
. OTUS Machine Learning: . , -, : « ML» « ».Im ersten Teil dieses Tutorials haben wir Ihr Klassifizierungsmodell erfolgreich in einem lokalen Verzeichnis gespeichert und alle Modellentwicklungsarbeiten im Zusammenhang mit dem Jupyter-Notizbuch abgeschlossen. Von nun an liegt der Schwerpunkt auf der Bereitstellung unseres Modells. Um das Modell für die Vorhersage wiederzuverwenden, können Sie es einfach laden und die Methode aufrufen,
predict()wie Sie es normalerweise in einem Jupyter-Notizbuch tun würden.
Um das Modell zu testen
model.pkl, erstellen Sie im selben Ordner wie die Datei eine Datei main.pymit dem folgenden Code:
import pickle
# ,
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
#
with open('./model.pkl', 'rb') as model_pkl:
knn = pickle.load(model_pkl)
# ( )
unseen = np.array([[3.2, 1.1, 1.5, 2.1]])
result = knn.predict(unseen)
#
print('Predicted result for observation ' + str(unseen) + ' is: ' + str(result))Wiederverwendung des Modells für Prognosen.
Sie können die Vorhersagemethode für unbekannte Beobachtungen mehrmals aufrufen, ohne den Trainingsprozess neu zu starten. Wenn Sie diese py-Datei jedoch im Terminal ausführen, kann ein Fehler wie der folgende auftreten:
Traceback (most recent call last):
File "main.py", line 4, in <module>
from sklearn.neighbors import KNeighborsClassifier
ImportError: No module named sklearn.neighborsDies liegt daran, dass das von uns verwendete Paket in der Umgebung, in der Sie die Datei ausführen, nicht verfügbar ist. Dies bedeutet, dass die zur Entwicklung des Modells verwendete Umgebung (conda) nicht mit der Laufzeit identisch ist (Python-Umgebung außerhalb von conda). Dies kann als potenzielles Problem angesehen werden, wenn unser Code in anderen Umgebungen ausgeführt wird. Ich wollte ausdrücklich, dass Sie diesen Fehler sehen, Ihnen helfen, das Problem zu verstehen, und erneut betonen, wie wichtig es ist, Container zur Bereitstellung unseres Codes zu verwenden, um solche Probleme zu vermeiden. Im Moment können Sie einfach alle erforderlichen Pakete manuell mit dem Befehl "pip install" installieren. Wir werden später hierher zurückkommen, um dies automatisch zu tun.
Nach der Installation aller Pakete und dem erfolgreichen Ausführen der Datei sollte das Modell schnell die folgende Meldung zurückgeben:
Predicted result for observation [[3.2 1.1 1.5 2.1]] is: [1]Wie Sie hier sehen können, verwenden wir fest codierte unbekannte Daten, um das Modell zu testen. Diese Zahlen repräsentieren die Länge des Kelchblattes, seine Breite, die Länge des Blütenblatts bzw. seine Breite. Da wir unser Modell jedoch als Service verfügbar machen möchten, muss es als eine Funktion verfügbar gemacht werden, die Anforderungen akzeptiert, die diese vier Parameter enthalten, und ein Vorhersageergebnis zurückgibt. Diese Funktion kann dann für einen API-Server (Backend) verwendet oder in einer serverlosen Laufzeit wie Google Cloud-Funktionen bereitgestellt werden . In diesem Tutorial werden wir versuchen, einen API-Server zusammenzustellen und in einen Docker-Container zu legen.
Wie funktioniert die API?
Lassen Sie uns darüber sprechen, wie Webanwendungen heute funktionieren. Die meisten Webanwendungen verfügen über zwei Hauptkomponenten, die fast alle Funktionen abdecken, die eine Anwendung benötigt: Frontend und Backend. Das Frontend konzentriert sich darauf, die Benutzeroberfläche (Webseite) für den Benutzer bereitzustellen, während der Frontend-Server häufig HTML, CSS, JS und andere statische Dateien wie Bilder und Töne speichert. Auf der anderen Seite verarbeitet der Backend-Server die gesamte Geschäftslogik, die auf vom Frontend gesendete Anforderungen reagiert.

Darstellung der Struktur von Webanwendungen .
Dies passiert, wenn Sie Medium in Ihrem Browser öffnen.
- HTTP-
medium.com. DNS-, , . ., . -
* .html,* .css,* .js, - . - Medium . , «clap» () .
- (javascript) HTTP- id . URL- , . id XXXXXXX.
- (, ) .
- .
- , .
Natürlich ist dies möglicherweise nicht genau derselbe Prozess, der bei Verwendung der Medium-Webanwendung abläuft, und tatsächlich wäre dies viel komplizierter, aber dieser vereinfachte Prozess kann Ihnen helfen, die Funktionsweise einer Webanwendung zu verstehen.
Jetzt möchte ich, dass Sie sich auf die blauen Pfeile im Bild oben konzentrieren. Dies sind HTTP-Anforderungen (vom Browser gesendet) und HTTP-Antworten (vom Browser empfangen oder an den Browser gesendet). Die Komponenten, die Anforderungen vom Browser verarbeiten und Antworten an den Back-End-Server zurückgeben, werden als "APIs" bezeichnet.
Unten ist die API-Definition:
(API — application program interface) — , . , API , .
API!
Es gibt viele Frameworks, mit denen wir APIs mit Python erstellen können, darunter Flask, Django, Pyramid, Falcon und Tornado. Die Vor- und Nachteile sowie ein Vergleich dieser Strukturen sind hier aufgelistet . Ich werde Flask für dieses Tutorial verwenden, aber die Technik und der Workflow bleiben die gleichen wie für die anderen. Alternativ können Sie an dieser Stelle Ihr bevorzugtes Framework verwenden.
Die neueste Version von Flask kann mit diesem Befehl über pip installiert werden:
pip install FlaskJetzt müssen Sie nur noch den Code aus dem vorherigen Schritt in eine Funktion umwandeln und nach der Initialisierung Ihrer Flask-Anwendung einen API-Endpunkt dafür registrieren. Standardmäßig wird eine Flask-Anwendung auf localhost (127.0.0.1) ausgeführt und wartet auf Anforderungen auf Port 5000.
import pickle
# ,
import numpy as np
import sys
from sklearn.neighbors import KNeighborsClassifier
# Flask API
from flask import Flask, request
#
with open('./model.pkl', 'rb') as model_pkl:
knn = pickle.load(model_pkl)
# Flask
app = Flask(__name__)
# API
@app.route('/predict')
def predict_iris():
#
sl = request.args.get('sl')
sw = request.args.get('sw')
pl = request.args.get('pl')
pw = request.args.get('pw')
# predict
#
unseen = np.array([[sl, sw, pl, pw]])
result = knn.predict(unseen)
#
return 'Predicted result for observation ' + str(unseen) + ' is: ' + str(result)
if __name__ == '__main__':
app.run()Darstellen Ihres Modells als API
Auf dem Terminal sollte Folgendes angezeigt werden:
* Serving Flask app "main" (lazy loading)
* Environment: production
WARNING: This is a development server. Do not use it in a production deployment.
Use a production WSGI server instead.
* Debug mode: off
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)Öffnen Sie Ihren Browser und geben Sie die folgende Abfrage in die Adressleiste ein:
http://localhost:5000/predict?sl=3.2&sw=1.1&pl=1.5&pw=2.1Wenn so etwas in Ihrem Browser erscheint, herzlichen Glückwunsch! Sie stellen Ihr Modell für maschinelles Lernen jetzt als Service mit einem API-Endpunkt zur Verfügung.
Predicted result for observation [['3.2' '1.1' '1.5' '2.1']] is: [1]API-Tests mit Postman
Wir haben kürzlich unseren Browser für schnelle API-Tests verwendet, dies ist jedoch kein sehr effizienter Weg. Beispielsweise könnten wir nicht die GET-Methode verwenden, sondern stattdessen die POST-Methode mit dem Authentifizierungstoken im Header, und es ist nicht einfach, den Browser dazu zu bringen, eine solche Anforderung zu senden. In der Softwareentwicklung wird Postman häufig zum Testen von APIs verwendet und ist für die grundlegende Verwendung völlig kostenlos.
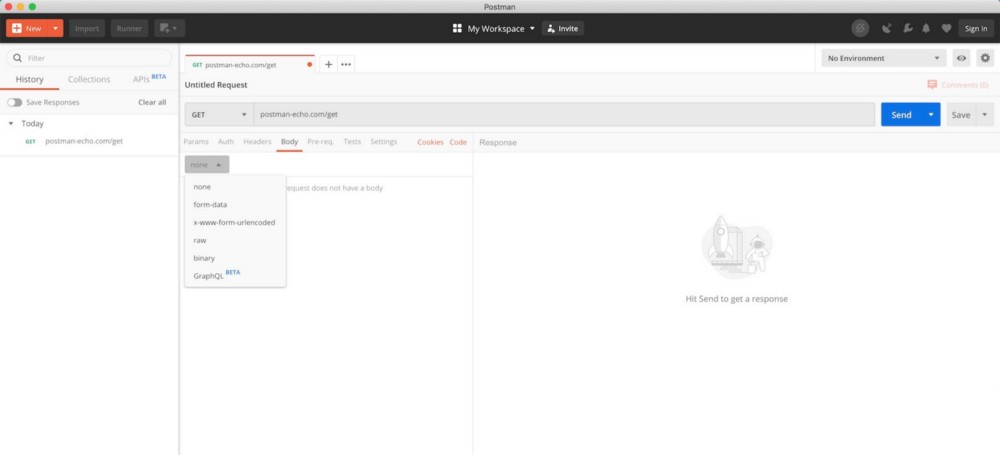
Postman-Benutzeroberfläche (von der Postman-Download-Seite )
Öffnen Sie nach dem Herunterladen und Installieren von Postman das Tool und befolgen Sie die nachstehenden Anweisungen, um Ihre Anfrage zu senden.

Senden einer GET-Anfrage mit Postman
- , GET , API GET . , POST .
- URL .
- . , .
- «», API.
- .
- HTTP-. .
Nachdem Sie nun wissen, wie Sie Ihr Modell für maschinelles Lernen als Service über einen API-Endpunkt verfügbar machen und diesen Endpunkt mit Postma testen können, besteht der nächste Schritt darin, Ihre Anwendung mit Docker zu containerisieren. Dort werden wir uns genauer ansehen, wie Docker funktioniert und wie es uns helfen kann. Lösen Sie alle zuvor aufgetretenen Abhängigkeitsprobleme.
Lesen Sie den ersten Teil.