Data Scientists finden heraus, woran Menschen interessiert sind und wofür sie ihr Geld ausgeben
Bei der Untersuchung verschiedener Zielgruppen beobachten Data Scientists sowohl natürliche als auch überraschende Fakten, die die Gesellschaft um uns herum lebendig charakterisieren. In diesem Artikel werde ich auf die Kuriositäten und ungewöhnlichen Fälle eingehen, die mir bei der Durchführung von Aufgaben im Zusammenhang mit der Prüfungsanalyse, der Untersuchung der Interessen von Internetnutzern und des Kaufverhaltens verschiedener sozialer Gruppen aufgefallen sind.
Welche soziologischen Merkmale wurden durch die Verwendung von Modellen des maschinellen Lernens identifiziert? Was wissen wir über Kunden?

Kundenprofil von seinem Scheck? Einfach!
Ich arbeite als Datenanalyst bei CleverDATA und stehe normalerweise vor folgenden Aufgaben: Klassifizierung von Rohdaten, Audit-Analyse und Erstellung von Look-Alike-Modellen (LaL), wenn der Kunde sein eigenes Publikum hat und ein ähnliches finden möchte. Es ist sehr gefragt für verschiedene Online-Werbekampagnen.
Wir haben 1DMC DATA Exchange, wo Mitglieder ihre Daten anreichern und monetarisieren können. Es enthält depersonalisierte Daten zweier Art, die in den Attributen unserer Taxonomie zusammengefasst sind - Online-Einkäufe und Clickstream, dh die Reihenfolge der Seitenbesuche, die wir verfolgen konnten. Das Datenformat entspricht der europäischen DSGVO-Norm für den Schutz personenbezogener Daten.
Die Attribute unserer Taxonomie sind die Tatsachen des Eigentums an einer Sache oder das Vorhandensein eines bestimmten Interesses an einer Person. Dies sind binäre Informationen - entweder dort oder nicht.
Hier einige Beispiele für unsere Taxonomieattribute:

Eine der wichtigsten Aufgaben ist die Aggregation von Rohdaten von Lieferanten zu Taxonomieattributen, dh die Klassifizierungsaufgabe.
Ich muss Schlussfolgerungen über die Einkäufe von Menschen über ihren Lebensstil ziehen und darüber, ob sie bestimmte Dinge haben (unter der Bedingung, dass eine Überprüfung eines Marken-Straßenrutenmodells wahrscheinlich anzeigt, dass der Käufer der Besitzer eines Harley-Davidson-Motorrads ist) oder potenzielles Interesse an Einkäufen von identifizieren über die Internetseiten, die sie besuchen. Diese Informationen werden dann für gezielte Werbung verwendet.

Im Verlauf meiner Arbeit erscheinen folgende Ketten:
- check - meine KI-Modelle - Käuferprofil;
- Klicken Sie auf Stream - Meine KI-Modelle - Website-Besucherprofil.
Das in CleverDATA verwendete Tool erstellt automatisch einen binären Klassifikator für jedes Attribut in unserer Taxonomie. Aus dem Namen des Taxonomie-Attributs (dem Besitzer des Chopper-Motorrad-Attributs) ergibt sich ein bereits automatisch ausgewerteter binärer Klassifikator (ob das Modell gut ist oder die Analyse verbessert werden muss), mit dem das Vorhandensein oder Fehlen eines solchen Elements in einer Person durch Prüfung festgestellt werden kann. Mehr dazu lesen Sie in unserem Artikel über Habré .

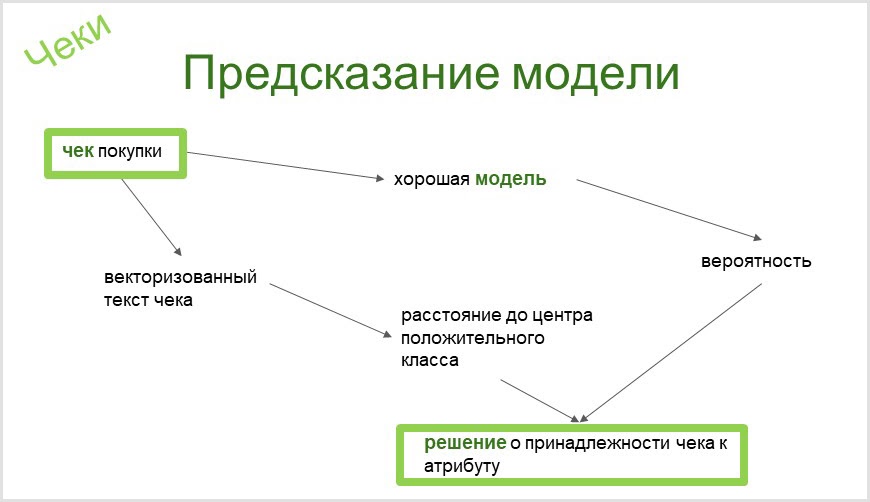
Wenn Sie Schecks klassifizieren, benötigen Sie ein Tool, mit dem Sie Schecks, die in Worten ähnlich sind, von ähnlichen Bedeutungen trennen können. Also habe ich irgendwie ein Modell gebaut, um das Interesse an professionellen Umschulungskursen zu wecken. Und sie identifizierte den Scheck für den Kauf von Paolo Cossis Kinderbuch "Ein Kurs in Zauberstunden für eine gewöhnliche Katze" als Interesse an dem Thema. Das ist natürlich ein lustiger Fehler. Übrigens habe ich durch diesen Scheck von der Existenz des Buches erfahren.

Um solche Kuriositäten zu vermeiden, haben wir Sprachmodelle verwendet, um die resultierenden binären Klassifikatoren zu bewerten und die Beispiele abzuschneiden, die in Worten ähnlich sind, aber keine Bedeutung haben.
Von Zeit zu Zeit muss ich mit meinen Augen die Belege durchsehen, um falsche Übereinstimmungen zu finden und anschließend die Suche nach solchen falsch aufgebauten Verbindungen zu automatisieren. Es kann hilfreich sein, dem auf den Grund zu gehen, denn vielleicht kann ich mit einem einzigen unverständlichen Fall den gesamten Prozess verbessern.
Im Laufe meiner gesamten Praxis habe ich eine ganze Reihe von Rätselprüfungen gesammelt, die ich nicht nur klassifizieren, sondern sogar entschlüsseln konnte, was genau der Käufer gekauft hat. Ich teile diese amüsanten Fälle regelmäßig mit Kollegen und habe sogar die Kolumne "KI-Witze" gestartet.
Der häufigste Hinweis ist die Angabe in der Prüfung des Titels des Buches ohne den Namen des Produkts. Genau das sehen wir im Fall von "Magie für eine gewöhnliche Katze". Und welche Einkäufe im Scheck "Zaun Nowosibirsk 1029 Rubel" vermerkt sind. und "Contract-Box 5000 Rubel". Ich verstehe immer noch nicht. Ich akzeptiere Ihre Versionen in den Kommentaren zu diesem Artikel.
Als nächstes fahren wir mit der Klassifizierung des Klickstroms fort.
Kundenprofil durch seine Bewegungen auf der Website
Das Clickstream-Klassifizierungssystem wurde von uns im Jahr 2019 eingeführt und war reich an Durchbrüchen im Bereich NLP (Natural Language Processing). Eine der bekanntesten und erfolgreichsten Erfindungen auf diesem Gebiet ist das BERT-Netzwerk ( Bidirectional Encoder Representations from Transformers ). Es wird also ein bisschen Bertologie vor uns liegen.

Aus dem Namen des Attributs erhalten wir unter Verwendung eines probabilistischen Sprachmodells eine erweiterte (mit Synonymen erweiterte) Liste von Abfragen, die wir crawlen (an eine Suchmaschine senden und Suchergebnisse sammeln), sodass unser Trainingsbeispiel erhalten wird. Lassen Sie es uns mit dem vorgefertigten BERT-Sprachmodell vektorisieren. Unter Verwendung der erhaltenen Einbettungen (Vektoren) trainieren wir den Klassifikator (mit der Triplettverlustfunktion).
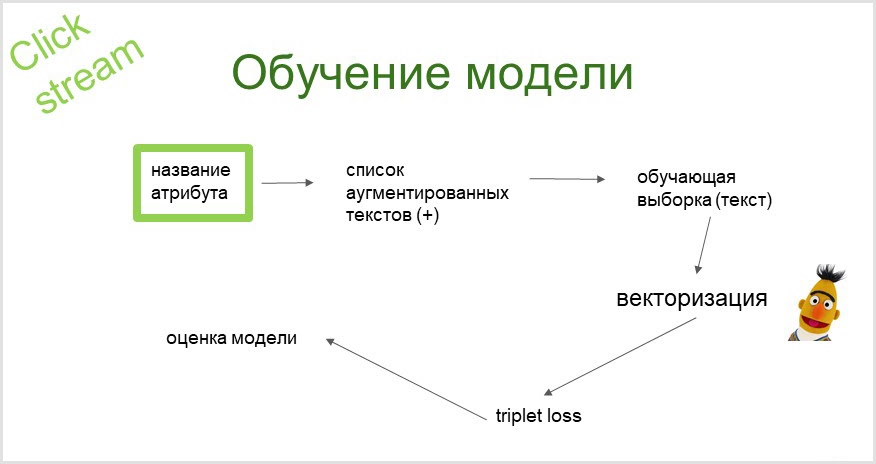
Wie funktioniert die Vorhersage?
Wir nehmen die URL der Seite, sammeln Textinformationen (Titel und Beschreibung der Seite). Mit Hilfe von BERT erhalten wir eine Vektordarstellung dieser Texte. Dann werden diese Vektoren in das Modell eingespeist und am Ausgang erhalten wir ein Attribut, auf das wir die Seite verweisen können.
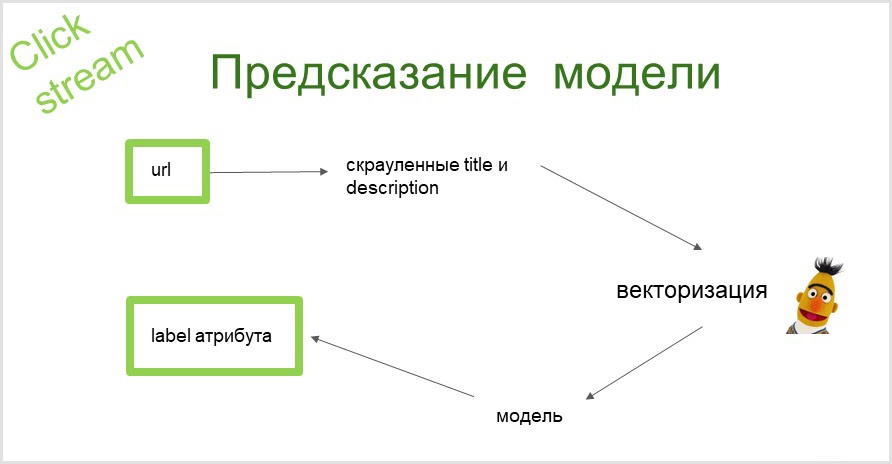
Im Allgemeinen ist dieses System sehr erfolgreich. Alle lustigen Fälle, auf die ich gestoßen bin, sind eher Ausnahmen als die Regel. Ich versuche jedoch, ihnen große Aufmerksamkeit zu schenken, da ein kleiner Fehler zu großen unangenehmen Konsequenzen führen kann, da eine große Datenmenge das System durchläuft.
Von mir recherchierte Online-Daten zeigten, dass Menschen im Internet mehr lesen. Es stellte sich heraus, dass dies eines der sehr beliebten Themen ist - Astrologie, Wahrsagerei usw.

Diese spezifischen Seiten (URLs, keine Domains) wurden täglich von über 5000.000 Personen (eindeutige Kennungen) besucht. Besonders beeindruckt hat mich die Website, die sich der Katzenastrologie widmet und die Verbindung zwischen dem Charakter des Tieres und seinem Sternzeichen aufzeigt.

Jeder kennt Stoppwörter und verbindet normalerweise Wörterbücher oder filtert nach Frequenzen, ohne tief in die Besonderheiten von Texten einzusteigen. Zuerst habe ich auch meine Wörterbücher verbunden. Das Ergebnis war nicht erfreulich: Der Ort der Rezepte ohne Verwendung von Backwaren wurde als ein Attribut von Interesse für das Backen (Backen zu Hause) eingestuft. Und das liegt daran, dass alle negativen Partikel in meinem Stoppwortwörterbuch vorhanden waren.

Anhand meines Beispiels fordere ich meine Kollegen auf, die Wörterbücher, mit denen Sie Ihre Daten filtern, sorgfältig zu lesen.
Ein weiteres häufiges Problem ist, dass Menschen häufig sarkastische Sprache verwenden, was während des Crawls zu lustigen Phrasen im Titel und in der Beschreibung von Seiten führt, die sich auf bestimmte Abfragen im Internet beziehen. Zum Beispiel kann das Modell Pasteten und Interesse an einer vegetarischen Ernährung verbinden. Es scheint mir, dass dies durch die Fülle von Kommentaren zu Artikeln zum Thema Vegetarismus im Sinne von "Wie leben Sie ohne Pasteten?" Erklärt werden kann.

Und jetzt eine Minute schwarzen Humors in unserer Überschrift "KI-Witze": Das Modell verband die Diskussion über die Legalisierung der Sterbehilfe mit dem Interesse, ein Haus zu kaufen, und Rapper Timati - mit einem Zirkus. Ich musste in die Daten kriechen und die Klasse manuell neu markieren.
Es gibt Setups, die wir nicht kontrollieren können. Sie hängen von der Gesellschaft ab, in der wir leben. Und dann wird das Verbrechen mit Komödien und familiären Beziehungen gemischt.

Und es gibt auch kontroverse Fälle, in denen Sie nicht einmal wissen, ob es sich lohnt, das Modell zu schelten und etwas neu zu gestalten, mit Fehlern zu kämpfen oder alles so zu lassen, wie es ist.
Es ist möglich, dass der Erhalt von Paketen ein Geschäftsrisiko birgt.
Alles ist am Schwarzen Brett zu finden.

Suchen Sie nach einem ähnlichen Publikum
Der nächste Aufgabenblock, den ich als Analyst lösen muss, ist Audiene Research / Look-Alike Modeling. Der Kunde möchte in der Regel neues Wissen über das Publikum, das ihm helfen soll, eine Kommunikation mit ihr aufzubauen. Aber auch wenn seine Anfrage nicht klar formuliert ist, versuchen wir immer, ihm zu helfen, und in den meisten Fällen sind wir erfolgreich.
Hier haben Sie die Wahl, ob Sie sich auf die Zielgruppenforschung konzentrieren möchten, dh auf interne Erkenntnisse (Intelligenzanalyse des Publikums) oder auf ein ähnliches Modell, mit dem Sie das Publikum unseres Austauschs beschleunigen und potenzielle Kunden anhand der internen Daten des Kunden über das Zielpublikum finden können. Unter einer Zielgruppe wird eine Reihe von codierten Kennungen (Telefonnummern, E-Mail-Adressen oder Online-ID) verstanden. Ich erinnere Sie daran, dass wir nicht in klarer Form mit Daten arbeiten, sondern alle gesetzlichen Bestimmungen einhalten.
So können wir eine Reihe von codierten Kennungen mit der Börse kreuzen und das Kaufverhalten oder deren Klickstrom sehen. Wir machen Clustering für jede Zielgruppe und jede Aufgabe. Nachdem das Modell die Leute nach ihrem Kaufverhalten gruppiert hatte, sah ich irgendwie einen Cluster, der nur aus Leuten bestand, die auf Sport wetten und nichts mehr online kaufen. Es ist jedoch möglich, dass sie für Buchmacherzwecke separate Konten haben.
Hier ist ein Screenshot dieses Clusters.

Fall "Glückliche Mutterschaft"
Für eine Werbekampagne für eine bekannte Windelmarke war es notwendig, eine Publikumsforschung durchzuführen und Frauen im dritten Trimenon der Schwangerschaft zu finden - die Kundin schlug vor, dass das Produkt ab dem dritten Trimenon beworben werden musste, damit die meisten Zuschauer es kaufen würden.
Zu Beginn der Analyse ähnelte die Beschreibung der Lebensumstände schwangerer Frauen einem idyllischen Bild: Eine junge Familie mit Haustieren rüstet am Vorabend der Geburt eines Kindes eine Unterkunft aus.

Frauen aus verschiedenen Clustern besitzen Geräte verschiedener Marken, bevorzugen verschiedene Marken von Hygieneprodukten und im Allgemeinen ist alles in Ordnung. Überzeugen Sie sich selbst.
25,5% der IDs
Käufer von Huggies Elite Soft kaufen dreimal seltener Pampers und siebenmal seltener Lovular-Produkte. Sie verwenden Produkte der Marke Peligrin. Mit hoher Wahrscheinlichkeit (0,6) sind die Eltern von Mädchen. Sie zahlen in der Regel für Versorgungsunternehmen über das Internet.
25,5% der Identifikatoren
neigen dazu, für Kommunikations- und Versicherungsdienstleistungen über das Internet zu bezahlen. Mit hoher Wahrscheinlichkeit (0,6) sind Hundebesitzer. Kaufen Sie Helen Harper Produkte. In der Unterhaltungselektronik kommt die Marke Xiaomi zum Ausdruck.
17,5% der Identifikatoren
Ozon Premium Benutzer. Sie kaufen Philips Avent Babypflegegeräte und interessieren sich für Bügelgeräte und -installationen.
Achtung, Ratschläge für die Zukunft: Achten Sie auf Werbeaktionen / Marken, die im gesamten Datenvolumen Rauschen verursachen.
Der Ozon Premium-Status in vielen unserer Cluster erwies sich als eines der bestimmenden Attribute. Die Zielgruppe potenzieller Windelkäufer nur für Ozon Premium anzusprechen, ist jedoch nicht vernünftig. Also musste ich den Status aus allen Daten entfernen. Ja, ich habe also die Metriken gesenkt, aber gleichzeitig die Angemessenheit des Modells erhöht. Den ersten Platz belegten Waren für Neugeborene und nicht den beförderten Volksstatus. Es war eine Erfahrung, die mich lehrte, Waren abzuschneiden, die für das Modell zu bedeutend waren.
Für eine ähnliche Modellierung liegt die Idee, mehrere einfache Klassifikatoren der Zielgruppe (Klasse 1) und der verallgemeinerten (Klasse 0) zu erstellen, auf der Oberfläche, um die Zielgruppe hervorzuheben.
Nehmen wir zum Beispiel Einkäufe der Zielgruppe und das Zehnfache des Volumens zufälliger Profile. Wir bringen diese Informationen nacheinander, Einkäufe. Dann arbeiten wir mit den resultierenden Texten (Vorverarbeitung): Wir entfernen alle hochfrequenten, nicht informativen Wörter und bringen den Rest in die ursprüngliche Form. Als nächstes erstellen wir einfache Klassifikatoren mehrerer verschiedener Familien - linear (lineare SVC, logistische Regression), "hölzern" (RandomForest) usw. - und messen die Wichtigkeit von Merkmalen, dh die Wichtigkeit von Wörtern nach Modellen. Ich habe Schwellenwerte gefunden, oberhalb derer die Bedeutung dieser Zeichen unzureichend ist, dh das Zeichen ist zu laut. Bevor Sie etwas Automatisches erstellen, müssen Sie den gesunden Menschenverstand und die Methode des sorgfältigen Blicks viele Male anwenden, um interne Statistiken zu sammeln und zu verstehen, welche Methoden funktionieren und welche nicht.
Wir untersuchten Cluster mit einem idyllischen Bild am Vorabend der Geburt eines Kindes, aber es wurden auch andere Lebensgeschichten verfolgt. In einem der Cluster haben potenzielle Käufer von Windeln für Neugeborene mit hoher Wahrscheinlichkeit (0,65) ein Konto auf einer Dating-Website. Dies ist keine unbegründete Aussage, sie zahlen für Dienstleistungen auf solchen Websites.
Damit Einsichten „funktionieren“, muss man immer neues Wissen interpretieren, aber dieses Mal möchte ich überhaupt nicht nach der Insider-Geschichte suchen - jeder kennt das soziale Unwohlsein und die alltägliche Störung des Lebens in unserem Land.

Ich möchte Sie daran erinnern, dass wir im Rahmen dieses Falls das gesamte Publikum untersucht haben, das daran interessiert war, Windeln für Neugeborene zu kaufen. Und es stellte sich heraus, dass nicht nur Frauen im dritten Trimenon der Schwangerschaft waren.
Ich habe einen separaten Cluster "Sunday Dads" genannt - seine Vertreter sind Fußballfans, begeisterte Autoenthusiasten, kaufen Komponenten für Sparco-Autos und kaufen von Zeit zu Zeit Chupa Chups-Waren.
Und nun Aufmerksamkeit, die Frage: Lohnt es sich, "Sonntagsväter" zu löschen, wenn sie sich nicht auf die ursprünglich festgelegte Zielgruppe beziehen? Ich stelle diese Frage oft meinen Projektmanagern, und die Aufgabe wird überdacht. Vielleicht brauchen wir nicht wirklich eine bestimmte Zielgruppe, sondern jeden, der Käufer des Produkts werden kann. In unserem Fall sind dies Väter und Großeltern, Brüder-Schwestern und Freundinnen einer Frau in Arbeit, die bereit sind, sich um das Baby zu kümmern. Die Antwort darauf, welches Publikum als Ziel angesehen werden sollte, sind Unternehmensvertreter.
Fall "Einzelunternehmer"

Der nächste Fall, über den ich Ihnen berichten werde, ist Audience Research für die Zielgruppe „Einzelunternehmer“, die ein Girokonto bei einer bekannten Bank eröffnet haben.
Die Hauptunterschiede zwischen diesen Personen und dem Publikum der Börse sind deutlich in ihren Einkäufen zu sehen. Am offensichtlichsten ist die Zahlung von Lizenzgebühren (10-15% der Profile), Sicherheitsdiensten und Stromrechnungen für Nichtwohngebäude. Zu den indirekten Anzeichen für Unternehmer gehört der Kauf eines zusätzlichen Gepäckstücks während des Fluges (in 15 bis 20% der Fälle). Ein wesentlicher Teil des gesamten Scheckvolumens besteht aus Büchern über Psychologie, Selbsterkenntnis und Selbstentwicklung, Workshops zur Kommunikation mit Untergebenen und Coaching-Literatur.
Mit Hilfe der LaL-Funktion haben wir indirekte Anzeichen für die Zielgruppe erhalten: Lufttransport, Kauf eines Roboterstaubsaugers, Kaffeemaschine, Honor-Smartphone, Blumenlieferung, Zahlung von Versicherungsprämien. Dieser Fall ist einer dieser wunderbaren Fälle, in denen Maschinen uns ein leicht interpretierbares Ergebnis liefern.
Vielbeschäftigte kaufen Heimroboter. Kein Büro kann ohne Kaffeemaschinen auskommen. Blumenlieferung und häufige Flüge können ebenfalls verknüpft werden =).
Fall "Autobesitzer"
Eine bekannte Automarke im „überdurchschnittlichen“ Preissegment war absolut davon überzeugt, dass ihre Kunden ganz außergewöhnliche Menschen waren und ihre Gewohnheiten und Vorlieben kennen wollten.
Diese Zielgruppe überschneidet sich erheblich mit dem vorherigen Fall ("Einzelunternehmer"). Aber nicht alle Einzelunternehmer kaufen diese Automarke.

Es stellte sich heraus, dass die Vorstellung des Kunden von der Einzigartigkeit der Kunden stark übertrieben ist. Ja, das Publikum stimmt nicht mit dem Durchschnitt überein, aber nur in einigen Details zum Beispiel bevorzugen Autofahrer den Kauf von Elite-Tee (300 Rubel teurer) und geben im Allgemeinen mehr für Schönes und Ästhetisches als für Funktionales und Praktisches aus.
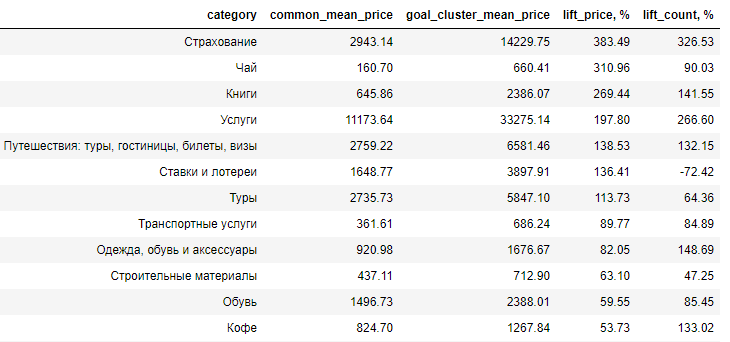
Hier wird der Unterschied zwischen der Zielgruppe und der durchschnittlichen Zielgruppe der Käufer in Bezug auf den Lift dargestellt, dh um wie viel Prozent übersteigt der durchschnittliche Preis eines Produkts in der untersuchten Zielgruppe den gleichen Wert in der durchschnittlichen Zielgruppe (lift_price). Wie Sie sehen können, sind die Hauptausgaben das Vergnügen.
Wir testen Hypothesen immer fair und unparteiisch. Es wird durchaus erwartet, dass die Hypothese des Kunden über die Exklusivität seines Publikums manchmal nicht durch die erhaltenen Daten gestützt wird. Es gibt nichts zu befürchten, es braucht nur eine neue Hypothese und neue Forschung.

Abschließend möchte ich sagen, dass ich mich bei meiner Arbeit am Prinzip "Routine beruhigt" orientiere. Und ich rate dir.
Bei solch einer Vielzahl von Daten ist es unerlässlich, sehr vorsichtig und aufmerksam auf die kleinen Dinge zu achten, da sich jede Ausnahme auf den ersten Blick später als Regel herausstellen kann und wir viele fehlerhafte Ergebnisse erzielen können.
Wenn ich also nicht gesehen hätte, was mein Modell "kein Backen" als "Backen" bezeichnet, wäre das "undichte" System in Produktion gegangen. Vernachlässigen Sie also nicht die Routine: Wenn Sie eine halbe Stunde mit Ihren Augen verbringen, können Sie gut schlafen - das Modell macht keine Fehler.
