Attribute mit Metainformationen
Titel (Titelattribut)
Der Titel beschreibt kurz das Wesentliche der Regel. Dieses Textfeld ist bis zu 256 Zeichen lang. Hier sollten Sie die kürzeste und umfangreichste Beschreibung geben. Befolgen Sie diese Richtlinien:
- Verwenden Sie keine Konstrukte wie "Erkennt ..." als Überschrift. Und ohne dies ist klar, dass die Regel etwas erkennt.
- Verwenden Sie umfangreiche Titel mit nicht mehr als 50 Zeichen.
- Schreiben Sie alle Erklärungen und wichtigen Kommentare in das Beschreibungsfeld (wir werden es weiter betrachten).
Detaillierte Beschreibung und zusätzliche Erläuterungen zur Regel (Beschreibungsattribut)
Wenn der Titel eine kurze Beschreibung der Regel enthält, um deren Zweck allgemein zu verstehen, können Sie im Beschreibungsfeld alle Nuancen und Merkmale angeben, die der Autor in diese Regel einfügt. Außerdem wird kurz der Angriff beschrieben, der mithilfe dieser Regel erkannt werden soll. Die maximale Länge für dieses Feld beträgt 65.535 Zeichen.
Eindeutiger Bezeichner der Regel und Bezeichner verwandter Regeln (ID, relativ)
Da die spezifischen Werte der Titel- und Beschreibungsattribute beliebig sein können, einschließlich derselben für zwei verschiedene Regeln (tun Sie dies niemals), eignen sie sich nicht zur eindeutigen Identifizierung einer Regel. Eine formellere, eindeutigere Kennung ist erforderlich. UUID (Universally Unique Identifier) wird in den meisten Produkten verwendet, um dieses Problem zu lösen. Die Autoren von Sigma raten Regelentwicklern, denselben Weg zu gehen. Für private Regeln kann jedoch jedes Schema zur Generierung von Bezeichnern verwendet werden. Im öffentlichen Repository wird die oben genannte UUID als Schema zum Erstellen von Kennungen ausgewählt. Wir haben den gleichen Ansatz in der Beispielregel im ersten Teil des Artikels verfolgt. Wenn Sie Ihre Regel in Zukunft veröffentlichen oder eine Anfrage zum Hinzufügen zum offiziellen Repository senden möchten,In diesem Fall empfehlen wir Ihnen, dasselbe Schema zum Erstellen einer Regelkennung zu verwenden.
Die eindeutige Kennung kann auf verschiedene Arten generiert werden. Unter Windows ist es am einfachsten, den folgenden PowerShell-Code auszuführen:
PS C:\> "id: $(New-Guid)"
id: b2ddd389-f676-4ac4-845a-e00781a48e5fAuf einem Linux-Kernel-basierten Betriebssystem können Sie das Dienstprogramm uuidgen verwenden:
$ echo “id: `uuidgen`”
id: b2ddd389-f676-4ac4-845a-e00781a48e5fWenn Sie wesentliche Änderungen an einer Regel vornehmen, muss deren Kennung geändert werden. Situationen, in denen eine neue Kennung erstellt werden soll:
- Ändern der Logik der Regel;
- Vererbung einer Regel von einer bestehenden unter Beibehaltung der ursprünglichen Regel (dies gilt auch für die Situation der Regelverbesserung);
- Regeln zusammenführen.
Für die Fälle der Vererbung und Zusammenführung von Regeln gibt es eine spezielle Kennung, die sich auf vier mögliche Werte des Typs bezieht (Typattribut).
Betrachten wir hypothetische Situationen, in denen es möglicherweise nützlich ist, den zugehörigen Bezeichner zu verwenden. Aus Gründen der Übersichtlichkeit schreiben wir anstelle langer Bezeichner im UUID-Format einfach X, Y, Z.
Im ersten Fall wird die neue Regel (id: X) von der vorhandenen Regel (id: Y) abgeleitet. Dies kann passieren, wenn wir die Arbeitslogik in einer neuen Regel verbessert haben, aber aus irgendeinem Grund die alte Regel beibehalten möchten. Daher verfügt unsere Regel über eine übergeordnete Regel, die gespeichert wird und in Zukunft verwendet werden kann:

Der zweite Fall ähnelt dem ersten bis auf eine Tatsache: Die alte Regel bleibt nicht erhalten. Das heißt, wir haben die Regel radikal umgeschrieben, und es war erforderlich, einen neuen Bezeichner zuzuweisen, und der alte ist veraltet (veraltet) und wird nicht mehr verwendet. Wir hatten also eine Regel (id: Y), die wir neu geschrieben haben, und wir haben entschieden, dass wir sie nicht mehr brauchen. Die neue Regel erhielt eine Kennung (ID: X). In der Sigma-Regel sieht eine ähnliche Situation ungefähr so aus:

Stellen Sie sich im dritten Fall eine Situation vor, in der eine neue Regel als Ergebnis des Zusammenführens von zwei oder mehr vorhandenen Regeln angezeigt wird. Die neue Regel (id: X) ist das Ergebnis der Zusammenführung zweier Regeln (id: Y, Z). Es ist wichtig zu beachten, dass beide übergeordneten Regeln, die an der Zusammenführung beteiligt waren, beibehalten werden und weiter verwendet werden können. In einer Sigma-Regel könnte eine ähnliche Situation folgendermaßen aussehen:

Obwohl die Reihenfolge der Regeln während der Zusammenführung nicht definiert wird, haben wir sie in den Kommentaren der Klarheit halber nummeriert.
Der vierte Typ ist Umbenennen. Wie der Name schon sagt, wird diese Art der Zuordnung zwischen Bezeichnern beim Umbenennen einer alten Regel angewendet. Tatsächlich wird dieser Typ in der Praxis nicht verwendet. Als Beispiel für die Verwendung führen die Autoren einen Fall an, in dem das Schema zum Erstellen von Bezeichnern geändert wird (wir erinnern uns, dass die UUID nicht das einzig mögliche Namensschema ist).
Regelbereitschaftsstatus (Statusattribut)
Gemäß der Spezifikation kann sich eine Regel in einem von drei Zuständen befinden:
- stabil - Die Regel kann in einer realen Infrastruktur verwendet werden, um Angriffe zu erkennen. Es sind keine Änderungen erforderlich.
- Test - Die Regel ist fast stabil, aber eine kleine Anpassung ist erforderlich.
- experimentell - eine solche Regel kann eine große Anzahl von Fehlalarmen erzeugen, enthüllt aber gleichzeitig interessante Ereignisse.
Normalerweise hat die Regel vor dem Ausführen einer Regel in einer realen Infrastruktur den experimentellen Status, da noch nicht genau bekannt ist, wie oft sie Fehler generiert. Wenn die Regel nach mehreren Monaten des Testens gut geschrieben ist und keine Fehler erzeugt (oder es vernachlässigbare gibt), wird sie in die stabile Kategorie übertragen. Andernfalls werden Korrekturen vorgenommen und erneut überprüft. Es gibt keine Regeln mit dem Teststatus im offiziellen Sigma-Repository.
Die Lizenz, unter der die Regel verteilt wird (das Lizenzattribut)
Die Lizenz, unter der die Regel verteilt wird. Dieses Feld stammt aus der Welt der freien Software. Es wird selten angegeben, aber wenn angegeben, muss es der SPDX-ID-Spezifikation entsprechen.
Regelersteller (Autorenattribut)
In diesem Feld werden alle Autoren der Regel aufgelistet. Es wird als gute Form angesehen, nicht nur die Person anzugeben, die die Regel selbst geschrieben hat, sondern auch den Autor der ursprünglichen Idee der Entdeckung.
Links zu Studien, die zur Entwicklung der Regel beigetragen haben (Referenzattribut)
Beim Schreiben von Sigma-Regeln ist es üblich, Links zu Originalartikeln, Tweets und Recherchen einzuschließen, die zur Erstellung der Regel beigetragen haben. Solche Links drücken nicht nur den Respekt für die Arbeit eines anderen aus, sondern helfen auch später zu verstehen, wie die Regel funktioniert.
Ereignisfelder, die für die Analyse nützlich sind, um anzuzeigen, wann eine Regel ausgelöst wird (Feldattribut)
Da der Autor der Regel den Angriffsalgorithmus und die Ereignisse, die während seiner Ausführung generiert werden, genau kennt, kann er eine Liste von Feldern aus Ereignissen auswählen, die dem SOC-Bediener oder einem anderen Mitarbeiter des Informationssicherheitsteams helfen, den Vorfall zu verstehen.
Fälle von falsch positiven Ergebnissen der Regel (Attribut falsch positive Ergebnisse)
Das Feld falsepositives ist für Erkennungsregeln eher ungewöhnlich. Es hat keinerlei Einfluss auf den Verlauf der Ereignisvalidierung, aber es macht zwei nützliche Dinge:
- Helfen Sie dem Benutzer festzustellen, ob ein bestimmter Regelauslöser ein Fehler ist.
- Erinnern Sie den Entwickler der Regel noch einmal daran, dass seine Regel fälschlicherweise ausgelöst werden kann. Solche Gedanken können dem Entwickler helfen, eine genauere Regel zu schreiben.
Verschiedene Tags und Tags (Tags-Attribut)
In der Regel wird dieses Feld für MITRE ATT & CK- und CAR-Tags verwendet. Wir empfehlen dringend, dass Sie Ihre Regel sofort klassifizieren, da Sie mit einem solchen Markup Sigma-Regeln in andere Informationssicherheitsprojekte integrieren können. Das Format beschränkt die Autoren der Regeln jedoch nicht nur auf solche Bezeichnungen, Sie können auch solche einfügen.
Sammlungen von Regeln
Gemäß dem YAML-Standard kann eine Datei (in ihrem Terminologiestream) mehrere YAML-Dokumente enthalten. Dies wird durch das YAML-Dokument-Tag erreicht - drei Bindestriche („---“). Für das Sigma-Format können diese Dokumente unabhängige Sigma-Regeln oder Aktionsdokumente sein.
Im ersten Fall ist alles einfach: Eine Datei enthält vollständige Sigma-Regeln, die durch eine YAML-Dokumentbezeichnung voneinander getrennt (Beispiel rules / proxy / proxy_ursnif_malware.yml ) Der
zweite Fall ist komplizierter: Ein YAML-Dokument wird als Aktionsdokument behandelt, wenn das Aktionsattribut der obersten Ebene einen der folgenden drei Werte aufweist:
- global — , YAML- . action- . : , Sigma- ;
- reset — , action-;
- repeat — repeat .
Hinweis : Das Aktionsattribut kann an einer beliebigen Stelle in der Regel angezeigt werden.
Der häufigste Anwendungsfall für eine Sammlung von Regeln besteht darin, mehrere Sigma-Regeln für ähnliche Ereignisse zu definieren, z. B. Windows Security EventID 4688 und Sysmon EventID 1. Beide Ereignisse werden als Ergebnis der Prozesserstellung angezeigt und haben nur unterschiedliche Quellen. Die Sammlung von Sigma-Regeln für ein bestimmtes Szenario kann drei Aktionsdokumente enthalten:
- Ein globales Aktionsdokument, das allgemeine Metadatenfelder und Erkennungsindikatoren definiert.
- Regel, die die Quelle des Windows-Sicherheitsereignisprotokolls und des Ereignisses EventID = 4688 definiert.
- Eine Regel, die die Quelle des Windows Sysmon-Ereignisprotokolls und des Ereignisses EventID = 1 definiert.
Eine alternative Lösung könnte sein:
- Ein globales Aktionsdokument, das allgemeine Metadatenfelder definiert.
- Windows Security Event Log ( EventID=4688) .
- Action- repeat, logsource EventID , . 2.
action-
In diesem Abschnitt wird genau beschrieben, wie Sigma basierend auf den Werten des Aktionsattributs Zusammenfassungsregeln generiert. YAML-Dokumente, die ein Aktionsattribut mit dem Wert global enthalten, werden als globale Dokumente in dieser Datei betrachtet, und ihre Felder werden allen anderen Dokumenten hinzugefügt.
Hinweis : Wenn das aktuelle Dokument das Aktionsattribut mit dem Rücksetzwert enthält, werden die globalen Dokumentfelder nicht hinzugefügt.
Die Logik für die Arbeit mit globalen Dokumenten lautet wie folgt: Sobald der Parser auf ein globales Dokument stößt (ein Dokument, das ein Aktionsattribut mit dem globalen Wert enthält), fügt er seine Felder einem speziellen Puffer hinzu und fährt mit dem nächsten Dokument fort. Nennen wir diesen speziellen Puffer GLOBALYAML. Es wird in Zukunft hilfreich sein, in Diagrammen darauf zu verweisen.
Wichtig: Da Dokumentgrenzen durch die Markierung „---“ definiert sind, ist es wichtig, diese Markierungen korrekt in der Datei zu platzieren.
Im folgenden Beispiel enthält das erste YAML-Dokument ein Aktionsattribut mit dem Wert global. Die Grenzen dieses Dokuments erstrecken sich bis zur ersten Dokumentmarke. Somit wird das gesamte erste Dokument in den globalen Puffer geschrieben. Die Felder dieses Puffers werden dann zu jedem nachfolgenden Dokument hinzugefügt. Als Ergebnis erhalten wir zwei Regeln am Ausgang. Schema 1. Verarbeiten einer einfachen Regel mit der korrekten Definition der YAML-Dokumentbeschriftungen Wenn Sie jedoch die erste Beschriftung löschen oder vergessen, werden alle Felder von YAML-DOKUMENT 2 in das globale Dokument aufgenommen. Infolgedessen erhalten wir nur eine Regel mit einem falschen Satz von Suchkennungen am Ausgang. Daher ist es sehr wichtig, YAML-Dokumente in solchen zusammengesetzten Regeln ordnungsgemäß zu kennzeichnen.
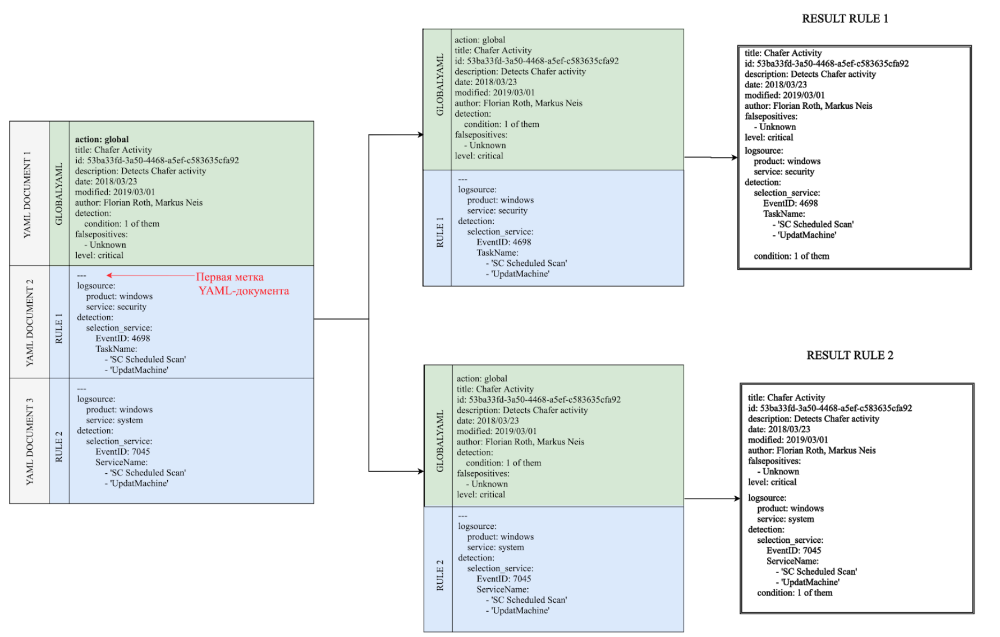

Schema 2. Verarbeitung der vorherigen Regel - Wenn Sie vergessen haben, das erste Etikett des YAML-Dokuments anzubringen,
sollte beachtet werden, dass das globale Dokument nicht unbedingt am Anfang steht. Wenn Sie sich die beiden vorherigen Schemata ansehen, dann ist es nicht immer YAML-DOKUMENT 1. Außerdem muss es nicht im Singular sein. Das folgende Diagramm veranschaulicht dies deutlich. Schema 3. Verarbeiten einer Regel mit verschiedenen Optionen zum Festlegen eines globalen YAML-Dokuments Daher haben wir die Probleme im Zusammenhang mit der korrekten Platzierung von YAML-Dokumentbeschriftungen berücksichtigt. Wir haben auch gesehen, dass Sie das globale YAML-Dokument mithilfe des Aktionsattributs mit dem globalen Wert auf verschiedene Arten festlegen können. Als nächstes betrachten wir das Schema zum Transformieren einer Regel unter Verwendung der beiden verbleibenden Werte des Aktionsattributs - Zurücksetzen und Wiederholen.


Schema 4. Verarbeiten einer Regel, die die Aktionsattribute mit den Werten zum Zurücksetzen und Wiederholen enthält
Was muss noch über das Sigma-Projekt gesagt werden?
Sigma ist nicht nur ein Satz formatierter Regeln, die wir in dieser Reihe behandelt haben.
In unseren Veröffentlichungen haben wir uns auf die Beschreibung des Formats und der Syntax der Regeln konzentriert. Die Regeln sind jedoch nur die eine Hälfte des Projekts, die zweite sind die vom Sigmac-Konverter verwendeten Backends. Herkömmlicherweise können diese Wandler als "Adapter" mit einem universellen Eingang und einem spezifischen Ausgang betrachtet werden. Es ist das Vorhandensein solcher "Adapter", die das universelle Beschreibungsformat so nützlich machen. In dieser Situation spielt es keine Rolle, welches der unterstützten Systeme Sie verwenden. Mit Sigma können Sie die Idee und den Erkennungsalgorithmus beschreiben, während das eine oder andere Backend für den Sigmac-Konverter für die spezifische Syntax des Zielsystems und die Zuordnung von Feldern verantwortlich ist.
Gehen Sie jedoch nicht davon aus, dass Sie durch Herunterladen der Regeln und Konvertieren in die Syntax des erforderlichen Zielsystems alle Probleme lösen, die mit dem Befüllen Ihres Systems mit Fachwissen verbunden sind. Wir werden kurz diskutieren, warum Sigma derzeit keine Out-of-the-Box-Lösung ist und warum es notwendig ist, die Syntax der Regeln zu verstehen.
Aktuelle Sigma-Herausforderungen
Sigma ist ein sich aktiv entwickelndes Projekt und wie jedes wachsende Projekt hat Sigma seine eigenen Herausforderungen. Persönlich sehe ich sie als Entwicklungspunkte und Wachstumsbereiche. Da es sich um ein Open-Source-Projekt handelt, können gemeinsame Kräfte einen wesentlichen Beitrag zur Entwicklung bestimmter Teile des Projekts leisten. Ich werde auflisten, worauf ich mich im Moment auf die Hauptaufrufe des Frameworks beziehe:
- . .
- , Windows- (. ). , .
- Wiki , . .
- experimental — , .
- .
- , .
Aus eigener Erfahrung werde ich sagen, dass sich der erste Punkt auf der Liste als der bedeutendste herausstellte, als ich das Sigma-Projekt kennenlernte und an OSCD teilnahm. Es stellte sich heraus, dass die Unterschiede zwischen der Syntax in MaxPatrol SIEM und in Sigma nicht nur mit der Semantik von Schlüsselwörtern und dem Entwurf von Korrelationsregeln enden. Einige unserer Ideen können nicht mit der Sigma-Syntax beschrieben werden, da zu diesem Zeitpunkt keine Möglichkeit einer Ereigniskorrelation besteht. Mit dem Korrelationsmechanismus können Sie nach gemeinsamen Werten von Ereignisfeldern suchen und solche Ereignisse miteinander in Beziehung setzen. Dies ist nützlich, wenn wir die Beziehung zwischen Ereignissen genau herstellen möchten. Zum Beispiel, um Ereignisse innerhalb einer Benutzersitzung zu verfolgen. Dazu müssen Sie Ereignisse nach dem Wert des LogonID-Felds oder dessen Äquivalent binden.
Es ist zu beachten, dass Punkterkennungen oder Erkennungen, die auf nicht direkt verwandten Ereignissen basieren, mit Sigma sehr erfolgreich beschrieben werden.
Eine Möglichkeit, diese und andere Probleme anzugehen, besteht darin, aktiv an einem der OSCD-Sprints teilzunehmen. Und da es viele Aufgaben gibt, kann jeder etwas finden, das ihn interessiert.
Neuer Sprint kommt bald, mach mit!
Wir bedanken uns bei den Organisatoren des ersten Sprints für die qualitativ hochwertige Durchführung der Veranstaltung und die aufmerksame Haltung gegenüber den Teilnehmern. Was sind die einzigen personalisierten Postkarten, die von Hand ausgefüllt und an jeden Teilnehmer gesendet werden? Wir für unseren Teil planen, weiterhin an neuen Sprints teilzunehmen und einen möglichen Beitrag zum Sigma-Repository zu leisten.
Nachdem Sie unsere Artikelserie gelesen und sich mit dem Format der Regeln vertraut gemacht haben, können Sie Ihr Fachwissen zum Nutzen der gesamten Community für Informationssicherheit einsetzen.
Nehmen Sie unbedingt am zweiten Sprint teil. Nehmen Sie individuell teil und stellen Sie Teams zusammen. Lassen Sie uns gemeinsam die Welt sicherer machen!
Kontakte der OSCD-Initiative:
Autor : Anton Kutepov, Spezialist der Abteilung für Expertendienste und Entwicklung positiver Technologien (PT Expert Security Center)