Für die Weizengenetik besteht eine wichtige Aufgabe darin, die Ploidie (die Anzahl identischer Chromosomensätze im Zellkern) zu bestimmen . Der klassische Ansatz zur Lösung dieses Problems basiert auf der Verwendung molekulargenetischer Methoden, die teuer und arbeitsintensiv sind. Die Bestimmung von Pflanzentypen ist nur unter Laborbedingungen möglich. Daher testen wir in dieser Arbeit die Hypothese: Ist es möglich, die Ploidie von Weizen mithilfe von Computer-Vision-Methoden nur anhand eines Ohrbildes zu bestimmen?

Daten Beschreibung
Um das Problem zu lösen, wurde bereits vor Beginn des Workshops ein Datensatz erstellt, in dem die Ploidie für jede Pflanzenart bekannt war. Insgesamt standen uns 2344 Fotos von Hexaploiden und 1259 Tetraproiden zur Verfügung.
Die meisten Pflanzen wurden unter Verwendung von zwei Protokollen fotografiert. Der erste Fall - auf einem Tisch in einer Projektion, der zweite - auf einer Wäscheklammer in 4 Projektionen. Die Fotos hatten immer eine Farbe checker Farbpalette , um es zu normieren Farben benötigt wird , und die Skala bestimmen.

Insgesamt 3603 Fotos mit 644 eindeutigen Startnummern. Der Datensatz enthält 20 Weizenarten: 10 hexaploide, 10 tetraploide; 496 einzigartige Genotypen; 10 einzigartige Vegetation. Die Pflanzen wurden zwischen 2015 und 2018 in Gewächshäusern gezüchtetICG SB RAS . Biologisches Material wurde von Akademiker Nikolai Petrovich Goncharov zur Verfügung gestellt .
Validierung
Eine Pflanze in unserem Datensatz kann bis zu 5 Fotos entsprechen, die mit unterschiedlichen Protokollen und in unterschiedlichen Projektionen aufgenommen wurden. Wir haben die Daten in drei geschichtete Gruppen unterteilt: trainieren (Trainingsstichprobe), gültig (Validierungsstichprobe) und durchhalten (verzögerte Stichprobe), in Verhältnissen von 60%, 20% bzw. 20%. Bei der Aufteilung haben wir berücksichtigt, dass alle Fotos eines bestimmten Genotyps immer in einer Teilstichprobe erscheinen. Dieses Validierungsschema wurde für alle trainierten Modelle verwendet.
Probieren Sie klassische CV- und ML-Methoden aus
Der erste Ansatz, mit dem wir das Problem gelöst haben, basiert auf dem vorhandenen Algorithmus, den wir zuvor entwickelt haben. Der Algorithmus ermöglicht das Extrahieren eines festen Satzes verschiedener quantitativer Merkmale aus jedem Bild. Zum Beispiel die Länge des Ohrs, die Fläche der Grannen usw. Für eine detaillierte Beschreibung des Algorithmus siehe Genaev et al., Morphometrie der Weizenspitze durch Analyse von 2D-Bildern, 2019 . Unter Verwendung dieses Algorithmus und der Methoden des maschinellen Lernens haben wir verschiedene Modelle trainiert, um die Arten der Ploidie vorherzusagen.
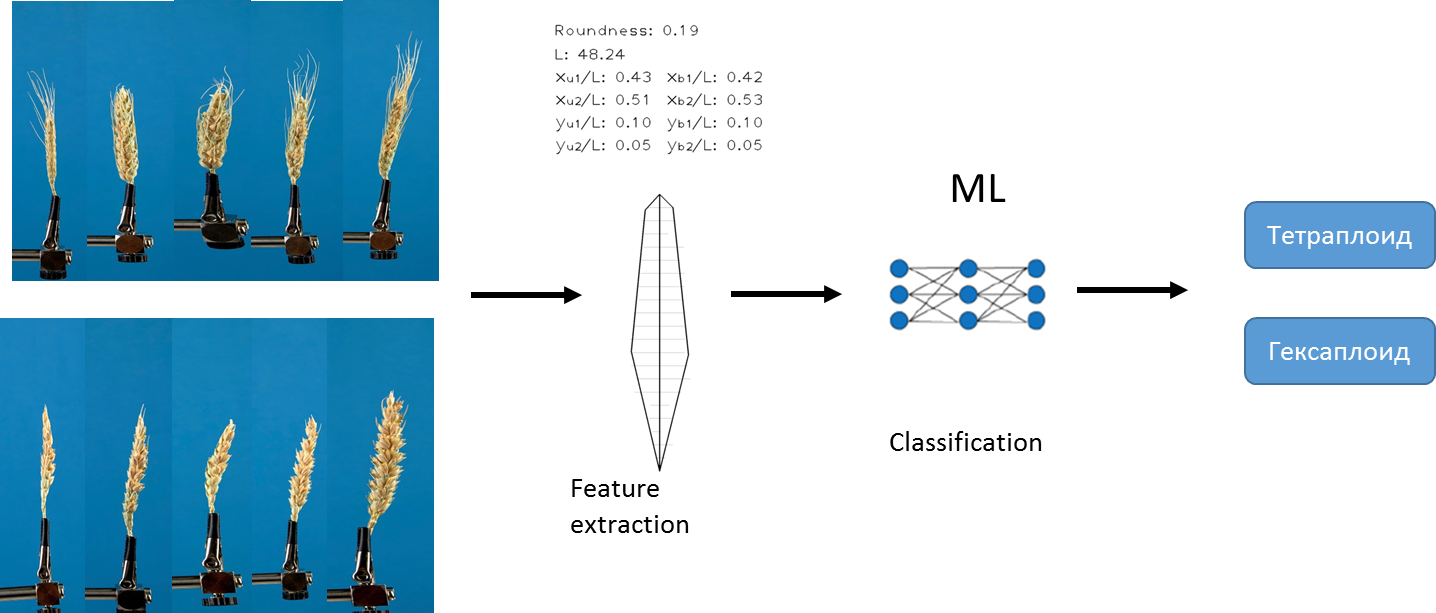
Wir verwendeten logistische Regressionsmethoden , zufällige Wald- und Gradientenverstärkung . Die Daten wurden prä- normalisiert... Wir haben AUC als Maß für die Genauigkeit gewählt .
| Methode | Zug | Gültig | Aushalten |
| Logistische Regression | 0,77 | 0,70 | 0,72 |
| Zufälliger Wald | 1,00 | 0,83 | 0,82 |
| Erhöhen | 0,99 | 0,83 | 0,85 |
Die beste Genauigkeit bei verzögerter Abtastung wurde durch die Gradientenverstärkungsmethode gezeigt, wir verwendeten die CatBoost-Implementierung.
Interpretation der Ergebnisse
Für jedes Modell erhielten wir eine Schätzung der "Wichtigkeit" jedes Merkmals. Als Ergebnis erhielten wir eine Liste aller unserer Merkmale, die nach ihrer Wichtigkeit geordnet waren, und wählten die 10 wichtigsten Merkmale aus: Grannenbereich, Zirkularitätsindex, Rundheit, Umfang, Stammlänge, xu2, L, xb2, yu2, ybm. (Eine Beschreibung der einzelnen Funktionen finden Sie hier ).
Ohrlänge und -umfang sind Beispiele für wichtige Merkmale. Die Verteilungen der Werte dieser Merkmale in Tetraploiden und Hexaploiden sind in den Histogrammen gezeigt. Es ist ersichtlich, dass die Verteilung für Hexaploide zu höheren Werten verschoben ist.

Wir haben die Top-10-Funktionen mithilfe der t-SNE-Methode geclustert
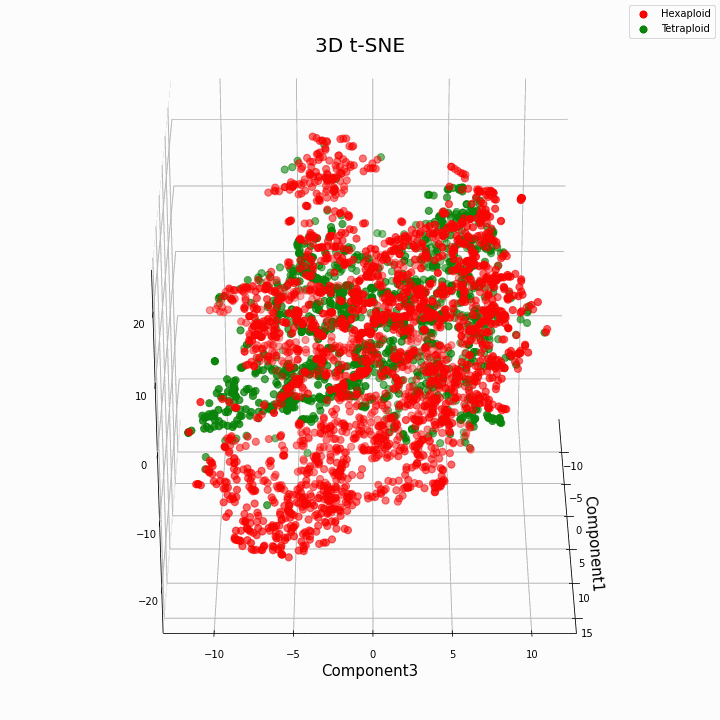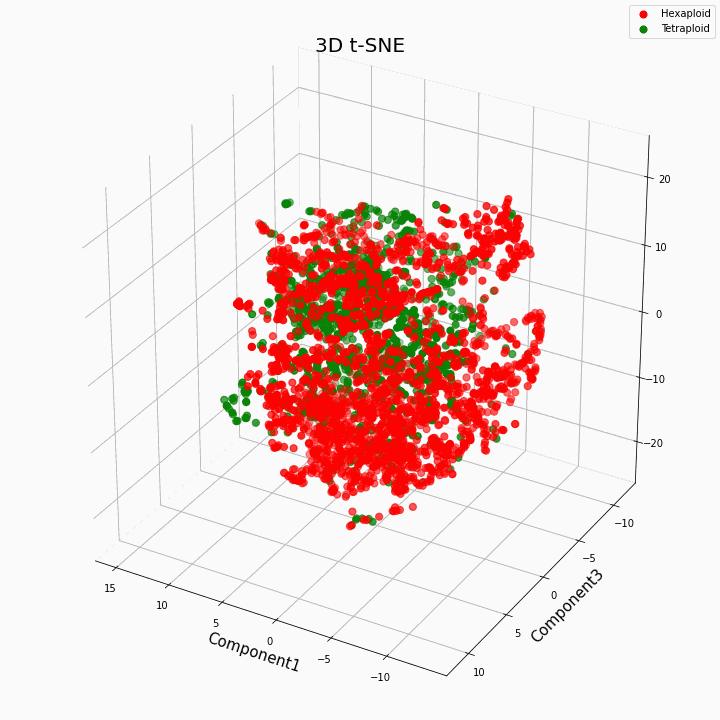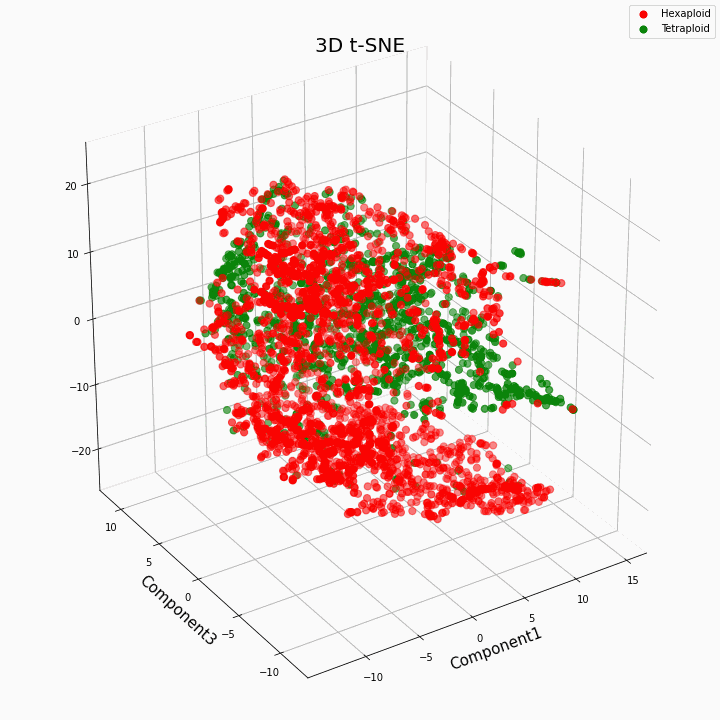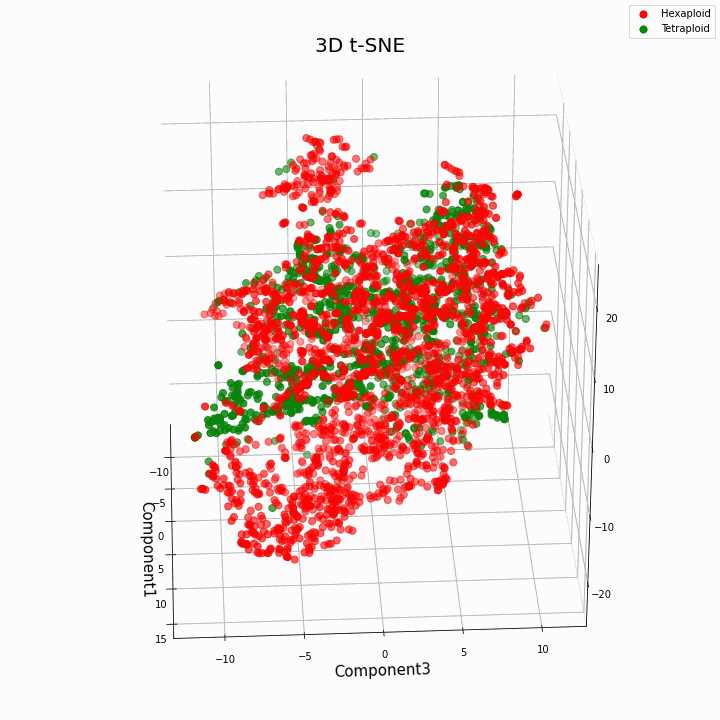
Im Allgemeinen ergibt eine größere Ploidie variablere Werte von Merkmalen. Hexaploide zeichnen sich durch eine größere Streuung / Varianz der Werte des Merkmals aus. Dies liegt daran, dass die Anzahl der Kopien von Genen in Hexaploiden größer ist und daher die Anzahl der Varianten der "Arbeit" dieser Gene zunimmt.
Um unsere Hypothese einer größeren phänotypischen Variabilität bei Hexaploiden zu bestätigen, haben wir die F-Statistik angewendet. Die F-Statistik gibt die Signifikanz der Varianzunterschiede zwischen den beiden Verteilungen an. Wir haben die Fälle betrachtet, in denen der p-Wert kleiner als 0,05 ist, um die Nullhypothese zu widerlegen, dass es keine Unterschiede zwischen den beiden Verteilungen gibt. Wir haben diesen Test unabhängig für jedes Merkmal durchgeführt. Testbedingungen: Es sollte eine Stichprobe unabhängiger Beobachtungen (bei mehreren Bildern ist dies nicht der Fall) und Normalverteilungen vorhanden sein. Um diese Bedingungen zu erfüllen, haben wir ein Bild von jedem Ohr getestet. Sie fotografierten nur in einer Projektion gemäß dem Protokoll „auf dem Tisch“. Die Ergebnisse sind in der Tabelle aufgeführt. Es ist ersichtlich, dass die Varianz für Hexaploide und Tetraploide signifikante Unterschiede für 7 Zeichen aufweist. Darüber hinaus ist in allen Fällen der Dispersionswert in Hexaploiden höher.Die größere phänotypische Variabilität bei Hexaploiden kann durch die große Anzahl von Kopien eines Gens erklärt werden.
| Name | F-statistic | p-value | Disp Hexaploid | Disp Tetraploid |
| Awns area | 0.376 | 1.000 | 1.415 | 3.763 |
| Circularity index | 1.188 | 0.065 | 0.959 | 0.807 |
| Roundness | 1.828 | 0.000 | 1.312 | 0.718 |
| Perimeter | 1.570 | 0.000 | 1.080 | 0.688 |
| Stem length | 3.500 | 0.000 | 1.320 | 0.377 |
| xu2 | 3.928 | 0.000 | 1.336 | 0.340 |
| L | 3.500 | 0.000 | 1.320 | 0.377 |
| xb2 | 4.437 | 0.000 | 1.331 | 0.300 |
| yu2 | 4.275 | 0.000 | 2.491 | 0.583 |
| ybm | 1.081 | 0.248 | 0.695 | 0.643 |
Unsere Daten umfassen 20 Pflanzenarten. 10 hexaploide und 10 tetraploide Weizen.
Wir haben die Clustering-Ergebnisse so eingefärbt, dass die Farbe + Form jedes Punkts einer bestimmten Ansicht entspricht.

Die meisten Arten besetzen ziemlich kompakte Gebiete auf der Karte. Obwohl sich diese Bereiche stark mit anderen überschneiden können. Andererseits kann es innerhalb einer Art klar definierte Cluster geben, beispielsweise für T compactum, T petropavlovskyi.
Wir haben die Werte für jede Art für 10 Merkmale gemittelt und eine Tabelle 20 mal 10 erhalten, wobei jede der 20 Arten einem Vektor von 10 Merkmalen entspricht. Für diese Daten wurde eine Korrelationsmatrix erstellt und eine hierarchische Clusteranalyse durchgeführt. Blaue Quadrate in der Grafik entsprechen Tetraploiden.

Auf dem konstruierten Baum wurden die Weizenarten im Allgemeinen in tetraploide und hexaploide unterteilt. Hexaploide Arten wurden klar in zwei Gruppen unterteilt: mittelhaarig - T. macha, T. aestivum, T. yunnanense und langhaarig - T. vavilovii, T. petropavlovskyi, T. spelta. Die einzige Ausnahme ist, dass die einzige wilde polyploide (tetraploide) Art T. dicoccoides als hexaploide klassifiziert wurde.
Gleichzeitig umfassten die tetraploiden Arten hexaploiden Weizen mit einem kompakten Ohrtyp - T. compactum, T. antiquorum und T. sphaerococcum - und die künstlich hergestellte isogene Linie ANK-23 von Weichweizen.
CNN versuchen

Um das Problem der Bestimmung der Weizenploidie aus dem Bild eines Ohrs zu lösen, haben wir ein Faltungs-Neuronales Netzwerk der EfficientNet B0-Architektur mit auf ImageNet vorab trainierten Gewichten trainiert. CrossEntropyLoss wurde als Verlustfunktion verwendet. Adam Optimierer; die Größe einer Charge beträgt 16; Die Größe der Bilder wurde auf 224 x 224 geändert. Die Lernrate wurde gemäß der Strategie fit_one_cycle mit einem anfänglichen lr = 1e-4 geändert. Wir haben das Netzwerk für 10 Epochen trainiert und dabei die folgenden Augmentationen zufällig angewendet: Rotationen um -20 +20 Grad, Änderung von Helligkeit, Kontrast, Sättigung, Spiegelung. Das beste Modell wurde gemäß der AUC- Metrik ausgewählt , deren Wert am Ende jeder Epoche berechnet wurde .
Infolgedessen ist die Genauigkeit der verzögerten Probe AUC = 0,995 , was dem Genauigkeitswert entspricht= 0,987 und ein Fehler von 1,3%. Welches ist ein sehr gutes Ergebnis.
Fazit
Diese Arbeit ist ein gutes Beispiel dafür, wie ein Team von 5 Studenten und 2 Kuratoren innerhalb weniger Wochen ein dringendes biologisches Problem lösen und neue wissenschaftliche Ergebnisse erzielen kann.
Ich möchte allen Teilnehmern unseres Projekts meinen Dank aussprechen: Nikita Prokhoshin , Alexey Prikhodko , Evgeny Zavarzin , Artem Pronozin , Anna Paulish , Evgeny Komyshev und Mikhail Genaev .
Koval Vasily Sergeevich und Kruchinina Yulia Vladimirovna für das Schießen von Ähren.
Nikolai Petrovich Goncharov und Afonnikov Dmitry Arkadyevich für das zur Verfügung gestellte biologische Material und helfen bei der Interpretation der Ergebnisse.
An das Mathematische Zentrum der Staatlichen Universität Nowosibirsk und das Institut für Zytologie und Genetik des SB RAS für die Organisation der Veranstaltung und die Rechenleistung.

PS Wir planen, den zweiten Teil des Artikels vorzubereiten, in dem wir über die Segmentierung eines Ohrs und die Auswahl einzelner Ährchen sprechen werden.