Es gibt also zwei Arten von Web-Bots - legitime und böswillige. Zu den legitimen gehören Suchmaschinen und RSS-Reader. Beispiele für böswillige Web-Bots sind Schwachstellenscanner, Scraper, Spammer, DDoS-Angriffs-Bots und Trojaner für Zahlungskartenbetrug. Sobald der Typ des Web-Bots identifiziert wurde, können verschiedene Richtlinien auf ihn angewendet werden. Wenn der Bot legitim ist, können Sie die Priorität seiner Anforderungen an den Server oder den Zugriff auf bestimmte Ressourcen verringern. Wenn ein Bot als bösartig identifiziert wird, können Sie ihn blockieren oder zur weiteren Analyse an die Sandbox senden. Das Erkennen, Analysieren und Klassifizieren von Web-Bots ist wichtig, da sie beispielsweise geschäftskritische Daten verlieren können. Außerdem wird die Belastung des Servers und das sogenannte Verkehrsrauschen reduziert, da bis zu 66% des Web-Bot-Verkehrs genau sindböswilliger Verkehr .
Bestehende Ansätze
Es gibt verschiedene Techniken zum Erkennen von Web-Bots im Netzwerkverkehr, die von der Begrenzung der Häufigkeit von Anforderungen an einen Host, der Sperrung von IP-Adressen, der Analyse des Werts des User-Agent-HTTP-Headers, dem Fingerabdruck eines Geräts bis hin zur Implementierung von CAPTCHAs und der Verhaltensanalyse der Netzwerkaktivität reichen maschinelles Lernen.
Das Sammeln von Reputationsinformationen über eine Site und das Aktualisieren von Blacklists mithilfe verschiedener Wissensdatenbanken und Bedrohungsinformationen ist jedoch ein kostspieliger und mühsamer Prozess. Bei Verwendung von Proxyservern ist dies nicht ratsam.
Die Analyse des User-Agent-Feldes in erster Näherung mag nützlich erscheinen, aber nichts hindert einen Web-Bot oder einen Benutzer daran, die Werte dieses Felds in einen gültigen zu ändern, sich als regulärer Benutzer zu tarnen und einen gültigen User-Agent für den Browser oder als legitimen Bot zu verwenden. Nennen wir solche Webbots Imitatoren. Durch die Verwendung verschiedener Gerätefingerabdrücke (Verfolgung der Mausbewegung oder Überprüfung der Fähigkeit des Clients, eine HTML-Seite zu rendern) können wir schwer zu erkennende Web-Bots hervorheben , die menschliches Verhalten imitieren, z. B. das Anfordern zusätzlicher Seiten (Stildateien, Symbole usw.) und das Parsen von JavaScript. Dieser Ansatz basiert auf der clientseitigen Code-Injektion, die häufig nicht akzeptabel ist, da ein Fehler beim Einfügen eines zusätzlichen Skripts die Webanwendung beschädigen kann.
Es ist zu beachten, dass Web-Bots auch online erkannt werden können: Die Sitzung wird in Echtzeit ausgewertet. Eine Beschreibung dieser Formulierung des Problems findet sich in Cabri et al. [1] sowie in den Arbeiten von Zi Chu [2]. Ein anderer Ansatz besteht darin, erst nach Ende der Sitzung zu analysieren. Am interessantesten ist natürlich die erste Option, mit der Sie Entscheidungen schneller treffen können.
Der vorgeschlagene Ansatz
Wir haben Techniken des maschinellen Lernens und den ELK-Technologie-Stack (Elasticsearch Logstash Kibana) verwendet, um Web-Bots zu identifizieren und zu klassifizieren. Die Forschungsgegenstände waren HTTP-Sitzungen. Sitzung ist eine Folge von Anforderungen von einem Knoten (eindeutiger Wert der IP-Adresse und des User-Agent-Felds in der HTTP-Anforderung) in einem festen Zeitintervall. Derek und Gohale verwenden ein 30-Minuten-Intervall, um Sitzungsgrenzen zu definieren [3]. Iliu et al. Argumentieren, dass dieser Ansatz keine echte Eindeutigkeit der Sitzung garantiert, aber dennoch akzeptabel ist. Aufgrund der Tatsache, dass das User-Agent-Feld geändert werden kann, werden möglicherweise mehr Sitzungen angezeigt, als tatsächlich vorhanden sind. Daher schlagen Nikiforakis und Co-Autoren eine genauere Abstimmung vor, die darauf basiert, ob ActiveX unterstützt wird, ob Flash aktiviert ist, Bildschirmauflösung, Betriebssystemversion.
Wir werden einen akzeptablen Fehler bei der Bildung einer separaten Sitzung berücksichtigen, wenn sich das Feld User-Agent dynamisch ändert. Um Bot-Sitzungen zu identifizieren, erstellen wir ein klares binäres Klassifizierungsmodell und verwenden:
- automatische Netzwerkaktivität, die von einem Web-Bot (Tag-Bot) generiert wird;
- vom Menschen erzeugte Netzwerkaktivität (Tag human).
Um Web-Bots nach Aktivitätstypen zu klassifizieren, erstellen wir ein Modell mit mehreren Klassen aus der folgenden Tabelle.
| Name | Beschreibung | Etikette | Beispiele von |
|---|---|---|---|
| Crawler | Web-Bots
sammeln Webseiten |
Crawler | SemrushBot,
360Spider, Heritrix |
| Soziale Netzwerke | Web-Bots verschiedener
sozialer Netzwerke |
Soziales Netzwerk | LinkedInBot,
WhatsApp Bot, Facebook Bot |
| RSS-Leser | -,
RSS |
rss | Feedfetcher,
Feed Reader, SimplePie |
| -
|
search_engines | Googlebot, BingBot,
YandexBot |
|
| -,
|
libs_tools | Curl, Wget,
python-requests, scrapy |
|
| - | bots | ||
| ,
User-Agent |
unknown |
Wir werden auch das Problem des Online-Trainings des Modells lösen.
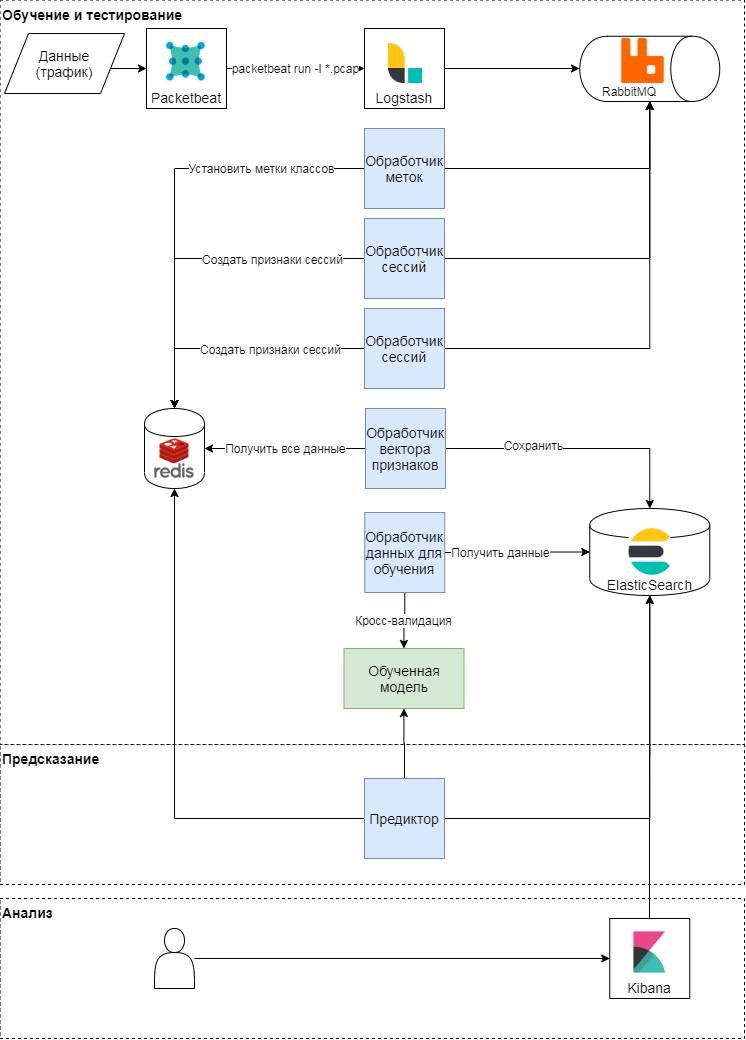
Konzeptionelles Schema des vorgeschlagenen Ansatzes
Dieser Ansatz besteht aus drei Phasen: Training und Testen, Vorhersage, Analyse der Ergebnisse. Betrachten wir die ersten beiden genauer. Konzeptionell folgt der Ansatz dem klassischen Muster des Lernens und der Anwendung von Modellen des maschinellen Lernens. Zunächst werden Qualitätsmetriken und Attribute für die Klassifizierung bestimmt. Danach wird ein Merkmalsvektor gebildet und eine Reihe von Experimenten (verschiedene Gegenprüfungen) durchgeführt, um das Modell zu validieren und Hyperparameter auszuwählen. In der letzten Phase wird das beste Modell ausgewählt und die Qualität des Modells anhand einer verzögerten Stichprobe überprüft.
Modellschulung und -prüfung
Das Packetbeat-Modul wird zum Analysieren des Datenverkehrs verwendet. Rohe HTTP-Anforderungen werden an logstash gesendet, wo Aufgaben mithilfe eines Ruby-Skripts in Sellerie-Begriffen generiert werden. Jeder von ihnen arbeitet mit einer Sitzungskennung, einer Anforderungszeit, einem Anforderungshauptteil und Headern. Sitzungskennung (Schlüssel) - Der Wert der Hash-Funktion aus der Verkettung von IP-Adresse und User-Agent. In dieser Phase werden zwei Arten von Aufgaben erstellt:
- über die Bildung eines Merkmalsvektors für die Sitzung,
- durch Beschriften der Klasse basierend auf dem Anforderungstext und User-Agent.
Diese Aufgaben werden an eine Warteschlange gesendet, in der die Nachrichtenhandler sie ausführen. Somit führt der Labeler- Handler die Aufgabe aus, die Klasse unter Verwendung von Expertenurteilen und offenen Daten aus dem Browscap-Dienst basierend auf dem verwendeten User-Agent zu kennzeichnen. Das Ergebnis wird in den Schlüsselwertspeicher geschrieben. Der Sitzungsprozessor generiert einen Merkmalsvektor (siehe Tabelle unten), schreibt das Ergebnis für jeden Schlüssel in den Schlüsselwertspeicher und legt auch die Schlüssellebensdauer (TTL) fest.
| Schild | Beschreibung |
|---|---|
| len | Anzahl der Anfragen pro Sitzung |
| len_pages | Anzahl der Anforderungen pro Sitzung auf Seiten
(URI endet mit .htm, .html, .php, .asp, .aspx, .jsp) |
| len_static_request | Anzahl der Anforderungen pro Sitzung auf
statischen Seiten |
| len_sec | Sitzungszeit in Sekunden |
| len_unique_uri | Anzahl der Anforderungen pro Sitzung,
die einen eindeutigen URI enthalten |
| headers_cnt | Anzahl der Header pro Sitzung |
| has_cookie | Gibt es einen Cookie-Header? |
| has_referer | Gibt es einen Referer-Header? |
| mean_time_page | Durchschnittliche Zeit pro Seite und Sitzung |
| mean_time_request | Durchschnittliche Zeit pro Anfrage und Sitzung |
| mean_headers | Durchschnittliche Anzahl von Headern pro Sitzung |
Auf diese Weise wird die Feature-Matrix gebildet und die Zielklassenbezeichnung für jede Sitzung festgelegt. Basierend auf dieser Matrix erfolgt ein periodisches Training der Modelle und eine anschließende Auswahl der Hyperparameter. Für das Training verwendeten wir: logistische Regression, Support-Vektor-Maschine, Entscheidungsbäume, Gradientenverstärkung über Entscheidungsbäume, Zufallswald-Algorithmus. Die relevantesten Ergebnisse wurden unter Verwendung des Zufallswaldalgorithmus erhalten.
Prognose
Während des Analysierens des Datenverkehrs wird der Vektor der Sitzungsattribute im Schlüsselwertspeicher aktualisiert: Wenn eine neue Anforderung in der Sitzung angezeigt wird, werden die sie beschreibenden Attribute neu berechnet. Beispielsweise wird das Vorzeichen der durchschnittlichen Anzahl von Headern in einer Sitzung (mean_headers) jedes Mal berechnet, wenn der Sitzung eine neue Anforderung hinzugefügt wird. Der Prädiktor sendet den Sitzungsmerkmalsvektor an das Modell und schreibt die Antwort des Modells zur Analyse an Elasticsearch.
Experiment
Wir haben unsere Lösung im Datenverkehr des SecurityLab.ru-Portals getestet . Datenvolumen - mehr als 15 GB, mehr als 130 Stunden. Die Anzahl der Sitzungen beträgt mehr als 10.000. Aufgrund der Tatsache, dass das vorgeschlagene Modell statistische Funktionen verwendet, waren Sitzungen mit weniger als 10 Anforderungen nicht an Schulungen und Tests beteiligt. Als Qualitätsmetriken haben wir die klassischen Qualitätsmetriken verwendet - Genauigkeit, Vollständigkeit und F-Maß für jede Klasse.
Testen des Web-Bot-Erkennungsmodells
Wir werden ein binäres Klassifizierungsmodell erstellen und bewerten, dh wir werden Bots erkennen und sie dann nach der Art der Aktivität klassifizieren. Basierend auf den Ergebnissen einer fünffach geschichteten Kreuzvalidierung (genau dies ist für die betrachteten Daten erforderlich, da ein starkes Klassenungleichgewicht besteht) können wir sagen, dass das konstruierte Modell recht gut ist (Genauigkeit und Vollständigkeit - mehr als 98%) und in der Lage ist, die Klassen menschlicher Benutzer und Bots zu trennen.
| Durchschnittliche Genauigkeit | Durchschnittliche Fülle | Durchschnittliches F-Maß | |
|---|---|---|---|
| bot | 0,86 | 0,90 | 0,88 |
| Mensch | 0,98 | 0,97 | 0,97 |
Die Ergebnisse des Testens des Modells an einer verzögerten Probe sind in der folgenden Tabelle dargestellt.
| Richtigkeit | Vollständigkeit | F-Maß | Anzahl der
Beispiele |
|
|---|---|---|---|---|
| bot | 0,88 | 0,90 | 0,89 | 1816 |
| Mensch | 0,98 | 0,98 | 0,98 | 9071 |
Die Werte der Qualitätsmetriken für die verzögerte Stichprobe stimmen ungefähr mit den Werten der Qualitätsmetriken während der Modellvalidierung überein, was bedeutet, dass das Modell für diese Daten das während des Trainings gewonnene Wissen verallgemeinern kann.
Betrachten wir die Fehler der ersten Art. Wenn diese Daten fachmännisch markiert werden, ändert sich die Fehlermatrix erheblich. Dies bedeutet, dass beim Markieren der Daten für das Modell einige Fehler gemacht wurden, das Modell solche Sitzungen jedoch weiterhin korrekt erkennen konnte.
| Richtigkeit | Vollständigkeit | F-Maß | Anzahl der
Beispiele |
|
|---|---|---|---|---|
| bot | 0,93 | 0,92 | 0,93 | 2446 |
| Mensch | 0,98 | 0,98 | 0,98 | 8441 |
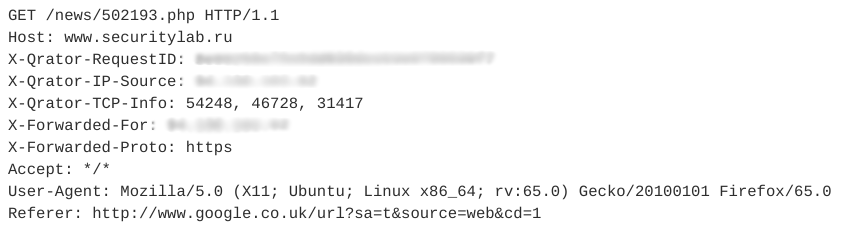
Schauen wir uns ein Beispiel für Sitzungsimitatoren an. Es enthält 12 ähnliche Abfragen. Eine der Anforderungen ist in der folgenden Abbildung dargestellt.
Alle nachfolgenden Anforderungen in dieser Sitzung haben dieselbe Struktur und unterscheiden sich nur in der URI.
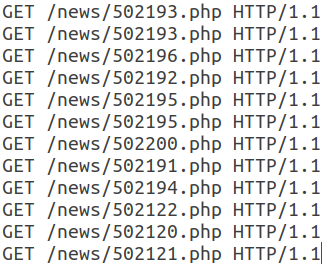
Beachten Sie, dass dieser Webbot einen gültigen User-Agent verwendet, ein Referer-Feld hinzufügt, das normalerweise nicht automatisch verwendet wird, und die Anzahl der Header in einer Sitzung gering ist. Darüber hinaus können wir aufgrund der zeitlichen Merkmale von Anforderungen - Sitzungszeit, durchschnittliche Zeit pro Anforderung - sagen, dass diese Aktivität automatisch erfolgt und zur Klasse der RSS-Reader gehört. In diesem Fall wird der Bot selbst als normaler Benutzer getarnt.
Testen des Web-Bot-Klassifizierungsmodells
Um Web-Bots nach Aktivitätstypen zu klassifizieren, verwenden wir dieselben Daten und denselben Algorithmus wie im vorherigen Experiment. Die Ergebnisse des Testens des Modells an einer verzögerten Probe sind in der folgenden Tabelle dargestellt.
| Richtigkeit | Vollständigkeit | F-Maß | Anzahl der
Beispiele |
|
|---|---|---|---|---|
| bot | 0,82 | 0,81 | 0,82 | 194 |
| Crawler | 0,87 | 0,72 | 0,79 | 65 |
| libs_tools | 0,27 | 0,17 | 0,21 | achtzehn |
| rss | 0,95 | 0,97 | 0,96 | 1823 |
| Suchmaschinen | 0,84 | 0,76 | 0,80 | 228 |
| Soziales Netzwerk | 0,80 | 0,79 | 0,84 | 73 |
| Unbekannt | 0,65 | 0,62 | 0,64 | 45 |
Die Qualität für die Kategorie libs_tools ist gering, aber die unzureichende Anzahl von Beispielen für die Bewertung erlaubt es uns nicht, über die Richtigkeit der Ergebnisse zu sprechen. Eine zweite Reihe von Experimenten sollte durchgeführt werden, um Web-Bots anhand weiterer Daten zu klassifizieren. Wir können mit Zuversicht sagen, dass das aktuelle Modell mit einer ziemlich hohen Genauigkeit und Vollständigkeit in der Lage ist, die Klassen von RSS-Readern, Suchmaschinen und allgemeinen Bots zu trennen.
Nach diesen Experimenten mit den betrachteten Daten werden mehr als 22% der Sitzungen (mit einem Gesamtvolumen von mehr als 15 GB) automatisch erstellt, und 87% beziehen sich auf die Aktivität von Bots allgemeiner Orientierung, unbekannten Bots, RSS-Readern, Web-Bots, die verschiedene Bibliotheken und Dienstprogramme verwenden ... Wenn Sie also den Netzwerkverkehr von Web-Bots nach der Art der Aktivität filtern, reduziert der vorgeschlagene Ansatz die Belastung der verwendeten Serverressourcen um mindestens 9-10%.
Testen des Web-Bot-Klassifizierungsmodells online
Das Wesentliche dieses Experiments ist wie folgt: In Echtzeit werden nach dem Parsen des Verkehrs Merkmale identifiziert und Merkmalsvektoren für jede Sitzung gebildet. In regelmäßigen Abständen wird jede Sitzung zur Vorhersage an das Modell gesendet, deren Ergebnisse gespeichert werden.
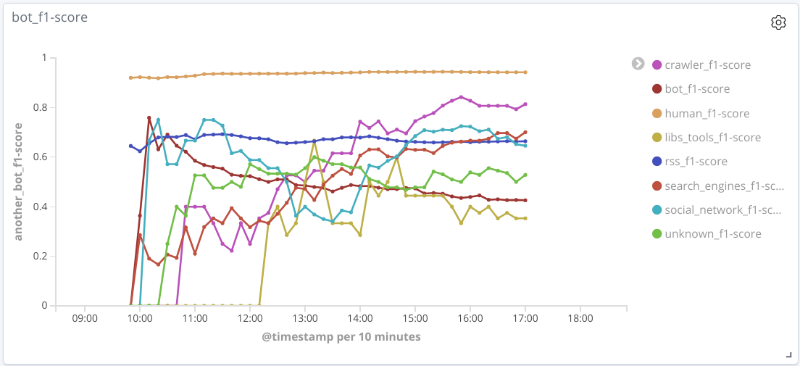
F-Maß des Modells über die Zeit für jede Klasse Die folgenden
Grafiken veranschaulichen die Änderung des Werts der Qualitätsmetriken über die Zeit für die interessantesten Klassen. Die Größe der Punkte auf ihnen hängt von der Anzahl der Sitzungen in der Stichprobe zu einem bestimmten Zeitpunkt ab.

Präzision, Vollständigkeit, F-Maß für die Suchmaschinenklasse

Präzision, Vollständigkeit, F-Maß für die libs tools Klasse
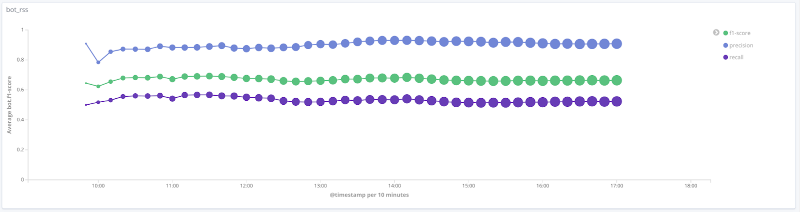
Präzision, Vollständigkeit, F-Maß für die RSS-Klasse

Präzision, Vollständigkeit, F-Maß für die Crawler-Klasse

Präzision, Vollständigkeit, F-Maß für Klasse Mensch
Für eine Reihe von Klassen (human, rss, search_engines) für die betrachteten Daten ist die Qualität des Modells akzeptabel (Genauigkeit und Vollständigkeit betragen mehr als 80%). Für die Crawler-Klasse steigt mit einer Erhöhung der Anzahl der Sitzungen und einer qualitativen Änderung des Merkmalsvektors für diese Stichprobe die Qualität des Modells: Die Vollständigkeit stieg von 33% auf 80%. Es ist unmöglich, vernünftige Schlussfolgerungen für die Klasse libs_tools zu ziehen, da die Anzahl der Beispiele für diese Klasse gering ist (weniger als 50). Daher können negative Ergebnisse (schlechte Qualität) nicht bestätigt werden.
Hauptergebnisse und Weiterentwicklung
Wir haben einen Ansatz zum Erkennen und Klassifizieren von Web-Bots unter Verwendung von Algorithmen für maschinelles Lernen und unter Verwendung statistischer Merkmale beschrieben. Bei den betrachteten Daten beträgt die durchschnittliche Genauigkeit und Vollständigkeit der vorgeschlagenen Lösung für die binäre Klassifizierung mehr als 95%, was darauf hinweist, dass der Ansatz vielversprechend ist. Für bestimmte Klassen von Web-Bots liegt die durchschnittliche Genauigkeit und Vollständigkeit bei etwa 80%.
Die Validierung der konstruierten Modelle erfordert eine echte Bewertung der Sitzung. Wie bereits gezeigt, wird die Leistung eines Modells erheblich verbessert, wenn für die Zielklasse ein korrektes Markup vorliegt. Leider ist es jetzt schwierig, ein solches Markup automatisch zu erstellen, und Sie müssen auf Experten-Markup zurückgreifen, was die Erstellung von Modellen für maschinelles Lernen erschwert, es Ihnen jedoch ermöglicht, versteckte Muster in den Daten zu finden.
Für die Weiterentwicklung des Problems der Klassifizierung und Erkennung von Web-Bots ist es ratsam:
- Weisen Sie zusätzliche Klassen von Bots zu und trainieren Sie das Modell neu.
- Fügen Sie zusätzliche Zeichen hinzu, um Web-Bots zu klassifizieren. Wenn Sie beispielsweise ein robots.txt-Attribut hinzufügen, das binär ist und für das Vorhandensein oder Fehlen eines Zugriffs auf eine robots.txt-Seite verantwortlich ist, können Sie den durchschnittlichen F-Score für eine Klasse von Web-Bots um 3% erhöhen, ohne andere Qualitätsmetriken für andere Klassen zu verschlechtern.
- Nehmen Sie unter Berücksichtigung zusätzlicher Metafunktionen und Expertenmeinungen ein korrekteres Markup für die Zielklasse vor.
Autor : Nikolay Lyfenko, führender Spezialist, Advanced Technologies Group, Positive Technologies
Quellen
[1] Cabri A. et al. Online Web Bot Detection Using a Sequential Classification Approach. 2018 IEEE 20th International Conference on High Performance Computing and Communications.
[2] Chu Z., Gianvecchio S., Wang H. (2018) Bot or Human? A Behavior-Based Online Bot Detection System. In: Samarati P., Ray I., Ray I. (eds) From Database to Cyber Security. Lecture Notes in Computer Science, vol. 11170. Springer, Cham.
[3] Derek D., Gokhale S. An integrated method for real time and offline web robot detection. Expert Systems 33. 2016.
[4] Iliou Ch., et al. Towards a framework for detecting advanced Web bots. Proceedings of the 14th International Conference on Availability, Reliability and Security. 2019.
[5] Nikiforakis N., Kapravelos A., Joosen W., Kruegel C., Piessens F. and Vigna G. Cookieless Monster: Exploring the Ecosystem of Web-Based Device Fingerprinting. 2013 IEEE Symposium on Security and Privacy, Berkeley, CA, 2013, pp. 541—555.
[2] Chu Z., Gianvecchio S., Wang H. (2018) Bot or Human? A Behavior-Based Online Bot Detection System. In: Samarati P., Ray I., Ray I. (eds) From Database to Cyber Security. Lecture Notes in Computer Science, vol. 11170. Springer, Cham.
[3] Derek D., Gokhale S. An integrated method for real time and offline web robot detection. Expert Systems 33. 2016.
[4] Iliou Ch., et al. Towards a framework for detecting advanced Web bots. Proceedings of the 14th International Conference on Availability, Reliability and Security. 2019.
[5] Nikiforakis N., Kapravelos A., Joosen W., Kruegel C., Piessens F. and Vigna G. Cookieless Monster: Exploring the Ecosystem of Web-Based Device Fingerprinting. 2013 IEEE Symposium on Security and Privacy, Berkeley, CA, 2013, pp. 541—555.