Einführung
Hallo Habr!
Viele Leute mochten den vorherigen Teil, also schaufelte ich wieder die Hälfte der Boost-Dokumentation und fand etwas zum Schreiben. Es ist sehr seltsam, dass es bei boost.compute keine solche Aufregung gibt wie bei boost.asio. Schließlich ist diese Bibliothek plattformübergreifend und bietet auch eine bequeme (im Rahmen von c ++) Schnittstelle für die Interaktion mit parallelem Computing auf der GPU und der CPU.
Alle Teile
- Teil 1
- Teil 2
Inhalt
- Asynchrone Operationen
- Benutzerdefinierte Funktionen
- Vergleich der Geschwindigkeit verschiedener Geräte in verschiedenen Modi
- Fazit
Asynchrone Operationen
Es würde viel schneller scheinen? Eine Möglichkeit, Ihre Arbeit mit Containern im Compute-Namespace zu beschleunigen, ist die Verwendung asynchroner Funktionen. Boost.compute bietet uns verschiedene Tools. Von diesen die compute :: future-Klasse zur Steuerung der Verwendung von Funktionen und die Funktionen copy_async (), fill_async () zum Kopieren oder Füllen des Arrays. Natürlich gibt es auch Tools für die Arbeit mit Ereignissen, aber Sie müssen sie nicht berücksichtigen. Das Folgende ist ein Beispiel für die Verwendung aller oben genannten Funktionen:
auto device = compute::system::default_device();
auto context = compute::context::context(device);
auto queue = compute::command_queue(context, device);
std::vector<int> vec_std = {1, 2, 3};
compute::vector<int> vec_compute(vec_std.size(), context);
compute::vector<int> for_filling(10, context);
int num_for_fill = 255;
compute::future<void> filling = compute::fill_async(for_filling.begin(),
for_filling.end(), num_for_fill, queue); //
compute::future<void> copying = compute::copy_async(vec_std.begin(),
vec_std.end(), vec_compute.begin(), queue); //
filling.wait();
copying.wait();
Hier gibt es nichts Besonderes zu erklären. Die ersten drei Zeilen sind die Standardinitialisierung der erforderlichen Klassen, dann zwei Vektoren zum Kopieren, ein Vektor zum Füllen, dessen Variable den vorherigen Vektor füllt, und direkt die Funktionen zum Füllen bzw. Kopieren. Dann warten wir auf ihre Hinrichtung.
Für diejenigen, die mit std :: future von STL gearbeitet haben, ist hier alles gleich, nur in einem anderen Namespace und es gibt kein Analogon zu std :: async ().
Benutzerdefinierte Funktionen für Berechnungen
Im vorherigen Teil habe ich erklärt, dass ich erklären werde, wie ich meine eigenen Methoden zum Verarbeiten eines Datensatzes verwende. Ich habe 3 Möglichkeiten gezählt, um dies zu tun: Verwenden Sie ein Makro, verwenden Sie make_function_from_source <> () und verwenden Sie ein spezielles Framework für Lambda-Ausdrücke.
Ich beginne mit der allerersten Option - einem Makro. Zuerst werde ich einen Beispielcode anhängen und dann erklären, wie es funktioniert.
BOOST_COMPUTE_FUNCTION(float,
add,
(float x, float y),
{ return x + y; });
Das erste Argument ist der Typ des Rückgabewerts, dann der Name der Funktion, ihre Argumente und der Hauptteil der Funktion. Weiter unter dem Namen add kann diese Funktion beispielsweise in der Funktion compute :: transform () verwendet werden. Die Verwendung dieses Makros ist einem regulären Lambda-Ausdruck sehr ähnlich, aber ich habe überprüft, dass sie nicht funktionieren.
Die zweite und wahrscheinlich schwierigste Methode ist der ersten sehr ähnlich. Ich habe mir den Code des vorherigen Makros angesehen und es stellte sich heraus, dass es die zweite Methode verwendet.
compute::function<float(float)> add = compute::make_function_from_source<float(float)>
("add", "float add(float x, float y) { return x + y; }");
Hier ist alles offensichtlicher, als es auf den ersten Blick scheinen mag. Die Funktion make_function_from_source () verwendet nur zwei Argumente, von denen eines der Name der Funktion und das zweite die Implementierung ist. Nachdem eine Funktion deklariert wurde, kann sie auf dieselbe Weise wie nach einer Makroimplementierung verwendet werden.
Nun, die letzte Option ist ein Lambda-Ausdrucks-Framework. Anwendungsbeispiel:
compute::transform(com_vec.begin(),
com_vec.end(),
com_vec.begin(),
compute::_1 * 2,
queue);
Als viertes Argument geben wir an, dass wir jedes Element aus dem ersten Vektor mit 2 multiplizieren möchten. Alles ist recht einfach und erfolgt an Ort und Stelle.
Boolesche Ausdrücke können auf die gleiche Weise angegeben werden. Zum Beispiel in der Methode compute :: count_if ():
std::vector<int> source_std = { 1, 2, 3 };
compute::vector<int> source_compute(source_std.begin() ,source_std.end(), queue);
auto counter = compute::count_if(source_compute.begin(),
source_compute.end(),
compute::lambda::_1 % 2 == 0,
queue);
Wir haben also alle geraden Zahlen im Array gezählt, der Zähler ist gleich eins.
Vergleich der Geschwindigkeit verschiedener Geräte in verschiedenen Modi
Nun, das Letzte, worüber ich in diesem Artikel schreiben möchte, ist ein Vergleich der Verarbeitungsgeschwindigkeit auf verschiedenen Geräten und in verschiedenen Modi (nur für die CPU). Dieser Vergleich wird beweisen, wann es sinnvoll ist, GPUs für das Rechnen und das parallele Rechnen im Allgemeinen zu verwenden.
Ich werde wie folgt testen: Mit compute für alle Geräte werde ich die Funktion compute :: sort () aufrufen, um ein Array von 100 Millionen Float-Werten zu sortieren. Rufen Sie zum Testen des Single-Threaded-Modus std :: sort für ein Array derselben Größe auf. Für jedes Gerät werde ich die Zeit in Millisekunden unter Verwendung der Chrono-Standardbibliothek notieren und alles an die Konsole ausgeben.
Das Ergebnis ist das Folgende:

Jetzt werde ich dasselbe nur für tausend Werte tun. Diesmal wird die Zeit in Mikrosekunden angegeben.

Diesmal war der Prozessor im Single-Threaded-Modus allen voraus. Daraus schließen wir, dass sich diese Art von Operation nur lohnt, wenn es um wirklich große Datenmengen geht.
Ich würde gerne noch einige Tests durchführen, also machen wir einen Test zur Berechnung von Kosinus, Quadratwurzel und Quadratur.
Bei der Berechnung des Cosinus ist der Unterschied sehr groß (die GPU läuft 60-mal schneller als die CPU in einem Thread).
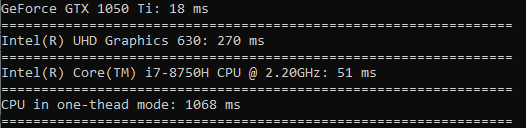
Die Quadratwurzel wird mit fast der gleichen Geschwindigkeit wie die Sortierung berechnet.
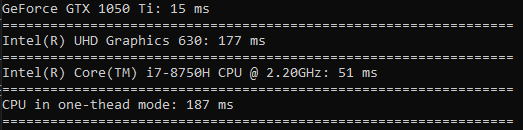
Der Zeitaufwand für das Quadrieren ist noch geringer als beim Sortieren (die GPU ist nur 3,5-mal schneller).

Fazit
Nachdem Sie diesen Artikel gelesen haben, haben Sie gelernt, wie Sie mit asynchronen Funktionen Arrays kopieren und füllen. Wir haben gelernt, wie Sie Ihre eigenen Funktionen verwenden können, um Berechnungen für Daten durchzuführen. Und auch klar gesehen, wann es sich lohnt, eine GPU oder CPU für paralleles Rechnen zu verwenden und wann man mit einem Thread auskommt.
Ich würde mich über positives Feedback freuen, danke für Ihre Zeit!
Allen viel Glück!