Dabei vergessen sie, dass Muster nur mögliche Lösungen sind. Muster haben wie alle Prinzipien Grenzen der Anwendbarkeit, und es ist wichtig, sie zu verstehen. Der Weg zur Hölle ist mit blindem und religiösem Festhalten an selbst maßgeblichen Worten gepflastert.
Und das Vorhandensein der notwendigen Muster im Framework garantiert nicht deren korrekte und bewusste Anwendung.

Der Glanz und die Armut von Active Record
Betrachten wir das Active Record-Muster als Antimuster, das einige Programmiersprachen und Frameworks auf jede mögliche Weise zu vermeiden versuchen.
Die Essenz von Active Record ist einfach: Wir speichern Geschäftslogik mit Entitätsspeicherlogik. Mit anderen Worten, um es ganz einfach auszudrücken, jede Tabelle in der Datenbank entspricht einer Entitätsklasse zusammen mit einem Verhalten.
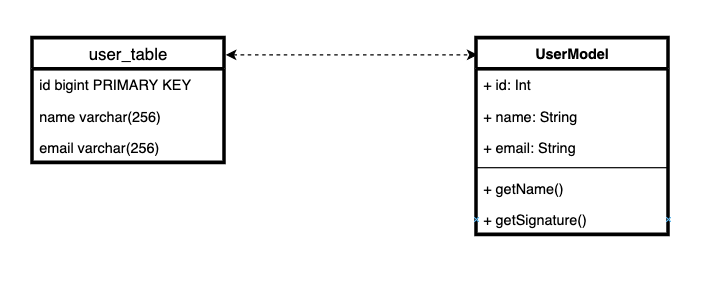
Es gibt eine ziemlich starke Meinung, dass die Kombination von Geschäftslogik mit Speicherlogik in einer Klasse ein sehr schlechtes, unbrauchbares Muster ist. Es verstößt gegen den Grundsatz der alleinigen Verantwortung. Und aus diesem Grund ist Django ORM von Natur aus schlecht.
In der Tat ist es möglicherweise nicht sehr gut, Speicherlogik und Domänenlogik in derselben Klasse zu kombinieren.
Nehmen wir zum Beispiel Benutzer- und Profilmodelle. Dies ist ein ziemlich häufiges Muster. Es gibt eine Hauptplatte und eine zusätzliche, in der nicht immer obligatorische, aber manchmal notwendige Daten gespeichert sind.

Es stellt sich heraus, dass die Entität der "Benutzer" -Domäne jetzt in zwei Tabellen gespeichert ist und wir im Code zwei Klassen haben. Und jedes Mal, wenn wir direkt einige Korrekturen vornehmen
user.profile, müssen wir uns daran erinnern, dass dies ein separates Modell ist und dass wir Änderungen daran vorgenommen haben. Und speichern Sie es separat.
def create(self, validated_data):
# create user
user = User.objects.create(
url = validated_data['url'],
email = validated_data['email'],
# etc ...
)
profile_data = validated_data.pop('profile')
# create profile
profile = Profile.objects.create(
user = user
first_name = profile_data['first_name'],
last_name = profile_data['last_name'],
# etc...
)
return user
Um eine Liste der Benutzer zu erhalten, müssen Sie unbedingt darüber nachdenken, ob diesen Benutzern ein Attribut entnommen wird,
profileum sofort zwei Zeichen mit einem Join auszuwählen und nicht SELECT N+1in einer Schleife zu erhalten.
user = User.objects.get(email='example@examplemail.com')
user.userprofile.company_name
user.userprofile.country
Noch schlimmer wird es, wenn innerhalb der Microservice-Architektur ein Teil der Benutzerdaten in einem anderen Service gespeichert wird - beispielsweise Rollen und Rechte in LDAP.
Gleichzeitig möchte ich natürlich nicht, dass sich externe Benutzer der API irgendwie darum kümmern. Es gibt eine REST-Ressource
/users/{user_id}, mit der ich arbeiten möchte, ohne darüber nachzudenken, wie Daten darin gespeichert werden. Wenn sie in verschiedenen Quellen gespeichert sind, ist es schwieriger, den Benutzer zu ändern oder die Datenliste abzurufen.
Generell ist ORM! = Domain Model!

Und je mehr sich die reale Welt von der Annahme „eine Tabelle in der Datenbank - eine Entität der Domäne“ unterscheidet, desto mehr Probleme treten mit dem Active Record-Muster auf.
Es stellt sich heraus, dass Sie sich jedes Mal, wenn Sie Geschäftslogik schreiben, daran erinnern müssen, wie die Essenz der Domäne gespeichert ist.
ORM-Methoden sind die niedrigste Abstraktionsebene. Sie unterstützen keine Einschränkungen des Themenbereichs, was bedeutet, dass sie die Möglichkeit geben, Fehler zu machen. Sie verbergen dem Benutzer auch, welche Abfragen tatsächlich in der Datenbank gestellt werden, was zu ineffizienten und langen Abfragen führt. Der Klassiker, wenn Abfragen in Schleifen statt in einem Join oder Filter durchgeführt werden.
Und was gibt uns ORM außer dem Erstellen von Abfragen (der Fähigkeit, Abfragen zu erstellen) noch? Nichts. Möglichkeit, in eine neue Datenbank zu wechseln? Und wer, der bei klarem Verstand und festem Gedächtnis ist, ist in eine neue Datenbank umgezogen, und ORM hat ihm dabei geholfen? Wenn Sie es nicht als Versuch wahrnehmen, das Domänenmodell (!) In die Datenbank abzubilden, sondern als einfache Bibliothek, mit der Sie auf bequeme Weise Abfragen an die Datenbank vornehmen können, passt alles zusammen.
Und obwohl sie in den Namen der Klassen
Modelund in den Namen der Dateien verwendet werden models, werden sie nicht zu Modellen. Täusche dich nicht. Dies ist nur eine Beschreibung der Etiketten. Sie werden nicht helfen, etwas zu kapseln.
Aber wenn alles so schlecht ist, was dann? Muster aus geschichteten Architekturen helfen.
Mehrschichtige Architektur schlägt zurück!
Die Idee hinter geschichteten Architekturen ist einfach: Wir trennen Geschäftslogik, Speicherlogik und Nutzungslogik.
Es erscheint völlig logisch, Speicher von Statusänderung zu trennen. Jene. Erstellen Sie eine separate Ebene, die Daten aus dem "abstrakten" Speicher empfangen und speichern kann.
Wir belassen beispielsweise die gesamte Speicherlogik in der Speicherklasse
Repository. Und Controller (oder Service-Layer) verwenden es nur, um Entitäten abzurufen und zu speichern. Dann können wir die Logik des Speicherns und Empfangens nach Belieben ändern, und dies wird ein Ort sein! Und wenn wir Client-Code schreiben, können wir sicher sein, dass wir keinen weiteren Ort vergessen haben, an dem wir speichern müssen oder von dem wir ihn übernehmen müssen, und wir wiederholen denselben Code nicht ein paar Mal.
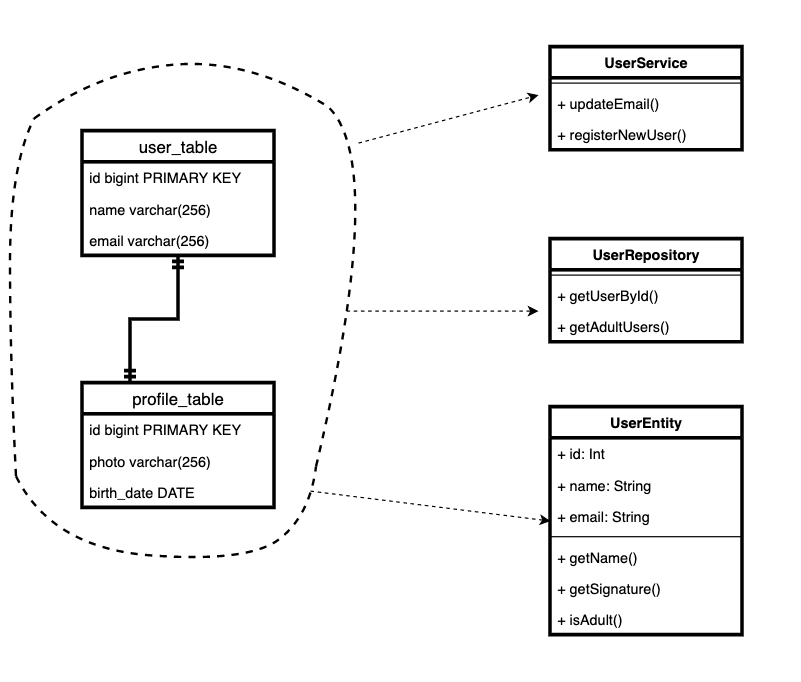
Es ist uns egal, ob die Entität aus Datensätzen in verschiedenen Tabellen oder Microservices besteht. Oder wenn Entitäten mit unterschiedlichem Verhalten je nach Typ in einer Tabelle gespeichert sind.
Diese Aufgabenteilung ist jedoch nicht frei . Es versteht sich, dass zusätzliche Abstraktionsebenen erstellt werden, um „schlechte“ Codeänderungen zu verhindern. Offensichtlich
Repositoryverbirgt es die Tatsache, dass das Objekt in der SQL-Datenbank gespeichert ist. Sie sollten also versuchen, den SQLismus nicht aus dem Rahmen zu lassen Repository. Und alle Anfragen, auch die einfachsten und offensichtlichsten, müssen durch die Speicherebene gezogen werden.
Wenn es beispielsweise erforderlich wird, ein Büro nach Namen und Abteilung zu erhalten, müssen Sie wie folgt schreiben:
#
interface OfficeRepository: CrudRepository<OfficeEntity, Long> {
@Query("select o from OfficeEntity o " +
"where o.number = :office and o.branch.number = :branch")
fun getOffice(@Param("branch") branch: String,
@Param("office") office: String): OfficeEntity?
...
Und bei Active Record ist alles viel einfacher:
Office.objects.get(name=’Name’, branch=’Branch’)
Es ist nicht so einfach, selbst wenn die Geschäftseinheit tatsächlich nicht trivial gespeichert ist (in mehreren Tabellen, in verschiedenen Diensten usw.). Um dies gut (und korrekt) zu implementieren - für das dieses Muster erstellt wurde - müssen Sie meistens Muster wie Aggregate, Arbeitseinheiten und Datenzuordnungen verwenden.
Es ist schwierig, ein Aggregat korrekt auszuwählen, alle ihm auferlegten Einschränkungen korrekt zu beachten und die Datenzuordnung korrekt durchzuführen. Und nur ein sehr guter Entwickler kann diese Aufgabe bewältigen. Derjenige, der im Fall von Active Record alles "richtig" machen könnte.
Was passiert mit regulären Entwicklern? Diejenigen, die alle Muster kennen und fest davon überzeugt sind, dass ihr Code bei Verwendung einer mehrschichtigen Architektur automatisch wartbar und gut wird, nicht wie bei Active Record. Und sie erstellen CRUD-Repositorys für jede Tabelle. Und sie arbeiten nach dem Konzept
einer Platte - eines Endlagers - einer Einheit.
Nicht:
ein Repository - ein Domänenobjekt.

Sie glauben auch blind, dass ein Wort, wenn es in einer Klasse verwendet wirdEntity, das Domänenmodell widerspiegelt. Wie ein WortModelin Active Record.
Das Ergebnis ist eine komplexere und weniger flexible Speicherschicht, die alle negativen Eigenschaften von Active Record- und Repository / Data-Mappern aufweist.
Aber geschichtete Architektur endet hier nicht. In der Regel wird auch die Serviceschicht unterschieden.
Die korrekte Implementierung einer solchen Serviceschicht ist ebenfalls eine schwierige Aufgabe. Und beispielsweise erstellen unerfahrene Entwickler eine Service-Schicht, die ein Service-Proxy für Repositorys oder ORM (DAO) ist. Jene. Services sind so geschrieben, dass sie die Geschäftslogik nicht wirklich einschließen:
#
@Service
class AccountServiceImpl(val accountDaoService: AccountDaoService) : AccountService {
override fun saveAccount(account: Account) =
accountDaoService.saveAccount(convertClass(account, AccountEntity::class.java))
override fun deleteAccount(id: Long) =
accountDaoService.deleteAccount(id)
Und es gibt eine Kombination von Nachteilen sowohl der Active Record- als auch der Service-Schicht.
Infolgedessen überschreitet in geschichteten Java-Frameworks und Code, die von jungen und unerfahrenen Musterliebhabern geschrieben wurden, die Anzahl der Abstraktionen pro Einheit der Geschäftslogik alle vernünftigen Grenzen.
Es gibt Ebenen, aber sie sind alle trivial und nur Ebenen zum Aufrufen der nächsten Ebene.
Das Vorhandensein von OOP-Mustern im Framework garantiert nicht deren korrekte und angemessene Anwendung.
Es gibt keine Silberkugel
Es ist ziemlich klar, dass es keine Silberkugel gibt. Komplexe Lösungen sind für komplexe Probleme und einfache Lösungen für einfache Probleme.
Und es gibt keine schlechten und guten Muster. In einer Situation ist Active Record eine gute, in anderen eine geschichtete Architektur. Und ja, für die überwiegende Mehrheit der kleinen und mittleren Anwendungen funktioniert Active Record recht gut. Und für die überwiegende Mehrheit der kleinen und mittleren Anwendungen ist die Schichtarchitektur (a la Spring) schlechter. Und genau das Gegenteil für logikreiche komplexe Anwendungen und Webdienste.
Je einfacher die Anwendung oder der Dienst ist, desto weniger Abstraktionsebenen benötigen Sie.
In Microservices, in denen es nicht viel Geschäftslogik gibt, ist es oft sinnlos, geschichtete Architekturen zu verwenden. Gewöhnliche Transaktionsskripte - Skripte in der Steuerung - können für die jeweilige Aufgabe vollkommen ausreichend sein.
Tatsächlich unterscheidet sich ein guter Entwickler von einem schlechten darin, dass er die Muster nicht nur kennt, sondern auch versteht, wann er sie anwenden muss.