
Fortsetzung der Sammlung von Geschichten aus dem Internet darüber, wie Fehler manchmal völlig unglaubliche Erscheinungsformen haben. Der erste Teil ist hier .
Mehr Magie
Vor einigen Jahren kramte ich in den Schränken, in denen sich der PDP-10-Computer befand, der zum MIT AI-Labor gehörte. Ich bemerkte einen kleinen Schalter, der an den Rahmen eines der Schränke geklebt war. Es war klar, dass es sich um ein hausgemachtes Produkt handelte, das von einem der Laborhandwerker hinzugefügt wurde (niemand wusste genau, wer).
Sie werden keinen unbekannten Schalter an Ihrem Computer berühren, ohne zu wissen, was er tut, da Sie Ihren Computer beschädigen könnten. Der Schalter war völlig unverständlich signiert. Es hatte zwei Positionen und die Wörter "Magie" und "mehr Magie" wurden mit Bleistift auf den Metallkörper gekritzelt. Der Schalter befand sich in der magischeren Position. Ich rief einen der Techniker an, um einen Blick darauf zu werfen. Er hatte so etwas noch nie gesehen. Bei näherer Betrachtung stellte sich heraus, dass nur ein Draht zum Schalter führt! Das andere Ende des Kabels verschwand im Kabelsalat im Computer, aber die Art der Elektrizität schreibt vor, dass ein Schalter nichts tut, bis Sie zwei Kabel daran anschließen.
Es war offensichtlich, dass dies jemandes dummer Witz war. Nachdem wir sichergestellt haben, dass der Schalter nichts tut, schalten wir ihn um. Der Computer wurde sofort ohnmächtig.
Stellen Sie sich unser Erstaunen vor. Wir haben es als Zufall gekreidet, aber den Knopf immer noch in die "magischere" Position gebracht, bevor wir den Computer gestartet haben.
Ein Jahr später erzählte ich diese Geschichte einem anderen Techniker, David Moon, soweit ich mich erinnern kann. Er stellte meine Angemessenheit in Frage oder vermutete, an die übernatürliche Natur dieses Schalters zu glauben, oder dachte, ich würde mit seiner falschen Geschichte herumalbern. Um meinen Standpunkt zu beweisen, zeigte ich ihm diesen Schalter, der immer noch am Rahmen klebte und mit einem einzigen Draht immer noch in der "magischeren" Position war. Wir haben den Schalter und das Kabel genau untersucht und festgestellt, dass es geerdet ist. Es sah doppelt bedeutungslos aus: Der Schalter war nicht nur elektrisch außer Betrieb, sondern auch an einer Stelle angeschlossen, die nichts beeinflusste. Wir haben es in eine andere Position gebracht.
Der Computer wurde sofort leer.
Wir haben uns an Richard Greenblatt gewandt, der ein langjähriger Techniker am MIT war und in der Nähe war. Auch er hatte den Schalter noch nie gesehen. Ich untersuchte es, kam zu dem Schluss, dass der Schalter unbrauchbar war, nahm die Drahtschneider heraus und schnitt den Draht ab. Dann schalteten wir den Computer ein und er begann leise zu arbeiten.
Wir wissen immer noch nicht, wie dieser Schalter den Computer heruntergefahren hat. Es gibt eine Hypothese, dass ein kleiner Kurzschluss in der Nähe des Massekontakts auftrat und die Verschiebung der Schalterpositionen die elektrische Kapazität veränderte, so dass der Stromkreis unterbrochen wurde, wenn Impulse mit einer Dauer von einer Millionstel Sekunde durch ihn gingen. Aber wir werden es nicht sicher wissen. Wir können nur sagen, dass der Schalter magisch war.
Es ist immer noch in meinem Keller. Das ist wahrscheinlich albern, aber ich halte es normalerweise in der "magischeren" Position.
1994 wurde eine andere Erklärung für diese Geschichte vorgeschlagen. Beachten Sie, dass der Schalterkörper aus Metall bestand. Angenommen, ein Kontakt ohne zweiten Draht wurde mit dem Körper verbunden (normalerweise ist der Körper geerdet, es gibt jedoch Ausnahmen). Der Schalterkörper war mit dem Computergehäuse verbunden, das wahrscheinlich geerdet war. Dann kann der Erdungskreis in der Maschine ein anderes Potential als der Rahmenerdungskreis haben, und das Ändern der Position des Schalters führte zu einem Spannungsabfall oder Spannungsanstieg, und die Maschine wurde neu gestartet. Dieser Effekt wurde wahrscheinlich von jemandem entdeckt, der über den möglichen Unterschied Bescheid wusste und sich für einen solchen Witzwechsel entschied.
OpenOffice wird dienstags nicht gedruckt
Heute bin ich auf dem Blog auf einen interessanten Fehler gestoßen. Einige Leute hatten Probleme beim Drucken von Dokumenten. Später bemerkte jemand, dass seine Frau sich darüber beschwerte, dass sie dienstags nicht drucken könne!
In den Fehlerberichten haben sich einige zunächst darüber beschwert, dass es sich um einen OpenOffice-Fehler handeln muss, da er von allen anderen Anwendungen problemlos gedruckt wurde. Andere haben festgestellt, dass das Problem kommt und geht. Ein Benutzer hat eine Lösung gefunden: Deinstallieren Sie OpenOffice, löschen Sie das System und installieren Sie es erneut (jede einfache Aufgabe unter Ubuntu). Der Benutzer berichtete am Dienstag, dass sein Druckproblem behoben wurde.
Zwei Wochen später schrieb er (am Dienstag), dass seine Lösung immer noch nicht funktioniere. Ungefähr vier Monate später beschwerte sich die Frau des Ubuntu-Hackers, dass OpenOffice dienstags nicht gedruckt habe. Stellen Sie sich diese Situation vor:
Frau: Steve, der Drucker ist dienstags geschlossen.
Steve: Es ist ein freier Tag am Drucker, natürlich wird dienstags nicht gedruckt.
Frau: Ich meine es ernst! Ich kann dienstags nicht aus OpenOffice drucken.
Steve: (ungläubig) Okay, zeig es mir.
Frau: Ich kann es dir nicht zeigen.
Steve: rollt mit den Augen Warum?
Frau: Heute ist Mittwoch!
Steve: (nickt, spricht langsam) Richtig.
Das Problem wurde auf ein Programm namens zurückgeführt
file. Dieses * NIX-Dienstprogramm verwendet Vorlagen zum Bestimmen von Dateitypen. Zum Beispiel, wenn die Datei mit beginnt%!und dann geht es PS-Adobe-, dann ist es PostScript. Offenbar schreibt OpenOffice Daten in eine solche Datei. Am Dienstag nimmt er seine Uniform %%CreationDate: (Tue MMM D hh:mm:...). Ein Fehler in der Vorlage für Erlang-JAM-Dateien führte dazu, dass Tuedie PostScript-Datei als Erlang-JAM-Datei erkannt wurde und daher vermutlich nicht zum Drucken gesendet wurde.
Die Vorlage für die Erlang JAM-Datei sieht folgendermaßen aus:
4 string Tue Jan 22 14:32:44 MET 1991 Erlang JAM file - version 4.2
Und es sollte so aussehen:
4 string Tue\ Jan\ 22\ 14:32:44\ MET\ 1991 Erlang JAM file - version 4.2
Angesichts der Vielzahl von Dateitypen, die dieses Programm zu erkennen versucht (über 1600), sind Vorlagenfehler nicht überraschend. Die Reihenfolge des Vergleichs führt aber auch zu häufigen Fehlalarmen. In diesem Fall wurde der Erlang-JAM-Typ dem PostScript-Typ zugeordnet.
Todespakete
Ich fing an, sie so zu nennen, weil sie genau Todespakete waren.
Star2Star hat eine Partnerschaft mit einem Hardwarehersteller geschlossen, der die letzten beiden Versionen unseres lokalen Client-Systems erstellt hat.
Vor ungefähr einem Jahr haben wir ein Update für diese Hardware veröffentlicht. Alles begann ziemlich einfach und folgte Moores üblichem Gesetz. Größer, besser, schneller, billiger. Die neue Hardware war 64-Bit, hatte 8-mal mehr Speicher, mehr Laufwerke und vier Intel Gigabit-Ethernet-Ports (mein Lieblingshersteller von Ethernet-Controllern). Wir hatten (und haben) viele Ideen zur Verwendung dieser Ports. Im Allgemeinen war das Stück Eisen erstaunlich.
Die Neuheit sauste durch Leistungs- und Funktionstests. Sowohl die Geschwindigkeit ist hoch als auch die Zuverlässigkeit. Im Idealfall. Dann haben wir die Geräte langsam an mehreren Teststandorten eingesetzt. Natürlich traten Probleme auf.
Eine schnelle Google-Suche legt nahe, dass der Intel 82574L Ethernet-Controller zumindest einige Probleme hatte. Insbesondere Probleme mit dem EEPROM, Fehler in ASPM, Tricks mit MSI-X usw. Wir haben jeden von ihnen seit mehreren Monaten gelöst. Und wir dachten, wir wären fertig.
Aber nein. Es wurde nur noch schlimmer.
Ich dachte, ich hätte das perfekte Software-Image (und BIOS) entworfen und bereitgestellt. Die Realität sah jedoch anders aus. Die Module fielen weiterhin aus. Manchmal erholten sie sich nach einem Neustart, manchmal nicht. Nach der Wiederherstellung des Moduls musste es jedoch getestet werden.
Nein, so was. Die Situation wurde merkwürdig.
Die Kuriositäten gingen weiter und schließlich beschloss ich, meine Ärmel hochzukrempeln. Ich hatte das Glück, einen sehr geduldigen und hilfsbereiten Händler zu finden, der drei Stunden lang auf meinem Handy blieb, während ich Daten sammelte. An diesem Client-Punkt kann aus irgendeinem Grund der Ethernet-Controller herunterfallen, während der Sprachverkehr über das Netzwerk übertragen wird.
Ich werde näher darauf eingehen. Wenn ich sage, dass der Ethernet-Controller „ausgefallen sein könnte“, bedeutet dies, dass er möglicherweise ausgefallen ist. Das System und die Ethernet-Schnittstelle sahen gut aus, und nach dem Senden einer zufälligen Menge an Datenverkehr konnte die Schnittstelle einen Hardwarefehler (Kommunikationsverlust mit dem PHY) melden und die Verbindung verlieren. Die LEDs am Schalter und an der Schnittstelle gingen buchstäblich aus. Der Controller war tot.
Es war nur durch Aus- und Einschalten möglich, es wieder zum Leben zu erwecken. Der Versuch, ein Kernelmodul oder einen Computer neu zu starten, führte zu einem PCI-Scanfehler. Die Schnittstelle blieb tot, bis die Maschine physisch ausgesteckt und wieder eingesteckt wurde. In den meisten Fällen bedeutete dies für unsere Kunden das Entfernen von Geräten.
Während des Debuggens mit diesem sehr geduldigen Reseller hörte ich auf, Pakete zu empfangen, als die Schnittstelle abstürzte. Am Ende identifizierte ich ein Muster: das letzte Paket von der Schnittstelle ist immer
100 Trying provisional response, und es hatte immer eine gewisse Länge. Das ist noch nicht alles. Schließlich habe ich diese Antwort (von Asterisk) auf die ursprüngliche INVITE-Anfrage zurückgeführt, die für eines der Telefone des Herstellers spezifisch ist.
Ich rief den Wiederverkäufer an, brachte Leute zusammen und zeigte die Beweise. Obwohl es Freitagabend war, nahmen alle an der Arbeit teil und montierten einen Prüfstand aus unseren neuen Geräten und Telefonen dieses Herstellers.
Wir setzten uns in einen Konferenzraum und wählten Nummern so schnell wir konnten. Es stellte sich heraus, dass wir das Problem reproduzieren können! Nicht bei jedem Anruf und nicht bei jedem Gerät, aber von Zeit zu Zeit haben wir es geschafft, den Ethernet-Controller einzuschalten, und von Zeit zu Zeit haben wir es nicht getan. Nachdem wir die Stromversorgung unterbrochen hatten, versuchten wir es erneut und es gelang uns. Wie jeder weiß, der versucht hat, technische Probleme zu diagnostizieren, besteht der erste Schritt in jedem Fall darin, das Problem zu reproduzieren. Wir haben es endlich geschafft.
Glauben Sie mir, es hat lange gedauert. Ich weiß, wie der OSI-Stack funktioniert. Ich weiß, wie Software segmentiert ist. Ich weiß, dass der Inhalt der SIP-Pakete den Ethernet-Adapter nicht beeinflussen sollte. Es ist alles Unsinn.
Schließlich ist es uns gelungen, das Problem der Pakete in der Zeit zwischen ihrem Eintreffen auf unserem Gerät und dem Spiegelungsport im Switch zu isolieren. Es stellte sich heraus, dass das Problem bei der Anfrage lag
INVITE, nicht bei der Antwort 100 Trying. Die auf dem gespiegelten Port erfassten Daten enthielten 100 Tryingkeine Antwort .
Es war notwendig, sich damit zu befassen
INVITE. War das Problem mit der Behandlung dieses Pakets durch den Userspace-Daemon verbunden? Vielleicht war die Übertragung das Problem 100 Trying? Einer meiner Kollegen schlug vor, die SIP-Anwendung zu schließen und zu prüfen, ob das Problem weiterhin besteht. Ohne diese App Pakete100 Tryingwurden nicht übertragen.
Es war notwendig, die Übertragung von Problempaketen irgendwie zu verbessern. Wir haben das vom Telefon übertragene Paket isoliert
INVITEund mit abgespielt tcpreplay. Es funktionierte. Zum ersten Mal seit Monaten konnten wir Ports auf Befehl mit einem einzigen Paket löschen. Dies war ein bedeutender Fortschritt, und es war Zeit, nach Hause zu gehen, dh den Prüfstand im Heimlabor zu wiederholen!
Bevor ich meine Geschichte fortsetze, möchte ich Ihnen von einer großartigen Open Source-Anwendung erzählen, die ich gefunden habe. Ostinato verwandelt Sie in einen Paketmaster. Seine Möglichkeiten sind buchstäblich endlos. Ohne diesen Antrag wäre ich nicht weiter vorangekommen.
Mit diesem vielseitigen Paket-Tool habe ich angefangen zu experimentieren. Ich war erstaunt über das, was ich gefunden habe.
Alles begann mit einer seltsamen SIP / SDP-Eigenart. Schauen Sie sich dieses SDP an:
v=0
o=- 20047 20047 IN IP4 10.41.22.248
s=SDP data
c=IN IP4 10.41.22.248
t=0 0
m=audio 11786 RTP/AVP 18 0 18 9 9 101
a=rtpmap:18 G729/8000
a=fmtp:18 annexb=no
a=rtpmap:0 PCMU/8000
a=rtpmap:18 G729/8000
a=fmtp:18 annexb=no
a=rtpmap:9 G722/8000
a=rtpmap:9 G722/8000
a=fmtp:101 0-15
a=rtpmap:101 telephone-event/8000
a=ptime:20
a=sendrecv
Ja, das ist richtig. Der Tonübertragungsvorschlag wird dupliziert. Dies ist ein Problem, aber was hat der Ethernet-Controller damit zu tun ?! Abgesehen von der Tatsache, dass nichts anderes die Größe des Ethernet-Frames erhöht ... Aber warten Sie, es gab viele erfolgreiche Ethernet-Frames in den übertragenen Paketen. Einige von ihnen waren kleiner, andere mehr. Es gab keine Probleme mit ihnen. Ich musste weiter graben. Nach ein paar Kung-Fu-Tricks mit Ostinato und einigen elektrischen Wiederverbindungen konnte ich die problematische Beziehung (mit dem Problemrahmen) identifizieren. Hinweis: Wir werden uns mit hexadezimalen Werten befassen.
Ein Schnittstellenabsturz wurde durch einen bestimmten Bytewert bei einem bestimmten Offset ausgelöst. In unserem Fall war es der Hexadezimalwert
32c 0x47f. In ASCII, hexadezimal 32ist2... Ratet mal, woher es kam 2.
a=ptime:20
Alle unsere SDPs waren identisch (einschließlich
ptime). Alle Quell- und Ziel-URIs waren identisch. Die einzigen Unterschiede waren die Nummer des Anrufers, Tags und eindeutige Sitzungs-IDs. Problempakete hatten eine solche Kombination von Anruf-IDs, Tags und Zweigen, was ptimezu einem Wert 2mit einem Versatz führte 0x47f.
Boom! Mit den richtigen IDs, Tags und Zweigen (oder zufälligem Müll) könnte aus einem "guten Paket" ein "Killer" -Paket werden, sobald die Zeile
ptimean einer bestimmten Adresse endet. Es war sehr seltsam.
Beim Generieren von Paketen habe ich mit verschiedenen Hexadezimalwerten experimentiert. Die Situation erwies sich als noch komplizierter. Es stellte sich heraus, dass das Verhalten des Controllers vollständig von diesem bestimmten Wert abhing, der sich an der angegebenen Adresse im ersten empfangenen Paket befand. Das Bild war wie folgt:
0x47f = 31 HEX (1 ASCII) -
0x47f = 32 HEX (2 ASCII) -
0x47f = 33 HEX (3 ASCII) -
0x47f = 34 HEX (4 ASCII) - (inoculation)
Als ich sagte "wirkt sich nicht aus", meinte ich nicht nur, dass die Schnittstelle nicht getötet wird, sondern auch nicht geimpft wird (mehr oder weniger). Und wenn ich sage, dass "die Schnittstelle abstürzt", erinnern Sie sich an meine Beschreibung? Die Schnittstelle stirbt. Vollständig.
Nach neuen Tests stellte ich fest, dass das Problem bei jeder Linux-Version, die ich finden konnte, mit FreeBSD und sogar beim Einschalten des Computers ohne bootfähige Medien weiterhin besteht! Es ging um die Hardware, nicht um das Betriebssystem. Beeindruckend.
Außerdem konnte ich mit Hilfe von Ostinato verschiedene Versionen des Killer-Pakets erstellen: HTTP POST, ICMP-Echoanforderung und andere. Fast alles was ich wollte. Mit einem modifizierten HTTP-Server, der Daten in Byte-Werten (basierend auf Headern, Host usw.) generierte, war es einfach, die 200. HTTP-Anforderung zu erstellen, die das Death Packet enthält und die Client-Computer hinter der Firewall beendet!
Ich habe bereits erklärt, wie seltsam die ganze Situation war. Aber das Seltsamste war mit dem Impfstoff. Es stellte sich heraus, dass, wenn das erste empfangene Paket einen Wert enthält (von mir getestet), mit Ausnahme
1, 2oder 3wenn die Schnittstelle für den Tod eines Pakets unverwundbar wird (mit dem Wert 2oder 3). Darüber hinaus sind die Codes und Attribute ptimehaben ein Vielfaches von 10 gewesen: 10, 20, 30, 40. Abhängig von der Kombination aus Anruf-ID, Tag, Zweig, IP, URI und mehr (mit diesem fehlerhaften SDP) wurden diese gültigen Attribute ptimein einer perfekten Reihenfolge angeordnet. Unglaublich!
Plötzlich wurde klar, warum das Problem sporadisch auftrat. Es ist erstaunlich, dass ich es herausfinden konnte. Ich arbeite seit 15 Jahren mit Netzwerken und habe so etwas noch nie gesehen. Und ich bezweifle, dass wir uns wiedersehen werden. Hoffentlich ...
Ich habe zwei Ingenieure bei Intel kontaktiert und ihnen eine Demo geschickt, damit sie das Problem reproduzieren können. Nachdem sie einige Wochen lang experimentiert hatten, stellten sie fest, dass das Problem beim EEPROM in den 82574L-Controllern lag. Sie haben mir ein neues EEPROM und ein Schreibwerkzeug geschickt. Leider konnten wir es nicht verteilen, und außerdem musste das e1000e-Kernelmodul entladen und neu geladen werden, sodass das Tool nicht für unsere Umgebung geeignet war. Zum Glück (mit ein wenig Wissen über die EEPROM-Schaltung) konnte ich ein Bash-Skript schreiben und dann auf magische Weise
ethtoolspeicherte die "korrigierten" Werte und registrierte sie in Systemen, in denen sich der Fehler manifestierte. Jetzt konnten wir problematische Geräte identifizieren. Wir haben unseren Anbieter kontaktiert, um den Patch auf alle Geräte anzuwenden, bevor er an uns gesendet wird. Es ist nicht bekannt, wie viele dieser Intel Ethernet-Controller bereits verkauft wurden.
Noch eine Palette
2005 hatte ich ein ungeklärtes Problem bei der Arbeit. Einen Tag nach dem ungeplanten Herunterfahren (aufgrund des Hurrikans) erhielt ich Anrufe von Benutzern, die sich über Zeitüberschreitungen beim Herstellen einer Verbindung zur Datenbank beschwerten. Da wir ein sehr einfaches Netzwerk mit 32 Knoten und praktisch ungenutzter Bandbreite hatten, war ich alarmiert, dass der Server mit der Datenbank 15 bis 20 Minuten lang normal pingte und die Antworten auf Zeitüberschreitung innerhalb von etwa zwei Minuten eingingen. Auf diesem Server wurden Leistungsüberwachung und andere Tools ausgeführt und von verschiedenen Standorten aus ein Ping-Befehl gesendet. Mit Ausnahme des Servers können die übrigen Computer jederzeit mit anderen Netzwerkmitgliedern kommunizieren. Ich suchte nach einem fehlerhaften Switch oder einer fehlerhaften Verbindung, konnte jedoch keine Erklärung für die zufälligen und zeitweiligen Fehler finden.
Ich bat einen Kollegen, die LEDs am Switch im Lager zu beobachten, während ich das Routing durchführte und verschiedene Geräte wieder anschloss. Es dauerte 45-50 Minuten, sagte mir ein Kollege im Radio: "Dieser ist aus, dieser ist aufgestanden." Ich fragte, ob er ein Muster bemerkt habe.
- Ja ... ich habe es bemerkt. Aber du wirst denken, ich bin verrückt. Jedes Mal, wenn ein Gabelstapler eine Palette aus der Versandhalle nimmt, tritt nach zwei Sekunden auf dem Server eine Zeitüberschreitung auf.
- WAS ???
- Ja. Der Server wird wiederhergestellt, wenn der Lader mit dem Versand einer neuen Bestellung beginnt.
Ich rannte zum Gabelstapler und war mir sicher, dass er den erfolgreichen Abschluss des Auftrags durch Einschalten eines riesigen Magnetrons markierte. Zweifellos führen die elektromagnetischen Wellen des Kondensators zu einer Unterbrechung des Raum-Zeit-Kontinuums und unterbrechen vorübergehend den Betrieb der Servernetzwerkkarte in einem anderen 50 Meter entfernten Raum. Nein. Der Gabelstapler stapelte einfach größere Kisten auf der Palette mit kleineren Kisten oben, während er jede Kiste mit einem drahtlosen Barcode-Scanner scannte. Aha! Es ist wahrscheinlich der Scanner, der auf den Datenbankserver zugreift, wodurch andere Abfragen fehlschlagen. Nee. Ich überprüfte und fand heraus, dass der Scanner nichts damit zu tun hatte. Der WLAN-Router und seine USV in der Versandhalle wurden korrekt konfiguriert und funktionieren normal. Der Grund war etwas anderes, denn vor der Schließung aufgrund des Hurrikans funktionierte alles einwandfrei.
Sobald die nächste Auszeit begann, rannte ich zur Versandhalle und sah zu, wie der Lader die nächste Palette füllte. Sobald er vier große Kisten Shampoo auf ein leeres Tablett gestellt hatte, war der Server wieder ausgefallen! Ich glaubte nicht an die Absurdität dessen, was geschah, und für weitere fünf Minuten entfernte ich Shampoo-Schachteln und stellte sie ab, mit dem gleichen Ergebnis. Ich wollte gerade auf die Knie fallen und um die Gnade des Intranetgottes beten, als ich bemerkte, dass der Router in der Versandhalle etwa 30 cm unter dem Niveau der Kisten auf der Palette hing. Es gibt einen Hinweis!
Wenn große Kisten auf eine Palette gestellt wurden, verlor der WLAN-Router die Sichtverbindung zum Außenlager. Nach zehn Minuten löste ich das Problem. Folgendes ist passiert. Während des Hurrikans gab es einen Stromausfall, bei dem das einzige Gerät, das nicht an die USV angeschlossen war, ausfiel - ein Test-WLAN-Router in meinem Büro. Die Standardeinstellungen machten es irgendwie zu einem Repeater für den einzigen anderen WLAN-Router, der in der Versandhalle hängt. Beide Geräte konnten nur miteinander kommunizieren, wenn sich keine Palette zwischen ihnen befand, aber selbst dann war das Signal nicht zu stark. Wenn die Router sprachen, erstellten sie eine Schleife in meinem kleinen Netzwerk, und dann gingen alle anderen Pakete zum Datenbankserver verloren. Der Server hatte einen eigenen Switch vom Hauptrouter, daher war er als Netzwerkknoten viel weiter entfernt.Die meisten anderen Computer befanden sich auf demselben 16-Port-Switch, sodass ich problemlos zwischen ihnen pingen konnte.
In einer Sekunde löste ich ein Problem, das ich seit vier Stunden quälte: Ich schaltete den Testrouter aus. Es gab keine Zeitüberschreitungen mehr auf dem Server.
Wie der Tron-Film nur auf einem Apple IIgs-Computer
Einer meiner Lieblingsfilme als Kind war Tron, der in den frühen 1980er Jahren gedreht wurde. Es handelte sich um einen Programmierer, der „digitalisiert“ und in die Computerwelt vertieft war, in der personalisierte Programme lebten. Der Protagonist schloss sich einer Widerstandsgruppe an, um das Unterdrücker-Master-Kontrollprogramm (MCP) zu stürzen, ein rebellisches Programm, das sich entwickelte, Machtgier erlangte und versuchte, das Computersystem des Pentagons zu übernehmen.
In einer der beeindruckendsten Szenen des Programms rasen die Charaktere auf leichten Zyklen - zweirädrigen Autos, die aussehen wie Motorräder, die Wände hinter sich lassen. Einer der Protagonisten zwang die feindlichen Pepelats, gegen die Wand in der Arena zu krachen und ein Durchgangsloch zu machen. Die Helden haben sich mit ihren Gegnern befasst und sind durch das Loch in die Freiheit geflohen - der erste Schritt zum Sturz der MCP.
Als ich den Film sah, hatte ich keine Ahnung, dass ich Jahre später versehentlich die Welt von Tron, rebellischen Programmen und allem anderen auf einem Apple IIgs-Computer neu erschaffen würde.
So ist es passiert. Als ich anfing zu programmieren, beschloss ich, ein Lichtzyklus-Spiel von Tron zu erstellen. Zusammen mit meinem Freund Marco schrieb ich ein Programm über Apple IIgs in ORCA / Pascal und 65816 Assembler. Während des Spiels wurde der Bildschirm schwarz mit einem weißen Rand gestrichen. Jede Linie repräsentiert einen der Spieler. Wir haben die Spielergebnisse in einer Reihe am unteren Bildschirmrand angezeigt. Grafisch war es nicht das fortschrittlichste Programm, aber es war einfach und machte Spaß. Sie sah so aus:

Das Spiel unterstützte bis zu vier Spieler, wenn sie vor einer Tastatur saßen. Es war unpraktisch, aber es hat funktioniert. Wir konnten selten genug Leute dazu bringen, alle vier Lichtzyklen zu nutzen, also fügte Marco computergesteuerte Spieler hinzu, die vernünftigerweise mithalten konnten.
Wettrüsten
Das Spiel war schon sehr lustig, aber wir wollten experimentieren. Wir haben Raketen hinzugefügt, um den Spielern die Möglichkeit zu geben, einem bevorstehenden Unfall zu entkommen. Wie Marco später beschrieb:
Menschen und KI hatten jeweils drei Raketen, die während des Spiels eingesetzt werden konnten. Als die Rakete die Wand traf, gab es eine "Explosion", deren Hintergrund schwarz übermalt war, wodurch Abschnitte der Spur entfernt wurden, die durch die vorherigen Lichtzyklen hinterlassen wurden.
Bald könnten Spieler und Computer mit Raketen aus schwierigen Situationen herausspringen. Obwohl die Tron-Puristen darüber lachen werden, hatten die Programme im Film nicht den Luxus von Raketen.
Die Flucht
Wie bei allen ungewöhnlichen und bizarren Ereignissen war es auch unerwartet.
Einmal, als Marco und ich gegen zwei Computerspieler spielten, haben wir eine der KI-Schleifen zwischen ihrer eigenen Wand und dem unteren Rand des Bildschirms eingeschlossen. Er erwartete einen bevorstehenden Unfall und feuerte wie immer eine Rakete ab. Aber diesmal schoss er anstelle einer Wand auf den Rand des Bildschirms, der wie die Spur eines der Lichtzyklen aussah. Die Rakete traf die Grenze, hinterließ ein Loch von der Größe eines Lichtzyklus, und der Computer verließ sofort das Spielfeld. Wir starrten verwirrt auf den Lichtzyklus, als er die Score-Linie durchlief. Er vermied es leicht, mit den Symbolen zusammenzustoßen, und verließ dann den Bildschirm insgesamt.
Und unmittelbar danach stürzte das System ab.

Unsere Gedanken schwankten, als wir versuchten zu begreifen, was passiert war. Der Computer hat einen Weg gefunden, aus dem Spiel auszusteigen. Als der Lichtzyklus den Bildschirm verließ, gelangte er wie im Film in den Computerspeicher. Unsere Kiefer fielen herunter, als wir merkten, was passiert war.
Was haben wir getan, als wir einen Fehler in unserem Programm entdeckten, der regelmäßig das gesamte System zum Absturz bringen konnte? Wir haben alles noch einmal gemacht. Zuerst haben wir versucht, selbst aus den Grenzen herauszukommen. Dann zwangen sie den Computer, wieder wegzulaufen. Jedes Mal wurden wir mit bezaubernden Systemabstürzen belohnt. Manchmal blinkte das Laufwerkslicht, als das Laufwerk endlos murrte. In anderen Fällen war der Bildschirm mit bedeutungslosen Zeichen gefüllt, oder der Lautsprecher gab ein Quietschen oder ein leises Summen von sich. Und manchmal passierte alles auf einmal, und der Computer befand sich in einem Zustand völliger Unordnung.
Warum ist das passiert? Um dies zu verstehen, schauen wir uns die Architektur des Apple IIgs-Computers an.
(Un) geschützter Speicher
Das Apple IIgs-Betriebssystem hatte keinen geschützten Speicher, was in späteren Betriebssystemen auftrat, als Speicherbereiche einem Programm zugewiesen und vor externem Zugriff geschützt wurden. Daher kann ein Programm unter Apple IIgs alles lesen und schreiben (außer ROM). IIgs verwendete speichergebundene E / A, um auf Geräte wie das Diskettenlaufwerk zuzugreifen, sodass das Diskettenlaufwerk durch Lesen aus einem bestimmten Speicherbereich aktiviert werden konnte. Diese Architektur ermöglichte es Grafikprogrammen, direkt in den Bildschirmspeicher zu lesen und zu schreiben.
Das Spiel verwendete einen der Apple IIgs-Grafikmodi - Super Hi-Res: eine erstaunliche Auflösung von 320 x 200 Pixel mit einer Palette von 16 Farben. Um eine Palette auszuwählen, gab der Programmierer 16 Einträge (nummeriert von 0 bis 15 oder von $ 0 bis F im Hexadezimalformat) für 12-Bit-Farbwerte an. Zum Zeichnen auf dem Bildschirm können Sie Farben direkt in den Videospeicher lesen und schreiben.
Kollisionserkennungsalgorithmus
Wir haben diese Funktion genutzt und einen Crash-Detektor implementiert, indem wir direkt aus dem Videospeicher gelesen haben. Das Spiel berechnete für jeden Lichtzyklus seine nächste Position basierend auf der aktuellen Richtung und las dieses Pixel aus dem Videospeicher. Wenn die Position leer war, dh durch ein schwarzes Pixel dargestellt wurde (Eintrag in der $ 0-Palette), wurde das Spiel fortgesetzt. Aber wenn die Position eingenommen wurde, stürzte der Spieler in den Lichtzyklus oder den weißen Rahmen des Bildschirms (Eintrag in der Palette 15 oder $ F). Beispiel:
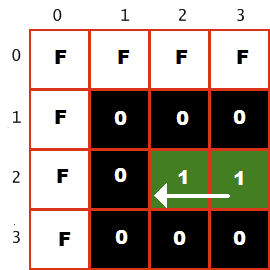
Die obere linke Ecke des Bildschirms wird hier angezeigt. Die Farbe $ F kennzeichnet einen weißen Rand und die Farbe $ 1 kennzeichnet den Grünlichtzyklus des Spielers. Es bewegt sich nach links, wie durch den Pfeil gezeigt, dh das nächste Pixel ist leer, seine Farbe ist $ 0. Wenn sich der Spieler länger als eine Runde in diese Richtung bewegt, trifft er eine Wand (Farbe $ F) und bricht.
Überschreiten
Der Algorithmus zum Bestimmen des nächsten Pixels unter Verwendung von Assembler-Mathematik berechnete schnell die Speicheradresse eines Pixels über, unter, links oder rechts vom aktuellen Pixel. Da jedes Pixel auf dem Bildschirm eine Adresse im Speicher war, berechnete der Algorithmus einfach eine neue Adresse zum Lesen. Und als der Lichtzyklus den Bildschirm verließ, bestimmte der Algorithmus einen Platz im Systemspeicher, um nach einer Kollision mit einer Wand zu suchen. Dies bedeutete, dass der Lichtzyklus nun den Systemspeicher durchlief, sinnlos Bits einschaltete und in den Speicher "stürzte".
Das Schreiben an zufällige Stellen im Systemspeicher ist keine kluge architektonische Entscheidung. Es überrascht nicht, dass das Spiel aus diesem Grund abgestürzt ist. Ein menschlicher Spieler fährt nicht blind und stürzt normalerweise sofort ab, was den Umfang der Systemprobleme einschränkt. Und KI hat keine solche Schwäche. Der Computer scannt sofort die Positionen um ihn herum, um festzustellen, ob er gegen eine Wand stößt und die Richtung ändert. Das heißt, aus Sicht des Computers unterschied sich der Systemspeicher nicht vom Bildschirmspeicher. Wie Marco beschrieb:
, , . , , 0. «» , . «», - - , , — . , - , .
Infolgedessen haben wir nicht nur das Lichtzyklusrennen aus dem Film nachgebildet, sondern auch die Flucht selbst. Wie im Film hatte die Flucht große Konsequenzen.
Dies ist heute schwer zu wiederholen, da Betriebssysteme geschützten Speicher erworben haben. Aber ich frage mich immer noch, ob es Programme wie Tron gibt, die versuchen, ihren "geschützten Räumen" zu entkommen, um zu verhindern, dass der KI-Code der Rebellen das Pentagon übernimmt.
Ich denke, um das herauszufinden, müssen wir auf die Erfindung der Digitalisierung des Bewusstseins warten.
Setzen Sie sich, um sich anzumelden
Jeder Programmierer weiß, dass das Debuggen schwierig ist. Obwohl für exzellente Debugger die Arbeit täuschend einfach aussieht. Bestürzte Programmierer beschreiben einen Fehler, den sie stundenlang abfangen, der Master stellt einige Fragen, und nach einigen Minuten sehen die Programmierer fehlerhaften Code vor sich. Ein Debugging-Experte vergisst nicht, dass es immer eine logische Erklärung gibt, egal wie mysteriös sich das System auf den ersten Blick verhält.
Diese Haltung wird durch eine Geschichte veranschaulicht, die im IBM Yorktown Heights Research Center stattfand. Der Programmierer hat kürzlich eine neue Workstation installiert. Alles war in Ordnung, als er vor dem Computer saß, aber er konnte sich nicht anmelden, während er stand. Dieses Verhalten wurde immer reproduziert: Der Programmierer loggte sich immer im Sitzen ein, konnte aber im Stehen nicht einmal.
Viele von uns saßen einfach da und wunderten sich. Wie konnte der Computer wissen, ob sie davor standen oder saßen? Gute Debugger wissen jedoch, dass es einen Grund geben muss. Das erste, was mir in den Sinn kommt, ist Elektrizität. Drahtbruch unter Teppich oder statische Elektrizität? Elektrische Probleme werden jedoch selten zu 100% reproduziert. Einer der Kollegen stellte schließlich die richtige Frage: Wie hat sich der Programmierer im Sitzen und Stehen angemeldet? Versuch es selber.
Der Grund war die Tastatur: Die beiden Tasten waren vertauscht. Wenn der Programmierer saß, tippte er blind und das Problem blieb unbemerkt. Und als er aufstand, verwirrte es ihn, er suchte nach Knöpfen und drückte sie. Mit diesem Hinweis und einem Schraubenzieher bewaffnet, tauschte der Debugging-Experte die Tasten und alles funktionierte.
Das in Chicago eingesetzte Bankensystem funktionierte viele Monate lang gut. Es wurde jedoch unerwartet beendet, als es zum ersten Mal zur Verarbeitung internationaler Daten verwendet wurde. Programmierer stöberten tagelang im Code herum, konnten jedoch keinen einzigen Befehl finden, der zur Beendigung des Programms führte. Bei näherer Betrachtung ihres Verhaltens stellten sie fest, dass das Programm mit der Eingabe von Ecuador-Daten beendet werden würde. Die Analyse ergab, dass das Programm den Namen der Hauptstadt (Quito) als Exit-Befehl interpretierte, wenn der Benutzer ihn eingab!
Eines Tages stieß Bob Martin auf ein System, das "einmal zweimal funktionierte". Sie hat die erste Transaktion korrekt verarbeitet, und bei allen nachfolgenden Transaktionen gab es kleine Probleme. Beim Neustart des Systems wurde die erste Transaktion erneut korrekt verarbeitet und schlug bei allen nachfolgenden Transaktionen fehl. Als Bob dieses Verhalten als "zweimal ausführen" beschrieb, wurde den Entwicklern sofort klar, dass sie nach einer Variablen suchen mussten, die beim Laden des Programms korrekt initialisiert, aber nach der ersten Transaktion nicht zurückgesetzt wurde. In allen Fällen konnten weise Programmierer mit den richtigen Fragen unangenehme Fehler schnell erkennen: „Was haben Sie im Stehen und Sitzen anders gemacht? Zeigen Sie mir, wie Sie sich in beiden Fällen anmelden "," Was genau haben Sie vor Programmende eingegeben? " „Hat das Programm vor Beginn der Abstürze richtig funktioniert? Wieviel mal?"
Rick Lemons sagte, dass die beste Lektion, die er über das Debuggen gelernt habe, darin bestand, dem Zauberer beim Auftritt zuzusehen. Er hatte ein Dutzend unmögliche Tricks gemacht, und Zitronen hatten das Gefühl, daran zu glauben. Dann erinnerte er sich daran, dass das Unmögliche nicht möglich ist, und er testete jeden Trick, um diese offensichtliche Inkonsistenz zu beweisen. Zitronen begannen mit einer unerschütterlichen Wahrheit - den Gesetzen der Physik, und von ihnen aus suchte er nach einfachen Erklärungen für jeden Trick. Diese Einstellung macht Zitronen zu einem der besten Debugger, die ich getroffen habe.
Das meiner Meinung nach beste Debugging-Buch ist The Medical Detectives, geschrieben von Berton Roueche und 1991 von Penguin veröffentlicht. Die Helden des Buches debuggen komplexe Systeme, von einer mäßig kranken Person bis zu sehr kranken Städten. Die dort verwendeten Problemlösungsmethoden können direkt beim Debuggen von Computersystemen verwendet werden. Diese wirklichen Geschichten sind so faszinierend wie jede Fiktion.
Der 500-Meilen-E-Mail-Fall
Hier ist eine Situation, die unvorstellbar klang ... Ich habe mich fast geweigert, darüber zu sprechen, weil es ein großartiges Fahrrad für Konferenzen ist. Ich habe die Geschichte leicht optimiert, um den Täter zu schützen, irrelevante und langweilige Details zu verwerfen und die Geschichte insgesamt ansprechender zu gestalten.
Vor einigen Jahren habe ich auf dem Campus ein E-Mail-System bedient. Der Leiter der Abteilung Statistik hat mich angerufen.
- Wir haben ein Problem beim Versenden von Briefen.
- Was für ein Problem?
„Wir können keine Briefe weiter als 500 Meilen senden.
Ich verschluckte mich an meinem Kaffee.
- Nicht verstanden.
„Wir können keine Briefe von der Abteilung weiter als 500 Meilen senden. In der Tat ein wenig weiter. Ungefähr 520 Meilen. Aber das ist die Grenze.
"Hmm ... Eigentlich funktioniert E-Mail nicht so", antwortete ich und versuchte, die Panik in meiner Stimme zu kontrollieren. In einem Gespräch mit dem Abteilungsleiter, auch nicht mit einem statistischen, kann keine Panik auftreten. - Warum haben Sie beschlossen, dass Sie keine Briefe weiter als 500 Meilen senden können?
"Ich habe mich nicht entschieden ", antwortete er schwerfällig. - Sie sehen, als wir bemerkten, was vor ein paar Tagen geschah ...
- Sie haben ein paar Tage gewartet? Ich unterbrach ihn mit zitternder Stimme. - Und du konntest die ganze Zeit keine Briefe schicken?
- Wir könnten senden. Nur nicht weiter ...
«» Fünfhundert Meilen, ja «, beendete ich für ihn. - Klar. Aber warum hast du nicht früher angerufen?
„Bis zu diesem Zeitpunkt hatten wir nicht genügend Daten, um sicher zu sein, was geschah.
Genau das ist der Leiter der Statistik .
- Wie auch immer, ich habe einen der Geostatistiker gebeten, damit zu arbeiten ...
- Geostatistiker ...
- Ja, und sie hat eine Karte erstellt, die den Radius zeigt, innerhalb dessen wir Briefe senden können, etwas mehr als 500 Meilen. Es gibt mehrere Orte in dieser Zone, an denen unsere Briefe nicht oder nur in regelmäßigen Abständen eintreffen, aber außerhalb des Radius können wir überhaupt nichts senden.
"Ich verstehe", sagte ich und ließ meinen Kopf in meine Hände fallen. - Als es angefangen hat? Sie haben das vor ein paar Tagen gesagt, aber wir haben nichts an Ihren Systemen geändert.
- Ein Berater ist gekommen, hat unseren Server gepatcht und neu gestartet. Aber ich rief ihn an und er sagte, dass er das Mailsystem nicht berührt habe.
„Okay, lass mich einen Blick darauf werfen und dich zurückrufen“, antwortete ich und glaubte kaum, dass ich an so etwas teilnahm. Heute war nicht der erste April. Ich versuchte mich zu erinnern, ob mir jemand einen Streich schuldete.
Ich habe mich beim Server ihrer Abteilung angemeldet und einige Bestätigungs-E-Mails gesendet. Dies fand im North Carolina Research Triangle statt, und der Brief kam ohne Probleme in meinem Briefkasten an. So auch die Briefe nach Richmond, Atlanta und Washington. Es gab auch einen Brief nach Princeton (400 Meilen).
Aber dann schickte ich einen Brief nach Memphis (600 Meilen). Es ist nicht gekommen. In Boston ist es nicht gekommen. In Detroit kam es nicht. Ich holte mein Adressbuch heraus und begann, Briefe darin zu verschicken. Es kam nach New York (420 Meilen), kam aber nicht nach Providence (580 Meilen).
Ich begann an meiner geistigen Gesundheit zu zweifeln. Schrieb an einen Freund in North Carolina, dessen Anbieter in Seattle war. Zum Glück kam der Brief nicht an. Wenn das Problem beim Standort der Empfänger und nicht bei ihren Mailservern lag, wäre ich wahrscheinlich in Tränen ausgebrochen.
Nachdem ich herausgefunden hatte, dass das Problem (unglaublich) vorhanden und reproduzierbar war, begann ich, die Datei sendmail.cf zu analysieren. Er sah gut aus. Wie gewöhnlich. Ich habe es mit sendmail.cf in meinem Home-Verzeichnis verglichen. Es gab keinen Unterschied - es war die Datei, die ich geschrieben habe. Und ich war mir ziemlich sicher, dass ich die Option nicht aufgenommen habe
FAIL_MAIL_OVER_500_MILES. In Verwirrung habe ich den SMTP-Port telnettiert. Der Server antwortete glücklich mit einem Sendmail-Banner von SunOS.
Warten Sie ... das Sendmail-Banner von SunOS? Zu diesem Zeitpunkt lieferte Sun Sendmail 5 noch mit seinem Betriebssystem aus, obwohl Sendmail 8 bereits vollständig implementiert war. Da ich ein guter Systemadministrator war, habe ich Sendmail 8 als Standard eingeführt. Da ich ein guter Systemadministrator war, schrieb ich außerdem sendmail.cf, in dem die coolen langen, selbstdokumentierenden Optionen und Variablennamen von Sendmail 8 anstelle der in Sendmail 5 verwendeten kryptischen Interpunktionscodes verwendet wurden.
Alles passte zusammen. und ich verschluckte mich wieder an meinem bereits abgekühlten Kaffee. Es sieht so aus, als hätte der Berater beim "Patchen des Servers" die SunOS-Version aktualisiert, von der aus er eine ältere Version von Sendmail herausgebracht hat. Glücklicherweise hat die Datei sendmail.cf überlebt, aber jetzt stimmte sie nicht mehr überein.
Es stellte sich heraus, dass Sendmail 5 - zumindest die von Sun gelieferte Version mit einer Reihe von Verbesserungen - mit sendmail.cf für Sendmail 8 funktionieren konnte, da die meisten Regeln gleich waren. Neue lange Konfigurationsoptionen wurden jedoch nicht mehr erkannt und verworfen. Und da die Sendmail-Binärdatei für die meisten von ihnen keine Standardeinstellungen enthielt, fand das Programm in sendmail.cf keine geeigneten Werte und setzte sie auf Null zurück.
Einer dieser Nullwerte war das Verbindungszeitlimit zu einem Remote-SMTP-Server. Nach einigen Experimenten stellte sich heraus, dass bei dieser bestimmten Maschine unter normaler Last eine Zeitüberschreitung von Null zu einer Unterbrechung in etwas mehr als drei Millisekunden führt.
Zu dieser Zeit war das Campus-Netzwerk komplett umgeschaltet. Das ausgehende Paket wurde nicht verzögert, bis es über POP den Router auf der anderen Seite erreichte. Das heißt, die Dauer einer Verbindung zu einem schwach belasteten Remote-Host in einem benachbarten Netzwerk hing hauptsächlich von der mit Lichtgeschwindigkeit zurückgelegten Entfernung ab und nicht von zufälligen Verzögerungen durch Router.
Ich fühlte mich ein wenig schwindelig und trat in die Kommandozeile ein:
$ units
1311 units, 63 prefixes
You have: 3 millilightseconds
You want: miles
* 558.84719
/ 0.0017893979
"500 Meilen oder mehr."
Fortsetzung folgt.