
Ich erzähle aus eigener Erfahrung, was wo und wann nützlich war. Umfrage und These, damit klar war, was und wo man als nächstes gräbt - aber hier habe ich eine ausschließlich subjektive persönliche Erfahrung, vielleicht ist bei Ihnen alles ganz anders.
Warum ist es wichtig, Abfragesprachen zu kennen und damit umgehen zu können? Im Kern hat Data Science mehrere wichtige Arbeitsphasen, und die allererste und wichtigste (ohne sie funktioniert natürlich nichts!) Ist die Datenerfassung oder -abfrage. Meistens befinden sich Daten in irgendeiner Form irgendwo und Sie müssen sie von dort "abrufen".
Mit Abfragesprachen können Sie nur genau diese Daten extrahieren! Und heute werde ich Ihnen von den Abfragesprachen erzählen, die sich für mich als nützlich erwiesen haben, und ich werde zeigen, wo und wie genau - warum es zum Lernen benötigt wird.
Insgesamt gibt es drei Hauptblöcke von Arten von Datenabfragen, die wir in diesem Artikel analysieren werden:
- "Standard" -Abfragesprachen verstehen sie normalerweise, wenn sie über eine Abfragesprache wie relationale Algebra oder SQL sprechen.
- Skript-Abfragesprachen: Zum Beispiel Pythons Pandas, Numpy oder Shell-Skripte.
- Abfragesprachen für Wissensgraphen und Graphendatenbanken.
Alles, was hier geschrieben steht, ist nur eine persönliche Erfahrung, die sich als nützlich erwiesen hat, mit einer Beschreibung der Situationen und "warum es gebraucht wurde" - jeder kann versuchen, wie ähnliche Situationen Sie treffen können, und versuchen, sich im Voraus darauf vorzubereiten, nachdem er sich mit diesen Sprachen befasst hat, bevor Sie es müssen sich (dringend) für ein Projekt bewerben oder sogar für ein Projekt, bei dem sie benötigt werden.
"Standard" Abfragesprachen
Standard-Abfragesprachen sind genau in dem Sinne, dass wir normalerweise über sie nachdenken, wenn wir über Abfragen sprechen.
Relationale Algebra
Warum wird heute relationale Algebra benötigt? Um eine gute Vorstellung davon zu haben, warum Abfragesprachen auf bestimmte Weise angeordnet sind, und um sie bewusst zu verwenden, müssen Sie den zugrunde liegenden Kern verstehen.
Was ist relationale Algebra?
Die formale Definition lautet wie folgt: Relationale Algebra ist ein geschlossenes System von Operationen auf Beziehungen in einem relationalen Datenmodell. Menschlicher ist dies ein System von Operationen an Tabellen, so dass das Ergebnis auch immer eine Tabelle ist.
Sehen Sie sich alle relationalen Operationen in diesem Artikel von Habr an - hier beschreiben wir, warum Sie wissen müssen und wo es nützlich ist.
Wozu?
Sie beginnen zu verstehen, wofür Abfragesprachen im Allgemeinen verwendet werden und welche Operationen hinter den Ausdrücken bestimmter Abfragesprachen stehen. Oft erhalten Sie ein tieferes Verständnis dafür, was und wie in Abfragesprachen funktioniert.
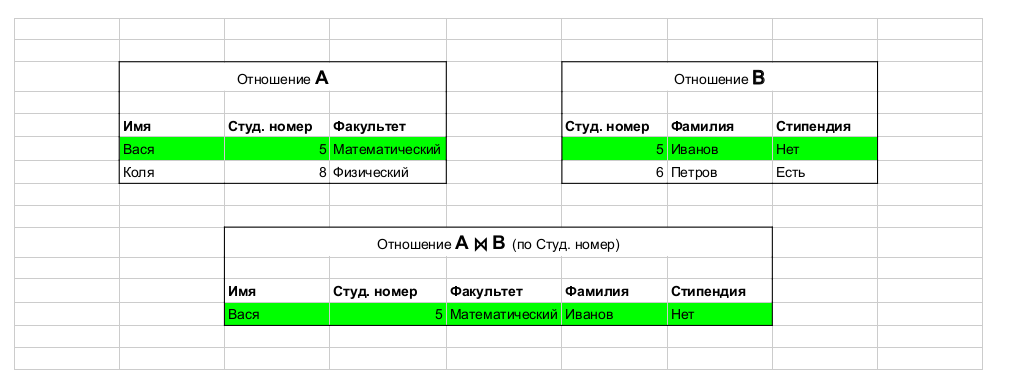
Aus diesem Artikel entnommen . Beispieloperation: join, die Tabellen verbindet.
Lernmaterialien:
Ein guter Einführungskurs von Stanford . Im Allgemeinen gibt es viele Materialien zur relationalen Algebra und Theorie - Coursera, Udacity. Es gibt auch eine große Menge an Online-Materialien, einschließlich guter akademischer Kurse . Mein persönlicher Rat ist, die relationale Algebra sehr gut zu verstehen - das ist die Grundlage.
SQL

Aus diesem Artikel entnommen .
SQL ist in der Tat eine Implementierung der relationalen Algebra - mit einer wichtigen Einschränkung ist SQL deklarativ! Das heißt, wenn Sie eine Abfrage in der Sprache der relationalen Algebra schreiben, sagen Sie tatsächlich, wie man zählt - aber mit SQL geben Sie an, was Sie extrahieren möchten, und dann generiert das DBMS bereits (effektive) Ausdrücke in der Sprache der relationalen Algebra (ihre Äquivalenz ist uns unter Codds Theorem bekannt ). ...
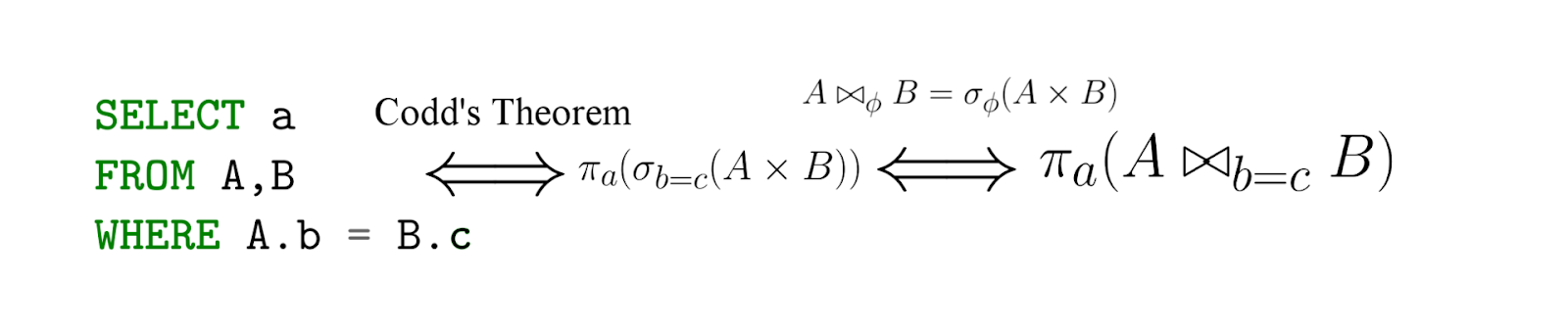
Aus diesem Artikel entnommen .
Wozu?
Relationale DBMS: Oracle, Postgres, SQL Server usw. sind immer noch praktisch überall und es besteht eine unglaublich hohe Wahrscheinlichkeit, dass Sie mit ihnen interagieren müssen, was bedeutet, dass Sie entweder SQL lesen (was sehr wahrscheinlich ist) oder darin schreiben müssen ( auch nicht unwahrscheinlich).
Was zu lesen und zu lernen ist
Von denselben Links oben (zur relationalen Algebra) gibt es eine unglaubliche Menge an Material, wie dieses .
Was ist übrigens NoSQL?
"Es ist noch einmal hervorzuheben, dass der Begriff" NoSQL "einen völlig spontanen Ursprung hat und keine allgemein anerkannte Definition oder wissenschaftliche Einrichtung dahinter hat." Der entsprechende Artikel über Habré.
Tatsächlich wurde den Menschen klar, dass ein vollständiges relationales Modell nicht erforderlich ist, um viele Probleme zu lösen, insbesondere bei solchen, bei denen beispielsweise die Leistung von grundlegender Bedeutung ist und bestimmte einfache Abfragen mit Aggregation dominieren. Es ist wichtig, Metriken schnell zu lesen und in die Datenbank zu schreiben, und die meisten Funktionen sind relational. Es stellte sich heraus, dass dies nicht nur unnötig, sondern auch schädlich ist - warum etwas normalisieren, wenn es das Wichtigste für uns (für eine bestimmte Aufgabe) - die Leistung - beeinträchtigt?
Außerdem werden häufig flexible Schemata anstelle der festen mathematischen Schemata des klassischen relationalen Modells benötigt - und dies vereinfacht die Anwendungsentwicklung unglaublich, wenn es wichtig ist, das System bereitzustellen und schnell zu arbeiten und die Ergebnisse zu verarbeiten - oder das Schema und die Arten der gespeicherten Daten sind nicht so wichtig.
Zum Beispiel erstellen wir ein Expertensystem und möchten Informationen in einer bestimmten Domäne zusammen mit einigen Metainformationen speichern - wir kennen möglicherweise nicht alle Felder und es ist kitschig, JSON für jeden Datensatz zu speichern - dies gibt uns eine sehr flexible Umgebung für die Erweiterung des Datenmodells und die schnelle Iteration - daher in einer solchen Der Fall von NoSQL wäre sogar vorzuziehen und lesbar. Ein Beispiel für einen Eintrag (aus einem meiner Projekte, in dem NoSQL genau dort war, wo es benötigt wurde).
{"en_wikipedia_url":"https://en.wikipedia.org/wiki/Johnny_Cash",
"ru_wikipedia_url":"https://ru.wikipedia.org/wiki/?curid=301643",
"ru_wiki_pagecount":149616,
"entity":[42775," ","ru"],
"en_wiki_pagecount":2338861}
Weitere Informationen zu NoSQL finden Sie hier .
Was zu studieren?
Hier müssen Sie nur gut darin sein, Ihre Aufgabe zu analysieren, welche Eigenschaften sie hat und welche NoSQL-Systeme verfügbar sind, die zu dieser Beschreibung passen - und dieses System bereits studieren.
Skript-Abfragesprachen
Zunächst scheint es, was Python damit zu tun hat - es ist eine Programmiersprache und überhaupt keine Abfragen.

- Pandas ist ein direktes Schweizer Messer der Datenwissenschaft, in dem eine große Menge an Datentransformation, Aggregation usw. stattfindet.
- Numpy ist Vektor-Computing, Matrizen und lineare Algebra da draußen.
- Scipy ist eine Menge Mathe in diesem Paket, insbesondere Statistiken.
- Jupyter-Labor - viele explorative Datenanalysen passen gut in Laptops - gut zu können.
- Anfragen - Vernetzung.
- Pysparks sind bei Dateningenieuren sehr beliebt. Wahrscheinlich müssen Sie mit diesem oder einem Funken interagieren, einfach wegen ihrer Beliebtheit.
- * Selen ist sehr nützlich, um Daten von Websites und Ressourcen zu sammeln. Manchmal gibt es einfach keine andere Möglichkeit, die Daten abzurufen.
Mein Top-Tipp: Lerne Python!
Pandas
Nehmen wir als Beispiel den folgenden Code:
import pandas as pd
df = pd.read_csv(“data/dataset.csv”)
# Calculate and rename aggregations
all_together = (df[df[‘trip_type’] == “return”]
.groupby(['start_station_name','end_station_name'])\
.agg({'trip_duration_seconds': [np.size, np.mean, np.min, np.max]})\
.rename(columns={'size': 'num_trips',
'mean': 'avg_duration_seconds',
'amin': min_duration_seconds',
‘amax': 'max_duration_seconds'}))Tatsächlich können wir sehen, dass der Code in das klassische SQL-Muster passt.
SELECT start_station_name, end_station_name, count(trip_duration_seconds) as size, …..
FROM dataset
WHERE trip_type = ‘return’
GROUPBY start_station_name, end_station_nameDer wichtige Teil ist jedoch, dass dieser Code Teil des Skripts und der Pipeline ist. Tatsächlich binden wir Anforderungen in die Python-Pipeline ein. In dieser Situation kommt die Abfragesprache aus Bibliotheken wie Pandas oder pySpark.
Im Allgemeinen sehen wir in pySpark eine ähnliche Art der Datentransformation durch die Abfragesprache im Sinne von:
df.filter(df.trip_type = “return”)\
.groupby(“day”)\
.agg({duration: 'mean'})\
.sort()Wo und was zu lesen ist
Es ist kein Problem, Materialien für das Studium von Python selbst zu finden . Es gibt eine Vielzahl von Tutorials zu Pandas , pySpark und Kursen zu Spark (sowie zu DS selbst ) im Internet . Im Allgemeinen sind die Materialien hier hervorragend gegoogelt, und wenn ich ein Paket auswählen müsste, auf das ich mich konzentrieren möchte, wären es natürlich Pandas. Das DS + Python-Bundle enthält auch viele Materialien .
Shell als Abfragesprache
Viele Datenverarbeitungs- und Analyseprojekte, mit denen ich arbeiten musste, sind Shell-Skripte, die Code in Python, Java und den Shell-Befehlen selbst aufrufen. Daher können Sie die Pipelines in bash / zsh / etc im Allgemeinen als eine übergeordnete Anforderung betrachten (Sie können dort natürlich Schleifen verschieben, dies ist jedoch nicht typisch für DS-Code in Shell-Sprachen). Wir geben ein einfaches Beispiel - ich musste die Wikidata-QID und zuordnen Ein vollständiger Link zum russischen und englischen Wiki. Dazu habe ich eine einfache Abfrage aus den Befehlen in der Bash geschrieben und für die Ausgabe ein einfaches Skript in Python geschrieben, das ich wie folgt zusammengestellt habe:
pv “data/latest-all.json.gz” |
unpigz -c |
jq --stream $JQ_QUERY |
python3 scripts/post_process.py "output.csv"
Wo
JQ_QUERY = 'select((.[0][1] == "sitelinks" and (.[0][2]=="enwiki" or .[0][2] =="ruwiki") and .[0][3] =="title") or .[0][1] == "id")' Dies war in der Tat die gesamte Pipeline, die das erforderliche Mapping erstellt hat. Wie wir alles sehen, funktionierte es im Stream-Modus:
- pv-Dateipfad - Gibt einen Fortschrittsbalken basierend auf der Dateigröße an und gibt dessen Inhalt weiter
- unpigz -c las einen Teil des Archivs und gab jq
- jq mit dem Schlüsselstrom erzeugte sofort das Ergebnis und übergab es an den Postprozessor (genau wie beim allerersten Beispiel) in Python
- Intern ist der Postprozessor eine einfache Zustandsmaschine, die die Ausgabe formatiert
Insgesamt eine komplexe Pipeline, die im Stream-Modus mit Big Data (0,5 TB) ohne nennenswerte Ressourcen arbeitet und aus einer einfachen Pipeline und einigen Tools besteht.
Ein weiterer wichtiger Tipp: Seien Sie gut und effizient im Terminal und schreiben Sie in bash / zsh / etc.Wo ist es nützlich? Ja, fast überall - es gibt wieder eine Menge Materialien zum Lernen im Internet. Insbesondere ist dies mein früherer Artikel.
R-Skripting
Auch hier kann der Leser ausrufen - nun, dies ist eine ganze Programmiersprache! Und natürlich wird er recht haben. Normalerweise musste ich mich jedoch immer mit R in einem solchen Kontext befassen, dass es tatsächlich einer Abfragesprache sehr ähnlich war.
R ist ein statistischer Rechen Rahmen und eine statischen Rechen- und Visualisierungs Sprache (entsprechend dieser ).
Von hier genommen . Übrigens empfehle ich gutes Material.
Warum mit einem Wissenschaftler ausgehen, um R zu kennen? Zumindest, weil es in R eine große Anzahl von Nicht-IT-Mitarbeitern gibt, die sich mit Datenanalyse beschäftigen. Ich habe mich an folgenden Orten getroffen:
- Pharmazeutischer Sektor.
- Biologen.
- Finanzsektor.
- Menschen mit einer rein mathematischen Ausbildung, die sich mit Statistiken befassen.
- Spezialisierte statistische und maschinelle Lernmodelle (die oft nur in der Upstream-Version als R-Paket zu finden sind).
Warum ist es eigentlich eine Abfragesprache? In der Form, in der es häufig gefunden wird, handelt es sich tatsächlich um eine Anforderung zum Erstellen eines Modells, einschließlich Lesen von Daten und Festlegen von Abfrageparametern (Modell) sowie Visualisieren von Daten in Paketen wie ggplot2 - dies ist auch eine Form zum Schreiben von Abfragen.
Beispiel für Abfragen zum Rendern
ggplot(data = beav,
aes(x = id, y = temp,
group = activ, color = activ)) +
geom_line() +
geom_point() +
scale_color_manual(values = c("red", "blue"))Im Allgemeinen sind viele Ideen von R auf Python-Pakete wie Pandas, Numpy oder Scipy wie Datenrahmen und Datenvektorisierung migriert worden. Daher werden Ihnen im Allgemeinen viele Dinge in R vertraut und praktisch erscheinen.
Es gibt viele Quellen zum Studieren, zum Beispiel diese .
Wissensgraph
Hier habe ich eine etwas ungewöhnliche Erfahrung, weil ich immer noch ziemlich oft mit Wissensgraphen und Abfragesprachen für Graphen arbeiten muss. Lassen Sie uns deshalb kurz auf die Grundlagen eingehen, da dieser Teil etwas exotischer ist.
In klassischen relationalen Datenbanken haben wir ein festes Schema - hier ist das Schema flexibel, jedes Prädikat ist tatsächlich eine „Spalte“ und noch mehr.
Stellen Sie sich vor, Sie würden eine Person modellieren und wichtige Dinge beschreiben. Nehmen wir zum Beispiel eine bestimmte Person von Douglas Adams. Wir nehmen diese Beschreibung als Grundlage.
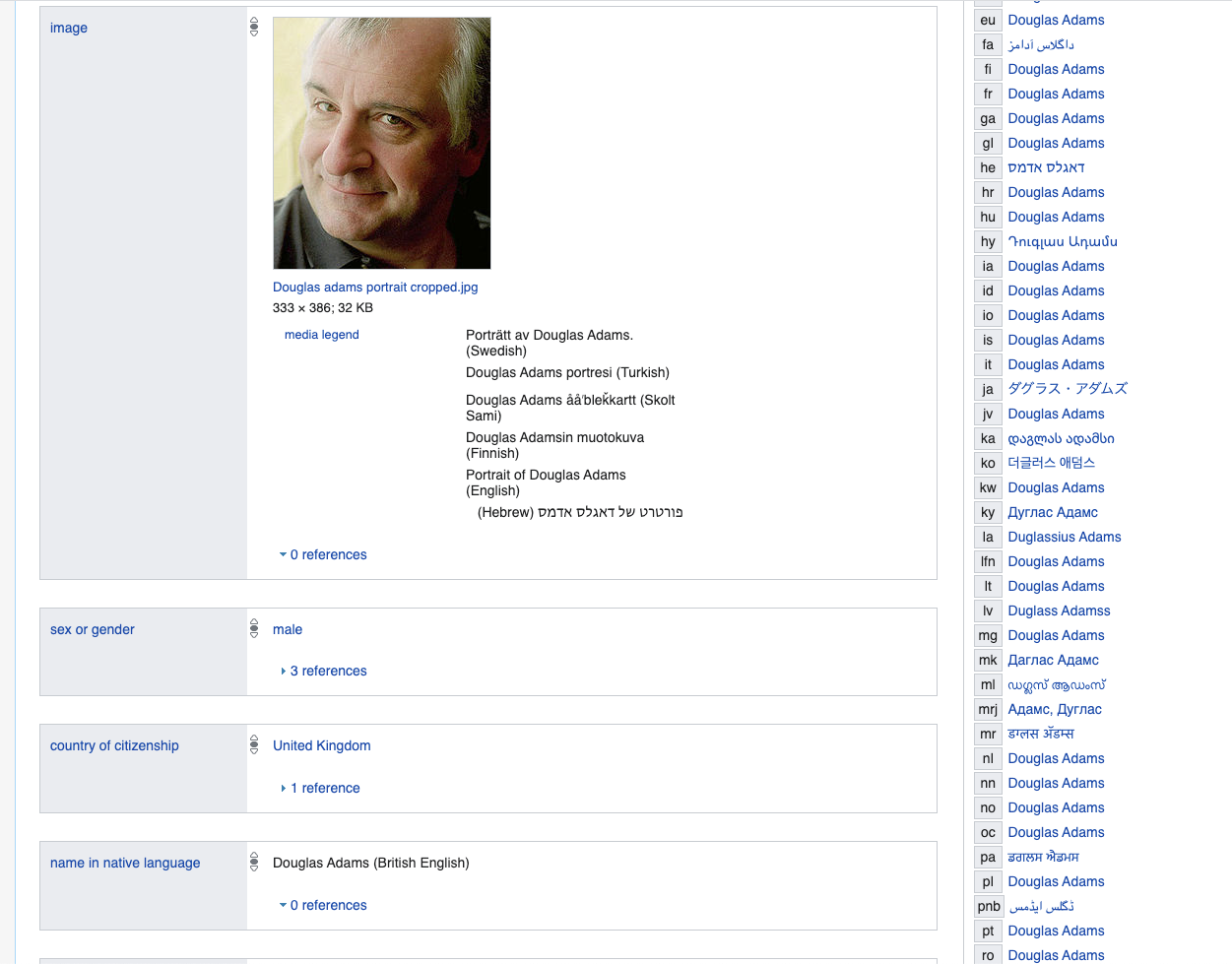
www.wikidata.org/wiki/Q42
Wenn wir eine relationale Datenbank verwenden würden, müssten wir eine große Tabelle oder Tabellen mit einer großen Anzahl von Spalten erstellen, von denen die meisten NULL wären oder mit einem Standardwert von False gefüllt wären, was beispielsweise unwahrscheinlich wäre Viele von uns haben einen Eintrag in der koreanischen Nationalbibliothek - natürlich könnten wir sie in separate Tabellen einfügen, aber dies wäre letztendlich ein Versuch, flexible Logik mit Prädikaten unter Verwendung einer festen relationalen zu modellieren.
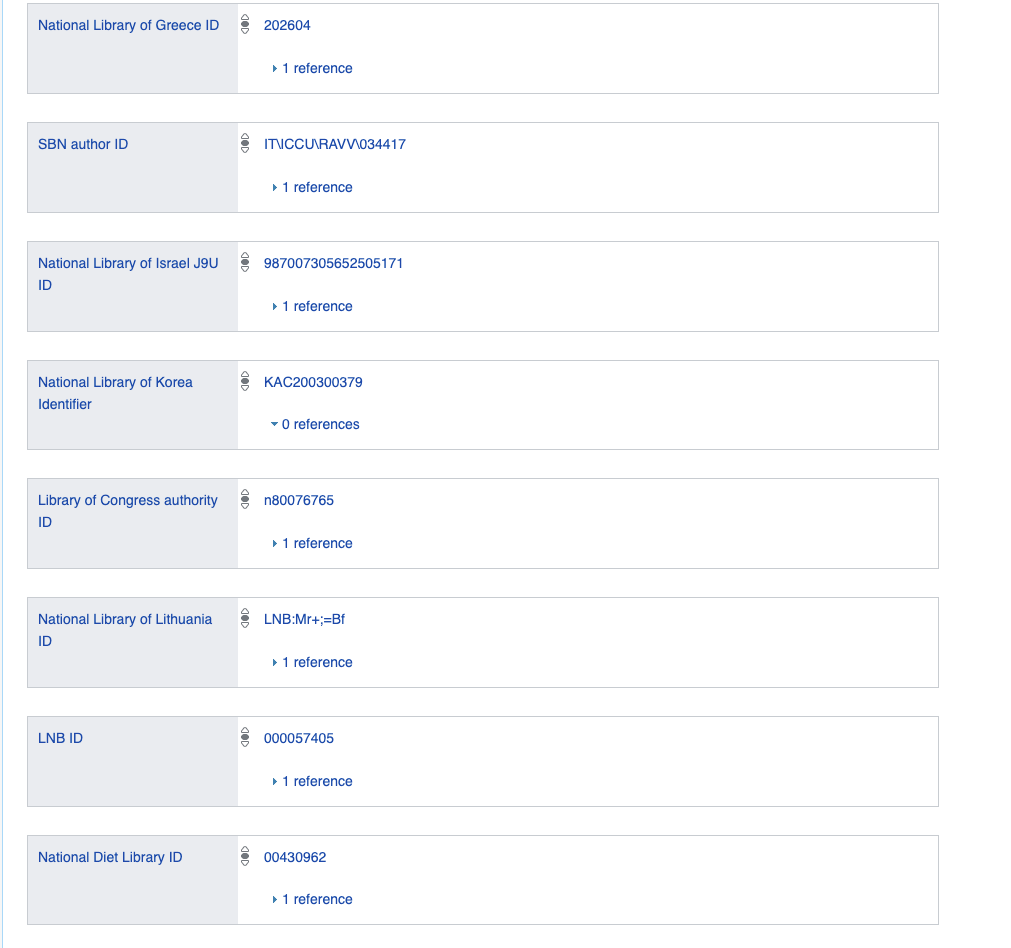
Stellen Sie sich daher vor, dass alle Daten als Graph oder als binäre und unäre logische Ausdrücke gespeichert werden.
Wo kannst du überhaupt darauf stoßen? Arbeiten Sie zunächst mit Wiki-Daten und mit beliebigen Grafikdatenbanken oder verbundenen Daten.
Im Folgenden sind die wichtigsten Abfragesprachen aufgeführt, mit denen ich gearbeitet habe.
SPARQL
Wiki:
SPARQL ( . SPARQL Protocol and RDF Query Language) — , RDF, . SPARQL W3C .
In Wirklichkeit ist es jedoch eine Sprache der Abfragen an logische unäre und binäre Prädikate. Sie geben nur bedingt an, was in einem booleschen Ausdruck festgelegt ist und was nicht (sehr simpel).
Die RDF-Basis (Resource Description Framework) selbst, über die SPARQL-Abfragen ausgeführt werden, ist ein Triplett
object, predicate, subject- und die Abfrage wählt die erforderlichen Triplets gemäß den angegebenen Einschränkungen aus, um ein X so zu finden, dass p_55 (X, q_33) wahr ist - wobei natürlich p_55 was ist -diese Beziehung zu ID 55 und q_33 ist ein Objekt mit ID 33 (das ist die ganze Geschichte, wobei alle möglichen Details weggelassen werden).
Beispiel für die Datenpräsentation:
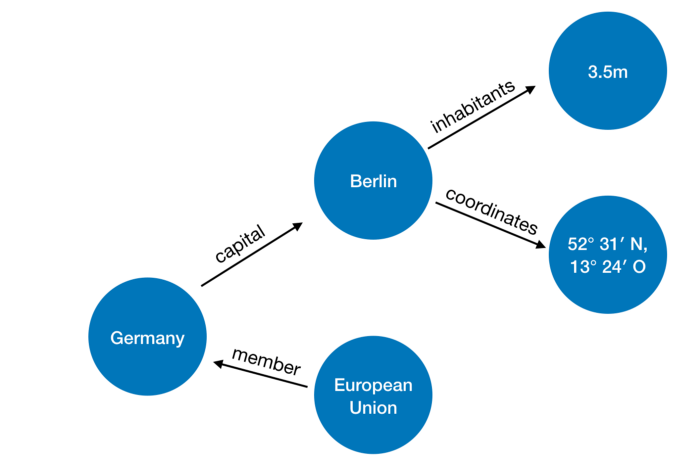
Bilder und ein Beispiel mit Ländern sind von hier .
Grundlegendes Abfragebeispiel

Tatsächlich möchten wir den Wert der Variablen? Country ermitteln, sodass für das Prädikat
member_of wahr ist, dass member_of (? Country, q458) und q458 die ID der Europäischen Union ist.
Ein Beispiel für eine echte SPARQL-Abfrage in der Python-Engine:
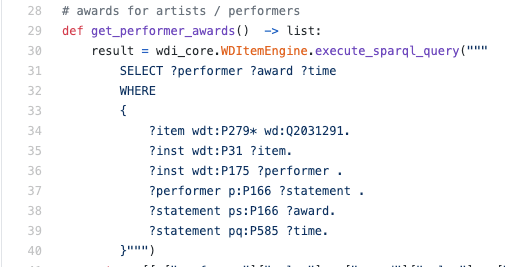
In der Regel musste ich SPARQL lesen, nicht schreiben - in einer solchen Situation ist es höchstwahrscheinlich eine nützliche Fähigkeit, die Sprache zumindest auf einer grundlegenden Ebene zu verstehen, um genau zu verstehen, wie die Daten abgerufen werden.
Es gibt viel Online-Lernmaterial, wie dieses und dieses . Ich selbst google normalerweise bestimmte Konstruktionen und Beispiele, und bis jetzt habe ich genug.
Logische Abfragesprachen
Weitere Informationen zum Thema finden Sie in meinem Artikel hier . Hier werden wir nur kurz diskutieren, warum logische Sprachen zum Schreiben von Abfragen gut geeignet sind. Tatsächlich ist RDF nur eine Sammlung logischer Anweisungen der Form p (X) und h (X, Y), und eine logische Abfrage sieht folgendermaßen aus:
output(X) :- country(X), member_of(X,“EU”).
Hier geht es um das Erstellen einer neuen Prädikatausgabe / 1 (/ 1 bedeutet unär), wenn vorausgesetzt, es gilt für X dieses Land (X) - das heißt, X ist das Land und auch Mitglied von (X, „EU“).
Das heißt, wir haben sowohl die Daten als auch die Regeln in diesem Fall im Allgemeinen auf die gleiche Weise dargestellt, was es sehr einfach und gut macht, Aufgaben zu modellieren.
Wo haben Sie sich in der Branche getroffen?: ein ganz großes Projekt mit einem Unternehmen, das Abfragen in einer solchen Sprache schreibt, sowie zum aktuellen Projekt im Kern des Systems - es scheint eine ziemlich exotische Sache zu sein, aber manchmal kommt es vor
Ein Beispiel für einen Codeausschnitt in wikidata zur Verarbeitung logischer Sprachen:
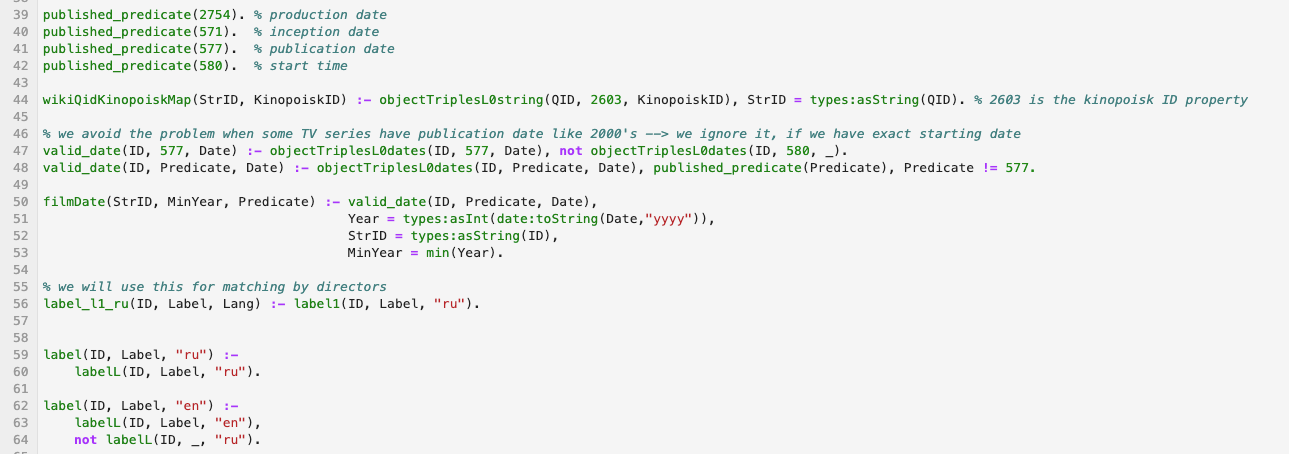
Materialien: Ich werde hier einige Links zur modernen logischen Programmiersprache geben. Answer Set Programming - Ich empfehle, sie zu studieren:
- http://peace.eas.asu.edu/aaai12tutorial/asp-tutorial-aaai.pdf
- http://ceur-ws.org/Vol-1145/tutorial1.pdf
- https://www.youtube.com/watch?v=gVQ0bP8zyHw
- https://www.youtube.com/watch?v=kdcd7Je2glc
- https://potassco.org/book/
- http://potassco.sourceforge.net/teaching.html
- https://www.cs.uni-potsdam.de/~torsten/Potassco/Tutorials/fmcad12.pdf
