Viel im Leben eines Projekts hängt davon ab, wie gut das Objektmodell und die Struktur der Basis zu Beginn durchdacht sind.
Der allgemein akzeptierte Ansatz war und ist eine verschiedene Option, um das „Stern“ -Schema mit der dritten Normalform zu kombinieren. In der Regel nach dem Prinzip: Anfangsdaten - 3NF, Vitrinen - Stern. Dieser bewährte Ansatz, der durch viele Untersuchungen gestützt wird, ist das erste (und manchmal einzige), woran eine erfahrene DWH-Person denkt, wenn sie darüber nachdenkt, wie ein analytisches Repository aussehen sollte.
Auf der anderen Seite ändern sich das Geschäft im Allgemeinen und die Kundenanforderungen im Besonderen schnell, und die Daten wachsen sowohl "in der Tiefe" als auch "in der Breite". Und hier zeigt sich der Hauptnachteil des Sterns - begrenzte Flexibilität .
Und wenn in Ihrem ruhigen und gemütlichen Leben als DWH-Entwickler plötzlich:
- es stellte sich die Aufgabe, „wenigstens schnell etwas zu tun, und dann werden wir sehen“;
- Es entstand ein sich schnell entwickelndes Projekt, bei dem mindestens einmal pro Woche neue Quellen angeschlossen und das Geschäftsmodell überarbeitet wurden.
- Es ist ein Kunde erschienen, der sich nicht vorstellt, wie das System aussehen soll und welche Funktionen es am Ende ausführen soll, aber bereit für Experimente und eine konsequente Verfeinerung des gewünschten Ergebnisses mit einem konsequenten Ansatz ist.
- Der Projektmanager kam mit der guten Nachricht: "Und jetzt haben wir Agilität!"
Oder wenn Sie nur neugierig sind, wie Sie sonst noch Speicher bauen können - willkommen unter der Katze!

Was bedeutet Flexibilität?
Definieren wir zunächst, welche Eigenschaften das System haben muss, um als „flexibel“ bezeichnet zu werden.
Unabhängig davon sollte beachtet werden, dass sich die beschriebenen Eigenschaften speziell auf das System und nicht auf den Prozess seiner Entwicklung beziehen sollten . Wenn Sie also über Agile als Entwicklungsmethode lesen möchten, ist es besser, andere Artikel zu lesen. Genau dort, auf Habré, gibt es zum Beispiel viele interessante Materialien (sowohl Umfragen als auch praktische und problematische ).
Dies bedeutet nicht, dass der Entwicklungsprozess und die Struktur der CD überhaupt nicht miteinander verbunden sind. Im Allgemeinen sollte es viel einfacher sein, einen agilen Speicher mit flexibler Architektur zu entwickeln. In der Praxis gibt es jedoch mehr Optionen für die agile Entwicklung des klassischen DWH von Kimball und DataVault von Waterfall als glückliche Zufälle der Flexibilität in den beiden Hypostasen eines Projekts.
Welche Funktionen sollte flexibler Speicher haben? Hier gibt es drei Punkte:
- Frühzeitige Lieferung und schnelle Überarbeitung bedeuten, dass im Idealfall das erste Geschäftsergebnis (z. B. die ersten Arbeitsberichte) so früh wie möglich eingehen sollte, dh noch bevor das gesamte System vollständig entworfen und implementiert ist. Darüber hinaus sollte jede nachfolgende Überarbeitung so wenig Zeit wie möglich in Anspruch nehmen.
- — , . — , , . , , — .
- Ständige Anpassung an sich ändernde Geschäftsanforderungen - Die gesamte Objektstruktur sollte nicht nur unter Berücksichtigung möglicher Erweiterungen entworfen werden, sondern mit der Erwartung, dass die Richtung dieser nächsten Erweiterung in der Entwurfsphase möglicherweise nicht einmal von Ihnen träumt.
Und ja, all diese Anforderungen in einem System zu erfüllen ist möglich (natürlich in bestimmten Fällen und mit einigen Einschränkungen).
Im Folgenden werde ich zwei der beliebtesten agilen Entwurfsmethoden für HD betrachten - das Ankermodell und Data Vault.... Hinter Klammern stehen so hervorragende Techniken wie EAV, 6NF (in seiner reinen Form) und alles, was mit NoSQL-Lösungen zu tun hat - nicht, weil sie irgendwie schlechter sind, und nicht einmal, weil der Artikel in diesem Fall drohen würde, das Volumen des Durchschnitts zu erreichen dissera. All dies bezieht sich nur auf Lösungen einer etwas anderen Klasse - entweder auf Techniken, die Sie in bestimmten Fällen anwenden können, unabhängig von der allgemeinen Architektur Ihres Projekts (wie EAV), oder auf global andere Paradigmen der Informationsspeicherung (wie Diagrammdatenbanken und andere Optionen) NoSQL).
Probleme des "klassischen" Ansatzes und ihre Lösungen in agilen Methoden
Mit dem "klassischen" Ansatz meine ich den guten alten Stern (unabhängig von der spezifischen Implementierung der zugrunde liegenden Schichten, mögen mir die Anhänger von Kimball, Inmon und CDM vergeben).
1. Starre Kardinalität der Bindungen
Dieses Modell basiert auf einer klaren Trennung der Daten in Dimensionen (Dimension) und Fakten (Fact) . Und das ist verdammt noch mal logisch - schließlich geht es bei der Datenanalyse in den allermeisten Fällen nur um die Analyse bestimmter numerischer Indikatoren (Fakten) in bestimmten Abschnitten (Dimensionen).
In diesem Fall werden Verknüpfungen zwischen Objekten in Form von Verknüpfungen zwischen Tabellen durch einen Fremdschlüssel gelegt. Dies sieht ganz natürlich aus, führt jedoch sofort zur ersten Einschränkung der Flexibilität - einer starren Definition der Kardinalität von Verbindungen .
Dies bedeutet, dass Sie in der Entwurfsphase von Tabellen für jedes Paar verwandter Objekte genau definieren müssen, ob es sich um viele-zu-viele oder nur 1-zu-viele handeln kann und "in welche Richtung". Es hängt direkt davon ab, welche der Tabellen einen Primärschlüssel und welche einen externen Schlüssel haben. Eine Änderung dieser Einstellung, wenn neue Anforderungen eingehen, führt höchstwahrscheinlich zu einer Neugestaltung der Basis.
Zum Beispiel haben Sie beim Entwerfen des Objekts "Bankscheck" unter Berufung auf die Eide der Verkaufsabteilung die Möglichkeit festgelegt, dass eine Beförderung auf mehrere Scheckpositionen wirkt (aber nicht umgekehrt):
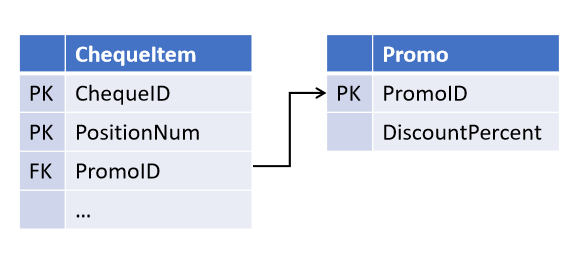
Und nach einer Weile stellten Kollegen eine neue Marketingstrategie vor, bei der mehrere Werbeaktionen gleichzeitig auf dieselbe Position wirken können . Und jetzt müssen Sie die Tabellen ändern, indem Sie den Link in einem separaten Objekt auswählen.
(Alle abgeleiteten Objekte, bei denen eine Promo-Prüfung stattfindet, müssen jetzt ebenfalls verbessert werden.)
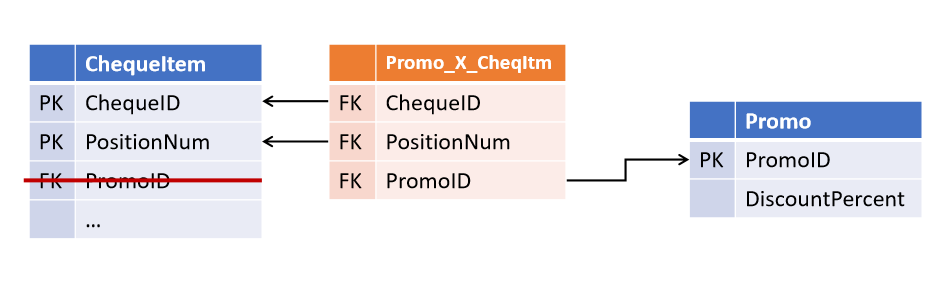
Links im Data Vault- und Anchor-Modell Es hat
sich als recht einfach herausgestellt, eine solche Situation zu vermeiden: Sie
Dieser Ansatz wurde vorgeschlagen von Dan Linstedt im Rahmen des Data Vault - Paradigmas und ist vollständig unterstützt von Lars Rönnbäck im Anchor Modell .
Als Ergebnis erhalten wir das erste Unterscheidungsmerkmal agiler Methoden:
Beziehungen zwischen Objekten werden nicht in den Attributen übergeordneter Entitäten gespeichert, sondern sind ein separater Objekttyp.Das Datentresor sind Tischbänder namens Link und die Ankermodelle - die Krawatte . Auf den ersten Blick sind sie sich sehr ähnlich, obwohl ihre Unterschiede nicht auf den Namen beschränkt sind (auf den weiter unten eingegangen wird). In beiden Architekturen können Verknüpfungstabellen eine beliebige Anzahl von Entitäten verknüpfen (nicht unbedingt 2).
Diese Redundanz bietet auf den ersten Blick eine erhebliche Flexibilität für Änderungen. Eine solche Struktur wird nicht nur tolerant gegenüber der Änderung der Kardinalität vorhandener Links, sondern auch gegenüber dem Hinzufügen neuer Links. Wenn die Scheckposition jetzt auch einen Link zu dem Kassierer enthält, der sie gestanzt hat, wird das Erscheinungsbild eines solchen Links einfach zu einem Add-On über vorhandene Tabellen, ohne dass vorhandene Objekte und beeinflusst werden Prozesse.

2. Datenvervielfältigung
Das zweite Problem, das durch flexible Architekturen gelöst wird, ist weniger offensichtlich und hängt hauptsächlich mit Messungen des SCD2-Typs (sich langsam ändernde Abmessungen des zweiten Typs) zusammen, wenn auch nicht nur mit diesen.
In einem klassischen Geschäft ist eine Dimension normalerweise eine Tabelle, die einen Ersatzschlüssel (als PK) und eine Reihe von Geschäftsschlüsseln und -attributen in separaten Spalten enthält.

Wenn die Dimension versioniert ist, werden Versionszeitgrenzen zu den Standardfeldern hinzugefügt, und mehrere Versionen werden pro Zeile in der Quelle im Geschäft angezeigt (eine für jede Änderung der versionierten Attribute).
Wenn eine Dimension mindestens ein häufig wechselndes versioniertes Attribut enthält, ist die Anzahl der Versionen einer solchen Dimension beeindruckend (auch wenn die restlichen Attribute nicht versioniert sind oder sich nie ändern). Wenn mehrere solcher Attribute vorhanden sind, kann die Anzahl der Versionen exponentiell von ihrer Anzahl an wachsen. Eine solche Dimension kann eine erhebliche Menge an Speicherplatz beanspruchen, obwohl die meisten darin gespeicherten Daten einfach doppelte Werte unveränderter Attribute aus anderen Zeilen sind.

Gleichzeitig wird auch sehr häufig die Denormalisierung verwendet - einige der Attribute werden absichtlich als Wert gespeichert und nicht als Verweis auf ein Verzeichnis oder eine andere Dimension. Dieser Ansatz beschleunigt den Datenzugriff, indem die Anzahl der Verknüpfungen beim Zugriff auf eine Dimension verringert wird.
Dies führt in der Regel dazu, dassDie gleichen Informationen werden gleichzeitig an mehreren Orten gespeichert . Beispielsweise können Informationen über die Wohnregion und die Zugehörigkeit zur Kundenkategorie gleichzeitig in den Dimensionen „Kunde“ und den Fakten „Einkauf“, „Lieferung“ und „Anrufe an das Callcenter“ sowie in der Verknüpfungstabelle „Kunde - Kundenmanager“ gespeichert werden.
Im Allgemeinen gilt das Obige für reguläre (nicht versionierte) Messungen, aber in versionierten Messungen können sie einen anderen Maßstab haben: Das Erscheinungsbild einer neuen Version eines Objekts (insbesondere im Nachhinein) führt nicht nur zur Aktualisierung aller zugehörigen Tabellen, sondern auch zum kaskadierenden Erscheinungsbild neuer Versionen verwandter Objekte. wenn Tabelle 1 zum Erstellen von Tabelle 2 verwendet wird und Tabelle 2 zum Erstellen von Tabelle 3 usw. verwendet wird. Selbst wenn keines der Attribute von Tabelle 1 an der Konstruktion von Tabelle 3 beteiligt ist (und andere Attribute von Tabelle 2 aus anderen Quellen beteiligt sind), führt eine versionierte Aktualisierung dieser Konstruktion zumindest zu zusätzlichen Gemeinkosten und höchstens zu unnötigen Versionen in Tabelle 3. das hat nichts damit zu tun und weiter entlang der Kette.

3. Nichtlineare Komplexität der Revision
Darüber hinaus erhöht jeder neue Mart, der auf einem anderen aufgebaut ist, die Anzahl der Stellen, an denen Daten bei Änderungen an ETL "divergieren" können. Dies führt wiederum zu einer Erhöhung der Komplexität (und Dauer) jeder nachfolgenden Überarbeitung.
Wenn dies Systeme mit selten geänderten ETL-Prozessen betrifft, können Sie in einem solchen Paradigma leben - Sie müssen nur sicherstellen, dass neue Änderungen korrekt in alle verwandten Objekte eingeführt werden. Wenn häufig Änderungen vorgenommen werden, steigt die Wahrscheinlichkeit, dass versehentlich einige Links "fehlen", erheblich.
Wenn wir außerdem berücksichtigen, dass "versionierte" ETL viel komplizierter ist als "nicht versionierte", wird es ziemlich schwierig, Fehler bei häufigen Überarbeitungen dieser gesamten Wirtschaft zu vermeiden.
Speichern von Objekten und Attributen im Datentresor- und Ankermodell
Der von den Autoren agiler Architekturen vorgeschlagene Ansatz kann wie folgt formuliert werden:
Es ist notwendig zu trennen, was sich von dem ändert, was unverändert bleibt. Halten Sie also die Schlüssel von den Attributen getrennt.Gleichzeitig sollten Sie ein nicht versioniertes Attribut nicht mit einem unveränderten verwechseln : Das erste speichert nicht den Verlauf seiner Änderung, kann sich jedoch ändern (z. B. wenn ein Eingabefehler korrigiert wird oder neue Daten empfangen werden), das zweite ändert sich nie.
Die Ansichten darüber, was genau im Datentresor und im Ankermodell als unveränderlich angesehen werden kann, unterscheiden sich.
Aus Sicht der Data Vault- Architektur kann der gesamte Schlüsselsatz als unverändert betrachtet werden - natürlich (TIN der Organisation, Produktcode im Quellsystem usw.) und als Ersatz. Gleichzeitig können die verbleibenden Attribute nach Quelle und / oder Häufigkeit der Änderungen in Gruppen unterteilt werden, und für jede Gruppe kann eine separate Tabelle mit einem unabhängigen Satz von Versionen verwaltet werden .
Im ParadigmaAnchor Modell ist unveränderlich betrachtet nur Entität Ersatzschlüssel . Alles andere (einschließlich natürlicher Schlüssel) ist nur ein Sonderfall seiner Attribute. Gleichzeitig sind standardmäßig alle Attribute unabhängig voneinander. Daher muss für jedes Attribut eine separate Tabelle erstellt werden .
In Data Vault werden Tabellen mit Entitätsschlüsseln als Hubs bezeichnet . Hubs enthalten immer einen festen Satz von Feldern:
- Entität natürliche Schlüssel
- Ersatzschlüssel
- Link zur Quelle
- Rekordzeit aufzeichnen
Einträge in Hubs werden nie geändert und haben keine Version . Äußerlich sind Hubs Tabellen des ID-Map-Typs sehr ähnlich, die in einigen Systemen zum Generieren von Ersatzzeichen verwendet werden. Es wird jedoch empfohlen, in Data Vault keine ganzzahlige Sequenz als Ersatzzeichen zu verwenden, sondern einen Hash aus einer Reihe von Geschäftsschlüsseln. Dieser Ansatz vereinfacht das Laden von Links und Attributen aus Quellen (Sie müssen nicht dem Hub beitreten, um einen Ersatz zu erhalten, sondern müssen nur den Hash aus dem natürlichen Schlüssel berechnen), kann jedoch andere Probleme verursachen (z. B. Kollisionen, Groß- und Kleinschreibung und nicht druckbare Zeichen in Zeichenfolgenschlüsseln usw.). .p.), daher wird es nicht allgemein akzeptiert.
Alle anderen Attribute von Entitäten werden in speziellen Tabellen gespeichert, die als Satelliten bezeichnet werden... Ein Hub kann mehrere Satelliten haben, die unterschiedliche Sätze von Attributen speichern.
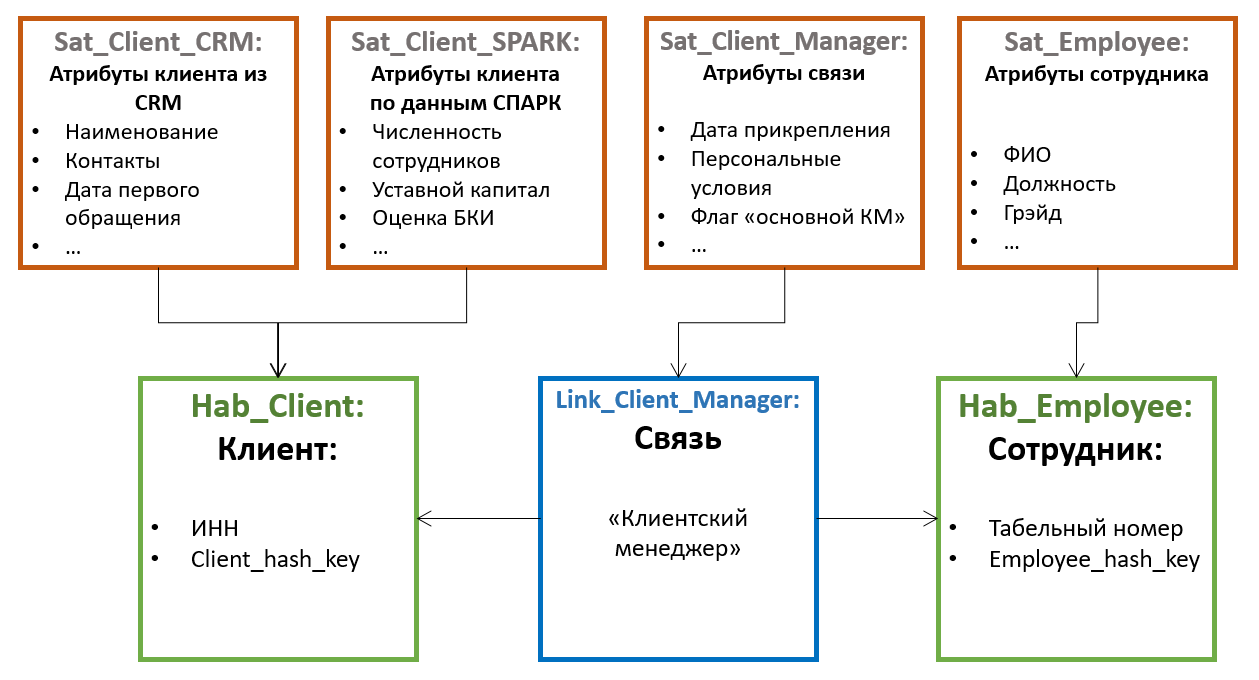
Die Verteilung der Attribute auf die Satelliten basiert auf dem Prinzip der gemeinsamen Änderung - ein Satellit kann nicht versionierte Attribute (z. B. Geburtsdatum und SNILS für eine Person) speichern, ein anderer - selten ändernde versionierte Attribute (z. B. Nachname und Passnummer), der dritte - häufig Ändern (z. B. Lieferadresse, Kategorie, Datum der letzten Bestellung usw.). In diesem Fall wird die Versionierung auf der Ebene einzelner Satelliten und nicht auf der Ebene der gesamten Entität durchgeführt. Daher ist es ratsam, die Attribute so zu verteilen, dass der Schnittpunkt von Versionen innerhalb eines Satelliten minimal ist (wodurch die Gesamtzahl der gespeicherten Versionen verringert wird).
Um den Datenladeprozess zu optimieren, werden Attribute, die aus verschiedenen Quellen stammen, häufig in separaten Satelliten platziert.
Satelliten kommunizieren mit dem Hub über einen Fremdschlüssel (was einer Kardinalität von 1 zu vielen entspricht). Dies bedeutet, dass mehrere Attributwerte (z. B. mehrere Kontakttelefonnummern für einen Kunden) von dieser "Standard" -Architektur unterstützt werden.
Im Ankermodell werden Tabellen mit Schlüsseln als Anchor bezeichnet . Und sie behalten:
- Nur Ersatzschlüssel
- Link zur Quelle
- Rekordzeit aufzeichnen
Natürliche Schlüssel werden aus Sicht des Ankermodells als gewöhnliche Attribute betrachtet . Diese Option scheint schwieriger zu verstehen, bietet jedoch viel mehr Raum für die Objektidentifizierung.

Zum Beispiel, wenn Daten über dieselbe Entität aus verschiedenen Systemen stammen können, von denen jedes seinen eigenen natürlichen Schlüssel verwendet. Im Data Vault kann dies zu ziemlich umständlichen Strukturen mehrerer Hubs führen (einer pro Quelle + die einheitliche Master-Version), während im Anchor-Modell der natürliche Schlüssel jeder Quelle in ein eigenes Attribut fällt und beim Laden unabhängig von allen anderen verwendet werden kann.
Hier gibt es jedoch einen heimtückischen Punkt: Wenn Attribute aus verschiedenen Systemen in einer Entität kombiniert werden, gibt es höchstwahrscheinlich einigeRegeln des "Klebens" , nach denen das System verstehen muss, dass Datensätze aus verschiedenen Quellen einer Instanz einer Entität entsprechen.
In Data Vault bestimmen diese Regeln höchstwahrscheinlich die Bildung des „Ersatz-Hubs“ der Master-Entität und wirken sich in keiner Weise auf die Hubs aus, in denen die natürlichen Schlüssel von Quellen und ihre ursprünglichen Attribute gespeichert sind. Wenn sich die Spleißregeln irgendwann ändern (oder die Attribute aktualisiert werden, durch die sie erstellt werden), reicht es aus, die Ersatz-Hubs neu zu bilden.
Im Ankermodell wird eine solche Entität höchstwahrscheinlich in einem einzelnen Anker gespeichert .... Dies bedeutet, dass alle Attribute, unabhängig davon, aus welcher Quelle sie stammen, an denselben Ersatz gebunden sind. Das Trennen irrtümlich zusammengeführter Datensätze und im Allgemeinen das Verfolgen der Relevanz des Zusammenführens in einem solchen System kann erheblich schwieriger sein, insbesondere wenn die Regeln komplex genug sind und sich häufig ändern und dasselbe Attribut aus verschiedenen Quellen bezogen werden kann (obwohl dies definitiv möglich ist, da jedes Die Attributversion behält einen Link zu ihrer Quelle bei.
In jedem Fall, wenn Ihr System die Funktionalität der Deduplizierung implementieren soll , indem Datensätze und andere MDM-Elemente zusammengeführt werdenEs lohnt sich, die Aspekte der Speicherung natürlicher Schlüssel in agilen Methoden genau zu betrachten. Das umständlichere Data Vault-Design wird sich in Bezug auf Zusammenführungsfehler wahrscheinlich plötzlich als sicherer erweisen.
Das Ankermodell sieht auch einen zusätzlichen Objekttyp vor, der als Knoten bezeichnet wird. Tatsächlich handelt es sich um eine spezielle entartete Art von Anker , die nur ein Attribut enthalten kann. Die Knoten sollen zum Speichern von flachen Verzeichnissen verwendet werden (z. B. Geschlecht, Familienstand, Kundendienstkategorie usw.). Im Gegensatz zu Anchor sind dem Knoten keine Attributtabellen zugeordnetund sein einziges Attribut (Name) wird immer in derselben Tabelle mit dem Schlüssel gespeichert. Knoten sind durch Bindungstabellen mit Ankern verbunden, genau wie Anker miteinander.
Es gibt keine eindeutige Meinung über die Verwendung von Knoten. Zum Beispiel glaubt Nikolai Golov , der die Verwendung des Ankermodells in Russland aktiv fördert, (nicht ohne Grund), dass es unmöglich ist, für jedes Nachschlagewerk mit Sicherheit zu sagen, dass es immer statisch und einstufig sein wird. Daher ist es für alle Objekte besser, sofort einen vollwertigen Anker zu verwenden.
Ein weiterer wichtiger Unterschied zwischen dem Data Vault- und dem Anchor-Modell ist das Vorhandensein von Attributen für die Links :
Im Data Vault sind die Links dieselben vollwertigen Objekte wie Hubs und können sie habeneigene Attribute . Im Ankermodell werden Links nur zum Verbinden von Ankern verwendet und können keine eigenen Attribute haben . Dieser Unterschied führt zu signifikant unterschiedlichen Ansätzen zur Modellierung von Fakten , auf die weiter unten eingegangen wird.
Fakten speichern
Vorher haben wir hauptsächlich über die Modellierung von Messungen gesprochen. Die Fakten sind etwas weniger einfach.
In Data Vault ist ein typisches Objekt zum Speichern von Fakten ein Link , in dessen Satelliten echte Indikatoren hinzugefügt werden.
Dieser Ansatz sieht intuitiv aus. Es bietet einfachen Zugriff auf die analysierten Indikatoren und ähnelt im Allgemeinen einer herkömmlichen Faktentabelle (nur die Indikatoren werden nicht in der Tabelle selbst, sondern in der „benachbarten“ Tabelle gespeichert). Es gibt aber auch Fallstricke: Eine der typischen Modellmodifikationen - das Erweitern des Faktschlüssels - erfordert das Hinzufügen eines neuen Fremdschlüssels zu Link . Dies wiederum "bricht" die Modularität und führt möglicherweise dazu, dass Verbesserungen an anderen Objekten erforderlich sind.
Im AnkermodellEin Link kann keine eigenen Attribute haben, daher funktioniert dieser Ansatz nicht. Absolut alle Attribute und Indikatoren müssen an einen bestimmten Anker gebunden sein. Die Schlussfolgerung daraus ist einfach - jede Tatsache braucht auch einen eigenen Anker . Für einen Teil dessen, was wir gewohnt sind, als Fakten zu betrachten, mag es natürlich aussehen - zum Beispiel wird die Tatsache eines Kaufs perfekt auf das Objekt „Bestellung“ oder „Quittung“, einen Besuch auf einer Website - auf eine Sitzung usw. reduziert. Es gibt aber auch Tatsachen, für die es nicht so einfach ist, ein so natürliches „Trägerobjekt“ zu finden - zum Beispiel die Warenreste in Lagern zu Beginn eines jeden Tages.
Dementsprechend gibt es keine Probleme mit der Modularität beim Erweitern des Faktschlüssels im Ankermodell (es reicht aus, nur einen neuen Link zum entsprechenden Anker hinzuzufügen), aber das Design des Modells zur Anzeige von Fakten ist weniger eindeutig. Es können „künstliche“ Anker auftreten, die das Geschäftsobjektmodell widerspiegeln.
Wie Flexibilität erreicht wird
Die resultierende Konstruktion enthält in beiden Fällen deutlich mehr Tabellen als die herkömmliche Dimension. Mit denselben versionierten Attributen wie mit einer herkömmlichen Dimension kann jedoch erheblich weniger Speicherplatz belegt werden . Natürlich gibt es hier keine Magie - es geht nur um Normalisierung. Durch die Verteilung von Attributen auf Satelliten (im Datentresor) oder separate Tabellen (Ankermodell) reduzieren wir die Verdoppelung von Werten einiger Attribute (oder beseitigen sie vollständig) , wenn andere geändert werden .
Für den Datentresor hängt die Verstärkung von der Verteilung der Attribute auf die Satelliten ab, und für das Ankermodell ist sie fast direkt proportional zur durchschnittlichen Anzahl von Versionen pro Messobjekt.
Das Gewinnen von Speicherplatz ist jedoch ein wichtiger, aber nicht der Hauptvorteil des separaten Speicherns von Attributen. Zusammen mit dem separaten Speichern von Links macht dieser Ansatz das Repository modular aufgebaut . Dies bedeutet, dass das Hinzufügen sowohl einzelner Attribute als auch ganz neuer Themenbereiche in einem solchen Modell wie ein Add- On zu einem vorhandenen Satz von Objekten aussieht, ohne diese zu ändern. Und genau das macht die beschriebenen Methoden flexibel.
Es ähnelt auch dem Übergang von der Stückproduktion zur Massenproduktion - wenn beim traditionellen Ansatz jede Modelltabelle einzigartig ist und separate Aufmerksamkeit erfordert, dann handelt es sich bei flexiblen Methoden bereits um eine Reihe typischer „Details“. Einerseits gibt es mehr Tabellen, die Prozesse zum Laden und Abrufen von Daten sollten komplizierter aussehen. Andererseits werden sie typisch . Dies bedeutet, dass sie durch Metadaten automatisiert und verwaltet werden können . Die Frage "Wie sollen wir es legen?"
Dies bedeutet nicht, dass in einem solchen System überhaupt keine Analysten benötigt werden - jemand muss noch eine Reihe von Objekten mit Attributen durcharbeiten und herausfinden, wo und wie all dies geladen werden soll. Der Arbeitsaufwand sowie die Wahrscheinlichkeit und die Kosten eines Fehlers werden jedoch erheblich reduziert. Sowohl in der Phase der Analyse als auch während der Entwicklung von ETL, die in einem wesentlichen Teil auf die Bearbeitung von Metadaten reduziert werden kann.
Die dunkle Seite
All dies macht beide Ansätze wirklich flexibel, technologisch fortschrittlich und für die iterative Verfeinerung geeignet. Natürlich gibt es auch ein „Fass Salbe“, von dem Sie meiner Meinung nach bereits raten.
Die Datenzerlegung, die der Modularität flexibler Architekturen zugrunde liegt, führt zu einer Erhöhung der Anzahl der Tabellen und dementsprechend des Overheads der Verknüpfungen beim Abrufen. Um einfach alle Attribute einer Dimension abzurufen, ist im klassischen Repository eine Auswahl ausreichend, und für eine flexible Architektur sind mehrere Verknüpfungen erforderlich. Wenn für Berichte alle diese Verknüpfungen im Voraus geschrieben werden können, leiden Analysten, die es gewohnt sind, SQL von Hand zu schreiben, doppelt darunter.
Es gibt mehrere Fakten, die diese Situation erleichtern:
Bei der Arbeit mit großen Dimensionen werden fast nie alle Attribute gleichzeitig verwendet. Dies bedeutet, dass möglicherweise weniger Verknüpfungen vorhanden sind, als es beim ersten Betrachten des Modells scheint. Im Datentresor können Sie auch die erwartete Freigabehäufigkeit berücksichtigen, wenn Sie Attribute auf Satelliten verteilen. Gleichzeitig werden die Hubs oder Anker selbst hauptsächlich zum Generieren und Zuordnen von Surrogaten in der Ladephase benötigt und nur selten in Anforderungen verwendet (insbesondere für Anker).
Alle Verknüpfungen erfolgen per Schlüssel.Darüber hinaus reduziert eine präzisere Art des Speicherns von Daten den Aufwand für das Scannen von Tabellen, falls erforderlich (z. B. beim Filtern nach Attributwerten). Dies kann dazu führen, dass das Abrufen aus einer normalisierten Datenbank mit einer Reihe von Verknüpfungen noch schneller ist als das Scannen einer schweren Dimension mit vielen Versionen pro Zeile.
Zum Beispiel gibt es hier in diesem Artikel einen detaillierten vergleichenden Leistungstest des Ankermodells mit einer Auswahl aus einer Tabelle.
Viel hängt vom Motor ab. Viele moderne Plattformen verfügen über interne Mechanismen zur Optimierung von Verknüpfungen. Beispielsweise können MS SQL und Oracle Verknüpfungen zu Tabellen „überspringen“, wenn ihre Daten nur für andere Verknüpfungen verwendet werden und die endgültige Auswahl (Eliminierung von Tabellen / Verknüpfungen) nicht beeinflussen, während dies bei MPP Vertica der Fall istDie Erfahrung von Kollegen aus Avito erwies sich unter Berücksichtigung einiger manueller Optimierungen des Abfrageplans als hervorragende Engine für das Anchor-Modell. Auf der anderen Seite scheint es vorerst keine gute Idee zu sein, das Ankermodell beispielsweise auf Click House zu belassen, das nur eine eingeschränkte Join-Unterstützung bietet.
Darüber hinaus gibt es für beide Architekturen spezielle Techniken , um den Zugriff auf Daten zu erleichtern (sowohl aus Sicht der Abfrageleistung als auch für Endbenutzer). Zum Beispiel Point-In-Time-Tabellen im Datentresor oder spezielle Tabellenfunktionen im Ankermodell.
Gesamt
Das Wesentliche der betrachteten flexiblen Architekturen ist die Modularität ihres „Designs“.
Diese Eigenschaft ermöglicht:
- , ETL, , . ( ) .
- ( ) 2-3 , ( ).
- , - .
- Aufgrund der Zerlegung in Standardelemente sehen ETL-Prozesse in solchen Systemen gleich aus, ihr Schreiben eignet sich für die Algorithmusisierung und letztendlich für die Automatisierung .
Der Preis für diese Flexibilität ist die Leistung . Dies bedeutet nicht, dass mit solchen Modellen keine akzeptable Leistung erzielt werden kann. Meistens benötigen Sie nur mehr Aufwand und Liebe zum Detail, um die gewünschten Metriken zu erreichen.
Anwendungen
Data Vault Entitätstypen

Weitere Informationen zu Data Vault:
Dan Listadt's Site
Alles über Data Vault auf Russisch
Über Data Vault auf Habré
Anchor Modell Entitätstypen

Weitere Informationen zum Ankermodell:
Site der
Ankermodellersteller Ein Artikel über die Erfahrungen bei der Implementierung des Ankermodells in Avito
Eine Übersichtstabelle mit den allgemeinen Merkmalen und Unterschieden der betrachteten Ansätze:
