1 Was ist das Voynich-Manuskript?
Das Voynich-Manuskript ist ein mysteriöses Manuskript (Kodex, Manuskript oder nur ein Buch) auf gut 240 Seiten, das vermutlich aus dem 15. Jahrhundert zu uns kam. Das Manuskript wurde 1912 versehentlich von einem Antiquar vom Ehemann des berühmten karbonischen Schriftstellers Ethel Voynich - Wilfred Voynich - erworben und ging bald in den Besitz der Öffentlichkeit über.
Die Sprache des Manuskripts ist noch nicht festgelegt. Eine Reihe von Forschern des Manuskripts schlagen vor, dass der Text des Manuskripts verschlüsselt ist. Andere sind sich sicher, dass das Manuskript in einer Sprache verfasst wurde, die in den uns heute bekannten Texten nicht erhalten geblieben ist. Wieder andere halten das Voynich-Manuskript für Unsinn (siehe die moderne Hymne an den Absurdismus Codex Seraphinianus ).
Als Beispiel werde ich ein gescanntes Fragment eines Themas mit Text und Nymphen geben:

2 Warum ist dieses ausgefallene Manuskript so interessant?
Vielleicht ist das eine späte Fälschung? Scheinbar nicht. Im Gegensatz zum Turiner Grabtuch haben weder die Radiokohlenstoffanalyse noch andere Versuche, die Antike des Pergaments zu bestreiten, bisher eine eindeutige Antwort gegeben. Aber Voynich hätte zu Beginn des 20. Jahrhunderts keine Isotopenanalyse vorhersehen können ...
Aber was ist, wenn das Manuskript eine bedeutungslose Reihe von Buchstaben aus der Feder eines verspielten Mönchs ist, eines Adligen in einem veränderten Bewusstsein? Nein, definitiv nicht. Wenn ich zum Beispiel gedankenlos auf die Tasten klopfe , werde ich das bekannte modulierte weiße Rauschen der QWERTZ-Tastatur wie „ asfds dsf”. Eine grafische Untersuchung zeigt, dass der Autor die ihm bekannten Symbole des Alphabets mit fester Hand geschrieben hat. Außerdem entsprechen die Korrelationen der Verteilung von Buchstaben und Wörtern im Text des Manuskripts dem „lebenden“ Text. Zum Beispiel gibt es in einem Manuskript, das bedingt in 6 Abschnitte unterteilt ist, Wörter - "endemisch" -, die häufig in einem der Abschnitte vorkommen, in anderen jedoch fehlen.
Was aber, wenn das Manuskript eine komplexe Chiffre ist und Versuche, es zu brechen, theoretisch bedeutungslos sind? Wenn wir dem ehrwürdigen Alter des Textes Glauben schenken, ist die Verschlüsselungsversion äußerst unwahrscheinlich. Das Mittelalter hätte nur eine Ersatzchiffre anbieten können, die Edgar Allan Poe so leicht und elegant brach . Auch hier ist die Korrelation von Buchstaben und Wörtern des Textes für die überwiegende Mehrheit der Chiffren nicht typisch.
Trotz der kolossalen Erfolge bei der Übersetzung alter Skripte, auch unter Verwendung moderner Computerressourcen, trotzt das Voynich-Manuskript immer noch erfahrenen professionellen Linguisten oder jungen, ehrgeizigen Datenwissenschaftlern.
3 Was aber, wenn uns die Sprache des Manuskripts bekannt ist?
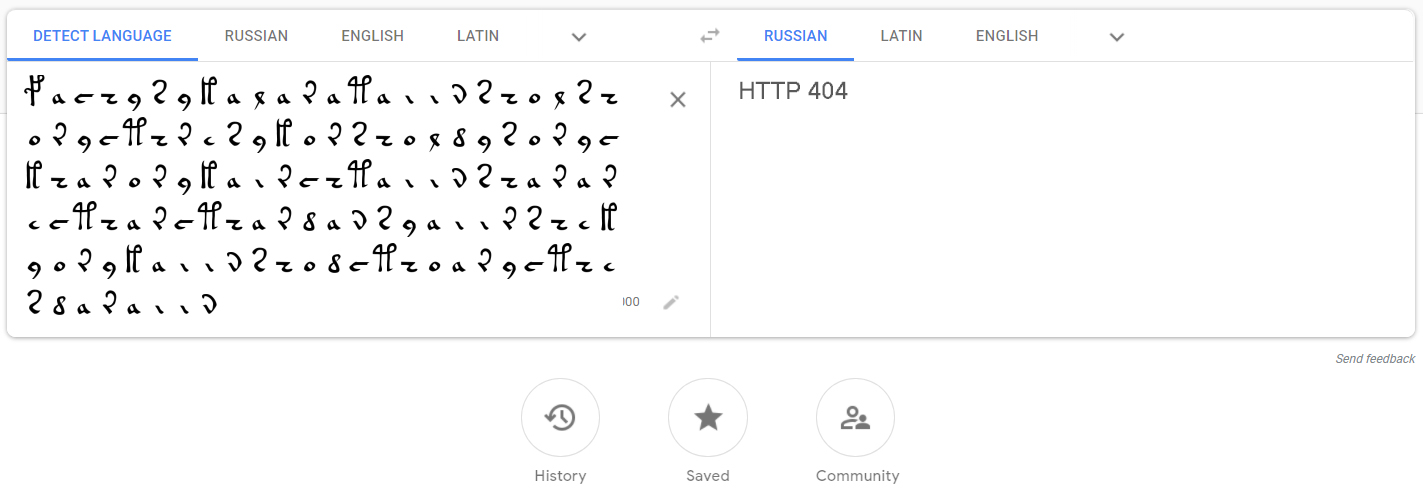
... aber die Schreibweise ist anders? Wer erkennt zum Beispiel Latein in diesem Text ?

Und hier ist ein weiteres Beispiel - Transliteration eines englischen Textes ins Griechische:
in one of the many little suburbs which cling to the outskirts of london
ιν ονε οφ θε μανυ λιττλε συμπυρμπσ whιχ cλιγγ το θε ουτσκιρτσ οφ λονδονPythons Transliterate- Bibliothek . NB: Dies ist keine Substitutions-Chiffre mehr. Einige Mehrbuchstabenkombinationen werden in einem Buchstaben übertragen und umgekehrt.
Ich werde versuchen, die Sprache des Manuskripts zu identifizieren (zu klassifizieren) oder aus den bekannten Sprachen den nächstgelegenen zu finden, die charakteristischen Merkmale hervorzuheben und das Modell darauf zu trainieren:
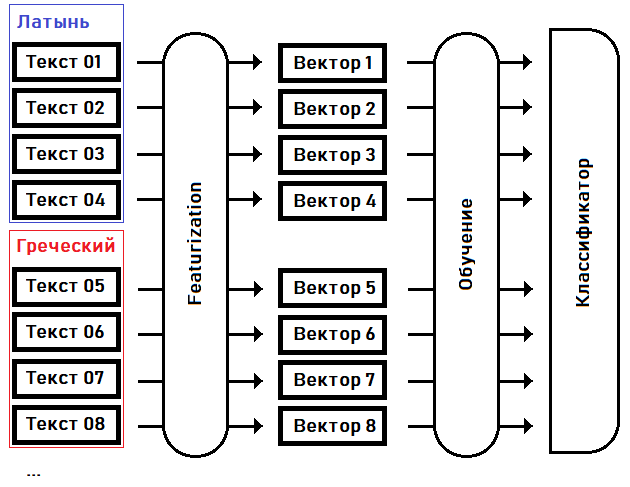
In der ersten Phase - Featurisierung- Wir verwandeln Texte in Merkmalsvektoren: Arrays mit reellen Zahlen fester Größe, wobei jede Dimension des Vektors für ihre eigene Besonderheit (Merkmal) des Quelltextes verantwortlich ist. Lassen Sie uns zum Beispiel in der 15. Dimension des Vektors vereinbaren, die Häufigkeit des häufigsten Wortes im Text beizubehalten, in der 16. Dimension - dem zweitbeliebtesten Wort ... in der N-ten Dimension - der längsten Länge einer Folge desselben wiederholten Wortes usw.
Im zweiten Schritt - Training - wählen wir die Koeffizienten des Klassifikators basierend auf den Vorkenntnissen der Sprache jedes Textes aus.
Sobald der Klassifikator trainiert ist, können wir dieses Modell verwenden, um die Sprache des Textes zu bestimmen, der nicht im Trainingsbeispiel enthalten war. Zum Beispiel für den Text des Voynich-Manuskripts.
4 Das Bild ist so einfach - was ist der Haken?
Der schwierige Teil ist, wie genau eine Textdatei in einen Vektor umgewandelt wird. Trennen Sie die Spreu vom Weizen und lassen Sie nur die Merkmale übrig, die für die gesamte Sprache charakteristisch sind, und nicht jeden spezifischen Text.
Wenn Sie zur Vereinfachung die Quelltexte in Codierung (dh Zahlen) umwandeln und diese Daten einem der vielen neuronalen Netzwerkmodelle „zuführen“, wird uns das Ergebnis wahrscheinlich nicht gefallen. Höchstwahrscheinlich wird ein Modell, das auf solchen Daten trainiert ist, an das Alphabet gebunden sein und auf der Grundlage von Symbolen zunächst versuchen, die Sprache eines unbekannten Textes zu bestimmen.
Aber das Alphabet des Manuskripts "hat keine Analoga." Darüber hinaus können wir uns bei der Verteilung von Buchstaben nicht vollständig auf Muster verlassen. Theoretisch ist es auch möglich, die Phonetik einer Sprache nach den Regeln einer anderen zu übertragen (die Sprache ist Elbisch - und die Runen sind Mordor).
Der listige Schreiber verwendete keine Satzzeichen oder Zahlen, wie wir sie kennen. Der gesamte Text kann als ein Strom von Wörtern betrachtet werden, die in Absätze unterteilt sind. Ich bin mir nicht einmal sicher, wo ein Satz endet und ein anderer beginnt.
Dies bedeutet, dass wir in Bezug auf Buchstaben auf eine höhere Ebene aufsteigen und uns auf Wörter verlassen werden. Wir werden ein Wörterbuch basierend auf dem Text des Manuskripts zusammenstellen und die Muster verfolgen, die sich bereits auf Wortebene befinden.
5 Originaltext des Manuskripts
Natürlich müssen Sie die komplizierten Zeichen des Voynich-Manuskripts nicht in ihre Unicode-Entsprechungen kodieren und umgekehrt - diese Arbeit wurde zum Beispiel hier bereits für uns erledigt . Mit den Standardoptionen erhalte ich das folgende Äquivalent zur ersten Zeile des Manuskripts:
fachys.ykal.ar.ataiin.shol.shory.cth!res.y.kor.sholdy!-Punkte und Ausrufezeichen (sowie eine Reihe anderer Symbole des EVA- Alphabets ) sind nur Trennzeichen, die für unsere Zwecke durch Leerzeichen ersetzt werden können. Fragezeichen und Sternchen sind nicht erkannte Wörter / Buchstaben.
Ersetzen Sie zur Überprüfung den Text hier und erhalten Sie ein Fragment des Manuskripts:
6 Programm - Textklassifikator (Python)
Hier ist ein Link zum Code-Repository mit den minimalen README-Hinweisen, die Sie zum Testen des Codes in Aktion benötigen.
Ich habe mehr als 20 Texte in Latein, Russisch, Englisch, Polnisch und Griechisch gesammelt und versucht, das Volumen jedes Textes in ± 35.000 Wörtern (das Volumen des Voynich-Manuskripts) zu halten.
Ich habe versucht, eine enge Datierung in den Texten in einer Schreibweise zu wählen - zum Beispiel in russischsprachigen Texten habe ich den Buchstaben Ѣ vermieden, und die Varianten des Schreibens griechischer Buchstaben mit unterschiedlichen diakritischen Zeichen führten zu einem gemeinsamen Nenner. Ich habe auch Zahlen und Specials aus den Texten entfernt. Zeichen, zusätzliche Leerzeichen, konvertierte Buchstaben in einen Fall.
Der nächste Schritt besteht darin, ein "Wörterbuch" zu erstellen, das Informationen enthält wie:
- Häufigkeit der Verwendung jedes Wortes im Text (Texte),
- Die "Wurzel" eines Wortes - oder vielmehr ein unveränderlicher, gemeinsamer Teil für eine Reihe von Wörtern,
- gemeinsame "Präfixe" und "Endungen" - oder vielmehr der Anfang und das Ende von Wörtern, zusammen mit der "Wurzel", die die eigentlichen Wörter bildet,
- gemeinsame Sequenzen von 2 und 3 identischen Wörtern und die Häufigkeit ihres Auftretens.
Ich habe die „Wurzel“ des Wortes in Anführungszeichen gesetzt - ein einfacher Algorithmus (und manchmal auch ich selbst) kann beispielsweise nicht bestimmen, wo die Wurzel der Wortunterstützung liegt. Durch immer ka? Unter der Rate ?
Im Allgemeinen handelt es sich bei diesem Vokabular um halb aufbereitete Daten zum Erstellen eines Merkmalsvektors. Warum habe ich diese Phase herausgegriffen - Wörterbücher für einzelne Texte und für eine Reihe von Texten für jede der Sprachen zusammengestellt und zwischengespeichert? Tatsache ist, dass die Erstellung eines solchen Wörterbuchs lange dauert, etwa eine halbe Minute für jede Textdatei. Und ich habe bereits über 120 Textdateien.
7 Featurization
Das Erhalten eines Merkmalsvektors ist nur eine Vorstufe für die weitere Magie des Klassifikators. Als OOP-Freak habe ich natürlich eine abstrakte BaseFeaturizer- Klasse für die Upstream-Logik erstellt, um das Prinzip der Abhängigkeitsinversion nicht zu verletzen . Diese Klasse hinterlässt Nachkommen, um eine oder mehrere Textdateien gleichzeitig in numerische Vektoren umwandeln zu können.
Außerdem muss die Vererbungsklasse jedem einzelnen Merkmal (i-Koordinate des Merkmalsvektors) einen Namen geben. Dies ist nützlich, wenn wir uns entscheiden, die Maschinenlogik der Klassifizierung zu visualisieren. Beispielsweise wird die 0. Dimension des Vektors als CRw1 markiert - Autokorrelation der Häufigkeit von Wörtern, die an der benachbarten Position aus dem Text entnommen wurden (mit Verzögerung 1).
Von der BaseFeaturizer- Klasse habe ich die Klasse geerbtWordMorphFeaturizer , dessen Logik auf der Häufigkeit der Verwendung von Wörtern im gesamten Text und innerhalb eines Schiebefensters von 12 Wörtern basiert.
Ein wichtiger Aspekt ist, dass der Code eines bestimmten Nachfolgers von BaseFeaturizer neben den Texten selbst auch Wörterbücher benötigt, die auf ihrer Basis erstellt wurden (die CorpusFeatures- Klasse ), die höchstwahrscheinlich bereits zu Beginn des Trainings und des Testens des Modells auf der Festplatte zwischengespeichert sind.
8 Klassifizierung
Die nächste abstrakte Klasse ist BaseClassifier . Dieses Objekt kann trainiert werden und dann Texte anhand ihrer Merkmalsvektoren klassifizieren.
Für die Implementierung (die RandomForestLangClassifier- Klasse ) habe ich den Random Forest Classifier- Algorithmus aus der sklearn- Bibliothek ausgewählt . Warum dieser spezielle Klassifikator?
- Random Forest Classifier passte zu mir mit seinen Standardparametern,
- es erfordert keine Normalisierung der Eingabedaten,
- bietet eine einfache und intuitive Visualisierung des Entscheidungsalgorithmus.
Da der Random Forest Classifier meiner Meinung nach seine Aufgabe gut gemeistert hat, habe ich keine weiteren Implementierungen geschrieben.
9 Schulung und Prüfung
80% der Dateien - große Fragmente aus den Werken von Byron, Aksakov, Apuleius, Pausanias und anderen Autoren, deren Texte ich im txt-Format finden konnte - wurden zufällig ausgewählt, um den Klassifikator zu trainieren. Die verbleibenden 20% (28 Dateien) werden für Tests außerhalb der Stichprobe ermittelt.
Während ich den Klassifikator an ~ 30 englischen und 20 russischen Texten getestet habe, gab der Klassifikator einen großen Prozentsatz an Fehlern: In fast der Hälfte der Fälle wurde die Sprache des Textes falsch bestimmt. Aber als ich ~ 120 Textdateien in 5 Sprachen (Russisch, Englisch, Latein, Althellenisch und Polnisch) startete, machte der Klassifikator keine Fehler mehr und erkannte die Sprache von 27 - 28 Dateien aus 28 Testfällen korrekt.
Dann habe ich das Problem ein wenig kompliziert: Ich habe den irischen Roman "Rachel Gray" aus dem 19. Jahrhundert ins Griechische transkribiert und ihn einem ausgebildeten Klassifikator vorgelegt. Die Sprache des Textes in der Transliteration wurde erneut korrekt definiert.
10 Der Klassifizierungsalgorithmus ist klar
So sieht einer von 100 Bäumen im trainierten Random Forest Classifier aus (um das Bild besser lesbar zu machen, schneide ich 3 Knoten des rechten Teilbaums ab):
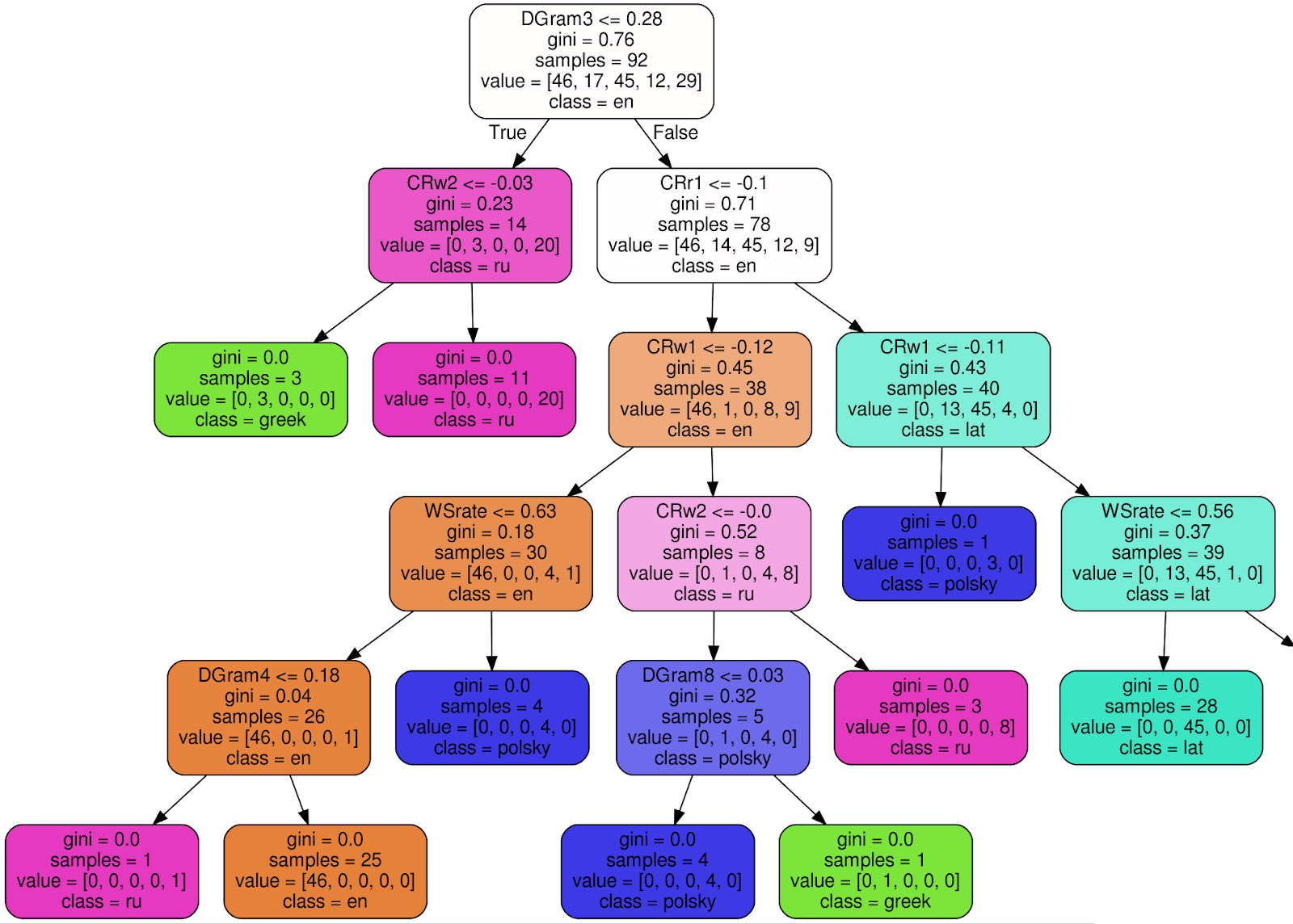
Am Beispiel des Wurzelknotens erkläre ich die Bedeutung jeder Signatur:
- DGram3 <= 0,28 - Klassifizierungskriterium. In diesem Fall ist DGram3 eine bestimmte Dimension eines von der WordMorphFeaturizer-Klasse benannten Merkmalsvektors, nämlich die Häufigkeit des dritthäufigsten Wortes in einem Schiebefenster von 12 Wörtern.
- gini = 0.76 — , Gini impurity, , , . , , - . . , gini, , 0 ( ),
- samples = 92 — , ,
- value = [46, 17, 45, 12, 29] — , (46 , 17 , 45 ..),
- class = en ( ) — .
Wenn das Kriterium (DGram3 <= 0,28 für den Wurzelknoten) erfüllt ist, gehen Sie zum linken Teilbaum, andernfalls - nach rechts. In jedem Blatt sollten alle Texte einer Klasse (Sprache) und dem Gini-Unsicherheitskriterium ≡ 0 zugeordnet werden. Die
endgültige Entscheidung trifft ein Ensemble von 100 ähnlichen Bäumen, die während des Trainings des Klassifikators gebaut wurden.
11 Und wie hat das Programm die Sprache des Manuskripts definiert?
Lateinisch , Wahrscheinlichkeitsschätzung 0,59. Und das ist natürlich noch nicht die Lösung für das Problem des Jahrhunderts.
Eine Eins-zu-Eins-Korrespondenz zwischen dem Manuskriptwörterbuch und der lateinischen Sprache ist nicht einfach - wenn nicht unmöglich. Hier sind zum Beispiel zehn der am häufigsten verwendeten Wörter: Voynich-Manuskripte, Latein,

Altgriechisch und Russisch: Das
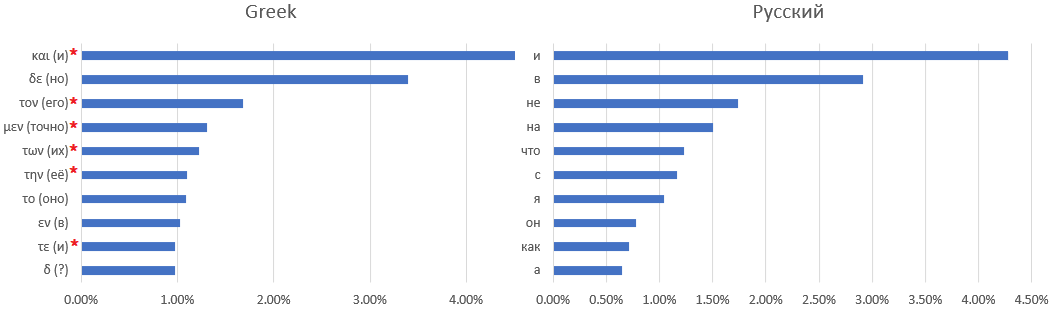
Sternchen kennzeichnet Wörter, für die es schwierig ist, ein russisches Äquivalent zu finden - zum Beispiel Artikel oder Präpositionen, deren Bedeutung je nach Kontext geändert wird.
Eine offensichtliche Übereinstimmung wie
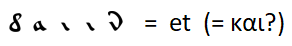
Mit der Erweiterung der Regeln zum Ersetzen von Buchstaben durch andere häufig verwendete Wörter konnte ich nicht finden. Sie können nur Annahmen treffen - zum Beispiel ist das häufigste Wort die Konjunktion "und" - wie in allen anderen betrachteten Sprachen außer Englisch, in denen die Konjunktion "und" durch den bestimmten Artikel "the" auf den zweiten Platz verschoben wurde.
Was weiter?
Zunächst lohnt es sich, die Stichprobe der Sprachen nach Möglichkeit durch Texte in modernem Französisch, Spanisch, ... und nahöstlichen Sprachen zu ergänzen - Altes Englisch, Französische Sprachen (vor dem 15. Jahrhundert) und andere. Selbst wenn keine dieser Sprachen die Sprache des Manuskripts ist, wird die Genauigkeit der Definition bekannter Sprachen immer noch zunehmen, und wahrscheinlich wird ein näheres Äquivalent zur Sprache des Manuskripts ausgewählt.
Eine kreativere Herausforderung besteht darin, für jedes Wort einen Teil der Sprache zu definieren. Für eine Reihe von Sprachen (natürlich vor allem - Englisch) erledigen PoS-Tokenizer (Part of Speech) als Teil der zum Download verfügbaren Pakete diese Aufgabe gut. Aber wie kann man die Rolle von Wörtern in einer unbekannten Sprache bestimmen?
Ähnliche Probleme wurden vom sowjetischen Sprachwissenschaftler B.V. Sukhotin - zum Beispiel beschrieb er die Algorithmen:
- Trennung von Zeichen eines unbekannten Alphabets in Vokale und Konsonanten - leider nicht 100% zuverlässig, insbesondere für Sprachen mit nicht trivialer Phonetik wie Französisch,
- Auswahl von Morphemen im Text ohne Leerzeichen.
Für die PoS-Tokenisierung können wir auf der Häufigkeit der Wortverwendung, dem Auftreten in Kombinationen von 2/3 Wörtern und der Verteilung von Wörtern über Textabschnitte aufbauen: Gewerkschaften und Partikel sollten gleichmäßiger verteilt sein als Substantive.
Literatur
Ich werde hier keine Links zu Büchern und Tutorials über NLP hinterlassen - das reicht im Internet. Stattdessen werde ich Kunstwerke auflisten, die für mich als Kind zu einem großartigen Fund wurden, bei dem die Helden hart arbeiten mussten, um die verschlüsselten Texte zu entwirren:
- E. A. Poe: Der Goldene Käfer ist ein zeitloser Klassiker
- V. Babenko: „Meeting“ ist eine bekanntermaßen verdrehte, etwas visionäre Detektivgeschichte der späten 80er Jahre.
- K. Kirita: „Ritter aus der Chereshnevaya-Straße oder das Schloss des Mädchens in Weiß“ ist ein faszinierender Jugendroman, der für das Alter des Lesers ohne Rabatt geschrieben wurde.