
Einführung
Es gibt viele Wettbewerbe im Bereich maschinelles Lernen sowie auf den Plattformen, auf denen sie stattfinden, und für jeden Geschmack. Aber nicht so oft ist das Thema des Wettbewerbs die menschliche Sprache und ihre Verarbeitung, noch seltener ist ein solcher Wettbewerb mit der russischen Sprache verbunden. Ich habe kürzlich an einem Wettbewerb für maschinelle Übersetzungen von Chinesisch nach Russisch auf der ML Boot Camp-Plattform von Mail.ru teilgenommen. Da ich nicht viel Erfahrung mit wettbewerbsfähiger Programmierung hatte und dank der Quarantäne alle Maiferien zu Hause verbracht hatte, konnte ich den ersten Platz belegen. Ich werde versuchen, darüber sowie über Sprachen und das Ersetzen einer Aufgabe durch eine andere im Artikel zu sprechen.
Kapitel 1. Sprechen Sie niemals Chinesisch
Die Autoren dieses Wettbewerbs schlugen vor, ein universelles maschinelles Übersetzungssystem zu schaffen, da die Übersetzung selbst von großen Unternehmen in einem chinesisch-russischen Paar deutlich hinter den populäreren Paaren zurückbleibt. Da die Validierung jedoch für Nachrichten und Belletristik erfolgte, wurde klar, dass es notwendig war, aus Nachrichtenkorpus und Büchern zu lernen. Die Metrik zur Bewertung von Übertragungen war die Standard- BLEU . Diese Metrik vergleicht die menschliche Übersetzung mit der maschinellen Übersetzung und schätzt grob gesagt anhand der Anzahl der gefundenen Übereinstimmungen die Ähnlichkeit von Texten auf einer 100-Punkte-Skala. Die russische Sprache ist reich an Morphologie, daher ist diese Metrik bei der Übersetzung immer merklich niedriger als in Sprachen mit weniger Arten der Wortbildung (z. B. romanische Sprachen - Französisch, Italienisch usw.).
Jeder, der maschinelles Lernen betreibt, weiß, dass es in erster Linie um Daten und deren Bereinigung geht. Lassen Sie uns nach Korpora suchen und parallel dazu werden wir die Wildnis der maschinellen Übersetzung verstehen. Also, in einem weißen Umhang ...
Kapitel 2. Pon Tiy Pi Lat
In einem weißen Umhang mit blutigem Futter und schlurfendem Kavalleriegang steigen wir in eine Suchmaschine hinter einem parallelen russisch-chinesischen Korps. Wie wir später verstehen werden, reicht das, was wir gefunden haben, nicht aus, aber jetzt schauen wir uns unsere ersten Funde an (ich habe die gefundenen und bereinigten Datensätze gesammelt und öffentlich zugänglich gemacht [1] ):
OPUS ist ein ziemlich großer und sprachlich vielfältiger Korpus. Schauen wir uns Beispiele an:
"Was sie und ich erlebt haben, ist noch ungewöhnlicher als das, was Sie erlebt haben ... " I
与 与 的 经历 比 你 的 经历
I I "Ich werde Ihnen davon erzählen." ”
给 你 讲讲 这段 经历…
“ Die kleine Stadt, in der ich geboren wurde ... "
我 出生 那座 小镇 ...
Wie der Name schon sagt, handelt es sich meistens um Untertitel für Filme und Fernsehsendungen. TED- Untertitel gehören zum selben Typ , der sich nach dem Parsen und Reinigen ebenfalls in einen vollständig parallelen Korpus verwandelt:
Dies ist , wie unser historisches Experiment in Strafe stellte sich heraus:WikiMatrix ist LASER- ausgerichtete Texte von Internetseiten (das sogenannte Common Crawlen ) in verschiedenen Sprachen, aber für unsere Aufgabe gibt es nur wenige davon, und sie sehen seltsam aus:
这就是关于我们印象中的惩戒措施的不为人知的一面
. Junge Menschen Angst haben , dass sie jederzeit gestoppt werden kann, durchsucht, festgehalten
年轻人总是担心随时会被截停、 搜身 和 逮捕
Und nicht nur auf der Straße, sondern auch in ihren eigenen
vier Wänden ,无论 是 在 街上 还是 在家
Zbranki (UkrainischNach der ersten Phase des Datenabrufs stellt sich bei unserem Modell eine Frage. Was sind die Werkzeuge und wie gehen Sie überhaupt mit der Aufgabe um?
。 被 其 否认。
Aber du solltest besser schnell sein, wenn du es nur wüsstest!。
对于 你们 更好 , , 你们 你们。
Er lehnte eine solche Aussage ab.
后来 这个 推论 被 否认。
Es gibt einen NLP- Kurs, den ich von MIPT on Stepic [2] sehr gemocht habe. Dieser ist besonders nützlich, wenn Sie online gehen, wo maschinelle Übersetzungssysteme auch in Seminaren verstanden werden und Sie sie selbst schreiben. Ich erinnere mich an die Freude, dass das Netzwerk, das nach seinem Studium in Colab von Grund auf neu geschrieben wurde, eine angemessene russische Übersetzung als Antwort auf den deutschen Text produzierte. Wir haben unsere Modelle auf der Architektur von Transformatoren mit einem Aufmerksamkeitsmechanismus aufgebaut, der einst zu einer bahnbrechenden Idee wurde [3] .
Der erste Gedanke war natürlich, „dem Modell einfach andere Eingabedaten zu geben“ und bereits zu gewinnen. Aber wie jeder chinesische Student weiß, gibt es in der chinesischen Schrift keine Leerzeichen, und unser Modell akzeptiert Sätze von Token als Eingabe, bei denen es sich um Wörter handelt. Bibliotheken wie Jieba können chinesischen Text mit einiger Präzision in Wörter zerlegen. Durch das Einbetten der Wort-Tokenisierung in das Modell und das Ausführen auf den gefundenen Korpussen erhielt ich eine BLEU von etwa 0,5 (und die Skala beträgt 100 Punkte).
Kapitel 3. Maschinelle Übersetzung und Offenlegung
Für den Wettbewerb wurde eine offizielle Basis (einfache, aber funktionierende Beispiellösung) vorgeschlagen, die auf OpenMNT basierte . Es ist ein Open-Source-Übersetzungslernwerkzeug mit vielen Hyperparametern zum Verdrehen. Lassen Sie uns in diesem Schritt das Modell trainieren und daraus schließen. Wir werden auf der Kaggle-Plattform trainieren, da dort 40 Stunden GPU-Training kostenlos angeboten werden [4] .
Es sei darauf hingewiesen, dass zu diesem Zeitpunkt so wenige Teilnehmer am Wettbewerb teilnahmen, dass man nach seiner Teilnahme sofort unter die ersten fünf kommen konnte, und es gab Gründe dafür. Das Format der Lösung war ein Docker-Container, in den Ordner während des Inferenzprozesses eingehängt wurden, und das Modell musste von einem lesen und die Antwort in einen anderen einfügen. Da die offizielle Grundlinie nicht begann (ich persönlich habe sie nicht sofort zusammengebaut) und ohne Gewichte war, beschloss ich, meine eigene zu sammeln und sie öffentlich zugänglich zu machen [5]. Danach begannen die Teilnehmer, sich mit der Bitte zu bewerben, eine Lösung korrekt zusammenzustellen und im Allgemeinen mit dem Docker zu helfen. Moralisch, Container sind der Standard in der heutigen Entwicklung, verwenden Sie sie, orchestrieren und vereinfachen Sie Ihr Leben (nicht jeder stimmt der letzten Aussage zu).
Fügen wir nun den im vorherigen Schritt gefundenen Körpern noch ein paar hinzu:
- Parallel Corpus der Vereinten Nationen (3M + Reihen)
- UM-Corpus: Ein großer englisch-chinesischer Parallelkorpus (News subcorpora) (450.000 Zeilen)
Das erste ist ein riesiges Korpus an Rechtsdokumenten von UN-Treffen. Es ist übrigens in allen Amtssprachen dieser Organisation verfügbar und richtet sich nach den Vorschlägen. Das zweite ist noch interessanter, da es sich direkt um ein Nachrichtenkorpus mit einer Besonderheit handelt - es ist Chinesisch-Englisch. Diese Tatsache stört uns nicht, da die moderne maschinelle Übersetzung vom Englischen ins Russische von sehr hoher Qualität ist und Amazon Translate, Google Translate, Bing und Yandex verwendet werden. Der Vollständigkeit halber zeigen wir Beispiele von dem, was passiert ist.
UN-Dokumente
.
它是一个低成本平台运转寿命较长且能在今后进一步发展。
.
报告特别详细描述了由参加者自己拟订的若干与该地区有关并涉及整个地区的项目计划。
UM-Corpus
Facebook hat Anfang Januar den Kaufvertrag für Little Eye Labs abgeschlossen.
1 Eye 脸 书 完成 Eye Eye Little Eye Labs 的 收购 ,
Vier Ingenieure in Bangalore haben Little Eye Labs vor ungefähr anderthalb Jahren ins Leben gerufen.
Das
Unternehmen entwickelt Software-Tools für mobile Apps wird zwischen 10 und 15 Millionen US-Dollar
kosten. 到 万 开发 移动 应用 软件 工具 , 这次 价值 价值 1000 到 1500 万 美元 ,
Also, unsere neuen Zutaten: OpenNMT + hochwertige Gehäuse + BPE (Informationen zur BPE-Tokenisierung finden Sie hier ). Wir trainieren, bauen zu einem Container zusammen und erhalten nach dem Debuggen / Reinigen und Standardtricks BLEU 6.0 (die Skala beträgt immer noch 100 Punkte).
Kapitel 4. Parallele Manuskripte brennen nicht
Bis zu diesem Punkt haben wir unser Modell Schritt für Schritt verbessert, und der größte Gewinn wurde durch die Verwendung des Nachrichtenkorpus erzielt, einer der Validierungsdomänen. Neben Nachrichten wäre es schön, eine Menge Literatur zu haben. Nach einiger Zeit wurde klar, dass die maschinellen Übersetzungen chinesischer Bücher ohne populäres System nicht liefern können - Nastasia wird so etwas wie Nostosi Filipauny und Rogozhin - Rogo Wren . Die Namen der Charaktere machen normalerweise einen ziemlich großen Prozentsatz der gesamten Arbeit aus, und oft sind diese Namen selten. Wenn das Modell sie daher noch nie gesehen hat, kann es sie höchstwahrscheinlich nicht richtig übersetzen. Wir müssen aus Büchern lernen.
Hier ersetzen wir die Aufgabe der Übersetzung durch die Aufgabe der Textausrichtung. Ich muss sofort sagen, dass mir dieser Teil am besten gefallen hat, weil ich selbst gerne Sprachen und parallele Texte von Büchern und Geschichten studiere. Meiner Meinung nach ist dies eine der produktivsten Arten zu lernen. Es gab mehrere Ideen für die Ausrichtung. Die produktivste war, Sätze in den Vektorraum zu übersetzen und den Kosinusabstand zwischen Kandidaten für die Konformität zu berechnen. Das Übersetzen von etwas in Vektoren wird als Einbettung bezeichnet. In diesem Fall handelt es sich um eine Satzeinbettung . Zu diesem Zweck gibt es mehrere gute Bibliotheken [6] . Bei der Visualisierung des Ergebnisses ist zu erkennen, dass der chinesische Text etwas abrutscht, da komplexe Sätze auf Russisch häufig als zwei oder drei auf Chinesisch übersetzt werden.
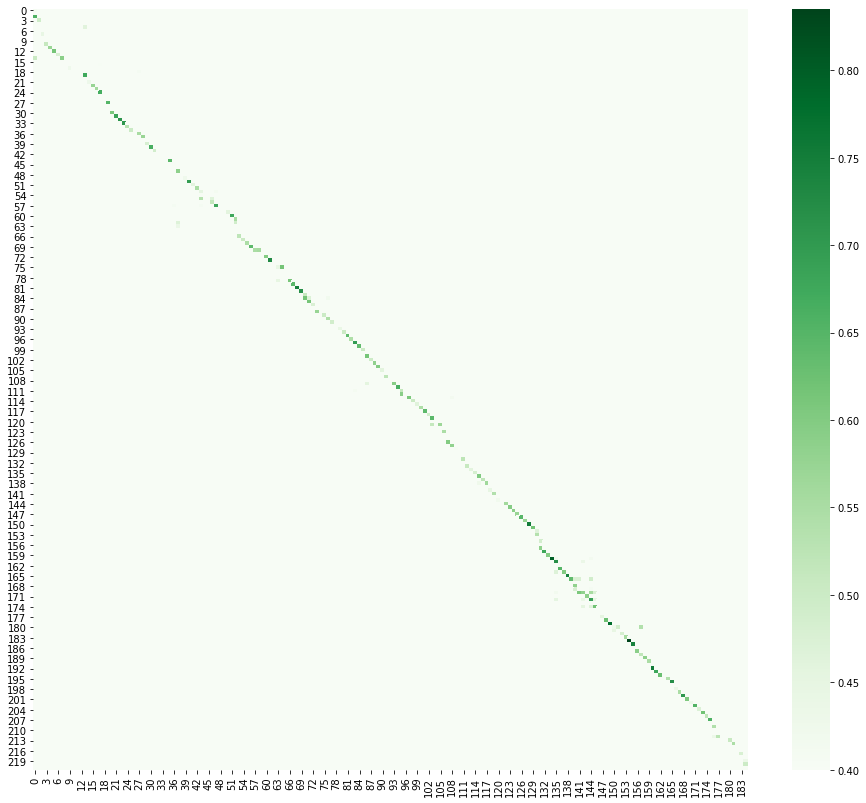
Nachdem wir im Internet alles Mögliche gefunden und die Bücher selbst geebnet haben, fügen wir sie unserem Korpus hinzu.
Er trug einen teuren grauen Anzug und fremde Schuhe in
Kostümfarbe.
Grau nimmt es berühmt am Ohr unter den Arm und trägt einen Stock mit einem schwarzen mit einem pudelförmigen Knopf
.
Sie sieht mehr als vierzig Jahre alt aus.
看 模样 年纪 在 四十 开外。
Nach der Schulung des neuen Gebäudes wuchs BLEU in einem öffentlichen Datensatz auf 20 und in einem privaten auf 19,7. Es spielte auch die Rolle der Tatsache, dass Arbeiten aus der Validierung offensichtlich in das Training kamen. In der Realität sollte dies niemals getan werden, es wird als Leck bezeichnet, und die Metrik ist nicht mehr indikativ.
Fazit
Die maschinelle Übersetzung hat einen langen Weg von Heuristiken und statistischen Methoden zu neuronalen Netzen und Transformatoren zurückgelegt. Ich bin froh, dass ich die Zeit gefunden habe, mich mit diesem Thema vertraut zu machen. Es verdient definitiv die Aufmerksamkeit der Community. Ich möchte den Autoren des Wettbewerbs und anderen Teilnehmern für die interessante Kommunikation und die neuen Ideen danken!
[1] Parallele russisch-chinesische Korpora
[2] Kurs über die Verarbeitung natürlicher Sprache von MIPT
[3] Durchbruchartikel Aufmerksamkeit ist alles, was Sie brauchen.
[4] Laptop mit einem Beispiel für das Erlernen von Kaggle.
[5] Öffentliche Docker-Grundlinie.
[6] Bibliothek für mehrsprachige Sätze Einbettungen