Google: 90% unserer Ingenieure verwenden ein von Ihnen geschriebenes Programm (Homebrew), aber Sie Ich kann einen Binärbaum auf einem Board nicht umkehren, also auf Wiedersehen.
Obwohl ich noch nie einen Binärbaum invertieren musste, stieß ich bei meiner täglichen Arbeit bei Skype / Microsoft, Skyscanner und Uber auf Beispiele für die tatsächliche Verwendung von Datenstrukturen und Algorithmen . Dies beinhaltete Codierung und Entscheidungsfindung basierend auf den Besonderheiten von Datenstrukturen und Algorithmen. Aber ich habe größtenteils das relevante Wissen genutzt, um zu verstehen, wie bestimmte Systeme erstellt wurden und warum sie auf diese Weise erstellt wurden. Die Kenntnis der relevanten Konzepte erleichtert das Verständnis der Architektur und Implementierung der Systeme, in denen diese Konzepte verwendet werden.

In diesem Artikel habe ich Geschichten über Situationen aufgenommen, in denen Datenstrukturen wie Bäume und Diagramme sowie verschiedene Algorithmen in realen Projekten verwendet wurden. Hier möchte ich dem Leser zeigen, dass Grundkenntnisse über Datenstrukturen und Algorithmen keine nutzlose Theorie sind, die nur für Interviews benötigt wird, sondern etwas, das sehr wahrscheinlich von jemandem benötigt wird, der in wachstumsstarken innovativen Technologieunternehmen arbeitet.
Hier werden wir über eine sehr kleine Anzahl von Algorithmen sprechen, aber was Datenstrukturen betrifft, kann ich feststellen, dass ich hier fast alle davon ansprechen werde. Es sollte niemanden überraschen, dass ich kein Fan von Interviewfragen bin, die Algorithmen überbetonen, die nicht mit der Praxis in Berührung kommen und auf exotische Datenstrukturen wie rot-schwarze Bäume oder AVL-Bäume abzielen. Ich habe solche Fragen in Interviews noch nie gestellt und werde sie auch nicht stellen. Am Ende dieses Artikels werde ich meine Gedanken zu solchen Interviews teilen. Trotz alledem ist die Kenntnis der zugrunde liegenden Datenstrukturen von immensem Wert. Mit diesem Wissen können Sie genau auswählen, was zur Lösung bestimmter praktischer Probleme erforderlich ist.
Kommen wir nun zu Beispielen für die Verwendung von Datenstrukturen und Algorithmen im wirklichen Leben.
Bäume und Baumdurchquerung: Skype-, Uber- und UI-Frameworks
Bei der Entwicklung von Skype für Xbox One musste der Code für ein reines Xbox-Betriebssystem geschrieben werden, das nicht über die benötigten Bibliotheken verfügt. Wir haben eine der ersten vollständigen Anwendungen für diese Plattform entwickelt. Wir brauchten ein Anwendungsnavigationssystem, das sowohl über den Touchscreen als auch über Sprachbefehle an die Anwendung bedient werden konnte.
Wir haben ein grundlegendes WinJS-basiertes Navigationsframework erstellt. Dazu mussten wir ein DOM-ähnliches Diagramm pflegen, das die Beobachtung der Elemente organisieren musste, mit denen der Benutzer interagieren konnte. Um solche Elemente zu finden, haben wir eine DOM-Durchquerung durchgeführt, die sich auf die Baumdurchquerung, dh die vorhandene Struktur von DOM-Elementen, beschränkte. Dies ist ein klassisches Beispiel für BFS oder DFS (Breitensuche oder Tiefensuche - Breitensuche oder Tiefensuche).
Wenn Sie eine Webentwicklung durchführen, bedeutet dies, dass Sie bereits mit einer Baumstruktur arbeiten, nämlich dem DOM. Alle DOM-Knoten können untergeordnete Knoten haben. Der Browser zeigt nach dem Durchlaufen des DOM-Baums Knoten auf dem Bildschirm an. Wenn Sie ein bestimmtes Element suchen müssen, können Sie dieses Problem mithilfe der integrierten DOM-Methoden lösen. Zum Beispiel die Methode getElementById. Eine Alternative besteht darin, eine eigene BFS- oder DFS-Lösung zu entwickeln, um die Knoten zu durchlaufen und das zu finden, was Sie benötigen. Zum Beispiel etwas Ähnliches geschieht hier .
Viele Frameworks, die UI-Elemente rendern, verwenden Baumstrukturen in ihrer Tiefe. Daher unterstützt React virtuelles DOM und verwendet einen intelligenten Abstimmungsalgorithmus(Vergleiche). Auf diese Weise können Sie eine hohe Leistung erzielen, da nur die geänderten Teile der Benutzeroberfläche neu gerendert werden. Eine Visualisierung dieses Prozesses finden Sie hier.
In der mobilen Architektur Uber, RIBsEs werden auch Bäume verwendet. Dadurch ähnelt diese Architektur den meisten anderen UI-Frameworks, die hierarchische Strukturen von Elementen anzeigen. Die RIBs-Architektur verwaltet einen RIB-Baum für Statusverwaltungszwecke. Durch das Anhängen und Trennen von RIBs wird das Rendern gesteuert. Während der Arbeit mit RIBs haben wir manchmal skizziert und versucht zu verstehen, ob die RIBs in die vorhandene Hierarchie passen, und diskutiert, ob die fraglichen RIBs sichtbare Elemente haben sollten. Das heißt, sie sprachen darüber, ob diese Struktur an der Bildung der visuellen Darstellung der Schnittstelle beteiligt sein wird oder nur für die Zustandsverwaltung verwendet wird.

Zustandsübergänge bei Verwendung von RIBs. Sie können weitere Informationen über RIB finden Sie hier.
Wenn Sie jemals hierarchische Elemente machen müssen, beachtendass Baumstrukturen in der Regel für diese verwendet werden, sie durchqueren und besuchten Elementemachen. Ich bin auf viele interne Tools gestoßen, die diesen Ansatz verfolgen. Ein Beispiel für ein solches Tool ist der RIBs-Renderer, der vom Mobile Platform-Team bei Uber erstellt wurde. Hier ist ein Bericht zu diesem Thema.
Gewichtete Grafiken und Finder für kürzeste Wege: Skyscanner
Skyscanner ist ein Projekt, das darauf abzielt, die besten Angebote für Flugtickets zu finden. Die Suche nach solchen Vorschlägen erfolgt durch Anzeigen und Analysieren aller weltweit existierenden Routen und deren Kombination. Das Wesentliche dieser Aufgabe hängt eher mit der automatischen Datenerfassung durch einen Suchroboter zusammen und nicht mit dem Zwischenspeichern all dieser Daten, da Fluggesellschaften die Wartezeit für den nächsten Flug unabhängig berechnen. Die Möglichkeit, eine Reise mit einem Besuch in mehreren Städten zu planen, hängt jedoch von der Aufgabe ab, den kürzesten Weg zu finden.
Die Reiseplanung für mehrere Städte war eine der Möglichkeiten, deren Implementierung Skyscanner lange gedauert hat. Gleichzeitig betrafen die Schwierigkeiten hauptsächlich das System, das selbst entwickelt wurde. Die besten Angebote dieser Art werden mit Algorithmen für kürzeste Wege wie Dijkstra oder A * gefunden. Flugrouten werden in Form eines gerichteten Diagramms dargestellt. Jeder Kante wird ein Gewicht in Form eines Ticketpreises zugewiesen. Bei der Suche nach der besten Route wird die Suche nach der günstigsten Route zwischen zwei Städten mithilfe der Implementierung des modifizierten A * -Algorithmus durchgeführt . Wenn Sie sich für das Thema Flugtickets auswählen und die kürzesten Routen finden möchten, finden Sie hier einen guten Artikel zur Verwendung von BFS zur Lösung solcher Probleme.
Im Fall von Skyscanner war es jedoch nicht besonders wichtig, welcher Algorithmus zur Lösung des Problems verwendet wurde. Caching, Verwendung von Suchrobotern, Organisation der Arbeit mit verschiedenen Sites - all dies war viel schwieriger als die Auswahl eines Algorithmus. Gleichzeitig treten in vielen verschiedenen Reiseplanungsunternehmen unterschiedliche Varianten des Problems auf, den kürzesten Weg zu finden und die Kosten solcher Reisen zu optimieren. Es überrascht nicht, dass dieses Thema auch bei Skyscanner Gegenstand von Gesprächen hinter den Kulissen war.
Sortieren: Skype (oder so ähnlich)
Ich hatte selten einen Grund, Sortieralgorithmen selbst zu implementieren oder die Feinheiten ihres Designs gründlich zu untersuchen. Trotzdem war es interessant zu verstehen, wie solche Algorithmen funktionieren - von Blasensortierung, Einfügesortierung, Zusammenführungssortierung und Auswahlsortierung bis hin zum komplexesten Algorithmus - Quicksort. Ich habe festgestellt, dass solche Algorithmen selten implementiert werden müssen, insbesondere wenn Sie keine Sortierfunktion schreiben müssen, die Teil einer Bibliothek ist.
In Skype musste ich jedoch auf die praktische Anwendung meiner Kenntnisse über Sortieralgorithmen zurückgreifen. Einer unserer Programmierer hat beschlossen, eine Einfügesortierung für die Anzeige von Kontakten zu implementieren. Im Jahr 2013, als Skype online war, wurden Kontakte stapelweise heruntergeladen. Das Herunterladen dauerte einige Zeit. Infolgedessen hielt dieser Programmierer es für besser, eine Liste von Kontakten zu erstellen, die nach Namen sortiert sind, indem sie die Einfügesortierung verwenden. Wir haben diesen Algorithmus viel diskutiert und darüber nachgedacht, warum wir nicht einfach etwas verwenden sollten, das bereits implementiert wurde. Infolgedessen haben wir die meiste Zeit gebraucht, um unsere Implementierung des Algorithmus ordnungsgemäß zu testen und seine Leistung zu überprüfen. Persönlich sah ich nicht viel Sinn darin, meine eigene Implementierung dieses Algorithmus zu erstellen. Aber dann war das Projekt in einem solchen Stadiumwo wir Zeit für solche Dinge hatten.
Natürlich gibt es reale Situationen, in denen eine effiziente Sortierung in einem Projekt eine sehr wichtige Rolle spielt. Und wenn der Entwickler unabhängig von den Merkmalen der Daten den am besten geeigneten Algorithmus auswählen kann, kann dies zu einer spürbaren Steigerung der Leistung der Lösung führen. Die Sortierung nach Einfügungen kann sehr nützlich sein, wenn Sie mit großen Datenmengen arbeiten, die irgendwo in Echtzeit übertragen werden, und diese Daten sofort visualisieren. Die Zusammenführungssortierung eignet sich gut zum Teilen und Erobern von Ansätzen, wenn große Datenmengen verarbeitet werden, die auf verschiedenen Knoten gespeichert sind. Ich habe noch nie mit solchen Systemen gearbeitet, daher betrachte ich Sortieralgorithmen vorerst weiterhin als etwas, das in der täglichen Arbeit nur begrenzt eingesetzt werden kann. Es stimmt,Es geht nicht darum, zu verstehen, wie die verschiedenen Sortieralgorithmen funktionieren.
Hash-Tabellen und Hashing: überall
Die Datenstruktur, die ich regelmäßig verwende, ist eine Hash-Tabelle. Dies beinhaltet auch Hash-Funktionen. Dies ist ein sehr nützliches Tool, mit dem eine Vielzahl von Aufgaben gelöst werden können - vom Zählen der Anzahl bestimmter Entitäten über das Erkennen von Duplikaten, das Zwischenspeichern bis hin zu Szenarien wie Sharding, die in verteilten Systemen verwendet werden . Hash-Tabellen sind nach Arrays die häufigste Datenstruktur in der Programmierung. Ich habe es in unzähligen Situationen benutzt. Es ist in fast allen Programmiersprachen vorhanden und bei Bedarf einfach selbst zu implementieren.
Stapel und Warteschlangen: von Zeit zu Zeit
Ein Stack ist eine Datenstruktur, die jedem bekannt ist, der Debug-Code in einer Sprache geschrieben hat, die Stack-Traces unterstützt. Wenn wir über den Stapel als Datenstruktur sprechen, bin ich im Laufe der Arbeit auf mehrere Probleme gestoßen, für deren Lösung er benötigt wurde. Es sollte jedoch beachtet werden, dass ich die Stapel beim Debuggen und Profilieren der Codeleistung richtig kennengelernt habe. Stapel sind auch eine natürliche Wahl für die Datenstruktur, die bei der Ausführung von DFS verwendet werden soll.
Ich musste selten auf Warteschlangen zurückgreifen, aber ich traf sie ziemlich oft in den Codebasen verschiedener Projekte. Angenommen, etwas wurde in die Warteschlange gestellt und etwas daraus abgerufen. In der Regel werden Warteschlangen verwendet, um die Durchquerung des Baums mit der Breite zuerst zu implementieren, und sie sind ideal für diese Aufgabe. Warteschlangen können auch in vielen anderen Situationen verwendet werden. Eines Tages stieß ich auf einen Jobplanungscode , in dem ich ein Beispiel für eine anständige Verwendung der vom Heapq- Python-Modul implementierten Prioritätswarteschlange fand , als die kürzesten Jobs zuerst ausgeführt wurden.
Kryptographische Algorithmen: Uber
Wichtige Daten, die Benutzer in mobile Apps oder Web-Apps eingeben, müssen verschlüsselt werden, bevor sie über das Netzwerk übertragen werden. Und sie entschlüsseln sie nur dort, wo sie gebraucht werden. Um ein solches Arbeitsschema zu organisieren, muss die Implementierung kryptografischer Algorithmen auf den Client- und Serverteilen der Anwendungen vorhanden sein.
Das Verständnis kryptografischer Algorithmen ist sehr interessant. Gleichzeitig sollten Sie keine eigenen Algorithmen zur Lösung bestimmter Probleme anbieten. Dies ist eine der schlimmsten Ideen, an die ein Programmierer denken kann. Stattdessen wird ein vorhandener, gut dokumentierter Standard verwendet und die integrierten Grundelemente der jeweiligen Frameworks verwendet. Normalerweise fungiert AES als Standard für die Implementierung kryptografischer Lösungen.... Es ist sicher genug, um Verschlusssachen in den USA zu verschlüsseln . Es sind keine funktionierenden Angriffe auf das Protokoll bekannt. AES-192 und AES-256 sind für die meisten praktischen Aufgaben normalerweise recht zuverlässig.
Als ich zu Uber kam, waren das mobile Verschlüsselungssystem und das Verschlüsselungssystem für die Webanwendung bereits implementiert. Sie basierten auf den oben genannten Mechanismen. Ich hatte also eine Ausrede, die Details zu AES (Advanced Encryption Standard) und HMAC (Hashed Message Authentication Codes) zu studieren. über den RSA-Algorithmus und andere solche Dinge. Es war auch interessant zu verstehen, wie die kryptografische Stärke der bei der Verschlüsselung verwendeten Abfolge von Aktionen bewiesen wird. Wenn wir beispielsweise über authentifizierte Verschlüsselung mit angehängten Daten sprechen, stellt sich heraus, dass bei der Analyse der Modi Verschlüsselung und MAC, MAC-dann-Verschlüsselung und Verschlüsselung-dann-MAC die kryptografische Stärke nur eines von ihnen nachgewiesen werden kann , obwohl dies nicht bedeutet Der Rest ist nicht kryptografisch sicher.
Sie müssen kryptografische Grundelemente kaum selbst implementieren, es sei denn, Sie implementieren ein völlig neues kryptografisches Framework. Möglicherweise müssen Sie jedoch entscheiden, welche Grundelemente verwendet und wie sie kombiniert werden sollen. Möglicherweise benötigen Sie auch Kenntnisse auf dem Gebiet der kryptografischen Algorithmen, um zu verstehen, warum ein bestimmtes System einen bestimmten Ansatz zur Datenverschlüsselung verwendet.
Entscheidungsbäume: Uber
Während wir an einem der Projekte arbeiteten, mussten wir komplexe Geschäftslogik in einer mobilen Anwendung implementieren. Basierend auf einem halben Dutzend Regeln musste nämlich einer von mehreren Bildschirmen angezeigt werden. Diese Regeln waren sehr komplex, da die Ergebnisse der Testsequenz und die Präferenz des Benutzers berücksichtigt werden mussten.
Der Programmierer, der dieses Problem zu lösen begann, versuchte zunächst, alle diese Regeln in Form von if-else-Anweisungen auszudrücken. Dies führte zu äußerst verwirrendem Code. Infolgedessen wurde beschlossen, den Entscheidungsbaum zu verwenden. Mit seiner Hilfe war es einfach, alle notwendigen Kontrollen durchzuführen. Es war relativ einfach zu implementieren. Darüber hinaus kann es bei Bedarf problemlos geändert werden. Wir mussten unsere eigene Implementierung des Entscheidungsbaums erstellen, sodass die Bedingungen an seinen Rändern überprüft werden. Das ist alles was wir von diesem Baum brauchen. Während wir durch einen anderen Ansatz die Zeit sparen konnten, die für die Implementierung des Baums aufgewendet wurde, entschied das Team, dass der jeweilige Baum einfacher zu pflegen ist, und machte sich an die Arbeit. Dieser Baum sieht so aus:Die Kanten symbolisieren die Ergebnisse der Überprüfung der Bedingungen (dies sind binäre Ergebnisse oder Ergebnisse, die durch Wertebereiche dargestellt werden), und die Blattknoten des Baums beschreiben die Bildschirme, zu denen Sie navigieren müssen.
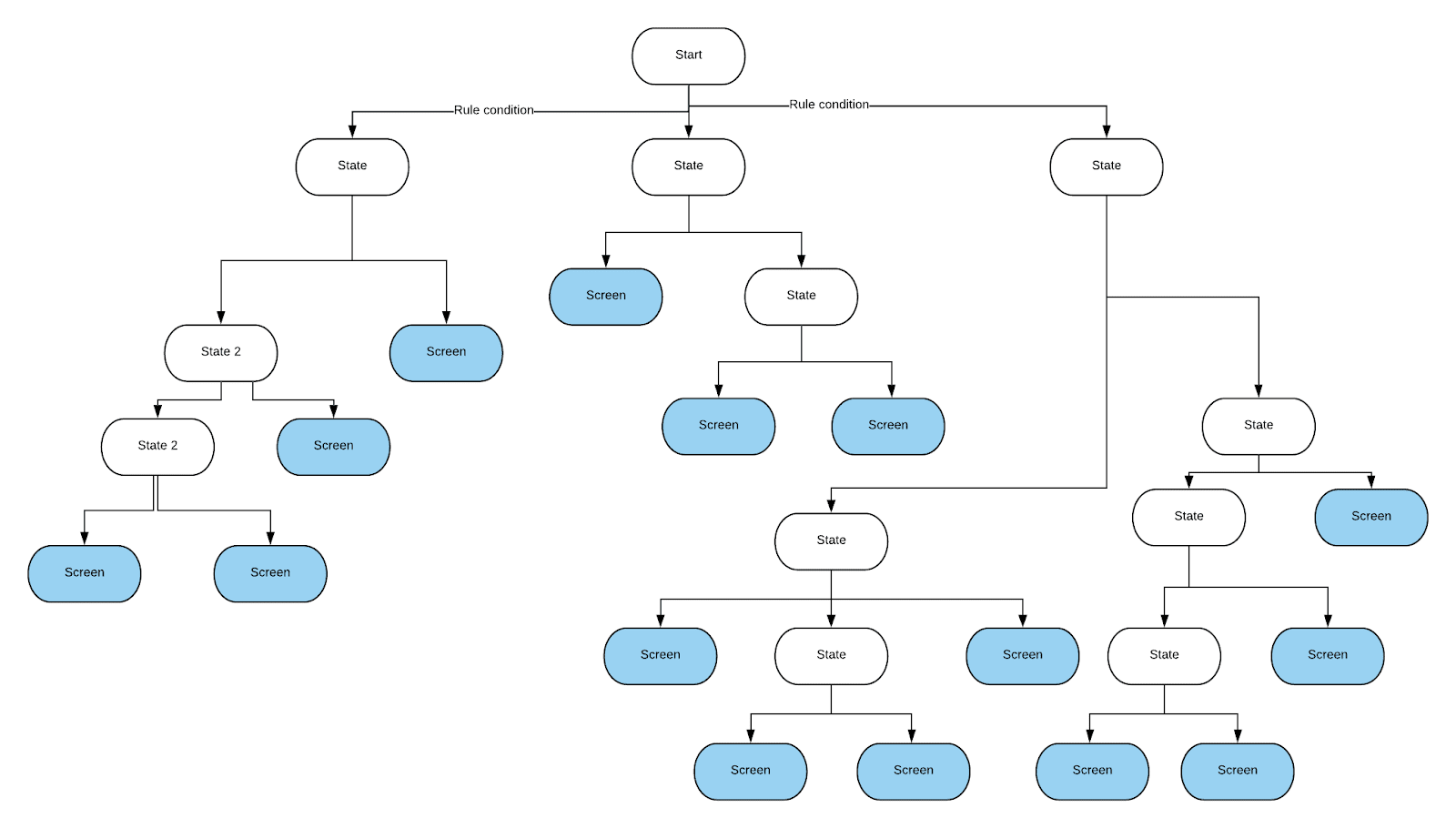
, , .
Das Build-System für Ubers mobile App namens SubmitQueue verwendete ebenfalls einen Entscheidungsbaum, der jedoch dynamisch generiert wurde. Das Developer Experience-Team musste sich mit dem schwierigen Problem befassen, täglich Hunderte von Quellzweigen mit dem Zielzweig zusammenzuführen. Gleichzeitig dauerte jede Montage etwa 30 Minuten. Dies umfasste das Kompilieren, Ausführen von Unit- und Integrationstests sowie Schnittstellentests. Das Parallelisieren von Assemblys war keine ausreichend gute Lösung, da sich Änderungen in verschiedenen Assemblys häufig überlappten, was zu Zusammenführungskonflikten führte. In der Praxis bedeutete dies, dass Programmierer manchmal 2-3 Stunden warten, auf eine Neubasis zurückgreifen und den Zusammenführungsprozess erneut starten mussten, in der Hoffnung, dass sie diesmal keinen Konflikt hatten.
Das Developer Experience-Team verfolgte einen innovativen Ansatz, um Zusammenführungskonflikte und Warteschlangenassemblierungen entsprechend vorherzusagen. Dies wurde unter Verwendung eines speziellen binären Entscheidungsbaums (Spekulationsbaum) durchgeführt.

SubmitQueue verwendet einen binären Entscheidungsbaum mit Kanten, die mit vorhergesagten Wahrscheinlichkeiten versehen sind. Mit diesem Ansatz können Sie bestimmen, welche Baugruppensätze parallel ausgeführt werden können. Dies geschieht, um die Zeit zwischen dem Empfangen und Ausführen von Aufgaben zu verkürzen und um den Systemdurchsatz zu erhöhen. In diesem Fall sollte nur vollständig getesteter und funktionsfähiger Code in den Hauptzweig gelangen. Das
Developer Experience-Team, das dieses System erstellt hat, hat hervorragendes Material darüber geschrieben. Aber hier- ein weiterer Artikel zum gleichen Thema, gut illustriert. Das Ergebnis der Einführung dieses Systems war die Schaffung eines viel schnelleren Projektmontagesystems als zuvor. Dadurch konnten wir die Bauzeit von Projekten optimieren und das Leben von Hunderten von mobilen Programmierern erleichtern.
Sechseckige Gitter, hierarchische Indizes: Uber
Dies ist das letzte Projekt, über das ich hier sprechen möchte. Es basierte vollständig auf einer bestimmten Datenstruktur. Auf diese Weise habe ich etwas über diese Datenstruktur gelernt. Wir sprechen von einem hexagonalen Gitter mit hierarchischen Indizes.
Eines der herausforderndsten und interessantesten Probleme bei Uber war die Optimierung der Reisekosten und die Verteilung der Bestellungen unter den Partnern. Die Fahrpreise können sich dynamisch ändern, die Fahrer sind ständig in Bewegung. Die Ingenieure von Uber haben das H3-Netzsystem entwickelt. Es wurde entwickelt, um Daten über Städte hinweg in verschiedenen Maßstäben zu visualisieren und zu analysieren. Die Datenstruktur, die zur Lösung der oben genannten Probleme verwendet wird, ist ein hexagonales Gitter mit hierarchischen Indizes. Zur Visualisierung der Daten werden einige spezielle interne Tools verwendet.

Aufteilen der Karte in hexagonale Zellen
Diese Datenstruktur verfügt über ein eigenes Indexierungssystem, eine Durchquerung, eigene Definitionen einzelner Bereiche des Rasters und eigene Funktionen. Eine ausführliche Beschreibung all dessen finden Sie in der Dokumentation zur entsprechenden API. Lesenmehr über H3 hier . Hier ist der Quellcode. Hier finden Sie eine Geschichte darüber, wie und warum dieses System erstellt wurde.
Durch die Erfahrung mit diesem System konnte ich ein Gefühl dafür bekommen, dass die Erstellung eigener spezialisierter Datenstrukturen bei der Lösung sehr spezifischer Probleme sinnvoll sein kann. Es gibt nur sehr wenige Probleme, bei deren Lösung Sie ein hexagonales Gitter anwenden können, wenn Sie die Unterteilung in Kartenfragmente bei einem Vergleich mit jedem resultierenden Datenfragment verschiedener Ebenen nicht berücksichtigen. Wie in anderen Fällen ist dies jedoch viel einfacher zu verstehen, wenn Sie mit anderen Datenstrukturen vertraut sind. Und für eine Person, die sich mit einem sechseckigen Gitter befasst hat, ist es einfacher, eine neue Datenstruktur zu erstellen, mit der Probleme gelöst werden können, die denen ähneln, die mit einem solchen Gitter gelöst werden.
Datenstrukturen und Algorithmen in Interviews
Oben habe ich darüber gesprochen, auf welche Datenstrukturen und Algorithmen ich bei meiner langen Arbeit in verschiedenen Unternehmen gestoßen bin. Ich schlage jetzt vor, zu dem Tweet von Max Howell zurückzukehren, den ich ganz am Anfang des Artikels erwähnt habe. Dort beschwerte sich Max, dass er in einem Google-Interview gebeten wurde, einen Binärbaum auf einer Tafel umzukehren. Er tat es nicht. Ihm wurde die Tür gezeigt. In dieser Situation bin ich auf Max 'Seite.
Ich glaube, dass das Wissen darüber, wie beliebte Algorithmen funktionieren oder wie exotische Datenstrukturen funktionieren, nicht die Art von Wissen ist, die Sie benötigen, um für ein Technologieunternehmen zu arbeiten. Sie müssen wissen, was ein Algorithmus ist, Sie müssen in der Lage sein, selbstständig einfache Algorithmen zu entwickeln, zum Beispiel nach dem "gierigen" Prinzip. Sie müssen auch Kenntnisse über die gängigsten Datenstrukturen wie Hash-Tabellen, Warteschlangen und Stapel haben. Aber etwas ganz Spezifisches, wie Dijkstras Algorithmus oder A * oder etwas noch Komplexeres, muss nicht auswendig gelernt werden. Wenn Sie diese Algorithmen wirklich benötigen, können Sie leicht Referenzmaterialien darauf finden. Wenn wir zum Beispiel über Algorithmen sprechen, die nicht mit Sortieralgorithmen zusammenhängen, habe ich normalerweise versucht, sie allgemein zu verstehen und ihre Essenz zu verstehen.Gleiches gilt für exotische Datenstrukturen wie rot-schwarze Bäume und AVL-Bäume. Ich hatte nie das Bedürfnis, sie zu benutzen. Und wenn ich sie brauchte, konnte ich mein Wissen über sie jederzeit auffrischen, indem ich auf die entsprechenden Veröffentlichungen zurückgriff. Wie ich bereits sagte, stelle ich beim Interview niemals solche Fragen, und ich habe nicht vor, sie zu stellen.
Ich bin für praktische Probleme im Zusammenhang mit der Programmierung, bei deren Lösung Sie eine Vielzahl von Ansätzen anwenden können: von Methoden der "Brute Force" - und "gierigen" Varianten von Algorithmen bis hin zu fortgeschritteneren algorithmischen Ideen. Zum Beispiel, ich glaube , es vollkommen in Ordnung ist , eine Textausrichtung Aufgabe wie haben diese . Zum Beispiel musste ich dieses Problem lösen, als ich eine Komponente zum Rendern von Text unter Windows Phone erstellte. Sie können dieses Problem einfach lösen, indem Sie ein Array und einige if-else-Anweisungen verwenden, ohne auf knifflige Datenstrukturen zurückgreifen zu müssen.
Tatsächlich übertreiben viele Teams und Unternehmen die Bedeutung algorithmischer Probleme. Ich verstehe die Attraktivität der Algorithmusfragen. Sie ermöglichen es Ihnen, den Bewerber in kurzer Zeit zu bewerten. Die Fragen sind leicht zu wiederholen. Wenn also die Fragen, die jemandem gestellt wurden, öffentlich werden, entstehen keine besonderen Probleme. Algorithmusfragen eignen sich gut für die Organisation von Studien für eine große Anzahl von Bewerbern. Sie können beispielsweise einen Pool von über hundert Fragen erstellen und diese zufällig an Bewerber verteilen. Fragen zur dynamischen Programmierung und zu exotischen Datenstrukturen werden immer häufiger. Besonders im Silicon Valley. Diese Fragen können Unternehmen dabei helfen, starke Programmierer einzustellen. Dieselben Fragen können jedoch den Weg für diejenigen Personen ebnen, die im Geschäft erfolgreich waren.wo tiefe Kenntnisse der Algorithmen nicht erforderlich sind.
Wenn Sie aus einem Unternehmen stammen, das nur Mitarbeiter anstellt, die fast von Geburt an über umfassende Kenntnisse komplexer Algorithmen verfügen, sollten Sie sich genau überlegen, ob dies die Personen sind, die Sie benötigen. Zum Beispiel habe ich großartige Teams bei Skyscanner (London) und Uber (Amsterdam) engagiert, ohne knifflige Algorithmusfragen zu stellen. Ich beschränkte mich auf die gängigsten Datenstrukturen und testete die Fähigkeiten des Befragten, die für die Problemlösung relevant sind. Das heißt, sie mussten über gängige Datenstrukturen Bescheid wissen und in der Lage sein, einfache Algorithmen zur Lösung der Probleme zu entwickeln, mit denen sie konfrontiert sind. Datenstrukturen und Algorithmen sind nur Werkzeuge.
Fazit: Datenstrukturen und Algorithmen sind Werkzeuge
Wenn Sie für ein dynamisches, innovatives Technologieunternehmen arbeiten, werden Sie wahrscheinlich auf Implementierungen einer Vielzahl von Datenstrukturen und Algorithmen im Code der Produkte dieses Unternehmens stoßen. Wenn Sie etwas völlig Neues entwickeln, müssen Sie häufig nach Datenstrukturen suchen, die es einfacher machen, die Probleme zu lösen, mit denen Sie konfrontiert sind. In solchen Situationen benötigen Sie allgemeine Kenntnisse über Algorithmen und Datenstrukturen sowie deren Vor- und Nachteile, um die richtige Wahl treffen zu können.
Datenstrukturen und Algorithmen sind Werkzeuge, die Sie beim Schreiben von Programmen mit Sicherheit verwenden sollten. Wenn Sie diese Tools kennen, werden Sie viel von dem, was Sie bereits wissen, in den Codebasen sehen, die sie verwenden. Darüber hinaus können Sie mit diesem Wissen komplexe Probleme mit viel mehr Vertrauen lösen. Sie kennen die theoretischen Einschränkungen von Algorithmen und wissen, wie sie optimiert werden können. Dies wird Ihnen helfen, letztendlich zu einer Lösung zu gelangen, die sich mit allen erforderlichen Kompromissen als so gut wie möglich herausstellt.
Wenn Sie Datenstrukturen und Algorithmen besser verstehen möchten, finden Sie hier einige Tipps und Ressourcen:
- -, , , , , , . , , . , . — , .
- « ». , , , . — , , . , , , .
- Hier noch ein paar Bücher: „ Algorithmen. Entwicklungshandbuch "und" Algorithmen in Java, 4. Ausgabe ". Ich habe sie verwendet, um mein Universitätswissen über Algorithmen aufzufrischen. Es stimmt, ich habe sie nicht bis zum Ende gelesen. Sie schienen mir eher trocken und für meine tägliche Arbeit nicht anwendbar zu sein.
Auf welche Datenstrukturen und Algorithmen sind Sie in der Praxis gestoßen?
