Dies ist keine systematische Analyse und keine Tabelle. Eine individuelle Sichtweise, auch aus Sicht eines Geophysikers. Aber ich bin immer neugierig, Gartner MQ zu lesen, sie formulieren einige Punkte perfekt. Hier sind die Dinge, auf die ich in technischer, marktbezogener und philosophischer Hinsicht geachtet habe.
Dies ist nicht für Leute, die tief in ML verliebt sind, sondern für Leute, die daran interessiert sind, was allgemein auf dem Markt passiert.
Der DSML-Markt selbst verschachtelt logisch zwischen BI- und Cloud AI-Entwicklerdiensten.
Gefiel erste Zitate und Begriffe:
- „Ein Marktführer ist möglicherweise nicht die beste Wahl“ - Der Marktführer ist nicht unbedingt das, was Sie brauchen. Sehr dringend! Infolge des Fehlens eines funktionierenden Kunden suchen sie immer nach der „besten“ Lösung, nicht nach der „geeigneten“.
- Die Modelloperationalisierung wird als MOPs abgekürzt. Und Möpse sind schwer für alle! - (cooles Mops-Thema lässt das Modell funktionieren).
- Die Notebook-Umgebung ist ein wichtiges Konzept, bei dem Code, Kommentare, Daten und Ergebnisse zusammengeführt werden. Dies ist sehr klar, vielversprechend und kann die Menge an UI-Code erheblich reduzieren.
- «Rooted in OpenSource» — – .
- «Citizen Data Scientists» — , , , . .
- «Democratise» — “ ”. «democratise the data» «free the data», . «Democratise» — long tail . — !
- «Exploratory Data Analysis – EDA» — . . . , . ,
- "Reproduzierbarkeit" - die maximale Erhaltung aller Parameter der Umgebung, der Ein- und Ausgänge, damit Sie das einmal durchgeführte Experiment wiederholen können. Der wichtigste Begriff für eine experimentelle Testumgebung!
Damit:
Alteryx
Die coole Oberfläche ist nur ein Spielzeug. Die Skalierbarkeit ist natürlich etwas eng. Dementsprechend ist die Citizen Community von Ingenieuren etwa gleich mit Tsatski zu spielen. Analytics hat alles in einer Flasche. Es erinnerte mich an die Coscad Spectral Correlation Data Analysis Suite , die in den 90er Jahren programmiert wurde.
Anakonda
Eine Community um Python- und R-Experten. Open Source ist jeweils groß. Es stellte sich heraus, dass meine Kollegen ständig verwenden. Ich wusste es nicht.
DataBricks
Besteht aus drei OpenSource-Projekten - Spark-Entwickler haben seit 2013 verdammt viel Geld gesammelt. Ich muss das Wiki direkt lesen:
„Im September 2013 gab Databricks bekannt, dass Andreessen Horowitz 13,9 Millionen US-Dollar gesammelt hat. Das Unternehmen sammelte 2014 weitere 33 Millionen US-Dollar, 2016 60 Millionen US-Dollar, 2017 140 Millionen US-Dollar, 2019 (Februar) 250 Millionen US-Dollar und 2019 (Oktober) 400 Millionen US-Dollar. “!!!Einige großartige Leute, die Spark gesägt hat. Nicht vertraut sorry!
Und die Projekte sind:
- Delta Lake - ACID on Spark wurde kürzlich veröffentlicht (wovon wir mit Elasticsearch geträumt haben) - es verwandelt es in eine Datenbank: ein starres Schema, ACID, Audit, Versionen ...
- ML Flow - Modellverfolgung, Verpackung, Verwaltung und Lagerung.
- Koalas - Pandas DataFrame API auf Spark - Pandas - Python API für die Arbeit mit Tabellen und Daten im Allgemeinen.
Sie können über Spark sehen, der plötzlich nicht weiß oder vergessen hat: Link . Vidosiki schaute mit Beispielen von ein wenig langweiligen, aber detaillierten beratenden Spechten: DataBricks für Data Science ( Link ) und für Data Engineering ( Link ).
Kurz gesagt, Databricks zieht Spark heraus. Wer Spark normalerweise in der Cloud verwenden möchte, nimmt DataBricks wie beabsichtigt ohne zu zögern :) Spark ist hier das Hauptunterscheidungsmerkmal.
Ich fand heraus, dass Spark Streaming keine echte gefälschte Echtzeit oder Mikrobatching ist. Und wenn Sie echte Echtzeit benötigen, ist es in Apache STORM. Trotzdem sagt und schreibt jeder, dass Spark cooler ist als MapReduce. Der Slogan lautet:
DATAIKU
Coole End-to-End-Sache. Es gibt viel Werbung. Sie verstehen nicht, wie es sich von Alteryx unterscheidet?
DataRobot
Paxata für die Aufbereitung von Daten ist cool ist ein separates Unternehmen, das im Dezember 2019 von Data Robots gekauft wurde. 20 MUSD erhöht und verkauft. Alles in 7 Jahren.
Daten in Paxata vorbereiten, nicht in Excel - siehe hier: Link .
Es gibt automatische Parodien und Verknüpfungsvorschläge zwischen zwei Datensätzen. Eine großartige Sache - um die Daten zu sortieren, noch mehr Wert auf Textinformationen ( Link ).
Der Datenkatalog ist ein großartiger Katalog von "Live" -Datensätzen, die niemand benötigt.
Interessant ist auch, wie Verzeichnisse in Paxata gebildet werden ( Link ).
«According to analyst firm Ovum, the software is made possible through advances in predictive analytics, machine learning and the NoSQL data caching methodology.[15] The software uses semantic algorithms to understand the meaning of a data table's columns and pattern recognition algorithms to find potential duplicates in a data-set.[15][7] It also uses indexing, text pattern recognition and other technologies traditionally found in social media and search software.»
Das Hauptprodukt von Data Robot ist hier . Ihr Slogan ist vom Modell zur Unternehmensanwendung! Entdeckte Beratung für die Ölindustrie im Zusammenhang mit der Krise, aber sehr banal und uninteressant: Link . Habe ihre Videos auf Mops oder MLops gesehen ( Link ). Dies ist ein Frankenstein, der aus 6-7 Akquisitionen verschiedener Produkte besteht.
Natürlich wird klar, dass ein großes Team von Data Scientists über eine solche Umgebung für die Arbeit mit Modellen verfügen sollte, da sie sonst viele davon produzieren und niemals etwas bereitstellen. Und in unserer vorgelagerten Realität für Öl und Gas konnte ein Modell erfolgreich erstellt werden, und dies ist bereits ein großer Fortschritt!
Der Prozess selbst erinnerte sehr an die Arbeit von Entwurfssystemen in der Geologie-Geophysik, zum Beispiel Petrel... Alle und verschiedene machen und modifizieren Modelle. Sammeln Sie Daten im Modell. Dann haben wir ein Referenzmodell gemacht und es in Produktion genommen! Es gibt viele Ähnlichkeiten zwischen beispielsweise einem geologischen Modell und einem ML-Modell.
Domino
Schwerpunkt auf offener Plattform und Zusammenarbeit. Geschäftsanwender haben freien Eintritt. Ihr Data Lab ähnelt stark einem Sharepoint. (Und aus dem Namen ergibt sich stark IBM). Alle Experimente sind mit dem Originaldatensatz verknüpft. Wie vertraut es ist :) Wie in unserer Praxis - einige Daten wurden in das Modell gezogen, dann wurden sie bereinigt und im Modell in Ordnung gebracht, und all dies befindet sich bereits im Modell, und Sie können die Enden in den Anfangsdaten nicht finden.
Domino verfügt über eine coole Infrastrukturvirtualisierung. Ich sammelte die Maschine wie viele Kerne pro Sekunde und ging zu zählen. Wie es gemacht wurde, ist nicht sofort ganz klar. Docker überall. Viel Freiheit! Alle Arbeitsbereiche der neuesten Versionen können verbunden werden. Führen Sie Experimente parallel durch. Verfolgung und Auswahl erfolgreicher.
Wie bei DataRobot werden die Ergebnisse für Geschäftsanwender in Form von Anwendungen veröffentlicht. Für besonders begabte „Stakeholder“. Auch die tatsächliche Nutzung der Modelle wird überwacht. Alles für die Möpse!
Ich habe nicht ganz verstanden, wie komplexe Modelle in Produktion gehen. Einige APIs werden bereitgestellt, um sie mit Daten zu versorgen und Ergebnisse zu erhalten.
H2O
Driveless AI ist ein sehr kompaktes und unkompliziertes System für Supervised ML. Alles in einer Box. Es ist nicht sofort klar über das Backend.
Das Modell wird automatisch in einen REST-Server oder eine Java-App gepackt. Das ist eine großartige Idee. Es wurde viel für Interpretierbarkeit und Erklärbarkeit getan. Interpretation und Erklärung der Ergebnisse der Modelloperation (Was sollte im Wesentlichen nicht erklärbar sein, sonst kann eine Person dasselbe berechnen?).
Zum ersten Mal wird eine Fallstudie zu unstrukturierten Daten und NLP im Detail betrachtet . Hochwertiges Architekturbild. Im Allgemeinen haben mir die Bilder gefallen.
Es gibt ein großes Open-Source-H2O-Framework, das nicht ganz klar ist (eine Reihe von Algorithmen / Bibliotheken?). Eigener visueller Laptop ohne Programmierung wie Jupiter ( Link). Ich habe auch über Pojo und Mojo gelesen - H2O-Modelle in der Realität. Der erste ist auf der Stirn, der zweite ist mit Optimierung. H20 sind die einzigen (!), Zu denen Gartner seine Stärken und Erklärungsbemühungen um Textanalyse und NLP erweitert hat. Es ist sehr wichtig!
Ebenda: Hohe Leistung, Optimierung und Industriestandard für die Integration von Eisen und Cloud.
Und es ist logisch in der Schwäche - Driverles AI ist schwach und eng im Vergleich zu ihrer eigenen Open Source. Die Datenaufbereitung ist im Vergleich zu denselben Paxata lahm! Und ignorieren Sie industrielle Daten - Stream, Grafik, Geo. Nun, es kann nicht alles richtig sein.
KNIME
Ich mochte 6 sehr spezifische, sehr interessante Geschäftsfälle auf der Homepage. Starke OpenSource.
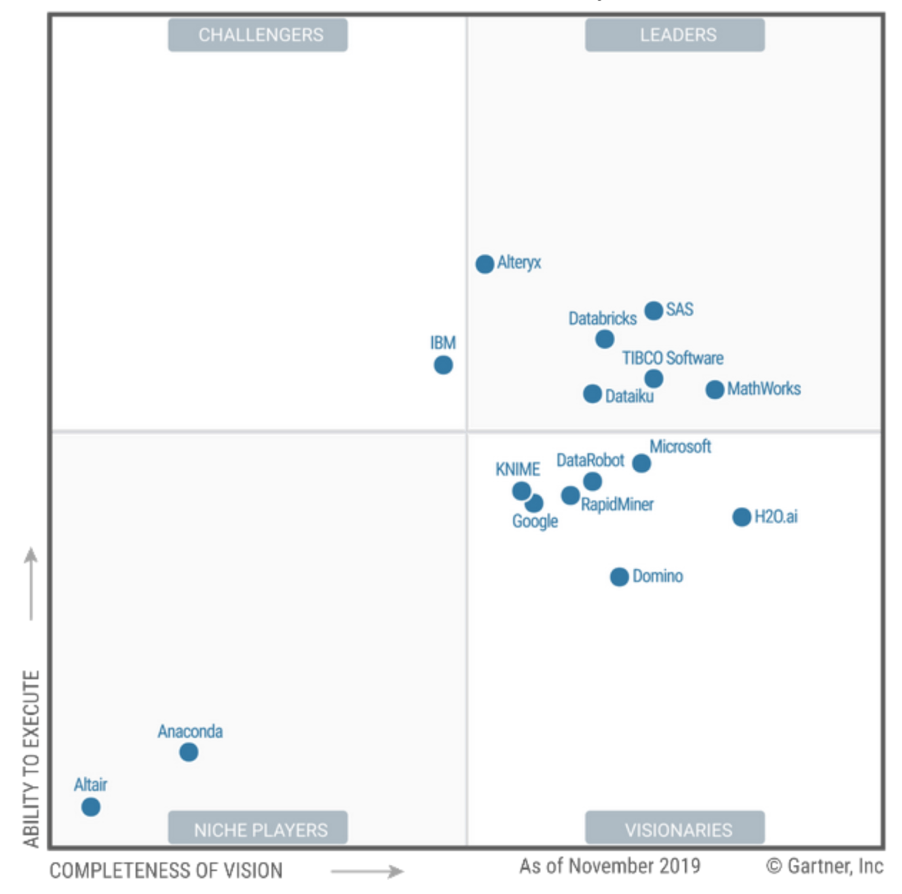
Gartner hat sich von Führungskräften zu Visionären entwickelt. Schlechtes Geld zu verdienen ist ein gutes Zeichen für Benutzer, da Leader nicht immer die beste Wahl ist.
Das Schlüsselwort ist genau wie in H2O - erweitert, es bedeutet, den armen Bürgerdatenwissenschaftlern zu helfen. Dies ist das erste Mal, dass jemand in einer Rezension wegen seiner Leistung beschimpft wurde! Interessant? Das heißt, es gibt so viel Rechenleistung, dass die Leistung überhaupt kein systemisches Problem sein kann? Gartner hat einen separaten Artikel über dieses Wort "Augmented" , den ich nicht bekommen konnte.
Und KNIME scheint der erste Nicht-Amerikaner in der Rezension zu sein! (Und unsere Designer mochten ihre Landingpage wirklich. Seltsame Leute.
MathWorks
MatLb ist ein alter Ehrenfreund, der allen bekannt ist! Werkzeugkästen für alle Lebensbereiche und Situationen. Etwas ganz anderes. In der Tat viel, viel, viel Mathematik für alle Gelegenheiten im Allgemeinen!
Simulink-Zusatzprodukt für das Systemdesign. Ich grub in die Werkzeugkästen für Digital Zwillinge - ich verstehe nicht alles darüber, aber eine Menge wurde hier geschrieben. Für die Ölindustrie . Im Allgemeinen ist dies ein grundlegend anderes Produkt als die Tiefen der Mathematik und Ingenieurwissenschaften. Auswählen bestimmter mathematischer Toolkits. Laut Gartner haben alle Probleme wie kluge Ingenieure - keine Zusammenarbeit - jeder stöbert in seinem eigenen Modell, keine Demokratie, keine Ausbeutbarkeit.
RapidMiner
Ich habe (zusammen mit Matlab) schon viel im Zusammenhang mit gutem Open Source gesehen und gehört. Wie üblich ein wenig in TurboPrep begraben. Ich bin daran interessiert, wie man saubere Daten aus schmutzigen Daten erhält.
Wieder können Sie sehen, dass die Leute in den Marketingmaterialien von 2018 gut sind und in der Feature-Demo schreckliche englischsprachige Leute.
Und Menschen aus Dortmund seit 2001 mit einer starken deutschen Vergangenheit)

Ich habe auf der Website nicht verstanden, was genau in Open Source verfügbar ist - Sie müssen tiefer graben. Gute Videos zu Bereitstellungs- und AutoML-Konzepten.
Auch das RapidMiner Server-Backend hat nichts Besonderes. Es wird wahrscheinlich kompakt sein und sofort einsatzbereit sein. In Docker verpackt. Freigegebene Umgebung nur auf dem RapidMiner-Server. Und dann ist da noch Radoop, Daten aus Hadup, die Reime aus Spark im Studio-Workflow zählen.
Drückte sie wie erwartet von den heißen jungen Anbietern "Striped Stick Sellers" runter. Gartner prognostiziert jedoch den zukünftigen Erfolg im Enterprise-Bereich. Sie können dort Geld sammeln. Die Deutschen wissen, wie heilig und heilig :) Erwähne SAP nicht !!!
Sie tun viel für die Bürger! Aber auf der Seite können Sie sehen, wie Gartner sagt, dass es ihnen mit Vertriebsinnovationen schwer fällt und sie nicht um die Breite der Abdeckung kämpfen, sondern um die Rentabilität.
Links SAS und Tibco typische BI - Anbieter für mich ... Und beide sind in der Spitze, die meine Überzeugung bestätigt , dass die normalen Data Science logisch wächst
von BI, und nicht aus den Wolken und die Hadoop - Infrastruktur. Aus dem Geschäft, d. H. Nicht aus der IT. Wie in Gazpromneft zum Beispiel: link entsteht eine ausgereifte DSML-Umgebung aus einer soliden BI-Praxis. Aber vielleicht hat sie einen Makel und eine Vorliebe für MDM und andere Dinge, wer weiß.
SAS
Nicht viel zu sagen. Nur offensichtliche Dinge.
TIBCO
Die Strategie wird in der Einkaufsliste auf einer seitenlangen Wiki-Seite gelesen. Ja, lange Geschichte, aber 28 !!! Charles. bestach BI Spotfire (2007) in meiner Techno-Jugend. Außerdem berichten Jaspersoft (2014), damals bis zu drei Anbieter von Predictive Analytics, Insightful (S-plus) (2008), Statistica (2017) und Alpine Data (2017), Streambase System (2013), MDM Orchestra Networks (2018) ) und Snappy Data (2019) In-Memory-Plattform.
Hallo Frankie!
