int main()
{
int n = 500000000;
int *a = new int[n + 1];
for (int i = 0; i <= n; i++)
a[i] = i;
for (int i = 2; i * i <= n; i++)
{
if (a[i]) {
for (int j = i*i; j <= n; j += i) {
a[j] = 0;
}
}
}
delete[] a;
return 0;
}Dies ist eine einfache Anwendung, insbesondere für Experimente. Sie sucht mit dem Eratosthenes-Sieb nach Primzahlen . Lassen Sie uns die Lösung 20 Mal ausführen und die Benutzerzeit für jede Ausführung berechnen.
Beschreibung des Prüfstands
i7-8750H @ 2,20
32 RAM
O:
Ubuntu 18.04.4
5.3.0-53-generic
32 RAM
O:
Ubuntu 18.04.4
5.3.0-53-generic
Streuung der Ausführungszeit vor Optimierungen:
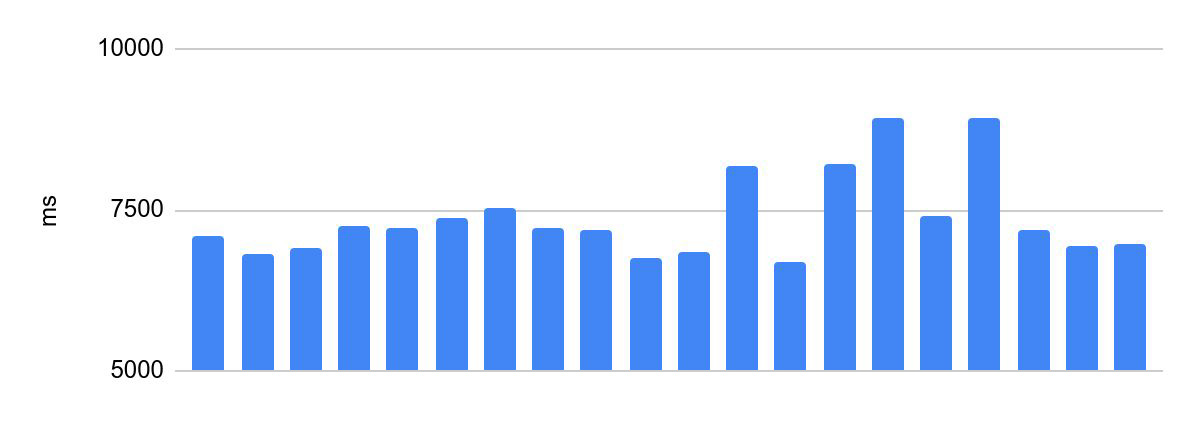
Der Unterschied zwischen der schnellsten und der langsamsten Ausführung beträgt 2230 ms.
Dies ist für die Olympiadenprogrammierung nicht akzeptabel. Die Ausführungszeit des Teilnehmercodes ist eines der Kriterien für den Erfolg seiner Lösung und eine der Bedingungen des Wettbewerbs, davon hängt die Verteilung der Preise ab. Daher gibt es für solche Systeme eine wichtige Anforderung - dieselbe Überprüfungszeit für denselben Code. Im Folgenden nennen wir dies die Konsistenz der Codeausführung.
Versuchen wir, die Ausführungszeit auszurichten.
Kernisolation
Beginnen wir mit dem Offensichtlichen. Prozesse konkurrieren um Kerne, und Sie müssen den Kern für die Ausführung der Lösung irgendwie isolieren. Wenn Hyper-Threading aktiviert ist, definiert das Betriebssystem einen physischen Prozessorkern als zwei separate logische Kerne. Für eine faire Kernisolation müssen wir Hyper Threading deaktivieren. Dies kann in den BIOS-Einstellungen erfolgen.
Der sofort einsatzbereite Linux-Kernel unterstützt ein Startflag, um den Kernel isolcpus zu isolieren. Fügen Sie dieses Flag in den Grub-Einstellungen zu GRUB_CMDLINE_LINUX_DEFAULT hinzu: / etc / default / grub. Zum Beispiel:
GRUB_CMDLINE_LINUX_DEFAULT="... isolcpus=0,1"
Führen Sie update-grub aus und starten Sie das System neu.
Alles sieht wie erwartet aus - die ersten beiden Kernel werden vom System nicht verwendet:

Beginnen wir mit einem isolierten Kernel. Mit der CPU-Affinitätskonfiguration können Sie einen Prozess an einen bestimmten Kern binden. Es gibt verschiedene Möglichkeiten, dies zu tun. Führen Sie die Lösung beispielsweise in einem Porto-Container aus (der Kernel wird mit dem Argument cpu_set ausgewählt):
portoctl exec test command='sudo stress.sh' cpu_set=0Offtop: Wir verwenden QEMU-KVM, um Lösungen in der Produktion auszuführen. Der Porto-Container wird in diesem Artikel verwendet, um die Darstellung zu vereinfachen.
Starten mit einem Kernel, der der Lösung gewidmet ist, ohne Belastung benachbarter Kernel:

Die Differenz beträgt 375 ms. Es wurde besser, aber es ist immer noch zu viel.
Tyunim Leistung
Probieren wir unseren Stresstest aus. Welcher? Unsere Aufgabe ist es, alle Kerne mit mehreren Threads zu laden. Dies kann auf verschiedene Arten erfolgen:
- Schreiben Sie eine einfache Anwendung, die viele Threads erstellt und in jedem von ihnen etwas zählt.
- :
cat /dev/zero | pbzip2 -c > /dev/null. pbzip2 — bzip2. - stress
stress --cpu 12.
Starten mit einem Kern, der einer Lösung gewidmet ist, mit Belastung benachbarter Kerne:

Die Differenz beträgt 1354 ms: eine Sekunde mehr als ohne Last. Offensichtlich wirkte sich die Last auf die Ausführungszeit aus, obwohl wir auf einem isolierten Kernel liefen. Es ist ersichtlich, dass zu einem bestimmten Zeitpunkt die Ausführungszeit abnahm. Auf den ersten Blick ist dies nicht intuitiv: Mit zunehmender Belastung steigt auch die Leistung.
In der Produktion kann dieses Verhalten (wenn die Ausführungszeit unter Last zu schweben beginnt) sehr schmerzhaft sein. Was ist die Last in diesem Fall? Eine Reihe von Entscheidungen der Teilnehmer, meistens bei großen Wettbewerben und Olympiaden.
Der Grund dafür ist, dass Intel Turbo Boost unter Last aktiviert wird - eine Technologie zur Erhöhung der Frequenz. Deaktivieren Sie es. Für meinen Stand habe ich auch SpeedStep ausgeschaltet... Für AMD-Prozessoren sollte Turbo Core Cool'n'Quiet ausgeschaltet sein. Alle oben genannten Schritte werden im BIOS ausgeführt. Die Hauptidee besteht darin, zu deaktivieren, was die Prozessorfrequenz automatisch steuert.
Laufen auf einem isolierten Kern mit deaktiviertem Turbo Boost und Laden benachbarter Kerne:

Sieht gut aus, aber der Unterschied beträgt immer noch 252 ms. Und das ist immer noch zu viel.
Offtop: Beachten Sie, dass die durchschnittliche Ausführungszeit um ca. 25% gesunken ist. Im Alltag sind behinderte Technologien gut.
Wir haben die Konkurrenz um Kerne beseitigt, die Kernfrequenz stabilisiert - jetzt wirkt sich nichts mehr auf sie aus. Woher kommt also der Unterschied?
NUMA
Uneinheitlicher Speicherzugriff oder ungleichmäßige Speicherarchitektur, "eine Architektur mit ungleichmäßigem Speicher". In NUMA-Systemen (dh herkömmlicherweise auf jedem modernen Multiprozessor-Computer) verfügt jeder Prozessor über einen lokalen Speicher, der als Teil der Gesamtsumme betrachtet wird. Jeder Prozessor kann sowohl auf seinen lokalen Speicher als auch auf den lokalen Speicher anderer Prozessoren (Remote-Speicher) zugreifen. Die Ungleichmäßigkeit besteht darin, dass der Zugriff auf den lokalen Speicher spürbar schneller ist.
Die Aufführungszeit "läuft" gerade wegen solcher Unebenheiten. Lassen Sie es uns beheben, indem Sie unsere Ausführung an einen bestimmten numa-Knoten binden. Fügen Sie dazu den Knoten numa zur Konfiguration des Portocontainers hinzu:
portoctl exec test command='stress.sh' cpu_set="node 0" cpu_set=0Laufen auf einem isolierten Kern mit deaktiviertem Turbo Boost, NUMA-Konfiguration und Laden benachbarter Kerne:
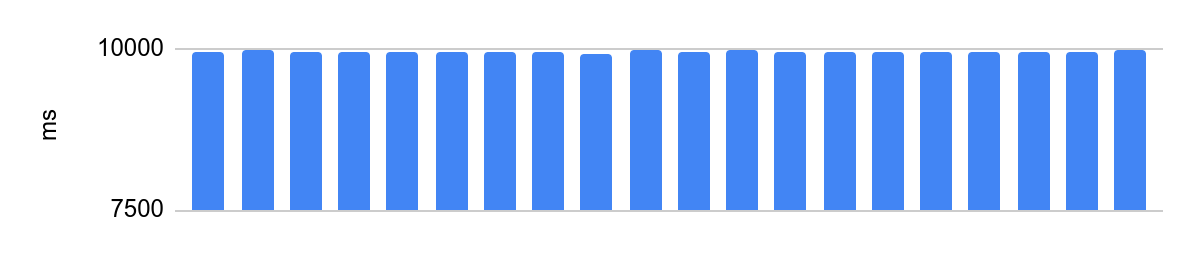
Die Differenz beträgt 48 ms, und die durchschnittliche Ausführungszeit nach Deaktivierung der Prozessoroptimierung beträgt 10 Sekunden. 48 ms bei 10 s entsprechen 0,5% Fehler, sehr gut.
Wichtiger Spoiler
Ein bisschen mehr über Isolcpus
Das isolcpus-Flag hat ein Problem: Einige Systemthreads können weiterhin einen isolierten Kernel planen.
Daher verwenden wir in der Produktion einen gepatchten Kernel mit erweiterter Funktionalität dieses Flags. Daher wählen wir den Kernel unter Berücksichtigung des Flags aus, wenn die Planung von Threads erfolgt.
, 3.18. kthread_run, . CPU, isolcpus.
— slave_cpus , .
— slave_cpus , .
Pläne für die Zukunft
Pools
Wenn eine entscheidende Maschine leistungsfähiger ist als die andere, hilft keine Menge von Kernisolationstricks - als Ergebnis erhalten wir immer noch einen großen Unterschied in der Ausführungszeit. Daher müssen Sie über heterogene Umgebungen nachdenken. Bisher haben wir die Heterogenität einfach nicht unterstützt - die gesamte Flotte der entscheidenden Maschinen ist mit derselben Hardware ausgestattet. In naher Zukunft werden wir jedoch damit beginnen, unterschiedliche Hardware in homogene Pools aufzuteilen, und jeder Wettbewerb wird innerhalb desselben Pools mit derselben Hardware stattfinden.
Umzug in die Cloud
Eine neue Herausforderung für das System wird die Notwendigkeit sein, in Yandex.Cloud zu starten. Nach heutigen Maßstäben sind Eisenserver unzuverlässig, ein Umzug ist notwendig, aber es ist wichtig, die Konsistenz bei der Ausführung von Paketen aufrechtzuerhalten. Hier werden die technischen Möglichkeiten noch untersucht. Es besteht die Idee, dass Cloud-Maschinen in extremen Fällen Lösungen ausführen können, für die keine strenge Ausführungszeit erforderlich ist. Auf diese Weise werden wir die Belastung von Eisenmaschinen reduzieren und sie werden sich nur mit Lösungen befassen, die nur Konsistenz erfordern. Es gibt noch eine andere Option: Überprüfen Sie zuerst das Paket in der Cloud und überprüfen Sie es auf realer Hardware erneut, wenn es das Zeitlimit nicht erreicht hat.
Statistiken sammeln
Selbst nach all den Optimierungen werden Prozessoren unweigerlich drosseln. Um den negativen Effekt zu verringern, führen wir die Lösungen parallel aus, vergleichen die Ergebnisse und starten, falls sie sich unterscheiden, eine erneute Überprüfung. Wenn sich eine der entscheidenden Maschinen ständig verschlechtert, ist dies eine Ausrede, um sie außer Betrieb zu setzen und sich mit den Gründen zu befassen.
Schlussfolgerungen
Der Wettbewerb hat eine Besonderheit - es scheint, dass alles darauf hinausläuft, einfach den Code auszuführen und das Ergebnis zu erhalten. In diesem Artikel habe ich nur einen kleinen Aspekt dieses Prozesses offenbart. Auf jeder Ebene des Dienstes gibt es so etwas.