Für Unternehmen, die Daten und Anwendungen auf mehr als einem Server verwalten müssen, ist die Infrastruktur von größter Bedeutung.
Für jedes Unternehmen besteht ein wesentlicher Teil des Workflows in der Überwachung von Infrastrukturknoten, insbesondere wenn kein direkter Zugriff zur Lösung neu auftretender Probleme besteht. Darüber hinaus kann der starke Einsatz einiger Ressourcen ein Indikator für Infrastrukturausfälle und Überlastungen sein. Die Überwachung kann jedoch nicht nur zur Vorbeugung, sondern auch zur Bewertung der möglichen Folgen des Einsatzes neuer Software in der Produktion eingesetzt werden. Derzeit gibt es mehrere gebrauchsfertige Lösungen zur Verfolgung des Ressourcenverbrauchs auf dem Markt, die jedoch zwei Hauptprobleme aufwerfen: die hohen Kosten für Installation und Konfiguration sowie die mit Software von Drittanbietern verbundenen Sicherheitsprobleme.
Das erste Problem ist das Preisproblem: Die Kosten können je nach Anzahl der zu überwachenden Hosts zwischen zehn Euro (Verbrauchertarife) und mehreren Tausend Euro (Unternehmenstarife) pro Monat liegen. Angenommen, ich möchte drei Knoten für ein Jahr überwachen. Bei einem Preis von 10 Euro pro Monat werde ich 120 Euro ausgeben, während ein kleines Unternehmen zehn bis zwanzigtausend Euro ausgeben muss, was sich als finanziell unhaltbare Entscheidung herausstellen und einfach das gesamte Budget untergraben wird.
Das zweite Problem ist Software von Drittanbietern. Angesichts der Tatsache, dass zur Analyse Benutzerdaten - ob eine Einzelperson oder ein Unternehmen - von einem Dritten verarbeitet werden müssen, stellt sich die Frage: Wie sammelt der Dritte die Daten und präsentiert sie dem Benutzer? Normalerweise wird hierfür eine spezielle Anwendung auf dem Knoten installiert, über die die Überwachung durchgeführt wird. Oft haben solche Anwendungen jedoch Zeit, veraltet zu werden oder sich als nicht kompatibel mit dem Betriebssystem des Clients herauszustellen. Die Erfahrungen der Forscher auf dem Gebiet der Informationssicherheit werfen ein Licht auf die Probleme bei der Arbeit mit " proprietärer Software ". Würden Sie einer solchen Software vertrauen? Ich nicht.
Ich habe meine Knoten sowohl für Tor als auch für einige KryptowährungenDaher bevorzuge ich die kostenlosen, Open Source, leicht anpassbaren Alternativen für die Überwachung. In diesem Beitrag werden drei solcher Tools vorgestellt: Grafana, InfluxBD und CollectD.

Überwachung
Um jede Metrik unserer Infrastruktur effektiv analysieren zu können, benötigen wir eine Anwendung, die Statistiken von den für uns interessanten Geräten abrufen kann. In dieser Hinsicht kommt CollectD zur Rettung : Dieser Dämon gruppiert und sammelt ("sammelt", daher ein solcher Name) alle Parameter, die auf der Festplatte gespeichert oder über das Netzwerk übertragen werden können.
Die Daten werden dann an die InfluxDB- Instanz übertragen : Dies ist eine Zeitreihendatenbank (TSBD), die die Daten mit der Zeit (UNIX-codierter Zeitstempel) verknüpft, zu der der Server sie empfangen hat. Somit kommen die von CollectD gesendeten Daten als eine Folge von Ereignissen an.
Schließlich werden wir Grafana verwenden: Dieses Programm stellt eine Verbindung zu InfluxDB her und zeigt die Daten auf benutzerfreundlichen, farbenfrohen Dashboards an. Dank aller Arten von Grafiken und Histogrammen können wir die Daten der CPU, des RAM usw. in Echtzeit verfolgen.

InfluxDB

Beginnen wir mit InfluxDB, einer kostenlosen TSBD zum Speichern von Daten als Folge von Ereignissen. Diese von Go entwickelte Datenbank wird das Herzstück unseres "Überwachungssystems" sein.
Immer wenn Daten eintreffen, ist standardmäßig ein UNIX-Label daran gebunden . Die Flexibilität dieses Ansatzes befreit den Benutzer von der Notwendigkeit, die Variable "Zeit" zu speichern, was ansonsten ziemlich kompliziert ist. Stellen wir uns vor, wir haben mehrere Geräte auf verschiedenen Kontinenten. Wie werden wir mit der Variablen "Zeit" umgehen? Werden wir alle Daten an die Greenwich Mean Time binden?, oder geben wir jedem Knoten eine eigene Zeitzone? Wenn die Daten in verschiedenen Zeitzonen gespeichert sind, wie können wir sie korrekt in den Diagrammen anzeigen? Wie Sie sehen, treten nacheinander Probleme auf.
Da InfluxDB die Zeit verfolgt und jede Datenankunft automatisch markiert, kann es synchron Daten in eine bestimmte Datenbank schreiben. Aus diesem Grund wird InfluxDB häufig als Zeitleiste dargestellt: Das Schreiben von Daten wirkt sich nicht auf die Leistung der Datenbank aus (was manchmal bei MySQL der Fall ist), da beim Schreiben lediglich ein bestimmtes Ereignis zur Zeitleiste hinzugefügt wird. Daher kommt der Name des Programms aus der Wahrnehmung der Zeit als endloser und unbegrenzter "Strom".
Installation und Konfiguration
Ein weiterer Vorteil von InfluxDB ist die einfache Installation und die umfangreiche Dokumentation der Projektgemeinschaft, die es weitgehend unterstützt . InfluxDB verfügt über zwei Arten von Schnittstellen: die Befehlszeile (ein praktisches Tool für Entwickler, das jedoch für die Arbeit mit großen Datenmengen schlecht vorbereitet ist) und die HTTP-API für die direkte Interaktion mit der Datenbank.
Sie können InfluxDB nicht nur von der offiziellen Website herunterladen, sondern auch über das Paketverwaltungssystem (wir werden dies durch Debian demonstrieren). Darüber hinaus wird empfohlen, die Pakete vor der Installation über GPG zu überprüfen. Im Folgenden werden die Schlüssel des InfluxDB-Pakets importiert:
root@node#~: curl -sL https://repos.influxdata.com/influxdb.key | sudo apt-key add -
root@node#~: source /etc/os-release
root@node#~: echo "deb https://repos.influxdata.com/debian $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/influxdb.listSchließlich werden wir InfluxDB aktualisieren und installieren:
root@node#~: apt-get update
root@node#~: apt-get install influxdbZum Ausführen verwenden wir
systemctl:
root@node#~: service start influxdb Um zu verhindern, dass sich jemand mit schändlichen Absichten bei uns anmeldet, erstellen wir einen Benutzer namens "Administrator". Sie können mit der Datenbank über die InfluxDB SQL-ähnliche Abfragesprache " InfluxQL " interagieren . Um einen neuen Benutzer zu erstellen, führen wir eine Anfrage aus
create user.
root@node#~: influx
Connected to http://localhost:8086
InfluxDB shell version: x.y.z
>
> CREATE USER admin WITH PASSWORD 'MYPASSISCOOL' WITH ALL PRIVILEGESIn derselben CLI-Schnittstelle erstellen wir eine Datenbank "Metriken", in der wir unsere Metriken speichern.
> CREATE DATABASE metricsAls Nächstes konfigurieren wir InfluxBD (
/etc/influxdb/influxdb.conf) so, dass die Schnittstelle an Port 24589 (UDP) mit einer direkten Verbindung zur "Metrics" -Datenbank geöffnet wird, um CollectD zu unterstützen. Wir müssen die Datei auch herunterladen types.dbund an der Adresse /usr/share/collectd/(oder in einem anderen Ordner) ablegen , um die von CollectD übertragenen Daten in ihrem nativen Format korrekt zu bestimmen .
root@node#~: nano /etc/influxdb/influxdb.conf
[Collectd]
enabled = true
bind-address = ":24589"
database = "metrics"
typesdb = "/usr/share/collectd/types.db"Weitere Informationen zu CollectD in der Konfiguration finden Sie in der Dokumentation .
CollectD

CollectD in unserer Überwachungsinfrastruktur fungiert als Datenaggregator, der die Datenübertragung zu InfluxDB vereinfacht. Per Definition sammelt CollectD Metriken von CPU, RAM, Festplatten, Netzwerkschnittstellen, Prozessen ... Das Potenzial dieses Programms ist unbegrenzt, insbesondere wenn man die große Auswahl an bereits verfügbaren Plugins sowie eine Reihe geplanter Plugins berücksichtigt .
Wie Sie sehen können, ist die Installation von CollectD einfach:
root@node#~: apt-get install collectd collectd-utilsLassen Sie uns anhand eines vereinfachten Beispiels veranschaulichen, wie CollectD funktioniert. Angenommen, ich möchte die Anzahl der Prozesse auf meinem Knoten wissen. Um dies zu überprüfen, führt CollectD einen API-Aufruf durch, um die Anzahl der Prozesse pro Zeiteinheit (per Definition 5000 Millisekunden) und nichts weiter herauszufinden. Sobald der Aggregator die Daten empfängt, überträgt er sie zur Konfiguration über ein Modul ("Netzwerk") an InfluxDB, das wir konfigurieren müssen.
Öffnen Sie die Datei mit unserem Editor
/etc/collectd.conf, scrollen Sie zum Abschnitt Networkund bearbeiten Sie sie wie unten angegeben. Stellen Sie sicher, dass Sie die IP-Adresse angeben, unter der sich die InfluxDB ( INFLUXDB_IP) -Schnittstelle befindet .
root@node#~: nano /etc/collectd.conf
...
<Plugin network>
<Server "INFLUXDB_IP" "24589">
</Server>
ReportStats true
</Plugin>
...
Ich schlage vor, den Hostnamen in der Konfigurationsdatei zu ändern, die an InfluxDB weitergeleitet wird (in unserer Infrastruktur handelt es sich um eine „zentralisierte“ Datenbank, da sie sich auf demselben Knoten befindet). Somit erhalten wir keine unnötigen Daten und das Risiko, dass Daten von anderen Knoten überschrieben werden, verschwindet.

Grafana

Eine Grafik ist tausend Bilder wert
In Anbetracht des umschriebenen Zitats können wir durch die Beobachtung von Infrastrukturmetriken in Echtzeit anhand von Grafiken und Tabellen effizient und zeitnah handeln. Wir werden Grafana verwenden, um das Dashboard für unsere Grafiken und Tabellen zu erstellen und anzupassen.
Grafana ist ein grafisches Freeware-Metriktool, das mit einer Vielzahl von Datenbanken (einschließlich InfluxDB) kompatibel ist und in dem der Benutzer Warnungen erstellen kann, wenn ein Teil der Daten eine bestimmte Bedingung erfüllt. Wenn Ihr Prozessor beispielsweise einen Spitzenwert erreicht, erhalten Sie möglicherweise eine Warnung in Slack, Mattermost, E-Mail usw. Außerdem habe ich meine Warnungen so konfiguriert, dass sie jeden Fall aktiv überwachen, wenn jemand meine Infrastruktur „betritt“.
Grafana erfordert keine speziellen Einstellungen: Wie bereits erwähnt, "scannt" InfluxDB die Variable "time". Die Integration selbst ist sehr einfach: Wir importieren zunächst den öffentlichen Schlüssel, um das Paket von der offiziellen Grafana-Website hinzuzufügen (dies hängt von Ihrem Betriebssystem ab):
root@node#~: wget -q -O - https://packages.grafana.com/gpg.key | sudo apt-key add -
root@node#~: echo "deb https://packages.grafana.com/oss/deb stable main" | sudo tee -a /etc/apt/sources.list.d/grafana.list
root@node#~: apt-get update && apt-get install grafanaDann lassen Sie es uns durch systemctl laufen:
root@node#~: systemctl start grafana-webWenn wir nun im Browser zur Seite localhost: 3000 gehen, sollte die Grafana-Anmeldeschnittstelle angezeigt werden. Per Definition können Sie den Anmeldeadministrator und das Kennwortadministrator durchgehen (nach Änderung der ersten Anmeldeinformationen wird empfohlen, diese zu ändern).

Gehen wir zum Abschnitt Quellen und fügen dort unsere Influx-Datenbank hinzu:


Jetzt sehen wir ein kleines grünes Rechteck unter der Bezeichnung Neues Dashboard. Bewegen Sie den Mauszeiger darüber und wählen Sie Panel hinzufügen und dann Grafik:

Sie können jetzt eine Grafik mit Testdaten sehen. Klicken Sie auf den Titel dieses Diagramms und dann auf Bearbeiten. Mit Grafana können Sie intelligente Abfragen erstellen: Sie müssen nicht jedes Feld in der Datenbank kennen, Grafana bietet sie Ihnen aus einer Liste von Parametern an, die für die Analyse geeignet sind.
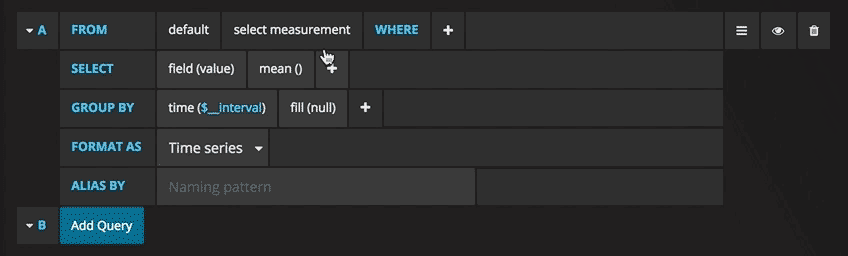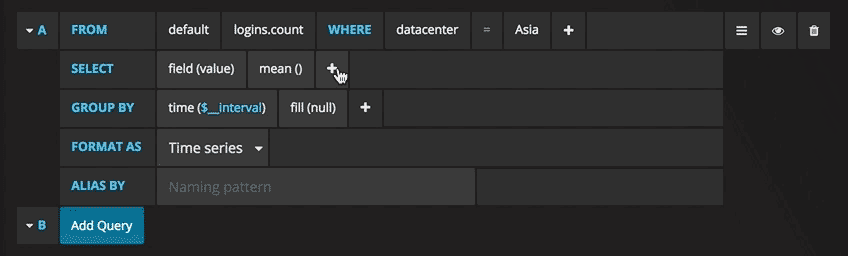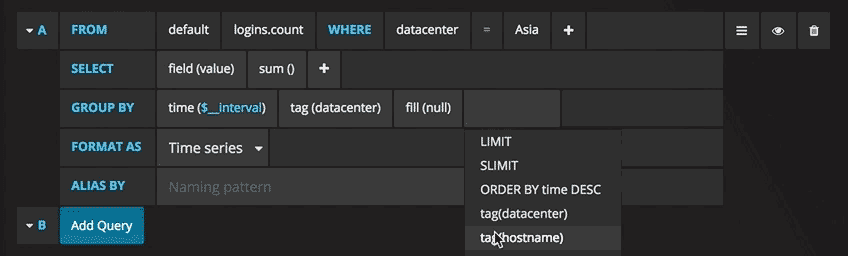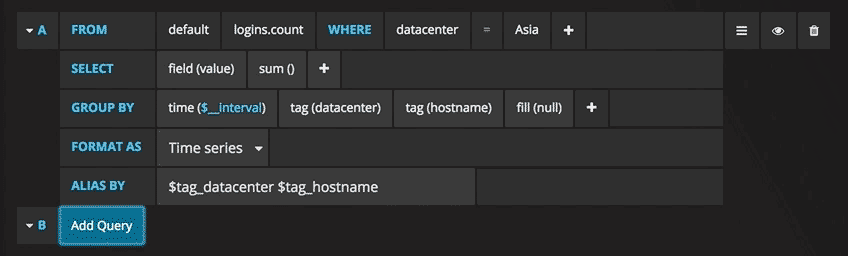
Das Schreiben von Abfragen war noch nie einfacher: Wählen Sie einfach die gewünschte Metrik aus und klicken Sie auf Aktualisieren. Ich empfehle außerdem, die Metriken nach Host zu trennen, um Probleme zu isolieren. Wenn Sie an anderen Ideen für das Control Panel interessiert sind, können Sie auf der Grafana-Website alle möglichen Beispiele zur Inspiration finden.
Wir haben festgestellt, dass Grafana ein sehr erweiterbares Tool ist und es uns ermöglicht, Daten zu vergleichen, die im Vergleich sehr unterschiedlich sind. Es gibt keine einzige Metrik, die nicht erhalten werden kann, daher schränkt Sie nur Ihr Einfallsreichtum ein. Verfolgen Sie Ihre Geräte und erhalten Sie in Echtzeit den umfassendsten Überblick über Ihre Infrastruktur!
