Google Sheets → Node.js → Google Charts → Visitenkarten-Site → Top-3 in der Suche Vollständiger Name + Spezialisierung
Aufgrund der Daten in der Tabelle habe ich beschlossen, die Visitenkarten-Site mit Informationen zu Veröffentlichungen zu ergänzen, die automatisch generiert werden. Was ich bekommen wollte:
- Eine aktuelle Zusammenfassung der Veröffentlichungen in der Google Charts-Zeitleiste .
- Automatische Generierung von Ausgabedaten und Links zu Artikeln aus einer Google-Tabelle in eine HTML-Version einer Visitenkarte.
- PDF-Versionen von Artikeln von allen Websites, da Bedenken hinsichtlich der Schließung einiger älterer Websites in der Zukunft bestehen.
Sie können hier sehen, wie es passiert ist . Implementiert auf der Node.js-Plattform mithilfe von Bootstrap, Google Charts und Google Sheets zum Speichern von Rohdaten.
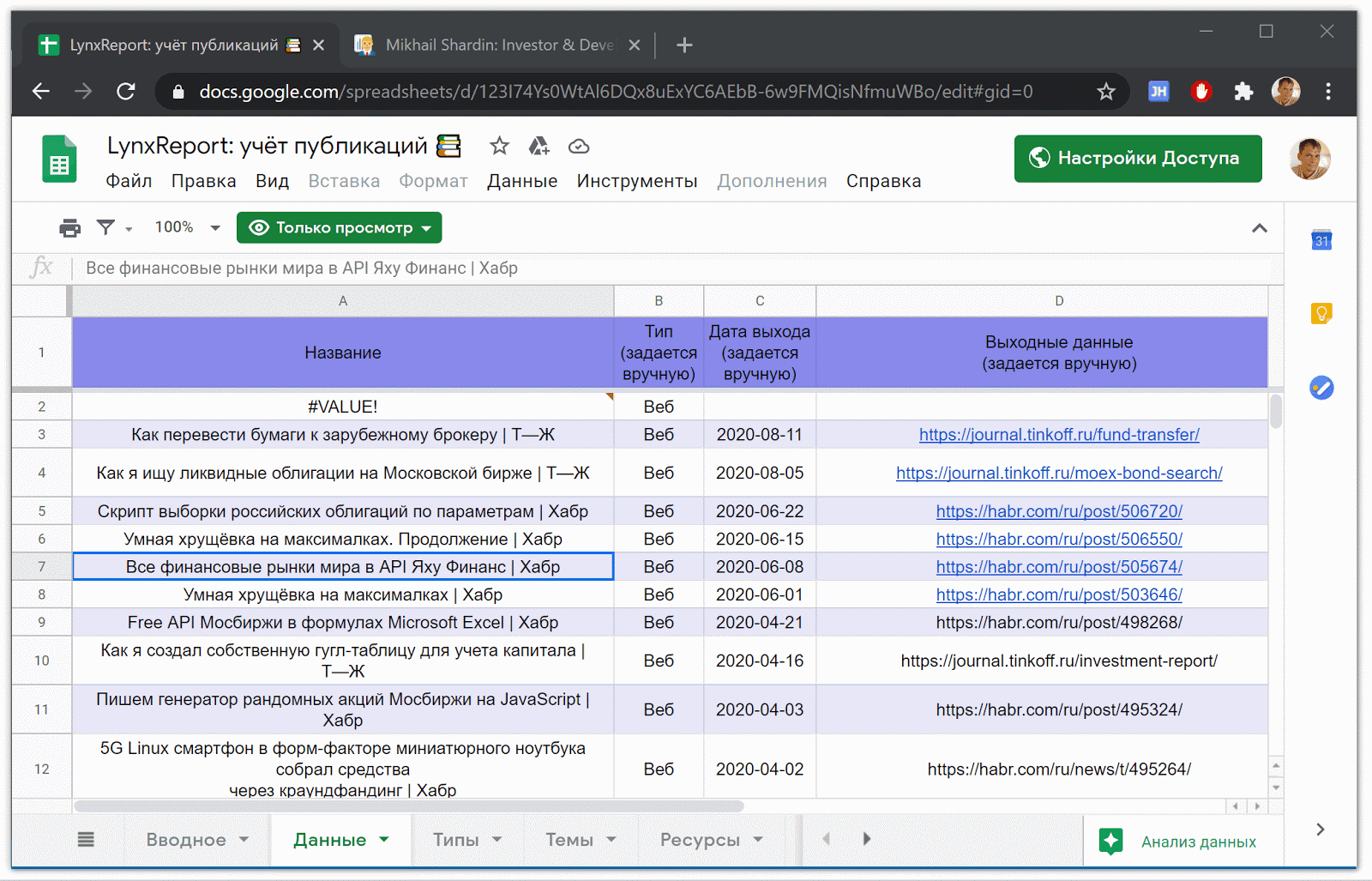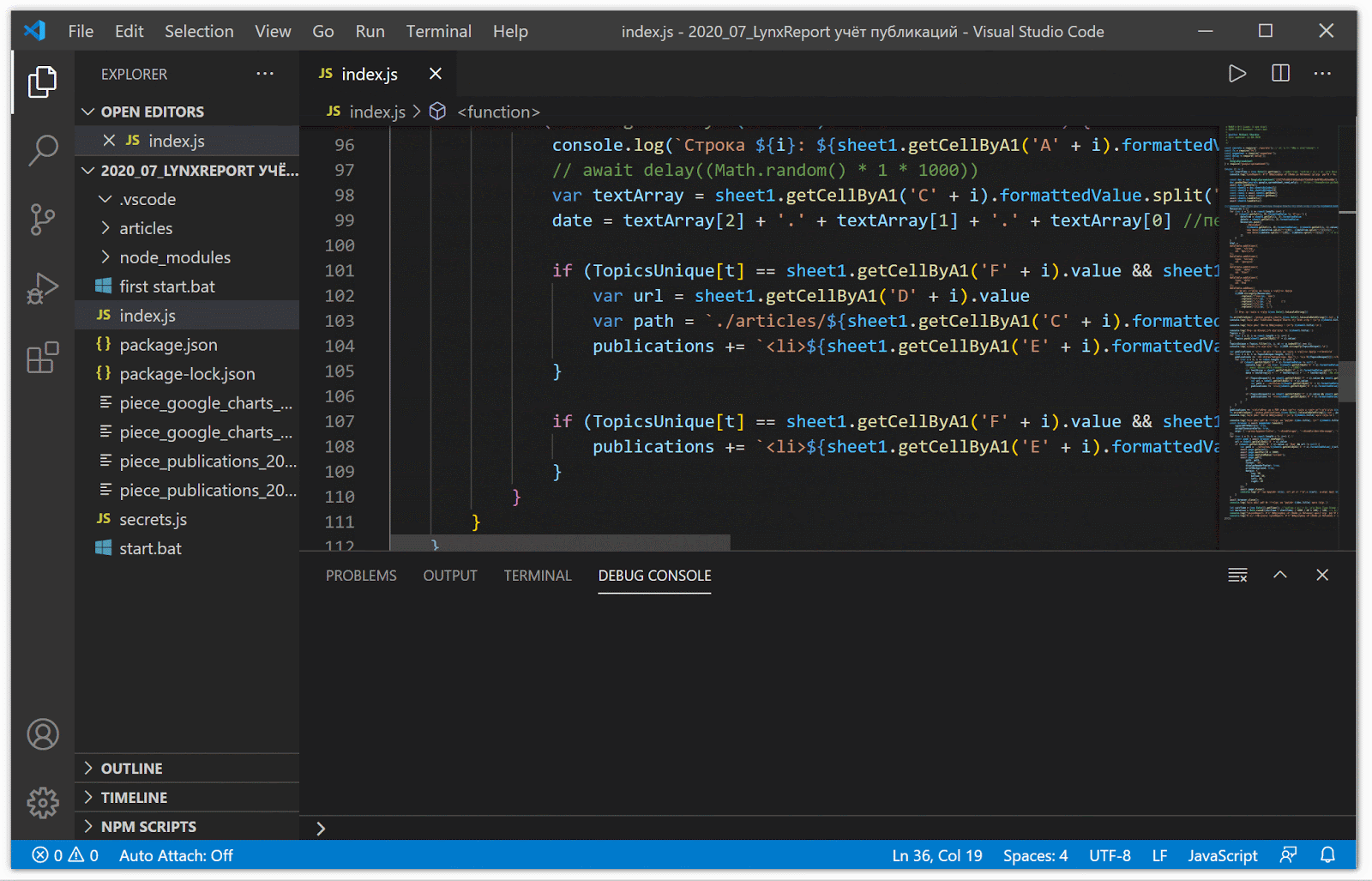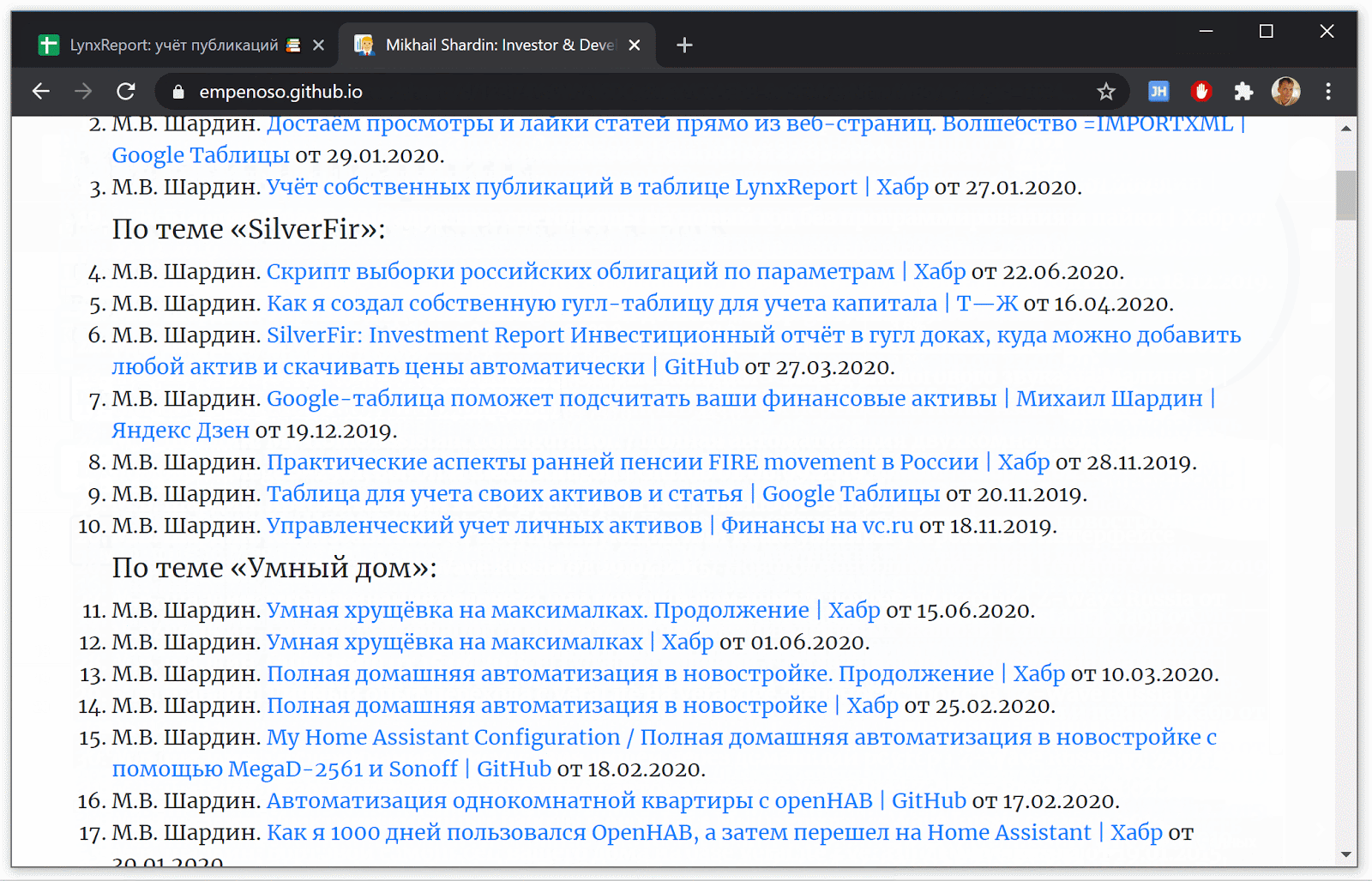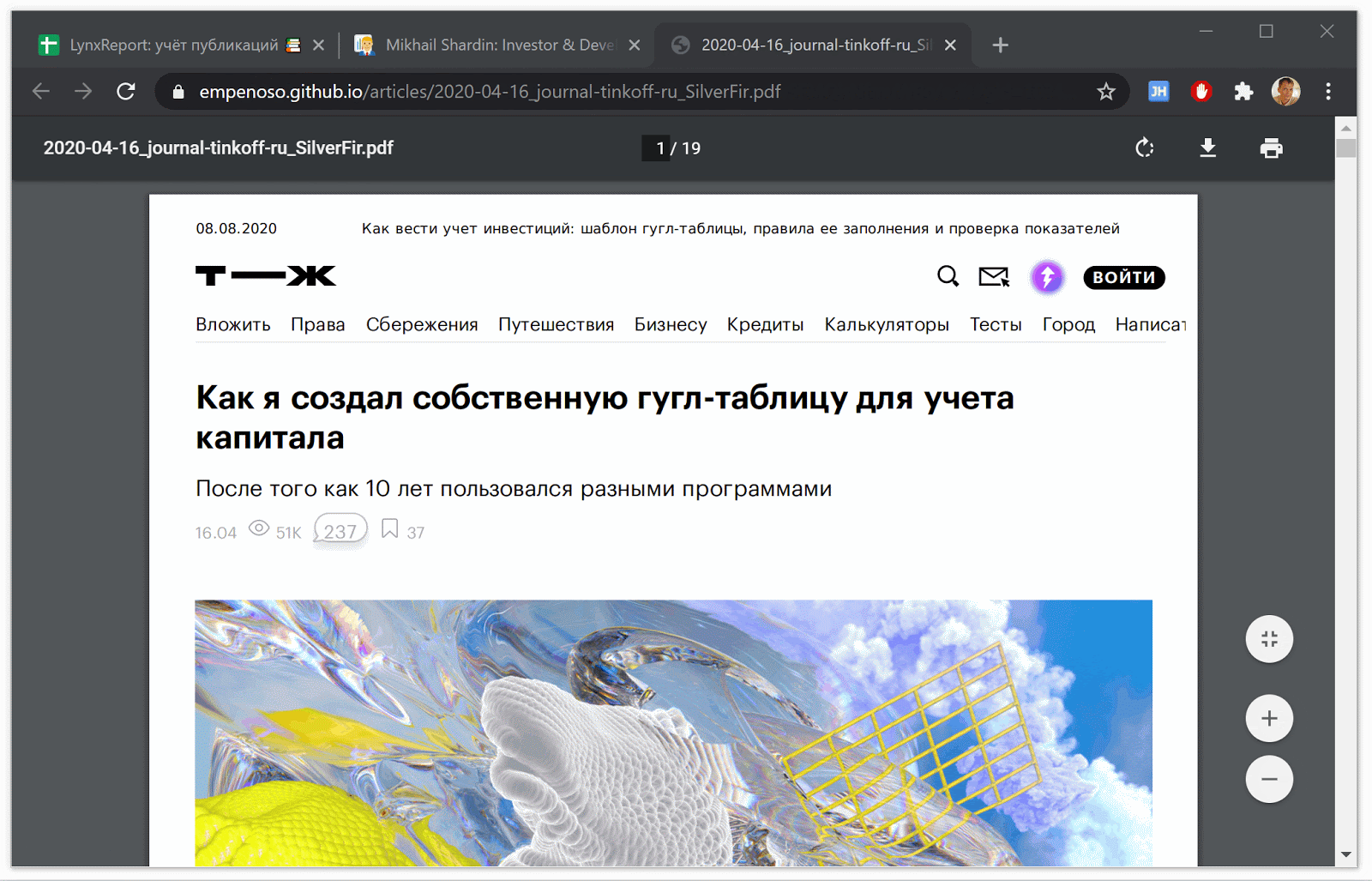
Rohdaten zu Veröffentlichungen in Google Spreadsheet
Google Spreadsheet LynxReport: Die Publikationsbuchhaltung enthält alle Quelldaten und Analysen für Publikationen. Ich halte die Informationen auf der Registerkarte "Daten" auf dem neuesten Stand, indem ich manuell neue Links zu Artikeln eingebe. Der Rest wird größtenteils automatisch heruntergeladen.
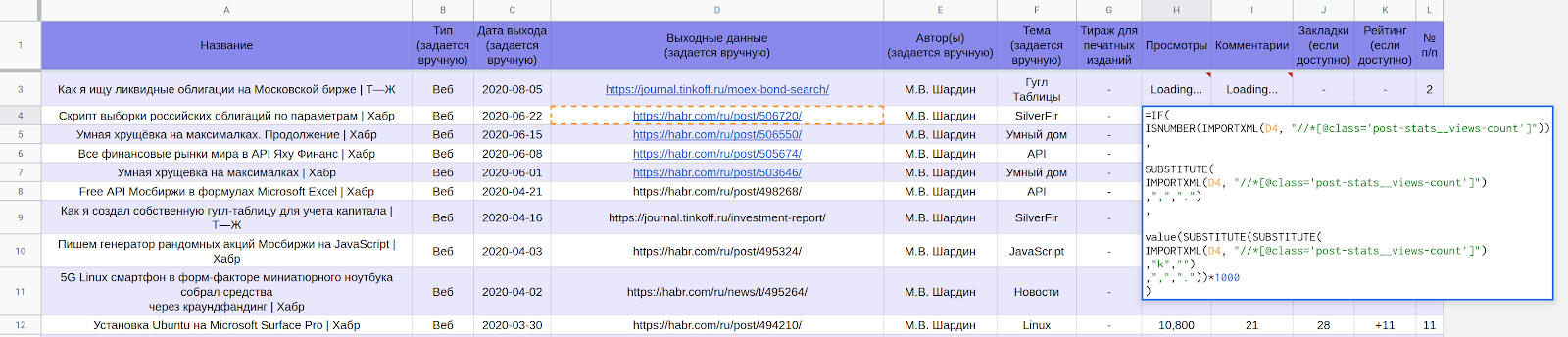
Teil der LynxReport- Tabelle : Berücksichtigung von Veröffentlichungen mit Anfangsdaten
Aktuelle Daten zu Ansichten und Kommentaren werden über Formeln geladen.
Verwenden Sie beispielsweise die folgende Formel, um die Anzahl der Aufrufe von Habr-Seiten in einer Zelle von Google-Tabellen abzurufen:
=IF(
ISNUMBER(IMPORTXML(D6, "//*[@class='post-stats__views-count']"))
,
SUBSTITUTE(
IMPORTXML(D6, "//*[@class='post-stats__views-count']")
,",",".")
,
value(SUBSTITUTE(SUBSTITUTE(
IMPORTXML(D6, "//*[@class='post-stats__views-count']")
,"k","")
,",","."))*1000
)
Formeln sind nicht die schnellste Option und Sie müssen ungefähr eine halbe Stunde warten, um mehrere hundert Positionen zu erhalten. Nach Abschluss des Downloads sehen Sie alle Zahlen wie im folgenden Screenshot. Sie geben Antworten darauf, welche Themen beliebt sind und welche nicht.

Teil der LynxReport- Tabelle : Posten mit Analyse
Lesen von Daten aus einer Tabelle und Konvertieren in das Google Charts-Format
Um diese Pivot-Daten aus einer Google-Tabelle in eine Visitenkarten-Website umzuwandeln , musste ich die Daten in das Google Charts-Zeitleistenformat konvertieren .

Die resultierende Zeitleiste von Google Charts auf der Visitenkarten-Website
Um ein solches Diagramm korrekt zu zeichnen, müssen die Daten wie folgt organisiert sein:

Daten für Google Charts auf der Visitenkarten-Website in HTML-Form
Um alle Transformationen automatisch durchzuführen, habe ich ein Skript unter Node.js geschrieben, das verfügbar ist auf GitHub .
Wenn Sie mit Node.js nicht vertraut sind, habe ich in meinem vorherigen Artikel ausführlich beschrieben, wie Sie das Skript unter verschiedenen Systemen verwenden können:
- Windows
- Mac OS
- Linux
Link mit Anweisungen hier . Das Prinzip ist ähnlich.

Die Arbeit des Skripts zum Konvertieren in das gewünschte Datenformat und zum Generieren von PDF-Versionen von Artikeln von Websites (alle Zeilen werden sofort verarbeitet - ich habe absichtlich eine Verzögerung für die Aufzeichnung dieses Videos festgelegt)
Um Daten aus der Google-Tabelle im automatischen Modus zu lesen, verwende ich die Schlüsselautorisierung .
Sie erhalten diesen Schlüssel in der Google Project Management Console : Anmeldeinformationen

in der Google Cloud Platform.
Nach Abschluss des Skripts sollten zwei Textdateien mit HTML-Daten der Grafiken und allen PDF-Kopien von Online-Artikeln generiert werden.
Ich importiere Daten aus Textdateien in den HTML-Code der Visitenkarten-Site.
Generierung von PDF-Kopien von Artikeln von Websites
Mit Hilfe von Puppeteer speichere ich die aktuelle Ansicht der Artikel zusammen mit allen Kommentaren im PDF-Format.
Wenn Sie keine Verzögerung festlegen, können mehrere Dutzend Artikel in der Liste in wenigen Minuten als PDF-Dateien gespeichert werden.
Die Verzögerung ist erforderlich, damit Kommentare auf einigen Websites geladen werden können ( z. B. auf - ).
Ergebnisse
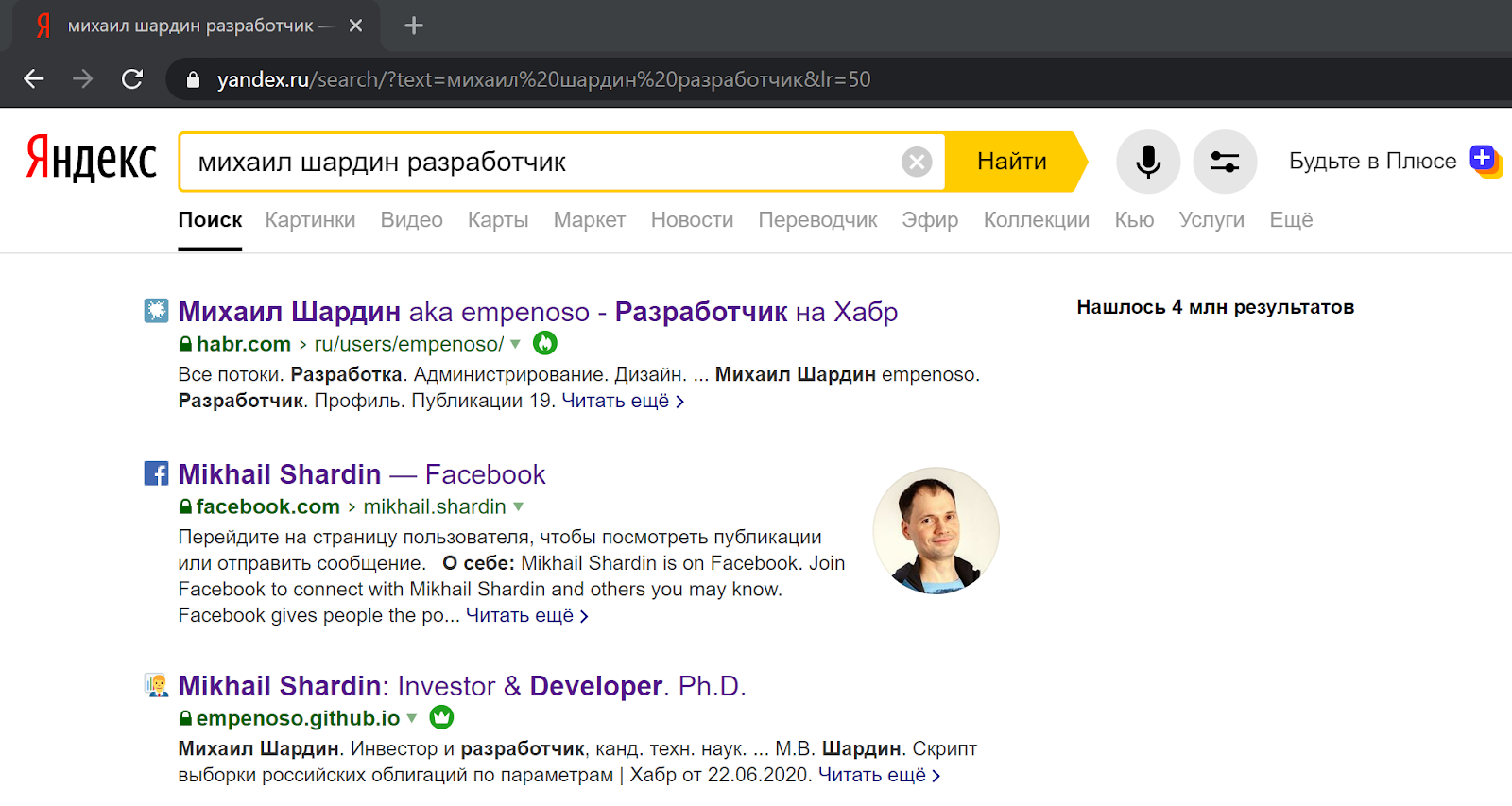
Da mit dem Schreiben des Skripts begonnen wurde, um den Suchalgorithmen besser zu entsprechen, können Sie die Ergebnisse mithilfe der Suche auswerten.
Die Suche nach Vor- und Nachnamen + Angabe der Spezialisierung gibt in beiden Fällen Links zu meinen Artikeln und sogar zu einer Visitenkarten-Website zurück:
In Yandex- Suchergebnissen :
In Google-Suchergebnissen :

Bisher kann ich nicht entscheiden, ob ein separater Domainname registriert werden soll, wenn die Visitenkarte empenoso.github.io lautet und so ist es in den obersten Zeilen der Suche?
Anstelle einer Schlussfolgerung
- Vielleicht lässt dieser Artikel jemanden darüber nachdenken, wie er im Internet aussieht.
- Vielleicht hilft dieser Artikel jemandem, die Buchhaltung und Organisation von Veröffentlichungen zu etablieren.
- Der Quellcode für das Skript befindet sich auf GitHub .
Von: Mikhail Shardin
17. August 2020