Zeilen
- Slovnet BERT Modelle
- U-Bahn-Stream über die Geschichte des Natasha-Projekts
- Aktualisierte Yargy-Dokumentation
- Zusätzliche Ressourcen zum Yargy-Parser
Für diejenigen, die mehr zuhören möchten, lesen Sie den stündlichen Vortrag auf dem Datafest 2020, der fast diesen Beitrag abdeckt:
Inhalt:
- Natasha — .
- Razdel —
- Slovnet — deep learning
- Navec —
- Nerus — ,
- Corus — +
- Naeval — NLP
- Yargy- —
- Ipymarkup —
Natasha — .

Zuvor löste die Natasha-Bibliothek das NER- Problem für die russische Sprache, baute auf Regeln auf , zeigte durchschnittliche Qualität und Leistung. Jetzt ist Natasha ein ganz großes Projekt, es besteht aus 9 Repositories . Die Natasha-Bibliothek vereint sie unter einer Oberfläche und löst die grundlegenden Aufgaben der Verarbeitung der natürlichen russischen Sprache: Segmentierung in Token und Sätze, vorab trainierte Einbettungen, Morphologie- und Syntaxanalyse, Lemmatisierung, NER. Alle Lösungen zeigen Top-Ergebnisse in Nachrichtenthemen und laufen schnell auf der CPU.
Natasha ähnelt anderen Kombinationsbibliotheken: SpaCy , UDPipe , Stanza... SpaCy initialisiert und ruft Modelle implizit auf, der Benutzer übergibt den Text an die magische Funktion
nlpund erhält ein vollständig analysiertes Dokument.
import spacy
# load ,
# , NER
nlp = spacy.load('...')
# ,
text = '...'
doc = nlp(text)
Natashas Benutzeroberfläche ist ausführlicher. Der Benutzer initialisiert Komponenten explizit: Lädt vorab trainierte Einbettungen und übergibt sie an Modellkonstruktoren. Sam ruft Methoden
segment, tag_morph, parse_syntaxSegmentierung in Token und Nachfrage, Analyse der Morphologie und Syntax.
>>> from natasha import (
Segmenter,
NewsEmbedding,
NewsMorphTagger,
NewsSyntaxParser,
Doc
)
>>> segmenter = Segmenter()
>>> emb = NewsEmbedding()
>>> morph_tagger = NewsMorphTagger(emb)
>>> syntax_parser = NewsSyntaxParser(emb)
>>> text = ' , , 2019 () ...'
>>> doc = Doc(text)
>>> doc.segment(segmenter)
>>> doc.tag_morph(morph_tagger)
>>> doc.parse_syntax(syntax_parser)
>>> sent = doc.sents[0]
>>> sent.morph.print()
NOUN|Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing
PROPN|Animacy=Inan|Case=Gen|Gender=Masc|Number=Sing
ADP
PROPN|Animacy=Inan|Case=Loc|Gender=Fem|Number=Sing
PROPN|Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing
PROPN|Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing
...
>>> sent.syntax.print()
┌──► nsubj
│
│ ┌► case
│ └─
│ ┌─
│ └► flat:name
┌─────┌─└───
│ │ ┌──► , punct
│ │ │ ┌► mark
│ └►└─└─ ccomp
│ │ ┌► case
│ └──►└─ obl
...
Der benannte Entitätsextraktor hängt nicht von den Ergebnissen der Morphologie und Analyse ab, sondern kann separat verwendet werden.
>>> from natasha import NewsNERTagger
>>> ner_tagger = NewsNERTagger(emb)
>>> doc.tag_ner(ner_tagger)
>>> doc.ner.print()
, ,
LOC──── LOC──── PER───────
2019
LOC──────────────
()
LOC─── ORG───────────────────────────────────────
...
PER────────────
Natasha löst das Lemmatisierungsproblem, verwendet Pymorphy2 und die Ergebnisse der morphologischen Analyse.
>>> from natasha import MorphVocab
>>> morph_vocab = MorphVocab()
>>> for token in doc.tokens:
>>> token.lemmatize(morph_vocab)
>>> {_.text: _.lemma for _ in doc.tokens}
{'': '',
'': '',
'': '',
'': '',
'': '',
'': '',
'': '',
',': ',',
'': '',
'': ''
...
Um den Ausdruck auf eine normale Form zu bringen, reicht es nicht aus, die Deckspelzen einzelner Wörter zu finden. Für das russische Außenministerium wird es sich als das russische Außenministerium herausstellen, für die Organisation der ukrainischen Nationalisten - die Ukrainian Nationalist Organization. Natasha verwendet die Ergebnisse der Analyse, berücksichtigt Beziehungen zwischen Wörtern und normalisiert benannte Entitäten.
>>> for span in doc.spans:
>>> span.normalize(morph_vocab)
>>> {_.text: _.normal for _ in doc.spans}
{'': '',
'': '',
' ': ' ',
' ': ' ',
'': '',
' ()': ' ()',
' ': ' ',
...
Natasha findet Namen, Organisationen und Ortsnamen im Text. Für Namen in der Bibliothek gibt es eine Reihe von vorgefertigten Regeln für den Yargy-Parser , das Modul unterteilt die normalisierten Namen in Teile, aus denen "Viktor Fedorovich Yushchenko" erhalten wird
{first: , last: , middle: }.
>>> from natasha import (
PER,
NamesExtractor,
)
>>> names_extractor = NamesExtractor(morph_vocab)
>>> for span in doc.spans:
>>> if span.type == PER:
>>> span.extract_fact(names_extractor)
>>> {_.normal: _.fact.as_dict for _ in doc.spans if _.type == PER}
{' ': {'first': '', 'last': ''},
' ': {'first': '', 'last': ''},
' ': {'first': '', 'last': ''},
'': {'last': ''},
' ': {'first': '', 'last': ''}}
Die Bibliothek enthält Regeln zum Parsen von Daten, Geldbeträgen und Adressen, die in der Dokumentation und im Nachschlagewerk beschrieben sind .
Die Natasha-Bibliothek eignet sich gut zur Demonstration von Projekttechnologien und wird in der Bildung eingesetzt. Archive mit Modellgewichten sind in das Paket integriert. Nach der Installation müssen Sie nichts mehr herunterladen und konfigurieren.
Natasha kombiniert andere Projektbibliotheken unter einer Schnittstelle. Um praktische Probleme zu lösen, sollten Sie sie direkt verwenden:
- Razdel - Segmentierung von Text in Sätze und Token;
- Navec - hochwertige kompakte Einbettungen;
- Slovnet - moderne Kompaktmodelle für Morphologie, Syntax, NER;
- Yargy - Regeln und Vokabeln zum Extrahieren strukturierter Informationen;
- Ipymarkup - Visualisierung von NER und syntaktischem Markup;
- Corus - Sammlung von Links zu öffentlichen russischsprachigen Datensätzen;
- Nerus ist ein großer Korpus mit automatischem Markup von benannten Entitäten, Morphologie und Syntax.
Razdel - Segmentierung von russischsprachigem Text in Token und Angebote

Die Razdel-Bibliothek ist Teil des Natasha-Projekts und unterteilt den russischsprachigen Text in Token und Sätze. Installationsanweisungen , Verwendungsbeispiele und Leistungsmessungen im Razdel-Repository.
>>> from razdel import tokenize, sentenize
>>> text = '- 0.5 (50/64 ³, 516;...)'
>>> list(tokenize(text))
[Substring(start=0, stop=13, text='-'),
Substring(start=14, stop=16, text=''),
Substring(start=17, stop=20, text='0.5'),
Substring(start=20, stop=21, text=''),
Substring(start=22, stop=23, text='(')
...]
>>> text = '''
... - " ?" - " --".
... . . . . ,
... '''
>>> list(sentenize(text))
[Substring(start=1, stop=23, text='- " ?"'),
Substring(start=24, stop=40, text='- " --".'),
Substring(start=41, stop=56, text=' . . . .'),
Substring(start=57, stop=76, text=' , ')]
Moderne Modelle kümmern sich oft nicht um die Segmentierung, sie verwenden BPE , zeigen bemerkenswerte Ergebnisse, erinnern sich an alle Versionen von GPT und den BERT- Zoo . Natasha löst die Probleme der Analyse von Morphologie und Syntax. Sie sind nur für einzelne Wörter innerhalb eines Satzes sinnvoll. Daher nähern wir uns verantwortungsbewusst der Phase der Segmentierung und versuchen, das Markup aus gängigen offenen Datensätzen zu wiederholen: SynTagRus , OpenCorpora , GICRYA .
Razdels Geschwindigkeit und Qualität sind vergleichbar oder besser als bei anderen Open Source-Lösungen für die russische Sprache.
| Token-Segmentierungslösungen | Fehler pro 1000 Token | Bearbeitungszeit, Sekunden |
| Regexp-Baseline | 19 | 0,5 |
| SpaCy
|
17 | 5.4 |
| NLTK
|
130 | 3.1 |
| MyStem
|
19 | 4.5 |
| Moses
|
elf | 1.9 |
| SegTok
|
12 | 2.1 |
| SpaCy Russian Tokenizer
|
8 | 46.4 |
| RuTokenizer
|
15 | 1.0 |
| Razdel
|
7 | 2.6 |
| 1000 | , | |
| Regexp-baseline | 76 | 0.7 |
| SegTok
|
381 | 10.8 |
| Moses
|
166 | 7.0 |
| NLTK
|
57 | 7.1 |
| DeepPavlov
|
41 | 8.5 |
| Razdel | 43 | 4.8 |
Die Anzahl der Fehler beträgt durchschnittlich 4 Datensätze : SynTagRus , OpenCorpora , GICRYA und RNC . Weitere Details im Razdel-Repository .
Warum brauchen wir Razdel überhaupt, wenn eine Grundlinie mit einer regulären Linie eine ähnliche Qualität ergibt und es viele vorgefertigte Lösungen für die russische Sprache gibt? Tatsächlich ist Razdel nicht nur ein Tokenizer, sondern eine kleine regelbasierte Segmentierungs-Engine. Die Segmentierung ist eine grundlegende Aufgabe, die in der Praxis häufig auftritt. Zum Beispiel gibt es eine gerichtliche Handlung, Sie müssen den operativen Teil darin hervorheben und ihn in Absätze unterteilen. Standardlösungen können das natürlich nicht. Lesen Sie, wie Sie Ihre eigenen Regeln in den Quellcode schreiben . Weiter werden wir darüber sprechen, wie Sie sich selbst pushen und eine Top-Lösung für Token und Angebote für unseren Motor entwickeln können.
Was ist die Schwierigkeit?
Im Russischen enden Sätze normalerweise mit einem Punkt, einem Fragezeichen oder einem Ausrufezeichen. Teilen wir den Text einfach mit einem regulären Ausdruck
[.?!]\s+. Diese Lösung ergibt 76 Fehler pro 1000 Sätze. Arten und Beispiele von Fehlern:
Abkürzungen
... jede Plattform mit einem Publikum von 3.000 oder mehr Personen ist ein Blogger.
... seit dem Ende des 17. Jahrhunderts stand ein Schlag über ihnen;
… Im nach ▒B.A benannten Chamber Musical Theatre. Pokrovsky.
Initialen
Nach den Opern "Idomeneo" von V.A.▒Mozart - R.▒Strauss ...
Listen
2. Ich dachte, es würde eine schöne lange Schlange beim finnischen Konsulat geben ...
g . Fahrkarten für Züge der russischen Eisenbahnen ...
Am Ende des Satzes ein Smiley oder eine typografische Ellipse
Wer auch immer einen Weg anbietet, die Minuspunkte loszuwerden - dank dessen :) ▒ Ich sah nachdenklich aus ... ▒ Nun ist dies unangenehmer, da der Inhalt kaputt sein wird.
Zitate, direkte Rede, am Ende des Satzes ein Anführungszeichen
- haben Sie eine Braut in der Stadt? “▒„ Für wen hat eine Braut? “
„Es ist so gut, dass ich nicht so bin!“ „Jetzt habe ich beim Übersetzen einen Freudschen Fehler gemacht:„ Idologie “.
Razdel berücksichtigt diese Nuancen und reduziert die Anzahl der Fehler von 76 auf 43 pro 1000 Sätze.
Ähnlich ist die Situation bei Token. Eine gute Basislösung ist ein Regex
[--]+|[0-9]+|[^-0-9 ], der 19 Fehler pro 1000 Token macht. Beispiele:
Bruchzahlen, komplexe Interpunktion
... In den späten 1980er - frühen 1990er Jahren
... BS-▒3 kann etwas weniger Masse festgestellt werden (3▒, ▒6 t)
- und sie starb ▒.▒. Verstehst du das Mädchen, Falke? ▒!
Razdel reduziert die Fehlerrate auf 7 pro 1000 Token.
Arbeitsprinzip
Das System basiert auf Regeln. Das Prinzip der Segmentierung in Token und Angebote ist dasselbe.
Sammlung von Kandidaten
Wir finden im Text alle Kandidaten für das Ende des Satzes: Punkte, Ellipsen, Klammern, Anführungszeichen.
6. Die häufigste und gleichzeitig hoch bewertete Antwortmöglichkeit „Ich bin froh“ (13 Aussagen, 25 Punkte) - Situationen, in denen Zustimmung und Ermutigung erhalten werden. , aber nur einmal gibt es die Antwort "Ich bin eine Frau" ▒; ▒ es gibt Aussagen "eine Ehe ist alles, was mich in diesem Leben erwartet" ▒ und "früher oder später muss ich gebären" ▒.▒ Compiler: V.▒P.▒Golovin , F.▒V.▒Zanichev, A.▒L.▒Rastorguev, R.▒V.▒Savko, I.▒I.▒Tuchkov.
Für Token teilen wir den Text in Atome auf. Die Token-Grenze verläuft nicht genau innerhalb des Atoms.
Ende 1980▒-▒▒-begin1990▒-▒▒
BS▒-▒3▒ ist es möglich , eine leicht kleine Masse zu markieren (▒3▒, ▒6▒▒) ▒
▒— Da▒and▒umerla▒.▒.▒.▒Got ▒ligirl, ▒der Falke▒? ▒!
Union
Wir umgehen konsequent Kandidaten für die Trennung, entfernen unnötige. Wir verwenden eine Liste von Heuristiken.
Listenpunkt. Das Trennzeichen ist ein Punkt oder eine Klammer, links eine Zahl oder ein Buchstabe
6. Die häufigste und gleichzeitig hoch bewertete Antwort „Ich bin froh“ (13 Aussagen, 25 Punkte) ist eine Situation der Zustimmung und Ermutigung. 7.▒ Es ist bemerkenswert, dass in der Antwort "Ich weiß" ...
Initialen. Trennzeichen - Punkt, ein Großbuchstabe links
... Zusammengestellt von V.▒P.▒Golovin, F.▒V.▒Zanichev, A.▒L.▒Rastorguev, R.▒V.▒Savko, I.▒I.▒Tuchkov ...
Rechts vom Trennzeichen ist kein Platz
... aber nur einmal lautet die Antwort "Ich bin eine Frau" ▒; Es gibt Aussagen „eine Ehe ist alles, was mich in diesem Leben erwartet“ und „früher oder später muss ich gebären“ ▒.
Vor dem schließenden Anführungszeichen oder der Klammer steht kein Satzende, dies ist kein Zitat oder keine direkte Rede
6. Die häufigste und am meisten geschätzte Antwort lautet „Ich bin froh“ (13 Aussagen, 25 Punkte) ▒ - Situationen, in denen Zustimmung und Ermutigung eingeholt werden. ... "Eine Ehe ist alles, was mich in diesem Leben erwartet" und "früher oder später werde ich gebären müssen".
Infolgedessen sind noch zwei Trennzeichen übrig, wir betrachten sie als Satzenden.
6. Die häufigste und gleichzeitig hoch geschätzte Variante der Antworten „Ich bin froh“ (13 Aussagen, 25 Punkte) ist eine Situation, in der Zustimmung und Ermutigung erhalten werden. “7. Es ist bemerkenswert, dass die Antwort „Ich weiß“ als die stereotypste bewertet wird, aber nur einmal, wenn die Antwort „Ich bin eine Frau“ gefunden wird. Es gibt Aussagen: „Eine Ehe ist alles, was mich in diesem Leben erwartet“ und „früher oder später muss ich gebären.“ ompKomponisten: V.P. Golovin, F.V. Zanichev, A.L. Rastorguev, R.V. Savko, I. I. Tuchkov.
Das Verfahren ist für Token ähnlich, die Regeln sind unterschiedlich. Bruch
oder rationale Zahl
... (3▒, ▒6 t) ...
Komplexe Interpunktion
- ja, und gestorben.▒.▒. Verstehst du das Mädchen, Falke? ▒!
Es gibt keine Leerzeichen um den Bindestrich, dies ist nicht der Beginn der direkten Sprache.
Ende 1980▒-▒ - Anfang 1990▒-▒
BS▒-▒3 kann festgestellt werden ...
Alles, was übrig bleibt, sind die Grenzen der Token.
Ende der 1980er Jahre - Anfang -1990 -
BS-3 - ist es möglich, eine leicht bedeutende
Masse (3,6,6 t) zu markieren - ja und umerla. ..▒Got it▒li▒girl, ▒sokol▒ ?!
Einschränkungen
Razdel-Regeln sind für sauber geschriebenen Text mit korrekter Interpunktion optimiert. Die Lösung funktioniert gut mit Nachrichtenartikeln und literarischen Texten. Bei Posts aus sozialen Netzwerken, Abschriften von Telefongesprächen, ist die Qualität geringer. Wenn zwischen den Sätzen kein Leerzeichen oder kein Punkt am Ende steht oder der Satz mit einem Kleinbuchstaben beginnt, macht Razdel einen Fehler. Lesen Sie,
wie Sie Regeln für Ihre Aufgaben in den Quellcode schreiben. Dieses Thema wurde in der Dokumentation noch nicht veröffentlicht.
Slovnet - Deep Learning-Modellierung für die Verarbeitung natürlicher russischer Sprache

In dem Projekt beschäftigt sich Natasha Slovnet mit der Lehre und Inferenz moderner Modelle für russischsprachiges NLP. Die Bibliothek enthält hochwertige Kompaktmodelle zum Extrahieren benannter Entitäten, zum Parsen von Morphologie und Syntax. Die Qualität aller Aufgaben ist vergleichbar oder überlegen gegenüber anderen offenen Lösungen für die russische Sprache für Nachrichtentexte. Installationsanweisungen , Anwendungsbeispiele - im Slovnet-Repository . Schauen wir uns genauer an, wie die Lösung für das NER-Problem angeordnet ist. Für Morphologie und Syntax ist alles analog.
Ende 2018 gab es nach einem Artikel von Google über BERT große Fortschritte bei der englischsprachigen NLP. Im Jahr 2019 die Jungs vom DeepPavlov-Projektangepasstes mehrsprachiges BERT für Russisch, erschien RuBERT . Ein CRF-Kopf wurde oben trainiert , es stellte sich heraus, DeepPavlov BERT NER - SOTA für die russische Sprache. Das Modell hat eine hervorragende Qualität, 2 Mal weniger Fehler als der nächstgelegene Verfolger DeepPavlov NER , aber die Größe und Leistung sind beängstigend: 6 GB - Verbrauch von GPU-RAM, 2 GB - Größe des Modells, 13 Artikel pro Sekunde - Leistung auf einer guten GPU.
Im Jahr 2020 gelang es uns im Natasha-Projekt, DeepPavlov BERT NER qualitativ nahe zu kommen. Die Modellgröße war 75-mal kleiner (27 MB), der Speicherverbrauch 30-mal geringer (205 MB) und die Geschwindigkeit der CPU 2-mal höher (25 Artikel pro Sekunde) ).
| Natasha, Slovnet NER | DeepPavlov BERT NER | |
| PER / LOC / ORG F1 nach Token, Durchschnitt nach Collection5, factRuEval-2016, BSNLP-2019, Gareev | 0,97 / 0,91 / 0,85 | 0,98 / 0,92 / 0,86 |
| Modellgröße | 27 MB | 2 GB |
| Speicherverbrauch | 205 MB | 6 GB (GPU) |
| Leistung, Nachrichtenartikel pro Sekunde (1 Artikel ≈ 1 KB) | 25 pro CPU (Core i5) | 13 GPU (RTX 2080 Ti), 1 CPU |
| Initialisierungszeit Sekunden | 1 | 35 |
| Die Bibliothek unterstützt | Python 3.5+, PyPy3 | Python 3.6+ |
| Abhängigkeiten | NumPy | TensorFlow |
Die Qualität von Slovnet NER ist 1 Prozentpunkt niedriger als die von SOTA DeepPavlov BERT NER, die Größe des Modells ist 75-mal kleiner, der Speicherverbrauch ist 30-mal geringer, die Geschwindigkeit der CPU ist 2-mal höher. Vergleich mit SpaCy, PullEnti und anderen Lösungen für russischsprachige NER im Slovnet-Repository .
Wie kommt man zu diesem Ergebnis? Kurzes Rezept:
Slovnet NER = Slovnet BERT NER - Analogon der DeepPavlov BERT NER + -Destillation durch synthetisches Markup ( Nerus ) in WordCNN-CRF mit quantisierten Einbettungen ( Navec ) + Engine zur Inferenz auf NumPy.
Jetzt in Ordnung. Der Plan lautet wie folgt: Trainieren Sie ein schweres Modell mit BERT-Architektur auf einem kleinen manuell kommentierten Datensatz. Wir markieren es mit einem Nachrichtenkorpus und erhalten einen großen schmutzigen synthetischen Trainingsdatensatz. Lassen Sie uns ein kompaktes primitives Modell darauf trainieren. Dieser Vorgang wird Destillation genannt: Das schwere Modell ist der Lehrer, das kompakte Modell ist der Schüler. Wir erwarten, dass die BERT-Architektur für das NER-Problem redundant ist, das kompakte Modell wird nicht viel an Qualität an das schwere verlieren.
Modelllehrer
DeepPavlov BERT NER besteht aus einem RuBERT-Encoder und einem CRF-Kopf. Unser schweres Lehrermodell wiederholt diese Architektur mit geringfügigen Verbesserungen.
Alle Benchmarks messen die NER-Qualität von Nachrichtentexten. Lassen Sie uns RuBERT in den Nachrichten trainieren. Das Corus- Repository enthält Links zum öffentlichen russischsprachigen Nachrichtenkorpus, insgesamt 12 GB Texte. Wir verwenden Techniken aus dem Facebook-Artikel über RoBERTa : große aggregierte Chargen, dynamische Maske, Weigerung, den nächsten Satz (NSP) vorherzusagen. RuBERT verwendet ein riesiges Wörterbuch mit 120.000 Subtokens - ein Erbe von Googles mehrsprachigem BERT. Wenn Sie die Größe auf die 50.000 häufigsten Nachrichten reduzieren, verringert sich die Abdeckung um 5%. Holen Sie sich NewsRuBERTDas Modell sagt getarnte Subtokens in den Nachrichten 5 Prozentpunkte besser voraus als RuBERT (63% in den Top 1).
Lassen Sie uns den NewsRuBERT-Encoder und den CRF-Kopf für 1000 Artikel aus Collection5 trainieren . Wir erhalten Slovnet BERT NER , die Qualität ist 0,5 Prozentpunkte besser als DeepPavlov BERT NER, die Größe des Modells ist 4-mal kleiner (473 MB), es arbeitet 3-mal schneller (40 Artikel pro Sekunde).
NewsRuBERT = RuBERT + 12 GB Nachrichten + Techniken aus dem RoBERTa + 50K-Wörterbuch.
Slovnet BERT NER (analog zu DeepPavlov BERT NER) = NewsRuBERT + CRF-Kopf + Collection5.
Um Modelle mit BERT-ähnlicher Architektur zu trainieren, ist es üblich, Transformers von Hugging Face zu verwenden. Transformatoren bestehen aus 100.000 Zeilen Python-Code. Wenn Verlust oder Müll aufgrund von Schlussfolgerungen explodieren, ist es schwierig herauszufinden, was schief gelaufen ist. Okay, dort wird viel Code dupliziert. Selbst wenn wir RoBERTa trainieren, können wir das Problem schnell auf ~ 3000 Codezeilen lokalisieren, aber das ist auch viel. Mit dem modernen PyTorch ist die Transformers-Bibliothek bei weitem nicht so relevant. Mit
torch.nn.TransformerEncoderLayerdem RoBERTa-ähnlichen Modellcode werden 100 Zeilen benötigt:
class BERTEmbedding(nn.Module):
def __init__(self, vocab_size, seq_len, emb_dim, dropout=0.1, norm_eps=1e-12):
super(BERTEmbedding, self).__init__()
self.word = nn.Embedding(vocab_size, emb_dim)
self.position = nn.Embedding(seq_len, emb_dim)
self.norm = nn.LayerNorm(emb_dim, eps=norm_eps)
self.drop = nn.Dropout(dropout)
def forward(self, input):
batch_size, seq_len = input.shape
position = torch.arange(seq_len).expand_as(input).to(input.device)
emb = self.word(input) + self.position(position)
emb = self.norm(emb)
return self.drop(emb)
def BERTLayer(emb_dim, heads_num, hidden_dim, dropout=0.1, norm_eps=1e-12):
layer = nn.TransformerEncoderLayer(
d_model=emb_dim,
nhead=heads_num,
dim_feedforward=hidden_dim,
dropout=dropout,
activation='gelu'
)
layer.norm1.eps = norm_eps
layer.norm2.eps = norm_eps
return layer
class BERTEncoder(nn.Module):
def __init__(self, layers_num, emb_dim, heads_num, hidden_dim,
dropout=0.1, norm_eps=1e-12):
super(BERTEncoder, self).__init__()
self.layers = nn.ModuleList([
BERTLayer(
emb_dim, heads_num, hidden_dim,
dropout, norm_eps
)
for _ in range(layers_num)
])
def forward(self, input, pad_mask=None):
input = input.transpose(0, 1) # torch expects seq x batch x emb
for layer in self.layers:
input = layer(input, src_key_padding_mask=pad_mask)
return input.transpose(0, 1) # restore
class BERTMLMHead(nn.Module):
def __init__(self, emb_dim, vocab_size, norm_eps=1e-12):
super(BERTMLMHead, self).__init__()
self.linear1 = nn.Linear(emb_dim, emb_dim)
self.norm = nn.LayerNorm(emb_dim, eps=norm_eps)
self.linear2 = nn.Linear(emb_dim, vocab_size)
def forward(self, input):
x = self.linear1(input)
x = F.gelu(x)
x = self.norm(x)
return self.linear2(x)
class BERTMLM(nn.Module):
def __init__(self, emb, encoder, head):
super(BERTMLM, self).__init__()
self.emb = emb
self.encoder = encoder
self.head = head
def forward(self, input):
x = self.emb(input)
x = self.encoder(x)
return self.head(x)
Dies ist kein Prototyp, der Code wird aus dem Slovnet-Repository kopiert . Transformatoren sind nützlich zu lesen, sie erledigen viel Arbeit, füllen den Code für Artikel mit Arxiv, oft ist die Python-Quelle klarer als die Erklärung in einem wissenschaftlichen Artikel.
Synthetischer Datensatz
Markieren wir 700.000 Artikel aus dem Lenta.ru-Korpus mit einem schweren Modell. Wir erhalten einen riesigen synthetischen Trainingsdatensatz. Das Archiv ist im Nerus- Repository des Natasha-Projekts verfügbar . Das Markup ist von sehr hoher Qualität, F1-Schätzungen nach Token: PER - 99,7%, LOC - 98,6%, ORG - 97,2%. Seltene Beispiele für Fehler:
ORG────────────── LOC────────────────────────────
241- 4- 10-
<
LOC─── LOC──────
>.
───────────~~~~~~~~~~~
ORG────────────────────~~~~~~~~~~~~~~~~
.
LOC───
<>
~~~~~~~~ LOC──────────────────
.
~~~~ ~~~~~~ LOC───
.
LOC────
-
PER─────────────────────
M&A.
~~~
:
~~~~~~~~~~~~ORG─── LOC──
,
PER─────── LOC───
,
ORG─ LOC─────────────
.
LOC
Modellschüler
Es gab keine Probleme bei der Wahl der Architektur des schweren Lehrermodells, es gab nur eine Option - Transformatoren. Das kompakte Studentenmodell ist schwieriger, es gibt viele Möglichkeiten. Von 2013 bis 2018, vom Aufkommen von word2vec bis zum Artikel über BERT, entwickelte die Menschheit eine Reihe neuronaler Netzwerkarchitekturen, um das NER-Problem zu lösen. Alle haben ein gemeinsames Schema:
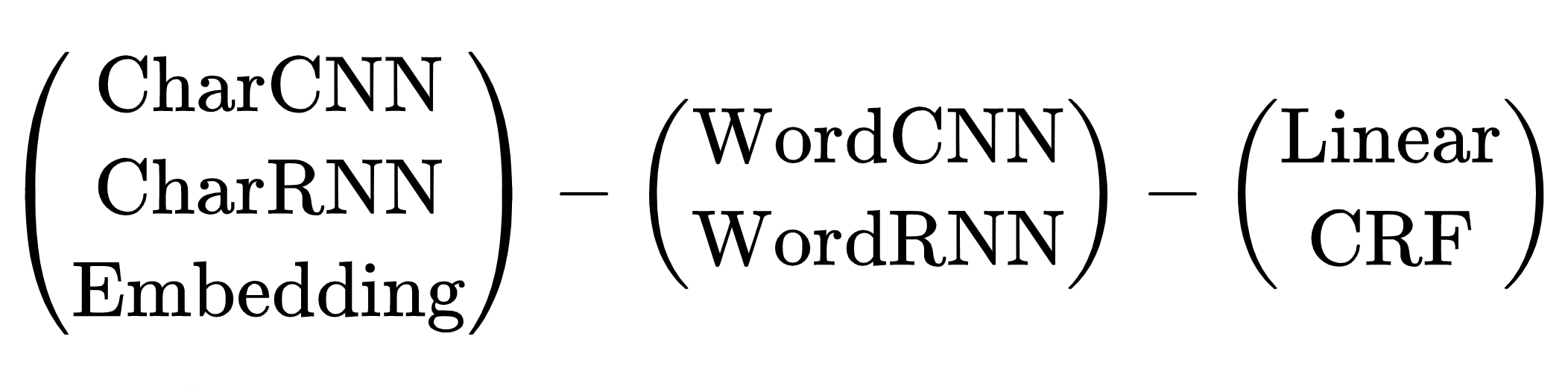
Schema neuronaler Netzwerkarchitekturen für die NER-Aufgabe: Token-Encoder, Kontext-Encoder, Tag-Decoder. Erklärungen zu Abkürzungen in einem Übersichtsartikel von Yang (2018) .
Es gibt viele Kombinationen von Architekturen. Welches soll ich wählen? Zum Beispiel ist (CharCNN + Embedding) -WordBiLSTM-CRF ein Modelldiagramm aus einem Artikel über DeepPavlov NER , SOTA für die russische Sprache bis 2019.
Wir überspringen die Optionen mit CharCNN, CharRNN. Das Starten eines kleinen neuronalen Netzwerks durch Symbole auf jedem Token ist nicht unser Weg, zu langsam. Ich möchte auch WordRNN vermeiden, die Lösung sollte auf der CPU funktionieren, Matrizen auf jedem Token langsam multiplizieren. Für NER ist die Wahl zwischen linear und CRF bedingt. Wir verwenden die BIO-Codierung, die Reihenfolge der Tags ist wichtig. Wir müssen schreckliche Bremsen ertragen, CRF verwenden. Es bleibt eine Option - Embedding-WordCNN-CRF. Dieses Modell unterscheidet nicht zwischen Groß- und Kleinschreibung, für NER ist es wichtig, "Hoffnung" ist nur ein Wort, "Hoffnung" ist möglicherweise ein Name. ShapeEmbedding hinzufügen - Einbetten mit Token-Konturen, zum Beispiel: "NER" - EN_XX, "Vainovich" - RU_Xx, "!" - PUNCT_ !, "Und" - RU_x, "5.1" - NUM, "New York" - RU_Xx-Xx. Slovnet NER-Schema - (WordEmbedding + ShapeEmbedding) -WordCNN-CRF.
Destillation
Lassen Sie uns Slovnet NER auf einem riesigen synthetischen Datensatz trainieren. Vergleichen wir das Ergebnis mit dem schweren Modelllehrer Slovnet BERT NER. Die Qualität wird berechnet und über die manuell gekennzeichnete Collection5, Gareev, factRuEval-2016, BSNLP-2019 gemittelt. Die Größe der Trainingsstichprobe ist sehr wichtig: Für 250 Nachrichtenartikel (factRuEval-2016) beträgt der Durchschnitt für PER, LOC, LOG F1 0,64, für 1000 (analog zu Collection5) - 0,81, für den gesamten Datensatz - 0,91, die Qualität von Slovnet BERT NER 0,92.
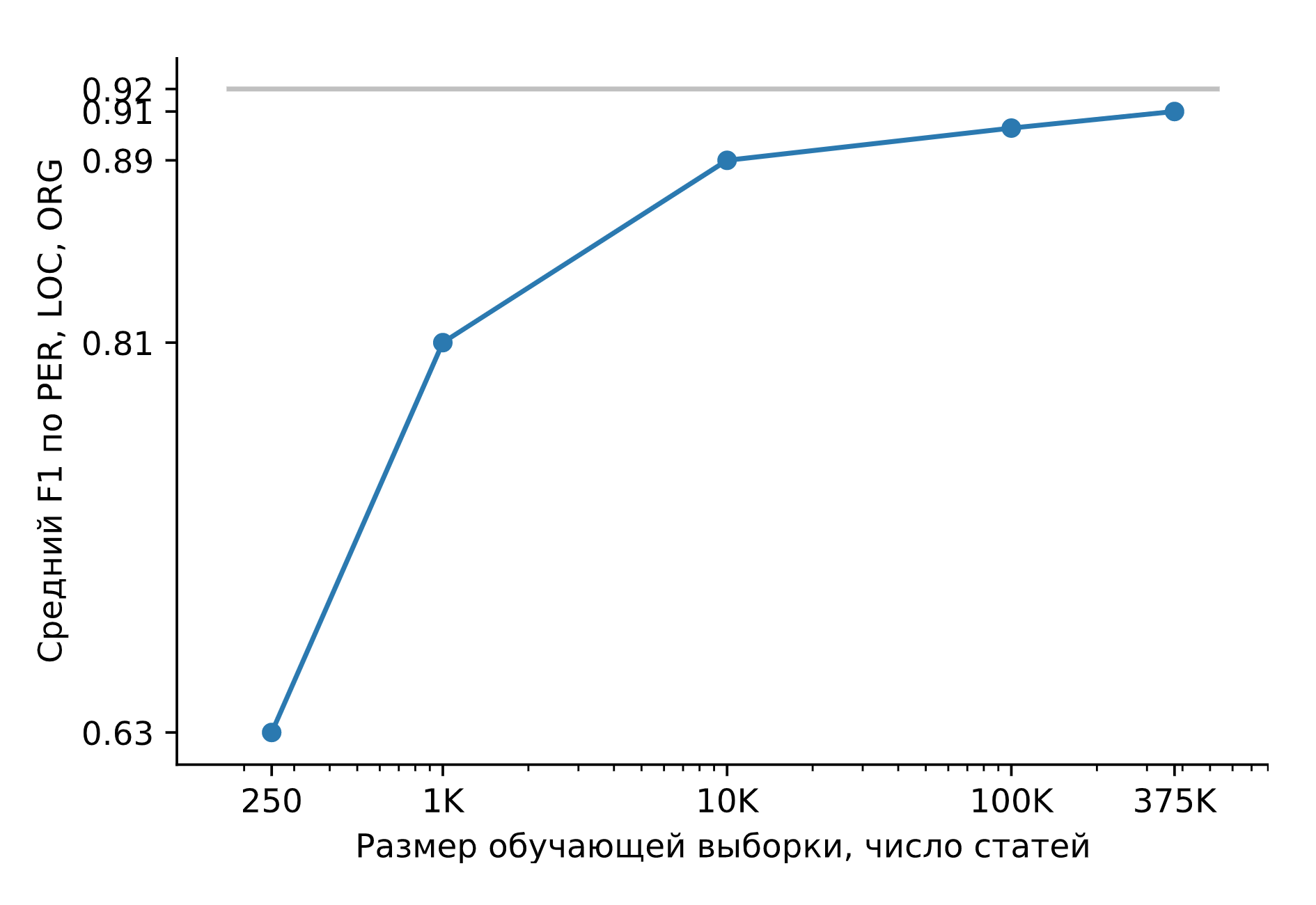
Slovnet NER-Qualität, Abhängigkeit von der Anzahl der synthetischen Trainingsbeispiele. Graue Linie - Slovnet BERT NER Qualität. Slovnet NER sieht keine handmarkierten Beispiele, sondern trainiert nur mit synthetischen Daten.
Das primitive Schülermodell ist 1 Prozentpunkt schlechter als das harte Lehrermodell. Das ist ein wunderbares Ergebnis. Ein universelles Rezept bietet sich an:
Wir markieren einige Daten manuell. Wir trainieren einen schweren Transformator. Wir generieren viele synthetische Daten. Wir trainieren ein einfaches Modell an einer großen Stichprobe. Wir erhalten die Qualität des Transformators, die Größe und Leistung eines einfachen Modells.
In der Slovnet-Bibliothek gibt es zwei weitere Modelle, die nach diesem Rezept trainiert wurden: Slovnet Morph - morphologischer Tagger, Slovnet Syntax - syntaktischer Parser. Slovnet Morph liegt 2 Prozentpunkte hinter dem Modell für schwere Lehrer zurück , Slovnet Syntax um 5 Prozentpunkte . Beide Modelle haben eine bessere Qualität und Leistung als bestehende russische Lösungen für Nachrichtenartikel.
Quantisierung
Die NER-Größe von Slovnet beträgt 289 MB. 287 MB werden von einem Tisch mit Einbettungen belegt. Das Modell verwendet ein großes Vokabular von 250.000 Zeilen und deckt 98% der Wörter in Nachrichtentexten ab. Ersetzen Sie mithilfe der Quantisierung 300-dimensionale Float-Vektoren durch 100-dimensionale 8-Bit-Vektoren. Die Größe des Modells wird um das 10-fache (27 MB) reduziert, die Qualität ändert sich nicht. Die Navec-Bibliothek ist Teil des Natasha-Projekts, einer Sammlung quantisierter vorab trainierter Einbettungen. Auf Fiktion trainierte Gewichte benötigen 50 MB, wobei alle statischen RusVectores-Modelle nach synthetischen Schätzungen umgangen werden .
Inferenz
Slovnet NER verwendet PyTorch zum Training. Das PyTorch-Paket wiegt 700 MB. Ich möchte es nicht zur Schlussfolgerung in die Produktion ziehen. PyTorch funktioniert auch nicht mit dem PyPy-Interpreter . Slovnet wird in Verbindung mit einem Yargy-Parser verwendet, einem Analogon zum Yandex Tomita-Parser . Mit PyPy arbeitet Yargy je nach Komplexität der Grammatik zwei- bis zehnmal schneller. Ich möchte nicht an Geschwindigkeit verlieren, weil ich von PyTorch abhängig bin.
Die Standardlösung besteht darin, TorchScript zu verwenden oder das Modell in ONNX zu konvertieren und die Schlussfolgerung in ONNXRuntime zu ziehen . Slovnet NER verwendet nicht standardmäßige Blöcke: quantisierte Einbettungen, CRF-Decoder. TorchScript und ONNXRuntime unterstützen PyPy nicht.
Slovnet NER ist ein einfaches Modell,Implementieren Sie alle Blöcke manuell in NumPy und verwenden Sie die von PyTorch berechneten Gewichte. Lassen Sie uns ein wenig NumPy-Magie anwenden, den CNN-Block und den CRF-Decoder sorgfältig implementieren. Das Auspacken der quantisierten Einbettung dauert 5 Zeilen . Die Inferenzgeschwindigkeit auf der CPU ist dieselbe wie bei ONNXRuntime und PyTorch, 25 Nachrichtenartikeln pro Sekunde auf Core i5.
Die Technik funktioniert bei komplexeren Modellen: Slovnet Morph und Slovnet Syntax sind auch in NumPy implementiert. Slovnet NER, Morph und Syntax haben eine gemeinsame Einbettungstabelle. Nehmen wir die Gewichte in einer separaten Datei heraus, die Tabelle wird nicht im Speicher und auf der Festplatte dupliziert:
>>> navec = Navec.load('navec_news_v1_1B.tar') # 25MB
>>> morph = Morph.load('slovnet_morph_news_v1.tar') # 2MB
>>> syntax = Syntax.load('slovnet_syntax_news_v1.tar') # 3MB
>>> ner = NER.load('slovnet_ner_news_v1.tar') # 2MB
# 25 + 2 + 3 + 2 25+2 + 25+3 + 25+2
>>> morph.navec(navec)
>>> syntax.navec(navec)
>>> ner.navec(navec)
Einschränkungen
Natasha extrahiert Standardentitäten: Namen, Namen von Toponymen und Organisationen. Die Lösung zeigt gute Qualität in den Nachrichten. Wie arbeite ich mit anderen Entitäten und Textarten? Wir müssen ein neues Modell trainieren. Das ist nicht einfach. Wir zahlen für die kompakte Größe und Geschwindigkeit der Arbeit durch die Komplexität der Modellvorbereitung. Skript-Laptop zur Vorbereitung eines schweren Lehrermodells , Skript-Laptop für ein Schülermodell , Anweisungen zur Vorbereitung quantisierter Einbettungen .
Navec - kompakte Einbettungen für die russische Sprache

Kompakte Modelle sind bequem zu handhaben. Sie starten schnell, verbrauchen wenig Speicher und mehr parallele Prozesse passen auf eine Instanz.
In NLP befinden sich 80-90% der Modellgewichte in der Einbettungstabelle. Die Navec-Bibliothek ist Teil des Natasha-Projekts, einer Sammlung vorgefertigter Einbettungen für die russische Sprache. In Bezug auf die intrinsischen Qualitätsmetriken liegen sie geringfügig unter den Top-Lösungen von RusVectores , aber die Größe des Archivs mit Gewichten ist 5-6-mal kleiner (51 MB), das Wörterbuch ist 2-3-mal größer (500 KB).
| Qualität * | Modellgröße, MB | Wörterbuchgröße × 10 3 | |
| Navec | 0,719 | 50.6 | 500 |
| RusVectores | 0,638-0,726 | 220,6–290,7 | 189-249 |
Wir werden über die guten alten Wort-für-Wort-Einbettungen sprechen, die NLP 2013 revolutioniert haben. Die Technologie ist bis heute relevant. Im Natasha-Projekt arbeiten Modelle zum Parsen von Morphologie , Syntax und Extraktion benannter Entitäten an wortweisen Navec-Einbettungen und zeigen Qualität vor anderen offenen Lösungen .
RusVectores
Für die russische Sprache ist es üblich, vorab trainierte Einbettungen von RusVectores zu verwenden . Sie haben eine unangenehme Eigenschaft: Die Tabelle enthält keine Wörter, sondern Paare „word_POS-tag“. Die Idee ist gut, für das Paar "Ofen_VERB" erwarten wir einen Vektor ähnlich "cook_VERB", "cook_VERB" und für "Ofen_NOUN" - "hut_NOUN", "Ofen_NOUN".
In der Praxis ist es unpraktisch, solche Einbettungen zu verwenden. Es reicht nicht aus, den Text in Token zu unterteilen, für jeden müssen Sie das POS-Tag irgendwie definieren. Der Einbettungstisch schwillt an. Anstelle eines Wortes "werden" speichern wir 6: 2 vernünftige "werden_VERB", "werden_NOUN" und 4 seltsame "werden_ADV", "werden_PROPN", "werden_NUM", "werden_ADJ". Eine Tabelle mit 250.000 Einträgen enthält 195.000 eindeutige Wörter.
Qualität
Lassen Sie uns die Qualität der Einbettungen für das Problem der semantischen Nähe abschätzen. Nehmen wir ein paar Wörter, für jedes finden wir einen Einbettungsvektor und berechnen die Kosinusähnlichkeit. Navec für ähnliche Wörter "Tasse" und "Krug" gibt 0,49 zurück, für "Obst" und "Ofen" - -0,0047. Sammeln wir viele Paare mit ähnlichen Ähnlichkeitsmerkmalen und berechnen die Spearman-Korrelation mit unseren Antworten.
Die Autoren von RusVectores verwenden eine kleine, sorgfältig überprüfte und überarbeitete Testliste von SimLex965- Paaren . Fügen wir einen neuen Yandex LRWC und Datensätze aus dem RUSSE-Projekt hinzu : HJ , RT , AE , AE2 :
| Durchschnittliche Qualität von 6 Datensätzen | Ladezeit Sekunden | Modellgröße, MB | Wörterbuchgröße × 10 3 | ||
| Navec | hudlit_12B_500K_300d_100q |
0,719 | 1.0 | 50.6 | 500 |
news_1B_250K_300d_100q |
0,653 | 0,5 | 25.4 | 250 | |
| RusVectores | ruscorpora_upos_cbow_300_20_2019 |
0,692 | 3.3 | 220,6 | 189 |
ruwikiruscorpora_upos_skipgram_300_2_2019 |
0,691 | 5.0 | 290.0 | 248 | |
tayga_upos_skipgram_300_2_2019 |
0,726 | 5.2 | 290.7 | 249 | |
tayga_none_fasttextcbow_300_10_2019 |
0,638 | 8.0 | 2741.9 | 192 | |
araneum_none_fasttextcbow_300_5_2018 |
0,664 | 16.4 | 2752.1 | 195 |
Die Qualität ist
hudlit_12B_500K_300d_100qvergleichbar oder besser als die von RusVectores-Lösungen, das Wörterbuch ist 2-3 mal größer, die Modellgröße ist 5-6 mal kleiner. Wie sind Sie zu dieser Qualität und Größe gekommen?
Arbeitsprinzip
hudlit_12B_500K_300d_100q- GloVe-Einbettungen für 145 GB Fiktion . Nehmen wir das Archiv mit den Texten aus dem RUSSE-Projekt . Verwenden wir die ursprüngliche GloVe-Implementierung in C und verpacken sie in eine praktische Python-Oberfläche .
Warum nicht word2vec? Experimente mit einem großen Datensatz sind mit GloVe schneller. Nachdem wir die Kollokationsmatrix berechnet haben, verwenden Sie sie, um Einbettungen mit verschiedenen Dimensionen vorzubereiten. Wählen Sie die beste Option.
Warum nicht fastText? Im Natasha-Projekt arbeiten wir mit Nachrichtentexten. Es gibt nur wenige Tippfehler, das Problem der OOV-Token wird durch ein großes Wörterbuch gelöst. 250.000 Zeilen in der Tabelle
news_1B_250K_300d_100qdecken 98% der Wörter in Nachrichtenartikeln ab.
Wörterbuchgröße
hudlit_12B_500K_300d_100q- 500.000 Einträge, 98% der Wörter in Belletristik-Texten. Die optimale Dimension von Vektoren beträgt 300. Eine Tabelle mit 500.000 × 300 Gleitkommazahlen benötigt 578 MB, die Größe des Archivs mit Gewichten hudlit_12B_500K_300d_100qist 12-mal kleiner (48 MB). Es geht um Quantisierung.
Quantisierung
Ersetzen Sie 32-Bit-Gleitkommazahlen durch 8-Bit-Codes: [−∞, −0.86) - Code 0, [−0.86, -0.79) - Code 1, [-0.79, -0.74) - 2,…, [0.86, ∞) - 255. Die Größe der Tabelle wird um das 4-fache (143 MB) reduziert.
:
-0.220 -0.071 0.320 -0.279 0.376 0.409 0.340 -0.329 0.400
0.046 0.870 -0.163 0.075 0.198 -0.357 -0.279 0.267 0.239
0.111 0.057 0.746 -0.240 -0.254 0.504 0.202 0.212 0.570
0.529 0.088 0.444 -0.005 -0.003 -0.350 -0.001 0.472 0.635
────── ──────
-0.170 0.677 0.212 0.202 -0.030 0.279 0.229 -0.475 -0.031
────── ──────
:
63 105 215 49 225 230 219 39 228
143 255 78 152 187 34 49 204 198
163 146 253 58 55 240 188 191 246
243 155 234 127 127 35 128 237 249
─── ───
76 251 191 188 118 207 195 18 118
─── ───
Die Daten sind grob, unterschiedliche Werte -0.005 und -0.003 ersetzen einen Code 127, -0.030 und -0.031 - 118
Ersetzen wir durch den Code nicht eine, sondern 3 Zahlen. Wir gruppieren alle Triplets von Zahlen aus der Einbettungstabelle unter Verwendung des k-means-Algorithmus in 256 Cluster. Anstelle jedes Triplets speichern wir einen Code von 0 bis 255. Die Tabelle wird um das Dreifache (48 MB) verringert. Navec verwendet die PQk-means-Bibliothek , teilt die Matrix in 100 Spalten auf, gruppiert jede einzeln, die Qualität bei synthetischen Tests sinkt um 1 Prozentpunkt. Über die Quantisierung wird im Artikel Produktquantisierer für k-NN klar .
Quantisierte Einbettungen sind langsamer als üblich. Der komprimierte Vektor muss vor der Verwendung entpackt werden. Wir implementieren das Verfahren sorgfältig und wenden Numpy Magic anIn PyTorch verwenden wir torch.gather . In Slovnet NER nimmt der Zugriff auf die Einbettungstabelle 0,1% der gesamten Rechenzeit in Anspruch.
Ein Modul
NavecEmbeddingaus der Slovnet-Bibliothek integriert Navec in PyTorch-Modelle:
>>> import torch
>>> from navec import Navec
>>> from slovnet.model.emb import NavecEmbedding
>>> path = 'hudlit_12B_500K_300d_100q.tar' # 51MB
>>> navec = Navec.load(path) # ~1 sec, ~100MB RAM
>>> words = ['', '<unk>', '<pad>']
>>> ids = [navec.vocab[_] for _ in words]
>>> emb = NavecEmbedding(navec)
>>> input = torch.tensor(ids)
>>> emb(input) # 3 x 300
tensor([[ 4.2000e-01, 3.6666e-01, 1.7728e-01,
[ 1.6954e-01, -4.6063e-01, 5.4519e-01,
[ 0.0000e+00, 0.0000e+00, 0.0000e+00,
...Nerus ist ein großer synthetischer Datensatz mit Markup von Morphologie, Syntax und benannten Entitäten

Im Natasha-Projekt werden die Analyse der Morphologie, Syntax und Extraktion benannter Entitäten anhand von drei kompakten Modellen durchgeführt: Slovnet NER , Slovnet Morph und Slovnet Syntax . Die Qualität der Lösungen ist 1–5 Prozentpunkte schlechter als die ihrer schweren Kollegen mit einer BERT-Architektur, die Größe ist 50–75-mal kleiner und die Geschwindigkeit auf der CPU ist 2-mal höher. Die Modelle werden auf einem riesigen synthetischen Nerus-Datensatz in einem Archiv von 700.000 Nachrichtenartikeln mit CoNLL-U- Markup von Morphologie, Syntax und benannten Entitäten trainiert :
# newdoc id = 0
# sent_id = 0_0
# text = - , ...
1 - _ NOUN _ Animacy=Anim|C... 7 nsubj _ Tag=O
2 _ ADP _ _ 4 case _ Tag=O
3 _ ADJ _ Case=Dat|Degre... 4 amod _ Tag=O
4 _ NOUN _ Animacy=Inan|C... 1 nmod _ Tag=O
5 _ PROPN _ Animacy=Anim|C... 1 appos _ Tag=B-PER
6 _ PROPN _ Animacy=Anim|C... 5 flat:name _ Tag=I-PER
7 _ VERB _ Aspect=Perf|Ge... 0 root _ Tag=O
8 , _ PUNCT _ _ 13 punct _ Tag=O
9 _ ADP _ _ 11 case _ Tag=O
10 _ DET _ Case=Loc|Numbe... 11 det _ Tag=O
11 _ NOUN _ Animacy=Inan|C... 13 obl _ Tag=O
12 _ PROPN _ Animacy=Inan|C... 11 nmod _ Tag=B-LOC
13 _ VERB _ Aspect=Perf|Ge... 7 ccomp _ Tag=O
14 _ ADV _ Degree=Pos 15 advmod _ Tag=O
15 _ ADJ _ Case=Nom|Degre... 16 amod _ Tag=O
16 _ NOUN _ Animacy=Inan|C... 13 nsubj _ Tag=O
17 _ ADP _ _ 18 case _ Tag=O
18 _ NOUN _ Animacy=Inan|C... 16 nmod _ Tag=O
19 , _ PUNCT _ _ 20 punct _ Tag=O
20 _ VERB _ Aspect=Imp|Moo... 0 root _ Tag=O
21 _ PROPN _ Animacy=Inan|C... 20 nsubj _ Tag=B-ORG
22 _ PROPN _ Animacy=Inan|C... 21 appos _ Tag=I-ORG
23 . _ PUNCT _ _ 20 punct _ Tag=O
# sent_id = 0_1
# text = , , , ...
1 _ ADP _ _ 2 case _ Tag=O
2 _ NOUN _ Animacy=Inan|C... 9 parataxis _ Tag=O
...Slovnet NER, Morph, Syntax - primitive Modelle. Wenn das Trainingsset 1000 Beispiele enthält, liegt Slovnet NER um 11 Prozentpunkte hinter dem schweren BERT-Analogon zurück, wenn 10.000 Beispiele - um 3 Punkte, wenn 500.000 - um 1 liegen.
Nerus ist das Ergebnis von Arbeit, schwere Modelle mit BERT-Architektur: Slovnet BERT NER , Slovnet BERT Morph , Slovnet BERT Syntax . Die Verarbeitung von 700.000 Nachrichtenartikeln dauert auf dem Tesla V100 20 Stunden. Wir sparen anderen Forschern Zeit und stellen das fertige Archiv offen zur Verfügung. Bereiten Sie in SpaCy-Ru bei Nerus ein qualitatives Modell für das russischsprachige SpaCy vor und bereiten Sie einen Patch im offiziellen Repository vor.

Synthetisches Markup hat eine hohe Qualität: Die Genauigkeit der Bestimmung morphologischer Tags beträgt 98%, syntaktische Verknüpfungen 96%. Für NER schätzt F1 nach Token: PER - 99%, LOC - 98%, ORG - 97%. Um die Qualität zu beurteilen, markieren wir SynTagRus , Collection5 und das News-Slice GramEval2020 , vergleichen das Referenz-Markup mit unserem. Weitere Informationen finden Sie im Nerus-Repository . Aufgrund von Fehlern im Syntax-Markup gibt es Schleifen und mehrere Roots. POS-Tags entsprechen manchmal nicht den syntaktischen Kanten. Es ist nützlich, den Validator aus Universal Dependencies zu verwenden . Überspringen Sie solche Beispiele.
Das Python-Paket Nerus organisiert eine praktische Oberfläche zum Laden und Rendern von Markups:
>>> from nerus import load_nerus
>>> docs = load_nerus('nerus_lenta.conllu.gz')
>>> doc = next(docs)
>>> doc
NerusDoc(
id='0',
sents=[NerusSent(
id='0_0',
text='- , ...',
tokens=[NerusToken(
id='1',
text='-',
pos='NOUN',
feats={'Animacy': 'Anim',
'Case': 'Nom',
'Gender': 'Masc',
'Number': 'Sing'},
head_id='7',
rel='nsubj',
tag='O'
),
NerusToken(
id='2',
text='',
pos='ADP',
...
>>> doc.ner.print()
- ,
PER───────────── LOC───
, . ,
ORG──────── PER──────
...
>>> sent = doc.sents[0]
>>> sent.morph.print()
- NOUN|Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing
ADP
ADJ|Case=Dat|Degree=Pos|Number=Plur
NOUN|Animacy=Inan|Case=Dat|Gender=Masc|Number=Plur
PROPN|Animacy=Anim|Case=Nom|Gender=Fem|Number=Sing
PROPN|Animacy=Anim|Case=Nom|Gender=Fem|Number=Sing
VERB|Aspect=Perf|Gender=Fem|Mood=Ind|Number=Sing
...
>>> sent.syntax.print()
┌►┌─┌───── - nsubj
│ │ │ ┌──► case
│ │ │ │ ┌► amod
│ │ └►└─└─ nmod
│ └────►┌─ appos
│ └► flat:name
┌─└─────────
│ ┌──────► , punct
│ │ ┌──► case
│ │ │ ┌► det
│ │ ┌►└─└─ obl
│ │ │ └──► nmod
└──►└─└───── ccomp
│ ┌► advmod
│ ┌►└─ amod
└►┌─└─── nsubj:pass
│ ┌► case
└──►└─ nmod
┌► , punct
┌─┌─└─
│ └►┌─ nsubj
│ └► appos
└────► . punct
Installationsanweisungen, Anwendungsbeispiele , Qualitätsbewertungen im Nerus-Repository.
Corus - eine Sammlung von Links zu öffentlichen russischsprachigen Datensätzen + Funktionen zum Herunterladen

Die Corus-Bibliothek ist Teil des Natasha-Projekts, einer Sammlung von Links zu öffentlichen russischsprachigen NLP-Datensätzen + Python-Paket mit Ladefunktionen. Liste der Links zu Quellen , Installationsanweisungen und Anwendungsbeispiele im Corus-Repository.
>>> from corus import load_lenta
# Corus Lenta.ru, :
# wget https://github.com/yutkin/Lenta.Ru-News-Dataset/...
>>> path = 'lenta-ru-news.csv.gz'
>>> records = load_lenta(path) # 2, 750 000
>>> next(records)
LentaRecord(
url='https://lenta.ru/news/2018/12/14/cancer/',
title=' \xa0 ...',
text='- ...',
topic='',
tags=''
)
Nützliche offene Datensätze für die russische Sprache sind so gut versteckt, dass nur wenige Menschen davon wissen.
Beispiele von
Korpus von Nachrichtenartikeln
Wir wollen das Sprachmodell auf Nachrichtenartikeln trainieren, wir brauchen viele Texte. Das erste, was mir in den Sinn kommt, ist ein News-Slice des Taiga-Datensatzes (~ 1 GB). Viele Leute kennen den Lenta.ru-Dump (2 GB). Andere Quellen sind schwieriger zu finden. Im Jahr 2019 veranstaltete Dialogue einen Wettbewerb zur Generierung von Schlagzeilen . Die Organisatoren bereiteten 4 Jahre lang einen Dump von RIA Novosti (3,7 GB) vor. Im Jahr 2018 veröffentlichte Juri Baburow einen Upload aus 40 russischsprachigen Nachrichtenquellen (7,5 GB). Freiwillige von ODS teilen die Archive (7 GB), die für das Projekt zur Analyse der Nachrichtenagenda gesammelt wurden .
In der Corus-RegistrierungLinks zu diesen Datensätzen getaggt «News», für alle Quellen eine Funktion Ladern haben:
load_taiga_*, load_lenta, load_ria, load_buriy_*, load_ods_*.
NER
Wir wollen NER für die russische Sprache unterrichten, wir brauchen kommentierte Texte. Zunächst erinnern wir uns an die Daten des factRuEval-2016-Wettbewerbs . Das Markup hat Nachteile: Sein komplexes Format, Entitätsbereiche überlappen sich, es gibt mehrdeutige "LocOrg" -Kategorien. Nicht jeder kennt die Named Entities 5-Sammlung, den Nachfolger von Persons-1000 . Layout im Standardformat , Spannweiten überschneiden sich nicht, Schönheit! Die anderen drei Quellen sind nur den engagiertesten Fans der russischsprachigen NER bekannt. Wir werden Rinat Gareev per E-Mail schreiben, einen Link zu seinem Artikel von 2013 anhängen und als Antwort 250 Nachrichtenartikel mit getaggten Namen und Organisationen erhalten. BSNLP-2019 Wettbewerb wurde im Jahr 2019 stattÜber NER für slawische Sprachen werden wir an die Organisatoren schreiben, wir werden 450 weitere markierte Texte erhalten. Das WiNER-Projekt hatte die Idee, halbautomatisches NER-Markup aus Wikipedia-Dumps zu erstellen . Ein großer Download für Russisch ist auf Github verfügbar .
Links und Funktionen des Registers Corus laden:
load_factru, load_ne5, load_gareev, load_bsnlp, load_wikiner.
Sammlung von Links
Bevor Sie einen Bootloader erhalten und in die Registrierung gelangen, werden im Abschnitt mit Tickets Links zu Quellen gesammelt . Die Sammlung von 30 Datensatz: eine neue Version von Taiga , 568GB russischem Text von Crawl der gemeinsamen , Bewertungen c Banki.ru und Auto.ru . Wir laden Sie ein, Ihre Ergebnisse zu teilen und Tickets mit Links zu erstellen.
Laderfunktionen
Der Code für einen einfachen Datensatz ist einfach selbst zu schreiben. Der Lenta.ru-Dump ist wohlgeformt, die Implementierung ist einfach . Taiga besteht aus ~ 15 Millionen CoNLL-U- Zip-Dateien. Damit der Download schnell funktioniert, nicht viel Speicher benötigt und das Dateisystem nicht ruiniert wird, müssen Sie verwirrt sein und die Arbeit mit Zip-Dateien auf niedriger Ebene sorgfältig implementieren .
Für 35 Quellen verfügt das Corus Python-Paket über Ladefunktionen. Die Schnittstelle für den Zugriff auf Taiga ist nicht komplizierter als der Lenta.ru-Dump:
>>> from corus import load_taiga_proza_metas, load_taiga_proza
>>> path = 'taiga/proza_ru.zip'
>>> metas = load_taiga_proza_metas(path)
>>> records = load_taiga_proza(path, metas)
>>> next(records)
TaigaRecord(
id='20151231005',
meta=Meta(
id='20151231005',
timestamp=datetime.datetime(2015, 12, 31, 23, 40),
genre=' ',
topic='',
author=Author(
name='',
readers=7973,
texts=92681,
url='http://www.proza.ru/avtor/sadshoot'
),
title=' !',
url='http://www.proza.ru/2015/12/31/1875'
),
text='... ...\n... ..\n...
)
Wir laden Benutzer ein, Pull-Anfragen zu stellen, ihre Loader-Funktionen zu senden und eine kurze Anweisung im Corus-Repository zu geben.
Naeval - quantitativer Vergleich von Systemen für russischsprachiges NLP

Natasha ist kein wissenschaftliches Projekt, es gibt kein Ziel, SOTA zu schlagen, aber es ist wichtig, die Qualität an öffentlichen Benchmarks zu überprüfen, um zu versuchen, einen hohen Platz einzunehmen, ohne viel an Leistung zu verlieren. Wie in der Akademie: Messen Sie die Qualität, erhalten Sie eine Nummer, nehmen Sie Tabletten aus anderen Artikeln, vergleichen Sie diese Zahlen mit ihren eigenen. Dieses Schema hat zwei Probleme:
- Vergessen Sie die Leistung. Sie vergleichen nicht die Größe des Modells, die Arbeitsgeschwindigkeit. Der Schwerpunkt liegt nur auf Qualität.
- Veröffentlichen Sie den Code nicht. Bei der Berechnung einer Qualitätsmetrik gibt es normalerweise eine Million Nuancen. Wie genau wurde es in anderen Artikeln gezählt? Unbekannt.
Naeval ist Teil des Natasha-Projekts, einer Reihe von Skripten zur Bewertung der Qualität und Geschwindigkeit von Open-Source-Tools zur Verarbeitung der natürlichen russischen Sprache:
| Aufgabe | Datensätze | Lösungen |
| Tokenisierung | SynTagRus, OpenCorpora, GICRYA, RNC
|
SpaCy, NLTK, MyStem, Moses, SegTok, SpaCy Russian Tokenizer, RuTokenizer, Razdel
|
| SynTagRus, OpenCorpora, GICRYA, RNC
|
SegTok, Moses, NLTK, RuSentTokenizer, Razdel
|
|
| SimLex965, HJ, LRWC, RT, AE, AE2
|
RusVectores, Navec
|
|
| GramRuEval2020 (SynTagRus, GSD, Lenta.ru, Taiga)
|
DeepPavlov Morph, DeepPavlov BERT Morph, RuPosTagger, RNNMorph, Maru, UDPipe, SpaCy, Stanza, Slovnet Morph, Slovnet BERT Morph
|
|
| GramRuEval2020 (SynTagRus, GSD, Lenta.ru, Taiga)
|
DeepPavlov BERT Syntax, UDPipe, SpaCy, Stanza, Slovnet Syntax, Slovnet BERT Syntax
|
|
| NER | factRuEval-2016, Collection5, Gareev, BSNLP-2019, WiNER
|
DeepPavlov NER , DeepPavlov BERT NER , DeepPavlov Slavic BERT NER , PullEnti , SpaCy , Strophe , Texterra , Tomita , MITIE , Slovnet NER , Slovnet BERT NER
|
Schauen wir uns das NER-Problem unten genauer an.
Datensätze
Es gibt 5 öffentliche Benchmarks für das russischsprachige NER: factRuEval-2016 , Collection5 , Gareev , BSNLP-2019 , WiNER . Quelllinks werden in der Corus-Registrierung gesammelt . Alle Datensätze bestehen aus Nachrichtenartikeln, Teilzeichenfolgen mit Namen, Namen von Organisationen und Ortsnamen sind in den Texten markiert. Was könnte einfacher sein?
Alle Quellen haben ein anderes Markup-Format. Collection5 verwendet das Standoff-Format der Dienstprogramme Brat , Gareev und WiNER - verschiedene Dialekte des BIO- Markups, BSNLP-2019 hat ein eigenes Format , factRuEval-2016 hat auch eine eigene nicht triviale Spezifikation... Naeval konvertiert alle Quellen in ein gemeinsames Format. Das Markup besteht aus Spannen. Spanne - drei: Entitätstyp, Anfang und Ende der Teilzeichenfolge.
Entitätstypen. factRuEval-2016 und Collection5 kennzeichnen Halbnamen-Halborganisationen getrennt: "Kreml", "EU", "UdSSR". BSNLP-2019 und WiNER heben die Namen der Veranstaltungen hervor: "Championship of Russia", "Brexit". Naeval passt einige der Tags an und entfernt sie. Die Referenz-Tags PER, LOC, ORG bleiben übrig: Namen von Personen, Namen von Toponymen und Organisationen.
Verschachtelte Bereiche. In der Tat, RuEval-2016, überlappen sich die Bereiche. Naeval vereinfacht das Markup:
:
, 5 Retail Group,
org_name───────
Org────────────
"", "" "",
org_descr───── org_name─ org_name─── org_name
Org──────────────────────
org_descr─────
Org─────────────────────────────────────
org_descr─────
Org──────────────────────────────────────────────────
, .
:
, 5 Retail Group,
ORG────────────
"", "" "",
ORG────── ORG──────── ORG─────
, .
Modelle
Naeval vergleicht 12 offene Lösungen mit dem russischen NER-Problem. Alle Tools sind in Docker-Containern mit einer Weboberfläche verpackt :
$ docker run -p 8080:8080 natasha/tomita-algfio
2020-07-02 11:09:19 BIN: 'tomita-linux64', CONFIG: 'algfio'
2020-07-02 11:09:19 Listening http://0.0.0.0:8080
$ curl -X POST http://localhost:8080 --data \
' \
\
'
<document url="" di="5" bi="-1" date="2020-07-02">
<facts>
<Person pos="18" len="16" sn="0" fw="2" lw="3">
<Name_Surname val="" />
<Name_FirstName val="" />
<Name_SurnameIsDictionary val="1" />
</Person>
<Person pos="67" len="14" sn="0" fw="8" lw="9">
<Name_Surname val="" />
<Name_FirstName val="" />
<Name_SurnameIsDictionary val="1" />
</Person>
</facts>
</document>
Einige Lösungen sind so schwer zu starten und zu konfigurieren, dass nur wenige Benutzer sie verwenden. PullEnti , ein ausgeklügeltes regelbasiertes System, belegte 2016 den ersten Platz im factRuEval-Wettbewerb. Das Tool wird als SDK für C # verteilt. Die Arbeit an Naeval führte zu einem separaten Projekt mit einer Reihe von Wrappern für PullEnti: PullentiServer ist ein C # -Webserver , Pullenti-Client ist ein Python-Client für PullentiServer:
$ docker run -p 8080:8080 pullenti/pullenti-server
2020-07-02 11:42:02 [INFO] Init Pullenti v3.21 ...
2020-07-02 11:42:02 [INFO] Load lang: ru, en
2020-07-02 11:42:03 [INFO] Load analyzer: geo, org, person
2020-07-02 11:42:05 [INFO] Listen prefix: http://*:8080/
>>> from pullenti_client import Client
>>> client = Client('localhost', 8080)
>>> text = ' ' \
... ' ' \
... ' '
>>> result = client(text)
>>> result.graph
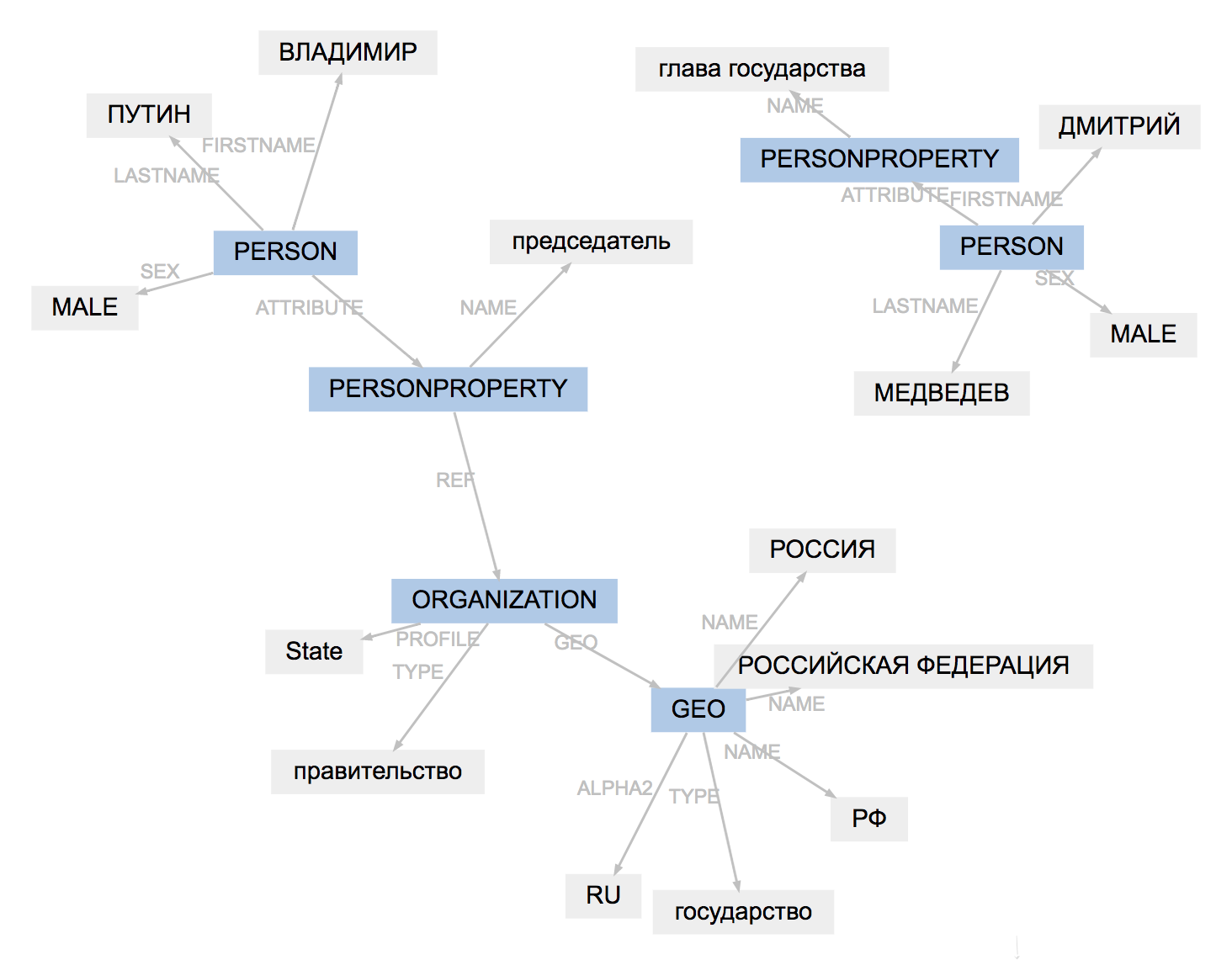
Das Markup-Format für alle Tools unterscheidet sich geringfügig. Naeval lädt Ergebnisse, passt Entitätstypen an und vereinfacht die Struktur von Spannen:
(PullEnti):
, 19
ORGANIZATION──────────
GEO─────────
PERSON────────────────
PERSONPROPERTY───────
──────────────── PERSON───────────────────────
PERSONPROPERTY──────────────
ORGANIZATION───
.
────────────────
:
, 19
ORG────── LOC─────────
PER───────────── ORG────────────
.
PER─────────────
Das Ergebnis von PullEntis Arbeit ist schwieriger anzupassen als das factRuEval-2016-Markup. Der Algorithmus entfernt das PERSONPROPERTY-Tag, teilt die verschachtelte PERSON, ORGANISATION und GEO in nicht überlappende PER, LOC, ORG auf.
Vergleich
Für jedes Paar "Modell, Datensatz" berechnet Naeval das F1-Maß anhand von Token und veröffentlicht eine Tabelle mit Qualitätsbewertungen .
Natasha ist kein wissenschaftliches Projekt, die Praktikabilität der Lösung ist für uns wichtig. Naeval misst Startzeit, Laufgeschwindigkeit, Modellgröße und RAM-Verbrauch. Die Tabelle mit den Ergebnissen im Repository .
Wir haben Datensätze vorbereitet, 20 Systeme in Docker-Container verpackt und Metriken für 5 andere Aufgaben des russischsprachigen NLP berechnet. Das Ergebnis ist das Naeval-Repository: Tokenisierung , Segmentierung in Sätze , Einbettungen , Morphologie und Syntaxanalyse .
Yargy- —

Der Yargy-Parser ist ein Analogon zum Yandex Tomita-Parser für Python. Installationsanweisungen , Anwendungsbeispiel , Dokumentation im Yargy-Repository. Die Regeln zum Extrahieren von Entitäten werden mit kontextfreien Grammatiken und Wörterbüchern beschrieben. Vor zwei Jahren schrieb ich über Habr einen Artikel über Yargy und die Natasha-Bibliothek , in dem es darum ging, das NER-Problem für die russische Sprache zu lösen. Das Projekt wurde gut aufgenommen. Yargy-Parser ersetzte Tomita in großen Projekten innerhalb von Sberbank, Interfax und RIA Novosti. Viele Lehrmaterialien sind erschienen. Ein großes Video aus einem Workshop in Yandex, anderthalb Stunden über den Prozess der Grammatikentwicklung mit Beispielen:
Die Dokumentation wurde aktualisiert, ich habe den Einführungsabschnitt und das Nachschlagewerk gekämmt . Am wichtigsten ist, dass das Kochbuch erschienen ist - ein Abschnitt mit nützlichen Praktiken. Es enthält Antworten auf die am häufigsten gestellten Fragen von t.me/natural_language_processing :
- wie man einen Teil des Textes überspringt ;
- wie man Token einreicht, nicht Text ;
- was zu tun ist, wenn der Parser verlangsamt .
Yargy Parser ist ein komplexes Werkzeug. Das Kochbuch beschreibt die nicht offensichtlichen Punkte, die bei der Arbeit mit großen Regelwerken auftreten:
- Reihenfolge der Argumente in or_ ;
- mehrdeutige Grammatiken ;
- Warum ist das Tagger-Argument in Parser .
Im Yargy-Labor laufen mehrere große Dienste. Ich habe den Code erneut gelesen und Muster im Kochbuch gesammelt, die nicht öffentlich beschrieben werden:
- Generierung von Regeln ;
- Vererbung Tatsache (besonders nützlich, keine Lösung in der Praxis kann ohne diese Technik auskommen).
Nach dem Lesen der Dokumentation ist es hilfreich, sich das Repository mit Beispielen anzusehen :
Das Natasha-Projekt verfügt auch über ein Natasha-Verwendungs- Repository . Hier setzt der Code der auf Github veröffentlichten Yargy-Parser-Benutzer an. 80% der Links sind Bildungsprojekte, aber es gibt auch informative Beispiele:
- Analyse des Feeds über die Arbeit der U-Bahn in St. Petersburg ;
- Analyse von Anzeigen für die Anmietung von Wohnraum in sozialen Netzwerken ;
- Extraktion von Attributen aus den Namen von Autoreifen ;
- Parsen von offenen Stellen aus dem Jobkanal des ODS-Chats ;
Die interessantesten Fälle der Verwendung des Yargy-Parsers werden natürlich nicht öffentlich auf Github veröffentlicht. Schreiben Sie an PM, wenn das Unternehmen Yargy verwendet, und fügen Sie, wenn Sie nichts dagegen haben, Ihr Logo zu natasha.github.io hinzu .
Ipymarkup - Visualisierung von Markups für benannte Entitäten und syntaktischen Beziehungen

Ipymarkup ist eine primitive Bibliothek, die zum Hervorheben von Teilzeichenfolgen in Text- und NER-Visualisierungen benötigt wird. Installationsanweisungen , Beispiel für die Verwendung im Ipymarkup-Repository. Die Bibliothek ähnelt DisplaCy und DisplaCy ENT und ist für das Debuggen von Grammatiken für Yargy-Parser von unschätzbarem Wert.
>>> from yargy import Parser
>>> from ipymarkup import show_span_box_markup as show_markup
>>> parser = Parser(...)
>>> text = '...'
>>> matches = parser.findall(text)
>>> spans = [_.span for _ in matches]
>>> show_markup(text, spans)

Das Natasha-Projekt hat eine Lösung für das Parsing-Problem . Es war notwendig, nicht nur Wörter im Text hervorzuheben, sondern auch Pfeile zwischen ihnen zu zeichnen. Es gibt viele vorgefertigte Lösungen, es gibt sogar einen wissenschaftlichen Artikel zu diesem Thema .
Natürlich passte keiner der vorhandenen, und eines Tages war ich wirklich verwirrt, wandte die berühmte Magie von CSS und HTML an und fügte Ipymarkup eine neue Visualisierung hinzu. Gebrauchsanweisung im Dock.
>>> from ipymarkup import show_dep_markup
>>> words = ['', '', '', '', '', '', '-', '', '', '', '', '', '', '', '.']
>>> deps = [(2, 0, 'case'), (2, 1, 'amod'), (10, 2, 'obl'), (2, 3, 'nmod'), (10, 4, 'obj'), (7, 5, 'compound'), (5, 6, 'punct'), (4, 7, 'nmod'), (9, 8, 'case'), (4, 9, 'nmod'), (13, 11, 'case'), (13, 12, 'nummod'), (10, 13, 'nsubj'), (10, 14, 'punct')]
>>> show_dep_markup(words, deps)
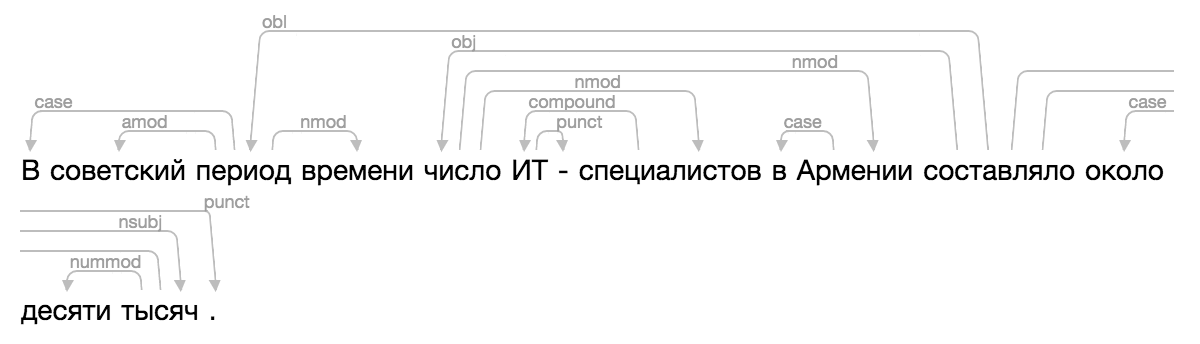
Jetzt in Natasha und Nerus ist es bequem, die Ergebnisse des Parsens zu sehen.
